trihug feb: hive on spark
TRANSCRIPT

Hive on Spark
Szehon Ho // Cloudera Software Engineer, Apache Hive PMC

2 © 2014 Cloudera, Inc. All rights reserved.
Background (Hive) • Apache Hive: SQL-based data query and management tool for a
distributed dataset • Founded in 2007 at Facebook, most of our customers run Hive
jobs in production.
3 © 2014 Cloudera, Inc. All rights reserved.
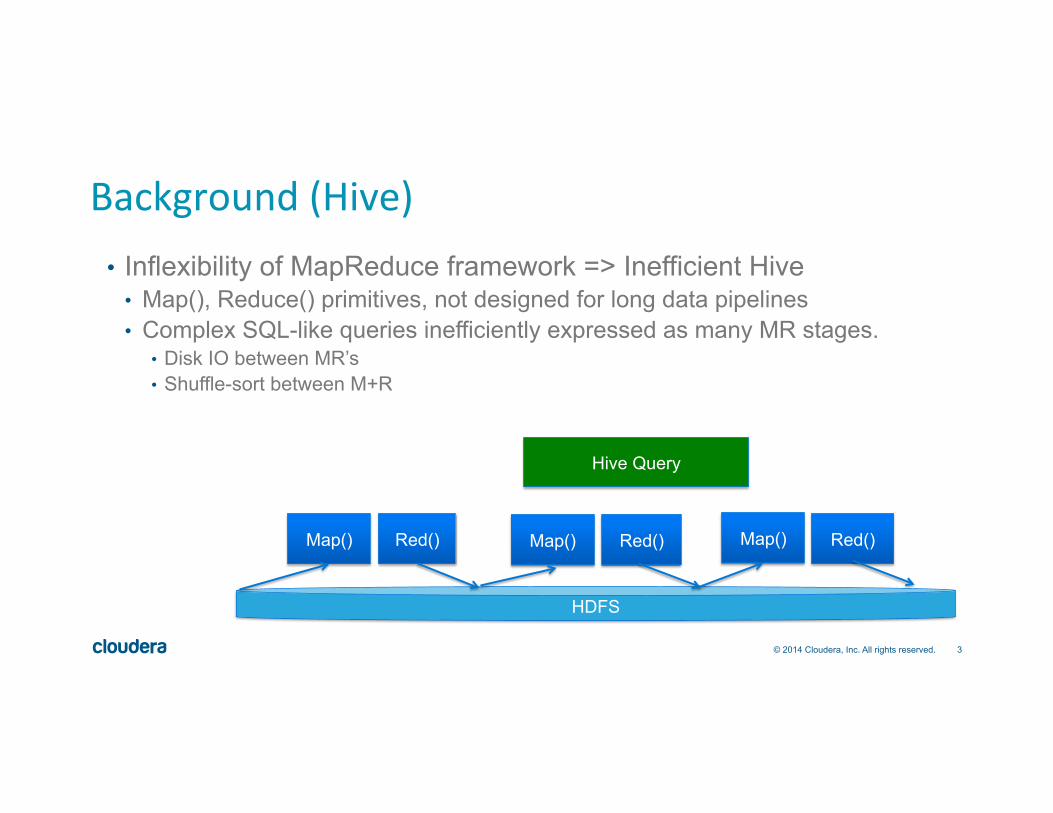
Background (Hive) • Inflexibility of MapReduce framework => Inefficient Hive
• Map(), Reduce() primitives, not designed for long data pipelines • Complex SQL-like queries inefficiently expressed as many MR stages.
• Disk IO between MR’s • Shuffle-sort between M+R
Map() Red()
Hive Query
Map() Red() Map() Red()
HDFS
4 © 2014 Cloudera, Inc. All rights reserved.
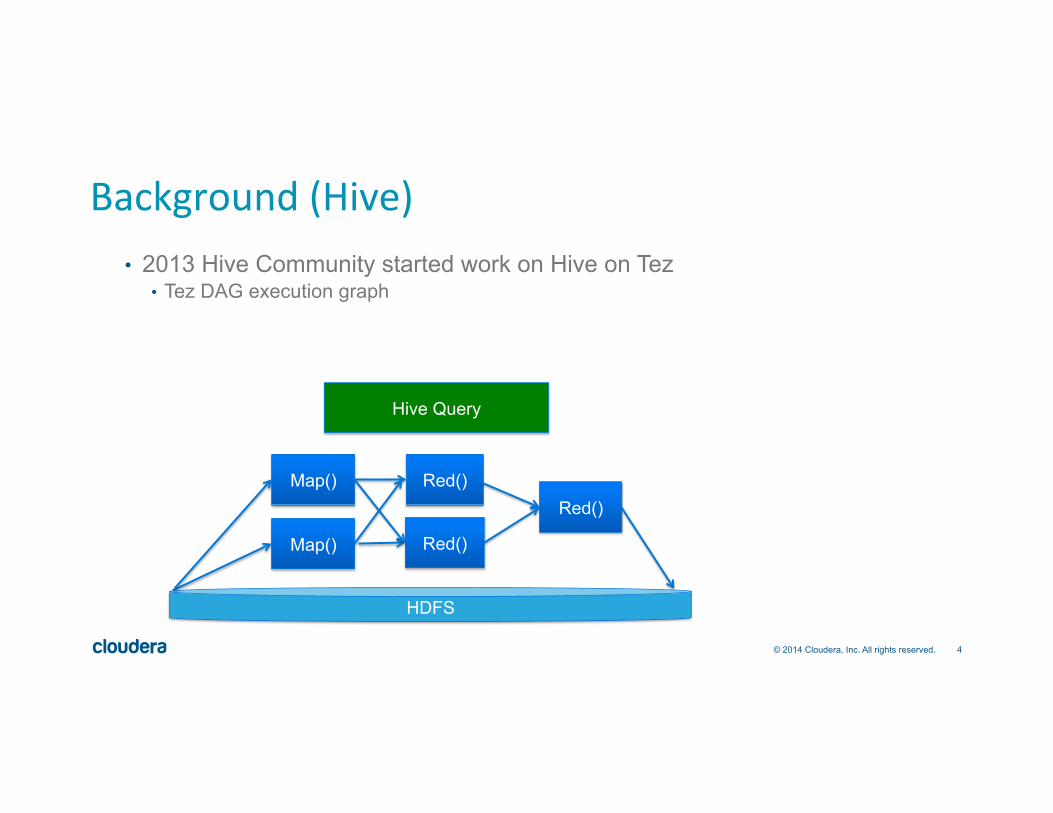
Background (Hive) • 2013 Hive Community started work on Hive on Tez
• Tez DAG execution graph
Map() Red()
Hive Query
Map() Red()
Red()
HDFS

5 © 2014 Cloudera, Inc. All rights reserved.
Background (Spark) • Generalized distributed processing framework created in ~2011 by
UC Berkeley AMPLab • Popular framework, heading to succeed MapReduce

6 © 2014 Cloudera, Inc. All rights reserved.
Background (Spark) • Clean programming abstrac:on: Resilient Distributed Dataset (RDD):
• A fault-‐tolerant dataset, can be a stage in a data pipeline. • Created from exis:ng data set like HDFS file, or transforma:on from other RDD (chain-‐up RDD’s)
• Expressive API’s, much more than MapReduce • Transforma:ons: map, filter, groupBy • Ac:ons: cache, save
• => More efficient representa:on of Hive queries

7 © 2014 Cloudera, Inc. All rights reserved.
Background (Spark) • Community Momentum:
• Spark Summit 2014: Already the most active project in Hadoop ecosystem, top 3 most active Apache projects.
• Since Spark 1.0 in June, two more biggest releases 1.1, 1.2
Compared to Other Projects
Map
Redu
ce
YARN
HDFS
St
orm
Spar
k
0
200
400
600
800
1000
1200
1400
Map
Redu
ce
YARN
HDFS
St
orm
Spar
k 0
50000
100000
150000
200000
250000
300000
Commits Lines of Code Changed
Activity in past 6 months
Compared to Other Projects
Map
Redu
ce
YARN
HDFS
St
orm
Spar
k
0
200
400
600
800
1000
1200
1400
Map
Redu
ce
YARN
HDFS
St
orm
Spar
k 0
50000
100000
150000
200000
250000
300000
Commits Lines of Code Changed
Activity in past 6 months

8 © 2014 Cloudera, Inc. All rights reserved.
Background (Spark) • Community Momentum:
• Advanced analytics, data science, ML, graph processing, etc. • Integration from with many Hadoop tools, ie Pig, Flume, Mahout, Crunch, Solr • Hive jobs can now leverage these Spark clusters as well

9 © 2014 Cloudera, Inc. All rights reserved.
Hive on Spark • Shark Project:
• AMPLab github project, fork of Hive • Not maintained by Hive community, sunseUed 2014
• Hive on Spark: • Done in Hive community • Architecturally compa:ble, by keeping same physical abstrac:on for Hive on Spark as Hive on Tez/MR.
• Code maintenance • Maximize re-‐use of common func:onality across execu:on engine
10 © 2014 Cloudera, Inc. All rights reserved.
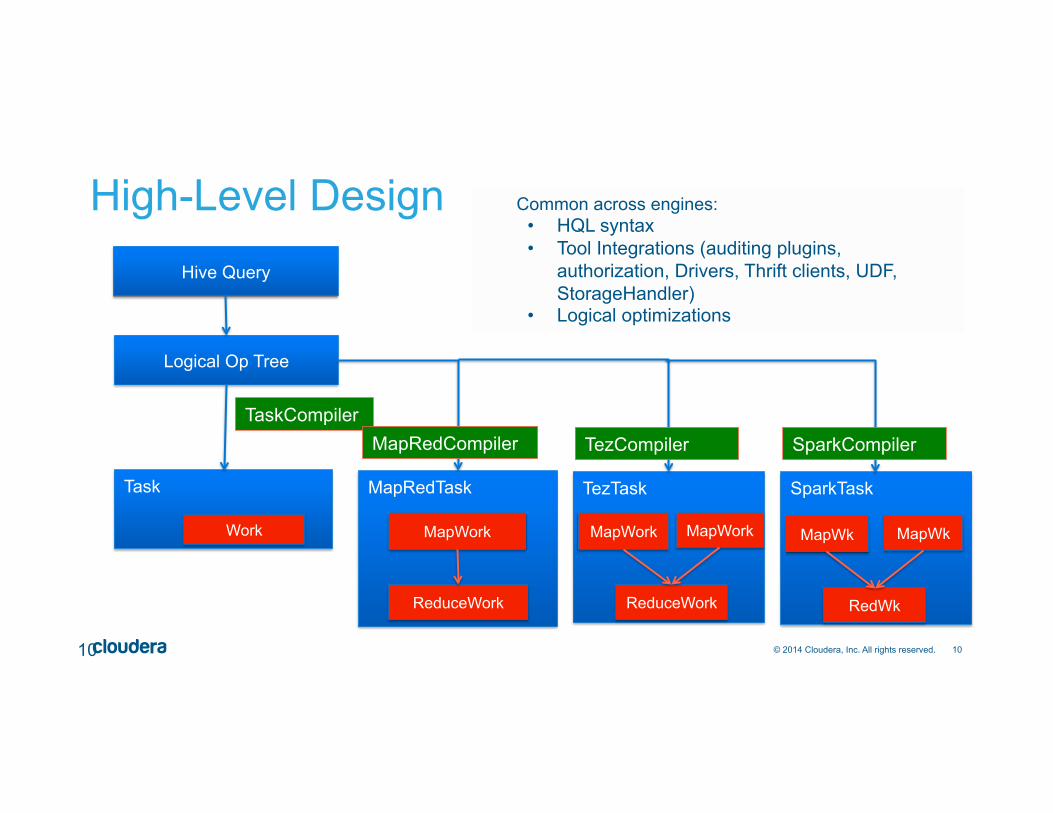
High-Level Design
10
Hive Query
Logical Op Tree
Task
TaskCompiler
Work
MapRedTask
MapWork
TezTask SparkTask
Common across engines: • HQL syntax • Tool Integrations (auditing plugins,
authorization, Drivers, Thrift clients, UDF, StorageHandler)
• Logical optimizations
ReduceWork
MapWork
ReduceWork
MapWork MapWk
RedWk
MapWk
SparkCompiler MapRedCompiler TezCompiler

11 © 2014 Cloudera, Inc. All rights reserved.
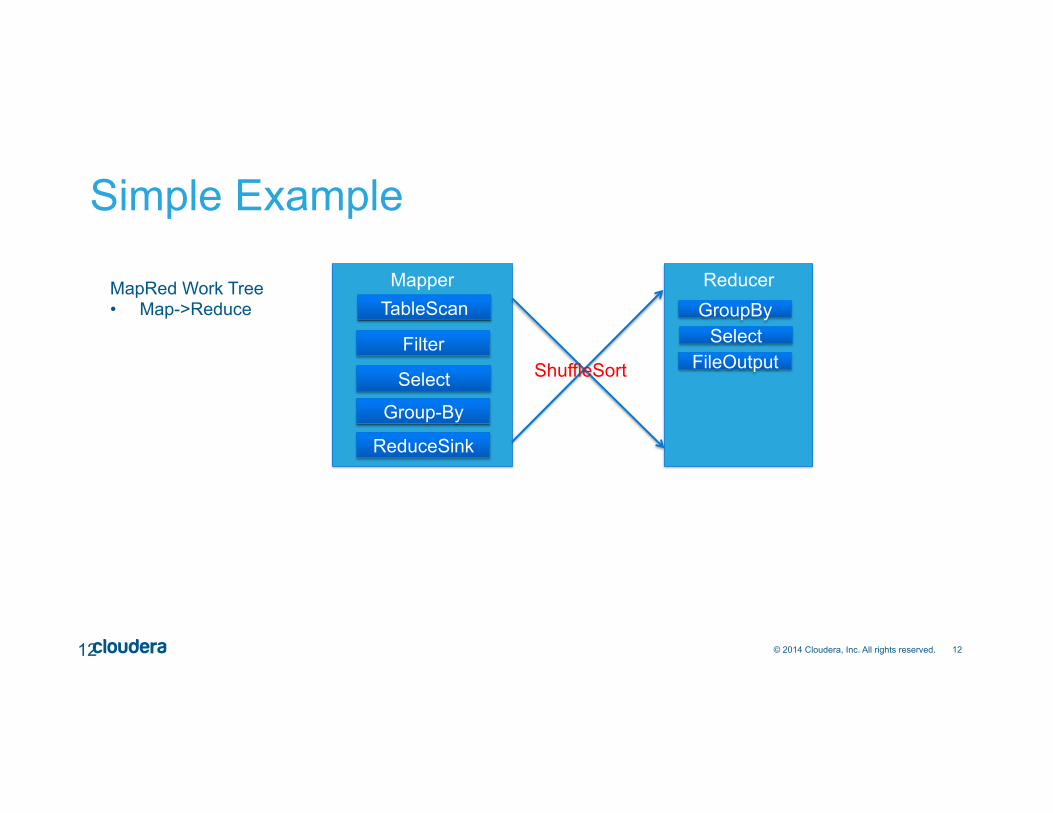
Simple Example
11
SELECT COUNT(*) from status_updates where ds = ‘2014-10-01’ group by region;
TableScan (status_updates)
Filter (ds=‘2014 10-01’)
Select (region)
Group-By (count)
Select
Operator Tree:
Hive Query:
GBY trigger reduce-boundary:
12 © 2014 Cloudera, Inc. All rights reserved.
Simple Example
12
Reducer GroupBy
Select FileOutput
Mapper TableScan
Filter
Select
Group-By
ReduceSink
MapRed Work Tree • Map->Reduce
ShuffleSort
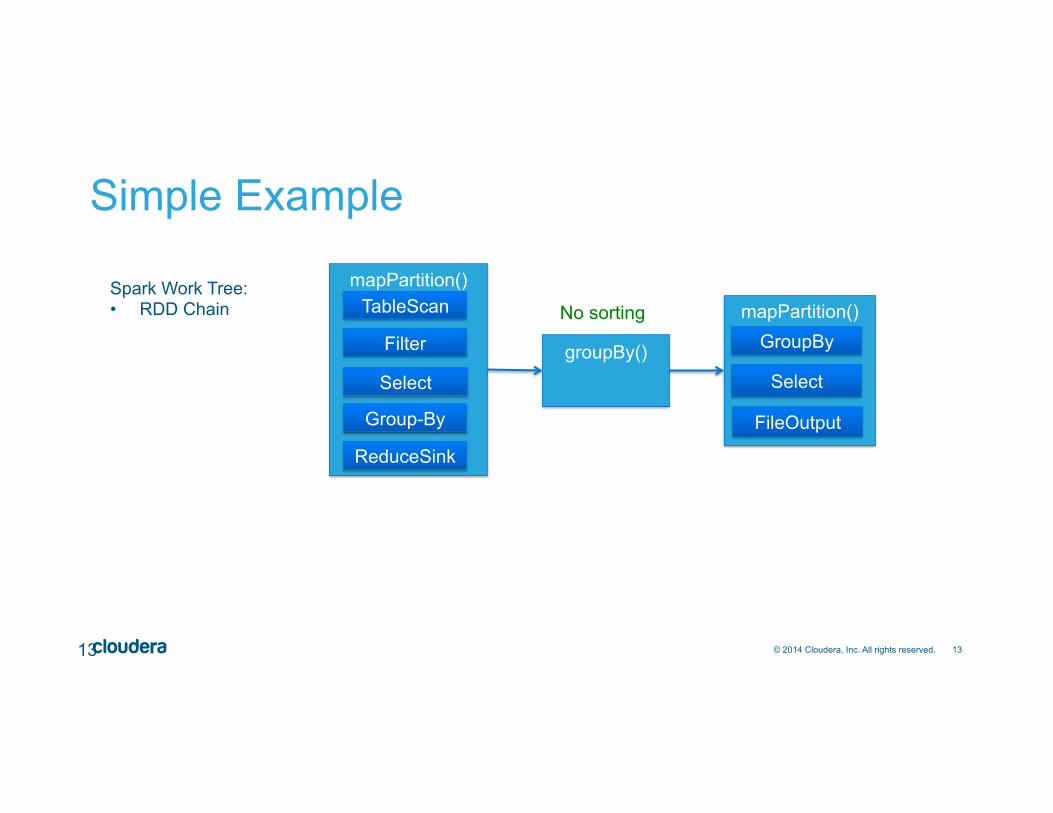
13 © 2014 Cloudera, Inc. All rights reserved.
Simple Example
13
mapPartition() GroupBy
Select
FileOutput
mapPartition() TableScan
Filter
Select
Group-By
ReduceSink
Spark Work Tree: • RDD Chain
groupBy()
No sorting

14 © 2014 Cloudera, Inc. All rights reserved.
Join Example TableScan
Filter
Select
Join
Select
Sort
Select
TableScan
Filter
Select
SELECT * FROM (SELECT key FROM src WHERE src.key < 10) src1 JOIN (SELECT key FROM src WHERE src.key < 10) src2 ON src1.key = src2.key ORDER BY src1.key;
Hive Query:
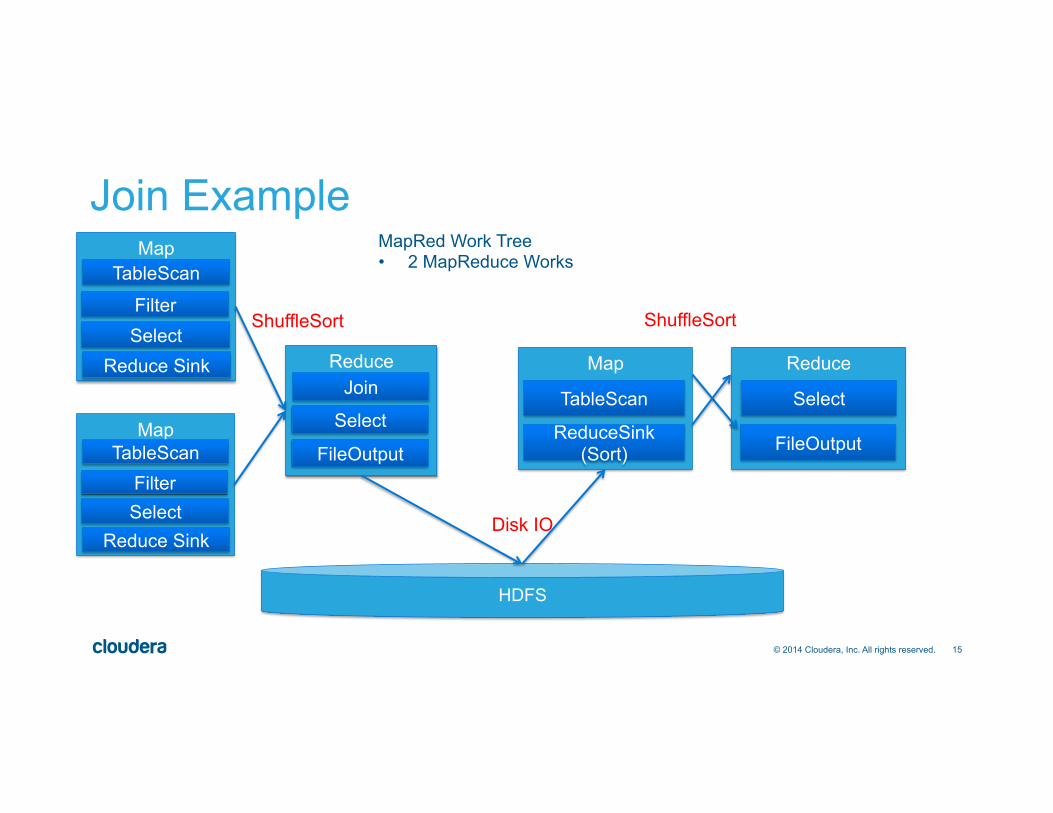
15 © 2014 Cloudera, Inc. All rights reserved.
Join Example
Map
ReduceSink (Sort)
TableScan
Map TableScan
Filter Select
Reduce Sink Reduce Join
Select
FileOutput
Reduce
FileOutput
Select Map
TableScan Filter Select
Reduce Sink
HDFS
ShuffleSort ShuffleSort
Disk IO
MapRed Work Tree • 2 MapReduce Works
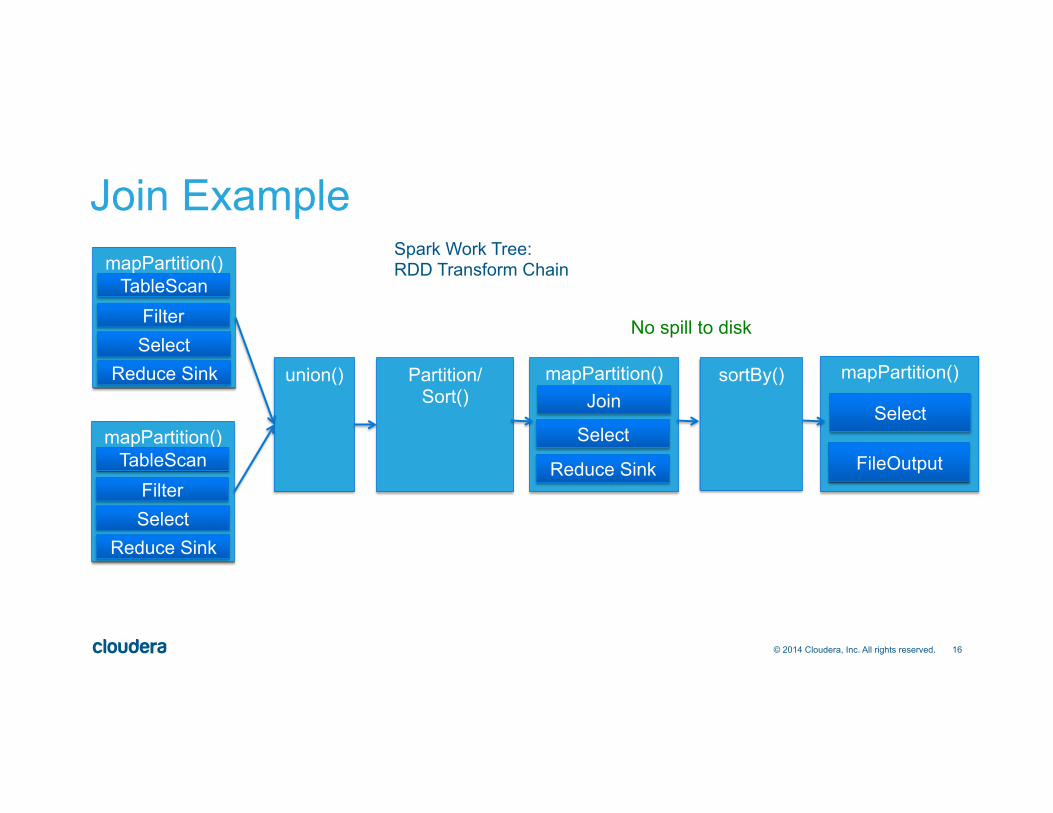
16 © 2014 Cloudera, Inc. All rights reserved.
Join Example
mapPartition() Join
Select
Reduce Sink
mapPartition()
FileOutput
Select
union() Partition/ Sort()
sortBy()
No spill to disk
mapPartition() TableScan
Filter Select
Reduce Sink
mapPartition() TableScan
Filter Select
Reduce Sink
Spark Work Tree: RDD Transform Chain

17 © 2014 Cloudera, Inc. All rights reserved.
Demo

18 © 2014 Cloudera, Inc. All rights reserved.
Improvements to Spark • Largest MR Java app ported on to Spark, can serve as reference.
• Spark Umbrella JIRA for improvements needed by Hive: SPARK-‐3145 • Implement Java version of Scala API’s (various), shade Spark Guava Library: SPARK-‐2848 • Monitoring API’s (SPARK-‐2636, various) • Shuffle-‐Sort Transform: SPARK-‐2978
• Spark had group(), sort(), but not par::on+sort like MR-‐style shuffle-‐sort. • Elas:c scaling of Spark applica:on: SPARK-‐3174

19 © 2014 Cloudera, Inc. All rights reserved.
Community • Thanks to contributors from many organiza:ons:
• Follow our progress on HIVE-‐7292 • Thank you!

Thank you.