tools for sound, speech, and multi- modal interaction johnny lee 05-830 advanced ui software
Post on 22-Dec-2015
219 views
TRANSCRIPT

Tools for Sound, Speech, and Multi-modal Interaction
Johnny Lee05-830 Advanced UI Software

Sound

Sound
• Authoring Tools– Recording, Playback– SFX libraries– Editing,Mixing– MIDI
• Developer Tools– Software APIs– FFT libraries

Recording Sound
Most laptops have built-in mono microphones
(Schoeps)

Recording Sound

Recording Sound

Playing SoundMost laptops have built in speakers

Multichannel Audio
• ProTools by Digidesign – up to 64 channels of 24-bit, 48Khz audio I/O

Multichannel Audio


Sound Libraries
• SoundIdeas (http://www.sound-
ideas.com/)– General 6000– Hanna Barbara (
http://gs304.sp.cs.cmu.edu/sfx/)
• Lots of other smaller suppliers of stock sound libraries

Editing/Mixing Sounds• LogicAudio, SoundForge,
Peak, SoundEdit16, many others.
• Edits sound kind of like a text-editor.
• Sophisitcated DSP (some realtime)
• Synchronization with video and MIDI support

MIDI• “Musical Instrument Digital Interface”• Hardware communication layer
– 5-pin din, uni-directional with pass-thru
• Software protocol layer – MIDI Commands are 2-3 bytes– Note specification– Device configuration (128 controllers)– Device Control/Synchronization

MIDI• Lots of general purpose fields• Simple electronics (2 resistors and
PIC processor)• Semi-popular option for simple
control/robotics applications.

MOD files
• File size can be tiny if using a MIDI synthesizer is used at playback time.
• Playback quality depends on the quality of the synthesizer
• MOD files (module format) combine MIDI data with WAV samples to produce high quality consistent playback in a relatively small file.


Software APIs for sound

Microsoft – DirectX 9.0
• DirectX is :– DirectDraw – 2D drawing– Direct3D – 3D drawing– DirectInput – input/haptic devices– DirectPlay – network gaming– DirectShow – video streams– DirectSound – wave audio I/O– DirectMusic – soundtrack management and
MIDI– DirectSetup – DirectX installation routines

DirectSound
• WAV capture• Multi-channel sound playback• Full duplex• 3D specification of sound sources.• Some real-time DSP: Chorus,
Compression, Flange, Distortion, Echo, Reverb

DirectMusic
• Coordinates several sound files (MIDI, wav, etc.) into “soundtracks”.
• Sequencing (timelines, cueing, and synchronization).
• Supports dynamic composition, variation, and transitioning between songs/parts.
• Dynamic content authored in DirectMusic Producer

DirectMusic• Compositions can be made with DLS
(downloadable sound) files – a cross-platform “smart” audio file format designed for dynamic loading in interactive applications.
• DLS = MIDI + WAV for interactive apps

MacOS X – Core Audio

MacOS X – Core Audio• Sound Manager – routines for resource
management and play/recording sound• AudioToolbox – sophisitcated DSP architecture,
sequencing/composition• MIDI Services – device abstraction, control, and
patching• Audio HAL – medium level I/O access (real-time,
low-latency, multi-channel, floating point is standard access)
• IOKit – low level device access• Drivers, Hardware - blarg• Full Java API provided

Java
• Basic data structures and routines for loading, playing, and stopping sounds.– java.applet.AudioClip– javax.sound.midi– javax.sound.midi.spi – javax.sound.sampled – javax.sound.sampled.spi
• I/O device access is somewhat limited.• I’ve been told that synchronization is a
problem in Java.

Voice as Sound
• “Voice as sound: using non-verbal voice input for interactive control.” Takeo Igarashi, John F. Hughes: UIST 2001: 155-156”
• STFT, FFT analysis• Extension to SUITEKeys

Fourier Transform(FT)
• Simple “properties” about a sound can be gotten by looking at the data file: duration, volume
• More interesting analysis requires some DSP – mainly Fourier Transform.
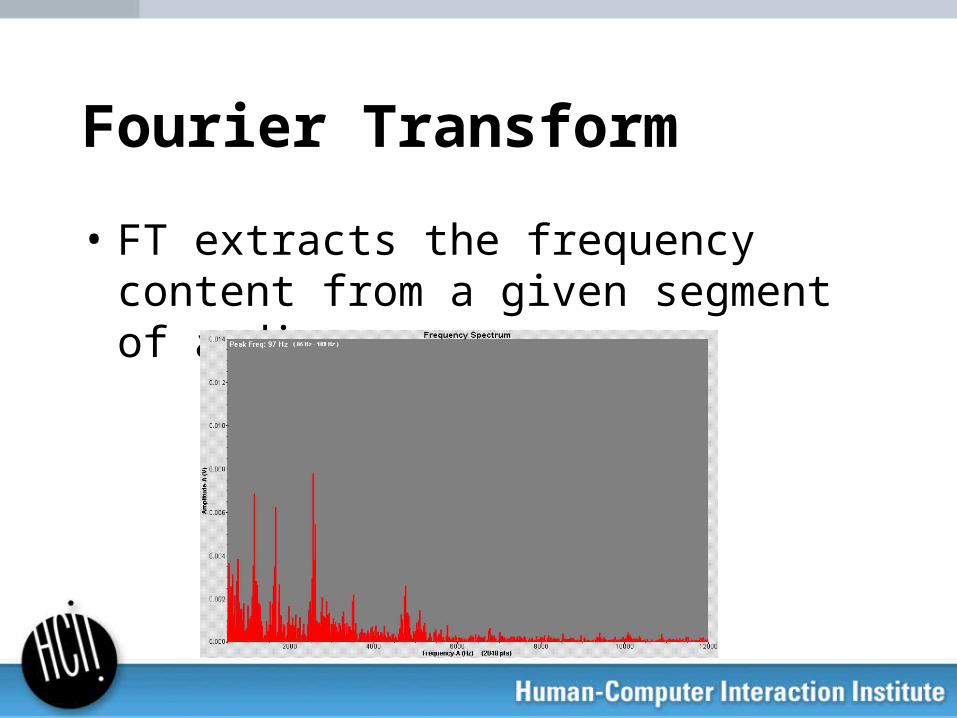
Fourier Transform
• FT extracts the frequency content from a given segment of audio.

Fourier Transform

Fast Fourier Transform(FFT)• FFT is a fast computational
algorithm for doing discrete Fourier transform (DFT).
• Implementations available in most languages.
• Good reference source: Numerical Recipes in C++

Speech (spech)

Speech SynthesisThree categories of speech synthesizers:• Articulatory synth - uses physical model of the
physiology of speech production and physics of sound generation in the vocal apparatus
• Formant synth - acoustic-phonetic approach to synthesis. Applies hundreds of “filters” loosely associated to the movement of articulators using rules.
• Concatenative synth - segmental database that reflects the major phonological features of a language. Creates smooth transitions and basic processing to match prosodic patterns
(http://cslu.cse.ogi.edu/HLTsurvey/ch5node4.html)

ATT Natural Voices
• US English, UK English, French, Spanish, German, Korean
• Can build a new voice font from an existing person
• Examples:– Male Voice– Custom UK English– Voice Font – French

Phoenix Semantic Frame Parser
• Center for Spoken Language Research, University of Colorado, Boulder
• http://communicator.colorado.edu/phoenix/license.html
• System for processing and parsing natural language

Phoenix

Phoenix
Details and Syntax for creating frames and networks:
http://communicator.colorado.edu/phoenix/Phoenix_Manual.pdf

Universal Speech Interfaces
• “In essence, we attempt to do for speech what Palm’s Graffiti™ has done for mobile text entry. “– http://www-2.cs.cmu.edu/~usi/USI-manifesto.htm
• “Speech is an ambient medium.”• “Speech is descriptive rather than referential.”• “Speech require modest physical resources.”• “Only speech will scale as digital technology
progresses.”• 3 Speech interaction techniques: Natural Language (NLI,
NLP), Dialog Trees, Command and Control
Universal speech interfaces> Ronald Rosenfeld , Dan Olsen , Alex Rudnicky> Interactions October 2001> Volume 8 Issue 6


Universal Speech Interfaces• “Look and Feel”::”Sound and Say”• Universal Metaphors – familiar ways of
doing things across applications.
• Universal User Primitives – standard dialog interaction techniques, detection, recovering from error, asking for help, navigation, etc.
• Universal Machine Primitives – standardize machine responses and meanings to increase user understanding.

Java Speech
• JSAPI – Java Speech API– Speech Generation
• Structure Analysis – Java Synthesis Markup Language (JSML)• Text Pre-Processing – abbreviation, acronyms, “1998”• Text-to-Phoneme Conversion• Prosody Analysis• Waveform Production
– Speech Recognition• Grammar Design - Java Speech Grammar Format (JSGF)• Signal Processing• Phoneme Recognition• Word Recognition• Result Generation

Windows .NET Speech SDK • Basically the .NET-ified SAPI 5.1 (Speech
API)• Continuous Speech Recognition (US
English, Japanese, and Simplified Chinese)• Concatenative Speech Synthesis (US
English and Simplified Chinese)• Interface is broken into two components:
– Application Programming Interface (API)– Device Driver Interface(DDI)

Windows .NET Speech SDK • Speech Synthesis API
– ISpVoice::Speak(“my text”, voice);
• Speech Synthesis DDI– Prases text into an XML doc– Calls the TTSEngine – Manages sound and threading details

Windows .NET Speech SDK • Speech Recognition API
– Define context– Define grammar– Request type (dictation or
command/control)– Event is fired when recognized
• Speech Recognition DDI– Interfacing and configuring the SREngine– Manages sound and threading details.

Windows .NET Speech SDK • Speech Application Language Tags
(SALT) – extension to HTML for speech integration in to webpages
• Speech Recognition Grammar Specification (SRGS) support for field parsing
• Telephony Controls – interfaces with telephone technology to develop voice-only apps.

MacOS X Speech • Barely changed since 1996, MacInTalk 3• US English only• Full Java API• Speech Synthesis Manager (PlainTalk)
– algorithmic voice generation
• Speech Recognition Manager– OS wide push-to-talk Command/Control– Customizable vocabulary w/scripting– Uses “Language Model” = grammar– No dictation support

Dragon Naturally Speaking• Commercial Recognition software
– Dictation– Command and control
• API available for developers for application integration
• http://www.scansoft.com/naturallyspeaking/

Sphinx• Open source speech recognizer from CMU (
http://fife.speech.cs.cmu.edu/sphinx/)• Auto-builds language model/grammer&vocabulary from example
sentences
• CMU-Cambridge Statistical Language Modeling Toolkit – semi-machine learning algorithms for digesting a large example corpus into a usable model
• Uses CMU Pronouncing Dictionary• SphinxTrain - builds new acoustic models
– Audio recording, transcript, pronunciation dictionary/vocabulary, phoneme list

SUITEKeys
• Manaris,B., McCauley,R., MacGyvers,V., An Intelligent Interface for Keyboard and Mouse Control--Providing Full Access to PC Functionality via Speech, Proceedings of 14th International Florida AI Research Symposium (www.cs.cofc.edu/~manaris/)
• Developed for individuals with motor disabilities.• Interface layer that generates keyboard and mouse
events for the OS– Recognizes keyboard strokes/operations: backspace,
function twleve, control-alt-delete, page down, press…. release
– Recognizes mouse buttons and movement: left-click, move down…. Stop, 2 units above clock, move to 5-18

Suede• Wizard of OZ tool for prototyping speech
interfaces• Allows the developer to quicky generate a
state machine representing the possible paths through a speech interface and stores recorded system responses.
• Operator simulates a functional system during evaluation by stepping through the state machine.
• Runtime transcripts are recorded for later analysis.
Scott R. Klemmer , Anoop K. Sinha , Jack Chen , James A. Landay , Nadeem> Aboobaker , Annie Wang> Proceedings of the 13th annual ACM symposium on User interface software and> technology November 2000


Mulitmodal Interaction

Multimodal Interaction
• According to Scott – “The term ‘multi-modal interface’ usually refers to ‘speech and something else’ because speech alone wasn’t good enough.”
• Though, should probably mean more than one (simultaneous?) input modality– Point, click, gesture, type, speak, write,
touch, look, bite, shake, think, sweat, etc… (lots of sensing techniques).

Multimodal Interaction
• Lots of things have used them, but no real “tools” or weren’t simultaneous.
• Cohen, P.R., Cheyer, A., Wang, M., and Baeg, S.C. An open agent architecture. AAAI 94 Spring Symposium Series on Software AgentsAAAI, (Menlo Park, CA, 1994); reprinted in Readings in Agents. MorganKaufmann, 1997, 197204.
• Brad Myers, Robert Malkin, Michael Bett, Alex Waibel, BenBostwick, Robert C. Miller, Jie Yang, Matthias Denecke, Edgar Seemann,Jie Zhu, Choon Hong Peck, Dave Kong, Jeffrey Nichols, BillScherlis. "Flexi-modal and Multi-Machine User Interfaces",<i>IEEE Fourth International Conference on Multimodal Interfaces</i>,Pittsburgh, PA. October 14-16, 2002. pp. 343-348.

Multimodal Interfaces• A common concept is “mode-ing” or
“modifying” interaction.– Gives extra context for recognizers (e.g. point and
speak)– Multiplies functionality of an interaction (e.g tool
stones, left/right/no click)Rekimoto, J., Sciammarella, E. (2000) “ToolStone: effective use of physical manipulation vocabularies of input devices”. Proceedings of the ACM Symposium on User Interface Software and Technology, pp. 109-117, November 2000
• Also, a need for an input interpretation layer for widgets that can be specified in multiple ways.