tooling and system support for authoring multi-device applications
TRANSCRIPT

The Journal of Systems and Software 69 (2004) 227–242
www.elsevier.com/locate/jss
Tooling and system support for authoring multi-device applications
Guruduth Banavar, Lawrence D. Bergman *, Yves Gaeremynck,Danny Soroker, Jeremy Sussman
IBM T.J. Watson Research Center, 19 Skyline Dr., Hawthorne, NY 10532, USA
Received 23 December 2002; accepted 28 December 2002
Abstract
This paper presents a development model, tooling environment, and system support for building and deploying applications
targeted to run on multiple heterogeneous end-user devices. Our approach is based on a device-independent application model and
consists of three elements: (1) an automated process of specialization, by which device-specific versions of the application are
generated, (2) support for hand-customization of generated applications, a process we call tweaking, both within our workbench and
using external editors, and (3) a designer-in-the-loop process of generalization, by which a generic model is inferred from concrete
interface artifacts such as HTML pages. We argue that this approach is cost-effective and results in usable applications that run on a
variety of devices.
� 2003 Elsevier Inc. All rights reserved.
Keywords: Model-based user interface design; Multi-device applications; Pervasive application design; Single-authoring; Device-independence
1. Introduction
Today’s world of rapidly proliferating end-user
computing devices, particularly mobile devices such as
mobile phones and hand-held computers, poses new
challenges for the application designer. No longer can
a designer custom-build an application for a single
‘‘old-style’’ device (i.e., PC)––carefully tuning the userinteraction for a large-screen desktop or HTML web-
browser. In developing pervasive applications intended
to run across a range of devices, the designer must be
concerned with wide variation in a number of factors
including screen size, interface objects such as hard-
buttons, and computing resources including connectiv-
ity.
Multiple specification, developing one specificationper platform, is today’s commonly employed approach
to pervasive application development. The application
interface and flow structure is simply rewritten for each
device, for example, using Java Server Pages. 1 A second
approach is to transform a declarative representation of
*Corresponding author.
E-mail address: [email protected] (L.D. Bergman).1 http://java.sun.com/products/jsp/.
0164-1212/$ - see front matter � 2003 Elsevier Inc. All rights reserved.
doi:10.1016/S0164-1212(03)00053-0
either data or interaction (e.g., XML 2) into concrete
presentations such as HTML, using per-device and per-
application transformation rules (e.g., XSLT 3) specified
by the application designer. Both approaches require
large investments in development and management of a
significant number of artifacts. An alternative approach
is model-based UI design, in which a single device-
independent specification can be used to automaticallygenerate interfaces and navigation for any device. Since
the designer deals with a single representation of the
application, this approach is referred to as single-
authoring. Although automatically generated interfaces
may produce good results for selected devices, they
typically do not have the visual appeal and usability of
handcrafted interfaces. Additionally, model-based ap-
proaches require learning new approaches to design, andnew tool sets.
Multiple specification and model-based UI design
represent end-points on a continuum, from manual
customization for each device type to a single high-level
specification with fully automatic generation. In this
paper we describe an intermediate single-authoring
2 http://www.w3.org/XML/.3 http://www.w3.org/Style/XSL/.

228 G. Banavar et al. / The Journal of Systems and Software 69 (2004) 227–242
strategy that combines automated generation of appli-
cation interfaces from a high-level semantic description
with an override facility that allows application design-
ers to tailor the interface to specific devices. This strat-
egy represents a balance between the desire to reduce
and manage complexity by dealing with a single speci-fication, and the commonly recognized fact that auto-
mated systems rarely produce perfect interfaces. We
seek a hybrid approach that minimizes development
effort while giving the designer as much control over the
structure and appearance of the final application as
desired. Another important requirement for our work is
to permit application designers to use existing and well-
understood methods and tools. Our objective is toprovide as much support as possible for existing prac-
tices, minimizing the requirement to learn new tools,
models, and techniques.
The applications targeted by our Platform Indepen-
dent Model for Applications (PIMA) system are best
described as forms-based applications. In such applica-
tions, control flow can be specified as a state diagram
with transitions between states, where transitions typi-cally correspond to user interface events, such as selec-
tions or button clicks. Each state of such an application
can be visually represented as a collection of interaction
elements (interactors), which may be sensitive to user
input (e.g., buttons, input fields and selection lists), or
insensitive (e.g., output fields and images). Thus, a web
shopping or banking application would be in the PIMA
domain, whereas a highly graphical and interactive gamewould not.
The PIMA methodology attempts to capture and re-
use the common aspects of an application across multiple
pervasive devices. Thus, the scope and relevance of the
work described here applies to cases where there is sig-
nificant commonality between devices in control flow
and presentation. In cases where the developer’s inten-
tion is to have a radically different user experience ondifferent devices, a possible use of PIMA is to define
‘‘application clusters’’ for device families (e.g., textual
phones, graphical phones, PDA’s, and so on), and to
treat each such cluster as a separate PIMA project. In
such a design, it might be possible to reuse much of the
application logic between different clusters. Studying and
facilitating such reuse is beyond the scope of this paper.
In this paper, we propose a development methodol-ogy, a tooling environment, and system support that
meet the above requirements. We begin by presenting an
overview of our approach, followed by more detailed
descriptions of each component of our solution. We
describe our abstract application model and the tooling
needed for creating it, including the specification of
meta-information that assists in creating device-specific
versions. This is followed by a description of our appli-cation adaptation technique, called specialization, and
the associated tooling. We then focus on support for
handcrafting the generated interfaces for individual
platforms, a process we call tweaking. In addition to de-
scribing tooling and infrastructure to support tweaking,
we discuss issues associated with maintaining a set of
associated presentations, both automatically generated
andmanually tweaked, as an application evolves throughiterative development. We then discuss an alternative
technique for creating our abstract application model, an
approach we call generalization. Generalization allows
designers to create generic applications using existing
tools, minimizing the need to learn a new methodology.
Finally, we discuss related work and summarize.
2. A semi-automated approach
Our architecture, called PIMA, focuses on the design
of an application’s user interface, including accompa-
nying interface logic such as navigation, event handling,
data validation, and error handling. We assume that
application logic is encapsulated as a set of external
services (EJB’s or CORBA objects, for example) that areinvoked from a PIMA application, as is a common ar-
chitecture for web-based applications. The services may
reside on the presentation device or may be accessed via
a network; issues of service access and location are be-
yond the scope of this paper.
Fig. 1 gives a high-level overview of our application
design process. The designer of a PIMA application
creates a device-independent generic application model.A generic application model consists of dialogs, inter-
actors, dialog transitions (navigation), and event-han-
dlers, as described in the next section. The generic
application model may also contain semantic meta-
information that guides the specialization process. Ex-
amples of meta-information include directives for
keeping elements together, for laying out elements in
particular ways on graphical devices, and for producingparticular kinds of navigation among generated pages.
The generic model may be created by hand, using
tools provided within the PIMA designer’s workbench,
or may be extracted from a previously existing interface
through generalization. Generalization is the process of
inferring portions of a generic application model from a
specific instance of an application interface (e.g., a set of
HTML pages). Generalization is typically an iterativeand interactive process - the system creates a ‘‘best
guess’’ model, which the designer iteratively adjusts.
Specialization is the automated process of converting
the generic application model into multiple device-spe-
cific representations (called specialized application mod-
els). A specialized application model consists of concrete
pages, page transitions, and additional information
(such as layout) about the interactors in the generic ap-plication model. Our specialization algorithm is com-
prised of three processes: page generation, the process of

Fig. 1. PIMA application development architecture.
4 Previously we used the term ‘‘task’’ instead of dialog. The interface
screen shots shown reflect that disparity.
G. Banavar et al. / The Journal of Systems and Software 69 (2004) 227–242 229
assigning interactors to pages; navigation generation, theprocess of creating interface widgets to permit navigation
between the generated pages; and layout generation, the
process of structuring the presentation of interactors for
concrete devices. A specialized application model can
either be translated into a renderable application (e.g., a
set of Java Server Pages), or it can be interpreted directly
by a PIMA runtime (e.g., a servlet).
The device-specific specialized application modelcreated by the specialization algorithm is typically quite
usable, but may not be completely visually satisfying in
some cases. The specialized model can be hand-tailored
through tweaking. This can involve adding additional
material such as logos, images, or text; altering the
appearance of interface elements; rearranging elements;
or removing elements. Tweaking can be performed on
the specialized application model internally within thePIMA development environment, or directly on the
renderable interface using an external device-specific
editor. The infrastructure and implications for applica-
tion evolution are different for the two approaches, as
will be discussed in a later section.
The approach described above can be characterized
as design-time specialization. Design-time specialization
allows the developer to perform tweaking at design-timeto improve the usability and appearance of applications.
After an application has been specialized at design-time,
the device-specific applications can be deployed to the
runtime system. Runtime specialization, specializing the
generic application at application invocation time, is an
alternative to specializing at design-time. Runtime spe-
cialization is beneficial in two important cases: (1) to
support new target devices that were not known at de-sign-time, and (2) to support specialization of dynamic
parts of the application. To support these scenarios, our
system supports the deployment of the generic applica-
tion directly to the runtime system. We support four
different runtime architectures for executing specialized
applications, depending on whether the specialized ap-
plication is interpreted or translated into a renderableform, and whether the target device has limited capa-
bilities (thin-client) or has richer capabilities (fat-client).
3. Application model
In this section we provide a brief overview of our
device-independent generic application model. A genericapplication model is a device-independent specification.
It is made up of a collection of dialogs 4 and the navi-
gation among the dialogs. Conceptually, a dialog rep-
resents a unit of end-user work, such as registering for a
subscription service, placing an online order, or brows-
ing a catalog. Navigation defines how a user proceeds
through the application from one dialog to the next, for
example, browsing a catalog which leads to placing anorder or to viewing item details. Navigation is described
as a set of transitions between dialogs; each transition
may be conditional. In general, a generic application is a
graph in which the nodes are dialogs and the arcs are
navigational transitions between dialogs.
Fig. 2 shows a visual display of a generic application
model within the PIMA development environment. On
the left is a set of four dialogs that have been defined fora sample e-commerce application. The dialog that will
be first presented to the user, called the initial dialog, is
indicated by a ball in the upper left corner of the box
(i.e., the BrowseProducts dialog, at the top). Navigation,
specified using click-and-drag operations between the
dialog icons, is represented by arrows between the dia-
logs. Arrows may be unidirectional, indicating one-way
navigation, or bi-directional.A dialog includes a number of interactors, which are
elements for interaction between the user and the sys-
tem. When an application is specialized to a particular

Fig. 2. A screenshot of the PIMA user interface showing construction of a generic application model.
230 G. Banavar et al. / The Journal of Systems and Software 69 (2004) 227–242
device, an interactor may be rendered as one or more
user interface widgets. Some interactors are used by the
system for displaying information to the user (for ex-
ample, a TextOutput interactor, which might be ren-
dered in HTML as text), while other interactors allow
the user to initiate events (for example, an Activator
interactor, which might be rendered in Java as a But-
ton). At this time, the list of interactors that we supportis: Activator, SelectableList (single choice and multiple
choice), BinaryChoice, TextInput (regular and pass-
word), and TextOutput. The panel on the right-hand
side of Fig. 2 shows the interactors contained within the
BrowseOrder dialog for the sample application. This
portion of the interface allows for creation and dele-
tion of interactors within a dialog, ordering of interac-
tors by dragging, and changing interactor propertyvalues (such as label or initial value) via a pop-up
property editor.
Associated with the interactors in a dialog, or with
navigational transitions, is a set of event-handlers.
Event-handlers specify a sequence of conditional ac-
tions to be executed when user-initiated or system-ini-
tiated events occur. Examples of these actions include
updating the state of the user interface and accessing
application logic and data encapsulated in external ser-
vices, such as Enterprise Java Beans or Web Services.
Event-handlers are expressed in a scripting language,
which may be specified using any scripting editor. Ourcurrent system uses a special-purpose scripting lan-
guage. We are in the process of converting to using a
Java as replacement for the scripting language in the
next-generation of our toolset.
The generic application model also includes meta-
information in the form of specialization directives,
which are assertions on sets of interactors. Directives are
specified in this generic application model view, shownin Fig. 2. The current set of directives and the tooling
interface for specifying them are described in the next
section, as are other aspects of the specialization model
and process.

G. Banavar et al. / The Journal of Systems and Software 69 (2004) 227–242 231
4. Specialization
Specialization is the automated process of converting
the generic application model into multiple device-spe-
cific representations, called specialized application
models. In this section, we describe the specializationprocess in more detail. Note that the goal of spe-
cialization is not to create an aesthetically beautiful
device-specific interface. Rather, the goal is to create a
device-specific user interface that is usable, and that can
allow the designer to more easily create an aesthetic user
interface via tweaking.
A specialized application model consists of a set of
pages, each containing a set of specialized interactors.Each page corresponds to a single (possibly scrolling)
screen on a graphical output device. Specialized inter-
actors point to the interactors in the generic application
model (using XPath 5 expressions), and differ from them
via a property override vector, described in the section
on tweaking below.
In this section will describe the directives used to
guide the specialization process, and then give a briefoverview of the specialization algorithms. We then
present a small set of example outputs from the spe-
cialization engine, showing a set of automatically-gen-
erated representations on different target platforms,
produced from a single generic application model.
4.1. Directives
Directives provide the designer with a means of ex-
erting control over the specialized application models
before the tweaking process. That is, rather than
tweaking the individual specialized application models
one at a time, the designer can specify hints to the spe-
cialization process about the desired layout of device-
specific applications.
The designer is required to specify the orderingamong interactors within a dialog. This information is
used to split a dialog into multiple pages. In addition, a
designer can optionally specify three types of directives:
(1) Grouping directives: specify that interactors are se-
mantically related, and should be kept together if
possible. For example, if a page is split into a set
of sub-pages, the split should not occur in the mid-dle of a group, unless the group cannot fit into a
page by itself. Groups can be nested, in which case
the largest group is kept on a page if possible.
(2) Single-column directives: specify that a set of interac-
tors should be placed one per line. This is a common
layout pattern for the types of devices targeted in
this work. For example, in a simple entry form, it
5 http://www.w3.org/TR/xpath.
is quite common for each line to contain only a sin-
gle captioned input field. The single-column direc-
tive provides for this type of layout.
(3) Same width/height directives: specify that a set of in-
teractors should have a common width or height, re-
spectively (if supported by the device). This is usedto create visually consistent user interfaces. For ex-
ample, the designer may want all entry fields within
a form to be of the same width.
Fig. 3 shows the portion of the interface that is used
to create directives. It is a close up of the right-hand side
of Fig. 2. The buttons along the left-hand side of the
panel are used to create directives. All currently imple-mented directives apply to sets of interactors. When a
set of interactors is selected in the right-hand side of the
panel, the appropriate buttons are enabled. Once di-
rectives have been created, they are graphically super-
imposed on the interactors shown on the right-hand
side. In the example shown, there is a group (represented
by the inner-most shaded box around the interactors), a
single-column directive (represented by the black barson the sides of the group), and a same width constraint
(represented by two-headed numbered arrows inside the
interactors).
The set of directives described here is by no means
complete (see (Badros et al., 1999) for a more complete
example). This set does not come close to supporting the
degree of control possible with a UI toolkit such as
AWT or Motif. This is by intent. Our goal here is pro-vide an easy-to-use, high-level set of directives that can
be used to specify interface characteristics to be applied
across a wide range of possible devices. The specializa-
tion engine uses these hints to produce a usable inter-
face for any device, with provisions via tweaking for a
Fig. 3. A screenshot of the PIMA user interface, zoomed in on the
section for specifying directives.

232 G. Banavar et al. / The Journal of Systems and Software 69 (2004) 227–242
designer to improve the default interface for particular
devices or sets of devices.
Currently, directives apply to all devices. A more
powerful and flexible approach is to use the notion of a
device space in determining which directives are to be
applied when specializing a generic application for aparticular device. A device space is a characterization of
a class of devices. The device space consists of a set of
permissible attribute values for a device in that class––
for example, screens with a width between 480 and 640
pixels. Specialization directives are stored in a map that
is keyed by a device space. When the application is to be
adapted to a device, the device description is checked
against each candidate device space and if the device isin that space (i.e., matches all attributes in the space),
then any associated directives are used during special-
ization. Our underlying framework implements device
spaces, although our interface does not yet expose them;
the next-generation interface currently under develop-
ment will provide for device space-based directives.
4.2. Specialization algorithms
Each time a directive is created, the specialization
engine is invoked to reflect those changes in the spe-
cialized application models. For clarity, we outline the
algorithm used to create the specialized application
models.
Application specialization consists of three main al-
gorithms, described here at a high-level:
(1) Layout generation: This algorithm takes as input the
size constraints of a screen and a set of interactors.
The screen constraints may be two-dimensional
(e.g., a phone screen that is 20 columns by 4 lines)
or one-dimensional (e.g., a browser screen that is
80 characters but can have unlimited height). The al-
gorithm translates the interactors into toolkit-spe-cific widgets, and also returns the positioning of
the interactors on a single page, or an indication that
the set of interactors cannot fit on a page. Interactor
translation is currently implemented via toolkit def-
initions. A toolkit definition includes a set of possi-
ble translation-definitions for each interactor type.
A translation-definition can translate an interactor
into a single toolkit widget, or a set of widgets.One such translation-definition is declared the de-
fault. The user can override the default translation-
definition as part of the tweaking process described
below. Our current implementation uses a ‘‘flow lay-
out’’ policy for all devices, but could use other lay-
out policies as well. The specialization directives
that affect this algorithm are: same width, same
height and single column.(2) Page generation: This algorithm allocates each dia-
log to one or more pages, depending upon the
amount of real estate needed by the interactors in
that dialog. The algorithm repeatedly calls the lay-
out algorithm as a subroutine to determine the num-
ber of interactors that can fit on each page. The
specialization directive that affects this algorithm is
the grouping directive, which specifies that a set ofinteractors should be kept on a single page if possi-
ble.
(3) Navigation generation: This algorithm takes a set of
pages generated by the page generation algorithm
and produces the navigation among them. If two di-
alogs correspond to single pages and the naviga-
tional transition between the dialogs is explicitly
specified in the application, then this algorithm needonly create a means for the user to navigate that
transition (i.e., a navigational interactor such as a
‘‘next’’ button). The more interesting case is when
a dialog is broken into multiple pages. In this case,
one of any number of policies can be applied––fully
connected navigation (e.g., tabbed windows), linear
navigation (e.g., forward and back buttons), etc.
Our current implementation uses linear navigationas a default policy for split pages.
Fig. 4 shows a portion of an automatically generated
online ordering application rendered on three different
platforms. Each of these interfaces was produced via
specialization from a single generic application model,
specified using the PIMA workbench. On the left is an
HTML rendering. In the middle is a Java version, ren-dered using the PIMA fat-client runtime. On the right
are shown three separate screens that represent the same
portion of the application rendered on a WAP phone
(WML). Although the automatically generated layouts
are not elegant, they are certainly usable. Through
tweaking, described in the next section, any or all of
these interfaces can be beautified.
5. Tweaking
Tweaking is the process of handcrafting the auto-
matically generated device-specific representation for
individual platforms. Fig. 5 shows an example of
tweaking. On the left we have the automatically gener-
ated HTML interface. On the right we have a version ofthe same interface, after the page has been externally
tweaked using an HTML editor. Note that the back-
ground has been changed, an image added, font styles
changed, and widget sizes and positions (e.g., centering)
specified.
We provide two different mechanisms for tweaking
an interface––either internally within the PIMA de-
signer’s workbench, or externally using a native editor.We will discuss each of these in turn, describing the in-
terface provided to the designer, and the internal

Fig. 4. Portion of an automatically generated application user interface rendered in HTML, Java, and WML.
Fig. 5. Automatically generated and tweaked versions of an HTML page.
Fig. 6. Greeked emulation views within the workbench: (a) hand-held,
(b) mobile phone.
G. Banavar et al. / The Journal of Systems and Software 69 (2004) 227–242 233
mechanisms for managing information about the
tweaks.
Internal tweaking is performed directly within the
workbench. The designer is presented with views of the
application on specific devices, as well as a set of con-
trols for altering the representation. We generate views
either by invoking emulators, or by greeking the inter-
face. A greeked view (Bergman et al., 2001) is a sim-plified, stylized representation of the interface. This
allows the designer to tweak the application for devices
for which no emulator is available, an important facility
in light of the rapid development of new devices and the
difficulty of managing multiple third-party emulators.
Fig. 6 shows greeked views for two different devices (a
hand-held, and a mobile phone). Note that widgets of all
types are uniformly represented as simple rectanglescontaining identifying text. The internal tweaking in-
terface in our development tool using a Java emulator is
shown in Fig. 7. The user can select an interactor in the
greeked view and then affect it through direct manipu-
lation (with the mouse or the menu choices) or by
opening a property editor dialog box. In the list belowwe specify how this manipulation works.
The designer tweaks the application by changing the
properties of individual interactors, or the relationships
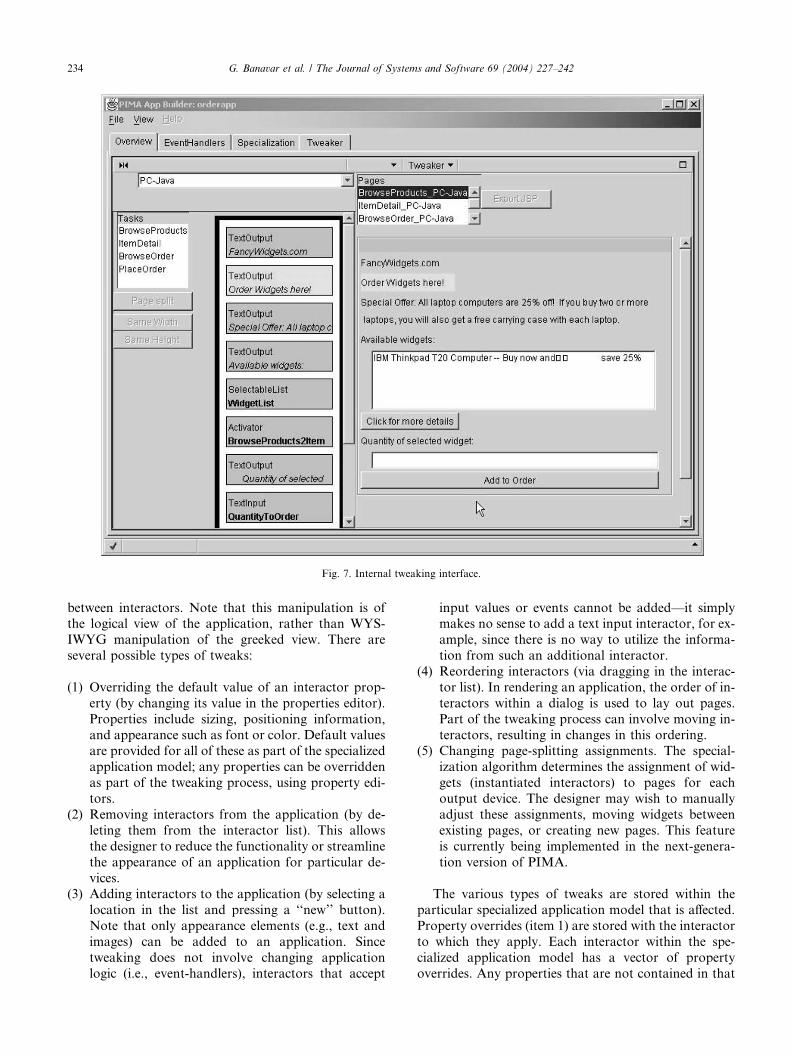
Fig. 7. Internal tweaking interface.
234 G. Banavar et al. / The Journal of Systems and Software 69 (2004) 227–242
between interactors. Note that this manipulation is ofthe logical view of the application, rather than WYS-
IWYG manipulation of the greeked view. There are
several possible types of tweaks:
(1) Overriding the default value of an interactor prop-
erty (by changing its value in the properties editor).
Properties include sizing, positioning information,
and appearance such as font or color. Default valuesare provided for all of these as part of the specialized
application model; any properties can be overridden
as part of the tweaking process, using property edi-
tors.
(2) Removing interactors from the application (by de-
leting them from the interactor list). This allows
the designer to reduce the functionality or streamline
the appearance of an application for particular de-vices.
(3) Adding interactors to the application (by selecting a
location in the list and pressing a ‘‘new’’ button).
Note that only appearance elements (e.g., text and
images) can be added to an application. Since
tweaking does not involve changing application
logic (i.e., event-handlers), interactors that accept
input values or events cannot be added––it simplymakes no sense to add a text input interactor, for ex-
ample, since there is no way to utilize the informa-
tion from such an additional interactor.
(4) Reordering interactors (via dragging in the interac-
tor list). In rendering an application, the order of in-
teractors within a dialog is used to lay out pages.
Part of the tweaking process can involve moving in-
teractors, resulting in changes in this ordering.(5) Changing page-splitting assignments. The special-
ization algorithm determines the assignment of wid-
gets (instantiated interactors) to pages for each
output device. The designer may wish to manually
adjust these assignments, moving widgets between
existing pages, or creating new pages. This feature
is currently being implemented in the next-genera-
tion version of PIMA.
The various types of tweaks are stored within the
particular specialized application model that is affected.
Property overrides (item 1) are stored with the interactor
to which they apply. Each interactor within the spe-
cialized application model has a vector of property
overrides. Any properties that are not contained in that

G. Banavar et al. / The Journal of Systems and Software 69 (2004) 227–242 235
vector retain the value specified in the generic applica-
tion model.
The other types of tweaks are easily retained by
simply adding, moving, or removing elements within the
specialized application model. The specialized applica-
tion model stores a set of pages, each containing a set ofinteractors to be rendered on the device. Pages can be
simply added and removed as needed, as can any in-
teractors that have been added, moved, or removed.
External tweaking is accomplished by having the
system create pages in the target markup language (i.e.,
the language used for rendering the final application),
and editing them via an external markup-specific editor.
These could be, for example, HTML pages. Externaltweaks are retained by storing the renderable interface
(e.g., the HTML pages). At runtime, the PIMA engine
checks to see if any given page has been translated from
the internal representation into a renderable interface. If
not, translation occurs on the fly. If it has, the stored
page, which may have been tweaked, is delivered.
External tweaking has several advantages. First, the
designer is able to employ any editor with which he or sheis comfortable. Second, it provides easy extensibility;
there is no need to integrate new emulators into the
PIMA development environment. Third, the designer
can add additional content or appearance elements to
individual pages. Background images, logos, descriptive
text, and informational links can all be used to enhance
the application without changes to the underlying ge-
neric model. Note that since there is an intermediaterenderable interface between the specialized application
model and the device, arbitrary information can be ad-
ded to the pages, including information that is not rep-
resentable within the PIMA generic application model.
6. Tweaking and evolution––ongoing work
Although managing tweaks is relatively straightfor-
ward, the picture becomes more complicated when
changes are made to the underlying generic application
model. Tweaks may no longer be applicable once the
model that created them has changed. This is known as
the software evolution or ‘‘round trip’’ problem.
The underlying difficulty is that any tweaking causes a
divergence between the expected device-specific repre-sentation corresponding to the generic application model
and the tweaked representation. If the generic applica-
tion model is changed subsequent to tweaking, conflicts
may ensue between these two representations. Our goal
is to merge changes in the generic application model and
tweaked changes, but the conflicts make this difficult.
We attack this problem by dividing tweaking infor-
mation into two types––those that affect only one in-teractor, which we call local changes; and those that
affect sets of interactors, which we call global changes.
Local changes are changes to individual interactors
that do not affect page layout. Only those property
changes that do not affect an interactor’s size or position
can be considered local changes. For local changes, we
adopt the policy that any tweaked properties are to be
retained. This is implemented by keeping track of in-teractor properties that have been tweaked. In the case
of internal tweaking, the record-keeping and property
updating is managed through the specialized application
model––easily accomplished, since widgets in the spe-
cialized application model contain pointers to the in-
teractors in the generic application model from which
they are derived. For externally tweaked pages, we store
XPath expressions that point from the interactors in thegeneric application model to Document Object Model
(DOM) elements in the generated page. This allows us
to determine which properties have been tweaked by
comparing the property values of the previous generated
page and the tweaked page. When the model changes,
we re-specialize the application and then apply these
tweaks to the relevant widgets.
Global tweaks include all other types of changes:adding, moving, or deleting interactors; property chan-
ges that affect interactor size or position; and changes to
page-splitting. Each of these tweaks potentially affects
more than the interactors touched, by affecting the lay-
out of the page. The problem in this case is due to lack
of information about the semantics of the change––there
is no basis on which to determine how updates are to be
applied. Consider, for example, adding a text outputinteractor with the contents ‘‘Welcome to our site. We
hope you find everything you need!’’ between the text
‘‘FancyWidgets.com’’ and ‘‘Browse your Order’’ for the
application page shown in Fig. 5. For the untweaked
page, shown on the left, this is no problem––the text is
simply inserted, producing the page shown in Fig. 8a.
For the tweaked page on the right of Fig. 5, the outcome
is less certain. We are likely to get the page shown in Fig.8b, which is not what the designer intended. The prob-
lem here is that the system has no way of knowing that
the image inserted during tweaking is clearly associated
with the text FancyWidgets.com, and nothing should be
inserted between them.
Resolving such ambiguities in the case of global
changes requires additional feedback from the designer.
We are currently developing update policies and a de-signer-in-the-loop interface that will allow the system to
present portions of the interface for which update ac-
tions are ambiguous to the system, requesting informa-
tion on how each such case is to be handled.
We expect that ambiguity resolution will be an iter-
ative process. First, the designer is presented with a
specialized application automatically generated by the
system––a best guess at how the tweaks and modelchanges should be merged. The designer evaluates
the output from the specialization algorithm for that

Fig. 8. Merge of model changes with page tweaks: (a) untweaked, (b) tweaked.
6 http://www.netscape.com/communicator/composer/v4.0/index.
html.
236 G. Banavar et al. / The Journal of Systems and Software 69 (2004) 227–242
platform, and either provides additional semantic in-
formation for another cycle, or tweaks the resulting
page to get what he or she wants.
The semantic information includes informationabout how tweaks are to be retained and updates in-
corporated. One possibility is for the designer to ex-
plicitly specify semantic information––in our example,
that FancyWidgets.com and the image are to be
grouped. Another possibility is to use inference to derive
a semantic rule. With notification that the text, ‘‘Wel-
come to our site!. . .’’ is out of place, and perhaps even
manual correction (by moving the text), the systemmight infer that the image added through tweaking, and
the FancyWidgets.com text are to be grouped. If more
than one likely hypothesis can be inferred, the system
could present the user with a set of choices.
Based on this additional input, the system can gen-
erate a new specialization that performs the automated
layout subject to constraints from previous tweaking
and the newly provided semantic information. Thenewly generated pages can be the starting point for
another round of iteration.
Note that the designer has complete control over how
much information is specified: there is no required ad-
ditional information. If no semantic information is
provided, the designer may need to completely re-tweak
pages each time the model is changed. As more semantic
information is provided, the system is more and morelikely to ‘‘get it right,’’ reducing the need for additional
tweaking.
It is important to recall the goal here: minimizing
development time and effort. Since tweaking is sup-
ported, the automation within a hybrid system does not
need to get the layout perfect. A system that simply
throws away all tweaks whenever there is a change to the
generic model is unacceptable, since the tweaks may
represent a large time investment. On the other hand, a
system which can integrate model changes with previous
tweaks to present an ‘‘almost right’’ interface requiringonly a bit of additional tweaking may represent a big
win over existing approaches.
7. Generalization
Our discussion so far has described the pipeline and
associated tooling for authoring pervasive applica-tions––creating a generic application model, automated
specialization of the model to individual devices, and
tweaking to customize the appearance for particular
devices. In this section we describe generalization, a
process that allows the designer to extract the generic
application model from previously authored user inter-
faces.
When employing generalization, the designer beginsby creating a device-specific user interface using familiar
application building tools, for example, creating web
pages in Netscape Composer. 6 The PIMA generaliza-
tion engine then infers a platform-independent model
for the user interface from this single design.
The goal in generalization is to abstract semantic
information from a concrete user interface so that it can
be represented in a platform-independent model. Ques-tions that naturally arise include:
• What kinds of information can be abstracted from
the concrete interface?

7 http://www.research.ibm.com/rules/.
G. Banavar et al. / The Journal of Systems and Software 69 (2004) 227–242 237
• How is the information abstracted from the concrete
interface?
• How does the system handle potential ambiguities in
the abstraction mechanism?
We will address these issues by considering a partic-ular type of application––a set of HTML pages con-
trolled by a servlet. Note that the gist of the discussion
applies to other implementations as well.
There are three types of information that can be in-
ferred from the HTML pages. First, there is the infor-
mation about the interaction elements that make up the
user interaction. Each concrete element of the HTML
may represent a single abstract element. For example, aninput field represents a piece of information that the user
must provide to the system, corresponding to our ab-
stract TextInput interaction element. On the other hand,
some concrete elements must be combined to form a
single abstract element. For example, a set of HTML
input elements of type checkbox may represent a list of
choices where the user can make more than one selec-
tion, corresponding to our abstract MultipleSelection-
List interaction element.
Secondly, the properties of interaction elements can
be inferred. The caption of an element is an example.
HTML does not contain explicit semantics for cap-
tions––the input field mentioned above may be preceded
by the text ‘‘First name:’’ which clearly is related to that
input field, but there is no binding specified in the
HTML. A simple rule such as assuming that the textnode that precedes a form element is that element’s
caption does not suffice: there are times when a caption
comes above or after a form element, and there are times
when an element does not have a caption. More complex
information, such as the geometric proximity of the form
element to text nodes, may be useful in determining the
caption. However, even given such higher-level infor-
mation, it may not be possible for the system to auto-matically disambiguate between the possible captions.
Finally, there is information in a page related to sets
of user interaction elements. For example, when a form
is contained within a table, elements that are in the same
row may be strongly related. This information may be
useful for deciding how to fragment this application for
a smaller device. Additionally, the properties or place-
ment of the elements on the page may be used to inferlayout directives such as alignment or sizing informa-
tion. In some cases, the alignment of a set of interaction
elements may be coincidental, while in others the de-
signer may have consciously decided that the elements
are to be aligned. Again, the system cannot consistently
disambiguate between these cases.
The PIMA generalization engine produces a best
guess for each decision on interactor and property as-signment (we are not currently inferring directives). In
addition, a set of alternatives for each decision is stored
to allow for designer overrides, as described below. The
generalization engine uses the CommonRules 7 system
for processing a set of page layout heuristics. Inputs to
this rule set include the DOM for the page, style sheet
information, and geometric information for each ren-
dered component. We have developed a set of handc-rafted rules expressed in a Prolog-like language, based
on DOM and geometric relationships, by observing
common patterns in a variety of commercial web pages.
Fig. 9 shows our generalization interface. The de-
signer begins by importing an HTML page, which is
displayed in the upper portion of the interface. By se-
lecting ‘‘generalize application’’ from the menu, the
generalization engine is invoked, and graphical infor-mation about the generalized application displayed in
the lower set of panels.
The left-most of the lower panels of the generaliza-
tion interface is a Java rendering of the inferred generic
application model. This rendering is produced by cre-
ating the best guess generic application model and then
running the full PIMA pipeline on it. The designer can
select individual elements in the rendered interface, andthrough use of highlighting, see the relationship between
that element and the original page. Notice that the
choice list labeled ‘‘Title:’’ is highlighted in the Java
rendering of the application, and the corresponding el-
ements in the HTML (both the choice list and the cap-
tion) are visually marked.
The right-most two lower panels permit the designer
to see alternatives to automatically selected propertyvalues. In this case, three possible captions were identi-
fied for the highlighted choice list. Although the correct
choice was automatically identified, at times this will not
be the case, and the designer is free to override the de-
fault assignment. Additionally, there are controls in the
left-lower corner to add or remove interactors, as well as
changing the relative position of interactors. This is only
a subset of the possible modeling operations; for others,the designer can switch to the generic application model
view (Fig. 2) and make required adjustments.
We evaluated the performance of our approach on a
test set of 48 publicly available web pages. We compared
hand-constructed ideal models for each page with the
automatically generated models using a standard edit
distance metric computed on the DOMs. The ideal
models contained on average 80 nodes; the largestmodel contained 173 nodes. Fig. 10 shows the results of
the evaluation. Overall, our generalization engine re-
covered the correct model from 40% of the web pages
with no error. 53% of the web pages were recovered with
less than 5% error, while 77% of the web pages con-
tained less than 10% error. As the figure shows, the
generalization engine can handle a large percentage of
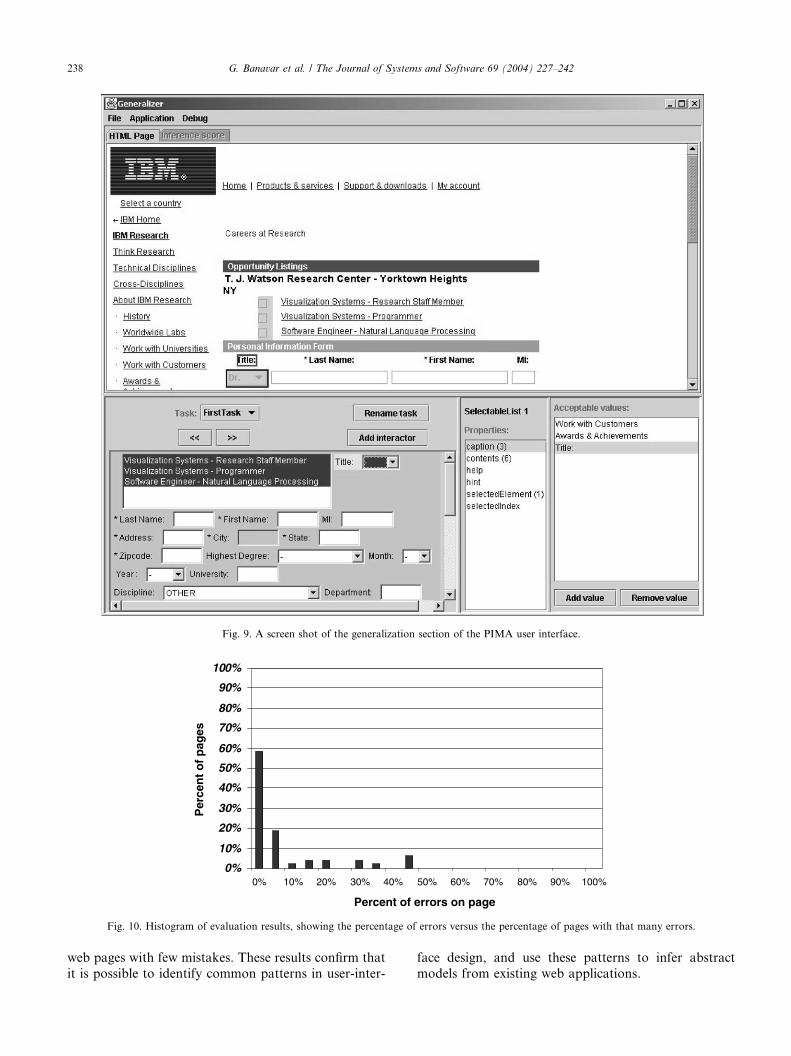
Fig. 9. A screen shot of the generalization section of the PIMA user interface.
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100%
Percent of errors on page
Per
cen
t o
f p
ages
Fig. 10. Histogram of evaluation results, showing the percentage of errors versus the percentage of pages with that many errors.
238 G. Banavar et al. / The Journal of Systems and Software 69 (2004) 227–242
web pages with few mistakes. These results confirm that
it is possible to identify common patterns in user-inter-
face design, and use these patterns to infer abstract
models from existing web applications.

G. Banavar et al. / The Journal of Systems and Software 69 (2004) 227–242 239
The previous discussion assumes post-production
processing of an HTML page––what we call ‘‘batch’’
generalization. Designer interaction occurs after the in-
ference engine has processed the full page. An alterna-
tive is for the system to interact with the designer as the
page is being constructed; what we call ‘‘over-the-shoulder’’ generalization. Although the two modes are
fairly similar, over-the-shoulder generalization would
permit an evolving dialog with the designer based on the
use of multiple examples within a single page, leading to
better choices of assignments.
8. Open issues and future work
We have a constructed a research prototype of the
system discussed thus far. There are some open issues
that our system has yet to address, however. In this
section, we discuss these issues and outline our approach
to addressing some of them.
There are some basic differences between the pre-
sentation model for web applications using web-brows-ers and the presentation model of applications that use
more conventional UI toolkits such as Java AWT.
Perhaps the most significant difference is that conven-
tional applications use a static layout of interaction el-
ements, whereas the browser model allows for a more
dynamic presentation. As an example, consider catalog-
browsing applications commonly seen on the web. The
user provides a query, and the system responds with alist of products, often displayed in a table. The size of
the web page adjusts with the size of the table, and the
user is expected to understand that the scroll bar is
used to see the entire list. There is no simple analogue to
this in the case of conventional applications. Since our
device-independent application specification bridges the
gap between these two models, it is necessary for
our specialization mechanism to support presentingsuch dynamic data within conventional applications.
Our simple solution is to use a statically sized scrolla-
ble panel to show this information. However, we believe
that there are other, perhaps better, ways to present
this information. For example, elements common to
iterated elements can be factored out, (e.g., the ‘‘sub-
mit’’ button in a list of purchasable items), and those
that are unique can be presented in a scrollable list ortable.
Our work in generalization is intended to facilitate
the import of existing web pages into our framework. As
such, it can only be useful if it handles a majority of the
web pages that exist today. In examining metaphors
commonly used in web pages, we have found that simple
HTML forms are often combined into complex user
interfaces. For example, form elements are often hier-archically organized, with checkboxes or radio buttons
used to enable or disable entire sections of a webpage.
Also, form elements are sometimes grouped together to
create a composite widget, such as combining drop
down lists for the day and month and an entry field for
the year to create a ‘‘choose date’’ element. Our current
model does not allow for such interactor composition.
We expect to introduce this idea into a later version, viaa concept that captures ‘‘phrases’’ composed of multiple
interactors.
A relatively major problem related to generalization
is whether we can abstract from dynamic pages such as
JSPs. A JSP is a combination of Java code and pre-
sentation markup language that is compiled on the
server to produce markup from dynamic data. In order
to generalize such pages into our system, we would needto understand the semantics of the Java embedded in the
page, which of course is impossible in general. The
movement of the web application community away from
arbitrary Java embedded within pages, and towards a
more structured set of dynamic tags, will facilitate the
generalization process.
As discussed in the section on our tweaking meth-
odology, the interaction between tweaking and softwareevolution is an area of ongoing work, specifically with
respect to ‘‘global tweaks’’. Global tweaks impact the
structure of an entire page. As a result, the system needs
to know the intent of the designer in order to properly
re-integrate the tweak with future changes to the generic
application. The best way to gather this information,
while maintaining usability and correctness, is an area
we will be investigating further.The issue of handling dynamic content is challenging
in the context of single-authoring, since one is not pre-
sented with the actual data at design-time. Providing the
right kind of modeling and tools for dynamic data is
part of our ongoing research.
In this paper we focus on devices with graphical in-
terfaces. It is important to note that the techniques de-
scribed here could be extended to work for voice andmulti-modal interfaces.
Finally, we are in the process of designing user studies
to validate the effectiveness of our single-authoring ap-
proach.
9. Related work
The general concept of loosening the coupling be-
tween logic and presentation is well established, thanks
to work on user interface management systems (UIMS)
(Olsen, 1986; Singh et al., 1990; Myers, 1991 and oth-
ers). The na€ııve use of this approach, however, still re-
quires that the designer create separate user interfaces
for each platform type, something we have argued is
impractical.The main alternative today for multi-device authoring
is that provided by XML and XSLT. In this approach,

8 http://www.w3c.org/MarkUp/Forms/.9 http://msdn.microsoft.com/vstudio/nextgen/technology/mobileweb-
forms.asp.10 http://www.oracle.com/mobile/collateral/index.html?OracleMo-
bile_OnlineStudio_ds.html.11 http://www.ximl.org/.12 http://www.webgain.com/products/visual_cafe.
240 G. Banavar et al. / The Journal of Systems and Software 69 (2004) 227–242
the XML abstractly represents the data to be presented,
and separate sets of XSLT rules represent the transfor-
mations needed to present that data on different devices.
In our approach, we represent not only the data, but also
the user interaction abstractly. We seek to automatically
transform this abstract description into usable device-specific presentations. Furthermore, if the output is not
satisfactory, we allow designers to specify the end-result
directly, instead of specifying the transformation rules
for getting there.
Model-based user interface systems (Sukaviriya et al.,
1993; Szekely et al., 1993) allow interfaces to be specified
by constructing a declarative model of how the interface
should behave, and then automatically generate con-crete user interfaces based on this declarative model.
The work described in this paper is a model-based UI
system whose design was driven specifically by the re-
quirements of multi-device application development. In
general, model-based systems pose a usability challenge,
since it is difficult for designers to maintain a mental
model that connects an abstract interface specification
with multiple concrete realizations of it. Puerta andEisenstein (1999) have proposed techniques to help de-
signers inspect and set the mapping of abstract interface
elements to concrete elements. Follow-on work targeted
to pervasive devices (Eisenstein et al., 2000; Eisensten
et al., 2001) enables modeling of platform, presentation
and task structure and the mappings between these
model components. The model is interpreted to auto-
matically produce a UI that is customized to the device.Developer controls are used for mapping at the abstract
model level, but not for specifying incremental modifi-
cations to target devices. The work described in this
paper aims to give the designers more control over the
targeting process, by allowing them to tweak the gen-
erated output to improve the presentation. In particular,
our goal is to provide a model that is flexible enough to
be suited for multi-device authoring, but concrete en-ough to have a straightforward correspondence to the
resulting device-specific application. This has the dual
advantage of providing a more familiar model to the
application designer, and enabling better integration of
tweaks in the abstract model.
Singh and Green (1989) have developed a model-
based approach to user-interface generation that takes
device characteristics and user preferences into account.Their Chisel system does automated selection of user-
interface elements and screen layout generation, using a
set of rules. In addition, they allow the designer to refine
the generated presentation using an interactive graphical
facility called vu. Our work extends this by providing for
multi-screen generation, including navigation, and by
allowing the use of a variety of off-the-shelf graphical
editors for doing the post-generation tweaking.Our model covers a limited domain of the possible
types of models. Using the terminology of (Puerta,
1996), we cover primarily an abstract presentation
model. In addition, we provide an explicit navigation
model, in lieu of a more general dialog model. We re-
strict ourselves to applications that do not differ radi-
cally in style or navigation between devices. Although
certain types of applications will therefore fall outsidethe coverage of our system (for example, a museum
guide program that will render as text on a cell phone,
but as an interactive map on a hand-held), we feel that a
large number of existing and future form-based appli-
cations will meet these constraints, particularly e-com-
merce and information access applications.
The Jade System (Vander Zanden and Myers, 1990)
also addresses the issue of tweaking generated output.Jade takes a textual specification of a dialog (written by
an application programmer), look-and-feel graphics and
rules files (created by a graphic designer), and generates
a graphical layout for the dialog. The system allows the
developer to modify the resulting graphical layout in
several ways. One way is to affect the look-and-feel files
(graphics or rules) directly. Another way is to use direct
manipulation and have the system infer rules or graphicsexceptions. In Jade, the results of tweaking are encap-
sulated as data that feeds directly into the specialization
process, whereas in PIMA the tweaking information is
kept at the concrete presentation level, with tweaking
applied as a separate phase following specialization. In
addition, the Jade system focuses on generating the
presentation of a single dialog from a high-level repre-
sentation, as opposed to PIMA where there is an explicitfocus on multiple devices.
There are several companies and consortia active in
designing and standardizing an abstract representation
for device-independent applications, such as XForms, 8
Mobile Web Forms, 9 MobileXML, 10 UIML (Abrams
et al., 1999) and XIML. 11 The goal of the work
presented here is not to propose yet another device-
independent language. We focus on developing meth-odologies and tools for helping designers start from one
of these languages and arriving at usable presentations
on several device platforms.
Several approaches are known for dealing with the
round trip problem of code evolution (e.g., Medvivovic
et al., 1999). The simple-minded approach of discarding
tweaked information upon re-generation is typically
unacceptable. One common approach for code builderssuch as VisualCafe 12 is to generate stylized comments
(place holders) in the generated code. As long as the

G. Banavar et al. / The Journal of Systems and Software 69 (2004) 227–242 241
designer makes ‘‘structured’’ changes (i.e., within the
‘‘allowed places’’), the tweaked code is unchanged upon
re-generation. However, if an ‘‘unstructured’’ change is
made, then it will likely be lost upon re-generation. A
more integrated approach (such as that supported by
Together ControlCenter 13) is to keep the model andgenerated code continually synchronized. In other
words, changes in the model are reflected in the gener-
ated code and vice versa. This approach is most effective
when the designer makes the changes and tweaks within
the IDE. An additional approach (Vlissides and Tang,
1991), which applies to languages that support inheri-
tance, is to have an object for each element of the model,
and a corresponding subclassed object for each elementof the presentation. Thus, changes to the model are
made to the model objects, and tweaks are made to the
corresponding presentation objects. This approach has
been formalized in the ‘‘Generation Gap’’ pattern
(Vlissides, 1998). The approach we take is based on
having the abstract level correspond fairly directly with
the concrete (device-specific) level, and to involve the
designer when the system needs assistance in reconcilingchanges in the different levels.
The goal of our generalization engine is similar to
that of the VAQUISTA system (Vanderdonckt et al.,
2001). VAQUISTA addresses the problem of allowing a
given web page to be accessed from devices with differ-
ent capabilities such as PDAs, WAP enabled phones or
desktop computers. VAQUISTAVAQUISTA provides a flexible way
of reverse-engineering a static web page into a corre-sponding XIML form, which can later be used in for-
ward-engineering. VAQUISTAVAQUISTA focuses more on
abstracting presentation information (such as the fact
that a particular text item is centered on the page), while
our generalization system focuses on extracting certain
types of semantic relationships (finding captions, for
example).
10. Summary and conclusion
This paper describes a novel approach for authoring
a single application that can be run on many different
device types. This approach includes the following in-
gredients: an abstract programming model for device-
independent applications, a generalization mechanismfor extracting the model from device-specific interfaces,
a specialization mechanism that automatically adapts
the application to a variety of target devices, and a
means for the application designer to override portions
of the automatically-generated interface for particular
platforms. We also describe a system that we have im-
13 http://www.togethersoft.com/us/products/index.html.
plemented that follows this approach, and the accom-
panying tooling employed by the designer.
The main contribution of this work is a methodology
for creating pervasive applications, using a single-au-
thoring approach based on an underlying application
model. The power of our methodology lies in theavailability of a fully automated generalization-special-
ization pipeline, but with numerous manual overrides,
giving the designer as much control over the model
formulation and device-specific renderings as desired.
On the one hand, designers who are uninterested in
learning new tools and models can generalize HTML
pages built using their favorite tools, automatically
specialize them to the required devices, and then tweakthe generated pages, once again using whatever tools
they desire. This scenario requires almost no interaction
with our toolset––the learning curve is minimal. On the
other hand, we support a much more involved usage
model; a designer can carefully construct an abstract
application model using our tools, and then perform as
little or as much tweaking of the generated interfaces as
desired, using either tools within our workbench, orexternal editors. In either case, our approach gives the
designer an automatically generated interface on any
output platform as a reasonable starting point for any
fine-tuning that might be desired (or no fine-tuning at
all).
We contend that this approach yields significant
savings in effort and complexity in developing and
maintaining applications, both through reducing thenumber of artifacts that are produced, and by providing
a uniform development methodology for a wide diver-
sity of device types.
References
Abrams, M., Phanouriou, C., Batongbacal, A., Williams, S., Shuster,
J., 1999. UIML: an appliance-independent XML user interface
language. In: Proceedings of the Eighth International World Wide
Web Conference, May 1999.
Badros, G.J., Nichols, J., Borning, A., 1999. SCWM: An Intelligent
Constraint-Enabled Window Manager AAAI 2000 Spring Sympo-
sium on Smart Graphics, October 1999. Available from <http://
w5.cs.uni-sb.de/~butz/AAAI-SSS2000/cameready/GBadros00.
pdf>.
Bergman, L.D., Kichkaylo, T., Banavar, G., Sussman, J., 2001.
Pervasive Application Development and the WYSIWYG Pitfall,
ECHI 2001, May 2001, pp. 203–217.
Eisenstein, J., Vanderdonckt, J., Puerta, A., 2000. Adapting to mobile
contexts with user-interface modeling. In: Proceedings of the 3rd
IEEE Workshop on Mobile Computing Systems and Applications
(WMCSA), December 2000, pp. 83–92.
Eisensten, J., Vanderdonckt, J., Puerta, A., 2001. Applying model-
based techniques to the development of UIs for mobile computers.
In: Proceedings of IUI ’01, Intelligent User Interfaces, Santa Fe,
New Mexico, USA, January 14–17, 2001.
Medvivovic, N., Egyed, A., Rosenblum, D.S., 1999. Round-trip
software engineering using UML: from architecture to design and
back. In: Proceedings of the 2nd Workshop on Object-Oriented

242 G. Banavar et al. / The Journal of Systems and Software 69 (2004) 227–242
Reengineering (WOOR), September 1999, pp. 1–8. Available from
<http://sunset.usc.edu/~aegyed/publications/Round-Trip_Software_
Engineering_Using_UML.pdf>.
Myers, B., 1991. Separating application code from toolkits: eliminating
the spaghetti of call-backs. In: Proceedings of the Fourth Annual
ACM SIGGRAPH Symposium on User Interface Software and
Technology, November, 1991, pp. 211–220.
Olsen, D., 1986. The menu interaction kontrol environment. ACM
Transactions on Graphics 5 (1), 318–344.
Puerta, A.R., 1996. The mecano project: comprehensive and integrated
support for model-based interface development. In: Vanderdonckt,
J. (Ed.), Computer-Aided Design of User-Interfaces, Presses
Universitaires de Namur, Namur, Belgium, pp. 19–25.
Puerta, A., Eisenstein, J., 1999. Towards a general computational
framework for model-based interface development systems model-
based interfaces. In: Proceedings of the 1999 International
Conference on Intelligent User Interfaces 1999, pp. 171–178.
Available from <http://www.acm.org/pubs/articles/proceedings/
uist/291080/p171-puerta/p171-puerta.pdf>.
Singh, G., Green, M., 1989. Chisel: a system for creating highly
interactive screen layouts. In: Proceedings of the Second annual
ACM SIGGRAPH Symposium on User Interface Software and
Technology, 1989, pp. 86–94.
Singh, G., Kok, C., Ngan, T., 1990. Druid: a system for demonstra-
tional rapid user interface development. In: Proceedings of the
Third Annual ACM SIGGRAPH Symposium on User Interface
Software and Technology, October 1990, pp. 167–177.
Sukaviriya, P.N., Foley, J.D., Griffith, T., 1993. A second generation
user interface design environment: the model and the runtime
architecture. In: Proceedings of ACM INTERCHI’93 Conference
on Human Factors in Computing Systems 1993, pp. 375–382.
Available from <http://www.acm.org/pubs/articles/proceedings/chi/
169059/p375-sukaviriya/p375-sukaviriya.pdf>.
Szekely, P., Luo, P., Neches, R., 1993. Beyond interface builders:
model-based interface tools. In: Proceedings of ACM INTER-
CHI’93 Conference on Human Factors in Computing Systems
1993, pp. 383–390. Available from <http://http://www.acm.org/
pubs/articles/proceedings/chi/169059/p383-szekely/p383-szekely.
pdf>.
Vanderdonckt, J., Bouillon, L., Souchon, N., 2001. Flexible reverse
engineering of web pages with vaquista. In: Proc. WCRE’2001:
IEEE 8th Working Conference on Reverse Engineering. Stuttgart,
October 2001. IEEE Press. Available from <http://dlib.comput-
er.org/conferen/wcre/1303/pdf/13030241.pdf>.
Vander Zanden, B., Myers, B.A., 1990. Automatic Look-and-Feel
Independent Dialog Creation for Graphical User Interfaces CHI
’90.
Vlissides, J.M., 1998. Pattern Hatching: Design Patterns Applied.
Addison-Wesley.
Vlissides, J.M., Tang, S., 1991. A unidraw-based user interface builder.
In: Proceedings of the Fourth Annual ACM SIGGRAPH Sympo-
sium on User Interface Software and Technology, November 1991,
pp. 201–210.
Guruduth Banavar is currently managing a team of researchers buildinginfrastructure and tools for creating, adapting, and delivering appli-cations to multiple pervasive devices. Prior to this, he contributed tothe development of middleware for supporting highly scalable publish/subscribe systems. He has also worked on a variety of programmingmodels and algorithms for sharing objects in distributed interactivegroupware applications. His overall research interests are to developsoftware infrastructures and tools for easily building distributed andpervasive applications. Guru received a Ph.D. in Computer Sciencefrom the University of Utah in 1995.
Lawrence Bergman is a Research Staff Member at IBM’s T.J. WatsonResearch Center, where his research focuses on desktop programming-by-demonstration. He has an MS and PhD in Computer Science fromthe University of North Carolina at Chapel Hill. Prior to graduatework, Dr. Bergman spent a number of years developing commercialand government systems for modeling hydrology, meteorology, andeconometrics. Dr. Bergman’s research interests include user-interfacedesign, visualization, and software engineering. In his spare time, hecomposes and performs electronic music.
Yves Gaeremynck is a French student working as a intern in the PIMAgroup at IBM’s T.J. Watson Research Center. He has a Master ofEngineering with a major in computer science from the �EEcole CentraleParis, and a Master of Science in distributed computed from theUniversity of Paris Sud-Orsay. Although his deep interest in computerscience leads him to spend a lot of time programming, he also enjoysreading and drawing.
Danny Soroker is a Research Staff Member at IBM’s T.J. WatsonResearch Center, where he is currently working on application devel-opment environments in the Pervasive Infrastructure Department. Hereceived a BS in Computer Engineering and an MS in Electrical En-gineering, both from the Technion, Israel Institute of Technology, anda PhD in Computer Science from the University of California,Berkeley. Dr. Soroker’s research interests (and publications) havespanned a variety of areas, including graph algorithms, parallel com-puting, multimedia, programming languages and models, integrateddevelopment environments, and pervasive computing.
Jeremy Sussman is a Research Staff Member at IBM’s T.J.WatsonResearch Center, where he is a member of the Social ComputingGroup. His current work involves designing, building, and evaluatingcomputer-mediated communication (CMC) systems to support groupsand organizations. He has an MS and PhD in Computer Science fromthe University of California, San Diego and an A.B. in ComputerScience from Princeton University. Prior to graduate work, Dr.Sussman worked on an object-based repository for a CASE tool. Hisresearch interests include computer-supported cooperative work(CSCW), user-interface design, fault tolerance and distributed com-puting.