tmpa-2017: distributed analysis of the bmc kind: making it fit the tornado supercomputer
TRANSCRIPT

1 / 31
Distributed Analysis of the BMC Kind: Making It
Fit the Tornado Supercomputer
Azat Abdullin, Daniil Stepanov, and Marat Akhin
JetBrains Research
March 3, 2017

2 / 31
Static analysis
Static program analysis is the analysis of computer software whichis performed without actually executing programs

3 / 31
Performance problem
I Most static analyses have big problems with performance
I Our bounded model checking tool Borealis is not an exception
I We decided to try scaling Borealis to multiple cores
4 / 31
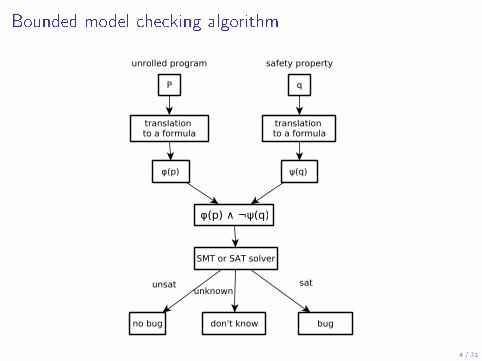
Bounded model checking algorithm

5 / 31
Veri�cation example
Program:
int x;
int y=8,z=0,w=0;
i f (x)
z = y - 1;
else
w = y + 1;
assert (z == 7 || w == 9)
Constraints:
y = 8,
z = x ? y -1 : 0,
w = x ? 0 : y + 1,
z != 7,
w != 9
UNSAT. Assert always true

6 / 31
Veri�cation example
Program:
int x;
int y=8,z=0,w=0;
i f (x)
z = y - 1;
else
w = y + 1;
assert (z == 5 || w == 9)
Constraints:
y = 8,
z = x ? y -1 : 0,
w = x ? 0 : y + 1,
z != 5,
w != 9
SAT. Program contains a bugCounterexample: y = 8, x = 1, w = 0, z = 7

7 / 31
Borealis

8 / 31
Program representation

9 / 31
Problem
A huge number of SMT queries is involved in BMC
We try to scale Borealis to multiple cores on our RSC Tornado

10 / 31
RSC Tornado supercomputer
I 712 dual-processor nodes with 1424 Intel Xeon E5-2697
I 64 GB of DDR4 RAM and local 120 GB SSD storage
I 1 PB Lustre storage
I In�niBand FDR, 56 Gb/s

11 / 31
Lustre storage
I Parallel distributed �le system
I Highly scalable
I Terabytes per second of I/O throughput
I Ine�cient work with small �les

12 / 31
Borealis compilation scheme

13 / 31
Distributed compilation
There are several ways to distribute compilation:
I Compilation on the Lustre storage
I Distribution of intermediate build tree to the processing nodes
I Distribution of copies of the analyzed project

14 / 31
Compilation on the Lustre storage
I Each node accesses Lustre for necessary �les
I Lustre is slow when dealing with multiple small �les

15 / 31
Distribution of intermediate build tree
I Reduce the CPU time
I Build may contain several related compilation/linking phases

16 / 31
Distribution of copies of the analyzed project
I Compilation is done using standard build tools
I We are repeating computations on every node
I Doesn't increase the wall-clock time

17 / 31
Distributed linking
I We distribute di�erent SMT queries to di�erent nodes/cores
I Borealis performs analysis on an LLVM IR module

18 / 31
Distributed linking
I Module level
• Same as parallel make
• Not really e�cient
I Instruction level
• Need to track dependencies between SMT calls
• Too complex
I Function level
• Medium e�ciency
• Simple implementation

19 / 31
Distributed linking
There are two ways how one can distribute functions betweenseveral processes:
I Dynamic distribution
I Static distribution

20 / 31
Dynamic distribution
I Master process distributes functions between several processes
I Based on a single producer/multiple consumers scheme
I If a process receives N functions, it also has to run auxiliaryLLVM passes N times

21 / 31
Static distribution
I Each process determines a set of function based on it's rank
I We use the following two rank kinds:
• global rank
• local rank
I After some experiments we decided to use static method

22 / 31
Improving static distribution
I Need to balance workload
I We reinforce method with function complexity estimation
I Our estimation is based on the following properties:
• Function size
• Number of memory work instructions

23 / 31
PDD
I Borealis records the analysis results
I Thereby we don't re-analyze already processed functions
I Persistent Defect Data (PDD) is used for recording results
I PDD contains:
• Defect location
• Defect type
• SMT result
{
"location": {
"loc": {
"col": 2,
"line": 383
},
"filename": "rarpd.c"
},
"type": "INI -03"
}

24 / 31
PDD synchronization problem
I Transferring a full PDD takes a long time
I We synchronize a reduced PDD (rPDD)
I rPDD is simply a list of already analyzed functions

25 / 31
rPDD synchronization
To make the synchronization we utilize a two-staged approach:
I Synchronize rPDD between the processes on a single node
I Synchronize rPDD between the nodes

26 / 31
Implementation
I Borealis HPC implementation is based on OpenMPI
I We implemented API to work with the library
I HPC Borealis is implemented in the form of 3 LLVM passes

27 / 31
Evaluation
We tested the prototype in the following con�gurations:
I One process on a local1 machine
I Eight processes on a local machine
I On RSC Tornado using 1, 2, 4, 8, 16 and 32 nodes
1a machine with Intel Core i7-4790 3.6 GHz processor, 32 GB of RAM and
Intel 535 SSD storage
28 / 31
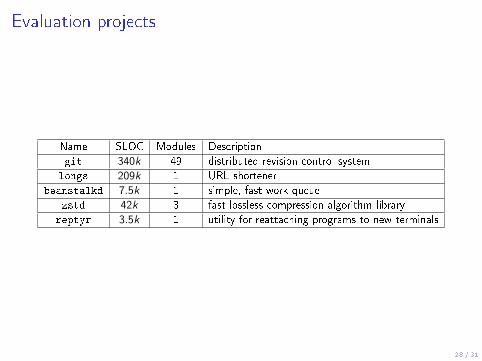
Evaluation projects
Name SLOC Modules Description
git 340k 49 distributed revision control system
longs 209k 1 URL shortener
beanstalkd 7.5k 1 simple, fast work queue
zstd 42k 3 fast lossless compression algorithm library
reptyr 3.5k 1 utility for reattaching programs to new terminals

29 / 31
Evaluation results
zstd git longs beanstalkd reptyr
SCC 1 process � 678:23 � 2:05 1:30
SCC 1 node 2433:05 113:59 58:53 2:50 1:53
SCC 2 nodes 2421:35 101:22 59:00 2:12 1:32
SCC 4 nodes 2419:23 96:53 61:09 2:19 1:19
SCC 8 nodes 2510:34 96:51 63:09 2:10 1:43
SCC 16 nodes 2434:05 97:26 63:06 2:37 1:34
SCC 32 nodes 2346:39 107:14 63:02 2:34 1:52
Local 1 process 2450:02 281:11 205:05 0:36 0:08
Local 8 processes 2848:55 103:21 93:14 0:30 0:06

30 / 31
Conclusion
Our main takeaways are as follows:
I Several big functions can bottleneck the analysis
I LLVM is not optimized for distributed scenarios
I Single-core optimizations can create di�culties for HPC
I Adding nodes can increase the time of analysis

31 / 31
Contact information
{abdullin, stepanov, akhin}@kspt.icc.spbstu.ru
Borealis repository:https://bitbucket.org/vorpal-research/borealis