theorie van databanken en zoekmachines theory of databases and search engines paul nieuwenhuysen...
TRANSCRIPT

Theorie van databanken en zoekmachinesTheory of databases and search engines
Paul Nieuwenhuysen
• Vrije Universiteit Brussel
• Information and Library Science, University of Antwerp
Belgium
Slides used to support this presentation at the one-day workshop on
“Technisch-wetenschappelijke databanken”“Databases for Technology and Science”
organised by KVIV,27 November 2003,
Katholieke Universiteit Leuven, Heverlee-Leuven, Belgium

- contents - summary - structure- overview
of this lecture
• Databases and computerised information retrieval
• Knowledge organisation: classifications and thesaurus systems
• Online access information sources and services, including Internet directories and text search engines
• Evaluations in information retrieval

Databases and computerized information retrieval

Types of databases: examples
Examples: The databases that form the basis for
»catalogues of books or other types of documents
»computerized bibliographies
»address directories
»a full text newspaper, newsletter, magazine, journal+ collections of these
»WWW and Internet search engines
» intranet search engines
» ...

Information retrieval: via a database to the user
Informationcontent
Informationcontent
Linear file Inverted file
Search engine
Search interface UserUser
Database

Information retrieval: building a database
Inverted file, index, register of the database
UserUser
Records derived from the input and stored in the database
Records fed into the database management system
Indexing
Retrieval
Comparison
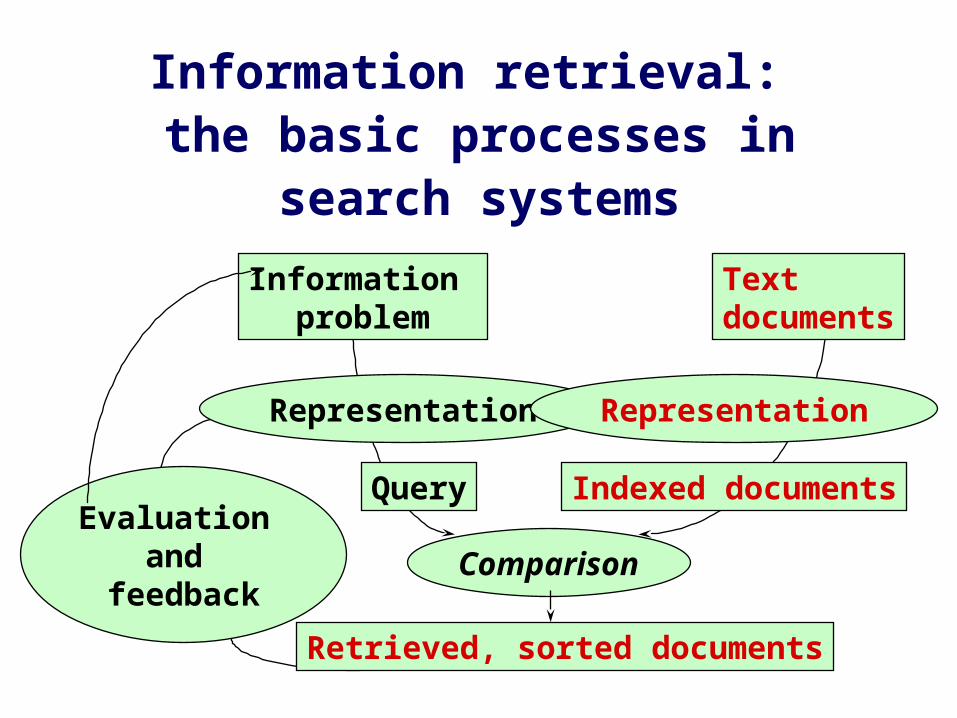
Information retrieval: the basic processes in search systems
Information problem
Representation
Query Indexed documents
Representation
Retrieved, sorted documents
Text documents
Evaluation and
feedback

Information retrieval systems: many components make up a system
• Any retrieval system is built up of many more or less independent components.
• These components can be modified to increase the quality of the results more or less independently.

Information retrieval systems: important components
the information content
system to describe formal aspects of information items
system to describe the subjects of information items
concrete descriptions of information items = application of the used information description systems
information storage and retrieval computer program(s)
computer system used for retrieval
type of medium or information carrier used for distribution

What determines the results of a search in a retrieval system?
• the information retrieval system ( = contents + system)
• the user of the retrieval system and the search strategy applied to the system
Result of a searchResult of a search

Layered structure of a database
Database
(File)
Records
Fields
Characters
+ in many systems:relations / links
between records

A simple database architecture: all records together form a database
The ‘salami architecture’ = ‘sliced bread architecture’
»the salami or the bread is a “database”
»each slice of salami or bread is a “database record”
»there are no relations between slices / records
»the retrieval system tries to offer the appropriate slices / records to the user

Structure of a bibliographic file
Record No. 1 Title Author 1: name + first name Author 2: ... Source Descriptor 1 Descriptor 2 ...
Record No. 2
Sub-fields
Repeated fields

Text retrieval and language: an overview
Text retrieval and language: an overview
Problems related to language / terminology occur1. even when the same language is used in searching and in the searched databases2. in the case of “multi-linguality”: “cross-language information retrieval” that is when more than 1 language is used
»in the search terms
»in the contents of the searched database(s) and/orin the subject descriptors of the searched database(s)

Text retrieval and language: enhancing retrieval
Text retrieval and language: enhancing retrieval
• Retrieval can be enhanced by coping with the problems caused by the use of natural language.
• Contributions to this enhancement of retrieval can be made by
»the database producer
»the computerized retrieval system
»the searcher/user
• (The distinction between these is not very sharp and clear in all cases.)

Text retrieval and language: a word is not a concept
Text retrieval and language: a word is not a concept
Problem: A word or phrase or term is not the same as a concept or
subject or topic.
Word
WordConcept

Text retrieval and language: a word is not a concept
So, to ‘cover’ a concept in a search, to increase the recall of a search, the user of a retrieval system should consider an expansion of the query; that is: the user should also include other words in the query to ‘cover’ the concept.
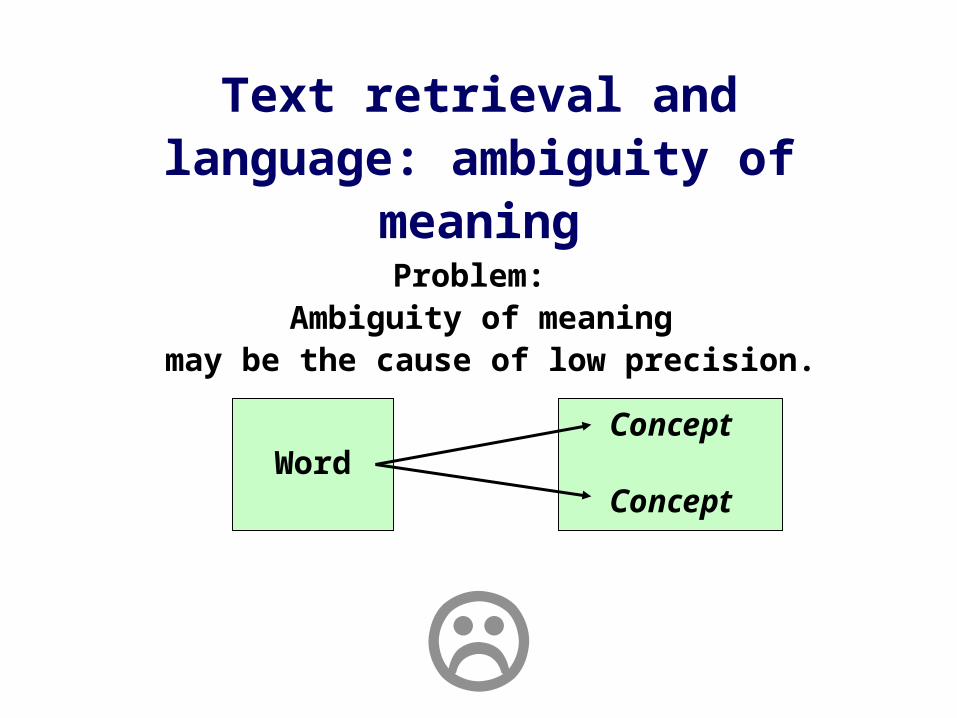
Text retrieval and language: ambiguity of meaning
Problem: Ambiguity of meaning
may be the cause of low precision.
WordConcept
Concept

Text retrieval and language: relation with recall and precision
Text retrieval and language: relation with recall and precision
Recapitulating the two problems discussed, we can say that
• Expansion of the query allows to increase the recall.
• Disambiguation of the query allows to increase the precision.

Text retrieval and language: phrases composed of words
Text retrieval and language: phrases composed of words
• Problem: Most retrieval systems can search for words, but they do not directly recognize or ‘know’ phrases / terms composed of more than 1 word.

Natural language processing of the documents AND of the query
Comparison and matching of both
Enhanced text retrieval using natural language processing
Information problem
Representation
Query Indexed documents
Representation
Retrieved, sorted documents
Text documents
Evaluation and
feedback

Text retrieval and language: conclusions
• The use of terms and language to retrieve information from databases/collections/corpora causes many problems.
• These problems are not recognized or underestimated by many users of search/retrieval systems= The power of retrieval systems is overestimated by many users.
• Much research and development is still needed to enhance text retrieval.

Hints on how to use information sources: Boolean combinations
Most text search systems understand the basic Boolean operators:
OR = obtain records that contain one or both search terms
AND = obtain records that contain both search terms
NOT= exclude records that contain a search term

Hints on how to use information sources: Boolean combinations
In the case of computer-based information sources, use Boolean combinations of search terms when appropriate and when possible.
term x1OR term x2ORterm x3
term x1OR term x2ORterm x3
term y1OR term y2OR term y3
term y1OR term y2OR term y3
term z1OR term z2OR term z3
term z1OR term z2OR term z3
AND AND AND ...

Knowledge organisation: classifications, and thesaurus systems
Knowledge organisation: classifications, and thesaurus systems

• To organise knowledge / documents / books / reports / information / data / records / things / items / materials for more efficient storage and retrieval, some related, similar tools / systems / methods / approaches are used.
• Often but not yet always, this process is assisted by a computer system.
• Good systems are expanded and updated when the need arises.
Knowledge organisation: introduction
Knowledge organisation: introduction

• Various related tools / systems / methods / approaches are available:
»Classification
»Taxonomy
»Controlled list of selected keywords
»Thesaurus
»Ontology
»Subject-related metadata
»…
Knowledge organisation: some tools
Knowledge organisation: some tools

Thesaurus: descriptionThesaurus: description
• Thesaurus (contents) =
»system to control a vocabulary (= words and phrases + their relations)
» + the contents of this vocabulary
• Thesaurus program =
program to create, manage, modify and/or search a thesaurus using a computer

Thesaurus relations
Thesaurus relations
Term(s) with broader meaning
BT (= Broader Term)
RT (= Related Term) UF (= Use(d) For)Other term(s) Term Synonym(s)
NT (= Narrower Term)
Term(s) with narrower meaning

Thesaurus applications related to information searching
Thesaurus applications related to information searching
• For users (!) of a database:When the database to be searched is produced with added descriptors (words and terms) that are taken from a controlled list of approved, selected words and terms, then the searcher can use some printed or computer-based system first, to find more and ‘correct’ suitable words and terms that belong to that controlled list of descriptors; then, the searcher can use these descriptors (and only these words or terms) in a database query.

Thesaurus applications related to information searching
Thesaurus applications related to information searching
• For users (!) of a database: When the database to be searched is NOT produced with added descriptors (words and terms) that are taken from a controlled list of words and terms, then the searcher can use one or several thesaurus systems first, to find more words and terms and more suitable words and terms; then the searcher can use these found words and terms to formulate a query for that database (to increase recall and precision).

Thesaurus systems that cover all subjectsThesaurus systems
that cover all subjects
• General systems
• Universal systems
• Covering all subjects
• Broad and shallow systems
• Horizontal systems

Thesaurus systems that cover all subjects: examples (1)
Thesaurus systems that cover all subjects: examples (1)
• Library of Congress Subject Headings (LCSH)
• thesaurus system built into word processing software
• thesaurus system that runs on a pc (independent of Internet) see for instance http://www.wordweb.co.uk/free/
• thesaurus systems that can be used free of charge through the WWW
»http://education.yahoo.com/reference/thesaurus/index.html
»http://thesaurus.plumbdesign.com/
Examples

Thesaurus systems focused on a particular subject
Thesaurus systems focused on a particular subject
• Focused on a particular subject domain = narrow and deep, vertical systems
• Examples:
»INSPEC: physics, electronics, information technology
»Medline (the Medical Subject Headings = MeSH)
»...

Online access information sources and services

Internet: subject-oriented meta-information offered via WWW
Information about information sources: in the form of
»subject guides = texts with references
»subject hypertext directories = subject guides
»key word indexes, generated automatically, for searching
»collections of links or forms to the above
»(multi-threaded search systems)

Internet global subject directories:introduction
• They are virtual libraries with open shelves, for browsing.
• They are manually generated, man-made by many people.
• They can be browsed following a tree structure or a more complicated variation.
• The most famous of these systems belong to the most popular and most visited sites on the WWW: e.g. Yahoo!

Internet global subject directories: pros and cons
• They cover a small number of selected WWW sites, in comparison with the total number of sites that are accessible.
+ The selected, included sites should be better than average.
- They are not suitable for deep, detailed, specific searches with a high coverage.

Internet global subject directories:why use one?
• They are suitable mainly for broad searches that can be difficult to formulate in words, but NOT for more specific searches that require combinations of several concepts.

Internet global subject directories:searching directories with a query
• Many of the Internet directories include an index to search their contents with a query.
• However, then the assisting classification structure is not well exploited and the user should be aware of the problems and difficulties of information retrieval with natural language queries.
• Furthermore, the possibility to use the system in this way may be confusing, as these directories are not real full-text Internet indexes, like those provided by other search tools.

Internet indexes:automated search tools
• Several systems allow to search for and to locate many items (addressable resources) in the Internet in a more systematic, direct way than by only browsing/navigating.
• These systems do NOT search the contents of computers through the real Internet in real time and completely when a user makes a query. Searching in that way would be much too slow due to limitations in the technology.
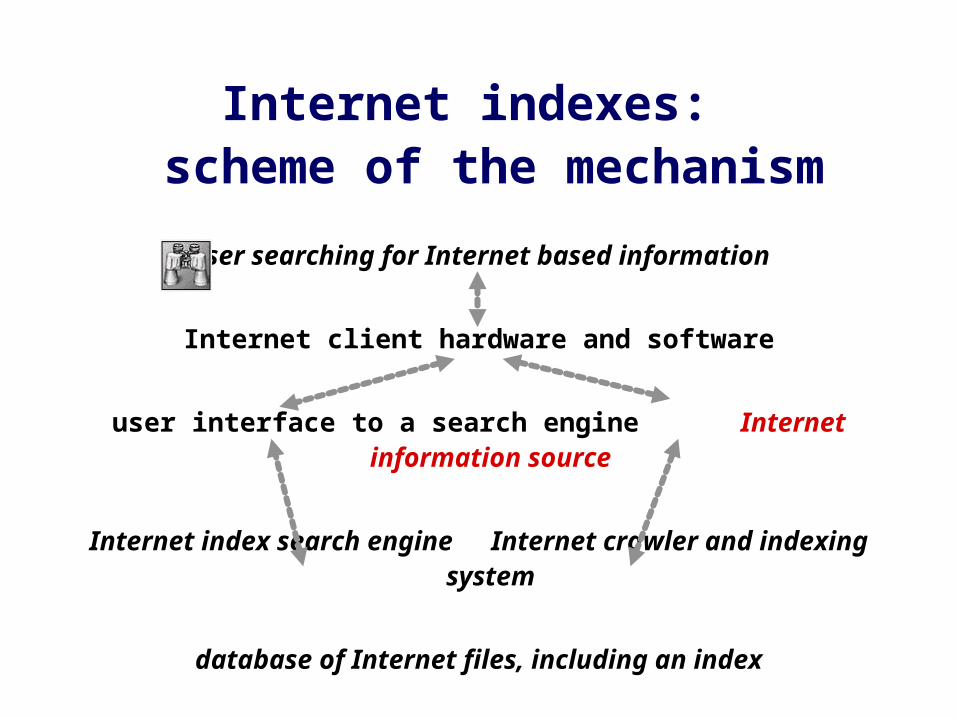
Internet indexes: scheme of the mechanism
User searching for Internet based information
Internet client hardware and software
user interface to a search engine Internet information source
Internet index search engine Internet crawler and indexing system
database of Internet files, including an index

Internet indexes:description of the mechanism
Each of these search systems is based on:
• a database of links to pages / URLs that can be retrieved by searching with queries through a big index that is built machine-made on the basis of the contents, the texts, of these pages(to build this database and to keep it up to date, pages are continuously collected from the Internet by a “robot” computer software system)
• a search system with a user interface in a WWW form, to allow the user to search through that database
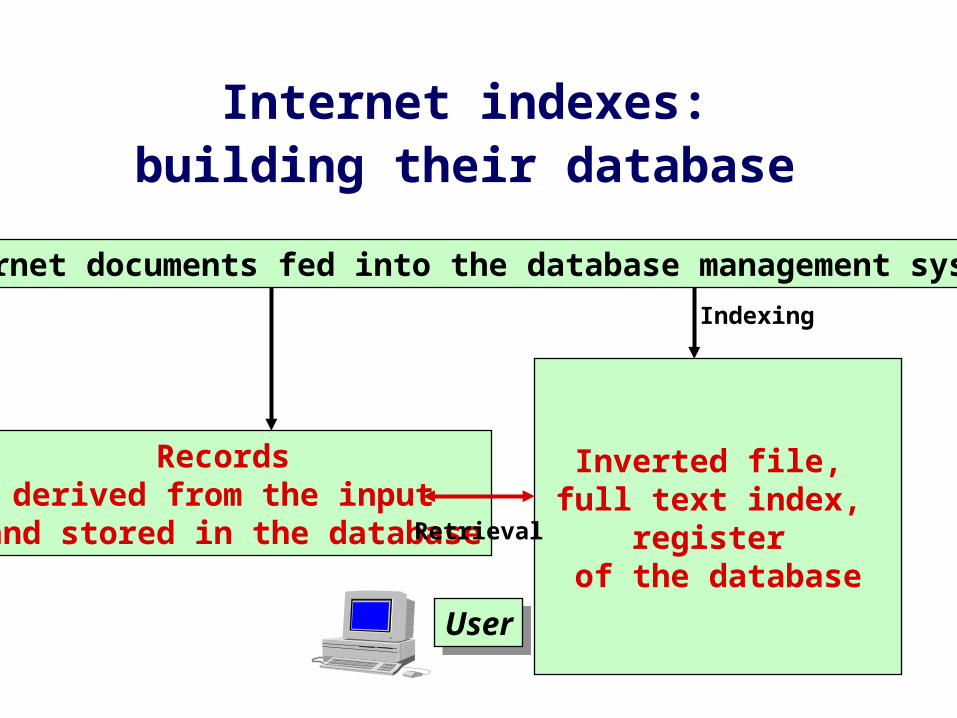
Internet indexes: building their database
Inverted file, full text index,
register of the database
UserUser
Records derived from the input
and stored in the database
Internet documents fed into the database management system
Indexing
Retrieval
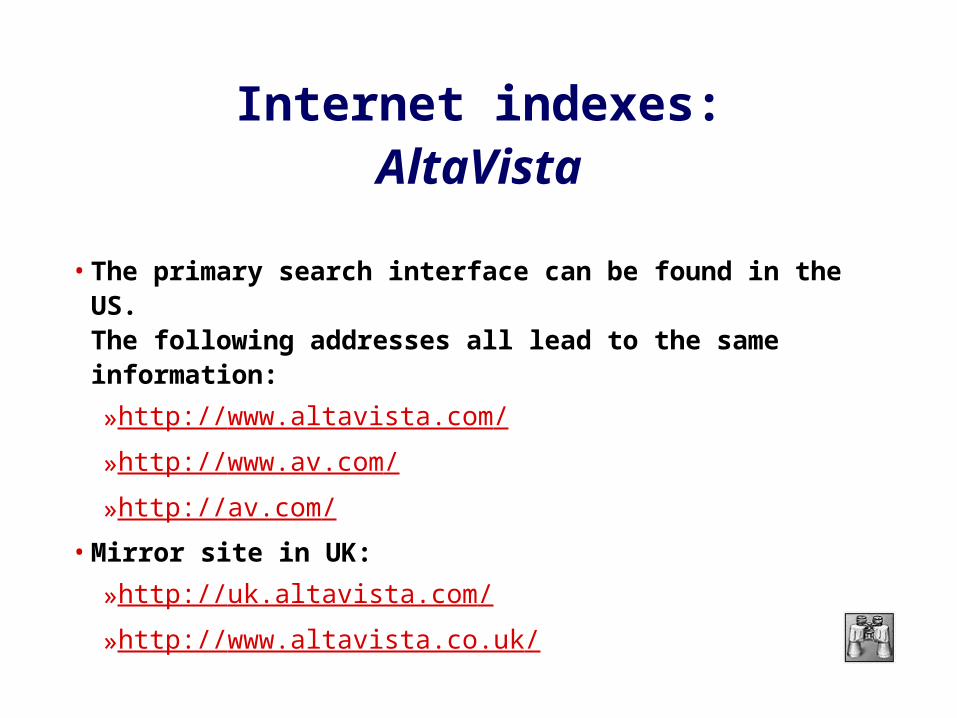
Internet indexes:AltaVista
• The primary search interface can be found in the US. The following addresses all lead to the same information:
»http://www.altavista.com/
»http://www.av.com/
»http://av.com/
• Mirror site in UK:
»http://uk.altavista.com/
»http://www.altavista.co.uk/

Internet indexes:All the Web
• The search interface can be found at:http://www.alltheweb.com/http://alltheweb.com/
• You can search the WWW and ftp servers.
• The database is one of the biggest.
• Not only HTML and plain text files, but also the full text of many Adobe PDF files is indexed.
• Offers also a module to search for pictures/images.
• Offers spelling suggestions in the search interface.

Internet indexes: Google (Part 1)
• http://www.google.com/
• Full-text searching is possible of many files that are available through the WWW.
• Not only HTML and plain text pages are covered, but also the first part is indexed of many files in other file formats, such as
»Adobe PDF,
»Microsoft Word, Microsoft Excel, Microsoft PowerPoint
»Rich Text Format…

Internet indexes: Google (Part 2)
• One of the most popular systems in 2001, 2002, 2003…
• For retrieval an algorithm is used that takes into account the links between WWW pages.A retrieved page is ranked higher when
»many sites/pages point to it
»“important” sites/pages point to it

Internet indexes: Google refers to a thesaurus
• In Google, the words used in a search query are returned to the user with hyperlinks to a dictionary and to a thesaurus on the WWW, that can be used partly free of charge.
• The thesaurus can of course show the user synonyms, narrower terms, related terms for the word.In this way, this system can be used to expand a search query, so that the query better covers the search concept.

Internet indexes: Google can expand a query: how?
• If you want to retrieve more documents, then you can request Google to include synonyms of one or several of the words in your query in an automatic way.
• This works since 2003.
• You can do this by putting a tilde ~ in front the selected word.
• Example of a query: word1 ~word2 word3 word4

Internet indexes: Google can expand a query: comment
• Of course, this is only a “quick and dirty” method.The system does not really understand your information need. Manual, intellectual expansion of a query should yield better results.

Internet indexes: Google additional features
• Besides a system to search for WWW pages, Google offers also »a subject directory»searching for images/pictures on the WWW
»searching an archive of Usenet messages + posting to Usenet groups
»searching for news
• Thus Google has become a great integrator / aggregator.

Internet indexes: MSN Web Search
• Offered free of charge by Microsoft.
• You can search for WWW content.
• Since 1998.
• Famous system, because the search interface can be found with the search functions that have been built into one of the most widespread Internet browser, Microsoft IE.
• Is based on an Internet index created by another company.But in 2003, Microsoft has started building its own WWW crawler.

Internet indexes: Scirus
• Allows you to search for manually selected scientific information (only) on the WWW. This includes
» the peer-reviewed articles in the journals that are published in ScienceDirect by Elsevier, that can be downloaded in full-text format only when a fee has been paid to the publisher
»scientific open archives files, that contain scientific research articles that can be downloaded free of charge.
• The search interface: http://www.scirus.com

Internet indexes: Teoma
• Allows you to search for information on the WWW.
• Offers a feature that is not offered by most other search systems: categorization = classification = refinement = categorization = clustering of search results, to help the user coping with the problem of ambiguity of meaning of the search query that was made
• The search interface: http://www.teoma.com/

Internet indexes: coverage
• Internet indexes do not cover all static documents on the WWW.
• Most indexes grow and their “size ranking” is variable.
• If exhaustive results are desired, then more than one Internet index search system should be used.

the complete WWW
Internet indexes: subject-specific, specialised systems
covered by a global / international Internet index
covered by an Internet index limited to
sources related to a specific subject

Internet indexes: variations among various systems
• Besides their common aims and characteristics, we can nevertheless see differences, variations among the searchable Internet index systems.
• To illustrate these variations and to assist Internet users to make a decision on which search system to use, the following list of some features and evaluation criteria can be useful.

Internet indexes: general evaluation criteria - desiderata
• Is usage free of charge?
• How complete is the coverage?
• Is the coverage good (or poor) for a particular geographic region?
• Is the coverage good (or poor) for a particular type of documents?
• Is the searchable database up to date? Is the database updated frequently? Do the search results contain only few dead (broken) links?

Internet indexes: indexing + searching
evaluation criteria - desiderata (1)
• Does the database system work with full text indexing of each document that has a place in the database, so that full text searching is possible?Is the complete text indexed and searchable, even for very long documents?

Internet indexes: indexing + searching evaluation criteria - desiderata (2)
• Are the contents of meta-fields also indexed to make them searchable?

Internet indexes: indexing + searching
evaluation criteria - desiderata (3)
• Does the system index also the text in files on the web that consist of non-ASCII codes to make these also searchable and retrievable? For instance files in the format of the various versions of
»Microsoft Word (DOC), Microsoft PowerPoint (PPT, PPS), Microsoft Excel
»Adobe Acrobat Portable Document Format (PDF)

Internet indexes: indexing + searching
evaluation criteria - desiderata (4)
• Field indexing, so that searching limited to the contents of a particular field is possible? for instance:
HTML title, HTML keywords,
URL, date,
link, Java applet,
text, image file,
sound file, video file...

Internet indexes: indexing + searching evaluation criteria - desiderata (5)
• Does the system offer powerful search options like
»searching for terms composed of several words, in queries like “word1 word2” with the words enclosed in double quote characters
»truncation of words in a query?
»Boolean search combinations?
»an unlimited number of search terms in a query?
»proximity/nearby/adjacency searching, with operators like “word1 NEAR word2” or “word1 ADJ word2”

Internet indexes: indexing + searching evaluation criteria - desiderata (6)
»spelling check of search terms in the query, and suggesting spelling variations?
»automatic expansion of the search terms in the initial user’s query, to achieve a higher recall, for instance by
—automatic stemming of words in a query
—including synonyms
—including narrower terms
—including translations into several other languages

Internet indexes: indexing + searching evaluation criteria - desiderata (7)
• Can the results be limited to a certain time period? For instance based on the date
»of the file as noted by the server computer, or
»of the most recent indexing of the file
• Is the user interface easy to understand and efficient to use?
• Is a user interface offered in your own language?

Internet indexes: indexing + searching evaluation criteria - desiderata (8)
• Is the search/query also submitted to another database to obtain more results? for instance: to a book database to obtain book descriptions besides WWW documents

Internet indexes: indexing + searching evaluation criteria - desiderata (9)
• Is spamming filtered out, to give other pages a better chance of turning up in the result set?Can the system cluster presumed duplicate documents in the results? Or does the system simply eliminate presumed duplicate documents from its database?

Internet indexes: output evaluation criteria - desiderata (1)
• Short response times?
• Are mirror sites available closer to you for faster response?
• Does the system rank the items in the result set according to their presumed relevance?
• Possibility to combine Boolean retrieval with relevance ranking of results?

Internet indexes: output evaluation criteria - desiderata (2)
• Can the results be ordered according to date
»of the file as noted by the server computer, or
»of the most recent indexing of the file
• Can the results be ordered according to size?
• Can the system rank the results (documents) on the basis of the number of WWW hyperlinks to that document?
• The system does NOT place/rank some results (documents) higher in the results list, on the basis of payments by the producer of those documents to the search system company.

Internet indexes: output evaluation criteria - desiderata (3)
• Are advertisements / sponsored links / sponsored results clearly distinguished from normal (not sponsored) search results?
• Good and detailed summary of each result available?
• Does the system offer a good presentation format of each result (document/page/item)?For instance: are search terms indicated / highlighted in the results?

Internet indexes: output evaluation criteria - desiderata (4)
• Is any evaluation offered (automatic?) of the quality of each result, besides ranking in an order related to probable relevance and importance of the results?
• Can all the results (documents) from the same site be grouped together (clustered)?

Internet indexes: output evaluation criteria - desiderata (5)
• Are results (retrieved documents) grouped / classified / categorized / clustered by the search system, on the basis of the subjects of the documents and are these presented as groups / clusters / classes / categories to the user of the search system, to assist the user in coping with the problems that can be caused for instance by multiple meanings of words used in a search query.
• Is translation of documents offered free of charge?

Internet indexes: output evaluation criteria - desiderata (6)
• Is any fact extraction from the information sources offered, in an attempt to answer the query more directly than by offering only links to documents?
• Term suggestion: Does the system analyse the search results of the first query, to find frequently occurring terms and to suggest these to the user as new and potentially interesting additional query terms?

Internet indexes: output evaluation criteria - desiderata (7)
• High stability and reliability?
• No large variations/fluctuations in the results from identical searches at different times.
• Relevance feedback:Can the user indicate among the search results of a first query the “good, relevant” and the “bad, irrelevant” results, so that the system can use this information to offer better results in a second query?

Internet indexes for citation searching: introduction
• Some Internet indexes / search engines allow you to search for documents / pages / URLs that link to a particular page, to some URL that you already know (such as one of the web pages that you have developed or that you have made available yourself).
• Linking to a URL is similar to citing an information source.
• Such search systems can be used to analyse web citations.
• Web citations are sometimes named “sitations”, referring to the term “web site”.

Internet indexes for citation searching: query syntax
• For details about the required query syntax, query formulation, see the online manual or help pages of the search system that you want to use.
• Take care to search for all variants such as
»//web-server-computer.country/website/index.html
»//web-server-computer.country/website/
»//web-server-computer.country/website

Internet indexes for citation searching: examples of systems
• AltaVista!
- Note that “Simple search” and “Advanced search” may give different results!?
+ Allows truncation, which can be used to search not only citations of a WWW page, but also of a whole WWW site.
+ Allows Boolean searching, which can be used to exclude self-citations.
• Lycos
Examples

Internet indexes for citation searching: applications
• Citation searching on the WWW or on an intranet can be used
»to get an idea of the importance, the fame, the impact of a particular web document, as measured by the number of links/citations to that page
»to find out who has considered a particular page as interesting enough to make a link to
»to find comments/criticisms on a particular web document

Internet indexes for citation searching: special evaluation criteria
• Can self-citations and/or other documents be excluded from the search results in the query used to find citations?
• Is left truncation possible of the URL for which you want to find citations, so that citations to this and to underlying documents can be found in one action?
• Is right truncation possible of the URL for which you want to find citations, so that citations to this and to related documents on multiple sites can be found in one action?

Meta- search systems: scheme 1+2
User
Client computer
+WWW
client program
Client computer
+ Multi-threaded Internet search client program
WWW server
computer
InternetWWW
WWW server
computerswith Internet
search systems
In Out
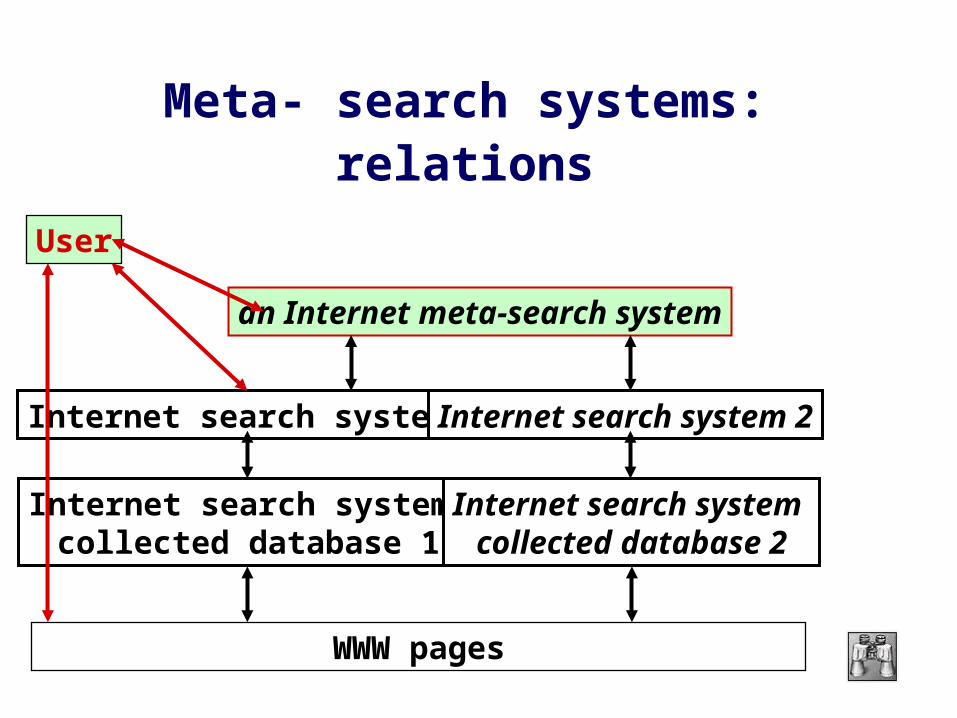
Meta- search systems: relations
User
an Internet meta-search system
Internet search system 1
Internet search system collected database 1
WWW pages
Internet search system 2
Internet search system collected database 2

Example
Meta-search systems: server-based: example: Vivisimo

Example
Meta-search systems: server-based: example: Vivisimo
• Vivisimo adds value by analysing the retrieved results / hits / links / WWW documents, in order to cluster / group / categorize / classify / map these under headings / classes / categories, to make further selections by the user / searcher easier and faster.
• Vivisimo can accomplish this on the fly, that is WITHOUT pre-processing the documents before the search.

Meta-search systems: advantages
+ Saves time when otherwise more than only 1 Internet index would have to be used one after the other; for instance when searching for specific information that is hard to find in any single Internet index.
+ Some meta-search systems provide a useful integration of the results they get from the various primary search systems, with a removal of repeated results.

Meta-search systems: disadvantages
- It is not always clear through which Internet indexes the meta-search system will search.
- Not all meta-search systems can search all the major primary search systems; for instance Google is normally NOT included.
- The systems are often slower than a direct, primary search system.
- Only a limited number of the results that can be obtained from the various Internet indexes are shown.

Internet indexes cover only a part of the Internet: introduction (1)
The “visible” part of Internet
The “hidden, invisible” part of Internet and the WWW, (that is not searchable using a global index
like Alltheweb, AltaVista, Google...)

Internet indexes cover only a part of the Internet: introduction (2)
Why can Internet indexes find only a part of what is in fact available through the Internet?
1. Quantitative technical limitations: Each Internet search system has indexed only a part of the static WWW pages that are available for indexing.
2. Qualitative technical limitations: Besides the static WWW pages that Internet search engines try to cover, many other, quite different sources exist, that are also available through the Internet, but that are not incorporated in those search engines.
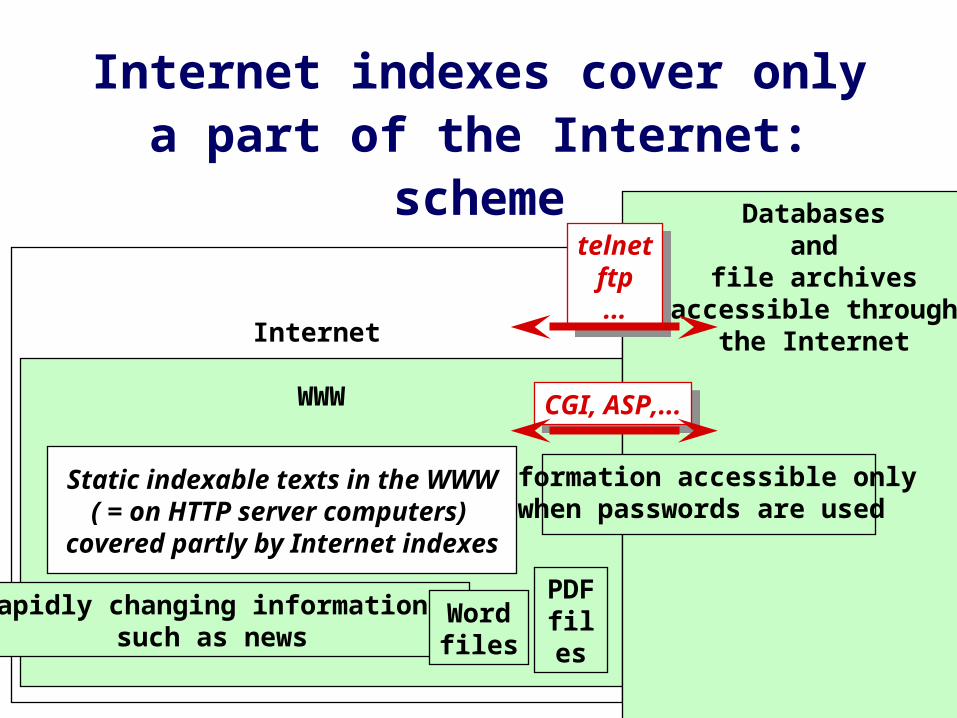
Internet
Internet indexes cover only a part of the Internet: scheme
WWW
Databases and
file archives accessible through
the Internet
telnetftp...
telnetftp...
CGI, ASP,...CGI, ASP,...
Rapidly changing information, such as news
Information accessible only when passwords are used
Static indexable texts in the WWW( = on HTTP server computers)
covered partly by Internet indexes
Wordfiles
PDFfiles

Current awareness services focusing on WWW pages: introduction
• Tracking changes in one or more public access pages on the WWW or finding new pages, is possible in an automated way,
»by using one of the available, suitable, programs loaded on your client workstation! example: the advanced version of Copernic that is not available free of charge
» through “alert” services based on a server on the WWW
—that track updates for the user/subscriber
—and send alerts by email to the user/subscriber

Current awareness services focusing on WWW pages: Google Alert
• Can discover relevant changed or new WWW pages for you in the future.
• Is based on the external Internet index Google.
• Works with search queries given by you that are stored on their server computer.
• Free of charge, at least up to 2003.
• http://www.googlealert.com/
Example

Evaluations in information retrieval

Evaluations in information retrieval:summary
• The following gives an overview of approaches that are applied to assess the quality of
»information retrieval systems, and more concretely of search systems
»the resulting set of records obtained after performing a query in an information retrieval system
• Note: This should not be confused with assessing the quality and value of the content of an information source.

Evaluations in information retrieval:introduction
• The quality of the results, the outcome of any search using any retrieval system depends on many components / factors.
• These components can be evaluated and modified to increase the quality of the results more or less independently.

Evaluations in information retrieval:important factors
• The information retrieval system ( = contents + system)
• The user of the retrieval system and the search strategy applied to the system
Result of a searchResult of a search

Evaluations in information retrieval:why? (Part 1)
• To study the differences in outcome/results when a component of a retrieval system is changed, such as
»the user interface
»the retrieval algorithm
»addition by the database of uncontrolled, natural language keywords versus keywords selected from a more rigid, controlled vocabulary

Evaluations in information retrieval:why? (Part 2)
• To study the differences in outcome/results when a search strategy is changed.
• To study the differences in outcome/results when searches are performed by different groups of users, such as
»children versus adults
»inexperienced users versus more experienced, professional information intermediaries/professionals

Evaluations in information retrieval: the simple Boolean model
Boolean model: # items in database = # items selected + # items not selected
# Items selected =
# relevant items + # irrelevant items
Relevant Yes
1In
IrrelevantNo0
Out
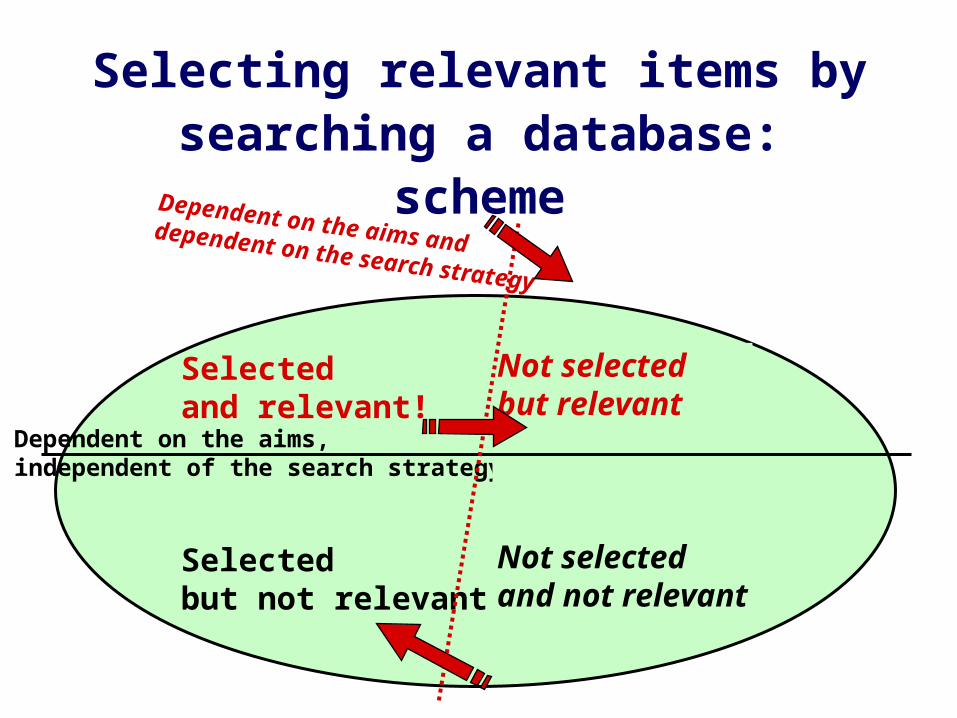
Selecting relevant items by searching a database: scheme
Dependent on the aims, independent of the search strategy
Selected and relevant!
Selectedbut not relevant
Not selected but relevant
Not selectedand not relevant
Dependent on the aims and dependent on the search strategy

Recall: definition and meaning
• Definition: # of selected relevant items “Recall” = ------------------------------------------------- * 100% Total # of relevant items in database
• Aim: high recall
• Difficulty: in most practical cases, the total # of relevant items in a database cannot be measured.

Precision: definition and meaning
• Definition:
# Of selected relevant items“Precision” = --------------------------------------- * 100% Total # of selected items
• Aim: high precision

Relation between recall and precision of searches
100%
Recall
0 0 Precision 100%
Ideal = Impossibleto reach in most systems
Ideal = Impossibleto reach in most systems
Search (results)

Recall and precision should be considered together
Examples:
• Increase in retrieved number of relevant items may be accompanied by an impractical decrease in precision.
• Precision of a search close to 100% may NOT be ideal, because the recall of the search may be too low. Make search / query broader to increase recall !
• Poor (low) precision is more noticeable than bad (low) recall.

Evaluation in the case of systems offering relevance ranking
• Many modern information retrieval systems offer output with relevance ranking.
• This is more complicated than simple Boolean retrieval, and the simple concepts of recall and precision cannot be applied.
• To compare retrieval systems or search strategies, decide to consider for comparison a particular number of items ranked highest in each output.This brings us to for instance: “first-20 precision”.