the utility of temporal abstraction in …pstone/courses/394rspring13/resources/...motivation...
TRANSCRIPT

MotivationExperimental Results
Summary
The Utility of Temporal Abstraction inReinforcement Learning
Nicholas K. Jong Todd Hester Peter Stone
Department of Computer SciencesThe University of Texas at Austin
The Seventh International Conference on AutonomousAgents and Multiagent Systems
Nicholas K. Jong, Todd Hester, Peter Stone The Utility of Temporal Abstraction in Reinforcement Learning

MotivationExperimental Results
Summary
Outline
1 Motivation: Hierarchical Reinforcement Learning
2 Experimental ResultsLearning with OptionsOptions and Random ExplorationOther Applications of Options
Nicholas K. Jong, Todd Hester, Peter Stone The Utility of Temporal Abstraction in Reinforcement Learning

MotivationExperimental Results
Summary
Goal: Learn Agent Behaviors Autonomously
Reinforcement learning algorithms:
Given experience with anunknown environmentEstimates the value of statesLearns a policy
ProblemHow to learn more efficiently?
G
Nicholas K. Jong, Todd Hester, Peter Stone The Utility of Temporal Abstraction in Reinforcement Learning

MotivationExperimental Results
Summary
Goal: Learn Agent Behaviors Autonomously
Reinforcement learning algorithms:
Given experience with anunknown environmentEstimates the value of statesLearns a policy
ProblemHow to learn more efficiently?
G
Nicholas K. Jong, Todd Hester, Peter Stone The Utility of Temporal Abstraction in Reinforcement Learning

MotivationExperimental Results
Summary
Goal: Learn Agent Behaviors Autonomously
Reinforcement learning algorithms:
Given experience with anunknown environmentEstimates the value of statesLearns a policy
ProblemHow to learn more efficiently?
G
Nicholas K. Jong, Todd Hester, Peter Stone The Utility of Temporal Abstraction in Reinforcement Learning

MotivationExperimental Results
Summary
Goal: Learn Agent Behaviors Autonomously
Reinforcement learning algorithms:
Given experience with anunknown environmentEstimates the value of statesLearns a policy
ProblemHow to learn more efficiently?
G
Nicholas K. Jong, Todd Hester, Peter Stone The Utility of Temporal Abstraction in Reinforcement Learning

MotivationExperimental Results
Summary
Intuition: Decompose Tasks into Subtasks
Standard RL assumes flat stateand action spaces.Real-world applications havehierarchical structure.Abstract actions
Represent sequences ofprimitive actionsAchieve subgoals
G
Nicholas K. Jong, Todd Hester, Peter Stone The Utility of Temporal Abstraction in Reinforcement Learning

MotivationExperimental Results
Summary
Intuition: Decompose Tasks into Subtasks
Standard RL assumes flat stateand action spaces.Real-world applications havehierarchical structure.Abstract actions
Represent sequences ofprimitive actionsAchieve subgoals
G
Nicholas K. Jong, Todd Hester, Peter Stone The Utility of Temporal Abstraction in Reinforcement Learning

MotivationExperimental Results
Summary
The Most Popular Framework for Hierarchical RL
Options: analogous to macro-operatorsInitiation set (precondition)Termination function (postcondition)Option policy (implementation)
Typically used to augment an action spaceCan be treated simply as temporally extended actions
Nicholas K. Jong, Todd Hester, Peter Stone The Utility of Temporal Abstraction in Reinforcement Learning

MotivationExperimental Results
Summary
The Most Popular Framework for Hierarchical RL
Options: analogous to macro-operatorsInitiation set (precondition)Termination function (postcondition)Option policy (implementation)
Typically used to augment an action spaceCan be treated simply as temporally extended actions
Nicholas K. Jong, Todd Hester, Peter Stone The Utility of Temporal Abstraction in Reinforcement Learning

MotivationExperimental Results
Summary
The Most Popular Framework for Hierarchical RL
Options: analogous to macro-operatorsInitiation set (precondition)Termination function (postcondition)Option policy (implementation)
Typically used to augment an action spaceCan be treated simply as temporally extended actions
Nicholas K. Jong, Todd Hester, Peter Stone The Utility of Temporal Abstraction in Reinforcement Learning

MotivationExperimental Results
Summary
The Most Popular Framework for Hierarchical RL
Options: analogous to macro-operatorsInitiation set (precondition)Termination function (postcondition)Option policy (implementation)
Typically used to augment an action spaceCan be treated simply as temporally extended actions
Nicholas K. Jong, Todd Hester, Peter Stone The Utility of Temporal Abstraction in Reinforcement Learning

MotivationExperimental Results
Summary
The Benefits of Options
Prior work: options are goodFuture work: where do the options come from?
Key QuestionHow precisely does the addition of options affect learning?
Nicholas K. Jong, Todd Hester, Peter Stone The Utility of Temporal Abstraction in Reinforcement Learning

MotivationExperimental Results
Summary
Learning with OptionsOptions and Random ExplorationOther Applications of Options
Outline
1 Motivation: Hierarchical Reinforcement Learning
2 Experimental ResultsLearning with OptionsOptions and Random ExplorationOther Applications of Options
Nicholas K. Jong, Todd Hester, Peter Stone The Utility of Temporal Abstraction in Reinforcement Learning

MotivationExperimental Results
Summary
Learning with OptionsOptions and Random ExplorationOther Applications of Options
Replicating Results in Option Discovery
Apply standard Q-learning with ε-greedy explorationIntroduce options after 20 episodes
One option for each of four given subgoalsOption policies learned from experience replayInitiation set: states that can reach subgoal
G
One of four options 0
100
200
300
400
500
0 10 20 30 40 50
Ste
ps p
er e
piso
de
Episodes
Q-learning
Nicholas K. Jong, Todd Hester, Peter Stone The Utility of Temporal Abstraction in Reinforcement Learning

MotivationExperimental Results
Summary
Learning with OptionsOptions and Random ExplorationOther Applications of Options
Replicating Results in Option Discovery
Apply standard Q-learning with ε-greedy explorationIntroduce options after 20 episodes
One option for each of four given subgoalsOption policies learned from experience replayInitiation set: states that can reach subgoal
One of four options 0
100
200
300
400
500
0 10 20 30 40 50
Ste
ps p
er e
piso
de
Episodes
Q-learningOptions after 20 eps
Nicholas K. Jong, Todd Hester, Peter Stone The Utility of Temporal Abstraction in Reinforcement Learning

MotivationExperimental Results
Summary
Learning with OptionsOptions and Random ExplorationOther Applications of Options
Hierarchical Reasoning or Additional Computation?
ObservationThe technique used to obtain the option policy can also beused to improve the value function without using options at all!
0
100
200
300
400
500
0 10 20 30 40 50
Ste
ps p
er e
piso
de
Episodes
Q-learningOptions after 20 eps
Experience replay at 20
Better baseline: just experience replay after 20 episodes
Nicholas K. Jong, Todd Hester, Peter Stone The Utility of Temporal Abstraction in Reinforcement Learning

MotivationExperimental Results
Summary
Learning with OptionsOptions and Random ExplorationOther Applications of Options
Options Can Degrade Learning Performance
Isolating the effect of hierarchyGive only subgoals (at start)Learn option policies online
Subgoals can degrade performance initially.Correct options can severely degrade performance!
0
1000
2000
3000
4000
5000
0 10 20 30 40 50
Ste
ps p
er e
piso
de
Episodes
Q-learningSubgoals from start
Nicholas K. Jong, Todd Hester, Peter Stone The Utility of Temporal Abstraction in Reinforcement Learning

MotivationExperimental Results
Summary
Learning with OptionsOptions and Random ExplorationOther Applications of Options
Options Can Degrade Learning Performance
Isolating the effect of hierarchyGive only subgoals (at start)Learn option policies online
Subgoals can degrade performance initially.Correct options can severely degrade performance!
0
1000
2000
3000
4000
5000
0 10 20 30 40 50
Ste
ps p
er e
piso
de
Episodes
Q-learningSubgoals from start
Options from start
Nicholas K. Jong, Todd Hester, Peter Stone The Utility of Temporal Abstraction in Reinforcement Learning

MotivationExperimental Results
Summary
Learning with OptionsOptions and Random ExplorationOther Applications of Options
Outline
1 Motivation: Hierarchical Reinforcement Learning
2 Experimental ResultsLearning with OptionsOptions and Random ExplorationOther Applications of Options
Nicholas K. Jong, Todd Hester, Peter Stone The Utility of Temporal Abstraction in Reinforcement Learning

MotivationExperimental Results
Summary
Learning with OptionsOptions and Random ExplorationOther Applications of Options
Options Change the Environment Structure
G
Random walk inoriginal environment
G
Random walk inaugmented environment
Nicholas K. Jong, Todd Hester, Peter Stone The Utility of Temporal Abstraction in Reinforcement Learning

MotivationExperimental Results
Summary
Learning with OptionsOptions and Random ExplorationOther Applications of Options
Restricting the Initiation Set
Idea: Limit options to certain statesRequires domain expertise
Initiation set of one option
0
200
400
600
800
1000
0 10 20 30 40 50
Ste
ps p
er e
piso
de
Episodes
Q-learningOptions
Nicholas K. Jong, Todd Hester, Peter Stone The Utility of Temporal Abstraction in Reinforcement Learning

MotivationExperimental Results
Summary
Learning with OptionsOptions and Random ExplorationOther Applications of Options
Restricting the Initiation Set
Idea: Limit options to certain statesRequires domain expertise
Initiation set of one option
0
200
400
600
800
1000
0 10 20 30 40 50
Ste
ps p
er e
piso
de
Episodes
Q-learningOptions
Limited options
Nicholas K. Jong, Todd Hester, Peter Stone The Utility of Temporal Abstraction in Reinforcement Learning

MotivationExperimental Results
Summary
Learning with OptionsOptions and Random ExplorationOther Applications of Options
Restricting the Initiation Set
Idea: Limit options to certain statesRequires domain expertise
Initiation set of one option
0
200
400
600
800
1000
0 10 20 30 40 50
Ste
ps p
er e
piso
de
Episodes
Q-learningOptions
Limited options
Nicholas K. Jong, Todd Hester, Peter Stone The Utility of Temporal Abstraction in Reinforcement Learning

MotivationExperimental Results
Summary
Learning with OptionsOptions and Random ExplorationOther Applications of Options
Delaying Option Deployment
Idea: wait until value function partially learnedSomewhat brittle
G
Value function on optiondeployment
0
200
400
600
800
1000
0 10 20 30 40 50
Ste
ps p
er e
piso
de
Episodes
Q-learningOptions
Nicholas K. Jong, Todd Hester, Peter Stone The Utility of Temporal Abstraction in Reinforcement Learning

MotivationExperimental Results
Summary
Learning with OptionsOptions and Random ExplorationOther Applications of Options
Delaying Option Deployment
Idea: wait until value function partially learnedSomewhat brittle
G
Value function on optiondeployment
0
200
400
600
800
1000
0 10 20 30 40 50
Ste
ps p
er e
piso
de
Episodes
Q-learningOptions
Delayed options
Nicholas K. Jong, Todd Hester, Peter Stone The Utility of Temporal Abstraction in Reinforcement Learning

MotivationExperimental Results
Summary
Learning with OptionsOptions and Random ExplorationOther Applications of Options
Delaying Option Deployment
Idea: wait until value function partially learnedSomewhat brittle
G
Value function on optiondeployment
0
200
400
600
800
1000
0 10 20 30 40 50
Ste
ps p
er e
piso
de
Episodes
Q-learningOptions
Delayed options
Nicholas K. Jong, Todd Hester, Peter Stone The Utility of Temporal Abstraction in Reinforcement Learning

MotivationExperimental Results
Summary
Learning with OptionsOptions and Random ExplorationOther Applications of Options
Outline
1 Motivation: Hierarchical Reinforcement Learning
2 Experimental ResultsLearning with OptionsOptions and Random ExplorationOther Applications of Options
Nicholas K. Jong, Todd Hester, Peter Stone The Utility of Temporal Abstraction in Reinforcement Learning

MotivationExperimental Results
Summary
Learning with OptionsOptions and Random ExplorationOther Applications of Options
Options and Optimistic Exploration
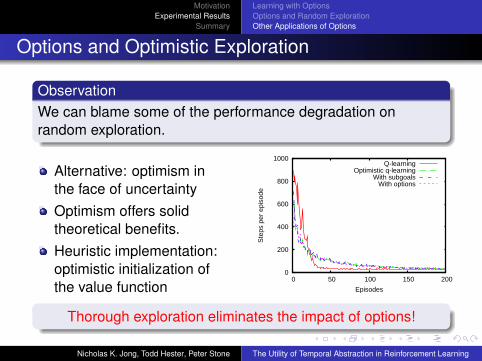
ObservationWe can blame some of the performance degradation onrandom exploration.
Alternative: optimism inthe face of uncertaintyOptimism offers solidtheoretical benefits.Heuristic implementation:optimistic initialization ofthe value function
Thorough exploration eliminates the impact of options!
Nicholas K. Jong, Todd Hester, Peter Stone The Utility of Temporal Abstraction in Reinforcement Learning
MotivationExperimental Results
Summary
Learning with OptionsOptions and Random ExplorationOther Applications of Options
Options and Optimistic Exploration
ObservationWe can blame some of the performance degradation onrandom exploration.
Alternative: optimism inthe face of uncertaintyOptimism offers solidtheoretical benefits.Heuristic implementation:optimistic initialization ofthe value function
0
200
400
600
800
1000
0 50 100 150 200
Ste
ps p
er e
piso
de
Episodes
Q-learningOptimistic q-learning
With subgoalsWith options
Thorough exploration eliminates the impact of options!
Nicholas K. Jong, Todd Hester, Peter Stone The Utility of Temporal Abstraction in Reinforcement Learning
MotivationExperimental Results
Summary
Learning with OptionsOptions and Random ExplorationOther Applications of Options
Options that Abstract Instead of Augment
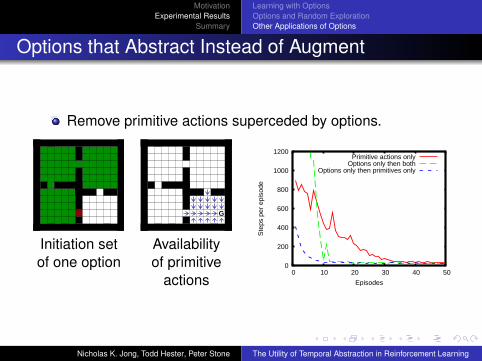
Remove primitive actions superceded by options.
G
Initiation set Availabilityof one option of primitive
actions 0
200
400
600
800
1000
1200
0 10 20 30 40 50
Ste
ps p
er e
piso
de
Episodes
Primitive actions onlyOptions only then both
Options only then primitives only
Nicholas K. Jong, Todd Hester, Peter Stone The Utility of Temporal Abstraction in Reinforcement Learning

MotivationExperimental Results
Summary
Learning with OptionsOptions and Random ExplorationOther Applications of Options
Temporal Abstraction in Other Algorithms
ObservationQ-learning may not be the best baseline algorithm for studyinghierarchy.
Q-learning uses each piece of experience exactly once.It therefore confounds data acquisition (exploration) withcomputatation (planning).
See alsoIn ICML 2008: Jong and Stone, “Hierarchical Model-BasedReinforcement Learning: R-MAX + MAXQ”
Nicholas K. Jong, Todd Hester, Peter Stone The Utility of Temporal Abstraction in Reinforcement Learning

MotivationExperimental Results
Summary
Summary
Options do not always help reinforcement learning; insome cases, they can severely hinder learning.Hierarchical methods impact learning by biasing orconstraining exploration.
Nicholas K. Jong, Todd Hester, Peter Stone The Utility of Temporal Abstraction in Reinforcement Learning