the (underestimated) role of product data for winning
TRANSCRIPT

IN DEGREE PROJECT INDUSTRIAL MANAGEMENT,SECOND CYCLE, 30 CREDITS
, STOCKHOLM SWEDEN 2020
The (underestimated) role of product data for winning online retail
JOHN BOLMGREN
HENRIK LINDSTRÖM
KTH ROYAL INSTITUTE OF TECHNOLOGYSCHOOL OF INDUSTRIAL ENGINEERING AND MANAGEMENT


The (underestimated) role of product data for winning
online retail
by
John Bolmgren Henrik Lindström
Master of Science Thesis TRITA-ITM-EX 2020:365
KTH Industrial Engineering and Management
Industrial Management
SE-100 44 STOCKHOLM

Den (underskattade) rollen av produktdata för att vinna e-handeln
av
John Bolmgren Henrik Lindström
Examensarbete TRITA-ITM-EX 2020:365
KTH Industriell teknik och management
Industriell ekonomi och organisation
SE-100 44 STOCKHOLM

Master of Science Thesis TRITA-ITM-EX 2020:365
The (underestimated) role of product data for winning online retail
John Bolmgren
Henrik Lindström
Approved
2020-06-15
Examiner
Lars Uppvall
Supervisor
Pernilla Ulfvengren
Commissioner
Contact person
Abstract
As E-commerce continues to take market share from traditional brick and mortar businesses, there are few choices left for managers apart from migrating their sales online. While the topic of online adoption has been studied extensively, this thesis attempts to investigate one of the major drivers of complexity within the industry - the role of structured product data. The study was performed on a major Nordic online retailer, and identified a set of six guiding propositions on the topic of structured product data in e-commerce from interviews with industry professionals. Contemporary data science literature contributes to the body of evidence suggesting a strategically prioritized focus on creating and maintaining structured product data is the way of the future for e-commerce, aligning with much of the interview results. Furthermore, the propositions were thoroughly examined through multiple linear regression analysis on data from the same firm. The study gives empirical support for significant positive impact on most studied metrics from having structured product data available on the website as well as within the internal systems, with slight discrepancies across product categories.
Key-words E-commerce, Product data, Structured product data

Examensarbete TRITA-ITM-EX 2020:365
Den (underskattade) rollen av produktdata för att vinna e-handeln
John Bolmgren
Henrik Lindström
Godkänt
2020-06-15
Examinator
Lars Uppvall
Handledare
Pernilla Ulfvengren
Uppdragsgivare
Kontaktperson
Sammanfattning
I takt med att e-handeln fortsätter att ta marknadsandelar från traditionella fysiska butiker finns det få alternativ för ledningsgrupper förutom att migrera sin försäljning online. Online-migrering som ämne har studerats i stor utsträckning tidigare, men denna uppsats försöker utforska en av huvuddrivarna till branschens komplexitet – rollen av strukturerad produktdata. Studien gjordes på en större nordisk e-handlare, och identifierade sex ledande teman inom ämnet för strukturerade produktdata i e-handel genom intervjuer med experter på bolaget. Kontemporär litteratur inom datavetenskapen bidrar till belägg för att ett strategiskt prioriterat fokus på att skapa och managera strukturerad produktdata är vägen framåt för e-handeln, vilket ligger i linje med resultaten från intervjuerna inom studien. Vidare analyserades de identifierade temana genom multipel linjär regression genom data från bolaget. Studien ger empiriska belägg för att strukturerad produktdata på e-handlarens hemsida samt i de interna systemen ger signifikant och positiv påverkan på de flesta responsvariabler, med vissa diskrepanser mellan produktkategorier.
Nyckelord E-commerce, Product data, Structured product data

Contents
1 Introduction 1
1.1 Scope and delimitations of the paper . . . . . . . . . . . . . . 3
1.2 Setting the stage for discussing e-commerce data . . . . . . . . 5
1.3 Research questions . . . . . . . . . . . . . . . . . . . . . . . . 7
2 Theoretical background 8
2.1 The current state of academic e-commerce literature . . . . . . 8
2.2 E-commerce from the perspective of Data Science . . . . . . . 11
2.2.1 Product data come in many shapes . . . . . . . . . . . 12
2.2.2 Towards the mighty concept of a structured product
catalogue . . . . . . . . . . . . . . . . . . . . . . . . . 13
2.2.3 The value proposition of structured product data . . . 15
2.3 Building a successful e-commerce business . . . . . . . . . . . 17
2.3.1 Critical success factors in E-commerce . . . . . . . . . 18
2.4 The different kinds of data affecting customer experience . . . 21
3 Method 22
3.1 Proposition analysis . . . . . . . . . . . . . . . . . . . . . . . . 22
i

3.1.1 Interviews . . . . . . . . . . . . . . . . . . . . . . . . . 23
3.2 Proposition validation . . . . . . . . . . . . . . . . . . . . . . 25
3.2.1 Multiple linear regression . . . . . . . . . . . . . . . . . 27
3.2.2 Data . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
3.2.3 Model specification . . . . . . . . . . . . . . . . . . . . 31
3.2.4 Validity of assumptions . . . . . . . . . . . . . . . . . . 33
3.3 Research ethics . . . . . . . . . . . . . . . . . . . . . . . . . . 35
4 Results 37
4.1 Proposition analysis . . . . . . . . . . . . . . . . . . . . . . . . 37
4.1.1 Structured vs. unstructured product data . . . . . . . 38
4.1.2 Structured data in online marketing . . . . . . . . . . . 40
4.1.3 Structured data in website design . . . . . . . . . . . . 46
4.1.4 Structured data in assortment curation . . . . . . . . . 48
4.1.5 Structured data in business intelligence . . . . . . . . . 49
4.1.6 Risks of working with structured data . . . . . . . . . . 50
4.2 The propositions . . . . . . . . . . . . . . . . . . . . . . . . . 51
4.3 Proposition validation . . . . . . . . . . . . . . . . . . . . . . 53
4.3.1 Data transformations . . . . . . . . . . . . . . . . . . . 54
4.3.2 Coefficients of interest . . . . . . . . . . . . . . . . . . 54
5 Discussion 60
5.1 Evaluating the propositions . . . . . . . . . . . . . . . . . . . 61
ii

5.1.1 Proposition 1: Structured product data, in contrast
to its unstructured counterpart, is significantly more
valuable in terms of its potential application in all parts
of the e-commerce value chain. . . . . . . . . . . . . . . 61
5.1.2 Proposition 2: Structured product data improves nav-
igation . . . . . . . . . . . . . . . . . . . . . . . . . . . 62
5.1.3 Proposition 3: Structured product data is crucial in
search engine optimization . . . . . . . . . . . . . . . . 64
5.1.4 Proposition 4: Optimizing product titles is important
for long-tail SEO, and structured product data makes
them seamless to create . . . . . . . . . . . . . . . . . 65
5.1.5 Proposition 5: High quality product images are impor-
tant for selling products online . . . . . . . . . . . . . . 66
5.1.6 Proposition 6: Structured data is highly valuable for
business intelligence and on-site curation . . . . . . . . 67
5.2 General implications of the results . . . . . . . . . . . . . . . . 68
5.2.1 Product catalogue creation . . . . . . . . . . . . . . . . 68
5.2.2 Toward a common product taxonomy . . . . . . . . . . 69
5.2.3 Critical success factors and their relation to product data 70
5.3 Limitations of the paper . . . . . . . . . . . . . . . . . . . . . 71
5.3.1 Proposition validation . . . . . . . . . . . . . . . . . . 72
5.3.2 Limitations of the proposition analysis . . . . . . . . . 75
5.3.3 Sustainability aspects of this paper . . . . . . . . . . . 75
5.4 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 76
A Appendix 82
iii

List of Figures
2.1 Illustration of structured vs. unstructured product page . . . . 13
2.2 Table of success factors from Varela et al. (2017) . . . . . . . . 19
3.1 Example QQ plot for the pageviews model of category bath . 34
4.1 Example of different types of searches . . . . . . . . . . . . . . 43
iv

List of Tables
4.1 Summary of the image count attribute regression coefficient
per category . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
4.2 Summary of the category specific attribute regression coeffi-
cient per category . . . . . . . . . . . . . . . . . . . . . . . . . 56
4.3 Summary of the base attribute regression coefficient per category 57
4.4 Summary of the standard attribute regression coefficient per
category . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
4.5 Summary of the dimensions attribute regression coefficient per
category . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
4.6 Summary of the title length attribute regression coefficient per
category . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
4.7 Summary of the description length attribute regression coeffi-
cient per category . . . . . . . . . . . . . . . . . . . . . . . . . 59
A.1 Regression table for category full . . . . . . . . . . . . . . . . 86
A.2 Regression table for category bath . . . . . . . . . . . . . . . . 90
A.3 Regression table for category construction . . . . . . . . . . . 94
A.4 Regression table for category floor . . . . . . . . . . . . . . . . 97
v

A.5 Regression table for category int . . . . . . . . . . . . . . . . . 102
A.6 Regression table for category kitchen . . . . . . . . . . . . . . 106
A.7 Regression table for category garden . . . . . . . . . . . . . . 110
vi

Chapter 1
Introduction
E-commerce has won tremendous ground in the past thirty years and its
growth has been accelerating even further in recent years. Today, there is
no debate on whether e-commerce will account for a significant share of the
consumer retail industry going forward, the question is rather how large that
share will ultimately become. Strong structural trends such as digitization,
online-adoption, demographic shifts and most recently the consequences of
the Covid-19 pandemic all support continued growth of the e-commerce in-
dustry. Amazon has become one of the world’s most valuable companies with
a significant part of its revenues attributable to its e-commerce business.
In light of these structural trends, many (if not most) brick-and-mortar busi-
nesses have been forced to adapt to the new market conditions by taking
their business online while new online-native businesses have entered the
market. The competition for consumers’ online spending has become fierce
and the dynamics have shifted significantly as retailers, search engine com-
1

panies, online aggregators and manufacturing companies all want their piece
of the seemingly ever-growing e-commerce sector. The tough competition
and rapid changes have triggered researchers to ask the question of how a
successful e-commerce business is built, what the key success factors are and
how technological developments can be leveraged in order to win over the
hearts and minds of online shoppers.
This paper asks the question of what role data generally, and product data
specifically, plays in the realm of e-commerce. When products are not on
physical display but presented through images, descriptions and attributes
and when stores are not visible from the street but accessed through specific
entries on a keyboard or smartphone - companies must adapt all parts of its
business, from marketing to purchasing, in order to find ways to survive and
thrive. In this study, we investigate how product data is used in all parts
of an e-commerce business, what role it plays, how it should be treated and
prioritized as well as how it relates to a company’s ability to prevail in a
harshly competitive landscape.
Since the theme of data specifically applied to e-commerce has not been
widely discussed, we approach the topic with an open mind and simply ask
the question of what role it plays in creating a successful online business.
This is done in the context of a case study involving interviews with several
industry professionals working at different functions in a large Nordic e-
commerce company, henceforth referred to as ”the Company”. This part
of the paper will henceforth be referred to as the ”proposition analysis”.
Insights and conclusions from the proposition analysis are then consolidated
to form a set of propositions about the role and significance of data in e-
2

commerce that are further investigated and benchmarked against previous
research and tested using statistical methods on company data.
1.1 Scope and delimitations of the paper
For purposes of clarity we begin by giving a definition of how we define
e-commerce. A general definition was proposed by Frost et al. (2018): “E-
commerce refers to the online transactions: selling goods and services on the
internet, either in one transaction (e.g., Amazon, Zappos, Ebay, Expedia) or
through an ongoing transaction (e.g., Netflix, Match.com, Linkedin etc.)”.
Given that this paper focuses on the trade of physical goods over the internet,
we narrow the definition used in this study to: E-commerce refers to the
transaction of physical goods over the internet.
We will also clarify what we mean by data. There are many different kinds of
data in the e-commerce space. The different kinds of data are collected and
used for different purposes and while some of the data can be seen as generic
for all businesses, sales data being the obvious example, other kinds of data
exist more or less uniquely in the e-commerce sector. Akter and Wamba
(2016) divides e-commerce data into four categories:
(a) Transactional data
(b) Click-stream data
(c) Data in the form of video
(d) Voice data
3

Yet again, given our narrowed scope for this paper and the subsequent defi-
nitional difference on the term E-commerce, only the first two types in Akter
and Wamba (2016) categorization applies to our definition in a meaningful
way. We suggest a different approach to the classification of data types based
on the source of the collected data as follows:
(a) Transactional data: Refers to data collected from transactions with
the customer. This data type includes sales, profitability, pricing and
return rates to name a few.
(b) Behavioural data: Refers to data collected from the customers’ online
behaviour and interactions with the e-commerce platform. This data
type includes conversion rates, site visits, session lengths and points of
entrance among others.
(c) Logistical data: Refers to data collected from the process of shipping
products to customers. This data type includes delivery times, delivery
methods, stock levels etc.
(d) Product data: Refers to data collected from the products themselves.
This type of data includes product features, images, titles and descrip-
tions.
The focus of this paper going forward will be mainly on the impact of product
data.
4

1.2 Setting the stage for discussing e-commerce
data
For purposes of clarity, some key concepts are defined as they relate to e-
commerce websites. While they are not commonly used in the literature on
e-commerce, these concepts play an integral role in understanding the role
of product data and will be referred to throughout this paper.
• Home page: The home page is the webpage that a customer is di-
rected to if they enter the store using only the website’s domain without
additions. Commonly, the home page in the e-commerce context is the
first point of contact with the customer and can be used to browse
the website’s assortment. A real-life analogy is to the entrance of a
large mall where a visitor is guided by signs to the appropriate store
or department.
• Landing page: Landing pages display several products within the
same category or with other kinds of similarities. These pages are often
used as interstages between the home page and the product page. Here,
customers can browse through a subset of the website’s assortment,
often with the help of filters. A real-life analogy is to the entrance of a
store within the mall that sells a specific kind of product.
• Product page: The product page is where the customer can make
the actual purchase of a product. The product page is dedicated to a
specific product and contains information and images relating to that
product.
5

This paper makes use of both qualitative and quantitative methods of study
in order to answer the research questions (see section 1.3). Firstly a propo-
sition analysis was conducted as a case study of a large Nordic e-commerce
company - as proposed by Baxter and Jack (2008). Interviews were con-
ducted with the aim of deriving propositions from leading professionals at the
company relating to product data and its role in e-commerce. Furthermore,
a rigorous exploration of current literature on the subject was conducted to
give perspective to the data gathered from the proposition analysis. Given
these propositions (see below), proposition validation was dedicated towards
testing their legitimacy in the context of this specific company in the form of
a quantitative analysis on company data (see section 4.3). While we recognize
that a single company cannot be used as a generalization for the industry as
a whole, since it is bound by its specific circumstances, we consider the com-
pany a good subject for study given its presence in many different product
categories as well as its size and market share. The conclusions might not
be upheld in the general case, especially the conclusions from quantitative
analysis drawn from company data, however we will try to argue as gener-
ally as possible since it is the sense of the authors that the assumptions laid
out in the hypotheses are broadly considered to be true, even outside of the
Company and their subsidiaries.
For reference, the following propositions were extracted from the proposition
analysis, and are elaborated on in section 4.1:
• Proposition 1: Structured product data, in contrast to its unstructured
counterpart, is significantly more valuable in terms of its potential ap-
plication in all parts of the e-commerce value chain
6

• Proposition 2: Structured product data improve navigation
• Proposition 3: Structured product data is crucial in search engine op-
timization
• Proposition 4: Optimizing product titles is very important for long-tail
SEO, and structured product data makes them seamless to create
• Proposition 5: High quality product images are important for selling
products online
• Proposition 6: Structured data is highly valuable for business intelli-
gence and on-site curation
1.3 Research questions
The following research questions are proposed for the study, and are inti-
mately linked to the identified propositions:
1. What role do online retailers place on structured product data?
2. How well does the online retailers’ appreciation of structured product
data align with measurable outcomes?
7

Chapter 2
Theoretical background
The purpose of Chapter 2 is to give the reader an introduction to contempo-
rary academic literature in the field of e-commerce in general, and product
data for the former in particular. Furthermore, this chapter provides a crit-
ical academic reference for discussing the identified propositions defined in
section 4.1. Given that the interviews that were conducted within the study
were confined to a single company, this literature review is deemed necessary
in indicating whether the findings from the proposition identification have
the potential of being considered valid also in the generalized case.
2.1 The current state of academic e-commerce
literature
The role of data in e-commerce has been studied from multiple perspectives.
Little has been written in the field of management on the necessity of placing
8

data at the heart of every e-commerce business. A surprising fact given that
daily operations in these businesses has data management as a core struggle,
taking up the vast majority of all operational activities. However, a lot has
been written from a technological perspective ranging from the potential
analytical values that could be extracted from e-commerce data to the field
of data science that have extensively studied methods for mining, deploying
and enriching product data as well as the potential of that same data for
search engine- and UX applications.
From the perspective of business and management the topic has mainly been
approached by more generally studying critical success factors in e-commerce
and also the potential of Big Data Analysis (BDA) in the e-commerce setting
given its native stance as an industry with great access to many kinds of
data in tremendous volumes. An extensive positional paper on the current
stance of research on BDA in e-commerce is offered by Akter and Wamba
(2016) from which we have drawn several references for this paper. The
overall conclusion from the study of BDA-applications in e-commerce is nicely
summed up by Loebbecke and Picot (2015) as “the platform for growth of
employment, increased productivity, and increased consumer surplus”.
The data science field has approached the topic of data in e-commerce from
a more practical standpoint. The value of having high quality data is seen as
axiomatic and much of the research is centered around how data on product
specifications, reviews and prices can be mined, structured and leveraged
to fit applications such as search engine optimization, product catalogue
creation and product matching. The topic of product feature extraction
from unstructured data sources online has made significant progress in recent
9

years and the most successful methods from the area are summarized by Rao
and Sashikuma (2016). Methods for solving the not at all trivial problem
of matching identical products from different sources has been proposed by
Ristoski et al. (2018) and a method for synthesizing product catalogues from
unstructured data sources was given by Ristoski et al. (2018).
The common theme of the data science papers on e-commerce data has been
that proposed applications are rarely aimed at the e-tailers themselves, but
rather in favour of platform-type applications such as product search engines
and other recommendation engines for consumer use. This approach is taken
by Nguyen et al. (2011) who describes a method for synthesizing products for
online catalogues using novel methods in computer science with the explicit
aim of developing methods for creating generalized product catalogues that
draw data from many e-commerce websites with the aim of consolidation.
On the same general topic, Ristoski et al. (2018) lay out a method for both
categorization of products and matching of products using neural language
models and deep learning. The paper mentions Google Product Search ex-
plicitly as a target use-case for their methods, but implicitly makes the same
assumption as Nguyen et al. (2011), namely that e-commerce companies have
already solved the problem of data quality and reliability internally and that
the next natural step in the data-accessibility-value-chain is democratizing
the data through consolidation of data from all e-commerce actors.
The aim of the following sections in the literature review is to provide
an overview of recent academic efforts adjacent to the topic of data in e-
commerce. Publications in the field are dominated by data science papers
which we will try and summarize in understandable language for those not
10

versed in the field. The key point is to stress two important facts that become
evident from the literature:
1. There is a vibrant discussion in the data science community on meth-
ods for, and applications of, e-commerce data driven and financed not
primarily by the e-commerce sector but by the technology giants and
search engine companies. The value of structured product data is ax-
iomatic and much of the research rests on the assumption that high
quality data is already “out-there” and the problem to be solved thus
becomes 1) collecting the data, and 2) structuring the collected data.
2. Regardless which field of study we turn to, there is little emphasis on the
value of data for the e-commerce companies themselves. Very little is
written on topics such as management priorities, operational challenges
and marketing opportunities in e-commerce in general. Particularly,
none of that research has the same axiomatic conviction on the value
of data that permeate the data science community.
2.2 E-commerce from the perspective of Data
Science
Sticking to our categorization of e-commerce data it becomes evident that
the focus of data science research is on product data. Keep in mind that
much of this research is aimed at finding solutions for consolidated product
databases such as price comparison sites and product search engines, or to
steal an expression from Krys and Bagheri (2016): the research is set on
11

finding solutions for “online aggregators”. The interest in product data has
emerged as the growth of e-commerce has continued to accelerate (Nguyen
et al., 2011). We will focus this part of the literature review to text form
data, meaning that media is left for a later part of the discussion.
2.2.1 Product data come in many shapes
An important distinction that is often made in the data science commu-
nity (but rarely if ever made in the business community) in terms of e-
commerce data is whether a set of data is unstructured, semi-structured or
structured (Rao and Sashikuma, 2016). Unstructured data is difficult to use
in its original form for applications ranging from BDA (Kang et al., 2003) to
search engine optimization and product catalogue creation (Nguyen et al.,
2011). Nguyen et al. (2011) conclude on the topic of structured data that
”This structured data is fundamental to drive the user experience: it en-
ables faceted search, comparison of products based on their specifications,
and ranking of products based on their attributes.”. To shed some light on
the distinction between structured and unstructured data we refer the reader
to Figure 3.1. In the case of the unstructured product page the data is in
free-text format and even though the reader can get a sense of the product,
the ability to leverage this data is very limited for most applications. A basic
example relates to on-site-navigation: if there is no product level structured
data, then there is no possibility to create filtering functionality that the user
can apply to find relevant results among large assortments of products. Other
examples can be applying AI/ML-algorithms to unstructured data generally
yields inferior results compared to structured data (Shimada and Endo, 2005)
12

Figure 2.1: Illustration of structured vs. unstructured product page
and the ability to generate relevant search results is significantly improved
by searching in a structured database compared to an unstructured (Duan
et al., 2013).
The important distinction between the different kinds of product data and
consequently the necessity of structured data, preferably in the form of key-
value-pairs (i.e. a key along with a connected value, where “Color” is an
example of a key associated with the value “Blue”) has emerged as an integral
component for achieving better customer experience (Ristoski et al., 2018)
as well as improved search performance (Nguyen et al., 2011).
2.2.2 Towards the mighty concept of a structured prod-
uct catalogue
As such, the task of the data science research in the area can be thought of
as three-fold, remembering it’s desired application for “online aggregators”:
1) Collect the (unstructured or structured according to unknown structure)
13

raw data from publicly available online sources on the web. 2) Make the
unstructured data structured by a) categorizing the products along a prede-
fined “category-tree” and b) extract key-value-pairs according to a predefined
schema of keys associated with the chosen category from the unstructured
product data. 3) Aggregate the products into a product catalogue. (Rao and
Sashikuma, 2016). Several methods have been proposed for achieving these
three tasks including web-mining via crawler-scripts for collection, regular
expressions and/or machine learning for structuring data and finally other
machine learning methods and feature comparison for aggregation. Worth
noting is that all of the efforts in this area are done with the objective of
building fully automated systems for achieving all of the steps above.
In light of this paper, where emphasis lies on the e-commerce sector, repre-
senting the data source for this field of research, the same three-fold process
can be successfully applied if the data source in 1) is exchanged to the e-tailers
supplier. Effectively moving the whole process one step backward in what
can be thought of as the “data-supply-chain” or “layers of data consolida-
tion”. Here it should be recognized that many suppliers of the retail industry
in general and the e-commerce sector in particular haven’t got sophisticated
websites making the full set of raw data publicly available. However, substi-
tuting a supplier website to a supplier product database and the comparison
still holds true. Efforts has been made to use supplier websites as the source
of raw data, though to a significantly lesser extent then using the e-commerce
websites directly (Walther et al., 2010).
Given the similarities in approaches for the data-supply-chain between the
use cases it is relevant to adress some key challenges faced by the data science
14

community adjacent to these tasks. Rao and Sashikuma (2016) describe the
major hurdles in structuring data faced by researchers. These include the
volatility of the source data (i.e. the e-commerce websites), the challenge
with different data formats from different sources (i.e. structured tabular
formats vs. unstructured text formats) and the incompleteness of the source
data with regard to the target schema och keys. It is not far fetched to
assume that e-commerce companies face similar challenges in their relation
towards their suppliers.
2.2.3 The value proposition of structured product data
To conclude the review on data science progress in this field we’ll address the
topic of value-creation to try and answer why working toward complete and
structured data is important for e-commerce actors and “online-aggregators”
alike.
Considering the main objective of the research, that is, creating a structured
product catalogue, Nguyen et al. (2011) says ”The product catalog is to
online shopping what the Web index is to Web search” and elaborates by
”[...] structured data is fundamental to drive the user experience: it enables
faceted search, comparison of products based on their specifications, and
ranking of products based on their attributes.”. Thus Nguyen et al. (2011)
regards structured data as an important enabler for a wide range of further
applications. Petrovski and Bizer (2017) make a similar analysis and argues
”The central challenge for many tasks within the domain of e-commerce, in-
cluding product matching, product categorization, faceted product search,
and product recommendation, is extracting attribute-value pairs with high
15

precision from unstructured product descriptions or semi-structured prod-
uct specifications.”. Ristoski et al. (2018) takes the perspective of the e-
commerce customer and argues that as the aggregated online assortment of
products has expanded it has become increasingly difficult for customers to
find and compare products online. Investigating the cause of this experi-
enced hardship on the part of the customer, Ristoski et al. (2018) find that
the majority of products for sale online is presented only in terms of a ti-
tle and description, meaning that unstructured product data dominate the
online retail environment. Looking at e-commerce websites input feeds of
product information, where target schemas for “online aggregators” product
catalogues are clearly stated, the authors find that the data is often incom-
plete in comparison to the input schema - making the search performance of
those products orders of magnitude less effective than products fulfilling the
schema requirements. Staying in the customer perspective, Walther et al.
(2010) argues that structured product specification are the most valuable
data for the online consumer as it creates a comprehensive understanding of
the product and allows comparison with other similar products.
We have briefly addressed the underlying assumption of completeness in the
data that is prerequisite for the success of aggregation systems of product
data. To fully address the problems of the assumption we turn to Walther
et al. (2010) who’s thesis is built on using supplier websites as source for raw
data collection given the flawedness in e-commerce data. On e-commerce
data they argue that “The information in individual online shops is restricted
to only the sold products and often error prone and not comprehensive”
and drive the thesis that supplier data is in contrast “complete, correct and
16

up-to-date”. Along with Rao and Sashikuma (2016) identification of data
incompleteness as a core obstacle in the journey towards building compre-
hensive product catalogues, we conclude that e-commerce website cannot be
considered a reliable source of complete product information.
Lastly, the value of complete and structured data is evident in terms of ma-
chine learning applications. Having incomplete data generates substantially
weaker classifiers in from ML-algorithms (Shimada and Endo, 2005) and
structured data works better in creating strong ML-based systems than it’s
unstructured counterpart.
2.3 Building a successful e-commerce busi-
ness
Given the technological developments in recent decades, many businesses
have had to rethink traditional ways of conducting commerce and adopt
their business to emerging technologies. Online commerce has been one such
example where, particularly brick-and-mortar retail businesses, have been
forced to go online to stay competitive in a new market environment. Given
these developments, transitioning business online and adapting them to the
digital era has become a major research area. E-commerce in particular has
been the target for much of this research to address the challenges companies
face during this transition.
Transitioning brick-and mortar business online appears to be easy. However,
constructing a profitable online based model including everything from prod-
17

uct presentation to fulfillment of logistical promises and after-sale activities
is evidently a big challenge (Atchariyachanvanich et al., 2008). While the
online supply of products and destinations where they can be purchased has
grown tremendously in the past decade, E-commerce has not evolved at the
same rate in quality and the possibility of setting up an online store without
huge initial investments has driven many without domain knowledge to in-
vest in this area (Varela et al., 2017). The strong trend of internet adoption
on part of the consumer has forced companies online rapidly in order for
them to stay relevant, but winning online takes more than presence and as
the competition has grown stronger, the need for domain knowledge to create
competitive advantages has become painfully evident for market participants.
2.3.1 Critical success factors in E-commerce
Varela et al. (2017) summarize the research on success factors for e-commerce
companies and find that the mainstream of the studies identify five categories
that need addressing to stay competitive online: technology acceptance fac-
tors, social factors, cognitive factors, ethical factors and environmental fac-
tors. Technology acceptance factors aside, the critical success factors relate
to organizational challenges that emerge from the effort of transitioning a
business from offline to online as well as behavioural challenges in getting
the consumers to adapt to online purchasing. Breaking down the larger
themes laid out by the categories, Varela et al. (2017) suggest twelve critical
success factors that must be addressed for building a successful e-commerce
website. These are presented in Figure 2.2.
While the success factors are often discussed in general terms in the littera-
18

Figure 2.2: Table of success factors from Varela et al. (2017)
19

ture without touching the topic of key enablers for the different dimensions
of building a website some have touched upon the topic of data complete-
ness and quality. Burgess and Karanasios (2008) and Cebi (2013) identify
information quality as a main factor in building a competitive e-commerce
business and Chaudhuri et al. (2019) argue that ”In e-commerce, content
quality of the product catalog plays a key role in delivering a satisfactory
experience to the customers”. The most widely discussed factor relates to
website usability and Varela et al. (2017) discuss on-site navigation as a crit-
ical problem in terms of usability. Moreover, the aspect of trust has been
discussed at length within this research area as it relates to both social and
ethical success factors (Lee and Lin, 2005), (Machado, 2011). Trust is im-
portant in every aspect of e-commerce, from describing products objectively
and honestly to practicing solid privacy policies (Ngai, 2003).
Other examples of research on the topic that has been done on a higher level
of abstractions is provided by Choshin and Ghaffari (2017) who investigate
important factors for small- and medium-sized companies in creating online
businesses and finds statistical proof for customer satisfaction, cost, techno-
logical infrastructure and customer awareness and knowledge being integral
factors for success. Furthermore, Nisar and Prabhakar (2017) find perceived
value, customer expectations, perceived quality and loyalty to be important.
To summarize, the research done in the realm of business and management
has accurately depicted the broad strokes of the many factors that are nec-
essary to keep in mind when pursuing the e-commerce space. However, the
field has yet to discuss the connection between these general factors and the
underlying data that is needed to support many of them.
20

2.4 The different kinds of data affecting cus-
tomer experience
So far in our discussion on e-commerce in general and the aspect of data in
particular, we have focused on data in textual format. An important note
is that selling products online demands complementing data for ensuring a
good customer experience. Product pages today contain reviews, comments,
images and videos along with the textual product data which all contribute
to the customer experience. The impact of these different forms of product
data on how a product is perceived online has been discussed individually.
Chaudhuri et al. (2019) discuss the impact of product images and argue that
”Images play a key role in influencing the quality of customer experience and
the customers’ decision-making path in e-commerce transactions. Images
provide detailed product information that helps the customer build confi-
dence in the product quality and fulfillment promises.” and further argue
that bad or incorrect images can have a significant negative impact on the
customers willingness to purchase a product online.
Similar studies have been made on the impact of product reviews by for ex-
ample Singh et al. (2017) and Wan et al. (2018). We want to highlight that
complete and structured data goes beyond the realm of textual data and end
on an important point made by Chaudhuri et al. (2019): “Human errors in
compiling product information and limitations of software systems severely
hinder the ability to provide a homogeneous content experience across cate-
gories to the customer.”
21

Chapter 3
Method
This chapter aims to give the reader an understanding of the methodology
used, and methods applied, when conducting the study. On the highest
level, a qualitative method using a case study approach was used in order to
evaluate the first research question: what role does an online retailer place
on structured product data? The findings from this analysis resulted in a set
of six key propositions. These propositions were used as input for a validity
analysis in the form of a multiple linear regression model, where data from the
subject company was used in an attempt to validate each of the propositions.
3.1 Proposition analysis
The proposition analysis is structured as a single case study with embedded
units as described by Baxter and Jack (2008). In this case, the embedded
units are the subsidiaries of the Company, and the analysis will largely be
22

considered a cross-case analysis. The results of the interviews are analyzed
and consolidated to a set of propositions, in this methodological context they
can directly be related to the propositions in the case study framework put
forward by Yin (2003). The design choice of linking data to propositions has
been decided in order to create a solid foundation for the latter part of the
study. The use of pattern matching Yin (2003) is deemed appropriate in order
to determine patterns observed from individuals close to, or within, the data
management teams at the Company and its subsidiaries. This would require
interviews as the main data collection method, which will be discussed in
greater detail below (Yin, 2003).
The proposition analysis encompassed 15 exploratory interviews with em-
ployees and management at a large Nordic e-commerce company. The main
purpose of this analysis was to gain insights into the role of data in e-
commerce. This was done by identifying themes where the importance of
data is prevalent, these themes then acted as input to the proposition vali-
dation analysis. The interviews were conducted in January and February of
2020.
3.1.1 Interviews
The guiding question of the role of data in e-commerce will be analysed
through interviews using a qualitative lens as outlined by Creswell (2009).
The process can, in short, be described in the following steps:
1. Collecting raw data (transcripts, notes etc.)
2. Organizing and preparing data for analysis
23

3. Reading through the data
4. Coding the data
5. Identify themes and descriptions for themes
6. Interrelating themes/descriptions
7. Interpretation
8. Validating accuracy of information (through cross-validation)
The interviews serve the main purpose of acting as input data for the formu-
lation of the propositions. The interviews were semi-structured in the sense
that they related to the guiding theme, while allowing the interviewees the
freedom to potentially add propositions of their own, which may or may not
be included in an extended scope.
The interviews were conducted in ten separate sessions either in person or
via video-conference. Interviewees were picked from multiple organizational
levels and categorized by organizational functions are listed below:
• Management
– Chief Operating Officer
– Head of Business Development & Strategic Projects
• Merchandising
– Head of Merchandising
– Merchandiser (x2)
• Product management
24

– Senior Category manager
– Junior Category manager (x2)
• Online marketing
– Head of online marketing
– Online marketing specialist (x2)
• Business controlling
– Controller (x2)
• Content & marketing
– Content curator (x2)
3.2 Proposition validation
The following propositions (refer to section 4.2) were deemed appropriate for
a quantitative analysis given the data available: Proposition 1, Proposition
2, Proposition 3, Proposition 4, Proposition 5. These propositions crucially
relate to tangible response variables in the form of internal traffic, external
traffic and quantity of orders. These response variables are described below.
The focus of the proposition validation lies in conducting a quantitative anal-
ysis of the propositions from section 4.1 in order to evaluate their legitimacy
connected to actual sales and product data within the scope of the specific
company. Note, again, that this single company is not to be used as a direct
generalization, but is considered an adequate subject for the scope of the the
25

study as a whole.
• Quantity of orders, in the models denoted as ”quantity”, is defined as
the number of orders placed from a single product page. This response
facilitates the evaluation of propositions 1, 2 and 5, as we can evaluate
the impact that our meta-attributes and images has directly on sales.
• External traffic, in the models denoted as ”sessions”, is defined as the
number of times a user has started their session on the e-commerce
website on a specific product page. That is, a session is only counted
where the user enters the e-commerce website from an external link on
e.g. a search engine. This response variable is thus suited to quantify
the external traffic that a single product page generates. This response
facilitates the evaluation of propositions 3 and 4, as we can evaluate
the impact of our chosen meta-attributes and the product title on the
external traffic that they generate.
• Internal traffic, in the models denoted as ”pageviews”, is defined as the
number of times any user has visited a product page, but not started
their session on that specific product page. This response variable is
thus suited to quantify the internal traffic that a single product page
generates. This response facilitates the evaluation of propositions 1
and 2, as we can evaluate the impact of our chosen meta-attributes on
the internal traffic that they generate.
The only proposition left out of the quantitative analysis is thus Proposition
6. This proposition captures the value of structured data on business intel-
ligence, and the benefits of exploiting such assets are not as direct as with
26

the former propositions.
3.2.1 Multiple linear regression
In order to evaluate how rich and structured data on product features is a
driver of online sales and traffic, a multiple linear regression model is proposed
as it is widely used for this kind of problem (see e.g. Ye, Law, Gu 2009).
This method of analysis allows us to not only evaluate whether there is a
significant impact on sales, but also to control for differing product/retailer
contexts in the analysis.
The full quantitative analysis will be made on the aforementioned response
variables on the company subject to study. The analysis consists of differ-
ent product categories which will be the main analysis in investigating the
legitimacy of propositions 1-5, but will also strengthen our analysis towards
a generalized conclusion. Data for the analysis will be made available to us
by the company and will be drawn from internal ERP-systems, PIM-systems
as well as from Google Analytics.
As mentioned, there are three response variables of interest. Each of the
response variables are to be modelled individually:
1. Number of visits to the product page from external links
2. Number of visits to the product page from internal links
3. Quantity of orders on a product page
These variables were modelled using essentially the same predictors where
the predictors were different measures of the data quality of the product page
27

in question. These measures included (but were not limited to): quality of
product title, length and quality of product description, number and type of
product attributes, number of high quality images and classification of the
product. The construction of the model and the choice of predictors has
been careful and deliberate, drawing from the interviews with industry pro-
fessionals from the proposition analysis as well as the theoretical background
in Chapter 2. Furthermore, a number of control variables that are well es-
tablished to correlate with the responses were used in order to limit model
variance.
In summary, the multiple linear regression model will not try to predict sales
or traffic, since we are aware that the aspect of product data is only one theme
among many that impact these variables. Instead, we want to investigates
the aspect of product data as it relates to sales and online traffic to see 1)
whether they have a significant role in predicting how well a product sells
online and thus further validate the propositions, and 2) how big of an impact
the different aspects have individually and in relation to one another.
3.2.2 Data
This section mainly aims to describe the quantitative data collected through
the Company’s various databases, but will also give a brief discussion on the
format of the interviews conducted.
For the data compiled from the Company’s internal databases, the chosen
time span ranges over two years - from 2018-01-01 through 2019-12-31.
28

Product data
The product data set is compiled from multiple exports from the Company’s
own PIM (product information management) system. The complete data set
contains all the relevant information on the SKU (stock keeping unit) level of
the product that is presented on the website. This is crucial for the analysis,
as we can utilize the category groupings on multiple levels to infer different
rules in the analysis.
A full list of parameters used in the models of analysis will be provided in
the appropriate section.
Sales data
The sales data is collected from the Company’s ERP (Enterprise resource
planning) system. In practice, the data describes the sales on SKU level,
both in terms of total revenue and number of SKU sold.
Traffic data
The traffic data set is generated from the Google Analytics platform, and
provides us with information on page hits, the customers’ journeys through
the website and conversion rates on the level of web pages. I.e., we can utilize
this data to track where the visitor entered the site, and how the journey
towards a specific product is conducted in order to model the importance of
certain data features.
29

Product attribute metadata
The product attribute metadata data set is a consolidated set on the product
data, where we define units of analysis relevant to the propositions. Firstly,
the key objective is to find measures indicating to what extent the products
have structured product data. Our approach is to consolidate the data in
different groupings, and count have many structured data points are present
for the different products in the data set. Secondly, we want to measure other
aspects of the data in one way or the other relating to the propositions. We
try to find measures for the quality of the product titles and to what extent
the underlying structured data have been leveraged in their creation and also
seek measures for images and descriptions. The following set of metadata
attributes have been carefully selected:
• Number of populated base attributes
– These attributes include, but are not limited to: product brand,
method of delivery, country of origin and unit type
• Number of populated standard attributes
– These attributes include, but are not limited to: design series,
material and model number
• Number of populated Dimensions attributes
• Number of populated category specific attributes
• Number of high-quality images on the product page
• The length of the product description (number of words)
30

• Whether or not the following attributes are present in the title:
– Design series
– Colour
– Brand
– Material
• Number of available colour attributes
• Length of the product title when adjusted for automated title creation
3.2.3 Model specification
From the reasoning above, the following multiple linear regression equations
are proposed for each category c:
log(pageviewsc,i) = βc,0 + βTc xc,i + εi (3.1)
log(sessionsc,i) = βc,0 + βTc xc,i + εi (3.2)
log(quantityc,i) = βc,0 + βT
c xc,i + εi (3.3)
For the models specified in equations 3.1 and 3.2, the vector of regressors is
31

defined as:
xc,i =
basec,i
standardc,i
dimensionsc,i
imagecountc,i
categorySpecificc,i
shortDescriptionc,i
longDescriptionc,i
intitleSeriesc,i
intitleMaterialc,i
colourc,i
log(averagePricec,i)
adjustedT itlec,i
log(averagePricec,i) × longDescc,i
log(averagePricec,i) × imagecountc,i
log(averagePricec,i) × adjustedtitlec,i
(3.4)
where the vector βc is then simply the corresponding coefficient vector for
the regressor vector xc,i. For equation 3.3, the vector of regressors xc,i is
identical to xc,i, but appended with an interaction term with the delivery
time deliveryc,i, pageviewsc,i as well as an interaction term between delivery
and log(averagePrice).
32

3.2.4 Validity of assumptions
Homoscedasticity
One key assumption of the multiple linear regression model is the homoscedas-
ticity assumption – that the error terms of the regression have a constant vari-
ance across the sample. To ensure that the model yielded no heteroskedastic
error terms, quantile-quantile plots were evaluated for each model. Figure 3.1
illustrates an example for the bath category. To ensure homoscedasticity,
the empirical and theoretical quantiles should match as closely as possible,
as shown in the figure.
In order to achieve homoscedastic error terms, however, the response vari-
ables had to be log-transformed in all cases. This is a common transformation
technique used for this type of problem.
Multicollinearity
While the existence of multicollinearity in the model is only a violation of the
model assumptions in the case of perfect multicollinearity, high levels can still
cause some issues. A common approach to detect potential multicollinearity
in the model is to utilize the variance inflation factor (vif). Each of the models
run were checked using vif, resulting in no highly correlated regressors – with
the exception of the interaction terms, which should be expected.
Omitted variable bias
One crucial point in the estimations of the regression models is the issue of
omitted variable bias. For a model to be biased through omitted variables,
33

Figure 3.1: Example QQ plot for the pageviews model of category bath
two conditions must hold:
xi is correlated with the omitted variable xo for some i
xo is a determinant of the response variable y
In the construction of the models, significant care was taken in order to
reduce the risk of bias from omitted variables. Since the models are not
aimed to be predictive by construction, this issue is largely simplified.
34

3.3 Research ethics
The study was conducted with great regard to current research ethical con-
siderations. Specifically, the study utilized the four principles for ethical re-
search proposed by the Swedish Research Council (Vetenskapsradet, 2002).
These four principles, or criteria, are presented below and discussed in rela-
tion to the study.
The criterion of information states that the researcher shall inform the peo-
ple included in the study about its aim. Specifically, the researcher shall
inform them about their role in the study, that participation is optional and
the terms which are at play. In order to accommodate for this set of rules,
all interviewees were asked whether or not they wanted to participate in the
study, leaving full disclosure of the terms of personal anonymity. The in-
terviewees were also informed of the aim of the study either via e-mail, a
workplace instant messaging application or verbally. All interviewees com-
plied in full.
The criterion of consent states that any participant in a study has the right
to control their own contribution. That is, the researcher shall collect the
participant’s consent (and possibly the consent of a legal guardian). Fur-
thermore, the participant has the right to independently decide the terms of
their involvement and be able to abort their involvement without any neg-
ative consequences. Finally, the participant shall not be the subject of any
undue pressure. As stated previously, consent was collected from every in-
terviewee in the study, and they were informed that they should only convey
information that they deem appropriate for sharing. Furthermore, as the
35

interviews were recorded, consent was asked for (and approved) before the
start of each interview.
The criterion of confidentiality concerns information about the research par-
ticipants. Any information on the participants shall be given as much con-
fidentiality as possible, and any personal data shall be stored so that none
other than the researcher has access to them. During the interview process,
no personal data was stored in the transcripts except the first name and func-
tion of the participant. The first name was collected in order to facilitate
discussions between the authors. When presenting findings, the intervie-
wees were simply referred to by their function at the Company. While some
of the employee functions only employ a few people, leaving the Company
anonymous throughout the thesis aids in keeping confidentiality.
The criterion of good use states that any information collected on single
participants shall only be used for the purpose of research. In the study, no
data was passed on from the researchers to any function of the Company
apart from the finished thesis. This means that the interview transcripts
were only seen by the authors, and any information relating directly to a
participant was thus ensured not to be used for other purposes.
36

Chapter 4
Results
4.1 Proposition analysis
The overall aim of the proposition analysis was to explore the topic of prod-
uct data, its application and potential, in e-commerce with an open mind.
In the pursuit of achieving an understanding as complete as possible we in-
terviewed people in most parts of the organization and let them explain their
thoughts and daily struggles relating to product data. A high-level take away
that became evident from our sessions was that the value ascribed to data
differed significantly between people from different organizational functions
which we will explore further below. In terms of structure, we present our
findings under six headlines representing the most common themes discussed
in the interviews. Moreover, all of the interviewees were in agreement when
discussing the value of product images with the message that images are in-
tegral for successfully selling products online. As such, the findings below
37

refer to textual product data.
4.1.1 Structured vs. unstructured product data
It is evident that product data cannot be discussed without making the
initial distinctions between unstructured and structured data. The terms
are assigned by the authors with inspiration from data science literature but
were referred to in the interviews as “tabular data” instead of structured,
and “free text data” instead of unstructured. The consensus from all parts
of the organization was that structured data is preferable given the many
applications in the e-commerce value-chain. However, there is a significant
trade-off between working towards structured data formatting and the cost
of pursuing that structured data (in terms of time, effort and quality).
The teams working with assortment onboarding, including category man-
agers with the responsibility for supplier relations, pricing and marketing
within categories and merchandisers with responsibility for data curation,
both stressed the value of structured data, and the onboarding process has
been tailored to achieve it by the best means available. When onboarding new
assortment, the suppliers must structure their data according to a template
defined by the category manager. The template represents a “blueprint” or
a “schema” for what data is necessary depending on which product category
it belongs to. The main purpose of a pre-defined schema is that it ensures
that products in the same category are presented in a consistent way, allow-
ing the customer to compare products across suppliers. A consistent set of
structured data within a category also allows for sitelist filtering, for example
on color or width, to allow the customer better on-site navigation in large
38

assortments.
The argument against working towards achieving structured product data
is that it consumes a lot of time. Suppliers are seldom capable of quickly
packaging their data to a pre-defined format. Instead, each supplier has
their own blueprint for how they store their data in different categories. This
forces suppliers to, often through manual effort, re-structure their data to fit
the mandated format, a process that often takes significant amounts of time.
When the data arrives to merchandising, it is re-packaged and enriched to en-
sure optimal site-presentation and compliance with the existing assortments
packaging. Moreover, many suppliers lack parts of the mandated data inter-
nally which creates a difficult situation, the supplier can be pressured into
“creating” the mandated data, but more often than not the suppliers lack
the willingness to do so, forcing the onboarding team to regularly make ex-
ceptions with regards to the blueprint. While the process generally achieves
the desired result of consistency, it is painfully manual for everyone involved,
has significant lead times and is prone to errors.
Interviewees from functions not involved in the process of assortment on-
boarding were in agreement over the necessity of structured data for multi-
ple reasons. Considering an assortment of products with unstructured data,
the possibilities for automated applications decrease significantly. Optimiz-
ing on-site navigation through filtering functionality was considered to be
near impossible, and the ability to understand the in-house assortment in
terms of white-spots and weak-spots would only be possible in terms of the
structured data available (namely the product categorization). Furthermore,
the ability for search engine optimization of the assortment would be very
39

limited without significant manual effort.
The most important finding from our discussions on structured versus un-
structured data was that all organizational functions are in agreement on the
necessity of structuring product data but from many different angles. Most
interviewees mentioned the obvious application in filtering functionality, but
other perspectives and levers of structured data were only raised by specific
organizational functions indicating that even though the value is appreciated
by everyone, there is a knowledge gap between internal functions in their un-
derstanding of how product data is leveraged throughout the organization.
Going forward, we discuss our findings relating to the current and potential
applications of structured product data, that is, taking the perspective of an
e-commerce business where the data is perfectly structured and complete.
4.1.2 Structured data in online marketing
Results from this section are derived from interviews with two online mar-
keting experts within the company.
Online marketing encompasses several channels and methods but the over-
whelming majority of online traffic arriving at the e-commerce website from
marketing efforts enter either from search engines such as Google or from
social media platforms such as Facebook. Social media marketing was only
discussed briefly since it was not the interviewees’ day-to-day responsibilities,
but search engine optimization was discussed at length and particularly how
structured data can be leveraged for ranking higher on the organic search
results for the company’s target keywords and categories.
40

Those familiar with SEO (Search Engine Optimization) recognized that the
overarching target in the e-commerce context is to get one’s website listed as
high up in the search results as possible in searches using specific keywords
that are related to one’s products. How the underlying ranking algorithms
used by the search engines work is proprietary, there are however some intu-
itive basics that experts in the field agree are the most important for making
a website rise in the search engine rankings and two of the three directly
relate to product data.
The first method for achieving a good search engine ranking relates to key-
words used in search queries. Words that relate to products in different cate-
gories are referred to as keywords, and the main concept here is that content
on the e-commerce website should include the same keywords that poten-
tial customers might use when searching for products in relevant categories.
Consider the scenario where a potential customer enters a search engine with
the intention of finding a suitable sofa, that customer will likely use keywords
such as e.g. ‘sofa’, ‘couch’, ‘settee’ or ‘divan’. For the e-commerce website
selling sofas, it is important that those keywords are present in the website
content to indicate to the search engine that this is a relevant website for a
consumer searching for sofas.
The second method relates to content relevance. The idea is that a website
yielded by a specific search query or keyword should have content directly
related to that query or keyword. The more specific results the better. Con-
tinuing with the same example, a result that links directly to a landing page
containing an assortment of sofas will rank higher than a result that links
to a homepage for a website selling a variety of furniture. The relevance is
41

measured by customers’ tendency to stay on a website after entering from a
search engine and also how many clicks a customer must use to navigate to
achieve a desired result.
The last method has to do with linking to a landing page, this method is
somewhat more technical and is excluded from this result as it does not relate
to product data.
Search queries can be categorized into general, specific and long-tail depend-
ing on their level of specificity as demonstrated in Figure 4.1. General queries
have the highest competition and is as such the hardest to achieve good
rankings for. Just imagine how many websites would like to be the preferred
results for queries such as ‘nice clothing’, ‘cheap furniture’ or ‘buy laptop’.
These queries are generally used by individuals wanting to explore assort-
ments and options and as such relates to broad categories of products. Rel-
evant results for these queries are often e-commerce homepages or category
landing pages. Given the fierce competition and the fact that the number of
pages at each e-commerce website that are relevant for general queries are
generally very few, the content on these pages is curated manually by SEO
experts.
However, with increasing specificity in search queries, the number of landing
pages in need of content curation and optimization increases exponentially,
and with the increase in number of landing pages follows an ever growing
burden in manually managing the content on thousands or even millions of
landing pages. In this context, structured product data can play an integral
role for success in the online marketing space.
42

Figure 4.1: Example of different types of searches
Keeping in mind the important concepts of keywords and relevance, take the
example of an e-commerce website offering a large assortment of furniture
and the specific search query ‘green sofa’. The website in question likely has
several other product categories besides sofas, including tables, chairs, beds
and storage furniture and all of these categories likely contain products of
different colors. Furthermore, all of the mentioned categories likely have one,
two or even three levels of subcategories resulting in hundreds of cumulative
categories on a single website. To present the most relevant results relating to
the query ‘green sofa’ the website would naturally want to refer to a landing
page containing all of the website’s green sofas (and no products that are not
both green and sofas to maximize relevance) and would further want that
landing pages’ content to include the keywords ‘green’ and ‘sofa’.
Here, the first use case of how structured data is a core prerequisite for
43

online marketing becomes evident: The only way one can easily, scalably and
without manual effort create a landing page containing all of the website’s
green sofas is if all sofas have a structured attribute where the key refers to
color and the associated value is green. Effectively using a category along
with an attribute filter for that same category. While this can be done
manually, but with 15-20 different colors and hundreds of categories, the
landing pages for the set of relatively simple search queries containing a
product type and a color is counted in the thousands. To make matters worse,
color is only one key, or attribute, relevant for the assortment. Customers
could use simple queries such as ‘leather sofa’ or ‘vintage sofa’ relating to the
keys material and style respectively implicating the addition of thousands
of more necessary landing pages to maximize search engine relevance. The
manual effort in creating this volume of pages and content is overwhelming,
calling for automated solutions. With a complete set of structured product
data, these pages and the related keywords can be created automatically
by combining categories and keys using simple algorithms without need for
manual efforts.
So far, specific search queries have been considered as they relate to land-
ing pages and concluded that thousands of landing pages are necessary for
relevance optimization in the SEO-context. Intuitively, thousands could be
exchanged for several millions depending on the size of the assortment and
the level of detail as well as the number of dimensions in the structured data.
Using the same example of a website selling furniture, we instead consider
the example of a long-tail query, namely ‘green velvet chesterfield sofa’. De-
pending on the depth of the assortment, the website could have none, one
44

or several products fulfilling the requirements stipulated by the query. If the
website has no such products it has no direct incentive to pursue a good
ranking on the query and if it has several such products the website can
extend the logic described for landing pages by using combinations of cat-
egories and several attributes to achieve a relevant landing page. However,
the most common situation for long-tail queries is that the website has a
single product that matches the description, making the product page the
most relevant result for that keyword.
Here, the second and equally important application of structured product
data appears. For the structured data can be used to automatically create
product titles that are used by the search engines to find the most relevant
results. If all of the words in the queries appear in structured form on the
product pages, the title can be automatically created as a combination of the
values associated with the relevant keys. In this particular case the logic for
a title could be set as color + material + design + category, rendering the
desired result given a complete and structured set of data for that product.
In this context, the number of potential relevant landing pages is equal to,
or even greater than, the number of products in the assortment and the
only effort necessary is to find which keys are the most relevant for different
categories to define a title structure, the rest can be done automatically.
Worth noting is that this approach is deemed impossible in the context of
unstructured product data.
On a final note, staying in the context of product pages, an automated mech-
anism for creating product titles also allows significantly more flexibility to
keep up to speed with changing consumer preferences. Heavily searched key-
45

words should always be present in the titles to optimize the relevance towards
search engines, but if trends change and new keywords become relevant, the
effort of changing titles is much less demanding if they are built from struc-
tured data, if the opposite were true a manual approach would be the only
alternative.
4.1.3 Structured data in website design
Results from this section are derived from interviews with two people working
with on-site content curation at different websites and one working with front-
end development.
Firstly, all interviewees agreed with the statement that structured product
data is an important factor in designing a e-commerce website. The key point
we drew from these interviews was that the underlying product data was
prerequisite for much of the the work being done in front-end development
and content curation, meaning that many features being developed build
directly on the product data schemas and would not work, or work flawedly,
without a set of complete and structured product data. We will begin by
addressing the important topic of on-site navigation and then give examples
of design-features enabled by the product data.
In terms of on-site navigation, there are many similarities with the previous
discussion on landing pages in the SEO context. In essence, on-site navigation
refers to how a customer navigates through an e-commerce website in search
of a suitable product. A rule of thumb is that the customer should have to
put in as little effort as possible in order to reach the desired outcome (may
46

it be inspiration, comparison or purchasing). A larger assortment implies a
greater need for efficient navigation. The two main components to on-site
navigation is the category navigation and the filtering functionality. Most
e-commerce websites have a categorization of their product in some shape
or form allowing the customer to find a subset of products resonating with
the interests of the customer. This constitutes the basic navigation feature
and can be constructed in many ways depending mainly on the size of the
assortment.
Once the customer has found the right category of products, the next step
in guiding the customer towards the desired outcome is through filtering
functionality. If there are hundreds of products in each category it takes
significant effort from the side of the customer to find the right products in
the absence of filters. However, using filters can quickly and with minimal
effort help the customer exclude significant parts of the assortment that are
not relevant to that particular customer. Examples of frequently used filters
in e-commerce could be color, material, dimensions, and size. The part
played by structured product data in this context is equivalent to the case of
landing pages, meaning the possibility to create filters and to have flexibility
in choosing which filters are offered to assist the customer is solely dependent
on having complete and structured product data in the product database.
Turning to website design features and continuous development the story is
similar. Many of the desired applications are thought out with the customer
in mind to help them find inspiration, compare products and create a better
overall website experience. An example of a commonly used feature is direct
product comparisons, where products in the same category are displayed in
47

connection with each other along with their respective features - allowing
the customer to compare products along all relevant product dimensions.
This kind of feature can only be built if all included products have the same
features classified completely. Another example is suggestion engines. These
help suggest similar products based on other products that customers have
already shown an interest in. For these engines to make good suggestions
an important input is the structured product data allowing the engine to
identify similarities and differences between products.
4.1.4 Structured data in assortment curation
Results from this section are derived from interviews with two people working
with on-site content curation at different websites.
The necessity for flexibility in light of swift changes in demand is evident and
a reoccurring challenge throughout the retail industry. E-commerce websites
with a broad and deep assortment face the challenge of curating their as-
sortment in such a way that it becomes inspirational, and to market the
parts of the assortment that are currently trending among consumers. To
this end, structured product data can be leveraged to easily browse, filter
and understand the in-house assortment both within and across categories.
This method is leveraged regularly to filter out subsets of products that have
common classifications along one or several dimensions of the structured data
to quickly find a manageable number of products to leverage in addressing
trends, creating marketing content and building inspirational entries for po-
tential customers.
48

The process of assortment curation had previously been done manually but
leveraging structured product data has increased the efficiency in the process
significantly.
4.1.5 Structured data in business intelligence
The final area where structured product data is being leveraged to some
extent today, but where the perceived potential is very promising is within
business intelligence. Findings from this section are derived from interviews
with management and a business controller within the company.
The potential value comes mainly from several different aspects of assort-
ment analysis. In today’s set-up, assortment analysis is mainly performed
along the dimensions of category and price. The main objective is to achieve
completeness in the assortment meaning that defined categories should have
a satisfactory number of products and preferably products in all price ranges
in order to offer a complete assortment to the consumer. Using this method-
ology, the company has been able to continuously identify weak-spots and
white-spots within its own assortment that has then served as valuable in-
telligence for category managers when prioritizing onboarding of new assort-
ments.
An important realization is that this kind of analysis can be done in many
more dimensions to get input in the strive towards an ever more complete
assortment. For example, the company might find from the initial analysis
that there are 20 daybeds on offer and that they range between all desired
price points from low to high. But by adding new dimensions using struc-
49

tured product data, the company might realize that the assortment in terms
of e.g. colors, materials, styles and designs is homogeneous. As such, in-
putting structured product data into big data analysis applications could
lead to valuable intelligence and strategic decision making support for future
assortment expansion.
Another application for structured product data discussed in the context of
business intelligence was trend identification on all levels. Similarly as with
assortment analysis, product data could be analyzed along with sales- or
traffic-data in order to quickly be able to identify and act upon trends that
go beyond categories, brands or other current dimensions of analysis. Intel-
ligence from this sort of analysis could be leveraged by many organizational
functions including marketing, onboarding and purchasing.
Both of these use cases has grown more relevant and necessary as the avail-
ability of analytical software has exploded in recent years.
4.1.6 Risks of working with structured data
Lastly, a point of caution that was raised in several interviews was the issue
of data completeness. For, while everyone agreed working towards structured
data is core for future success and the potential for business development, if
all products aren’t classified according to the defined schemas for the struc-
tured data many applications lose much of their leverage. Take filtering for
example, say that a customer browses for a green sofa and applies the filter
‘green’ in the sofa-category but only a subset of the green sofas in the as-
sortment has the value ‘green’ connected to the key ‘color’. Then only the
50

correctly classified sofas will appear in the filtering limiting the customers
option. Many examples of undesirable outcomes that can appear through in-
complete or incorrectly classified structured data can be imagined. As such,
the strive towards structuring data must be accompanied by an equal strive
towards correctness and completeness.
4.2 The propositions
Reviewing the results of the proposition analysis, we identify several inter-
esting themes that invites further investigation. First of all, the distinction
between structured and unstructured product data is identified as a core con-
cept playing an integral role in how to view product data in the e-commerce
space. Thus, the propositions below all relate to product data in its struc-
tured form:
• Proposition 1: Structured product data, in contrast to its unstructured
counterpart, is significantly more valuable in terms of its potential ap-
plication in all parts of the e-commerce value chain
– Given that products which have values classified for the keys that
are used in filters are the only ones appearing once filters are ap-
plied, such products are likely exposed more frequently than prod-
ucts that doesn’t which could imply comparatively larger sales for
the products with structured data.
• Proposition 2: Structured product data improve navigation
– Given that products which have values classified for the keys that
51

are used in filters are the only ones appearing once filters are ap-
plied, such products are likely exposed more frequently than prod-
ucts that doesn’t which could imply comparatively larger sales for
the products with structured data.
• Proposition 3: Structured product data is crucial in search engine op-
timization
– Given that structured data seemingly play a key role in search en-
gine optimization, it appears likely that products with well struc-
tured data will have more traffic to their product pages and con-
sequently larger sales than other products.
• Proposition 4: Optimizing product titles is very important for long-tail
SEO, and structured product data makes them seamless to create
– Creating good titles for products that contain values for important
product attributes was discussed as a key part in long-tail SEO.
The implication is that products with well structured titles should
attract more traffic than products with weaker titles in terms of
included attributes and thus also more sales.
• Proposition 5: High quality product images are important for selling
products online
– While not discussed at length in the results, all agreed that prod-
uct images were of upmost importance implying that number- and
quality of images likely affect sales of products.
• Proposition 6: Structured data is highly valuable for business intelli-
52

gence and on-site curation
– Structured product data is described as highly valuable for mar-
keting and analytical purposes. While these effects wouldn’t be
visible in sales figures, it has interesting implications for the broad
necessity of working towards achieving structured product data.
The above propositions serve as input for the quantitative analysis in sec-
tion 4.3
4.3 Proposition validation
The quantitative analysis was conducted on a data set of roughly 67000
observations. In addition, the data set was grouped by the top-level product
category, resulting in 8 group regressions.
Furthermore, for each group, three regression models were fitted with the
following response variables:
• Page views
• Sessions
• Sales quantity
For the full tables of coefficients, see Appendix.
All of the models were checked for multicollinearity, significance and het-
eroskedasticity individually.
53

4.3.1 Data transformations
This part focuses on the transformations made on the data set in order to
accommodate the general linear regression assumptions.
Response variables
For all models, the response variables were log-transformed in order to reduce
the risk of heteroskedastic error terms. For each model, a quantile-quantile
plot of theoretical residual quantiles versus empirical residual quantiles were
evaluated and approved.
Regressors
The regressor for average price point was transformed across all regression
models through a log-transform in order to homogenize the variance of the
residuals. For each model, a quantile-quantile plot of theoretical residual
quantiles versus empirical residual quantiles were evaluated and approved.
Another key transformation made was to include interaction terms in the
regression. These interaction terms serve the purpose of isolating the effect
of a regressor, e.g. length of description, conditional on e.g. average price.
The full set of interaction terms is listed in the Appendix.
4.3.2 Coefficients of interest
This section provides some key findings of the coefficients of interest. For a
full list of coefficients for the different regressions, refer to the Appendix. For
definitions of the relevant regressors, refer to section 3.2.2.
54

Note further that the response variables of all regressions were log-transformed.
Image count
The number of images that are displayed for a product was significant and
positive for all categories except for interior decoration and kitchen. Table 4.1
presents a condensed view of each model. This indicates that, on average,
presenting an additional image on a product page yields significant increases
in volumes sold, page visits and session starts. This result is consistent with
Proposition 5.
Category Pageviews Sessions Quantity
All 0.37143*** 0.12771*** 0.22436***Bath 0.49106*** 0.34936*** 0.33297***Construction 0.48946*** 0.27863*** 0.15767***Floor 0.92903*** 0.26854* 0.41708***Furnishing (-0.10371) -0.20705*** -0.13658**Kitchen (0.02649) 0.31376* (-0.02588)Garden 0.41229*** 0.30494*** 0.13344***
Table 4.1: Summary of the image count attribute regression coefficient percategory
Category specific attributes
Looking at the category specific attributes, that is the number of struc-
tured product attributes that have category specific keys, we can see that
the kitchen category responds most positive across the board to increases in
these types of attributes. However, for the full regression the quantity sold is
seemingly negatively impacted on average, while the amount of traffic that
55

the page drives is positively impacted. The significance of the result across
most models was expected from Proposition 1, the negative impact in some
models however was not aligned with the propositions. Table 4.2 presents a
condensed view of each model.
Category Pageviews Sessions Quantity
All (0.00274) 0.00726** -0.14312***Bath (-0.00112) (0.00249) 0.23988***Construction -0.18675*** -0.09331*** -0.22263***Floor -0.10195*** -0.04430*** -0.11221**Furnishing 0.07192*** 0.04560*** -0.07404***Kitchen 0.05799*** 0.07523*** 0.33701***Garden (-0.01732) (0.02139) (-0.08985)
Table 4.2: Summary of the category specific attribute regression coefficientper category
Base attributes
From table 4.3, we see that on average, base attributes had a significant
positive impact in all models. However, on category level it was only positive
for kitchen, floor and bath, with negative values for interior design, outdoors
and construction. The base attributes are rarely presented on the websites
and not used in titles, thus the volatile impact is not surprising.
Standard attributes
Standard attributes had a significant impact across the board in every model
but internal traffic for the floor category. These attributes are often leveraged
for filters and titles making the result consistent with propositions 2, 3 and
56

Category Pageviews Sessions Quantity
All 0.00531* 0.01167*** 0.03372***Bath (-0.00598) 0.01005* 0.02887***Construction -0.13586*** -0.09686*** -0.04646***Floor 0.02362*** 0.01705*** -0.01264***Furnishing -0.10451*** -0.00868*** -0.02117***Kitchen 0.09435*** 0.11426*** 0.05420***Garden -0.04712*** (-0.01328) (0.00375)
Table 4.3: Summary of the base attribute regression coefficient per category
4. Table 4.4 presents a condensed view of each model.
Category Pageviews Sessions Quantity
All -0.14395*** -0.17414*** -0.06618***Bath (-0.02480) -0.05476*** -0.03285***Construction -0.43771 -0.40815*** -0.10417***Floor 0.08104*** (-0.03233) -0.05021**Furnishing -0.17463*** -0.20492*** -0.11726***Kitchen (-0.05944) -0.13902*** -0.09711***Garden (-0.03076) (-0.01023) (-0.05902)
Table 4.4: Summary of the standard attribute regression coefficient per cat-egory
Dimensions
The dimensions regressor, measuring the number of structured dimension
attributes for a product, was in general positive and significant across the
categories in terms of pageviews and sessions, but not in the quantity sold.
On average we saw that adding a dimension attribute roughly increases the
page hits by 11%, and the external traffic by 15% as seen in table 4.5. This
is consistent with propositions 2 and 3.
57

Category Pageviews Sessions Quantity
All 0.11029*** 0.14539*** (-0.00628)Bath (0.02414) 0.12040*** (-0.01054)Construction 0.33961*** 0.334432*** 0.05380***Floor 0.10506*** -0.09643*** -0.13634***Furnishing (0.00533) 0.03017* (0.01389)Kitchen 0.11295*** 0.04578* (-0.01316)Garden 0.17431*** 0.20669*** 0.06819***
Table 4.5: Summary of the dimensions attribute regression coefficient percategory
Information in title
Regarding information in the title, several different coefficients were used to
evaluate the effect on traffic and sales. Table 4.6 presents a condensed view
of the coefficient of information in the title not attributable to Series, Brand,
Colour or Material. For the quantity sold, this regressor was not significant
in any category. In general, however, the traffic driven from within the site
was positively correlated with the amount of extra information in the title
with the exception of bath and interior design.
Regarding structured information in the title, colour, series and material
had significant positive correlation with the traffic, while the brand was not
significant for internal traffic and negative for external traffic.
Length of description
For all categories where the description length was significant, the coefficient
was also positive with the exception of the bath category. Table 4.7 presents
a condensed view of each model.
58

Category Pageviews Sessions Quantity
All 0.25592*** 0.08663*** (-0.02138)Bath -0.21350*** -0.31870*** (-0.07646)Construction 0.09874* (0.07178) (0.05279)Floor 0.63347*** 0.60028*** (0.08490)Furnishing (0.08128) -0.20377*** (-0.05623)Kitchen (0.20987) (0.10165) (-0.00713)Garden 0.48688*** 0.17667* (0.10517)
Table 4.6: Summary of the title length attribute regression coefficient percategory
Category Pageviews Sessions Quantity
All 0.01095*** 0.00633** (0.00073)Bath (-0.00112) (-0.00287) -0.00762***Construction 0.01142*** 0.00943*** 0.00411***Floor (0.00328) (0.00471) (-0.00253)Furnishing (0.00058) (-0.00320) 0.01740***Kitchen 0.02082*** 0.02841*** (0.00490)Garden 0.02936*** 0.02717 0.01449***
Table 4.7: Summary of the description length attribute regression coefficientper category
Interactions
The interaction terms were constructed with the average price as a basis.
In brief, the importance of a quick delivery increases with the price of the
product on a significant level. Furthermore, most of the coefficients had a
negative conditional effect with the average price, indicating that cheaper
products on average rely more heavily on structured product information.
59

Chapter 5
Discussion
The intention of this section is to merge the findings from chapters two
through four in order to discuss what conclusions can be drawn as well as
potential implications of the findings. Firstly, we discuss our findings in
terms of the propositions put forward in section 4.2. We will continue on to
discuss more general implications of the results put forward and lastly, we
discuss the limitations of the paper.
60

5.1 Evaluating the propositions
5.1.1 Proposition 1: Structured product data, in con-
trast to its unstructured counterpart, is signif-
icantly more valuable in terms of its potential
application in all parts of the e-commerce value
chain.
This proposition is considered the key distinction. As such, it is the propo-
sition on which the majority of other results are evaluated on.
In terms of the current literature on the topic of e-commerce, we find that this
proposition holds under scrutiny. While rarely discussed explicitly, Rao and
Sashikuma (2016), Kang et al. (2003) and Nguyen et al. (2011) all directly
argue for the value of structured data. Moreover, the applications being
researched in the data science community all include methods for structuring
unstructured data or re-structuring already structured data before it can be
leveraged in different applications (Nguyen et al., 2011), (Krys and Bagheri,
2016).
From the quantitative part of the analysis we find further support that the
proposition holds. The results of the regression state that while some at-
tribute types seem more important than others, the total number of struc-
tured data points for a product has a significant and positive impact on both
sales and online traffic for that same product. Thus, the more of the prod-
uct data that can be presented in a structured fashion, the more likely the
61

product is to drive traffic and, ultimately, sell.
The direct importance of having structured data for concrete functionality
such as filtering, product comparisons and creation of large numbers of land-
ing pages is evident from the proposition analysis, and is coherent with the
intuitive hypothesis. These are the applications that the Company struggles
with in daily operations to optimize the performance of their websites. The
consensus was that the effort with structuring product data, while being te-
dious and difficult to create and maintain, can be directly related to positive
developments in terms of traffic and sales. Thus, the efforts are considered
worthwhile for basic applications but from the literature review we find that
the potential of extracting value from a well maintained structured product
database are quite vast. Ranging from BDA, SEO optimization and better
customer experiences the potential is significant and we conclude that not
only does the proposition hold, but the effort of creating these product data
sets should be a core activity for all e-commerce companies if they want to
stay competitive in online retail.
5.1.2 Proposition 2: Structured product data improves
navigation
While this proposition is intuitively true from the very construction of database
filters, we find some proof that the implication of the proposition is that it
can generate more sales and traffic. Nguyen et al. (2011) argue explicitly
for the positive impact on user experience from filtering functionality and
how structured data is its enabler. Petrovski and Bizer (2017) and Ristoski
62

et al. (2018) argue in similar fashion and we conclude that the proposition
has significant support in academic literature.
While the quantitative method does not allow investigation of this proposi-
tion directly, it gives some insight into the implications of improved naviga-
tion. Given that filtering is only possible once structured data is in place, we
earlier argued that products with structured data should get more exposure
than similar products that lack in this property. The regression yielded re-
sults implying that both page views and sessions increased with the number
of structured attributes present, in line with our expectation, but also that
the same structured data had a significant positive impact on the quantity
sold over the two year period investigated in the study. They key response
variable in this case is the page views, as it models the traffic to a product
page from internal sources. Having established that improved data structure
for a product does have a significant positive correlation with internal traffic,
it remains to show directly that these products are also more likely to sell
as a result. While the modelling of direct sales for a product gives an indi-
cation that this is the case (given the number of page visits) supports this
propositions, section 5.3.1 discusses potential issues with this approach and
potential remedies to consider in further studies.
Thus we conclude that proposition two has both support in the literature
and that the regression results were aligned with the expected implication of
the proposition.
63

5.1.3 Proposition 3: Structured product data is crucial
in search engine optimization
While reviewing the literature, we were surprised to find that very little has
been written on the topic of search engine optimization as it relates to e-
commerce. The interviews conducted within the proposition analysis found
that SEO was a highly prioritized subject within the organization and that
it is considered key in staying competitive over time. However, we did find
evidence of the important role of structured data as it relates to generalized
database searches. Petrovski and Bizer (2017) and Nguyen et al. (2011)
both argue that searching product databases, be that through actual search
engines or with database queries, is significantly more effective if the product
data is in structured format. We suspect that while search engine algorithms
are generally proprietary, these insights do in fact give some support for the
proposition.
More important, however, are the results of the regressions in this matter.
For the quantitative analysis yielded support for structured data in terms of
page views, sessions and quantity sold as discussed for earlier propositions,
implying its evident value in the context of SEO. Noteworthy is that the out-
come of the proposition analysis suggested that the SEO-value of structured
data was mainly implicit, meaning that its existence was more of an enabler
for further activities (the creation of new landing pages) rather than valuable
in and of itself.
Although, in general, the above holds, there are some considerations to be
taken when interpreting the data. For example, there is a seemingly negative
64

impact (or at least correlation) of standard attributes on the internal and ex-
ternal traffic driven to the products. This could be interpreted as an error in
the model, since the trivial hypothesis would be that extra attributes would
not decrease the traffic or quantity sold. On the other hand, it is possible
that these attributes, especially if they are considered as equally weighted as
e.g. dimensions, brand and category specific attributes in the search engine
algorithm, would serve to dilute the critical information. This could poten-
tially rank the products lower in the search engine perspective compared to
products which display only what are considered critical attributes. Testing
this would require entirely new hypotheses and potential interaction terms in
a regression, and is left for further research or a continuation of the results of
this paper. With the search engine algorithms being proprietary, we further
consider this a difficult issue to solve in any case.
We conclude that the literature implies that it also has an explicit value,
strengthening the support for the proposition further.
5.1.4 Proposition 4: Optimizing product titles is im-
portant for long-tail SEO, and structured prod-
uct data makes them seamless to create
Given the scarcity of academic literature on SEO in the context of e-commerce,
we could not find sufficient support for this proposition in the research. In-
tuitively, the latter part of the proposition relating to the automatic creation
of titles seems to hold just given the trivial logic that the process is based
on. And as was suggested by professionals on the topic we see no reason to
65

doubt its validity – at least in the context of the case subject. The former
part of the proposition on the other hand is more interesting as it should
have a direct effect on traffic and sales.
From Chapter 4, we can conclude that the length and content of the product
titles has a significant and positive impact on most measured dimensions.
Most importantly, one would expect a positive impact on the number of
sessions since long-tail SEO implies traffic directed straight to the product
page from external sources. This effect is confirmed by our analysis and
we conclude that the proposition is supported at least in part. Regarding
the quantity sold directly, no coefficient was significant on the 5% level of
confidence for any category or in the full data set. This would imply that
there is, in general, a positive correlation with external and internal traffic
that does not coincide with increased sales when controlling for the number
of page visits. In fact, the crass interpretation would be that while products
with more information in the title drive more traffic, there is no support
for an argument that these products sell in larger quantities. This latter
argument does not, however, contradict the proposition as such, but is an
interesting observation nonetheless.
5.1.5 Proposition 5: High quality product images are
important for selling products online
Once again, the proposition can be argued to make strong intuitive sense in
the context of e-commerce. Moreover, Chaudhuri et al. (2019) give support
that image quality is key for increasing online sales. While the quantitative
66

analysis could not capture the relative quality aspect of product images, it
does give proof that the number of product images had a significant positive
impact on both sales and traffic for the Company.
In fact, in the general case, the number of images on a product page yielded
the highest significant regression coefficients of all considered meta-attributes.
This indicating that the number of images is a key factor to consider for on-
line retailers when onboarding new assortment. However, it is also likely
a tedious process to engage in if images are not available in the suppliers’
databases since this would require an in-house or outsourced unit with the
responsibility to take new high-quality images of products. The magnitude
of this issue increases if the online retailer is employing drop-shipping, and
hence would not keep the product units in stock themselves.
Finally, the coefficients of the number of images should be interpreted with
caution. It is not likely that increasing the number of images ad infinitum
would generate constant marginal returns to traffic and sales. A model with
decreasing marginal returns could likely be constructed to deal with the in-
terpretation of the coefficient in a predictive model.
5.1.6 Proposition 6: Structured data is highly valuable
for business intelligence and on-site curation
This proposition was not considered to be possible to investigate with means
of quantitative analysis with the data set available. In terms of current aca-
demic literature, we could not find support for the explicit use of structured
product data for analytical purposes. On the other hand, Akter and Wamba
67

(2016) discuss the benefits of structured data for BDA applications in more
general applications. We can thus conclude that proposition 6 needs further
investigation to be able to be considered fully supported, but with confidence
in the intuitive hypothesis that the proposition holds even in the general case.
5.2 General implications of the results
5.2.1 Product catalogue creation
Upon reviewing the data science research on methods for consolidation of
products, it became clear that the incompleteness and lack of structure in
the e-commerce data was a major hurdle for achieving better results (Rao and
Sashikuma, 2016), (Ristoski et al., 2018). This is consistent with the find-
ings from the proposition analysis that indicated that many suppliers simply
cannot provide all of the requested data and that in some cases the manual
workload of structuring the data for large assortments is too overwhelming to
pursue, and thus products with less information than desired are allowed to
appear on e-commerce websites due to lack of alternatives. This mechanism
limits the value that can be created in all parts of the product-data value
chain and consequently the user experience for the consumer.
Moreover, the pursuit of automation in the data science community in solving
these issues is evident, and a flora of methods for structuring data using novel
technologies such as machine learning are proposed and successfully tested.
In contrast, the efforts of doing those exact same tasks in the company inves-
tigated (and possibly other e-commerce companies as well) are highly manual
68

and thus costly in terms of time and effort. This might very well present an
interesting opportunity for the e-commerce sector. The three-step process
for automatically collecting, structuring and aggregating product data could
potentially be adopted by online retailers themselves with the purpose of
reducing cost and potentially increasing the quality of data.
5.2.2 Toward a common product taxonomy
There seems to be great inefficiencies generally in transferring and leveraging
data between different parts of the product-data value chain. The proposi-
tion analysis identifies barriers between the suppliers and the e-commerce
companies, and the literature review identifies similar struggles in collecting
and structuring the e-commerce websites data. While novel technologies can
play a role in making these inefficiencies less prevalent, one way of elimi-
nating these struggles more efficiently could be creating common product
taxonomies.
There are such taxonomies relating to product categorization that are lever-
aged by several online aggregators in their classification of products. The
next natural step would be to elaborate on those categories and enrich each
category node with a schema for structured data points that relate to prod-
ucts in that category. With such an approach, it would be clear for suppliers
and e-commerce companies alike how the data should be structured and
eliminate much of the tension in transferring data between systems. We
recognize, however, that creating common standards is difficult and requires
participation from many stakeholders, and might also be vitiated by other
problems. Yet, the approach is intriguing in light of the results in this paper
69

and would be of interest for further research.
5.2.3 Critical success factors and their relation to prod-
uct data
As is evident from the proposition analysis, the topic of product data is core
for many parts of running a successful e-commerce company. Collecting,
structuring and managing the data is costly in terms of time and effort but
makes a significant impact on the success of the business. While we recog-
nize the risk of our assessment being somewhat biased by the fact that our
perspective was data-centered to begin with, we find it surprising that the
topic has not been discussed more frequently in the literature outside the
data science community. Some insights on the direct relation between prod-
uct data and success factors are given by Burgess and Karanasios (2008),
Cebi (2013) and Chaudhuri et al. (2019) while most others discuss the im-
portance of applications that leverage structured product data for trust and
user-experience (navigation for example) without touching the topic of the
underlying data.
Our deduction is that structured product data lies at the core of many of the
critical success factors discussed in the literature. That both the creation,
growth and potential scalability of an e-commerce business requires a data-
centered mindset and that while the current research does a good job on
enlightening the importance of considering all parts of the e-commerce value
chain, it does not do justice to the role of product data in achieving the
desired outcomes. A final note on the topic relates to the way e-commerce
70

is discussed in the academic community. As we point out in the review
of the literature, much research is written with the objective of supporting
traditional retailers’ transition to the online marketplace, but given the fact
that e-commerce has evolved into an industry in its own right with many
participants being online-native, we suggest a more e-commerce centered
focus going forward that can better account for the intricacies of conducting
e-commerce that is not necessarily related to the dynamics of traditional
retail.
5.3 Limitations of the paper
This section aims to discuss both limitations in the study and potential
weaknesses of the different chapters. We consider it appropriate to separate
the proposition analysis and the quantitative analysis. Starting with the
latter, as it is more straightforward to introduce the apparent weaknesses.
We do, however, want to re-iterate that this study was conducted on a single
case (although multiple subsidiaries in the proposition analysis). This means
that conclusions drawn in the paper might not always hold in the general case,
as interviewees are undisputedly shaped by their organizational context, and
the data only represents a, albeit relatively large, fraction of total online
sales in the Nordics. We hope to have created a solid foundation for future
research with different case subjects, where our results can be evaluated in
contexts differing in product space, company size and geographic location.
71

5.3.1 Proposition validation
Firstly, the issue of causality versus correlation and reverse-causality needs
to be addressed. When performing a regression analysis, while significant
coefficients indicates correlation, it does not necessarily provide a basis for
causality. In the context of this study, reverse-causality is a valid concern.
If it were the case that products that either sold better or drove more traffic
were to be retroactively amended with more structured data, reverse causal-
ity would indeed be an issue. However, interviews with employees at the
Company did not provide any evidence that products are amended on the
basis of sales or traffic, which gives validity to the results. Furthermore, the
model was not constructed ad hoc, but was deliberately specified together
with professionals within the company. This yields additional validity in the
interpretation of the model, as not only does the careful specification lower
the risk of omitted variable bias, it also provides some confidence in the pro-
posed causal relationship between the regressors and the response variables.
Secondly, the data sample from the Company only consisted of data from
2018 and 2019, yielding 2 years of data. While the time aspect is not a direct
issue, the analysis is solely built upon data from a single e-commerce website,
and thus the results are not guaranteed to hold in the general case. Further-
more, a larger data set from different sources would likely have facilitated
a more thorough analysis of the long-tail products. Almost half of the orig-
inal data set provided from the Company had fewer than 10 orders placed
during the 2-year period, which made data unsuitable for analysis. These
data points were thus excluded, and effect from the long-tail would then not
72

be captured. From the proposition analysis, it is clear that these kinds of
products are of significant value, and is the reason why many e-tailers aim for
full assortments within the categories. In the limitations on the data, there
was also an issue where all relevant categories was not eligible for regression
due to a lack of observations. This means that insights into these categories
were lost, and would have benefited from a data set either from a longer sales
period or from more online retailers.
Furthermore, one desired response variable in the study was the conversion
rate. With the type of data provided from the Company, there was no way to
properly model the conversion rate with a standard multiple linear regression
model - even with a logit transform. Thus, we attempted to use the quantity
of orders as a proxy, controlling for page views. We recognize that this is not
a perfect substitute, but the analysis is still deemed valid for the purposes
of understanding the relative impact of different types of structured product
data. This leaves an opening for further research, where a potential data set
tracking customer journeys could be utilized to model the conversion rate in
a more direct way.
To the topic of regressors, there are some considerations that need to be
addressed. Firstly, the description regressors were constructed as the number
of words in the short and long descriptions on the product page. We recognize
that this might not be a perfect method of controlling for the information
in the product description. An ideal scenario would have been to use as a
regressor a modified description which excludes information that is (or would
have been) present in the structured data of the product. This would then
have served as a better indicator of how the description text impacts sales
73

and website traffic. This approach was, however, deemed unfeasible with the
limitations of the data set that was available to us at this time.
One potential problem that was evaluated was the common occurrence of
sales on the Company’s website, which severely lowered prices and likely
affected sales at different times. While we have motivated that there is a
low risk of generating an omitted variable bias from these occurrences, since
there is likely no correlation between sales and the amount of product data,
we recognize that there is a potential for additional uncaptured variation in
the sales and traffic driven. The former assumption on no correlation between
sales and data might not, however, hold true if the Company would have used
an automated system to drive campaigns. At this time we did not receive
any indication that this was the case, but also not a firm confirmation of the
alternative. On the same line, there could be some correlation with our meta-
attributes and other factors which we are still oblivious to, as automation of
sales and advertisement becomes more prominent - especially in a company
with the resources of the subject of study.
A final note is that of seasonal differences in sales, and how that could po-
tentially dramatically affect sales. While this point is intimately connected
to sales, especially since the emergence of more and more annual ”sales holi-
days”, there is a distinct probability that these time periods exhibit different
behaviours on sales and traffic than the more mundane weekdays. The fact
that the data set covers two whole years does however mean that every season
is indeed captured. A suggestion for further research would be to control for
the biggest sales holidays (e.g. Black Friday weekend and the post-christmas
sale). This could be done by excluding it or finding a set of suitable control
74

variables. For the purpose of generating new intelligence, it would also be an
interesting case to conduct an analysis specifically for these types of events,
as there is a significant potential for retailers to generate unusual amounts
of revenue.
5.3.2 Limitations of the proposition analysis
The proposition analysis is of course limited by the fact that it only encom-
passes interviews from employees from a single company group. As such, the
nature of the proposition analysis findings can in general only be considered
valid in the context of that group of companies. Moreover, the selection of
interviewees did not include representation from all of the companies orga-
nizational functions. Thus, potential insights or questionings of our propo-
sitions might not be included in this paper. We further acknowledge that
our focus on product data going in to the interviews might have affected the
interviewees notions of the relative importance of product data relative to
other important aspects of the e-commerce business.
5.3.3 Sustainability aspects of this paper
As we are closing in on the end of this paper we will discuss sustainability
aspects as they relate to this paper. A framework of three sustainability
aspects are used to guide the discussion: ecological, social and economic
sustainability.
Ecological sustainability is difficult to relate directly to this work. There
is, however, second layer considerations in terms of ecological factors worth
75

considering. In terms of consumer retail, the main ecological factors to con-
sider are what products people are buying and how they are being delivered.
In terms of the products themselves, the aspect of sustainability metrics for
judging the quality of products from a sustainability standpoint relates di-
rectly to the data available to the customer. Including structured product
data product sustainability is thus integral to empower the consumer to in-
formed decision making. Such data can also be leveraged by e-commerce
companies by leveraging such data in filters, landing pages and marketing
materials. As such, sustainability metrics should be included in data schemas
all across the data value chain.
Since this paper is concerned with data on existing products, the social as-
pects of this work is negligible. In terms of the method, the interviews were
made with a diverse group of people in terms of gender and age but the se-
lection was of course limited by the fact that the study was made at a single
company.
Lastly, in terms of economic sustainability, we consider approaches for au-
tomation of manual efforts in the realm of product data to be the only
reasonable approach to create a dynamic and scalable business model for
e-commerce considering the huge amount of manual effort dedicated to these
activities today.
5.4 Conclusion
This study has served the purpose of exploring the impact of structured
product data in the e-commerce space through means of a limited case study
76

on a large Nordic online retailer, a rigorous review of contemporary academic
literature as well as a quantitative study on data provided by the Company.
Through the proposition analysis, six guiding propositions were deduced,
and used as guiding propositions for the rest of the study. All six of the
propositions were addressed in relation to the literature review conducted,
and were later evaluated through a multiple regression model.
On an overarching level, it is clear that there is a significant positive corre-
lation between most of the meta-attributes that were defined in the scope
of the study and the three response variables internal traffic, external traffic
and quantity sold. An exception included the coefficient for the standard
attributes in relation to SEO optimization, which could be attributed to a
diluting effect of such attributes on the response of a search engine algo-
rithm. These correlations are coherent with the current academic literature
on the subject of product data, although literature in the specific context of
e-commerce is surprisingly limited.
In conclusion, the paper gives strong support for propositions 1-5, indicating
that online retailers are currently well-aware of potential positive implica-
tions of structured product data on their business. However, there is are
significant knowledge gaps within the firm, as well as between the firm and
the state-of-the-art research on BDA. We propose that further research needs
to apply a context-specific lens on e-commerce as a whole in order to reduce
this knowledge gap and ultimately make the solutions accessible for online
retailers with less resources than e.g. Amazon.
77

Bibliography
Akter, S. and Wamba, S. F. (2016), ‘Big data analytics in E-commerce:
a systematic review and agenda for future research’, Electronic Markets
26(2), 173–194.
Atchariyachanvanich, K., Okada, H. and Sonehara, N. (2008), Critical success
factors of Internet shopping: The case of Japan, in ‘Communications in
Computer and Information Science’, Vol. 23 CCIS, pp. 98–109.
Baxter, P. and Jack, S. (2008), ‘Qualittive Case Study Methodology’, The
Qualitative Report 13(4), 544–559.
Burgess, S. and Karanasios, S. (2008), ‘Electronic commerce and business-
to-consumer (B2C) relations’, Journal of Electronic Commerce in Organi-
zations 6(4), 1–7.
Cebi, S. (2013), ‘Determining importance degrees of website design parame-
ters based on interactions and types of websites’, Decision Support Systems
54(2), 1030–1043.
Chaudhuri, A., Messina, P., Kokkula, S., Subramanian, A., Krishnan, A.,
Gandhi, S., Magnani, A. and Kandaswamy, V. (2019), A Smart System
78

for Selection of Optimal Product Images in E-Commerce, in ‘Proceed-
ings - 2018 IEEE International Conference on Big Data, Big Data 2018’,
pp. 1728–1736.
Choshin, M. and Ghaffari, A. (2017), ‘An investigation of the impact of
effective factors on the success of e-commerce in small- and medium-sized
companies’, Computers in Human Behavior 66, 67–74.
Creswell, J. W. (2009), Research Design: Qualitative, Quantitative and Mixed
Approaches (3rd Edition).
Duan, H., Zhai, C. X., Cheng, J. and Gattani, A. (2013), ‘Supporting key-
word search in product database: A probabilistic approach’, Proceedings
of the VLDB Endowment 6(14), 1786–1797.
Frost, R., Fox, A. K. and Strauss, J. (2018), E-marketing, eighth edition.
Kang, K.-D., Son, S. and Stankovic, J. (2003), ‘Differentiated Real-Time
Data Services for E-Commerce Applications’, Electronic Commerce Re-
search 3(1/2), 113–142.
Krys, G. and Bagheri, E. (2016), Semi-Supervised Product Specification Ex-
traction From The Web.
Lee, G. G. and Lin, H. F. (2005), ‘Customer perceptions of e-service quality
in online shopping’.
Loebbecke, C. and Picot, A. (2015), ‘Reflections on societal and business
model transformation arising from digitization and big data analytics: A
research agenda’, Journal of Strategic Information Systems 24(3), 149–157.
79

Machado, A. (2011), ‘Usability : impact on e-commerce’.
Ngai, E. W. (2003), ‘Selection of web sites for online advertising using the
AHP’, Information and Management 40(4), 233–242.
Nguyen, H., Fuxman, A., Paparizos, S., Freire, J. and Agrawal, R. (2011),
‘Synthesizing products for online catalogs’, Proceedings of the VLDB En-
dowment 4(7), 409–418.
Nisar, T. M. and Prabhakar, G. (2017), ‘What factors determine e-
satisfaction and consumer spending in e-commerce retailing?’, Journal of
Retailing and Consumer Services 39, 135–144.
Petrovski, P. and Bizer, C. (2017), Extracting Attribute-Value Pairs
from Product Specifications on theWeb, in ‘Proceedings - 2017
IEEE/WIC/ACM International Conference on Web Intelligence, WI 2017’,
pp. 558–565.
Rao, H. and Sashikuma, M. (2016), ‘A Survey on Automated Web Data
Extraction Techniques for Product Specification from E-commerce Web
Sites’, International Journal of Advanced Research in Computer Science
and Software Engineering 6(8).
Ristoski, P., Petrovski, P., Mika, P. and Paulheim, H. (2018), ‘A machine
learning approach for product matching and categorization’, Semantic Web
9(5), 707–728.
Shimada, K. and Endo, T. (2005), Acquisition of new training data from un-
labeled data for product specification extraction, in ‘Pacling 2005’, p. 284.
Singh, J. P., Irani, S., Rana, N. P., Dwivedi, Y. K., Saumya, S. and Kumar
80

Roy, P. (2017), ‘Predicting the “helpfulness” of online consumer reviews’,
Journal of Business Research 70, 346–355.
Varela, M. L. R., Araujo, A. F., Vieira, G. G., Manupati, V. K. and Manoj,
K. (2017), ‘Integrated Framework based on Critical Success Factors for E-
Commerce’, Journal of Information Systems Engineering & Management
2(1).
Vetenskapsradet (2002), ‘Forskningsetiska principer inom humanistisk-
samhallsvetenskaplig forskning’, Stockholm.
Walther, M., Hahne, L., Schuster, D. and Schill, A. (2010), Locating and
extracting product specifications from producer websites, in ‘ICEIS 2010
- Proceedings of the 12th International Conference on Enterprise Informa-
tion Systems’, Vol. 4 SAIC, pp. 13–22.
Wan, Y., Ma, B. and Pan, Y. (2018), ‘Opinion evolution of online consumer
reviews in the e-commerce environment’, Electronic Commerce Research
18(2), 291–311.
Yin, R. (2003), Case study methodology R.K. Yin (2003, 3rd edition). Case
Study Research design and methods. Sage, Thousand Oaks (CA)..pdf, in
‘Case Study Research: design and methods’, pp. 19–39; 96–106.
81

Appendix A
Appendix
82

logPageviews logSessions Quantity
(Intercept) 2.18945∗∗∗ 2.50456∗∗∗ 0.93710∗∗
(0.10786) (0.10913) (0.28954)
base 0.00531∗ 0.01167∗∗∗ 0.03372∗∗∗
(0.00216) (0.00218) (0.00165)
Standard −0.14395∗∗∗ −0.17414∗∗∗ −0.06618∗∗∗
(0.00759) (0.00767) (0.00568)
Dimensions 0.11029∗∗∗ 0.14539∗∗∗ −0.00628
(0.00562) (0.00564) (0.00426)
count 0.37143∗∗∗ 0.12771∗∗∗ 0.22436∗∗∗
(0.02440) (0.02470) (0.01861)
CategorySpecific 0.00274 0.00726∗∗ −0.14312∗∗∗
(0.00259) (0.00262) (0.00826)
short desc words 0.00079∗ 0.00423∗∗∗ −0.00019
(0.00032) (0.00032) (0.00024)
long desc words 0.01095∗∗∗ 0.00633∗∗∗ 0.00073
(0.00058) (0.00059) (0.00044)
intitle seriesTrue 0.27084∗∗∗ 0.10665∗∗∗ 0.13524∗∗∗
(0.02035) (0.02049) (0.01524)
83
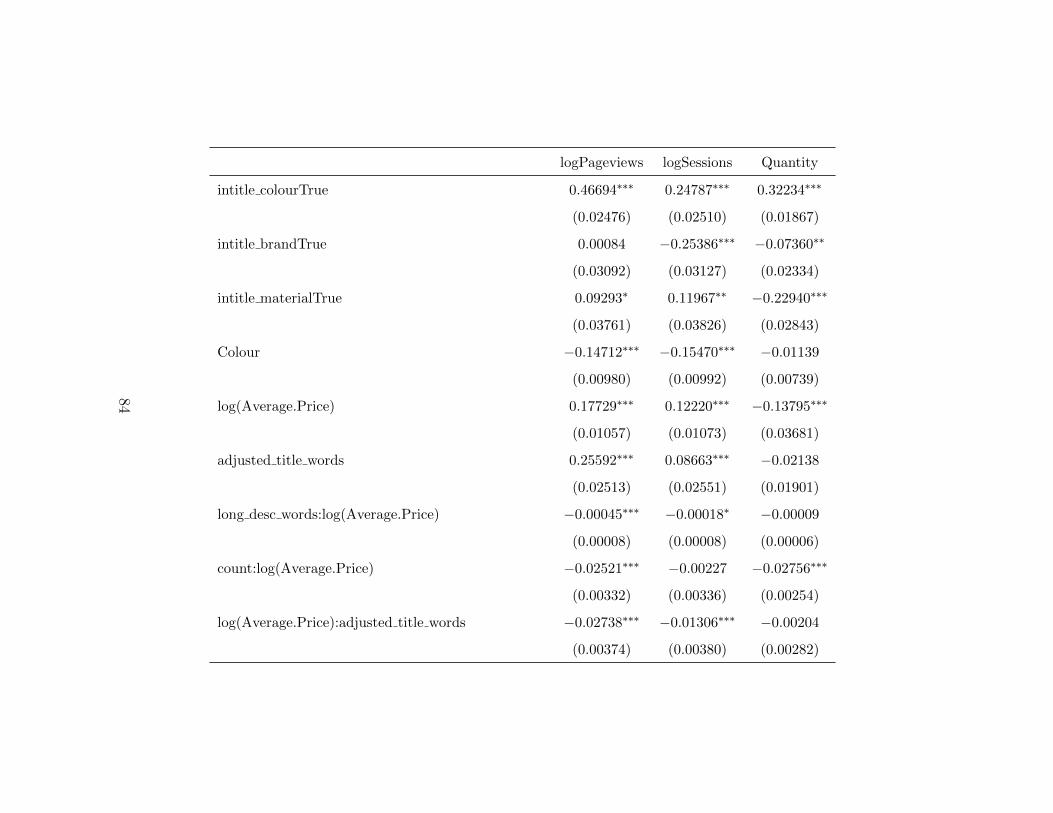
logPageviews logSessions Quantity
intitle colourTrue 0.46694∗∗∗ 0.24787∗∗∗ 0.32234∗∗∗
(0.02476) (0.02510) (0.01867)
intitle brandTrue 0.00084 −0.25386∗∗∗ −0.07360∗∗
(0.03092) (0.03127) (0.02334)
intitle materialTrue 0.09293∗ 0.11967∗∗ −0.22940∗∗∗
(0.03761) (0.03826) (0.02843)
Colour −0.14712∗∗∗ −0.15470∗∗∗ −0.01139
(0.00980) (0.00992) (0.00739)
log(Average.Price) 0.17729∗∗∗ 0.12220∗∗∗ −0.13795∗∗∗
(0.01057) (0.01073) (0.03681)
adjusted title words 0.25592∗∗∗ 0.08663∗∗∗ −0.02138
(0.02513) (0.02551) (0.01901)
long desc words:log(Average.Price) −0.00045∗∗∗ −0.00018∗ −0.00009
(0.00008) (0.00008) (0.00006)
count:log(Average.Price) −0.02521∗∗∗ −0.00227 −0.02756∗∗∗
(0.00332) (0.00336) (0.00254)
log(Average.Price):adjusted title words −0.02738∗∗∗ −0.01306∗∗∗ −0.00204
(0.00374) (0.00380) (0.00282)
84

logPageviews logSessions Quantity
Pageviews 0.00028∗∗∗
(0.00000)
deliverydelivery within 40 days 0.16264
(0.28691)
deliverydelivery within five days −0.09209
(0.27976)
deliverydelivery within ten days 1.21731∗∗∗
(0.28201)
CategorySpecific:log(Average.Price) 0.01636∗∗∗
(0.00115)
log(Average.Price):deliverydelivery within 40 days −0.02200
(0.03725)
log(Average.Price):deliverydelivery within five days 0.08572∗
(0.03636)
log(Average.Price):deliverydelivery within ten days −0.11784∗∗
(0.03669)
R2 0.16897 0.09554 0.23189
Adj. R2 0.16866 0.09523 0.23148
85

logPageviews logSessions Quantity
Num. obs. 45493 49367 46322
RMSE 1.68631 1.77295 1.26958
∗∗∗p < 0.001, ∗∗p < 0.01, ∗p < 0.05
Table A.1: Regression table for category full
86

logPageviews logSessions Quantity
(Intercept) 3.03324∗∗∗ 1.81521∗∗∗ −0.00689
(0.30925) (0.31647) (2.02519)
base −0.00598 0.01005∗ 0.02887∗∗∗
(0.00444) (0.00454) (0.00359)
Standard −0.02480 −0.05476∗∗∗ −0.03285∗∗
(0.01371) (0.01403) (0.01068)
Dimensions 0.02414 0.12040∗∗∗ −0.01054
(0.01451) (0.01480) (0.01147)
count 0.49106∗∗∗ 0.34936∗∗∗ 0.33297∗∗∗
(0.06749) (0.06943) (0.05308)
CategorySpecific −0.00112 0.00249 0.23988∗∗∗
(0.00583) (0.00598) (0.02771)
short desc words 0.00272∗∗ 0.00759∗∗∗ 0.00118
(0.00083) (0.00085) (0.00066)
long desc words −0.00112 −0.00287 −0.00762∗∗∗
(0.00177) (0.00181) (0.00137)
intitle seriesTrue 0.08009 0.08191 −0.02379
(0.04782) (0.04891) (0.03743)
87

logPageviews logSessions Quantity
intitle colourTrue 0.66121∗∗∗ 0.42385∗∗∗ 0.29619∗∗∗
(0.04712) (0.04815) (0.03661)
intitle brandTrue 1.88661∗∗∗ 1.56287∗∗∗ 0.63929∗∗∗
(0.18017) (0.18459) (0.13868)
intitle materialTrue 0.07012 0.00864 −0.16597
(0.13106) (0.13345) (0.10136)
Colour −0.15287∗∗∗ −0.17552∗∗∗ −0.10379∗∗∗
(0.02571) (0.02636) (0.01997)
log(Average.Price) −0.09129∗∗∗ −0.06943∗∗ −0.11778
(0.02598) (0.02652) (0.23302)
adjusted title words −0.31450∗∗∗ −0.31870∗∗∗ −0.07646
(0.07647) (0.07790) (0.05928)
long desc words:log(Average.Price) 0.00070∗∗ 0.00066∗∗ 0.00092∗∗∗
(0.00023) (0.00024) (0.00018)
count:log(Average.Price) −0.03814∗∗∗ −0.02635∗∗ −0.03687∗∗∗
(0.00873) (0.00899) (0.00685)
log(Average.Price):adjusted title words 0.04080∗∗∗ 0.03550∗∗∗ 0.01036
(0.01011) (0.01031) (0.00785)
88

logPageviews logSessions Quantity
Pageviews 0.00022∗∗∗
(0.00000)
deliverydelivery within 40 days 0.65027
(2.02546)
deliverydelivery within five days 1.39758
(2.01291)
deliverydelivery within ten days 1.89899
(2.01356)
CategorySpecific:log(Average.Price) −0.02858∗∗∗
(0.00327)
log(Average.Price):deliverydelivery within 40 days −0.05604
(0.23444)
log(Average.Price):deliverydelivery within five days −0.02737
(0.23290)
log(Average.Price):deliverydelivery within ten days −0.17054
(0.23293)
R2 0.10562 0.06399 0.33129
Adj. R2 0.10418 0.06258 0.32971
89

logPageviews logSessions Quantity
Num. obs. 10532 11307 10623
RMSE 1.68172 1.78129 1.30663
∗∗∗p < 0.001, ∗∗p < 0.01, ∗p < 0.05
Table A.2: Regression table for category bath
90

logPageviews logSessions Quantity
(Intercept) 7.54899∗∗∗ 6.10407∗∗∗ 3.07121∗∗∗
(0.32559) (0.33810) (0.46891)
base −0.13586∗∗∗ −0.09686∗∗∗ −0.04646∗∗∗
(0.00744) (0.00771) (0.00502)
Standard −0.43771∗∗∗ −0.40815∗∗∗ −0.10417∗∗∗
(0.02167) (0.02265) (0.01466)
Dimensions 0.33961∗∗∗ 0.33432∗∗∗ 0.05380∗∗∗
(0.01183) (0.01233) (0.00856)
count 0.48956∗∗∗ 0.27863∗∗∗ 0.15767∗∗∗
(0.04985) (0.05175) (0.03373)
CategorySpecific −0.18675∗∗∗ −0.09331∗∗∗ −0.22263∗∗∗
(0.00919) (0.00940) (0.02510)
short desc words 0.00196∗ 0.00454∗∗∗ 0.00184∗∗∗
(0.00078) (0.00081) (0.00051)
long desc words 0.01142∗∗∗ 0.00943∗∗∗ 0.00411∗∗∗
(0.00087) (0.00092) (0.00058)
intitle seriesTrue 1.27074∗∗∗ 0.93653∗∗∗ 0.31278∗∗∗
(0.06022) (0.06247) (0.04049)
91

logPageviews logSessions Quantity
intitle colourTrue 0.97336∗∗∗ 0.76747∗∗∗ 0.24736∗∗∗
(0.08970) (0.09444) (0.06030)
intitle brandTrue −0.13142∗ −0.24649∗∗∗ −0.11654∗∗
(0.05161) (0.05415) (0.03553)
intitle materialTrue 0.30226∗∗∗ 0.39449∗∗∗ −0.20829∗∗∗
(0.07142) (0.07557) (0.04970)
Colour −0.20747∗∗∗ −0.13351∗∗∗ −0.06542∗∗∗
(0.02010) (0.02105) (0.01393)
log(Average.Price) 0.14459∗∗∗ 0.15192∗∗∗ −0.06710
(0.02244) (0.02343) (0.05675)
adjusted title words 0.09874∗ 0.07178 0.05279
(0.04464) (0.04730) (0.03049)
long desc words:log(Average.Price) −0.00027∗ −0.00042∗∗∗ −0.00051∗∗∗
(0.00012) (0.00012) (0.00008)
count:log(Average.Price) −0.03108∗∗∗ −0.01762∗∗ −0.01684∗∗∗
(0.00654) (0.00682) (0.00445)
log(Average.Price):adjusted title words 0.00676 0.00075 −0.01534∗∗
(0.00708) (0.00749) (0.00485)
92

logPageviews logSessions Quantity
Pageviews 0.00022∗∗∗
(0.00001)
deliverydelivery within 40 days 0.72186
(0.40389)
deliverydelivery within five days 0.86126∗
(0.40475)
deliverydelivery within ten days 0.73659
(0.40362)
CategorySpecific:log(Average.Price) 0.02301∗∗∗
(0.00381)
log(Average.Price):deliverydelivery within 40 days −0.02437
(0.05349)
log(Average.Price):deliverydelivery within five days −0.04861
(0.05426)
log(Average.Price):deliverydelivery within ten days 0.00343
(0.05372)
R2 0.43917 0.29011 0.25348
Adj. R2 0.43801 0.28879 0.25132
93

logPageviews logSessions Quantity
Num. obs. 8208 9132 8692
RMSE 1.55202 1.69530 1.03558
∗∗∗p < 0.001, ∗∗p < 0.01, ∗p < 0.05
Table A.3: Regression table for category construction
94

logPageviews logSessions Quantity
(Intercept) −0.57652 0.49963 2.09927∗
(0.39538) (0.42785) (0.88381)
base 0.02362∗∗∗ 0.01705∗∗ −0.01264∗∗
(0.00600) (0.00645) (0.00446)
Standard 0.08104∗∗∗ −0.03233 −0.05021∗∗
(0.02228) (0.02383) (0.01700)
Dimensions 0.10506∗∗∗ −0.09643∗∗∗ −0.13634∗∗∗
(0.02073) (0.02219) (0.01515)
count 0.92903∗∗∗ 0.26854∗ 0.41708∗∗∗
(0.10445) (0.11298) (0.07815)
CategorySpecific −0.10195∗∗∗ −0.04430∗∗∗ −0.11221∗∗
(0.01166) (0.01254) (0.04352)
short desc words 0.00069 0.00086 −0.00113∗∗
(0.00056) (0.00058) (0.00041)
long desc words 0.00328 0.00471 −0.00253
(0.00278) (0.00302) (0.00205)
intitle seriesTrue −0.11627∗ 0.07472 −0.26285∗∗∗
(0.04812) (0.05169) (0.03555)
95

logPageviews logSessions Quantity
intitle colourTrue 0.03351 0.04248 0.18538∗∗∗
(0.05764) (0.06225) (0.04238)
intitle brandTrue −0.26515∗∗ 0.13896 −0.35473∗∗∗
(0.08951) (0.09560) (0.06504)
intitle materialTrue 0.30114∗∗∗ 0.40084∗∗∗ 0.18510∗∗∗
(0.06135) (0.06603) (0.04530)
Colour 0.06250∗ −0.14860∗∗∗ −0.21754∗∗∗
(0.02615) (0.02822) (0.01915)
log(Average.Price) 0.62573∗∗∗ 0.46674∗∗∗ −0.00455
(0.05266) (0.05718) (0.13974)
adjusted title words 0.63347∗∗∗ 0.60028∗∗∗ 0.08490
(0.09793) (0.10620) (0.07790)
long desc words:log(Average.Price) 0.00035 −0.00029 0.00057
(0.00048) (0.00052) (0.00036)
count:log(Average.Price) −0.12407∗∗∗ −0.02167 −0.05148∗∗∗
(0.01813) (0.01962) (0.01357)
log(Average.Price):adjusted title words −0.09846∗∗∗ −0.08962∗∗∗ −0.01634
(0.01698) (0.01843) (0.01350)
96

logPageviews logSessions Quantity
Pageviews 0.00029∗∗∗
(0.00001)
deliverydelivery within five days 1.51390
(0.84262)
deliverydelivery within ten days 1.63676
(0.88001)
CategorySpecific:log(Average.Price) 0.01878∗
(0.00738)
log(Average.Price):deliverydelivery within five days −0.14284
(0.13527)
log(Average.Price):deliverydelivery within ten days −0.14738
(0.14197)
R2 0.22140 0.07617 0.34110
Adj. R2 0.21933 0.07391 0.33874
Num. obs. 6416 6972 6447
RMSE 1.48819 1.66986 1.08607
∗∗∗p < 0.001, ∗∗p < 0.01, ∗p < 0.05
Table A.4: Regression table for category floor
97

98

logPageviews logSessions Quantity
(Intercept) 8.63638∗∗∗ 5.15022∗∗∗ 4.18897∗
(0.30885) (0.32293) (1.96461)
base −0.10451∗∗∗ −0.00868 −0.02117∗∗∗
(0.00658) (0.00689) (0.00549)
Standard −0.17463∗∗∗ −0.20492∗∗∗ −0.11726∗∗∗
(0.02016) (0.02109) (0.01650)
Dimensions 0.00533 0.03017∗ 0.01389
(0.01263) (0.01319) (0.01024)
count −0.10371 −0.20705∗∗∗ −0.13658∗∗
(0.05796) (0.06107) (0.04777)
CategorySpecific 0.07192∗∗∗ 0.04560∗∗∗ −0.07404∗∗∗
(0.00432) (0.00451) (0.01897)
short desc words −0.00418∗∗∗ 0.00170 −0.00202∗∗
(0.00091) (0.00096) (0.00073)
long desc words 0.00058 −0.00320 0.01740∗∗∗
(0.00356) (0.00373) (0.00287)
intitle seriesTrue −0.02734 −0.03125 −0.08924∗
(0.04400) (0.04596) (0.03516)
99

logPageviews logSessions Quantity
intitle colourTrue 0.47658∗∗∗ 0.21840∗∗∗ 0.17174∗∗∗
(0.05161) (0.05382) (0.04152)
intitle brandTrue −0.61969∗∗∗ −0.87628∗∗∗ −0.33349∗∗∗
(0.05410) (0.05665) (0.04438)
intitle materialTrue −0.17839∗ −0.07101 0.26948∗∗∗
(0.07849) (0.08277) (0.06316)
Colour −0.07070∗∗ 0.01366 −0.01043
(0.02488) (0.02599) (0.02014)
log(Average.Price) 0.01286 −0.02831 −0.18602
(0.02165) (0.02274) (0.21589)
adjusted title words 0.08128 −0.20366∗∗∗ −0.05623
(0.05598) (0.05862) (0.04522)
long desc words:log(Average.Price) 0.00246∗∗∗ 0.00227∗∗∗ −0.00215∗∗∗
(0.00057) (0.00059) (0.00046)
count:log(Average.Price) 0.01904∗ 0.02919∗∗∗ 0.00880
(0.00817) (0.00860) (0.00680)
log(Average.Price):adjusted title words −0.01695 0.01736 0.00796
(0.00874) (0.00915) (0.00706)
100

logPageviews logSessions Quantity
Pageviews 0.00040∗∗∗
(0.00001)
deliverydelivery within 40 days 1.02764
(1.95152)
deliverydelivery within five days −0.08112
(1.94176)
deliverydelivery within ten days 3.63775
(1.94721)
CategorySpecific:log(Average.Price) 0.01362∗∗∗
(0.00307)
log(Average.Price):deliverydelivery within 40 days −0.16148
(0.21699)
log(Average.Price):deliverydelivery within five days −0.02483
(0.21559)
log(Average.Price):deliverydelivery within ten days −0.55743∗
(0.21675)
R2 0.12823 0.06955 0.32994
Adj. R2 0.12661 0.06795 0.32814
101

logPageviews logSessions Quantity
Num. obs. 9201 9960 9325
RMSE 1.49467 1.62712 1.19979
∗∗∗p < 0.001, ∗∗p < 0.01, ∗p < 0.05
Table A.5: Regression table for category int
102

logPageviews logSessions Quantity
(Intercept) −1.12798 −3.44343∗∗∗ 1.32183
(0.61139) (0.63267) (1.23178)
base 0.09435∗∗∗ 0.11426∗∗∗ 0.05420∗∗∗
(0.01015) (0.01056) (0.00819)
Standard −0.05944 −0.14902∗∗∗ −0.09711∗∗∗
(0.03394) (0.03541) (0.02580)
Dimensions 0.11295∗∗∗ 0.04578∗ −0.01316
(0.02224) (0.02307) (0.01707)
count 0.02649 0.31376∗ −0.02588
(0.13345) (0.13916) (0.10399)
CategorySpecific 0.05788∗∗∗ 0.07523∗∗∗ 0.33701∗∗∗
(0.00872) (0.00902) (0.05775)
short desc words −0.00023 0.00387∗∗∗ 0.00026
(0.00072) (0.00077) (0.00059)
long desc words 0.02082∗∗∗ 0.02841∗∗∗ 0.00490
(0.00548) (0.00566) (0.00422)
intitle seriesTrue −0.26639∗∗ −0.35160∗∗∗ −0.08468
(0.09125) (0.09485) (0.06955)
103

logPageviews logSessions Quantity
intitle colourTrue 0.68069∗∗∗ 0.50291∗∗∗ 0.25680∗∗∗
(0.09642) (0.10167) (0.07464)
intitle brandTrue 0.84117∗∗∗ 0.63934∗∗ 0.31881
(0.23383) (0.24417) (0.17474)
intitle materialTrue 0.72365∗∗ 0.30164 −0.43707∗
(0.22612) (0.23892) (0.17234)
Colour −0.33027∗∗∗ −0.18376∗∗ −0.22576∗∗∗
(0.05333) (0.05584) (0.04061)
log(Average.Price) 0.21710∗∗∗ 0.41485∗∗∗ −0.18596∗∗
(0.05972) (0.06160) (0.06884)
adjusted title words 0.20987 0.10165 −0.00713
(0.12334) (0.12692) (0.09311)
long desc words:log(Average.Price) −0.00183∗∗ −0.00319∗∗∗ −0.00031
(0.00065) (0.00067) (0.00050)
count:log(Average.Price) −0.00584 −0.04268∗ −0.00158
(0.01672) (0.01739) (0.01305)
log(Average.Price):adjusted title words −0.03499∗ −0.02036 −0.00338
(0.01570) (0.01616) (0.01184)
104

logPageviews logSessions Quantity
Pageviews 0.00041∗∗∗
(0.00001)
deliverydelivery within 40 days −2.74612
(1.51541)
deliverydelivery within five days −0.88489
(1.14438)
deliverydelivery within ten days −0.30310
(1.04480)
CategorySpecific:log(Average.Price) −0.03991∗∗∗
(0.00694)
log(Average.Price):deliverydelivery within 40 days 0.35621∗∗
(0.13562)
log(Average.Price):deliverydelivery within five days 0.08568
(0.05999)
R2 0.23114 0.27673 0.44188
Adj. R2 0.22501 0.27145 0.43561
Num. obs. 2152 2346 2161
RMSE 1.37762 1.49698 1.03938
105

logPageviews logSessions Quantity
∗∗∗p < 0.001, ∗∗p < 0.01, ∗p < 0.05
Table A.6: Regression table for category kitchen
106

logPageviews logSessions Quantity
(Intercept) 2.29032∗∗∗ 1.98878∗∗∗ 1.23828
(0.41470) (0.42813) (4.69087)
base −0.04712∗∗∗ −0.01328 0.00375
(0.00785) (0.00812) (0.00665)
Standard −0.03076 −0.01023 −0.05902
(0.03888) (0.04001) (0.03204)
Dimensions 0.17431∗∗∗ 0.20669∗∗∗ 0.06819∗∗∗
(0.01801) (0.01841) (0.01500)
count 0.41229∗∗∗ 0.30494∗∗∗ 0.13344∗
(0.07178) (0.07418) (0.06208)
CategorySpecific −0.01732 0.02139 −0.08985
(0.01473) (0.01529) (0.06947)
short desc words 0.00423∗∗∗ 0.00419∗∗ 0.00341∗∗
(0.00126) (0.00130) (0.00104)
long desc words 0.02836∗∗∗ 0.02717∗∗∗ 0.01449∗∗∗
(0.00258) (0.00271) (0.00223)
intitle seriesTrue 0.15154 −0.14573 0.21382∗∗
(0.08681) (0.08964) (0.07251)
107

logPageviews logSessions Quantity
intitle colourTrue −0.13275 −0.27339∗∗ −0.07883
(0.09258) (0.09661) (0.07773)
intitle brandTrue 0.05399 −0.16113 0.07269
(0.12105) (0.12527) (0.10323)
intitle materialTrue −0.32477∗ 0.02558 −0.15691
(0.16528) (0.17414) (0.13660)
Colour −0.25447∗∗∗ −0.20923∗∗∗ −0.10157∗∗
(0.03785) (0.03919) (0.03166)
log(Average.Price) 0.51585∗∗∗ 0.35526∗∗∗ −0.08761
(0.03756) (0.03910) (0.88918)
adjusted title words 0.48688∗∗∗ 0.17667∗ 0.10571
(0.08312) (0.08674) (0.06915)
long desc words:log(Average.Price) −0.00256∗∗∗ −0.00253∗∗∗ −0.00151∗∗∗
(0.00029) (0.00030) (0.00025)
count:log(Average.Price) −0.04203∗∗∗ −0.03577∗∗∗ −0.01756∗
(0.00905) (0.00931) (0.00785)
log(Average.Price):adjusted title words −0.07127∗∗∗ −0.03166∗ −0.01696
(0.01234) (0.01287) (0.01026)
108

logPageviews logSessions Quantity
Pageviews 0.00025∗∗∗
(0.00001)
deliverydelivery within 40 days 0.34298
(4.68870)
deliverydelivery within five days 1.35165
(4.67073)
deliverydelivery within ten days 1.61811
(4.67310)
CategorySpecific:log(Average.Price) 0.00653
(0.00878)
log(Average.Price):deliverydelivery within 40 days 0.03036
(0.89117)
log(Average.Price):deliverydelivery within five days −0.06610
(0.88845)
log(Average.Price):deliverydelivery within ten days −0.16621
(0.88868)
R2 0.32325 0.23606 0.25935
Adj. R2 0.32031 0.23299 0.25464
109

logPageviews logSessions Quantity
Num. obs. 3933 4247 3955
RMSE 1.54132 1.65990 1.26853
∗∗∗p < 0.001, ∗∗p < 0.01, ∗p < 0.05
Table A.7: Regression table for category garden
110