the new disruptive db2 analytics...
TRANSCRIPT

© 2018 IBM Corporation1
Roberta Nobili
IBM Cloud & Analytics
The New Disruptive Db2 Analytics AcceleratorDelivering new flexible, integrated deployment options

© 2018 IBM Corporation2
AGENDA
�Data gravity approach
�Db2 Analytics Accelerator V5 – Today
�Db2 Analytics Accelerator V7 components
�Differences V7 to V5
�

© 2017 IBM Corporation3
Data is the world’s new natural
resource, transforming industries and
professions
Data is at the core of industry transformation and productivity
Data is the new basis
of industry disruption and
competitive advantage
Hybrid Transaction /Analytical
Processing (HTAP) will foster
opportunities for dramatic business
innovation2
“Enterprises should let Data
Gravity govern analytical
processing�”1
Analyze data where it originates
to minimize cost and complexity
while improving integrity
1 Source: A commissioned study conducted by Forrester Consulting on behalf of IBM, May 20162 Source: https://www.gartner.com/doc/2657815/hybrid-transactionanalytical-processing-foster-opportunities
HTAP enables simplified
infrastructure and drives
innovation and agility

© 2018 IBM Corporation4
IBM Z Analytics Keep your data in place – a different approach to enterprise analytics
• Keep data in place for analytics • Keep data in place, encrypted and secure
• Minimize latency, cost and complexity of data movement
• Transform data on platform
• Improve data quality and governance
• Apply the same resiliency to analytics as your
operational applications
• Combine insight from structured & unstructured data
from z and non-z data sources
• Leverage existing people, processes and infrastructure

© 2018 IBM Corporation5
The Db2 Analytics Accelerator further advances HTAP and IBM Z
The hybrid computing
platform on IBM Z
Supports transaction processing and
analytics workloads concurrently, efficiently
and cost-effectively
Delivers industry leading performance for
mixed workloads
The unique heterogeneous scale-out
platform in the industry
Superior availability, reliability and security
Transaction
Processing
Analytical
Workload
Db2 Analytics Accelerator and Db2 for z/OSA self-managing, hybrid workload-optimized database management system that runs each query workload in the most efficient
way, so that each query is executed in its optimal environment for greatest performance and cost efficiency

© 2018 IBM Corporation6
Today
Db2 Analytics Accelerator Version 5

© 2018 IBM Corporation7
Today
Current infrastructure
− based on Netezza technology
• N1001.., N2001.., N3001..
and
− DB2 Analytics Accelerator for z/OS V4 or V5
IT Use Case PDA N3001
Query Acceleration today
In-database transformation today
Incremental Update today
True HTAP today
Federation today
In-database analytics today
Use historical data (HPSS) today

© 2018 IBM Corporation8
What is “True HTAP” in V5 ?
So far, True HTAP with Db2 and Db2 Analytics Accelerator was limited:
• When a table changes on Db2 for z/OS, the changes are not immediately visible to queries routed to IDAA.
• However, some applications require the guarantee that any change committed on Db2 will be seen by a subsequent query.
• The HTAP feature provides this guarantee, presenting the next step in the journey towards full query offload transparency for accelerated queries.
✅ Analytics is performed against COMMITTED data that is known to be current relative to the SQL
✅ Latency no longer impacts SQL result consistency
Db2 Analytics Accelerator

© 2018 IBM Corporation9
How does True HTAP work?
Asynchronous replication
Most recent
committed
data
available?
no
Wait for
given time
period
Most recent
committed
data
required?
yes
no
Initiate
apply
Write
requests
OLTP
reads
OLAP
readsyes
Db2 Analytics Accelerator

© 2018 IBM Corporation10
How is HTAP implemented?
� Introducing a new ZPARM + Bind option + Special register
� CURRENY QUERY ACCELERATION WAITFORDATA = n.m.
− n.m. = 0.0 – 3500.0 (seconds)
− Default 0.0 = No wait
� WAITFORDATA = 0.0
− Immediately execute in Accelerator (Current behavior)
� WAITFORDATA > 0.0
− Wait for committed changes to be applied via asynchronous replication
• If wait time exceeded check Delay Expiration rule
• If FAIL (default) check CURRENT QUERY ACCELERATION special register
�If “WITH FAILBACK” is specified, execute query in Db2
�Else FAIL query with SQLCODE -904
• If “CONTINUE”, immediately execute in Accelerator and return SQLCODE +904 i

© 2018 IBM Corporation11
Add Column support �After a column has been added to a DB2 table the column can be added to the
associated table on the Accelerator by executing a synchronization operation − No need any more to remove the table from the Accelerator, re-add it and re-load it again
− For archive-enabled tables, no restore and re-archive is needed
− Queries can use the new column directly after the synchronization operation
�Supported table types: − Accelerator-shadow tables
• PTF 5: Without Incremental Upate enabled only
• PTF 6: With or without Incremental Update enabled
− Accelerator-archive tables
�Supported Schema Changes− ALTER TABLE ADD COLUMN (adding a nullable column)
− ALTER TABLE ADD COLUMN ... NOT NULL WITH DEFAULT (adding a non-nullable column with a default value)
• Default values are supported as long as they are explicit. Hexadecimal character strings are not supported as default value
Db2 Analytics Accelerator

© 2018 IBM Corporation12
Add Column support
� Support for ALTER TABLE ADD COLUMN only
� Required CDC capture agent configuration
− ONSCHEMACHANGE=STOP
− ADDCOLUMNISSCHEMACHANGE=YES
Db2 Analytics Accelerator

© 2018 IBM Corporation13
Task: Adding a new column to a replicated table
ALTER TABLE “EMPLOYEES” ADD COLUMN MIDDLENAME VARCHAR(128);
COMMIT;
Replication subscription will STOP with (CHC0860E event)
DSNX881I message will the thrown, requesting synchronization
Synchronization must be triggered via GUI or stored procedure call.
In the GUI the synchronization dialog will pop-up automatically.
Subscription will be starting again
1
2
3
4
5
Db2 Analytics Accelerator

© 2018 IBM Corporation14
Federation support
� Before: Data from subsystems sharing same accelerator is fully isolated
� Now: Grant read access to a table from another subsystem
− Prerequisites:
• Data from different DB2 systems is loaded into the same accelerator
• V5.1 PTF 5 and DB2 11 with APARs/PTFs PI77826/UI48595 and PI76645/ UI48595 installed
DB2R DB2O1D.
Accelerator
SELECT
D.
DB2O2
D.
Db2 Analytics Accelerator

© 2017 IBM Corporation15
Federation scenario• Terminology:
• Owning DB2 (DB2O) – DB2 that has read/write access to a table on the Accelerator. Table was added by DB2O to the Accelerator
• Referencing DB2 (DB2R) – DB2 that references, in RO mode, a (remote) table on the Accelerator that was added by DB2O to the
Accelerator
� DBA of DB2O grants privileges to DB2R to select
from DB2O tables
− New Accelerator stored procedure
� DBA of DB2R creates references to tables for which
privileges were granted from DB2O
− Another new Accelerator stored procedure
− References created as AOTs to get a „proxy“ within DB2
catalog tables of DB2R
� User of DB2R executes a query on the Accelerator that joins
tables from both DB2O and DB2R (T1 and T2_O)
− Uses AOT references in DB2R for DB2O tables in query
DB2R DB2O
Accelerator
SELECT on T1 and T2_O
AOT
T2_O
Table
T1Table
T2

© 2017 IBM Corporation16
Federation related new stored procedures
� Grants another DB2 for z/OS subsystem (DB2R) the privilege to select from accelerator-shadow or
accelerator-only tables that this subsystem (DB2O) has added to the specified accelerator (not a DB2
GRANT)
ACCEL_GRANT_TABLES_REFERENCE (ACCEL1, DB2R, Set<Accelerator-table>)
� Creates a referencing accelerator-only table for each table listed in the specified table set that allows this
DB2 for z/OS subsystem (DB2R) to reference an accelerator-shadow or accelerator-only table created in
another subsystem (DB2O) from a query running in this subsystem.
ACCEL_CREATE_REFERENCE_TABLES (ACCEL1, DB2O, Set<Accelerator-table-of-db2o>)
� Revokes the privilege to select from accelerator-shadow or accelerator-only tables that this subsystem
(DB2O) has added to the specified Accelerator from another DB2 for z/OS subsystem (DB2R)
ACCEL_REVOKE_TABLES_REFERENCE (ACCEL1, DB2R, Set<Accelerator-table>)
� Removes a referencing AOT on DB2R for each table that is referenced from DB2O and listed in the
specified table set. Do not use SQL DROP for referencing AOTs.
ACCEL_REMOVE_REFERENCE_TABLES (ACCEL1, DB2O, Set<Accelerator-table-of-db2o>)

© 2017 IBM Corporation17
Federation: More technical details
� The SELECT privilege for the referencing AOTs is managed/checked in the referencing DB2
subsystem (DB2R)
� Table metadata for referencing AOTs is required in DB2R for query rewrite and eligibility analysis
− Creation of referencing AOTs inserts entries in SYSIBM.SYSTABLES and
SYSACCEL.SYSACCELERATEDTABLES on DB2R
� DB2 catalog changes
− New pseudo-catalog table SYSACCEL.SYSACCELERATEDTABLESAUTH
• Contains one row for each accelerator-shadow or accelerator-only table on the owning DB2
(DB2O) for which a grant exists that allows another subsystem sharing the same accelerator to
access the table
− New column REMOTELOCATION in SYSACCEL.SYSACCELERATEDTABLES
• Contains the DB2 location of the owner table being referenced by a referencing AOT on DB2R.

© 2018 IBM Corporation18
Db2 Analytics Accelerator Version 7.1

© 2018 IBM Corporation19
Db2 Analytics Accelerator Version 7.1Delivering flexible, integrated deployment options
• Introduces flexible, integrated deployment options
• Accelerator on IBM Z
• Unified homogeneity of service, support and operations
• Flexible Capacity
• Accelerator on IBM Integrated Analytics System
• Fast, simple deployment on pre-configured hardware and software
• Flexible and elastic data storage
• Based on IBM’s premier analytical engine, Db2 Warehouse software
• Transition easily between deployment options
• One API
• One database engine
High-speed analysis of your enterprise data for real-time insight
under the control and security of IBM Z

© 2018 IBM Corporation20
Db2 Analytics Accelerator Version 7.1Deployment Options
In Version 7.1, Db2 acceleration can be implemented within different
operating environments:
• On an on-premises appliance � IDAA on IIAS
• On a SW appliance installed on the z14 mainframe � IDAA on Z
Both new options will offer
• the same functionality
• the same API
• the same implementation
This provides:
• Coexistence and combination of deployment options, fully
transparent for Db2 applications
• Flexibility in moving data for query acceleration as workload
demands grow or change
• Consistency and efficiency in managing different Db2 Analytics
Accelerator environments
Db2 Analytics Accelerator
Version 7.1:
Two deployment options

© 2018 IBM Corporation21
Db2 WarehouseThe new acceleration engine for Db2 Analytics Accelerator Version 7.1
Advantages of the new technology for Db2 Analytics Accelerator
• Improved SQL compatibility
• Columnar technology
• Improved throughput and performance
• Faster, easier integration with other technologies and approaches

© 2018 IBM Corporation22
Powered by Db2 with BLU acceleration
•Huge potential for faster ingest for incremental updates, and thereby less HTAP query delay!
•IBM’s premier analytics engine across many products
•Latest analytics technology innovations
•Improved SQL compatibility and performance
•Higher degree of concurrent users and queries
In-memory column processing with dynamic movement of data from storage
Multi-core and SIMD parallelism
(Single instruction Multiple Data)
Patented compression technique
preserves order so data can be used without
decompressing
Skips unnecessary processing of
irrelevant data
The new engine is replaced internally – external interfaces will stay the same.
The same Db2 subsystem can be connected to the existing and new generation.

© 2018 IBM Corporation23
Version 7.1 - New Architecture
Virtual or physical server CPU Memory
Docker Supported OS
Storage (local, SAN, NAS)(Clustered) Filesystem
Docker container
IBM Analytics
Engine
Authentication
Accelerator
server
Workload
Monitoring
Systems
Manager
Additional
functionality
Additional future
functionality
Infrastructure
Management

© 2018 IBM Corporation24
Db2 Analytics Accelerator Version 7.1,
Deployment on IBM Integrated Analytics
System

© 2018 IBM Corporation25
Db2 Analytics Accelerator for z/OS Version 7.1
deployment on IBM Integrated Analytics System (IIAS)
• Next generation hardware appliance
• A full solution that provides all components out of the box –including optimized hardware and software
• All components provided by IBM in a balanced, performance-optimized configuration
• HW, which includes the rack, the physical servers and the storage
• SW stack including the Docker host operating system as well as the Docker container and the
infrastructure management
• IBM Power hardware for the appliance, balanced and optimized for price/performance

© 2018 IBM Corporation26
IBM Db2 Analytics Accelerator on IBM Integrated Analytics System Product components
OSA-Express
10 GbE
CLIENT
Data Studio withDb2 Analytics Accelerator
Studio Plug-in
IBM Z
Data Warehouse applicationDb2 for z/OS enabled for IBM
Db2 Analytics Accelerator
Users/
Applications
Dedicated highly availablenetwork connection
IBM Integrated Analytics System
OSA-Express
10 GbE
P
a
t
h
c
h
P
a
n
e
l

© 2018 IBM Corporation27
Designed for Massively Parallel Performance
Memory Optimized In-memory Db2 Warehouse columnar processing with dynamic movement of
data from storage
Powered by RedHat® Linux on PowerOptimized for analytics with 4X threads per core, 4X memory
bandwidth and 6X more cache at lower latency compared to x86
Data SkippingSkips unnecessary processing of irrelevant data
Actionable CompressionPatented compression technique that preserves order allowing data to be used
without decompressing first
ALL Flash StorageHardware accelerated architecture enabling faster insights with extreme performance,
99.999% reliability and operational efficiency
IBM Integrated Analytics System – Designed for speed
Db2 Analytics Accelerator

© 2018 IBM Corporation28
IBM Integrated Analytics System Configurations
M4001-0031/3 Rack
M4001-0062/3 Rack
M4001-010Full Rack
Servers 3 5 7
Cores 72 120 168
Memory 1.5 TB 2.5 TB 3.5 TB
User capacity(Assumes 4x
compression)
64 TB 128 TB 192 TB
IBM Power 8 S822L 24 core server 3.02GHz, IBM FlashSystem 900
Mellanox 10G Ethernet switches

© 2018 IBM Corporation29
Rack Configuration
1/3 Rack 2/3 Rack Full Rack
• Modular design: adding 2 compute nodes and 1 storage node to scale up

© 2018 IBM Corporation30
Db2 Analytics Accelerator Version 7.1,
deployment on IBM Z

© 2018 IBM Corporation31
• A software appliance running on IBM Z
• Packages the SW stack into an IBM Secure Service Container to deliver a fully self-managed
appliance running in a SSC LPAR that can be deployed in minutes
• Integrates seamlessly into the customer’s IBM Z environment and leverages known LPAR-,
memory and CPU management procedures, including call home support for enterprise hardware
components.
• Uses customer-provided storage to hold the Accelerator-side data
• Scales smoothly with the assignment of available processor cores, initially addressing sizes
comparable up to 1/2 rack PDA (N3001-005) appliances
Db2 Analytics Accelerator for z/OS Version 7.1
deployment on IBM Z

© 2018 IBM Corporation32
IBM Db2 Analytics Accelerator on IBM ZProduct components
IBM z14
DB2 code
including Stored Procedures
Db2 Analytics Accelerator Studio Plug-In for Data Studio Accelerator Appliance
Appliance UI

© 2018 IBM Corporation33
Topology
One Db2 subsystem can connect to multiple
Accelerators
One Accelerator can connect to multiple Db2
subsystems
One Accelerator can use IFLs of up to one Drawer
The set of IFLs in one Drawer can be split to be used by
multiple Accelerators (dedicated - no “virtual sharing”)
LPAR LPAR LPAR
Drawer (~35 IFLs)Drawer (~35 IFLs)

© 2018 IBM Corporation34
Key advantages • Out-of-the-box experience
• Workload Optimized System
• Wide set of Analytics use cases
• Proven technology with client
references cross-industry
• Out-of-the-box experience
• Workload Optimized System
• Optimized for True HTAP
• Evolving set of Analytics use
cases
• Download & Go experience
• Homogeneity within IBM Z:
common resources, operation
• Evolving set of Analytics use
cases
Workload Size • Very good scale-out • Very good scale-out
• Optimized for very large query
throughput and load performance
• Good scale-up to full drawer
Db2 Analytics Accelerator on Pure Data for Analytics
N3001 (Netezza Technology)
Db2 Analytics Accelerator on
Integrated Analytics System M4001
Db2 Analytics Accelerator
on IBM Z
Key Characteristics of the deployment options

© 2018 IBM Corporation35
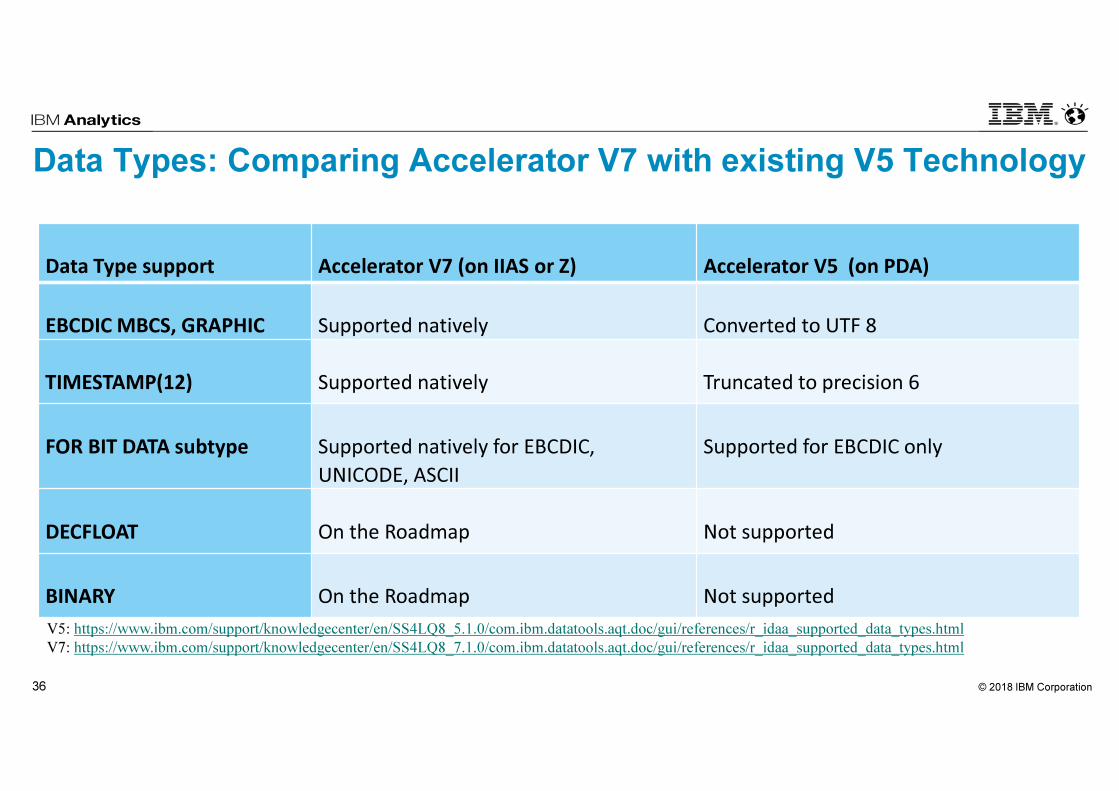
Differences V5 to V7
© 2018 IBM Corporation36
Data Types: Comparing Accelerator V7 with existing V5 Technology
Data Type support Accelerator V7 (on IIAS or Z) Accelerator V5 (on PDA)
EBCDIC MBCS, GRAPHIC Supported natively Converted to UTF 8
TIMESTAMP(12) Supported natively Truncated to precision 6
FOR BIT DATA subtype Supported natively for EBCDIC,
UNICODE, ASCII
Supported for EBCDIC only
DECFLOAT On the Roadmap Not supported
BINARY On the Roadmap Not supported
V5: https://www.ibm.com/support/knowledgecenter/en/SS4LQ8_5.1.0/com.ibm.datatools.aqt.doc/gui/references/r_idaa_supported_data_types.html
V7: https://www.ibm.com/support/knowledgecenter/en/SS4LQ8_7.1.0/com.ibm.datatools.aqt.doc/gui/references/r_idaa_supported_data_types.html

© 2018 IBM Corporation37
SQL Coverage: Comparing Accelerator V7 with existing V5
Technology
SQL support Accelerator V7 (on IIAS or Z) Accelerator V5 (on PDA)
correlated subqueries All types supported including table expressions with
sideway references
Only a small subset supported
Recursive SQL Supported Not supported
TIMESTAMP value 24:00:00 Supported natively Mapped to 23:59:59.999999
Scalar functions Improved support Some not supported when using specific datatypes,
e.g. MIN/MAX, DAY, LAST_DAY, BIT*,
TIMESTAMP_ISO, VARIANCE/STDDEV/… with
UNIQUE clause,
HEX() function Supported Not supported
Mixed Encodings Adding EBCDIC tables when UNICODE tables already
added is supported
(SQL joins with data in Unicode and EBCDIC not possible)
Only supported to add UNICODE tables after
EBCDIC table has already been added (required to set AQT_ENABLE_MULTIPLE_ENCODINGS
environment variable)
CURRENT_TIME,
CURRENT_TIMESTAMP,
CURRENT_DATE
Supported with improved accuracy (no longer dependent
on time synchronization)
Supported
Local Date Exit format Not supported Supported

© 2018 IBM Corporation38
Loading data with Db2 Analytics Accelerator V5
� ACCEL_LOAD_TABLES stored procedure
− Tables are loaded sequentially
� Tables can be loaded in parallel through separate invocation of stored procedure
− Partitions are loaded in parallel
• Max number of partitions loaded in parallel determined by AQT_MAX_UNLOAD_IN_PARALLEL environment
variable (AQTENV)
� AQT_MAX_UNLOAD_IN_PARALLEL applies to each partititioned table in a stored procedure call
− If two ACCEL_LOAD_TABLES stored procedures are called in parallel each loading a partitioned table then each
stored procedure call opens at max as many load streams as specified in AQT_MAX_UNLOAD_IN_PARALLEL
� Disadvantage
− Load streams might not be used efficiently if multiple tables (partitioned or non-partitioned) are loaded via one
ACCEL_LOAD_TABLES stored procedure call
− Accelerator might get overloaded by load requests if multiple ACCEL_LOAD_TABLE stored procedures are executed
in parallel

© 2018 IBM Corporation39
Example – Load in V5
� AQT_MAX_UNLOAD_IN_PARALLEL = 6
� One ACCEL_LOAD_TABLES call with two partitioned tables.
− Table T1_4G, has four partitions
− T2_5G contains two partitions with 1 and 4 GB
− Not all streams are used
− Gaps in streams because partitions are not equal in size,
but tables are loaded sequentially

© 2018 IBM Corporation40
Loading data with Db2 Analytics Accelerator V7 – Smart Load
� Data is loaded or refreshed using ACCEL_LOAD_TABLES stored procedure
− Non-partitioned tables and table partitions are loaded in parallel• Max number of tables and partitions loaded in parallel determined by
AQT_MAX_UNLOAD_IN_PARALLEL environment variable
� AQT_MAX_UNLOAD_IN_PARALLEL applies to each stored procedure call, global max governed internally
� The Accelerator checks the number of all load requests coming in parallel (from one subsystem or multiple connected subsystems) and dependent on resource consumption of the load requests, the percentage of the resource consumption per subsystem and the max number of parallel load streams per subsystem will be adjusted
� Advantages− All tables or partitions of tables specfied in one ACCEL_LOAD_TABLES call are efficiently loaded in
parallel− Reduces the need for customers to manage load streams efficiently by calling ACCEL_LOAD_TABLES in
parallel− Ensures that the Accelerator manages the resources used for loading data proactively to prevent resource
bottlenecks and overloading

© 2018 IBM Corporation41
Example – “Smart Load“ in V7
� AQT_MAX_UNLOAD_IN_PARALLEL = 6
� One ACCEL_LOAD_TABLES call with two partitioned
tables.
− Table T1_4G, has four partitions
− T2_5G contains two partitions with 1 and 4 GB
− All streams are used
− No gaps in streams
�Load management optimized by the Accelerator and
therefore minimized load elapsed time
�User does not need to manage load streams manually
by multiple parallel ACCEL_LOAD_TABLES calls 5 10 15 20 25 30 35 40 45 50
Duration in seconds
1
2
3
4
5
6
Stream
T1_4G
T2_5G
Table

© 2018 IBM Corporation42
Incremental Update with V5
� INSERT/UPDATE/DELETE statements captured from DB2 log data
after commit and replicated to the Accelerator
� On Accelerator data applied in mini-batches to leverage bulk load
interface
− Replication engine applies all committed changes that arrived
during a 60s window (or if minimum size reached)
• Minimum latency around one minute
� Defaults:
− Mini-batches are applied table by table (serial)
− If an error occurs for one replicated table replication stops for
all tables
− If a replication enabled table is loaded/reloaded:
• Table is removed from subscription during the load.
• Replication for other tables continues with short breaks
when the loaded table is removed/added from subscription
• Table is locked on Db2 to prevent changes while the load is
running

© 2018 IBM Corporation43
Incremental Update v7 vs. v5
Accelerator V7 Accelerator V5
Availability Yes, since Q1 2018 Yes, since V3
Default apply interval Targeting 20s or lower 60s
Mode Default: Continuous Replication, Parallel Apply,
Suspend faulty tables
Default: “Normal” Replication
Configurable: Continuous Replication, Parallel
Apply, Suspend fault tables
Eligible tables Only tables with enforced uniqueness (primary
key, unique index)
or a defined informational constraint
(via ACCEL_ADD_TABLES)
All tables, even when row uniqueness is not
enforced
Performance for
scenarios with many
changed tables
Targeting > 1600 changed tables / min 1 rack Mako: 200 changed tables /min

© 2018 IBM Corporation44