the inference problem: maintaining maximal availability in the presence of database updates
TRANSCRIPT

c o m p u t e r s & s e c u r i t y 2 9 ( 2 0 1 0 ) 8 8 – 1 0 3
ava i lab le a t www.sc iencedi rec t .com
journa l homepage : www.e lsev ier . com/ loca te /cose
The inference problem: Maintaining maximal availabilityin the presence of database updates5
Tyrone S. Toland a,*, Csilla Farkas b, Caroline M. Eastman b
a Department of Informatics, University of South Carolina Upstate, 800 University Way, Spartanburg, SC 29303, USAb Department of Computer Science and Engineering, University of South Carolina, Columbia, SC 29208, USA
a r t i c l e i n f o
Article history:
Received 19 February 2009
Received in revised form
18 July 2009
Accepted 21 July 2009
Keywords:
Disclosure inference
Confidentiality
Availability
Updates
Access control
Collaboration
Collusion
Database
5 This work was partially supported by the* Corresponding author. Tel.: þ1 864 503 531
E-mail addresses: [email protected]/$ – see front matter ª 2009 Elsevidoi:10.1016/j.cose.2009.07.004
a b s t r a c t
In this paper, we present the Dynamic Disclosure Monitor (D2Mon) architecture to prevent
illegal inferences via database constraints. D2Mon extends the functionality of Disclosure
Monitor (DiMon) to address database updates while preserving the soundness and
completeness properties of the inference algorithms. We study updates from the
perspective of increasing data availability. That is, updates on tuples that were previously
released may affect the correctness of the user inferences over these tuples. We develop
a mechanism, called Update Consolidator (UpCon), that propagates updates to a history file
to ensure that no query is rejected based on inferences derived from outdated data. The
history file is used by the Disclosure Inference Engine (DiIE) to compute inferences. We
show that UpCon and DiIE working together guarantee confidentiality (completeness prop-
erty of the data-dependent disclosure inference algorithm) and maximal availability
(soundness property of the data-dependent disclosure inference algorithm) even in the
presence of updates. We also present our implementation of D2Mon and our empirical
results.
ª 2009 Elsevier Ltd. All rights reserved.
1. Introduction data accesses when unauthorized information is obtained via
During the last couple of decades, our society became
increasingly dependent on computerized information
resources. Electronic databases contain information with
sensitivity levels ranging from public (e.g., airline schedules,
phone numbers and addresses) to highly sensitive (e.g.,
financial and medical information, military research). The aim
of information security policies is to protect the confidentiality
(secrecy) and integrity of data, while ensuring data availability.
Access control models, such as discretionary access control
(DAC), mandatory access control (MAC), and role-based access
control (RBAC), prevent direct unauthorized accesses to data.
However, these models are unable to protect against indirect
National Science Found0; fax: þ1 864 503 5408.u (T.S. Toland), farkas@cser Ltd. All rights reserved
inference channels. An inference channel is the ability to
determine sensitive data using non-sensitive data (Jajodia and
Meadows, 1995). Most of the inference channels in relational
databases are established by combining metadata (e.g., data-
base constraints) with non-sensitive data to obtain sensitive
information.
Techniques to detect and remove inference channels can
be organized into two categories. The first category includes
techniques that detect inference channels during database
design time (Buczkowski, 1990; Dawson et al., 1999b; Goguen
and Meseguer, 1984; Hinke, 1988; Hinke et al., 1995; Marks,
1996; Morgenstern, 1988; Smith, 1990; Su and Ozsoyoglu, 1991;
Yip and Levitt, 1998). Inference channels are removed by
ation under grant numbers IIS-0237782 and P200A000308-02.
e.sc.edu (C. Farkas), [email protected] (C.M. Eastman)..

Table 1 – Employee relation.
NAME RANK SALARY DEPT.
Original
John Clerk 38,000 Toy
Mary Secretary 28,000 Toy
Chris Secretary 28,000 Marketing
Joe Manager 45,000 Appliance
Sam Clerk 38,000 Appliance
Eve Manager 45,000 Marketing
Updated
John Manager 45,000 Toy
Mary Secretary 28,000 Toy
Chris Secretary 28,000 Marketing
Joe Manager 45,000 Appliance
Sam Clerk 39,520 Appliance
Eve Manager 45,000 Marketing
c o m p u t e r s & s e c u r i t y 2 9 ( 2 0 1 0 ) 8 8 – 1 0 3 89
modifying the database design or by increasing the classifi-
cation levels of some of the data items. Techniques in the
second category seek to eliminate inference channel viola-
tions during query processing time (Denning, 1985; Keefe et al.,
1989; Marks et al., 1996; Mazumdar et al., 1988; Stachour and
Thuraisingham, 1990; Thuraisingham, 1987). If an inference
channel is detected, the query is either refused or modified to
avoid security violations. While, in general, database design
time approaches are computationally less expensive and may
provide better on-line performance than query processing
time approaches, database design time approaches often
result in over-classification of data items, thus reducing data
availability. Query processing time approaches allow greater
availability by analyzing the data released to the user.
In this paper, we study database updates from the
perspective of increasing data availability. For this, we propose
a system that uses a query processing time algorithm to control
inferences that reveal sensitive data. Our work extends the
Disclosure Monitor (DiMon) model presented by Brodsky et al.
(2000). DiMon detects and eliminates inference channels based
on database constraints. A Disclosure Inference Engine (DiIE) is
proposed, that generates all information that can be disclosed
based on a user’s previous query results, the current query
results, and a set of Horn-clause constraints (Ullman, 1988).
However, Brodsky et al. do not consider dynamic databases
where updates may violate the soundness property of the data-
dependent disclosure inference algorithm. The following are
two examples of an execution of DiMon. The first example
satisfies both the soundness and completeness property, while
the second example violates the soundness property.
For both examples, we use the Employee relation containing
information about the name, rank, salary, and department of
employees (See Table 1). The relation satisfies the functional
dependency (FD) RANK & SALARY. The security requirement is
that the employees’ salaries can only be accessed by autho-
rized users; that is, partial tuples over attributes NAME and
SALARY can only be accessed by authorized users. However, to
increase data availability, unauthorized users are allowed to
access NAME and SALARY separately.
Example 1.1. Suppose an unauthorized user submits the
following two queries:
Query 1: ‘‘List the name and rank of the employees working in
the toy department.’’ (PNAME, RANKsDEPARTMENT¼‘Toy’)
Query 2: ‘‘List the salaries of all clerks in the appliance depart-
ment.’’ (PSALARYsRANK¼‘Clerk’ ^ DEPARTMENT¼‘Appliance’)
The answer to the queries is as follows: Query 1¼ {CJohn,
ClerkD,CMary,SecretaryD} and Query 2¼ {CClerk, $38,000D}. Since
the Employee relation satisfies the FD RANK / SALARY, these
query results reveal that John’s salary is $38,000. These types
of inferences are correctly detected and prevented by DiIE.
That is, DiIE would reject Query 2 to prevent the user from
inferring the unauthorized information.
Example 1.2. Now, suppose the following is submitted:
Query 1: ‘‘List the name and rank of the employees working in
the toy department.’’ (PNAME, RANKsDEPARTMENT¼‘Toy’)
Update: ‘‘John is promoted to the rank of manager.’’
Update: ‘‘The salaries of all the clerks are increased by 4%.’’
Query 2: ‘‘List the salaries of all clerks in the appliance
department.’’
(PSALARYsRANK¼‘Clerk’^DEPARTMENT¼‘Appliance’)
The answer to Query 1 is the same as in Example 1.1. As
a result of the database updates shown in Table 1, the answer
to Query 2 is {CClerk, $39,520D}. In this case, DiIE would indicate
that CJohn, $39,520D is disclosed; and, since it is unauthorized,
Query 2 would be rejected. However, this sub-tuple is not
contained in the updated relation and has never been present
in any of the earlier versions. Therefore, the second query
could be safely answered without revealing any unauthorized
information.
The reason that the second query can be released in
Example 1.2 is that the FD was applied on outdated data
values. We call inferences based on outdated data values
‘‘wrong’’ inferences. That is, the ‘‘wrong’’ inference that
John’s salary is $39,520 does not reveal unauthorized data
under the security requirement specified in this example. We
will permit queries that generate ‘‘wrong’’ inferences in order
to increase data availability.
We evaluate the disclosure inference algorithms in our
model from the perspective of soundness and completeness.
Intuitively, soundness means that only existing disclosure
inferences are generated by the algorithm (data availability);
completeness means that all existing disclosure inferences
are generated (secrecy).
Our preliminary work, Farkas et al. (2001), formalizes our
initial results and presents our conceptual framework, called
Dynamic Disclosure Monitor (D2Mon). D2Mon guarantees
data confidentiality and maximal availability even in the
presence of inferences and updates. We do not propose to
replace an existing access control mechanism. It is our
intention to complement an existing access control mecha-
nism (e.g., DAC, MAC, RBAC) to address the inference
problem. To this end, we assume the existence of an access
control mechanism that utilizes a predefined security
classification.

c o m p u t e r s & s e c u r i t y 2 9 ( 2 0 1 0 ) 8 8 – 1 0 390
We develop a new module called Update Consolidator
(UpCon) that, given a history file, an update log on the base
relations, and the database constraints, generates a new
history file that marks outdated data values and indicates only
valid inferences. All updates on the base relations are recorded
in an update log. The history file contains all data that the user
previously received or that can be disclosed from the received
answers. When a new query is requested by a user, the history
file is modified according to the updates that have been made
since the history file was created. Each updated data value is
stamped with the modified value. Intuitively, a stamped value
means that the original value is no longer valid, and the new
value is unknown to the user. Stamping will prevent the
disclosure inference algorithm from indicating a disclosure
based on outdated values (soundness) while maintaining
maximal equalities among modified data values, thus allowing
maximal dependency application (completeness). We show,
that with the use of UpCon, the Data-Dependent Disclosure
Inference (DiIE) Algorithm (Brodsky et al., 2000) is sound and
complete even in the presence of updates.
To the authors’ best knowledge, this is the first work that
considers updates from the perspective of increased data
availability and proposes formal characterizations of the
effects of updates. Our framework addresses inferences via
generalized database dependencies represented as Horn-
clause constraints (Ullman, 1988).
Our empirical results show that D2Mon can increase data
availability as a result of permitting inferences that are based
on outdated data items. Using several instances of the
Employee database, we conducted experiments using Exam-
ples 1.1 and 1.2, respectively. Our algorithm runs in poly-
nomial time.
The paper is organized as follows. Section 2 contains the
preliminaries and our notations. In Section 3, we present the
Dynamic Disclosure Monitor architecture. We further develop
the Update Consolidator mechanism. In Section 4, we discuss
how D2Mon prevents multiple users from colluding to reveal
sensitive information. Section 5, we prove that DiIE is sound
and complete when used with Update Consolidator. In Section
6, we discuss the complexity and some empirical results of our
framework. Section 7 discusses some related work. We
discuss some future research directions in Section 8. Section 9
concludes the paper.
2. Preliminaries
Our model is built upon the Disclosure Monitor (DiMon)
security architecture, developed by Brodsky et al. (2000), to
protect data confidentiality against illegal inferences in rela-
tional databases.
We propose the Dynamic Disclosure Monitor (D2Mon) archi-
tecture shown in Fig. 1. D2Mon incorporates updates in its
inference process to increase data availability, while guaran-
teeing that no unauthorized disclosure is possible via data
requests.1 To accomplish this, we propose extending DiMon
by developing a module called Update Consolidator (UpCon).
1 In this work, we do not consider covert channels created byupdates.
This module will propagate the updates from the base relation
to the history files. The additional features of D2Mon over
DiMon are used when DiIE works in data-dependent mode.
Clearly, in data-independent mode when the actual data
items received by a user are not known by DiIE, updates made
on the base relation will not affect the processing of DiIE. We
also modify DiIE to use a single history file to store query
results that are released to all users. This allows us to detect
and prevent inferences via user collaboration.
Before explaining the functionality of the Update Consoli-
dator (UpCon) we need to introduce some new and modify
some existing concepts. We assume as in Brodsky et al. (2000)
and Marks (1996) the existence of a universal relation r over
schema R¼ {A1, ., Ak} (Ullman, 1988). We shall denote by
dom(Ai) (1� i� k) the domain of attribute Ai.
We require that each tuple within the database has
a unique tuple identifier (ID) that is maintained internally and
not released to the user. When a new tuple is added to the
database, a unique ID is assigned to it.
We now define an update log entry.
Definition 2.1. (Update) Given a schema R and a relation r over
R, an update UP on r is a 5-tuple of the form (t, id, A, vold, vnew),
where t is the time of the update, id is the identifier of the tuple
in r that is being updated, A is the attribute name that is being
updated such that A ˛ R, and vold, vnew are the old and the new
(updated) values of A, respectively such that vold,
vnew ˛ dom(A)W{�}. The special symbol – is used to represent
old values of an attribute when the update is an insertion and
new values when the update is a deletion.
Using Example 1.2, a set U of updates at times t2 and t3 are
recorded as follows: U ¼ fðt2;1;RANK;Clerk;ManagerÞ; ðt2; 1;
SALARY; $38; 000; $45; 000Þ; ðt3;5;SALARY; $38;000; $39;520Þg.We represent updates on tuples which were previously
released to a user by ‘‘stamping’’ these values with the new
value. For this process, we need the notion of a stamped attribute.
Definition 2.2. (Stamped attribute) Let r be a relation over
schema R. Let A be an attribute name from a schema R and
dom(A)¼ a1, ., al the domain of A. A stamped attribute SA is an
attribute such that its value sa is of the form aaj
i ði; j ¼ 1;.; lÞ,where ai ˛ dom(A)W{�} and aj ˛ dom(A)W{�}. We call ai the value
of sa and aj is the stamp or updated value of sa. We assign aj the
updated value for A. If the attribute A has been deleted, then we
assign aj the symbol {�}. We call this process stamping.
Our framework uses stamped attributes internally to
represent query results that were received by the user but are
now outdated. For example, assume at some time t1 that the
user has received the tuple CClerk, $38,000D over the attributes
RANK and SALARY from the Employee relation. Since the tuple
was released, it is also stored in the history file. If at some time
t2(t1< t2) the salaries of the clerks are modified, e.g., increased
to $39,520, the corresponding tuple in the history file is
stamped as follows CClerk, $38,000$39, 520D. We are able to
determine from this tuple: 1) the attribute values Clerk and
$38,000 have been released to the user and 2) the attribute
Clerk has not been modified; however, the attribute value of
Salary has been modified to $39,520, which is unknown to the
user. If at some time t3(t2< t3) the tuple from which these
attribute values were received is deleted, then the history file

Mandatory AccessControl(MAC)
DisclosureInference Engine
(DiIE)
Database
Dynamic Disclosure Monitor (D2Mon)
User
Database Constraints
All DisclosedData
Accept/RejectQuery
Current Query Current QueryResults
UpdatedHistory
User HistoryDatabase
Update
Consolidator
(UpCon)
UpdateLog
Fig. 1 – Dynamic Disclosure Monitor (D2Mon).
c o m p u t e r s & s e c u r i t y 2 9 ( 2 0 1 0 ) 8 8 – 1 0 3 91
tuple would be updated as CClerk{�},$38,000{�}D. Again, by
inspecting the history file, we can now determine that: 1) Clerk
and $38,000 has been released to the user and 2) the tuple from
which this information was received has been deleted.
We recognize that previous stamped values can be over-
written by successive stamping procedures, but our proposed
solution requires that only the most recent update be stored.
Definition 2.3. (Equalities of stamped attributes) Given two
stamped attributes sa ¼ aaj
i and sb ¼ bbj
i , we say that sa¼ sb iff
ai¼ bi and aj¼ bj. Given a stamped attribute sa ¼ aaj
i and a non-
stamped attribute b, we say that sa¼ b iff ai¼ b and ai¼ aj.
Next, we need the notion of projection facts and stamped
projection facts which are manipulated by the DiIE.
Definition 2.4. (Projection fact) A projection fact (PF) of type A1,
., Ak, where A1, ., Ak are attributes in the schema R, is
a mapping m from {A1, ., Ak} to Ukj¼1dom
�Aj
�WUk
j¼1dom�SAj
�such that m(Aj) ˛ dom(Aj) W dom(SAj) for all j¼ 1, ., k. A
projection fact is denoted by an expression of the form
R[A1¼ v1, ., Ak¼ vk], where R is the schema name and v1, .,
vk are values of attributes A1, ., Ak, respectively. A PF is
classified as one of the following:
1. A stamped projection fact (SPF) is a projection fact R[A1¼ v1,
., Ak¼ vk], where at least one of vj ( j¼ 1, ., k) is a stamped
attribute value.
2. A non-stamped projection fact is a projection fact R[A1¼ v1,
., Ak¼ vk], where all vjs are constants in dom(Aj).
For example, Employee[NAME¼ John, Rank¼ Clerk] is a non-
stamped projection fact, while Employee[NAME¼ John, Rank¼ClerkManager] is a stamped projection fact.
In the remainder of this paper the term projection fact may
refer to either a stamped or an non-stamped projection fact.
The type of projection fact (i.e., stamped or non-stamped) will
be clear from its usage.
Definition 2.5. (Query–answer pair) An atomic query–answer pair
(QA-pair) is an expression of the form (P, PYsC), where P is
a projection fact over Y that satisfies C, or P is a stamped
projection fact, such that the un-stamped projection fact
generated from P satisfies C. A query–answer pair is either
an atomic QA-pair or an expression of the form ðP;PYsCÞ,where P is a set of projection facts (stamped or non-stam-
ped) {P1, ., Pl} such that every Pi, (i¼ 1, ., l ) is over Y and
satisfies C.
Similar to Brodsky et al. (2000), the database dependencies
will be defined by way of Horn-clauses (Ullman, 1988).
Definition 2.6. (Horn-clause constraint) Let r denote a relation
with schema R¼ {A1, ., Al}. Let D ¼ fd1;.dmg, where m> 0, be
a set of dependencies for R. Each di˛D is of the following form:
p1^/^pk/q (k� 1). The pi’s are called the prerequisites and
have the form R[A1¼ a1, ., Al¼ al], where ai is either
a constant or a variable that must appear in the prerequisite.
The consequence q can have the following forms:
1. If the consequence q is either of the form ai¼ aj (ai, aj ˛ R) or
ai¼ c (c ˛ dom(Ai)), then q represents an equality-generating
dependency
2. If the consequence q has the form R[A1¼ a1, ., Al¼ al]
where A1, ., Al are all of the attributes of the schema R (i.e.,
constraint is full) and each ai is either a constant or a vari-
able that must appear in the prerequisite pi(i¼ 1, ., k), then
q represents a tuple-generating dependency.

Fig. 2 – Dynamic Disclosure Monitoring (D2Mon) algorithm.
Table 2 – History file.
Time ID NAME RANK SALARY DEPARTMENT
ti 1 John ClerkManager d1 Toy
ti 2 Mary Secretary d2 Toy
tj 5 d3 Clerk $39,520 Appliance
c o m p u t e r s & s e c u r i t y 2 9 ( 2 0 1 0 ) 8 8 – 1 0 392
As an example, the FD: Rank / Salary would be defined as
follows:
Emp:ðN ¼ a1;R ¼ b;S ¼ c1;D ¼ d1Þ^Emp:
ðN ¼ a2;R ¼ b; S ¼ c2;D ¼ d2Þ/c1 ¼ c2: ð1Þ
Our examples are based on MAC, requiring a method to
assign security labels to the subjects and objects of the
system. Traditionally, the inference problem addressed
issues in multi-level security databases. Our examples will
follow this tradition; however, the proposed approach is
applicable to other access control models as we discussed
earlier.
Definition 2.7. (Security classification) Let SL be a set of security
labels, (e.g., unclassified, secret, top-secret, etc). A security
classification is a triple CO;U; lD, where O ¼ fo1;.ong is a set of
security objects, U is a set of subjects (users), and l : OWU/SL
is a mapping from the set of users and objects to the security
labels.
In our system, we will maintain in a history file a set of QA-
pairs along with the respective query answer times.
Definition 2.8. (History file entry) A history file entry consists of
a QA-pair along with the time that the QA-pair was answered.
An atomic QA-pair entry in the history file has the form [(P,
PYsC), t], where P is a projection fact over attributes Y that
satisfies a constraint C at time t. A set of QA-pair entries in the
history file has the form [(P,PYsC),t], where P is a set of
projection facts over Y that satisfies C at time t.
The following is an example of a history file entry:�P;PName;RanksDept:¼0Toy0 ; ti
�, where
P ¼�n
Emp:hName ¼ John;Rank ¼ ClerkManager
i;
Emp:½Name ¼ Mary;Rank ¼ Secretary�o; ti
�
From this history entry, it can be determined that at time ti,
John is a Clerk and Mary is a Secretary in the Toy department,
respectively. Since the Rank attribute of John has been
stamped with the value Manager, it can be determined that
John has been promoted to Manager at some time tj (ti< tj) and
the user is unaware of this information. This follows from
Definition 2.2.
In our architecture, we require two additional conditions
that a history file entry must adhere to. First, the attributes
that are in the selection condition of a query, but are not in the
projection condition of the query, are included in the projec-
tion fact. For example, if the projection fact constructed from
the result of the query PName,RanksDept¼‘Toy’ is non-empty, then
the corresponding tuples must have the value of Toy stored in
the Department attribute in the base relation. Therefore, this
query is modified to PName,Rank,Dept.sDept.¼‘Toy’. Secondly, we use
unique delta values (di, i> 0) to represent attribute values that
are not in the projection condition and cannot be implied from
the selection condition. The inference engine used by our
architecture computes the missing values that these delta
values represent in the base relation, indicating that these
values that can be inferred by the user.
We show in Table 2 the history file created by the events in
Example 1.2.
3. Dynamic Disclosure Monitor architecture
We now present and discuss the Dynamic Disclosure Monitor
(D2Mon) algorithm in Fig. 2. We then discuss the Update
Consolidator and Disclosure Inference Engine.
D2Mon first uses the Mandatory Access Control (MAC)
mechanism to inspect the current query for a direct security
violation. If a direct security violation is detected, then the
query request is rejected. Otherwise, the query is submitted to
the DBMS. After generating the query answer, the Update
Consolidator stamps the history file with any updates that have
occurred since the user’s last query request (i.e., Uupdated-history).
The current query results are combined with the updated (i.e.,
stamped) history file to create an Uall-disclosed history file. The
Disclosure Inference Engine (DiIE) computes any newly disclosed
data that can be inferred from Uall-disclosed and the database
dependencies. The extended set of disclosed data is evaluated
to determine if any sensitive information is disclosed. If no
security violations are detected, then the current query
request is accepted which means: 1) the query results are
returned to the user and 2) the Uall-disclosed history file becomes
the current history file, Uhistory. Otherwise, the query is rejected
and Uupdated-history becomes the current history file, Uhistory.

c o m p u t e r s & s e c u r i t y 2 9 ( 2 0 1 0 ) 8 8 – 1 0 3 93
We first define atom mapping which is used to apply the
Horn-clause dependencies.
Definition 3.1. (Atom mapping of dependencies) Given a Horn-
clause constraint p1, ., pn / q and a relation r over schema
R, we define an atom mapping as a function h:{p1, ., pn} / r
such that
1. h preserves constants; i.e., if h(R[.,Ai¼ c,.])¼ (c1, ., ci, .,
cm) ˛ r and c is a constant (i.e., c ˛ dom(Aj) W dom(SAj)), then
c¼ ci.
2. h preserves equalities; i.e., if pi¼ R[.,Ak¼ a,.], pj¼ R[.,Al¼a,.] and h
�pi
�¼ ðc1;.; ck;.; cmÞ;h
�pj
�¼�c01;.; c0l;.; c0m
�,
then ck ¼ c0l.
We now formally define how to apply a Horn-clause
dependency.
Definition 3.2. (Application of dependencies) A dependency d is
applied on a relation r by using an atom mapping h as follows:
1. If d is an equality-generating dependency of the form p1, .,
pn / a¼ b, where a and b are either free-variables occurring
in pi(i¼ 1, ., n) or constants, then equate h(a) and h(b) as
follows:
(a) If both h(a) and h(b) are null-values then replace all
occurrences of h(b) in r with h(a).
(b) If one of them, say h(a), is not a null-value, then replace
all occurrences of h(b) in r with h(a).
(c) If both are not null-values (i.e., constants), do nothing.
(d) If h(a) s h(b), we say that inconsistency occurred.
2. If d is a tuple-generating dependency of the form p1, .,
pn / R[A1¼ a1, ., An¼ an], where a1, ., an are either
constants or free-variables occurring in p1, ., pn, and the
tuple (h(a1), ., h(an)) is not in r, then add it to r.
We require that any variable or constant that appears in
the consequence of the dependency must also appear in the
prerequisite. This is necessary to guarantee that our inference
algorithm will terminate.
For example, suppose we use Definition 3.2 to apply the FD
defined in Equation (1) to the history file in Table 2. We would
have h( p1) map to (N¼ John, R¼ ClerkManager, S¼ d1, D¼ Toy) and
h( p2) map to (N¼ d3, R¼ Clerk, S¼ $38,000, D¼Appliance).
Because of the update, we cannot apply the FD; however, if the
update had not occurred, then we could apply the FD to get
c1¼ d1 and c2¼ $38,000 by Definition 3.2 (1).
The application of dependency process is a variation of the
Chase method (Ullman, 1988) as shown in Fig. 3.
Fig. 3 – Chase process.
Definition 3.3.. (Dynamic data-dependent disclosure) Let D be a set
of database constraints, UP ¼ fUP1;.UPmg a set of updates, P1,
., Pn be sets of projection facts over attribute sets X1, ., Xn, PF
be a projection fact over Y, and t1�. � tn� t be times. We say
that the set P ¼ f½ðP1;PX1 sC1 Þ; t1Þ�;.; ½ðPn;PXn sCn Þ; tn�gdiscloses [(PF, PYsC), t] under database constraints D and in the
presence of updates UP, if 1) no update occurred on Pi’s (i¼ 1,
., n) between tn and t, and 2) for every r0, r1, ., rn, r over R that
all satisfy D, Pi4PXisCiðriÞ at time ti for all i¼ 1, ., n implies
PF ˛ PYsC(r) at time t, where r0 is the original relation and ri
(i¼ 1, ., n), r are the relations generated from r0 by the
updates in UP, respectively. Dynamic data-dependent disclo-
sure is denoted as P~UP;D½ðPF;PYsCÞ; t�.Note that two relations ri and rj (i, j¼ 0, ., n and i s j ) may
be the same if no update occurred between ti and tj.
Given a set S of atomic QA-pairs and times, we say that
P~UP;DS if for every (atomic) QA-pair [(PF, PYsC), t] ˛ S,
P~UP;D½ðPF;PYsCÞ; t�. Finally, we denote by ½ðPF;PYsCÞ;t1�~UP[(PF0, PY
0sC0), t2] the disclosure f½ðPF;PYsCÞ; t1�g~UP;D
½ðPF0;PY0sC0 Þ; t2�, where D is empty. In this case, we say that
[(PF, PYsC), t1] dominates [(PF0, PY0sC0), t2].
We require that updates preserve the database
constraints; that is, if a relation r satisfies the set of
constraints D before an update, it will also satisfy D after the
update. Furthermore, disclosure is established based on
updated tuples rather than the originally released tuples.
Intuitively, this may allow a user, who is unaware of the
update, to infer a fact that may have never existed in the base
relation or is no longer valid. In either case, we allow such
‘‘wrong’’ inferences, since our goal is to prevent disclosure of
valid sensitive data.
We now define the dynamic data-dependency disclosure cover
which states the definition of sound and complete which we
will use to argue the correctness of our framework.
Definition 3.4.. (Dynamic data-dependent disclosure of P under D)
Given a set of dependencies D, a set of updates
UP ¼ fUP1;.;UPmg, and a set of QA-pairs with query pro-
cessing times P¼ {[(P1,Px1sC1),t1],.,[(Pn,PxnsCn),tn]}, where P
has been stamped with the updates from UP, where UP could
be empty. The dynamic data-dependent disclosure cover
under D, denoted as�D2DCDðPÞ
�, is defined as a set S of QA-
pairs [(PF, PYsC), t] that is:
1. Sound; i.e., for every [(P, PYsC), t] ˛ S and [(P0, PY0sC0), t],
½ðP;PYsCÞ; t�~½ðP0;PY0sC0 Þ; t�0P~D½ðP0;PY0sC0 Þ; t�2. Complete; i.e., for every [(PF0, PY
0sC0), t], P~D ½ðPF0;PY0sC0 Þ; t�
implies that there exists [(P, PYsC), t] in S such that
½ðP;PYsCÞ; t�~½ðPF0;PY0sC0 Þ; t�.
By extending the concepts of projection fact and query–
answer pairs to incorporate stamped attributes DiIE can
operate on relations containing regular attribute values
(constants), stamped attribute values, and null-values. Fig. 4
shows the DiIE algorithm.
In the following section we develop the Update Consoli-
dator (UpCon) module that creates a new input history file for
DiIE by stamping those attribute values that have been
modified by an update operation. Update Consolidator (UpCon)
propagates updates that happened since the last answered

Fig. 5 – Update Consolidator (UpCon) algorithm.
Fig. 4 – Disclosure Inference Engine (DiIE) algorithm.
c o m p u t e r s & s e c u r i t y 2 9 ( 2 0 1 0 ) 8 8 – 1 0 394
query. For this we require that every tuple of the relation has
a unique identifier and all original answers (extended by the
equalities required by the selection conditions of the
queries), are kept permanently. For efficiency, we also keep
track of the database dependencies D that were previously
applied on the history file. Intuitively, stamping of attributes
may limit the application of the dependencies but never
increases it.
Fig. 5 shows the UpCon algorithm. Table 2 shows the
stamped history file created by UpCon.
4. Inference collaboration prevention
In this section, we address the inference problem via collab-
oration of multiple users. That is, D2Mon can prevent security
violations between multiple users who may want to use their
query results together to reveal sensitive information. We
address three special cases of colluding users:
1. None of the users collude.
2. All users collude.
3. A subset of users may collude.
The first case, i.e., when none of the users collude, corre-
sponds to our original approach. We keep a separate history
file for each user. When a user requests a new query, only that
user’s history file is used in combination with the answer to
the current query and the known metadata to detect any
unauthorized inferences. This approach will give the highest
data availability.
The second approach corresponds to the case when users of
the same level may share their previously received data. Also,
users may share their data with higher security clearances but
not with users who have lower security clearances. For
example, assuming a Top-Secret (TS ), Secret (S ), Public (P) secu-
rity hierarchy, Secret users may access all the answers received
by Secret and Public users but not the answers received by Top-
Secret users. That is, there is no direct information flow
downward in the security lattice. To implement this approach,
D2Mon returned query results are stored in separate history
files for each security label. When a user requests a new query,
all answers at the user’s security clearance and at the security
levels dominated by the user’s security label are used along
with the current answer and the known metadata to detect any
unauthorized inferences. This is the most restrictive approach
and may severely limit data availability.
To counteract theshortcomingof theabove twoapproaches,
we propose a solution when subsets of all users are evaluated
for potential unauthorized disclosure. Our approach requires at
least k number of users to collude to be able to access the
unauthorized data item. Based on practical consideration, such
as existing real life policies and complexity of our inference
algorithm, we chose the number 3 as k. That is, if no security
violation is detected in any pairwise combination of the current
user and the other users at or a lower security level of the
current user, then the user’s query can be answered.
Similarly to case one, we keep a separate history file for
each user. When a user requests a new query, the user’s
history file, the current query answer, the known metadata,
and the history files of each users at equal or lower security
levels than the security level of the current user are evaluated
together. This evaluation is performed separately for each of

c o m p u t e r s & s e c u r i t y 2 9 ( 2 0 1 0 ) 8 8 – 1 0 3 95
the other users. So, if there are n number of other users with
equal or lower security clearance than the current user, n
number of inference detection must be performed and n
number of new history files stored for the user. On the other
hand, we assume that if the user colluded with a particular
user, it is unlikely that he will find any other user to collude
with. This assumption is in accordance of current practices in
several domains with high security needs.
5. Dynamic data-dependent disclosure
In this section we present our theoretical results. In particular,
we discuss our findings regarding the soundness and
completeness of our algorithms and the decidability of the
dynamic disclosure problem.
Theorem 5.1. (Dynamic data decidability) If data values cannot be
modified to their original values and tuples cannot be reinserted, the
following problem is decidable: Given a set D of database
constraints, set of updates UP, and a set P of QA-pairs with query
times, whether P~UP;D½SðtÞ� for a given set S of atomic QA-pairs at
time t.
Theorem 5.1 will be a corollary to Theorem 5.2 that states
correctness (i.e., soundness and completeness) of DiIE in the
presence of updates.
Proposition 5.1. Given a set D¼ d1, ., dk of dependencies that can
be applied by DiIE on a set of non-stamped projection facts S, i.e.,
projection facts without stamped attributes. Then at most D¼ d1, .,
dk can be applied on S0, a set of stamped projection facts generated
from S by stamping some of the attribute values.
Proof 5.1. Let S be a set of projection facts and U be a set of
database updates. Let S0 be a set of stamped projection facts
constructed by stamping S with U and let D¼ d1, ., dk be a set
of dependencies that can be applied to S.
Assume by contradiction that a dependency dm can be
applied on S0 but not on S and that dm ; D. Assume that
a stamped projection fact s0i˛S0 was constructed by stamping
a non-stamped projection fact si ˛ S and by Definition 2.4 of
a stamped projection fact, let s0i be the only stamped projection
fact in S0. We need only consider two cases: 1) If s0i does not
participate in the valuation of the body of dm and 2) if s0i does
participate in the valuation of the boy of dm. ,
Case 1. Suppose that s0i does not participate in the valua-
tion of the body of dm. Then the body of dm must contain non-
stamped projection facts from S.
Since the body of dm contains non-stamped projection facts
(i.e., projection facts from S ), then this asserts that dm must
also be applicable to S and we have a contradiction.
Case 2. Suppose that s0i does participate in the valuation of
the body of dm.
But because stamping cannot introduce new equalities,
then si (the un-stamped attribute) must have also participated
in the valuation of the body of dm. Therefore, dm must be
applicable to S and we have a contradiction and this
completes the proof.
Corollary 5.1. (Algorithm 3: Update Consolidator) Given a base
relation, a history file of un-stamped projection facts, and an update
log. Then Algorithm 3 correctly stamps the attributes in the history
file with the updates from the update log
That is, an attribute is stamped iff an update occurred on that
attribute in the base relation. The proof trivially follows from Algo-
rithm 3 andDefinition 2.1.
Theorem 5.2. If data values cannot be modified to their original
values and tuples cannot be reinserted, the data-dependent disclo-
sure inference algorithm is sound and complete.
Proof 5.2. Theorem 5.2 states that Disclosure Inference Engine
(DiIE) Algorithm in Fig. 4 computes the dynamic data-depen-
dency disclosure cover in Definition 3.4, which is sound and
complete. To prove Theorem 5.2, we shall prove the following
claims. ,
Claim 1. Let r be a relation, D be a set of database constraints
satisfied by r, UP ¼�
up1;.;upm
�a set of updates, and
P ¼ fP1;.; Png be a set of non-stamped QA-pairs with query pro-
cessing times. If UP is empty (i.e., UP ¼ B)then Algorithm 4
inFig. 4is sound and complete
This follows from the fact that we extended the data-
dependent inference engine that is sound and complete in
static databases to handle dynamic databases. But, if UP is
empty, then stamping P with UP will create a stamped set of
QA-pairs, P0, where P0 ¼ P. This asserts that UP ¼ B is a special
case of Algorithm 4 where r is static. Therefore, Algorithm 4 is
sound and complete when UP ¼ B. This completes Claim 1.
We now present the proof of soundness and completeness
as a claim when the update log is non-empty.
Claim 2. Let r be a base relation, D be a set of database constraints
satisfied by r, UP ¼�
up1;.;upm
�a set of updates, and
P ¼ fP1;.; Png be a set of non-stamped QA-pairs with query pro-
cessing times. If UP is not empty (i.e., UPsB) and P0 is constructed
by stamping P with UP, then there exists a mapping from P to P0 that
is sound (i.e., only valid equalities exist) and complete (i.e., all valid
equalities used by the inference algorithm in applying database
constraints remain intact).
Proof of Soundness. Let UP ¼�
up1;.;upm
�be a set of updates
andletD ¼ d1;.; dk beaset ofdatabaseconstraints.Let P be aset
of non-stamped QA-pairs that satisfy D and let r1 be a relation
constructed by performing Step 1 of the inference algorithm in
Fig. 4 using P and D as input. By Claim 1, there exists a mapping
from r1 to r2 (i.e., a relation constructed from a stamped set of
QA-pairs) if UPsB. We need to show that if UPsB and r1 is
stamped with UP then there exists anatommapping from r1 to r2
such that only valid equalities are preserved.
Using the same approach that was used in proving Propo-
sition 5.1 without loss of generality assume that tuple t ˛ r1 was
stamped and suppose that dm ˛ D is satisfied by r1 and that
tuple t participates in the valuation of the body of dm. It follows

c o m p u t e r s & s e c u r i t y 2 9 ( 2 0 1 0 ) 8 8 – 1 0 396
from Proposition 5.1 that either r2 satisfies dm or r2 does not
satisfy dm. If r2 satisfies dm, then there must exist an atom
mapping from a tuple t ˛ r1 to a corresponding tuple t0 ˛ r2 that
preserves equalities (i.e., t¼ h(t0)), where h is the atom mapping
of dependencies of Definition 3.1. If r2 does not satisfy dm, then
t s h(t0), which still satisfies our goal that only valid equalities
are preserved. This completes the proof of soundness. ,
Proof of Completeness. Let r be a relation, D be a set of database
constraints satisfied by r, UP ¼�
up1;.;upm
�a set of updates,
P ¼ fP1;.; Png be a set of non-stamped QA-pairs with query
processing times, and P ¼�
P01;.; P0n�
be a set of stamped QA-
pairs constructed by stamping P with UP. We need to consider
several cases that can occur when P is stamped with UP. ,
Case 3. Suppose that none of the attributes that are stamped
participate in the valuation of the body of any dependency
di˛Dð1 � i � nÞ.
Trivially, we have an atom mapping from P to P0 that
satisfies the completeness constraint. This completes Case 3.
Case 4. Suppose that some of the attributes that are stamped
participate in the valuation of the body of a di˛Dð1 � i � nÞ.
Let a tuple t be correctly disclosed from the originally
released QA-pairs P, the current query answer, the database
dependencies D, and the updates UP. We need to show that
tuple t is generated by DiIE applied on the set of stamped
projection facts P0.
Assume by contradiction that a tuple t is correctly disclosed
from P (i.e., originally released tuples), the current query
answer, the database dependencies D ¼ d1;.; dl and the
updates, but t was not generated by DiIE applied on the stam-
ped set of QA-pairs, P0. Since t is disclosed, DiIE must have
generated a set of projection facts (PF) that contains t if the
original set of projection facts P, the current query answer and
the database dependencies D are given as input. The disclosed
query t clearly cannot be one of the originally released projec-
tion facts, because those are stored in the stamped set of
projection fact P0 and stamps are only added according to the
updates. But then, t must have been generated by a sequence of
dependency applications d1, ., dl. But since the updates
satisfied the database dependencies and t is correctly disclosed
based on valid inferences then d1, ., dl must be applicable on
the stamped projection facts P0. But then, DiIE must have
applied d1, ., dl on the stamped projection facts P0, thus
creating a tuple that coincides with t on the non-stamped
attributes. This is a contradiction of our original assumption,
which completes the proof of Case 4. Claim 2 and the proof of
completeness is completed, respectively.
6. Performance analysis
6.1. Complexity analysis
The complexity of D2Mon (Fig. 2) is determined by the
complexity of DiIE(Fig. 4) and UpCon(Fig. 5), respectively.
UpCon takes each entry of the Update Log and applies the
update to the corresponding entry in the history file. Each
Update Log entry can be applied to a corresponding entry in the
history file in O(n $ m) time, where n is the size of the history
file and m is the size of the Update Log.
DiIE applies the equality-generating and tuple-generating
dependencies, respectively. For each dependency the prereq-
uisite of the dependency must be satisfied. So, for a dependency
p1^/^pk/h, where k> 1, each pi (i¼ 1, ., k) is matched to an
entry in the history file. Then, h is processed as either a equality-
generating dependency or a tuple-generating dependency.
Since eachpi must beapplied to eachentry inthe historyfile, this
operation can be done for one dependency in O(nk), where n is
the size of the history file and k is the number of prerequisites in
an individual dependency. Assuming that each dependency has
a maximum of k prerequisites, the total complexity for DiIE is
O( p $ nk), where n is the size of the history file, k is the number of
prerequisites in the dependency, and p is the total number of
databasedependencies. So, the complexity ofD2MonisO( p $ nk).
6.2. Experimental results
We developed a prototype of the D2Mon framework using Java
1.6.0. The prototype ran on a Dell OPTIPLEX 745 machine that
contained an Intel Core 2 Duo processor running at a speed of
1.86 GHz. This computer contained 1.99 gigabytes of RAM and
is running Windows XP Professional. The database manage-
ment system that we used was Oracle 10.3 g.
We used the following relational schema: Employee(Id,
Name, Rank, Salary, Department, Hiredate). The database
constraint is Rank / Salary. We assume that there are two
security labels (i.e., confidential and public). The security
requirement is that Name and Salary together are confidential.
That is, only a person who has confidential clearance is allowed
to retrieve or infer a person’s salary. We assume that all
SELECT queries are submitted by a public user, while the
update queries are submitted by an authorized user.
We use the number of operations to show the performance
of D2Mon. The operations are as follows:
1. The number of operations to compute inferences (i.e.,
application of dependencies).
2. The number of operations to construct and store update
entries in the update log.
3. The number of operations to stamp the history file.
Since the DBMS is independent of our framework, we do
not consider the DBMS in our performance analysis.
We conducted two simulations with a single user and two
simulations with two users, respectively.
6.2.1. Experiment 1: single userIn this experiment, we compare the results of 1) a set of
queries without updates (Test Case 1) and 2) a set of queries
that includes updates (Test Case 2).
The test cases that were used are as follows:
Test Case 1.
Query 1: SELECT Name, Rank FROM Employee WHERE
Department¼ ‘TOY’

Table 3 – Simulation of D2Mon with one user.
Sim. Tuples Test Case 1 Test Case 2
Q1 Q2 % Q1 Q2 %
1 2000 52,063,838 11,946,988 (77) 52,063,838 7,798,070 (85)
2 4000 412,973,491 47,387,376 (89) 412,973,491 31,270,552 (92)
3 6000 1,345,120,707 105,872,292 (92) 1,345,120,707 69,808,666 (95)
4 8000 3,212,149,758 187,977,570 (94) 3,212,149,758 124,321,576 (96)
5 10,000 6,278,428,274 291,603,818 (95) 6,278,428,274 193,897,915 (97)
c o m p u t e r s & s e c u r i t y 2 9 ( 2 0 1 0 ) 8 8 – 1 0 3 97
Query 2: SELECT Salary, Rank FROM Employee WHERE
Department¼ ‘APPLIANCE’ AND Rank¼ ‘CLERK’
Test Case 2. (2)
Query 1: SELECT Name, Rank FROM Employee WHERE
Department¼ ‘TOY’
Update: UPDATE Employee SET Rank¼ ‘MANAGER’ WHERE
Name¼ ‘JOHN’
Update: UPDATE Employee SET Salary¼ 45,000 WHERE
Name¼ ‘JOHN’
Update: UPDATE Employee SET Salary¼ 39,500 WHERE
Rank¼ ‘CLERK’
Query 2: SELECT Salary, Rank FROM Employee WHERE
Department¼ ‘APPLIANCE’ AND Rank¼ ‘CLERK’
We randomly generated several instances of the Employee
database that contained 2000, 6000, 8000, and 10,000 tuples,
respectively. Each test case was ran against the respective
database instance.
Table 3 shows the results from both test cases, which
includes the number of operations for Q1, the number of
operations for Q2, and the change in percent of the number of
operations between Q1 and Q2. In both Test Cases, Q1 was
accepted. In Test Case 1, Q2 is rejected because the results
from Q2 can be combined with the results from Q1 and the FD:
Rank / Salary to infer that John’s salary is $35,000 (i.e., a valid
inference). However, when we ran Test Case 2, Q2 was indeed
accepted. The FD could not be applied because of the updates.
We notice that in each simulation of Test Case 1 and Test
Case 2, the number of operations decreased from Q1 to Q2,
respectively. As we would expect, the number of operations
decreased significantly in the simulations in which we stam-
ped the history file. This is because our stamp process reduces
the number of times the FD can be applied. Fig. 6 compares the
number of operations of Q2 in both test cases.
6.2.2. Experiment 2: single userWe used a database of 5000 tuples and fifty randomly gener-
ated SELECT queries in two simulations.
The first simulation submitted these queries against the
database. We then inspected the results of the first simulation
2 We acknowledge that these updates should be performed ina single update (i.e., transaction); however, some DBMS (e.g.,miniSQL) may not support updates that contained expressionssuch as Salary¼ Salary� 1.04 when we began developing theprototype in 2000. We may revisit this issue in future work.
to determine which queries were either rejected or accepted
by D2Mon. Fig. 7 shows the result of this simulation.
We found that there were a total of 20 queries that were
rejected by D2Mon. There were 12 queries that were rejected
because the user did not have the authority to submit the query.
Notice that in Fig. 7 the number of operations for these queries
is zero because no inference processing was performed. The
remaining 8 queries were rejected because the query results
could be used to infer some sensitive information.
In the second simulation, our goal was to get the 8 queries
that could infer sensitive information to be accepted. To
accomplish this, we generated the necessary updates that
would produce ‘‘wrong’’ inferences. So, for this simulation, we
ran the same fifty queries. However, we ran updates before
the respective 8 queries. The graph of this simulation is shown
in Fig. 8. Of course, the 12 queries rejected in the first simu-
lation were again rejected; however, the other 8 queries were
accepted.
The graph from Figs. 7 and 8 appear to be polynomial, which
supports our theoretical claim of the complexity of D2Mon.
6.2.3. Experiment 3: two usersWe again ran two simulations for this experiment in which we
used the same queries as in Test Case 1 and Test Case 2,
respectively; however, we simulate a multi-user environment
by submitting queries as if different public users submitted
the queries (i.e., Bob and Alice).
The following show the test cases that we used:
Test Case 3. Test Case 1 is modified to assign Query 1 to Bob
and Query 2 to Alice.
Test Case 4. Test Case 2 is modified to assign Query 1 to Bob
and Query 2 to Alice.
Fig. 6 – Single user simulation of D2Mon comparing Q2
operations.
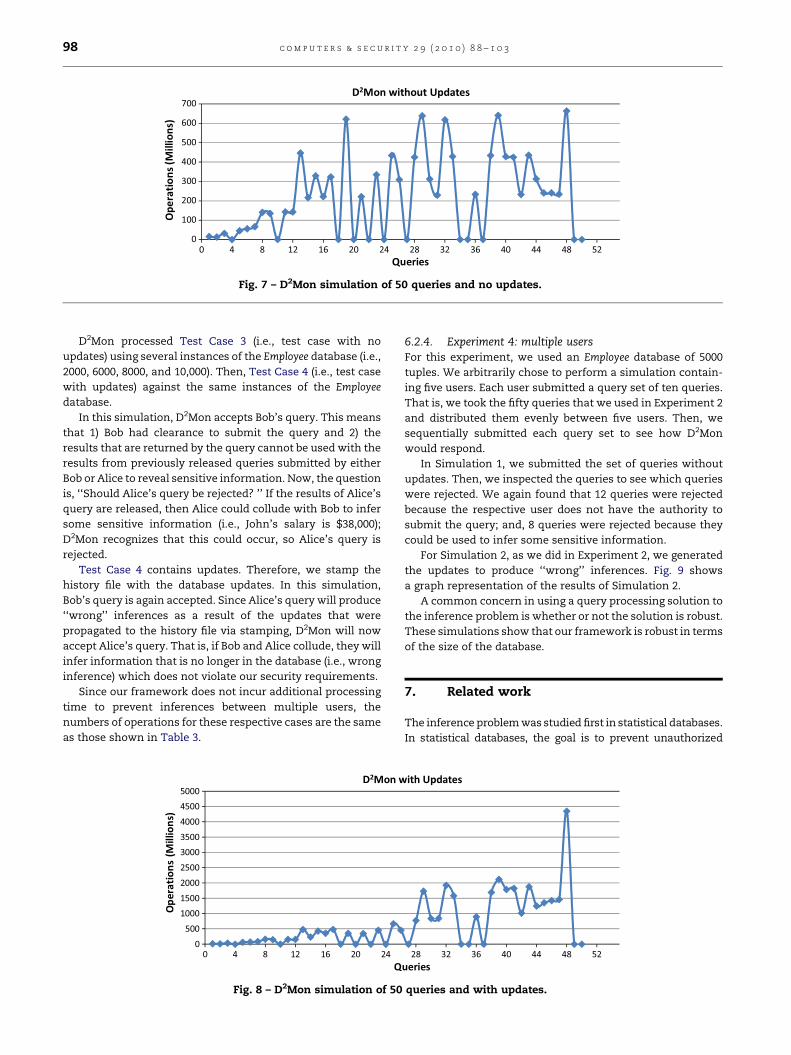
Fig. 7 – D2Mon simulation of 50 queries and no updates.
c o m p u t e r s & s e c u r i t y 2 9 ( 2 0 1 0 ) 8 8 – 1 0 398
D2Mon processed Test Case 3 (i.e., test case with no
updates) using several instances of the Employee database (i.e.,
2000, 6000, 8000, and 10,000). Then, Test Case 4 (i.e., test case
with updates) against the same instances of the Employee
database.
In this simulation, D2Mon accepts Bob’s query. This means
that 1) Bob had clearance to submit the query and 2) the
results that are returned by the query cannot be used with the
results from previously released queries submitted by either
Bob or Alice to reveal sensitive information. Now, the question
is, ‘‘Should Alice’s query be rejected? ’’ If the results of Alice’s
query are released, then Alice could collude with Bob to infer
some sensitive information (i.e., John’s salary is $38,000);
D2Mon recognizes that this could occur, so Alice’s query is
rejected.
Test Case 4 contains updates. Therefore, we stamp the
history file with the database updates. In this simulation,
Bob’s query is again accepted. Since Alice’s query will produce
‘‘wrong’’ inferences as a result of the updates that were
propagated to the history file via stamping, D2Mon will now
accept Alice’s query. That is, if Bob and Alice collude, they will
infer information that is no longer in the database (i.e., wrong
inference) which does not violate our security requirements.
Since our framework does not incur additional processing
time to prevent inferences between multiple users, the
numbers of operations for these respective cases are the same
as those shown in Table 3.
Fig. 8 – D2Mon simulation of 50
6.2.4. Experiment 4: multiple usersFor this experiment, we used an Employee database of 5000
tuples. We arbitrarily chose to perform a simulation contain-
ing five users. Each user submitted a query set of ten queries.
That is, we took the fifty queries that we used in Experiment 2
and distributed them evenly between five users. Then, we
sequentially submitted each query set to see how D2Mon
would respond.
In Simulation 1, we submitted the set of queries without
updates. Then, we inspected the queries to see which queries
were rejected. We again found that 12 queries were rejected
because the respective user does not have the authority to
submit the query; and, 8 queries were rejected because they
could be used to infer some sensitive information.
For Simulation 2, as we did in Experiment 2, we generated
the updates to produce ‘‘wrong’’ inferences. Fig. 9 shows
a graph representation of the results of Simulation 2.
A common concern in using a query processing solution to
the inference problem is whether or not the solution is robust.
These simulations show that our framework is robust in terms
of the size of the database.
7. Related work
The inference problem was studied first in statistical databases.
In statistical databases, the goal is to prevent unauthorized
queries and with updates.
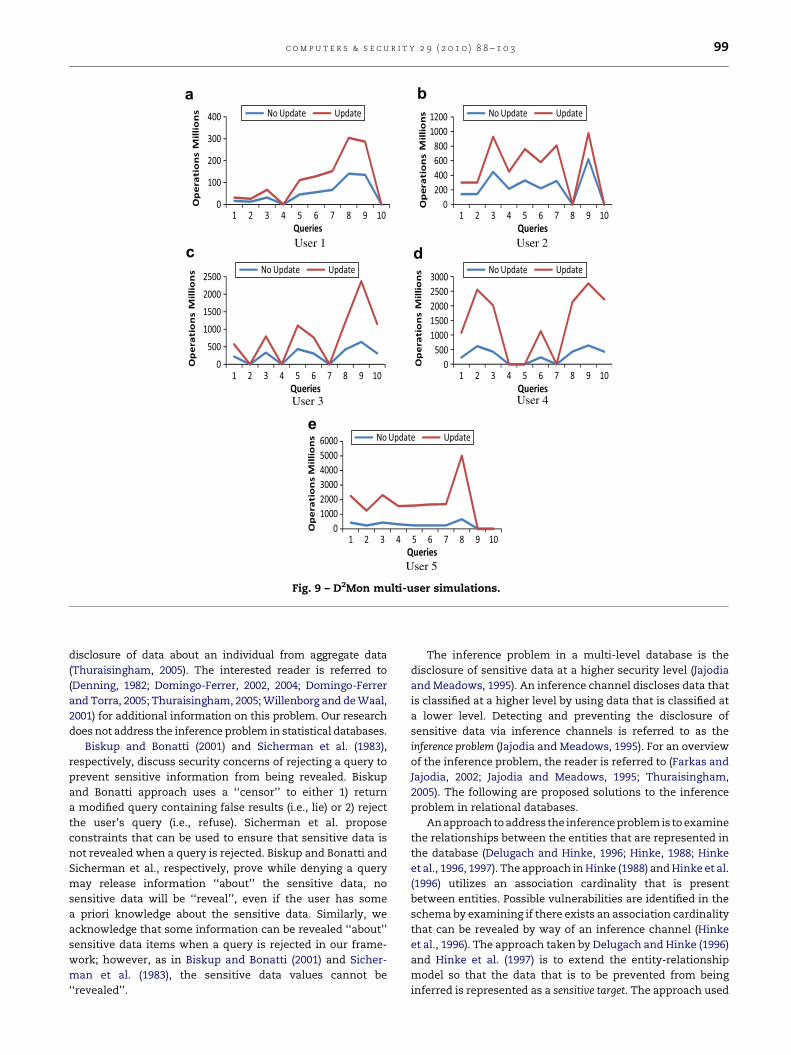
Fig. 9 – D2Mon multi-user simulations.
c o m p u t e r s & s e c u r i t y 2 9 ( 2 0 1 0 ) 8 8 – 1 0 3 99
disclosure of data about an individual from aggregate data
(Thuraisingham, 2005). The interested reader is referred to
(Denning, 1982; Domingo-Ferrer, 2002, 2004; Domingo-Ferrer
and Torra, 2005; Thuraisingham, 2005; Willenborg and de Waal,
2001) for additional information on this problem. Our research
does not address the inference problem in statistical databases.
Biskup and Bonatti (2001) and Sicherman et al. (1983),
respectively, discuss security concerns of rejecting a query to
prevent sensitive information from being revealed. Biskup
and Bonatti approach uses a ‘‘censor’’ to either 1) return
a modified query containing false results (i.e., lie) or 2) reject
the user’s query (i.e., refuse). Sicherman et al. propose
constraints that can be used to ensure that sensitive data is
not revealed when a query is rejected. Biskup and Bonatti and
Sicherman et al., respectively, prove while denying a query
may release information ‘‘about’’ the sensitive data, no
sensitive data will be ‘‘reveal’’, even if the user has some
a priori knowledge about the sensitive data. Similarly, we
acknowledge that some information can be revealed ‘‘about’’
sensitive data items when a query is rejected in our frame-
work; however, as in Biskup and Bonatti (2001) and Sicher-
man et al. (1983), the sensitive data values cannot be
‘‘revealed’’.
The inference problem in a multi-level database is the
disclosure of sensitive data at a higher security level (Jajodia
and Meadows, 1995). An inference channel discloses data that
is classified at a higher level by using data that is classified at
a lower level. Detecting and preventing the disclosure of
sensitive data via inference channels is referred to as the
inference problem (Jajodia and Meadows, 1995). For an overview
of the inference problem, the reader is referred to (Farkas and
Jajodia, 2002; Jajodia and Meadows, 1995; Thuraisingham,
2005). The following are proposed solutions to the inference
problem in relational databases.
An approach to address the inference problem is to examine
the relationships between the entities that are represented in
the database (Delugach and Hinke, 1996; Hinke, 1988; Hinke
et al., 1996, 1997). The approach in Hinke (1988) and Hinke et al.
(1996) utilizes an association cardinality that is present
between entities. Possible vulnerabilities are identified in the
schema by examining if there exists an association cardinality
that can be revealed by way of an inference channel (Hinke
et al., 1996). The approach taken by Delugach and Hinke (1996)
and Hinke et al. (1997) is to extend the entity-relationship
model so that the data that is to be prevented from being
inferred is represented as a sensitive target. The approach used

c o m p u t e r s & s e c u r i t y 2 9 ( 2 0 1 0 ) 8 8 – 1 0 3100
in Hinke et al. (1997) can identify inferences in the schema,
group and database instance. In particular, an inference engine
called Merline was developed to examine the inference
vulnerabilities in a relational database (Hinke et al., 1997).
Another approach to the inference problem is to provide
a minimal classification that will promote availability of data,
while preventing the sensitive data from being inferred
(Dawson et al., 1999a,b). Simpler classification constraints are
constructed from examining existing classification
constraints. Because these classification constraints are
simpler than the original constraints, they can be quickly
applied to an instance of a database to construct a ‘‘minimally
classified database’’ (Dawson et al., 1999b). Goguen and Mese-
guer (1984) discuss unwinding the security policies in a data-
base. That is, the security policies are unwound into simpler
security policies, which can inductively be proven to be correct.
Morgenstern (1988) presents a framework that can be used
to control inferences by using a concept called the sphere of
influence (SOI) to restrict inferences. The base data refers to
entities, attributes, relationships, and inference rules
(constraints). Several solutions are presented by Morgenstern
(1988). The following solutions are given for an inference
channel consisting of a set of objects: 1) raise the security
clearance of that object to an appropriate classification, 2)
impose an aggregation classification on the set and classify
the aggregation at an appropriate level, and 3) introduce noise
into the inference channel, which would prevent precise
inference from being revealed. Morgenstern also proposes the
idea of simply accepting the inference channel and moni-
toring it for future actions (e.g., audit trails).
Su and Ozsoyoglu (1991) examine inference resulting from
functional dependencies (FD) and multivalued dependencies
(MVD) in a relational database. They referred to these infer-
ence violations as FD compromise and MVD compromise,
respectively. In the case of an FD compromise the solution
proposed is to adjust the attributes that are involved such that
the compromise is removed. A similar approach is presented
with MVD compromise; however, adjusting the classification
of the tuple is proposed.
The solution to the inference problem proposed by Marks
(1996) forms equivalence classes from the query results
returned from the database. The equivalence classes are then
used to construct a graph, which can be used to reveal infer-
ences. The query results are referred to as views. The two
types of views that are discussed are referred to as total_-
disclosed and cover_by, respectively. A total_disclosed view is
when a view is created from different views, while a cover_by
view is a view where releasing a tuple in one view discloses
tuples in another view (Marks, 1996). The inference process is
to convert a query to a view and insert it into the graph. Then,
inspect the graph to see if it will introduce any inference
channels that will lead to some sensitive data. If it does, then
reject the query; otherwise, release the current query results.
Because the approach presented by Marks examines infer-
ences at the attribute level, preprocessing can be done by
examining the query before execution to see if it contains
attributes that will produce an inference channel that will
reveals sensitive data. Obviously, in this approach, if the query
produces an inference channel before execution, then the
results from the queries will as well.
The inference engine presented by Thuraisingham (1987) is
used to augment the relational database by acting as an
intermediary between the queries and the database. The
inference engine uses first order logic to represent queries,
security constraints, environment information, and real world
information. That is, the inference engine converts the
current query to first order logic. The first order logic query is
then compared against the database constraints to determine
if a security constraint will be violated. If a security violation
exists, the query is rejected; otherwise, the query is converted
into relational algebra and forwarded to the database for
execution. The results that are returned from the database are
assigned classification labels that ensure that no security
violation exists.
Stachour and Thuraisingham (1990) propose a system
called Lock Data Views (LDV). This approach to the inference
problem is similar to Thuraisingham (1987). That is, the
solution proposed by Stachour and Thuraisingham performs
query processing that involves converting a query to an
internal format, determining if a violation exists by submit-
ting the query to the database management system (DBMS)
and classifying the query results accordingly. Unlike the
approach presented by Thuraisingham (1987), the approach
presented in Stachour and Thuraisingham (1990) runs on top
of a trusted computing base called LOgical Coprocessing
Kernel (LOCK) and is dependent on LOCK functioning correctly
(i.e., securely).
Yip and Levitt (1998) discuss an inference detection system
that utilizes five inference rules to uncover any possible
inference channels that may be present. These rules are
applied to the initial query and the query results to determine
if an inference channel exists. These rules are sound, but not
necessarily complete.
Staddon (2003) presents a query processing solution to the
inference problem that does not use a query history database.
Users get access to data by using keys which generate access-
enables tokens. Staddon uses a concept called crowd control that
monitors the number of users that have accessed the number
of data items in an inference channel. Staddon considers the
inference problem from the perspective of dynamic access
control to the data items within an inference channel. That is,
access to data items in an inference channel by one or more
users is allowed provided that the number of data items
accessed does not exceed a predetermined limit. Staddon does
not consider the effects of updating data items that have been
previously released.
Woodruff and Staddon (2004) present a query processing
solution to the inference problem that protects the disclosure
of sensitive data, while also protecting the server from
learning what data items were requested by the user.
Although the approach presented ensures that the server does
not learn what data items the user has requested, this
approach does not consider the effects that updates on
previously released data items have on increasing data
availability.
Chen and Chu (2006) present a query processing solution to
the inference problem which uses a history log. Their frame-
work consists of a Knowledge Acquisition module, a Semantic
Inference Model (SIM) module, and a Security Violation
Detection module. The knowledge acquisition module uses

c o m p u t e r s & s e c u r i t y 2 9 ( 2 0 1 0 ) 8 8 – 1 0 3 101
the database schema and database data to extract database
dependencies knowledge, data scheme knowledge, and
domain semantic knowledge. This extracted knowledge is
used to form SIM, which is an inference model that shows
‘‘links’’ between entities and related attributes along with
semantic knowledge about the database; each link is assigned
a probability value. Their framework uses SIM to construct
inference channels between entities and attributes. In
particular, a Semantic Inference Graph (SIG) is constructed
from the SIM module to be used in the inference process. That
is, using the current query (i.e., query results), query log (i.e.,
previous query results), and the SIG module reveals informa-
tion that has a probability that is above a specified threshold,
then their framework indicates that a security violation exists
and the current query is rejected; otherwise, the current query
is accepted. To address inferences via collaboration, Chen and
Chu (2006) include a collaboration analysis module. This
module uses 1) authoritativeness of the information source
and 2) fidelity of communication channel between source and
recipient to determine inference collaboration of sensitive
information. Again, if the collaboration between users is
higher than a predetermined threshold, then the query is
rejected; otherwise, the query is accepted.
Similar to our approach, this solution uses the current
instance of the database to determine what data items will be
released; however, this approach may be computationally
expensive. While it is not clear, it appears as though the
authors will rebuild the knowledge acquisition module, the
SIM module, and the SIG when a database update occurs. This
will ensure that their inference framework reflects the current
state of the database. While this may not be an issue for
a static database, it could be expensive in the presence of
updates. The authors do address some computational
concerns of computing inferences by mapping the SIG to
a Bayesian network (Chen and Chu, 2006, 2008), but this
approach does not address the computational cost of updates.
Moreover, the authors do not consider inferences that reveal
outdated data items.
Unlike the approach by Chen and Chu (2006, 2008), D2Mon
does not have to be trained. Our framework prevents infer-
ence in either a single or a multi-user environment (i.e.,
collaboration inference). Our framework is robust in regards
to updates and database size.
8. Future research directions
Currently our framework allows the user to derive ‘‘wrong’’
inferences, regardless of whether the derived data had
previously existed in the relation or not. However, in certain
applications even outdated data might be sensitive. For
example, we may want to protect the information that John
earned $38,000 when working as a clerk. Our update log
based model can be extended to detect different types of
inferences that are the result of a sequence of updates. That
is, we keep only the released data items and the most current
update in the history file. However, the update log contains
all of the updates that have occurred. We could use the
update log as a secondary history file which shows the
history of updates. By mining the update log, we can identify
an update sequence that either reveals sensitive data (i.e.,
a sensitive ‘‘wrong’’ inference) or does not reveal sensitive
data (i.e., a non-sensitive ‘‘wrong’’ inference). For example,
suppose that John’s Rank had the following update sequence:
Clerk, Manager, and Clerk. Through a set of subsequent
queries that the user submits, this update sequence may be
revealed from the response that the user receives from the
DBMS. Even if a query is rejected, a set of negative responses
could reveal this update sequence. The interested reader is
referred to Ishihara et al. (2002) for a discussion of negative
inferences. So, it is possible that an update sequence could
reveal that John was promoted and then demoted, which is
a ‘‘wrong’’ inference that we may not want to reveal; or, the
update sequence could represent an erroneous promotion
that was created and corrected via a sequence of updates.
We need to develop a process by which we can classify and
identify these update sequences.
It could be the case that wrong inferences may reveal an
updated value from the base relation, which in turn could
disclose some sensitive data. Again, consider the Employee
relation in Table 1 with the FD: RANK / SALARY.
Example 8.1. Suppose that the following queries are
submitted:
Query 1. ‘‘List Rank and Department of the employee John
working in the Toy Department.’’ (select Name, Rank,
Department from Employee where Name¼ ‘John’).
Update. ‘‘Update John’s Rank to Manager and Salary to
$45,000.’’ (update Employee set Rank¼ ‘MANAGER’,
Salary¼ 45,000 where Name¼ ‘JOHN’).
Update. ‘‘Update all Clerk’s Salary to $44,000.’’ (update
Employee set Salary¼ 44,000 where Rank¼ ‘CLERK’).
Query 4. ‘‘List the Salary of the Clerks in the Appliance Depart-
ment.’’ (select Salary, Rank from Employee where
Department¼ ‘APPLIANCES’ and Rank¼ ‘CLERK’).
Since John’s exact Salary cannot be inferred via the results
from Query 2, D2Mon will release the data values that are
retrieved via Query 2. However, the updated value is close to
the outdated value, so releasing the outdated value does
reveal the updated value.
Example 8.1 is an example of an interval-based inference.
We can prevent interval-based inferences by defining an
interval for which update values must not fall within. If an
update is outside a predefined interval, then we will stamp the
history file. Otherwise, we will not stamp the history file and
allow our system to compute inferences as if no update has
occurred. We will need to define a distance metric to define
the intervals and to determine if the update values are within
the intervals.
A common concern in performing inference analysis at
query processing time is that there could be negative effect on
performance and resources usage (e.g., CPU processing and
history file storage). Currently, D2Mon utilizes all of the tuples
that are returned from a query in computing inferences, which
obviously can be expensive in terms of computation and space
resources. In fact, there could be tuples in the history file that
can be omitted from the inference process. Consider again
Table 2 and the FD defined in Equation (1) (i.e., RANK /

c o m p u t e r s & s e c u r i t y 2 9 ( 2 0 1 0 ) 8 8 – 1 0 3102
SALARY ). Once we have h( p1) / (John,ClerkManager,d1,Toy), then
we know that any tuple to which h( p2) maps to must contain
Rank¼ ClerkManager. That is, the mapping of p1 determines the
mapping of p2. By using this observation, we can form an index
table from the prerequisites of the database dependency to the
tuples in the history file that satisfy the database dependen-
cies. The process of computing inferences for a database
dependency reduces to a linear traversal of the index table.
This process should reduce the inference and space
complexity. Brodsky et al. (2000) presents a ‘‘dominance’’
process that removes a tuple if it is dominated by another tuple.
We have proposed some preliminary work that uses the
concept of a Prerequisite Index Mapping Table to access the
history file in polynomial time (Toland et al., 2005). These two
concepts could be modified and applied to D2Mon to reduce the
size and access time of the history file, respectively.
Although our model does prevent user collusion, another
approach may be possible that includes additional user
characteristics in addition to the user’s security clearance.
One approach would be to define groups of potential
collaborators based upon user characteristics such as secu-
rity profile, access privilege, organizational role, and role
assignment. For example, users in the same physical loca-
tion may be more likely to collaborate than users in different
locations. Based on these wide characteristics, finding the
best characteristics to group possible collaborating users is
domain specific. A different approach would protect against
a specified level of collaboration as in Chen and Chu
(2006,2008). For this, the mechanism must require that no
less than k number of users can disclose sensitive informa-
tion by combining their data. Implementation of this model
requires the maintenance of the history database for all
subsets of k users, which is
�nk
. For example, if for 10
users, we require no fewer than 3 users can collude, then we
would have to monitor no fewer than
�103
¼ 120 subsets.
Since this is computationally expensive, a combination of
both approaches would be better.
9. Conclusion
In this paper we present a Dynamic Disclosure Monitor
(D2Mon) architecture that guarantees data confidentiality and
maximal data availability in the presence of inferences based
on database constraints and updates. We propose an exten-
sion of DiMon that incorporates the effects of updates in order
to increase data availability. We propose a component called
Update Consolidator (UpCon) which uses the user’s existing
history file, database updates, and database constraints to
generate a new history file that does not contain any outdated
data values. We show that using UpCon with DiIE will guar-
antee data secrecy (completeness property of inference algo-
rithm) and data availability (soundness property of inference
algorithm) in the presence of updates. We also present some
experimental results that show how our framework prevents
inferences in a single and multi-user environment; moreover,
our results show that D2Mon is robust in regards to the
number of users and the size of the database.
r e f e r e n c e s
Biskup J, Bonatti P. Lying versus refusal for known potentialsecrets. Data Engineering 2001;38(2):199–222.
Brodsky A, Farkas C, Jajodia S. Secure databases: constraints,inference channels, and monitoring disclosure. IEEETransactions on Knowledge and Data Engineering November,2000.
Buczkowski LJ. Database inference controller. In: Spooner D,Landwehr C, editors. Database security III: status andprospects. Amsterdam: North-Holland; 1990. p. 311–22.
Chen Y, Chu W. Database security protection via inferencedetection. In: Mehrotra S, Zeng D, Chen H, Thuraisingham B,Wang F, editors. Intelligence and security informatics. LectureNotes in Computer Science (LNCS), vol. 3975. Heidelberg:Springer Berlin; 2006. p. 452–8.
Chen Y, Chu W. Protection of database security via collaborativeinference detection. In: Chen H, Yang C, editors. Intelligenceand security informatics. Lecture Notes in Computer Science(LNCS), vol. 135. Heidelberg: Springer Berlin; 2008. p. 275–303.
Dawson S, di Vimercati SDC, Samarati P. Minimal data upgradingto prevent inference and association attacks. In: Proceedingsof the 18th ACM SIGMOD-SIGACT-SIGART symposium onprinciples of database systems; 1999a. p. 114–25.
Dawson S, di Vimercati SDC, Samarati P. Specification andenforcement of classification and inference constraints. In:Proceedings of the 20th IEEE symposium on security andprivacy (Oakland, CA); 1999b.
Delugach HS, Hinke TH. Wizard: a database inference analysisand detection system. IEEE Transactions on Knowledge andData Engineering 1996;8(1):56–66.
Denning DE. Cryptography and data security. Reading,Massachusetts: Addison-Wesley; 1982.
Denning DE. Commutative filters for reducing inference threats inmultilevel database systems. In: Proceedings of the IEEEsymposium on security and privacy; 1985. p. 134–46.
Domingo-Ferrer J. Inference control in statistical databases: fromtheory to practice. In: Lecture Notes in Computer Science, vol.2316. Berlin, Heidelberg: Springer-Verlag; 2002.
Privacy in statistical databases: casc project internationalworkshop, PSD 2004, Barcelona, Spain, June 9–11, 2004.Proceedings series. In: Domingo-Ferrer J, Torra V, editors.Privacy in statistical databases. Lecture Notes in ComputerScience, vol. 3050. Springer; 2004.
Domingo-Ferrer J, Torra V. Ordinal, continuous andheterogeneous k-anonymity through microaggregation. DataMining and Knowledge Discovery 2005;11(2):117–212.
Farkas C, Jajodia S. The inference problem: a survey. SIGKDDExplorations Newsletter 2002;4(2):6–11.
Farkas C, Toland TS, Eastman CM. The inference problem andupdates in relational databases. In: Proceedings of the IFIPWG11.3 working conference on database and applicationsecurity; 2001. p. 171–86.
Goguen JA, Meseguer J. Unwinding and inference control. In:Proceedings of the IEEE symposium on security and privacy;1984. p. 75–86.
Hinke TH. Inference aggregation detection in databasemanagement systems. In Proceedings of the IEEE symposiumon security and privacy; 1988. p. 96–106.
Hinke TH, Delugach HS, Chandrasekhar A. A fast algorithm fordetecting second paths in database inference analysis. Journalof Computer Security 1995;3(2, 3):147–68.
Hinke TH, Delugach HS, Wolf R. A framework for inferencedirected data mining. In: Proceedings of the 10th IFIP WG11.3workshop on database security; 1996. p. 229–39.
Hinke TH, Delugach HS, Wolf RP. Protecting databases frominference attacks. Computers and Security 1997;16(8):687–708.

c o m p u t e r s & s e c u r i t y 2 9 ( 2 0 1 0 ) 8 8 – 1 0 3 103
Ishihara Y, Ako S, Fujiwara T. Security against inference attackson negative information in object-oriented databases. In:ICICS 2002, Lecture Notes in Computer Science, vol. 2513.London, UK: Springer–Verlag; 2002. p. 49–60.
Jajodia S, Meadows C. Inference problems in multilevel securedatabase management systems. In: Abrams M, Jajodia S,Podell H, editors. Information security: an integratedcollection of essays. Los Alamitos, Calif.: IEEE ComputerSociety Press; 1995. p. 570–84.
Keefe TF, Thuraisingham MB, Tsai WT. Secure query-processingstrategies. IEEE Computer 1989:63–70.
Marks DG. Inference in MLS database systems. IEEE Transactionson Knowledge and Data Engineering 1996;8(1):46–55.
Marks DG, Motro A, Jajodia S. Enhancing the controlleddisclosure of sensitive information. In: Proceedings of theEuropean symposium on research in computer security.Lecture Notes in Computer Science, vol. 1146. Springer–Verlag;1996. p. 290–303.
Mazumdar S, Stemple D, Sheard, T. Resolving the tensionbetween integrity and security using a theorem prover. In:Proceedings of the ACM int’l conference on management ofdata; 1988. p. 233–42.
Morgenstern M. Controlling logical inference in multileveldatabase systems. In: Proceedings of the IEEE symposium onsecurity and privacy; 1988. p. 245–55.
Sicherman GL, de Jonge W, van de Riet RP. Answering querieswithout revealing secret. ACM Transactions on DatabaseSystems 1983;8(1):41–59.
Smith GW. Modeling security-relevant data semantics. In:Proceedings of the IEEE symposium on research in securityand privacy; 1990. p. 384–91.
Stachour PD, Thuraisingham B. Design of LDV: a multilevelsecure relational database management system. IEEETransactions on Knowledge and Data Engineering 1990;2(2):190–209.
Staddon J. Dynamic inference control. In: DMKD ’03:proceedings of the eighth ACM SIGMOD workshop onresearch issues in data mining and knowledge discovery.ACM Press; 2003. p. 94–100.
Su T, Ozsoyoglu G. Inference in MLS database systems. IEEETransactions on Knowledge and Data Engineering 1991;3(4):474–85.
Thuraisingham BM. Security checking in relational databasemanagement systems augmented with inference engines.Computers & Security 1987;6:479–92.
Thuraisingham BM. Database and applications security;integrating information security and data management. BocaRaton, FL: Auerbach Publications; 2005.
Toland TS, Farkas C, Eastman CM. Dynamic disclosure monitor(D2Mon): an improved query processing solution. In: Jonker W,Petkovic M, editors. Proceedings of secure data management:second VLDB workshop (SDM 2005). Berlin Heidelberg,Trondheim, Norway: Springer–Verlag; 2005. p. 124–42.
Ullman JD. Principles of database and knowledge-base systems,vols. 1, 2. Rockville, MD: Computer Science Press; 1988.
Willenborg L, de Waal T. Elements of statistical disclosurecontrol. In: Lecture notes in statistics, vol. 155. New York, NY:Springer–Verlag; 2001.
Woodruff D, Staddon J. Private inference control. In: CCS ’04:proceedings of the 11th ACM conference on computer andcommunications security. New York, NY, USA: ACM Press;2004. p. 188–97.
Yip RW, Levitt KN. Data level inference detection in databasesystems. In: Proceedings of the 11th IEEE computer securityfoundation workshop (Rockport, MA); June 1998. p. 179–89.
Tyrone S. Toland is an Assistant Professor in the Department ofInformatics at the University of South Carolina Upstate (USCUpstate). He received his Ph.D. from the University of SouthCarolina (USC). While at USC he conducted research in the Centerfor Information Assurance Engineering. Dr. Toland has held theposition of computer programmer and systems programmer atthe Metropolitan Life Insurance Company (MetLife) and USC.Dr. Toland was instrumental in redesigning the computer systemat USC to print official transcripts using IBM’s Advance FunctionPrinting Application Programming Interface. Dr. Toland teachesdatabase design, data warehousing, and information security. Hisresearch interests lie in information retrieval and database secu-rity. Dr. Toland is a Graduate Assistant in Areas of National Need(GAANN) Fellow.
Csilla Farkas is an Associate Professor in the Department ofComputer Science and Engineering and Director of the Center forInformation Assurance Engineering at the University of SouthCarolina. Csilla Farkas received her Ph.D. from George MasonUniversity, Fairfax. In her dissertation she studied the inferenceand aggregation problems in multilevel secure relational data-bases. Dr. Farkas’ current research interests include informationassurance, data inference problem, security and privacy on theSemantic Web, and security and reliability of Service OrientedArchitecture. Dr. Farkas is a recipient of the National ScienceFoundation Career award. The topic of her award is "SemanticWeb: Interoperation vs. Security – A New Paradigm of Confiden-tiality Threats." Dr. Farkas actively participates in internationalscientific communities as program committee member andreviewer.
Caroline M. Eastman is Professor and Director of UndergraduateStudies in the Department of Computer Science and Engineeringat the University of South Carolina. She received her Ph.D. fromthe Department of Computer Science at the University of NorthCarolina. Prior to joining the University of South Carolina, shewas at Florida State University, Southern Methodist University,and the National Science Foundation. Her current researchinterests are in the general area of information retrieval, witha focus on search behavior and query processing. She is currentlyPI for an NSF Research Experiences for Undergraduate Site andacademic liaison at the University of South Carolina for the NSF-supported STARS Alliance for Broadening Participation inComputing.