the history and future of atlas data management architecture d. malon, s. eckmann, a. vaniachine...
TRANSCRIPT

The History and Future of ATLAS Data Management Architecture
D. Malon, S. Eckmann, A. Vaniachine (ANL), D. Malon, S. Eckmann, A. Vaniachine (ANL),
J. Hrivnac, A. Schaffer (LAL), D. Adams (BNL)J. Hrivnac, A. Schaffer (LAL), D. Adams (BNL)
CHEP’03CHEP’03
San Diego, CaliforniaSan Diego, California24 March 200324 March 2003

24 March 200324 March 2003David M. Malon, ANL CHEP'03, San DiegoDavid M. Malon, ANL CHEP'03, San Diego
2
Outline
Persistent principlesPersistent principles
Pre-POOL: The ATLAS event store architecturePre-POOL: The ATLAS event store architecture
Hybrid event storesHybrid event stores
ATLAS and POOLATLAS and POOL
Non-event data in ATLASNon-event data in ATLAS
ATLAS data management and gridsATLAS data management and grids
ATLAS data management and other emerging technologiesATLAS data management and other emerging technologies

24 March 200324 March 2003David M. Malon, ANL CHEP'03, San DiegoDavid M. Malon, ANL CHEP'03, San Diego
3
Long-standing principles
Transient/persistent separation—not by any means unique to ATLAS—Transient/persistent separation—not by any means unique to ATLAS—
means (in ATLAS, anyway):means (in ATLAS, anyway): Physics code does not depend on storage technology used for input or
output data
Physics code does not “know” about persistent data model
Selection of storage technology, explicit and implicit, involves only job
options specified at run time
Commitment to use common LHC-wide solutions wherever possible, Commitment to use common LHC-wide solutions wherever possible,
since at least the time of the ATLAS Computing Technical Proposalsince at least the time of the ATLAS Computing Technical Proposal Once this implied Objectivity/DB (RD45)
Now this implies LCG POOL

24 March 200324 March 2003David M. Malon, ANL CHEP'03, San DiegoDavid M. Malon, ANL CHEP'03, San Diego
4
Pre-POOL: The ATLAS event store architecture
Event collection is fundamental: processing model is “read one or more Event collection is fundamental: processing model is “read one or more
collections, write one or more collections”collections, write one or more collections” Note: collections are persistent realizations of something more general
Model allows navigational access, in principle, to all upstream dataModel allows navigational access, in principle, to all upstream data Output “event headers” retain sufficient information to reach any data
reachable from input event headers
Architecture supports strategies for “sharing” data, so that writing Architecture supports strategies for “sharing” data, so that writing
events to multiple streams, for example, does not require (but may events to multiple streams, for example, does not require (but may
allow) replication of component event data allow) replication of component event data

24 March 200324 March 2003David M. Malon, ANL CHEP'03, San DiegoDavid M. Malon, ANL CHEP'03, San Diego
5
Pre-POOL: The ATLAS event store architecture - II
Data selection model is, in relational terms, “SELECT … FROM … Data selection model is, in relational terms, “SELECT … FROM …
WHERE …”WHERE …” SELECT which components of event data? FROM which event collection(s)? WHERE qualifying events satisfy specified conditions Designed to allow server-side and client-side selection implementation
Architecture also describes a placement service, though our Architecture also describes a placement service, though our
implementations were rather rudimentaryimplementations were rather rudimentary Mechanism for control of physical clustering of events (e.g., by stream), of
event components (e.g., by “type”), and for handling file/database allocation and management
Interface could satisfied by a within-job service, or by a common service shared by many jobs (e.g., in a reconstruction farm)
““Extract and transform” paradigm for selection/distributionExtract and transform” paradigm for selection/distribution

24 March 200324 March 2003David M. Malon, ANL CHEP'03, San DiegoDavid M. Malon, ANL CHEP'03, San Diego
6
Hybrid event stores
There were (and are) many questions about where genuine database There were (and are) many questions about where genuine database
functionality may be required, or useful, in an event storefunctionality may be required, or useful, in an event store
STAR, for example, had already successfully demonstrated a “hybrid” STAR, for example, had already successfully demonstrated a “hybrid”
approach to event stores:approach to event stores: File-based streaming layer for event data Relational database to manage the files
A hybrid prototype (AthenaROOT) was deployed in ATLAS in parallel A hybrid prototype (AthenaROOT) was deployed in ATLAS in parallel
with the ATLAS baseline (Objectivity-based)with the ATLAS baseline (Objectivity-based)
Transient/persistent separation strategy supports peaceful coexistence; Transient/persistent separation strategy supports peaceful coexistence;
physicists’ codes remain unchangedphysicists’ codes remain unchanged
……all of this was input to the LCG requirements technical assessment all of this was input to the LCG requirements technical assessment
group that led to initiation of POOL…group that led to initiation of POOL…

24 March 200324 March 2003David M. Malon, ANL CHEP'03, San DiegoDavid M. Malon, ANL CHEP'03, San Diego
7
ATLAS and POOL
ATLAS is fully committed to using LCG persistence software as its ATLAS is fully committed to using LCG persistence software as its
baseline, and to contributing to its direction and its developmentbaseline, and to contributing to its direction and its development
This means POOL: see earlier talks for POOL detailsThis means POOL: see earlier talks for POOL details
What POOL provides is closer to a framework than to an architectureWhat POOL provides is closer to a framework than to an architecture …though architectural assumptions, both implicit and explicit, go into
decisions about POOL components and their designs The influence is bidirectional Because POOL is still in its infancy, we do not fully understand its
implications for ATLAS data management architecture
Not a criticism: even if POOL delivered all the functionality of Not a criticism: even if POOL delivered all the functionality of
Objectivity/DB (or of Oracle9i), LHC experiments would still need to Objectivity/DB (or of Oracle9i), LHC experiments would still need to
define their data management architecturesdefine their data management architectures

24 March 200324 March 2003David M. Malon, ANL CHEP'03, San DiegoDavid M. Malon, ANL CHEP'03, San Diego
8
Non-event data in ATLAS
While event and conditions stores may be logically distinct and While event and conditions stores may be logically distinct and
separately managed at some levels, there is no reason they should not:separately managed at some levels, there is no reason they should not: employ common storage technologies (POOL/ROOT, for example) register their files in common catalogs
ATLAS currently has a variety of non-event data in relational databases ATLAS currently has a variety of non-event data in relational databases
(e.g., the “primary numbers” that parameterize ATLAS detector (e.g., the “primary numbers” that parameterize ATLAS detector
geometry)geometry) Today this entails ATLAS-specific approaches, but in principle, a POOL
MySQL(ODBC?) Storage Manager implementation could be used, as could the LCG SEAL dictionary for data definition
For interfaces unique to time-varying data, e.g., access based on For interfaces unique to time-varying data, e.g., access based on
timestamps and intervals of validity, ATLAS again hopes to employ timestamps and intervals of validity, ATLAS again hopes to employ
common LHC-wide solutions where possiblecommon LHC-wide solutions where possible

24 March 200324 March 2003David M. Malon, ANL CHEP'03, San DiegoDavid M. Malon, ANL CHEP'03, San Diego
9
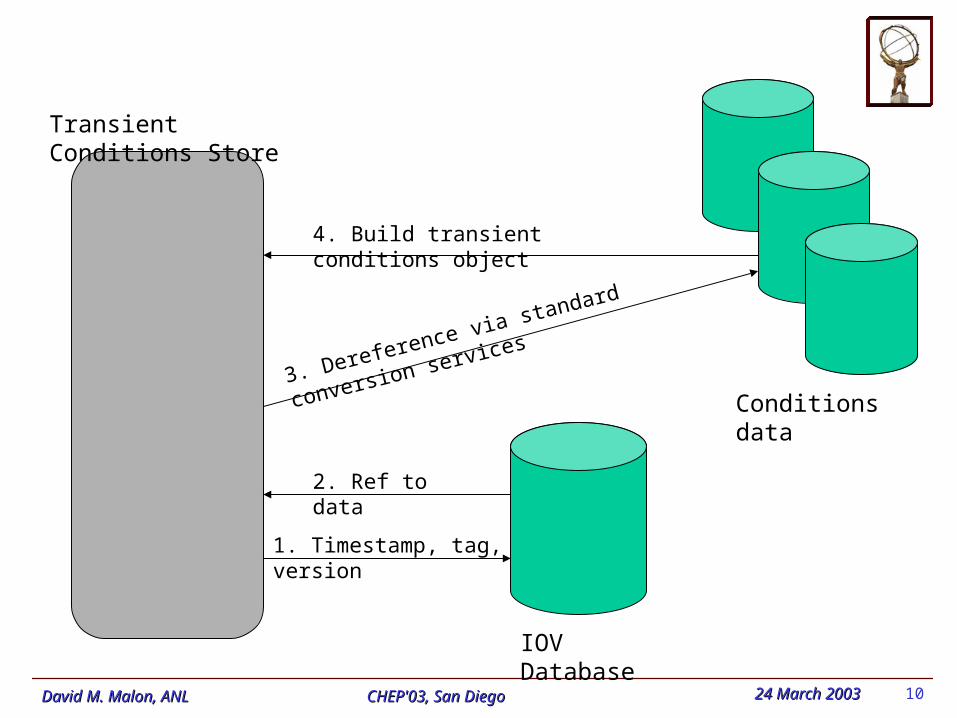
Architectural principles for time-varying data
Separate the interval-of-validity (IOV) database infrastructure from Separate the interval-of-validity (IOV) database infrastructure from
conditions data storage.conditions data storage.
Should be possible to generate and store conditions data in any Should be possible to generate and store conditions data in any
supported technology (POOL ROOT, MySQL, plain ASCII files, …) supported technology (POOL ROOT, MySQL, plain ASCII files, …)
without worrying about the interval-of-validity infrastructurewithout worrying about the interval-of-validity infrastructure Generation of data, and assignment of intervals of validity, versions, and
tags, may be widely separated in time, and done by different people
Later register the data in the IOV database, assigning an interval of Later register the data in the IOV database, assigning an interval of
validity, tag, version, …validity, tag, version, …
Transient IOV service will consult IOV database to get pointer to correct Transient IOV service will consult IOV database to get pointer to correct
version of data, then invoke standard Athena conversion services to put version of data, then invoke standard Athena conversion services to put
conditions objects in the transient store conditions objects in the transient store
24 March 200324 March 2003David M. Malon, ANL CHEP'03, San DiegoDavid M. Malon, ANL CHEP'03, San Diego
10
IOV Database
Transient Conditions Store
Conditions data
1. Timestamp, tag, version
2. Ref to data
3. Dereference via standard conversion services
4. Build transient conditions object

24 March 200324 March 2003David M. Malon, ANL CHEP'03, San DiegoDavid M. Malon, ANL CHEP'03, San Diego
11
Nonstandard data?
Cannot expect that all useful non-event data are produced by ATLAS-Cannot expect that all useful non-event data are produced by ATLAS-
standard toolsstandard tools
How do such data enter ATLAS institutional memory?How do such data enter ATLAS institutional memory? Is it as simple as registration in an appropriate file catalog (for files, anyway)
managed by the ATLAS virtual organization?
Is there a minimal interface such data must satisfy?Is there a minimal interface such data must satisfy? ATLAS “dataset” notions are relevant here Ability to externalize a pointer to an object in this technology?
What is required in order for an application in the ATLAS control What is required in order for an application in the ATLAS control
framework (Athena) to access such data?framework (Athena) to access such data? Provision of an LHCb/Gaudi-style conversion service?
LCG SEAL project may influence our answers to these questionsLCG SEAL project may influence our answers to these questions

24 March 200324 March 2003David M. Malon, ANL CHEP'03, San DiegoDavid M. Malon, ANL CHEP'03, San Diego
12
ATLAS data management and grids
With the current state of grid tools, grid data management has meant, With the current state of grid tools, grid data management has meant,
primarily, file replica cataloging and transfer, with a few higher-level primarily, file replica cataloging and transfer, with a few higher-level
servicesservices
ATLAS has prototyped and used a range of grid replica catalogs ATLAS has prototyped and used a range of grid replica catalogs
(GDMP, EDG, Globus (pre-RLS), RLS,…), grid file transport tools, grid (GDMP, EDG, Globus (pre-RLS), RLS,…), grid file transport tools, grid
credentialscredentials
Principal tool for production purposes is MAGDA (ATLAS-developed)Principal tool for production purposes is MAGDA (ATLAS-developed) MAGDA designed so that its components can be replaced by grid-standard
ones as they become sufficiently functional and mature This has already happened with transport machinery; will happen with replica
catalog component as RLS implementations improve

24 March 200324 March 2003David M. Malon, ANL CHEP'03, San DiegoDavid M. Malon, ANL CHEP'03, San Diego
13
Databases on grids
Need more detailed thinking on how to deal with database-resident Need more detailed thinking on how to deal with database-resident
data on gridsdata on grids Do Resource Brokers know about these? Connections between grid replica tracking and management and database-
provided replication/synchronization, especially when databases are updateable
Have looked a bit at EDG SpitfireHave looked a bit at EDG Spitfire
Could, in some cases, transfer underlying database files via replication Could, in some cases, transfer underlying database files via replication
tools, and register them (a la GDMP with Objectivity/DB databases)tools, and register them (a la GDMP with Objectivity/DB databases) Have done some prototyping with MySQL embedded servers
On-demand access over the net poses some challengesOn-demand access over the net poses some challenges
Grid/web service interfaces (OGSA) should helpGrid/web service interfaces (OGSA) should help

24 March 200324 March 2003David M. Malon, ANL CHEP'03, San DiegoDavid M. Malon, ANL CHEP'03, San Diego
14
Recipe management, provenance, and “virtual data”
Every experiment maintains, via software repositories and managed Every experiment maintains, via software repositories and managed
releases, official versions of recipes used to produce datareleases, official versions of recipes used to produce data
Everyone logs the recipes (job options, scripts) used for official Everyone logs the recipes (job options, scripts) used for official
collaboration data production in a bookkeeping databasecollaboration data production in a bookkeeping database ATLAS does this in its AMI bookkeeping/metadata database
Virtual data prototyping has been done in several ATLAS contextsVirtual data prototyping has been done in several ATLAS contexts Parameterized recipe templates (transformations), with actual parameters
supplied and managed by a database in DC0/1 (derivations) See Nevski/Vaniachine poster
Similar approach in AtCom (DC1) GriPhyN project’s Chimera virtual data catalog and Pegasus planner, used
in SUSY data challenge, and (currently) for reconstruction stage of Data Challenge 1

24 March 200324 March 2003David M. Malon, ANL CHEP'03, San DiegoDavid M. Malon, ANL CHEP'03, San Diego
15
Provenance
““Easy” part of provenance is at the “job-as-transformation” level:Easy” part of provenance is at the “job-as-transformation” level: What job created this file?
What job(s) created the files that were input to that job?
…and so on…
But provenance can be almost fractal in its complexity:But provenance can be almost fractal in its complexity: An event collection has a provenance, but provenance of individual events
therein may be widely varying
Within each of those events, provenance of event components varies
Calibration data used to produce event component data have a provenance
Values passed as parameters to algorithms have a provenance
…

24 March 200324 March 2003David M. Malon, ANL CHEP'03, San DiegoDavid M. Malon, ANL CHEP'03, San Diego
16
Some provenance challenges
CHALLENGES:CHALLENGES: Genuinely browsable, queryable transformation/derivation catalogs,
with sensible notions of similarity and equivalence
Integration of object-level history tracking, algorithm version
stamping, …., (currently experiment-specific), with emerging
provenance management tools

24 March 200324 March 2003David M. Malon, ANL CHEP'03, San DiegoDavid M. Malon, ANL CHEP'03, San Diego
17
The metadata muddle Ill-defined: One man’s metadata is another man’s dataIll-defined: One man’s metadata is another man’s data
Essential, though: a multi-petabyte event store will not be navigable Essential, though: a multi-petabyte event store will not be navigable
without a reasonable metadata infrastructurewithout a reasonable metadata infrastructure
Physicist should query a physics metadata database to discover what Physicist should query a physics metadata database to discover what
data are available and select data of interestdata are available and select data of interest
Metadata infrastructure should map physics selections to, e.g., lists of Metadata infrastructure should map physics selections to, e.g., lists of
logical files, so that resource brokers can determine where to run the job, logical files, so that resource brokers can determine where to run the job,
what data need to be transferred, and so onwhat data need to be transferred, and so on
Logical files have associated metadata as wellLogical files have associated metadata as well
Some metadata about provenance is principally bookkeeping, but some is Some metadata about provenance is principally bookkeeping, but some is
as useful as physics properties to physicists trying to select data of as useful as physics properties to physicists trying to select data of
interestinterest

24 March 200324 March 2003David M. Malon, ANL CHEP'03, San DiegoDavid M. Malon, ANL CHEP'03, San Diego
18
Metadata integration?
Current ATLAS data challenge work distinguishes 1.) physics metadata, 2.) Current ATLAS data challenge work distinguishes 1.) physics metadata, 2.)
metadata about logical and physical files, 3.) recipe/provenance metadata, 4.) metadata about logical and physical files, 3.) recipe/provenance metadata, 4.)
permanent production bookkeeping, and 5.) transient production log data, as a permanent production bookkeeping, and 5.) transient production log data, as a
starting point starting point
It is not too hard to build an integrated system when the components are all It is not too hard to build an integrated system when the components are all
under the experiment’s control, but when replica metadata management is under the experiment’s control, but when replica metadata management is
coming from one project, provenance metadata management from another, coming from one project, provenance metadata management from another,
physics, perhaps, from the experiment itself, bookkeeping from (perhaps) still physics, perhaps, from the experiment itself, bookkeeping from (perhaps) still
another source, a system that supports queries across layers is a CHALLENGEanother source, a system that supports queries across layers is a CHALLENGE
……in ATLAS, we still do not quite have a system that lets a physicist choose a in ATLAS, we still do not quite have a system that lets a physicist choose a
physics sample as input, and emits EDG JDL, for example, and this is just a physics sample as input, and emits EDG JDL, for example, and this is just a
small stepsmall step

24 March 200324 March 2003David M. Malon, ANL CHEP'03, San DiegoDavid M. Malon, ANL CHEP'03, San Diego
19
Beyond persistence
Persistence—saving and restoring object states—is a minimalist view: Persistence—saving and restoring object states—is a minimalist view:
it is necessary, but is it sufficient?it is necessary, but is it sufficient?
Should the object model (in transient memory) of the writer determine Should the object model (in transient memory) of the writer determine
the view that clients can extract from an event repository?the view that clients can extract from an event repository?
““Schema evolution” does not suffice: Schema evolution” does not suffice: Schema evolution recognizes that, though I write objects {A, B, C, D} today,
the class definitions of A, B, C, and D may change tomorrow It fails to recognize that my object model may use entirely different classes
{E,F, G} in place of {A, B, C, D} next year
Simple persistence fails to acknowledge that readers may not want the Simple persistence fails to acknowledge that readers may not want the
same objects that writers used, and that not all readers share a single same objects that writers used, and that not all readers share a single
viewview

24 March 200324 March 2003David M. Malon, ANL CHEP'03, San DiegoDavid M. Malon, ANL CHEP'03, San Diego
20
Beyond persistence: a trivial example
Can a reader build a “simple” track (AOD track) from a “full track” data Can a reader build a “simple” track (AOD track) from a “full track” data
object (the saved state of an object of a different class), without object (the saved state of an object of a different class), without
creating an intermediate “full track” on the client side?creating an intermediate “full track” on the client side?
In a relational database, I can write a 500-column table but read and In a relational database, I can write a 500-column table but read and
transfer to clients the data from only three of the columnstransfer to clients the data from only three of the columns
Simplified view: Need an infrastructure that can answer the question, Simplified view: Need an infrastructure that can answer the question,
“Can I build an object of type B from the data pointed to by this “Can I build an object of type B from the data pointed to by this
persistent reference (perhaps the saved state of an object of type A)?”persistent reference (perhaps the saved state of an object of type A)?”
24 March 200324 March 2003David M. Malon, ANL CHEP'03, San DiegoDavid M. Malon, ANL CHEP'03, San Diego
21
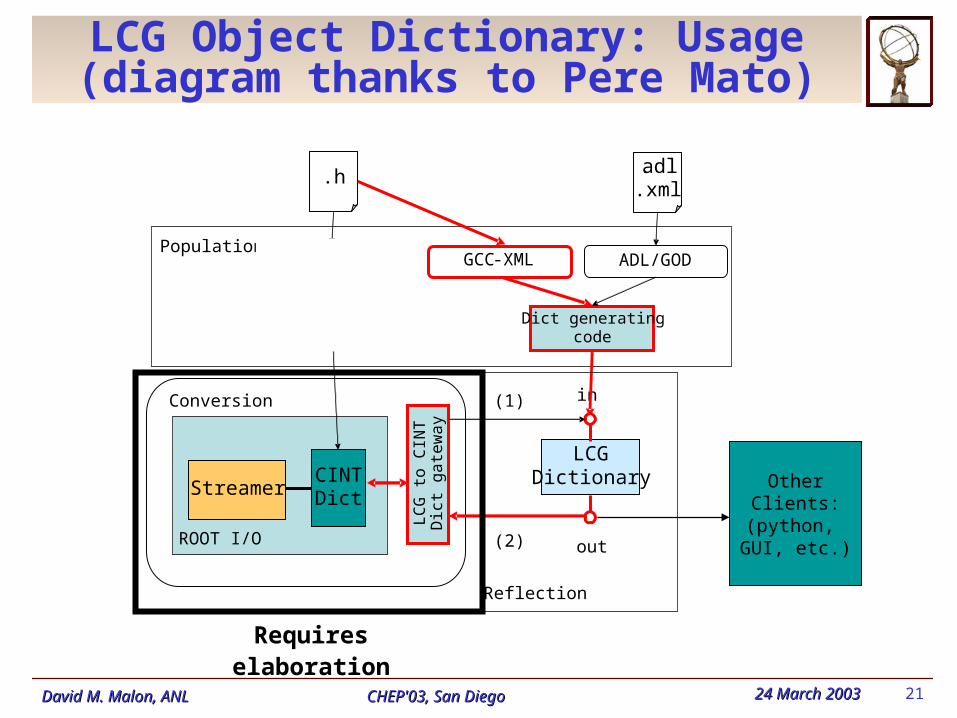
LCG Object Dictionary: Usage (diagram thanks to Pere Mato)
ROOT I/O
LCGDictionaryCINT
DictStreamer
.h
in
out
ROOTCINT
CINT generatedcode Dict generating
code
.adl.xml
ADL/GOD
OtherClients:
(python, GUI, etc.)
LCG
to C
INT
Dic
t gate
way
(2)
(1)
Population
Conversion
Reflection
GCC-XML
Requires elaboration

24 March 200324 March 2003David M. Malon, ANL CHEP'03, San DiegoDavid M. Malon, ANL CHEP'03, San Diego
22
Elaboration?
Selection of persistent representation and streamer generation can be Selection of persistent representation and streamer generation can be
separated separated
More than one persistent representation may be supported
Custom streamers
Separation of transient object dictionaries and persistent layout dictionaries
On input, what one reads need not dictate what one builds in transient memoryOn input, what one reads need not dictate what one builds in transient memory
Not “Ah! This is the state of a B; I’ll create a transient B!”
Rather, “Can I locate (or possibly create) a recipe to build a B from these
data?”
ROOT I/O
CINTDictStreamer
LCG
to C
INT
Dic
t gate
way
Conversion

24 March 200324 March 2003David M. Malon, ANL CHEP'03, San DiegoDavid M. Malon, ANL CHEP'03, San Diego
23
Other emerging ideas
Current U.S. ITR proposal is promoting knowledge management in Current U.S. ITR proposal is promoting knowledge management in
support of dynamic workspacessupport of dynamic workspaces
One interesting aspect of this proposal is in the area of ontologiesOne interesting aspect of this proposal is in the area of ontologies An old term in philosophy (cf. Kant), a well-known concept in the (textual)
information retrieval literature, and a hot topic for semantic web folks
Can be useful when different groups define their own metadata, using
similar terms with similar meanings, but not identical terms with identical
meanings
Could also be useful in defining what is meant, for example, by “Calorimeter
data,” without simply enumerating the qualifying classes