the effect of language on response distributions in likert data bert weijters maggie geuens hans...
TRANSCRIPT

The Effect of Language on Response Distributions in Likert
Data
Bert Weijters
Maggie Geuens
Hans Baumgartner

Effect of language on response distributions in Likert data
The non-equivalence problem in cross-national research
Surveys are popular in cross-national marketing research However, one common concern is that survey responses may
not be equivalent across countries:□ the same response (e.g., ‘4’ on a five point-agree/ disagree
scale) may have a different meaning for different respondents (e.g., in different countries);
□ sources of non-equivalence: Item-specific (different meanings attached to a particular
item)
General (i.e., over multiple tems)

Effect of language on response distributions in Likert data
Remedies for non-equivalence□ Non-equivalence of responses to individual items has
been addressed: Procedurally: back-translation
(Kumar 2000)
Statistically: measurement invariance testing of item parameters such as item loadings and intercepts
(Steenkamp and Baumgartner 1998; He, Merz, and Alden 2008)
□ Non-equivalence due to biases that are not item-specific has been partially addressed:
Multiple response styles have been identified and statistical remedies have been suggested
(Baumgartner and Steenkamp 2001; De Jong et al. 2008)
Response styles have been related to national culture (Harzing 2006; Johnson et al. 2005; Van Herk, Poortinga and Verhallen 2004)

Effect of language on response distributions in Likert data
Research objective General non-equivalence (i.e., bias not specific to a
particular item) has been attributed to national culture; However, nationality and language have been consistently
confounded; The present investigation aims to
□ Assess the effect of language on response bias (resulting in shifts in response distributions), controlling for nationality;
□ Explain the mechanism underlying the language effect studied;

Effect of language on response distributions in Likert data
A multi-step investigation into cross-regional non-equivalence
Cross-regional non-equivalence
Nationality
Language
Respondent
Questionnaire response category labels
Label intensity
Label currency
Study 1: Cross-regional European survey

Effect of language on response distributions in Likert data
Study 1 Does nationality or language lead to greater
similarity in responses to heterogeneous Likert items?
“Natural” experiment using native speakers of different languages in Europe who share or do not share the same nationality;

Effect of language on response distributions in Likert data
Method: Design and sample
Country
Netherlands Belgium France Germany Switzerland Italy Total
Language Dutch 1046 644 1690
French 371 1000 303 1674
German 993 606 1599
Italian 50 939 989
Total 1046 1015 1000 993 959 939 5952

Effect of language on response distributions in Likert data
Method: Measuring response
distributions A major challenge is to measure bias in response
distributions that is not item-specific and independent of substantive content;
To do this, we need to observe patterns of responses across heterogeneous items (i.e., items that do not share common content but have the same response format):
Deliberately designed scales consisting of heterogeneous items (Greenleaf 1992)
Random samples of items from scale inventories (Weijters, Geuens & Schillewaert 2010)

Effect of language on response distributions in Likert data
Method: InstrumentGreenleaf 1992 scale (16
items)
#(one)#(two)

Effect of language on response distributions in Likert data
Response Proportions by Region (Study 1)
1 2 3 4 5 6 7
Netherlands-Dutch 5.51% 13.18% 12.39% 23.20% 21.63% 18.25% 5.84%
Belgium-Dutch 5.49% 12.56% 14.06% 22.72% 20.98% 16.73% 7.45%
Belgium-French 5.27% 7.46% 13.54% 20.40% 26.01% 16.39% 10.92%
France-French 7.63% 7.76% 14.21% 20.29% 24.20% 14.31% 11.60%
Switzerland-French 7.45% 9.72% 13.39% 19.04% 24.09% 14.93% 11.39%
Germany-German 9.20% 11.72% 13.67% 23.75% 17.29% 16.33% 8.04%
Switzerland-German 10.52% 12.46% 12.62% 20.18% 18.88% 17.73% 7.60%
Switzerland-Italian 7.38% 8.00% 11.13% 13.00% 24.88% 23.88% 11.75%
Italy-Italian 5.09% 9.26% 9.36% 15.05% 25.71% 22.90% 12.63%

Effect of language on response distributions in Likert dataHierarchical clustering of regions by
response category proportions (Ward’s method)

Effect of language on response distributions in Likert data
A multi-step investigation into cross-regional non-equivalence
Cross-regional non-equivalence
Nationality
Language
Mother tongue Language of questionnaire
Questionnaire response category labels
Label intensity
Label currency
Study 1: Cross-regional European survey
Study 2: Experiment with bilinguals

Effect of language on response distributions in Likert data
Study 2 Are differences in response distributions due to language
mainly related to respondents’ mother tongue (i.e., an individual characteristic) or the language of the questionnaire (i.e., a stimulus characteristic)?
In particular, does the use of different category labels within each language affect the response distributions?
□ Response category labels are a potential systematic source of
differences in response distributions since they are constant
across items but variable across languages;
□ Even within the same language, response distributions may
differ if different response category labels are used;
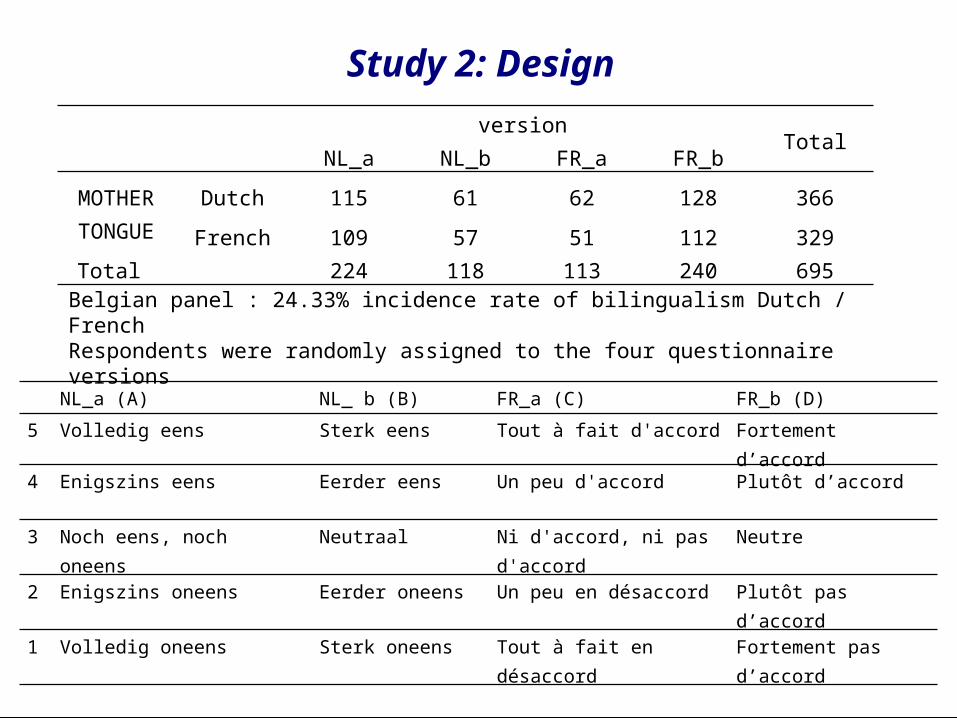
Effect of language on response distributions in Likert data
versionTotalNL_a NL_b FR_a FR_b
MOTHERTONGUE
Dutch 115 61 62 128 366
French 109 57 51 112 329Total 224 118 113 240 695
Belgian panel : 24.33% incidence rate of bilingualism Dutch / FrenchRespondents were randomly assigned to the four questionnaire versions
NL_a (A) NL_ b (B) FR_a (C) FR_b (D)
5 Volledig eens Sterk eens Tout à fait d'accord Fortement d’accord
4 Enigszins eens Eerder eens Un peu d'accord Plutôt d’accord
3 Noch eens, noch oneens Neutraal Ni d'accord, ni pas d'accord
Neutre
2 Enigszins oneens Eerder oneens Un peu en désaccord Plutôt pas d’accord
1 Volledig oneens Sterk oneens Tout à fait en désaccord Fortement pas d’accord
Study 2: Design

Effect of language on response distributions in Likert data
Dependent variable:□ 16-item Greenleaf (1992) scale;□ 16 heterogeneous Likert items sampled from as many
unrelated marketing scales;□ the two sets of measures achieved convergent validity
and were combined; demographic background variables; language profile (language proficiency and use of
Dutch/French);
Study 2: Design (cont’d)

Effect of language on response distributions in Likert dataStudy 2: Results

Effect of language on response distributions in Likert data
Statistical analysis
Score Statistics For Type 3 GEE Analysis
Chi-Source DF Square Pr > ChiSq
Language 1 4.21 0.0402Label(Language) 2 24.82 <.0001Mother_tongue 1 0.12 0.7297Language*Mother_tongue 1 2.56 0.1097Label(Language)*Mother_tongue 2 1.81 0.4043Scale Category 3 391.22 <.0001Scale Category*Language 3 19.85 0.0002Scale Category*Label(Language) 6 72.96 <.0001Scale Category*Mother_tongue 3 4.93 0.1773Scale Category*Language*Mother_tongue 3 3.98 0.2631Scale Category*Label(Language)*Mother_tongue 6 6.34 0.3860

Effect of language on response distributions in Likert data
Discussion Study 2 response distributions do not seem to differ as a function
of a respondent’s mother tongue; the language of the questionnaire and the labels used for
the scale categories can have a substantial influence on how readily certain positions on the rating scale are endorsed:□ even within the same language, supposedly similar labels
strongly affected responses to items that were presumably free of common content;
□ in a multi-language context, where category labels do differ across languages but are common across items within the same language, the labels attached to different scale positions can be a potent source of response bias;

Effect of language on response distributions in Likert data
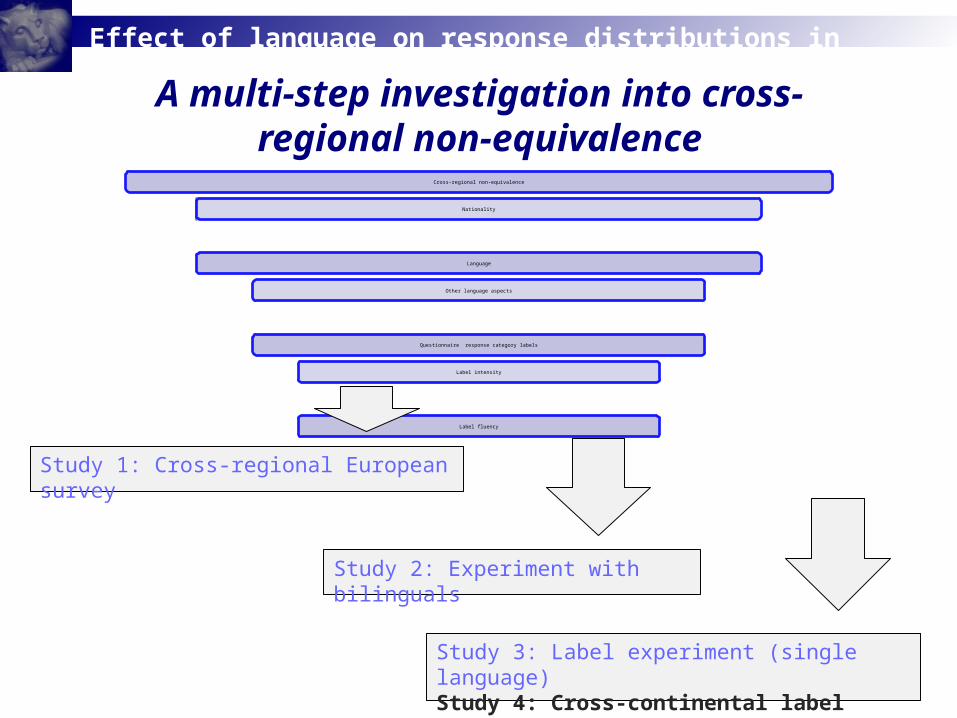
A multi-step investigation into cross-regional non-equivalence
Cross-regional non-equivalence
Nationality
Language
Other language aspects
Questionnaire response category labels
Label intensity
Label fluency
Study 1: Cross-regional European survey
Study 2: Experiment with bilinguals
Study 3: Label experiment (single language)Study 4: Cross-continental label experiment

Effect of language on response distributions in Likert data
Note
Henceforth, we will focus on the endpoint labels: This avoids the confounding effects of the labels of adjacent
categories (e.g., is the frequency of ‘4’ responses due to the label of categories 3, 4 or 5?);
Extreme response style has been the focus of much recent cross-cultural research (e.g., Arce-Ferrer 2006; Clarke 2001; De Jong et al. 2008);
In practice, scales in which only the endpoints are labelled are most prevalent (Weijters, Cabooter & Schillewaert, forthcoming);

Effect of language on response distributions in Likert data
Two alternative hypotheses to explain the effect of response
category labels
H1: Endpoint labels with higher intensity are less frequently endorsed.
H2: Endpoint labels with higher fluency are more frequently endorsed.

Effect of language on response distributions in Likert data
H1: Intensity hypothesis Item Response Theory:
□ respondents map their standing on the latent variable onto the response category that covers their position on the latent variable (Samejima 1969; Maydeu-Olivares 2005);
□ the wider the response category, the more likely respondents are to endorse it; more intense endpoint labels move the category’s lower or upper boundary away
from the midpoint, resulting in lower response frequencies;
1 2 3 4 5 6 7 Overt Likert response
Latent construct
Extreme endpoint label Shifting boundaryNarrow categoryLow frequency

Effect of language on response distributions in Likert data
H2: Fluency hypothesis Research on processing fluency shows that the meta-cognitive experience
of ease of processing affects judgment and decision making:□ perceptions of the truth value of statements (e.g., Unkelbach 2007)□ liking for objects and events (e.g., Reber, Schwarz, and Winkielman
2004)□ choice deferral or choices of compromise options (e.g., Novemski et al.
2007); Repeated statements are more likely to be rated as true (Unkelbach 2007)
and repetition increases liking, as suggested by the mere exposure effect (e.g., Bornstein 1989), in part because repetition makes stimuli more familiar and contributes to greater processing fluency;
Therefore, if scale labels are more commonly used in everyday language and are thus easier to process, this should increase the likelihood that the corresponding response option on the rating scale is selected;

Effect of language on response distributions in Likert data
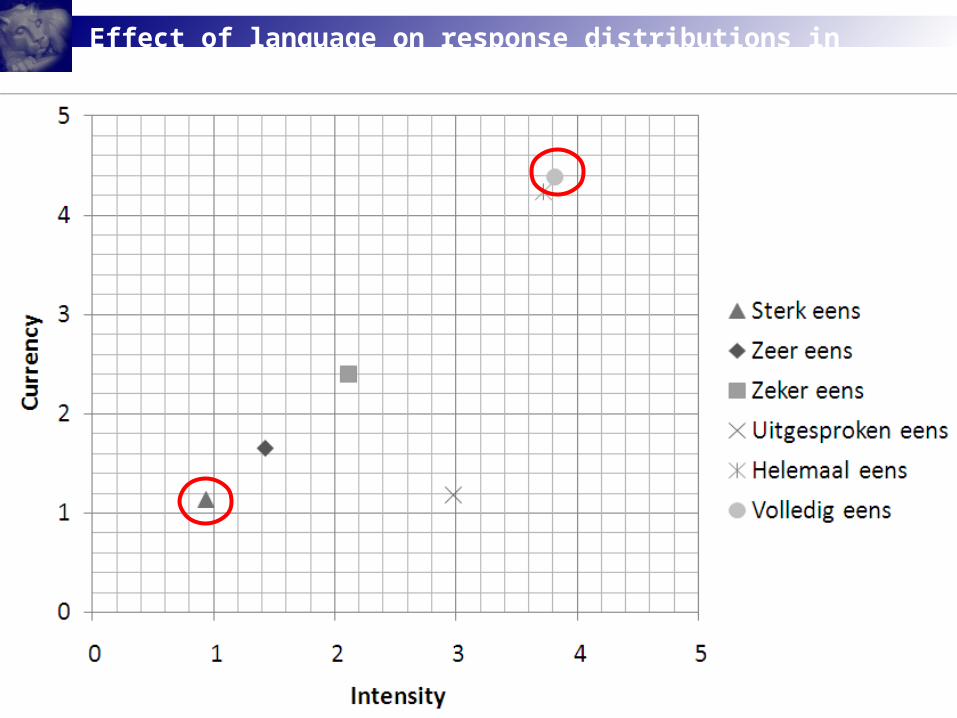
Pre-test: Stimuli selection
1. Select two labels with intensity and fluency levels that would lead to contradictory effects under H1 and H2;
2. Pilot intensity and fluency measure using pair-wise comparisons (“Which expression indicates the stronger sense of agreement?” and “Which expression is more commonly used in day-to-day speech?”);
M (SE)Dutch label Free translation Intensity Fluency
Sterk (on)eens Strongly (dis)agree 0.94 (0.13) 1.14 (0.11)
Zeer (on)eens Very much (dis)agree 1.43 (0.12) 1.65 (0.12)
Zeker (on)eens Definitely (dis)agree 2.11 (0.11) 2.40 (0.1 )
Uitgesproken (on)eens Certainly (dis)agree 2.98 (0.18) 1.18 (0.13)
Helemaal (on)eens Completely (dis)agree 3.72 (0.13) 4.24 (0.08)
Volledig (on)eens Fully (dis)agree 3.82 (0.12) 4.39 (0.08)
Pre-test among Dutch speaking students (N = 83) using 6 endpoint labels in Dutch (including the labels used in the previous study)

Effect of language on response distributions in Likert data
Main experiment: Method
□ We randomly assigned Dutch speaking students (N = 100) to two
alternative versions of a brief online questionnaire (10 hetero-
geneous Likert items and pairwise comparisons);
□ In one version, the extreme categories were labelled ‘sterk
(on)eens’ (‘strongly (dis)agree’), in the other version the extreme
categories were labelled ‘volledig (on)eens’ (‘fully (dis)agree’);
□ The intermediate categories (disagree, neutral, agree) had the same
labels in both versions;

Effect of language on response distributions in Likert data
Main experiment: Findings
A generalized linear model analysis showed that the number of extreme positive responses was significantly lower in the ‘sterk eens’ (low intensity and fluency) condition than in the ‘volledig eens’ (high intensity and fluency) condition: means of 3.63 vs. 4.44 (χ2
1=3.998, p = .046);
This result is consistent with H2: labels that are more fluent lead to higher response category frequencies (in this case despite their higher intensity);
Note: In the bilinguals study, ‘volledig eens’ also had a higher endorsement frequency than ‘sterk eens’ (17% vs. 13%, respectively, p < .05).
Effect of language on response distributions in Likert data
A multi-step investigation into cross-regional non-equivalence
Cross-regional non-equivalence
Nationality
Language
Other language aspects
Questionnaire response category labels
Label intensity
Label fluency
Study 1: Cross-regional European survey
Study 2: Experiment with bilinguals
Study 3: Label experiment (single language)Study 4: Cross-continental label experiment
Effect of language on response distributions in Likert data
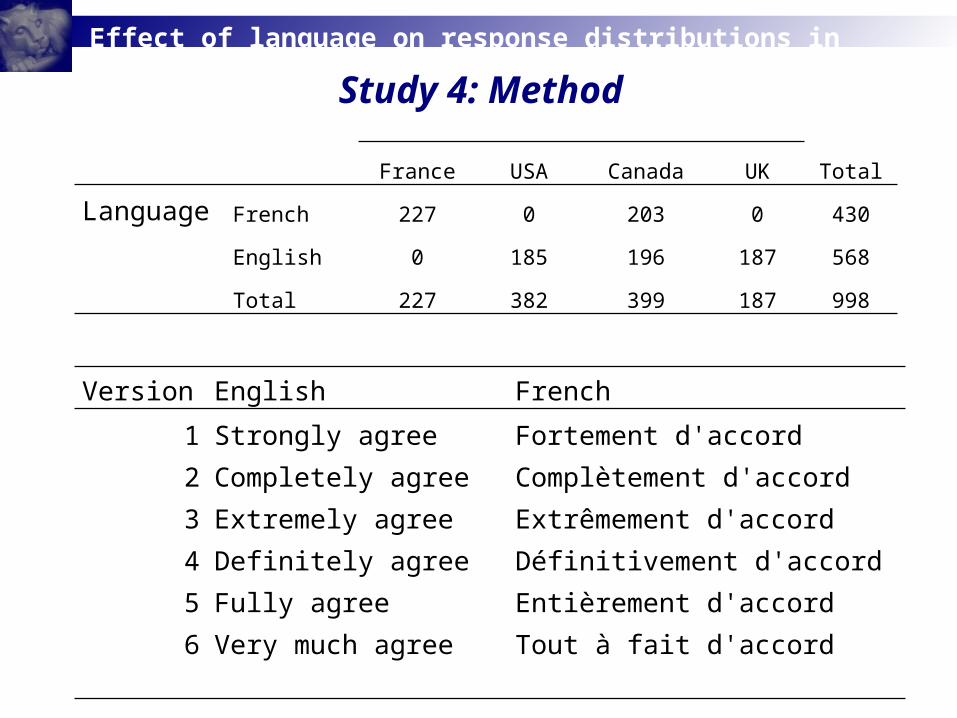
Study 4: Method
France USA Canada UK Total
Language French 227 0 203 0 430
English 0 185 196 187 568
Total 227 382 399 187 998
Version English French
1 Strongly agree Fortement d'accord2 Completely agree Complètement d'accord3 Extremely agree Extrêmement d'accord4 Definitely agree Définitivement d'accord5 Fully agree Entièrement d'accord6 Very much agree Tout à fait d'accord

Effect of language on response distributions in Likert data
Intensity and fluency ratings by region

Effect of language on response distributions in Likert data
Multilevel results Estimate S.E. Est./S.E. P-ValueWithin Level ERS ON FEMALE 0.057 0.047 1.196 0.232 AGE -0.001 0.003 -0.279 0.781 EDU_HI -0.048 0.085 -0.560 0.575
Between Level ERS ON FLUENCY 0.165 0.064 2.594 0.009 INTENSITY -0.133 0.131 -1.014 0.311 LANG_FR 0.061 0.087 0.703 0.482 C_US 0.119 0.102 1.166 0.244 C_FR 0.007 0.076 0.091 0.927 C_UK 0.025 0.120 0.212 0.832 Intercept ERS 1.002 0.184 5.444 0.000

Effect of language on response distributions in Likert data
Discussion: summary of findings
Cross-regional non-equivalence
Nationality
Language
Other language aspects
Questionnaire response category labels
Label intensity
Label currency
Study 1: Cross-regional European surveyResponse distributions are more homogeneous for regions sharing the same language than for regions sharing the same nationality.

Effect of language on response distributions in Likert data
Cross-regional non-equivalence
Nationality
Language
Other language aspects
Questionnaire response category labels
Label intensity
Label currency
Study 2: Experiment with bilingualsResponse distributions vary as a function of category labels, even within the same language and regardless of respondents’ mother tongue
Discussion: summary of findings

Effect of language on response distributions in Likert data
Cross-regional non-equivalence
Nationality
Language
Other language aspects
Questionnaire response category labels
Label intensity
Label currency
Study 3: Label experiment (one sample)Highly fluent labels lead to higher endorsement rates of response categories, irrespective of label intensity (and keeping language constant)
Study 4: Cross-continental label experimentThis finding holds in a multilingual cross-continental setting, irrespective of language and nationality
Discussion: summary of findings

Effect of language on response distributions in Likert data
Implications Response style research
Need to extend the scope to questionnaire characteristics
Need to cross-validate/replicate earlier cross-national comparisons
Cross-cultural survey research Reconsider regional segmentations Validate measures cross-regionally rather than
cross-nationally

Effect of language on response distributions in Likert data
Implications formultilingual survey research
□ Translations usually imply a trade-off between the attempt to be literal and the attempt to be idiomatic;
□ Optimize equivalence: use response category labels that are equally fluent in different languages (rather than literal translations or words with equal intensity);
e.g., ‘Strongly agree’ is most commonly used in scales, but may not have valid equivalents in some other languages. ‘Completely agree’ seems to be a viable alternative.
Currency ERS%
Completely agree 1.24 18.8%
Tout à fait d’accord 1.22 19.2%

Effect of language on response distributions in Likert data

Effect of language on response distributions in Likert dataCross-language differences in response
distributions
Effect of language on response distributions in Likert data
Pre test: Stimuli selection