the design and evaluation of a buffer algorithm for database machines
TRANSCRIPT

CONCURRENCY: PRACTICE AND EXPERIENCEConcurrency: Pract. Exper., Vol. 10(15), 1291–1316 (1998)
The design and evaluation of a buffer algorithmfor database machinesF. F. CAI1, M. E. C. HULL2∗AND D. A. BELL3
1Department of Computing, Information Systems and Mathematics, London Guildhall University,London EC3N 1JY, UK
2School of Computing and Mathematics, University of Ulster, Newtownabbey, Co Antrim BT37 0QB, UK
3School of Information and Software Engineering, University of Ulster, Newtownabbey, Co Antrim BT37 0QB,UK
SUMMARYThis paper reports on the design, development and evaluation of a buffer algorithm namedRESBAL, which exploits parallelism in order to provide high query execution performance inrelational database systems. The algorithm aims to provide both predictive and efficient databuffering by exploiting the use of advance knowledge of query reference behaviour. Designed tooffer a high level of flexibility, RESBAL employs a multiple buffering strategy both on page fetchlevel and page replacement level in order to improve buffer performance. The evaluation ofRESBAL has been carried out in a parallel database system environment based on a transputerarchitecture. The results of this performance assessment allow comparison to be made betweendifferent buffer algorithms, and demonstrate the feasibility and effectiveness of the RESBALalgorithm. 1998 John Wiley & Sons, Ltd.
1. INTRODUCTION
The recent advent of various general purpose parallel hardware devices has brought thepromise of a significant performance enhancement for database machines. However, thisimprovement can only be maximized, and indeed delivered, when database managementsystems (DBMSs) which can fully exploit the potential parallelism offered by the hardwareare available.
A buffer manager is one of the most important modules of a DBMS. Its design andimplementation can significantly affect the overall performance of a relational databasesystem. The purpose of providing buffer space in a database machine is to allow harmo-nization of the diverse speeds of processors and peripherals[1]. Therefore, the fundamentalrequirement of this process is that of retaining in the buffer those pages which have strongprobabilities of being reused. Satisfaction of this requirement will minimize disk activitiesand maximize system throughput[2]. This is particularly true in a high-performanceparalleldatabase system where concurrent transactions often compete for memory space as well asprocessing power.
Following decades of successful research and development, various commercial re-lational database management systems are now widely available to, and used by, bothdatabase professionals and non-professionals alike. However, many new applications havesince emerged which are presenting some fresh challenges to the database community. The
∗Correspondence to: Professor M. E. C. Hull, School of Computing and Mathematics, University of Ulster,Newtownabbey, Co Antrim BT37 0QB, UK.
CCC 1040–3108/98/151291–26$17.50 Received 17 September 19931998 John Wiley & Sons, Ltd. Accepted 30 March 1998

1292 F. F. CAI ET AL.
typical examples of these applications include multimedia systems, data mining and datawarehousing, to name but a few.
As a consequence of these changes in information technology the forms of data storageand management are undergoing radical changes[3]. Furthermore, the issue of databaseperformance has been pushed to the forefront of database design and implementation asnever before. Efficient and effective information retrieval and processing are considered tobe essential to the success of any commercial database systems.
Designing a buffer manager specially tailored for database systems with both parallelhardware and software environments remains a challenging research area. Only a limitednumber of proposals have emerged over the years. These are exemplified by the algorithmbased on the hot-set (HS) model[4] and the DBMIN algorithm based on the query localityset model[5]. HS, perhaps the first systematic database buffering model, improves on earlierproposals by exploiting the predictability of reference strings. One potential flaw of thisalgorithm results from its uniform provision of the LRU (least-recently-used) policy, whichhas proved to be unsuitable for certain looping patterns. The DBMIN algorithm tackles thisproblem by assigning different replacement policies for different access patterns, and wasreported to have outperformed HS in many cases.
The work presented here, however, is based ultimately on ideas in earlier algorithmsand with the objective of further improving performance. It reports on the design andevaluation of a buffering algorithm called RESBAL, proposed in [6], for a relationaldatabase system utilizing a transputer architecture[7]. Aimed at making predictive pagingdecisions, the algorithm exploits the use of prior knowledge of query access patterns.This is supported by an underlying model of query reference, the Resident Set Model,which can be viewed as a systematic tool to predict reference behaviour and to determinethe buffer requirement of a query before its execution. By managing buffers on a query-driven, relation-based principle, RESBAL incorporates a set of highly flexible strategiesof multiple-fetch, multiple-replacement and multiple-buffer-page, designed for differentdatabase access patterns. The algorithm has been implemented as part of an early prototypedatabase system based on transputer architecture. Performance evaluation has been carriedout to investigate the feasibility of the algorithm and to assess if it offers advantages overother proposals. Some of the preliminary results from the evaluation were presented in anearlier paper[8].
The remainder of this paper is organized as follows. The next two sections briefly reviewthe resident set model and the RESBAL algorithm, respectively. The architecture of theexperimental database system on which the RESBAL algorithm has been implemented isthen described in Section 4. Section 5 discusses the methods used in the evaluation studyand presents some of its findings, which enable various comparisons to be made betweenRESBAL and its counterparts.
2. THE RESIDENT SET MODEL FOR QUERY REFERENCE BEHAVIOUR
The predictive quality of the RESBAL algorithm is basically derived from the underlyingresident set (RS) model, which provides a useful vehicle to capture the reference behaviourof database queries. The model allows a static page set of a relation, a resident set, to beidentified, and consequently the optimal buffer space needed for efficient query processingto be estimated, prior to query execution.
Informally, a resident set of a relation (RRS) can be described as a collection of pages
1998 John Wiley & Sons, Ltd. Concurrency: Pract. Exper., 10, 1291–1316 (1998)

BUFFER ALGORITHM FOR DATABASE MACHINES 1293
which are frequently reaccessed during query processing, whilst a query’s resident set(QRS) is the union of pertinent resident sets of all relations accessed by the query. Since aQRS comprises a set of pages that have a combined high reference probability for the givenquery, its ‘residence’ in the buffer is highly desirable. The optimal buffer space requiredfor that query is, therefore, usually equal to the size of its QRS.
In the RS model, a query’s reference behaviour is described as, and decomposed into,a set of simple and regular access patterns. They are classified into the following threemain categories, and this classification is more suitable for use on our system than thatof [5]. Consequently, the size of an RRS conforming to any (or combinations) of thesepatterns, and hence the size of a QRS, can be estimated according to statistical informationon relations which is available to the system.
2.1. Independent accesses
This class of access patterns is distinguished by a conspicuous absence of locality in pagereference across different pages. Pages in a relation are accessed independently withoutalgorithmic repetition; once a page is left, it will not be used again by the same query.There is usually no advantage, therefore, in allocating more than one buffer frame, if notfor the benefit of prefetches. There are three cases identifiable within this class, which areindependent random accesses (IR), independent sequential accesses (IS) and independentindex accesses (II).
2.2. Cyclic accesses
This class of patterns represents those in which locality of reference is observed over someor all pages of a relation that are repeatedly used in a cyclic loop. Again, three cases can bedefined. A dispersed cyclic access (DC) occurs when the locality exists in a repeated accessto a cluster across a set of relation pages which are non-adjacent in physical storage. Apartial cyclic access (PC) appears in situations where a sequential scan on part of a relationis repeated, and where those pages being reused are physically adjacent (being differentfrom the DC pattern). A complete cyclic access (CC) exists for all the pages of a relationsequentially referenced in a loop which repeats. For these three patterns, either part of orthe entire relation concerned should be kept in the buffer to ensure fast and efficient queryexecution.
2.3. Hierarchical repeated accesses
Hierarchical repeated accesses (HR) refer particularly to a repeated index tree traversal inwhich the probability of page reuse within the hierarchical index tree T shows a non-uniformdistribution[9]. Pages close to the root (level 1) have more likelihood to be re-accessedthan those close to the leaves (level t). The estimate of a resident set size and subsequentpaging activities for this access pattern must be performed in such a way that pages at leveli should have higher priority of remaining in the buffer than those at level i+ 1.
Figure 1 summarizes in a tabular form the classification of different access patterns andestimation of their resident set sizes using the RS model. A more detailed description ofthe model is presented in [6].
1998 John Wiley & Sons, Ltd. Concurrency: Pract. Exper., 10, 1291–1316 (1998)

1294 F. F. CAI ET AL.
Figure 1. Access pattern identification and size estimation
3. THE RESBAL BUFFERING ALGORITHM
Supported by the RS model, the RESBAL buffering algorithm (REsident Set Based ALgo-rithm) manages the buffer on a query-driven, relation-based principle which facilitates theprovision of highly flexible buffering policies tuned for different access patterns.
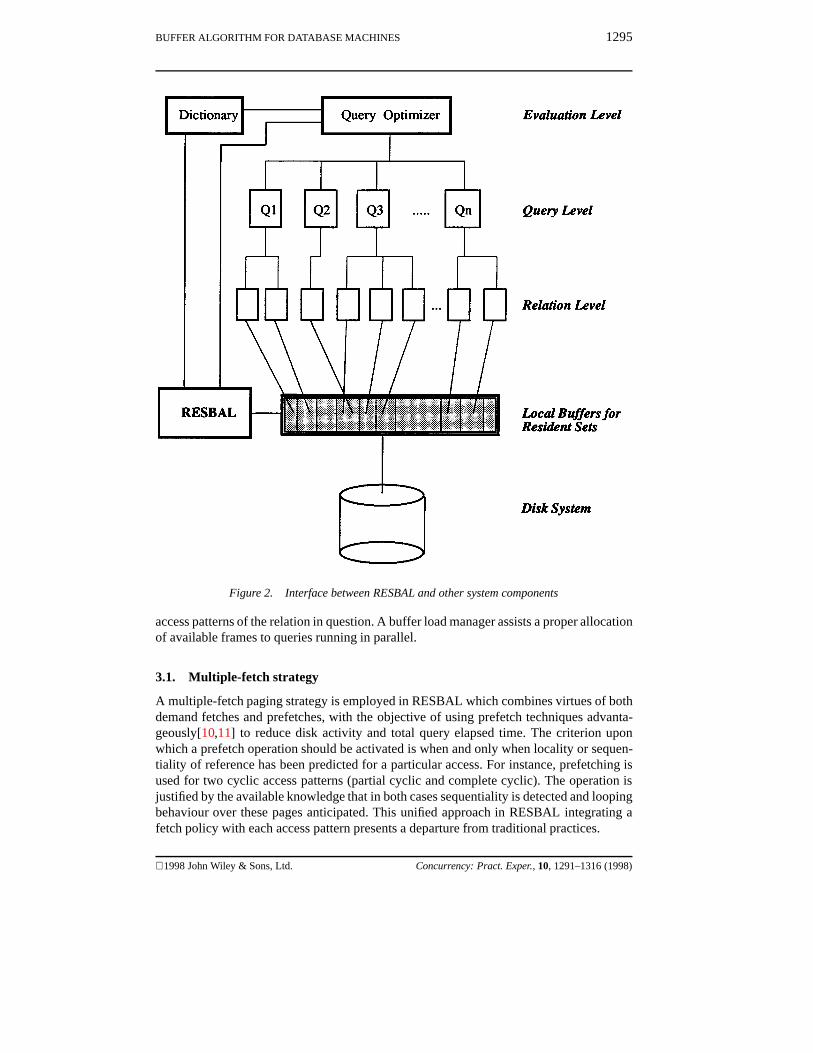
A schematic view of the RESBAL module and other system components is illustrated inFigure 2. Upon submission to the database system, a multi-relation query is decomposedfrom query level to relation level. When a relation is required by a query, a local buffer isallocated to the relation, with its estimated resident set size and associated buffering policygiven to the buffer manager.
From the query evaluation module and system dictionary, RESBAL acquires some‘knowledge’ essential to its operation, such as the types of the queries and relations involved,and statistics about the structure and contents of, the intended usage of, and access pathsavailable to, each relation concerned.
The unique features of the RESBAL algorithm are reflected by the provision of multiple-fetch, multiple-replacement and multiple-buffer-page strategies, which are motivated bythe observation of unsuitability in exercising a ‘one-policy-for-all-patterns’ as in someprevious proposals. The whole buffer area is dynamically partitioned into a collection oflocal buffers on a per-relation basis. The number of frames assigned to a local buffer isassociated with the resident set size of a relation. Each local buffer holding one residentset is separately managed by a set of fetch-replacement policies specially chosen for the
1998 John Wiley & Sons, Ltd. Concurrency: Pract. Exper., 10, 1291–1316 (1998)
BUFFER ALGORITHM FOR DATABASE MACHINES 1295
Figure 2. Interface between RESBAL and other system components
access patterns of the relation in question. A buffer load manager assists a proper allocationof available frames to queries running in parallel.
3.1. Multiple-fetch strategy
A multiple-fetch paging strategy is employed in RESBAL which combines virtues of bothdemand fetches and prefetches, with the objective of using prefetch techniques advanta-geously[10,11] to reduce disk activity and total query elapsed time. The criterion uponwhich a prefetch operation should be activated is when and only when locality or sequen-tiality of reference has been predicted for a particular access. For instance, prefetching isused for two cyclic access patterns (partial cyclic and complete cyclic). The operation isjustified by the available knowledge that in both cases sequentiality is detected and loopingbehaviour over these pages anticipated. This unified approach in RESBAL integrating afetch policy with each access pattern presents a departure from traditional practices.
1998 John Wiley & Sons, Ltd. Concurrency: Pract. Exper., 10, 1291–1316 (1998)
1296 F. F. CAI ET AL.
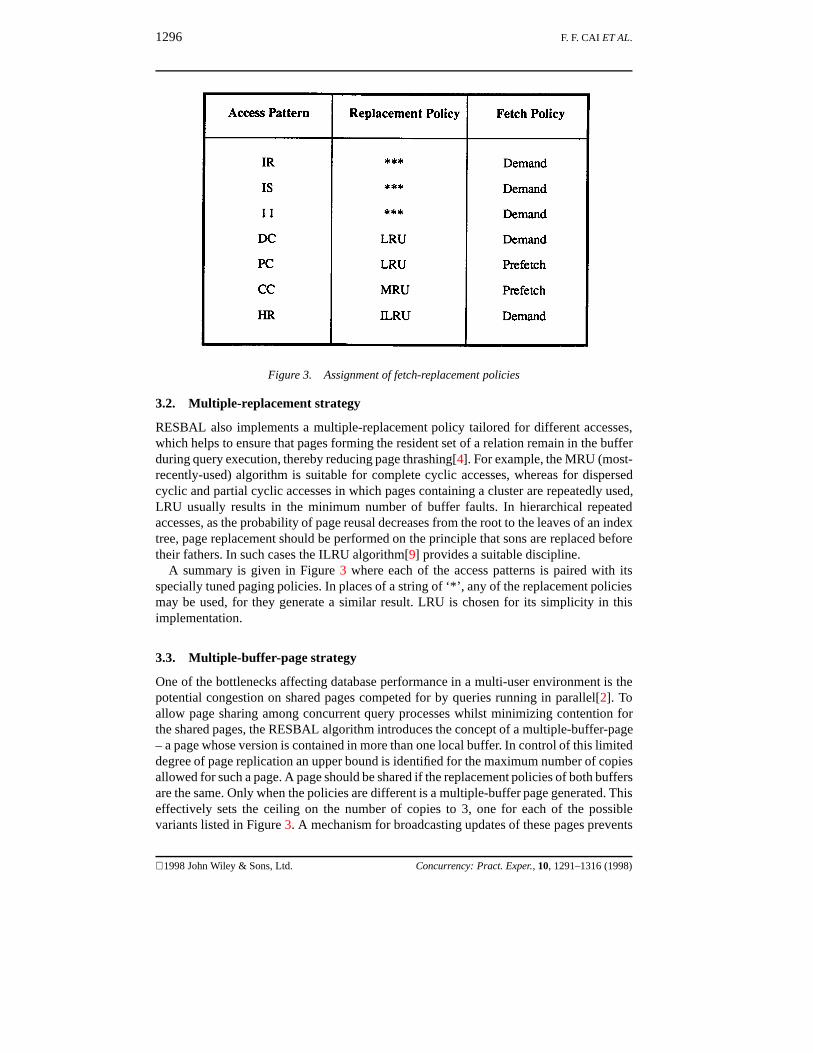
Figure 3. Assignment of fetch-replacement policies
3.2. Multiple-replacement strategy
RESBAL also implements a multiple-replacement policy tailored for different accesses,which helps to ensure that pages forming the resident set of a relation remain in the bufferduring query execution, thereby reducing page thrashing[4]. For example, the MRU (most-recently-used) algorithm is suitable for complete cyclic accesses, whereas for dispersedcyclic and partial cyclic accesses in which pages containing a cluster are repeatedly used,LRU usually results in the minimum number of buffer faults. In hierarchical repeatedaccesses, as the probability of page reusal decreases from the root to the leaves of an indextree, page replacement should be performed on the principle that sons are replaced beforetheir fathers. In such cases the ILRU algorithm[9] provides a suitable discipline.
A summary is given in Figure 3 where each of the access patterns is paired with itsspecially tuned paging policies. In places of a string of ‘*’, any of the replacement policiesmay be used, for they generate a similar result. LRU is chosen for its simplicity in thisimplementation.
3.3. Multiple-buffer-page strategy
One of the bottlenecks affecting database performance in a multi-user environment is thepotential congestion on shared pages competed for by queries running in parallel[2]. Toallow page sharing among concurrent query processes whilst minimizing contention forthe shared pages, the RESBAL algorithm introduces the concept of a multiple-buffer-page– a page whose version is contained in more than one local buffer. In control of this limiteddegree of page replication an upper bound is identified for the maximum number of copiesallowed for such a page. A page should be shared if the replacement policies of both buffersare the same. Only when the policies are different is a multiple-buffer page generated. Thiseffectively sets the ceiling on the number of copies to 3, one for each of the possiblevariants listed in Figure 3. A mechanism for broadcasting updates of these pages prevents
1998 John Wiley & Sons, Ltd. Concurrency: Pract. Exper., 10, 1291–1316 (1998)

BUFFER ALGORITHM FOR DATABASE MACHINES 1297
data consistency from being violated.Although a more detailed presentation of RESBAL can be found in [6], the discussion
so far suffices as a brief summary to our approach. The most important implication of theRS model and its associated RESBAL algorithm is that a query can be processed withmaximum efficiency only when the whole set of pages forming its resident set is kept in thebuffer. The overall performance will deteriorate accordingly whenever some of these pagesare forced out from the buffer due to insufficient space and inappropriate paging policies.To minimize this scenario RESBAL provides a high level of flexibility, with a variety ofmechanisms available which are carefully tailored to the needs of database applications.
4. REALIZATION OF RESBAL ON TRANSPUTERS
The RESBAL algorithm is designed to be generally applicable to relational databasesystems. For this study it has been implemented as part of an early prototype databasesystem based on INMOS transputers[7].
The transputer architecture consists of a closely integrated pair of processors and localmemory, with up to four bi-directional communication channels interacting with the outsideworld. A transputer can work in either stand-alone or multi-process mode, and also as anode within a transputer network, allowing many topologies to be constructed. Parallelprocessing running on such a network can communicate with each other through thechannels. The Occam program language[7] provides elegant and powerful facilities forparallel programming in the transputer architecture.
There are several motivations behind the choice of using transputers to construct adatabase system. Firstly, although the superiority of the transputer in terms of cost/performance compared with other processors has been shown in a number of areas in theliterature, its use in database applications is still relatively new. Therefore, outcome fromexperimentation can serve as useful indications to the effectiveness of using transputers fordatabase machines.
Secondly, the transputer permits dynamic reconfiguration and offers a varying level ofgranularity for parallelism. Relational queries are well suited to parallel execution, as theyconsist of uniform operations applied to uniform streams of data[12]. Using transputers asbuilding blocks it is possible to configure a parallel database system which is efficient inperformance yet flexible in structure.
Finally, it is recognized that a consensus on parallel and distributed database systemarchitecture is emerging. This architecture is based on a shared-nothing hardware design inwhich processors communicate with each other only by sending messages via an intercon-nection network[12]. Transputers seem to be well placed to provide the viable hardwarebase for such an architecture.
4.1. A prototype of a transputer-based database system
The prototype database system is basically of a front-end/back-end configuration, witha transputer network working as the back-end. Database queries are submitted to thefront-end, parsed and validated before being sent to the back-end for processing. Uponcompletion of the queries the results are returned to the front-end.
In the present topology, the back-end transputer network is essentially a tree structure,with the transputer at the top level interacting with the front-end system and the transputers
1998 John Wiley & Sons, Ltd. Concurrency: Pract. Exper., 10, 1291–1316 (1998)

1298 F. F. CAI ET AL.
at the bottom level being connected with the disk to access the physical database. Thebuffer manager based on the RESBAL algorithm facilitates data exchange between thedisk system and the transputer network. Acting as a query execution engine, the back-endmachine distributes a collection of tasks over the available transputers in the system so thata query can be processed by several transputers if necessary, and several queries executedin parallel.
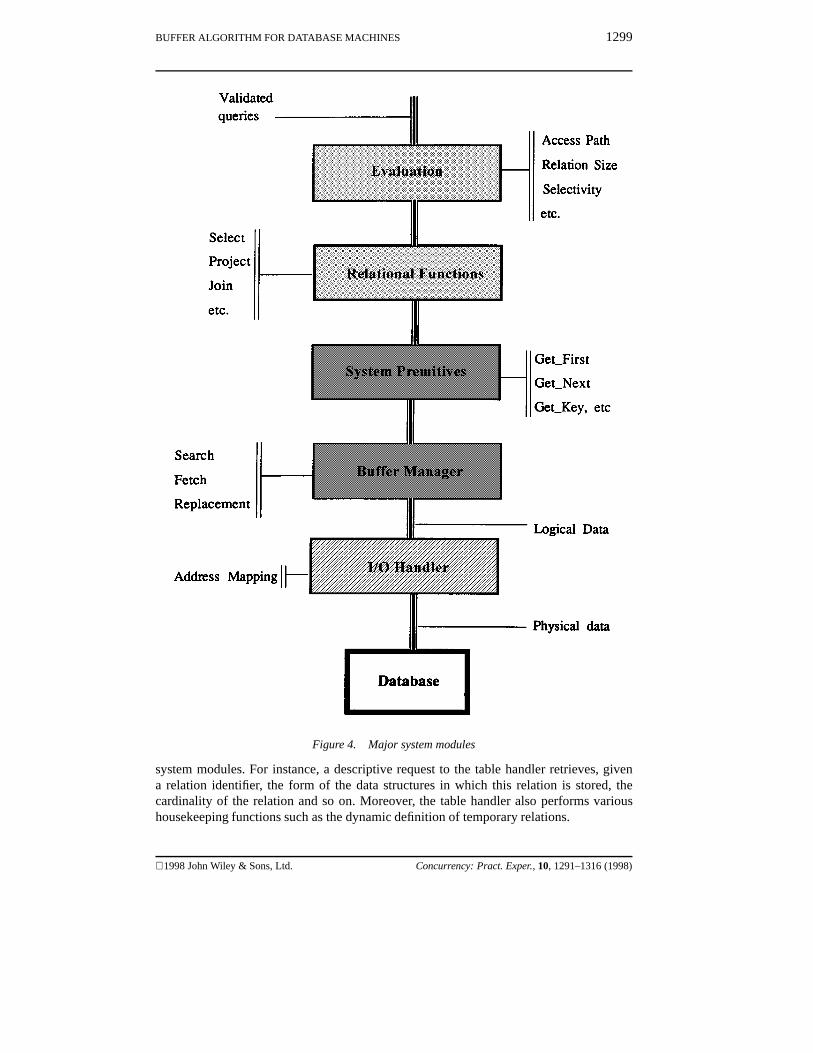
There are several basic system modules residing at different levels. Each of these modulesis required to perform a set of functions, interact with other modules where necessary, andhave access to relevant system data and other data structures. Each level encapsulates aparticular view of the system supported by the levels below. Figure 4 illustrates a set ofbasic functional modules in the system.
4.1.1. Bottom level – I/O handler
The I/O handler sits at the bottom level of the system, between the transputer network andthe physical database. Its main operations include mapping logical page requests from thebuffer manager to physical page accesses to the database, and controlling data exchangebetween the buffer and the disk. Each disk is connected to an associated transputer whichacts as both a disk controller and, if required, a gateway to higher-level functions, providing,for example, on-the-fly operation to filter away unwanted tuples. To the higher levels, theI/O handler is simply a supplier of a string of logical pages required for query operations.
4.1.2. Middle level – system primitives and buffer manager
This level provides a basic set of primitive tuple functions which can be combined to providehigher-level operations. All the functions operate on logical pages which are assumed tobe accessible in the main memory through buffering. So far as the system primitives areconcerned the database can be viewed as a sequence of logical pages permanently availablein memory.
The buffer manager takes control of the buffer area inside transputers to make sure thatthe logical pages necessary for operations are in memory when needed. By implementing analgorithm based on RESBAL, the buffer manager sustains the illusive image that the entiredatabase resides in the transputer memory throughout the execution of database queries,thus divorcing the higher levels from any physical storage considerations.
4.1.3. Top level – relational functions and evaluation
These modules provide high-level database functions. The evaluation module is responsiblefor receiving validated user queries, evaluating various query execution plans and perform-ing high-level scheduling. It communicates with the system dictionary to obtain requiredinformation for query optimization. The Relational Functions module then executes queryplans by performing required relational operations, such as select, project and join, on therelations in question.
It should be noted that Figure 4 and its brief overview by no means presents a completesystem specification, but only a simplified image of the system functionality. There aremodules which do not belong to any level in particular and which are not included in theFigure. One example is a table handler which stores and provides information for other
1998 John Wiley & Sons, Ltd. Concurrency: Pract. Exper., 10, 1291–1316 (1998)
BUFFER ALGORITHM FOR DATABASE MACHINES 1299
Figure 4. Major system modules
system modules. For instance, a descriptive request to the table handler retrieves, givena relation identifier, the form of the data structures in which this relation is stored, thecardinality of the relation and so on. Moreover, the table handler also performs varioushousekeeping functions such as the dynamic definition of temporary relations.
1998 John Wiley & Sons, Ltd. Concurrency: Pract. Exper., 10, 1291–1316 (1998)

1300 F. F. CAI ET AL.
Figure 5. A double-buffer within a transputer
4.2. Buffer management for transputer local memory
When contemplating a database system on a transputer network rather than on a moretraditional architecture, it gives rise to a set of new design problems one of which is theefficient implementation of a buffer manager. As a transputer is basically a processor/localmemory pair, a transputer network can be viewed as a loosely coupled multiprocessorsystem. In such a system, interaction between connecting transputers can be very frequent.Furthermore, there is generally no easy way to construct a shared-memory structure withoutincurring costly inter-transputer communication. To diminish the potential adverse impactof this problem on the overall system performance, the following approaches have beenconsidered.
4.2.1. For I/O- or control-intensive applications
For those transputers which perform mainly system control functions rather than dataprocessing, a simple local buffer manager may suffice which employs a simple bufferstrategy, such as the Random, FIFO or LRU algorithm. A double buffer structure can beuseful for input/output oriented applications, where available buffer space in a transputeris divided into two areas, say A and B. While the processor is consuming the data storedin buffer A, buffer B can at the same time receive more incoming data. The processor thenperiodically switches over to accessing data from buffer B when it is full or when buffer Ais empty. This method is illustrated in Figure 5.
4.2.2. For data-intensive applications
For those transputers performing relational operations (more often that not, operating onlarge volumes of data), a more complex and efficient buffer algorithm like RESBAL isneeded in order to improve the buffering performance of the system. In this case, the
1998 John Wiley & Sons, Ltd. Concurrency: Pract. Exper., 10, 1291–1316 (1998)

BUFFER ALGORITHM FOR DATABASE MACHINES 1301
Figure 6. Extending local memory through neighbouring transputers
RESBAL based algorithm is copied to each of these transputers to manage its local mem-ory. Communications and data migration are achieved via data links between connectingtransputers.
4.2.3. Extending local memory
Furthermore, to exploit the possible horizontal parallelism in processing a relational oper-ation, and increase buffer capacity when the resident set of relation(s) in question exceedswhat a single transputer local memory can accommodate, one or more transputers may beadded simply for the benefit of extending the local memory. These added transputers shouldbe connected directly where possible to the transputer concerned, as illustrated in Figure 6.This physical adjacency in the transputer interconnection reduces the communication costbetween them. The extended memory created by the neighbouring transputers also helpsminimize disk accesses as the whole resident set needed may now be accommodated.
4.3. Applying RESBAL onto transputers
We now proceed to describe how the RESBAL based buffer algorithm is implemented forthe transputer memory in our system. Each relation in the database is maintained as a file ofpages which are ultimately stored on disk. When the system is active, an area of memory isset aside in each transputer for use as a buffer space for logical pages. The buffer is dividedinto a set of page frames of equal length, each of which can hold one logical page. Initially,each page frame is marked as empty and free.
During execution of a query operation a template operator[13] may need to read, modifyor write a page. When a page is read from disk it is copied into an allocated buffer frame.Similarly, when a page is written by a template operator it is actually written to a bufferframe and only flushed out to disk when necessary.
The RESBAL based buffer manager is operated as three processes: the page handler,the size handler and the replacement handler. The page handler process acts as a receptionclerk for the buffer manager. It receives incoming page requests and other messages. Whenthese requests are met, the required information is returned to the calling process.
1998 John Wiley & Sons, Ltd. Concurrency: Pract. Exper., 10, 1291–1316 (1998)

1302 F. F. CAI ET AL.
The size handler process estimates the resident set size of a relation to be referencedwhen the first page request to that relation is received. It allocates an appropriate number ofbuffer frames to that relation, and issues a prefetch instruction where applicable. When themessage arrives indicating the end of the accesses to the resident relation, the correspondingset of buffer frames holding the pages from the relation is set free.
The replacement handler process is responsible for handling page faults, placing incom-ing pages, and selecting candidates for replacement when there is no free buffer frame leftin the allocated buffer area. A set of replacement policies tailored to the current relationaloperations is exercised. This set of replacement policies, described in Section 3, is passedfrom the size handling process to the replacement handling process at the start of theexecution.
The buffer manager maintains information about the current status of all buffer pages andabout current page requests in two separate linked list structures. These are the active-pagelist (APL) and the free-page list (FPL).
Each entry on the APL represents an active buffer page and contains the followinginformation: the page ID, the relation ID (to which the page belongs), a ‘busy’ countshowing the number of processes accessing the page, a timestamp recording the latest timeof reference to the page, and a ‘dirty’ mark indicating if the page has been updated sincebeing brought into the buffer. All free pages in the buffer are connected in another liststructure called a free-page list, FPL, where each entry denotes a free buffer frame. A freebuffer frame can be either of the following two types. In the first instance, it can be aframe holding a page released by a terminated operation. In this case, the information aboutthe page ID, relation ID and timestamp remain in the entry for possible future use. In thesecond instance, a buffer frame which is yet to be occupied by an incoming logical page isregarded as empty. This is indicated by setting to 0 the page ID, relation ID and timestampin its FPL entry. The FPL is arranged in the least recently used (LRU) order.
The buffer manager operates as follows: when the page handler receives a page requestfrom a template process a page search is initiated. If the page is already in the buffer and idlethen its buffer address (i.e. its buffer frame identifier) is passed to the requesting process.If the page is on the FPL then it is moved from that list to the APL. If the page is presentin the APL but busy the request is added to the queue waiting for that page. If the page isnot in the buffer at all then the page request is forwarded to the buffer replacement handlerfor a disk access.
When a process has consumed a page it informs the page handler, also specifying whetherthe page is clean (i.e. having been read only) or dirty (having been written over). If thepage is dirty then its dirty mark is set to 1. Non-resident pages are transferred to the FPL.Resident pages become non-resident when the initiating template process has completedan operation and has no further use of them (e.g. when a nested loop join has completed).
As well as handling requests from the template processes, the page handler also processesmessages from the disk controller. These messages arise when the disk controller hascompleted a task (such as retrieving a page from disk, writing a page to disk, etc). Eachmessage contains status information which the page handler forwards to the appropriateprocess. If the page has been fetched from disk then the associated buffer frame identifieris sent to the template process. If the page has been written to disk then the page is markedas clean and the page handler notifies the template process that the physical write hasoccurred.
1998 John Wiley & Sons, Ltd. Concurrency: Pract. Exper., 10, 1291–1316 (1998)

BUFFER ALGORITHM FOR DATABASE MACHINES 1303
5. PERFORMANCE EVALUATION OF RESBAL
This Section discusses the performance issue of RESBAL and other buffer algorithmsand presents results obtained from the evaluation study. The Section is organised into twoparts. The first part outlines the method used in the evaluation. Several key aspects of theevaluation model are described, which include the construction of a synthetic database andsource relations, choice of relational query operations, variation of system workload, andselection of buffer algorithms. The second part presents empirical results from the perfor-mance assessment and summarises important observations. Situations in which RESBALdoes not perform favourably are also identified. The outcome of this evaluation providessome insight into the merits and deficiencies of each individual algorithm studied and offersuseful indications to the relative performance of RESBAL and its counterparts.
5.1. Establishment of an evaluation environment
To study the efficiency of the RESBAL algorithm and compare it with that of other bufferalgorithms, it is necessary to establish an environment as a test-bed where the performanceof various buffering algorithms can be investigated under a set of common criteria. As thedata input to the system, a synthetic database was constructed which consisted of severalsource relations with varying structures and sizes. A number of common relational queryoperations were performed on this database and both single-relation queries and multi-relation queries were executed. Such a performance test-bed allows some major systemparameters to be varied to reflect different conditions in a real database environment.
5.1.1. A synthetic database and source relations
A synthetic database was constructed for the evaluation. The main consideration andadvantage of using a synthetic database rather than a ‘real’ one is that a synthetic databasecan be automatically generated with precise control of some important parameters, suchas value distribution, selectivity and data volume. As a result, their impact on bufferingperformance can be carefully examined and measured.
The database, whose structure is similar to that introduced in [14], contains a number ofsource relations with different sizes. Figure 7 illustrates the structure of one of the sourcerelations named R1.ONEKT, in which each tuple has ten attributes with a total length of 32bytes, and the relation contains 1k tuples. A detailed schema for the database is providedin the Appendix.
5.1.2. Relational operations
Selecting database query operations and developing system work loads are other key aspectsof the evaluation. To this end, a number of relational operations known to be typical ina real database environment were chosen to form benchmark queries for the performancestudy. These operations include: select, project, join and aggregate. They are frequentlyused in both commercial and scientific database applications.
Select with different selectivity factorsProject with duplicate attributeJoin with nested loopAggregate such as MIN value of a key attribute
1998 John Wiley & Sons, Ltd. Concurrency: Pract. Exper., 10, 1291–1316 (1998)

1304 F. F. CAI ET AL.
Figure 7. Structure of a source relation
Note that there are two groups of relational operations in terms of whether there are modi-fications to a source relation during the execution: retrieval operations where no change ismade and update operations where changes are made. All the above are retrieval operations.Update operations (such as delete, insert, append and modify) are not implemented at thisstage. In practice, these update operations can usually be realized by implementing cer-tain types of retrieval operations followed by proper adjustments in ordering to the sourcerelations concerned.
5.1.3. Buffer algorithms for evaluation
To conduct a meaningful performance assessment of the proposed RESBAL algorithm, it isnecessary to compare it with other buffer algorithms under the same system environment, sothat merits and deficiencies of each algorithm are exposed and identified. For this purpose,four buffer management algorithms were evaluated, which are divided into two groups interms of the level of complexity in the algorithm.
1998 John Wiley & Sons, Ltd. Concurrency: Pract. Exper., 10, 1291–1316 (1998)

BUFFER ALGORITHM FOR DATABASE MACHINES 1305
The first group represents the class of algorithms that have previously been proposedfor database systems. In addition to the RESBAL algorithm, HS (hot set model basedalgorithm) and DBMIN (QLS model based algorithm) were included in this group. Whilstthis first group was of more sophisticated algorithms, the simple LRU algorithm wasselected as the second group because it is a typical page replacement algorithm and easyto implement. Furthermore, a wealth of literature has shown that LRU performs well forgeneral purpose operating systems. It is therefore interesting to assess its usefulness fordatabase applications and compare it for performance with more sophisticated algorithmsto see if their added complexity is justified.
As far as the replacement policy is concerned, LRU can be viewed as a global algorithm inthe sense that the replacement discipline is applied globally to all the buffers in the system.The algorithms in the first group, on the other hand, are local policies, in which replacementdecisions are made within each local buffer pool. Moreover, all three algorithms base theirload control on the (estimated) memory demands of the submitted queries. A new query isactivated only if there is sufficient free space available in the system.
5.1.4. System work load
The efficiency of a buffer algorithm is not only determined by the way in which thealgorithm exploits advance knowledge of query reference, but is also influenced by thelevel of system workload. Therefore, the evaluation model allows the system workload tobe varied to reflect the dynamic nature of a multi-user database environment. Both single-relation query operations and multiple-relation query operations were performed in thesimulation runs. To quantify the results, a set of statistical measurements, such as bufferpage faults, and query elapsed time, are used as the performance metrics.
5.2. Evaluation outcome
As mentioned above, the performance study conducted allows various comparisons to bemade of the effectiveness of RESBAL with that of its counterparts under the same systemenvironment. This Section presents some results obtained from the evaluation and analysesthe differences and similarities between the buffer algorithms concerned. Furthermore,situations where the RESBAL algorithm does not produce favourable outcomes are alsodiscussed.
5.2.1. In relation to join operations
Since a join is perhaps the most complex and ‘expensive’ relational operation, efficientjoin processing is critical for an acceptable database system performance. It is clear thatdifferences in join performance result from not only the selection and quality of a joinalgorithm itself, but also the efficiency of the buffer algorithm used.
A common pattern is that join algorithms extract a tuple from the first relation (outerrelation) and use the value of its join attribute as the search key to do a selection on thesecond relation (inner relation). By applying the resident set model, the page referencepattern to the outer relation is always independent-sequential, so it is the reference patternto the inner relation which differs. For the nested loop join algorithm, the access pattern tothe inner relation is complete-cyclic (see Section 2).
1998 John Wiley & Sons, Ltd. Concurrency: Pract. Exper., 10, 1291–1316 (1998)
1306 F. F. CAI ET AL.
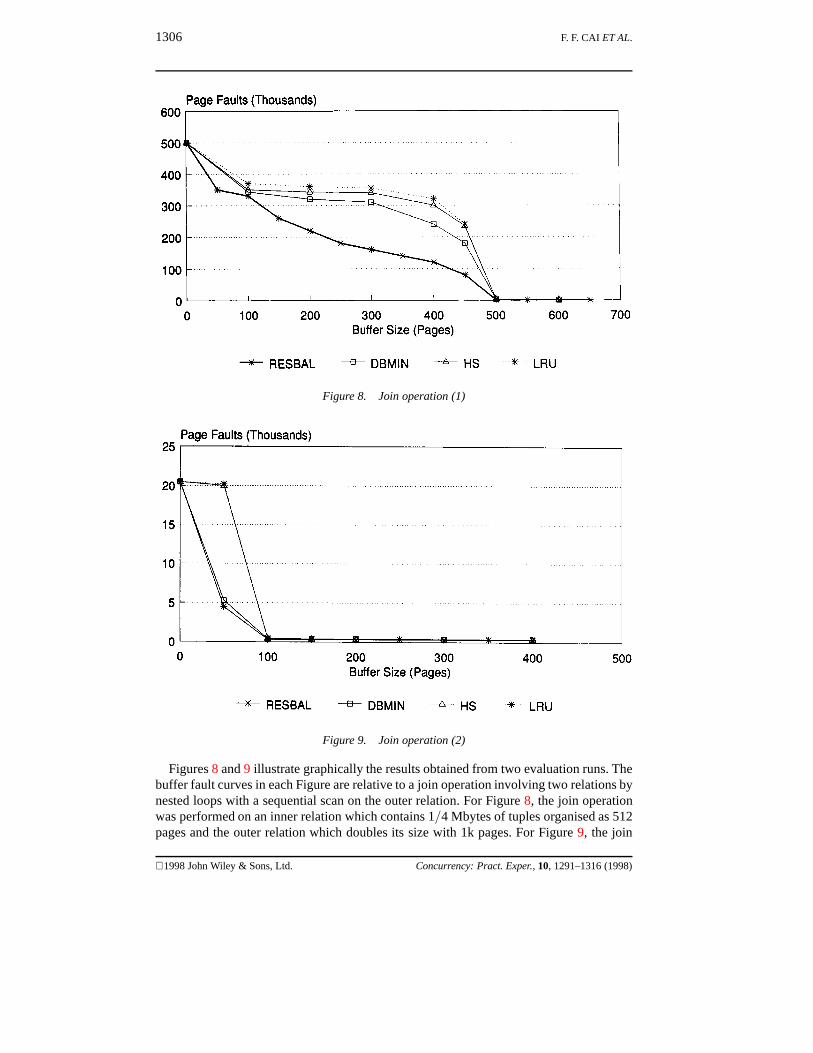
Figure 8. Join operation (1)
Figure 9. Join operation (2)
Figures 8 and 9 illustrate graphically the results obtained from two evaluation runs. Thebuffer fault curves in each Figure are relative to a join operation involving two relations bynested loops with a sequential scan on the outer relation. For Figure 8, the join operationwas performed on an inner relation which contains 1/4 Mbytes of tuples organised as 512pages and the outer relation which doubles its size with 1k pages. For Figure 9, the join
1998 John Wiley & Sons, Ltd. Concurrency: Pract. Exper., 10, 1291–1316 (1998)

BUFFER ALGORITHM FOR DATABASE MACHINES 1307
was performed on R1.ONEKT as the inner relation (with 1 k tuples, 64 pages) and onR3.FIVEKT as the outer relation (with 5 k tuples, 320 pages).
Under RESBAL two separate access patterns and resident set sizes for the two relationsinvolved in this operation were first predicted. The outer relation conformed to the indepen-dent sequential access for which demand fetches paired with an LRU replacement policywere implemented, whilst the inner relation conformed to the complete cyclic access andwas processed with a MRU replacement policy coupled with a prefetch operation.
As indicated in both Figures, all four buffer algorithms chosen for the study, RESBAL,DBMIN, HS and LRU, were evaluated under this situation. There were several interestingfindings with regard to the join operations.
Firstly, it is clear from Figure 8 that RESBAL resulted in a substantially lower level ofbuffer faults than the other algorithms over a wide range of available buffer space. Thiswas mainly a result of RESBAL’s prefetch policy. Predicting that the entire inner relationwould be needed for the operation, RESBAL deliberately brought as many pages of therelation as possible into the buffer before they were actually requested, thereby reducingthe ‘future’ buffer faults substantially. This reduction should obviously lead to a sharpfall in the number of disk accesses. On the other hand, the HS and DBMIN algorithmsproduced similar fault curves due to their demand-only fetch policy, which failed to takefull advantage of the available buffer space.
Secondly, a sharp fall in the number of buffer faults was witnessed in Figure 8 forall the curves around the buffer size of about 500 pages, indicating strongly that whensufficient buffer frames were allocated to accommodate the whole inner relation (whichwas repeatedly scanned by the outer relation), the buffer page faults could be decreased toa minimum. This point has been observed by others[4]. As a result, the disk activity wasalso sharply reduced. This finding was confirmed again in Figure 9, where there is a steepdrop in buffer faults after the buffer size increases towards 100 pages (note that the innerrelation contains 64 pages).
Thirdly, the difference in Figure 9 between the RESBAL and the DBMIN was muchless noticeable than that in Figure 8. The reason is that, for join operations, only an innerrelation is prefetched under the RESBAL regime. In this case the size of the inner relation(64 pages) is much smaller than the outer relation (320 pages). Compared to the total numberof buffer faults, the reduction brought about by the prefetch operation in this circumstancewas almost negligible. Therefore, the smaller the inner relation, the less noticeable thebenefit of prefetching.
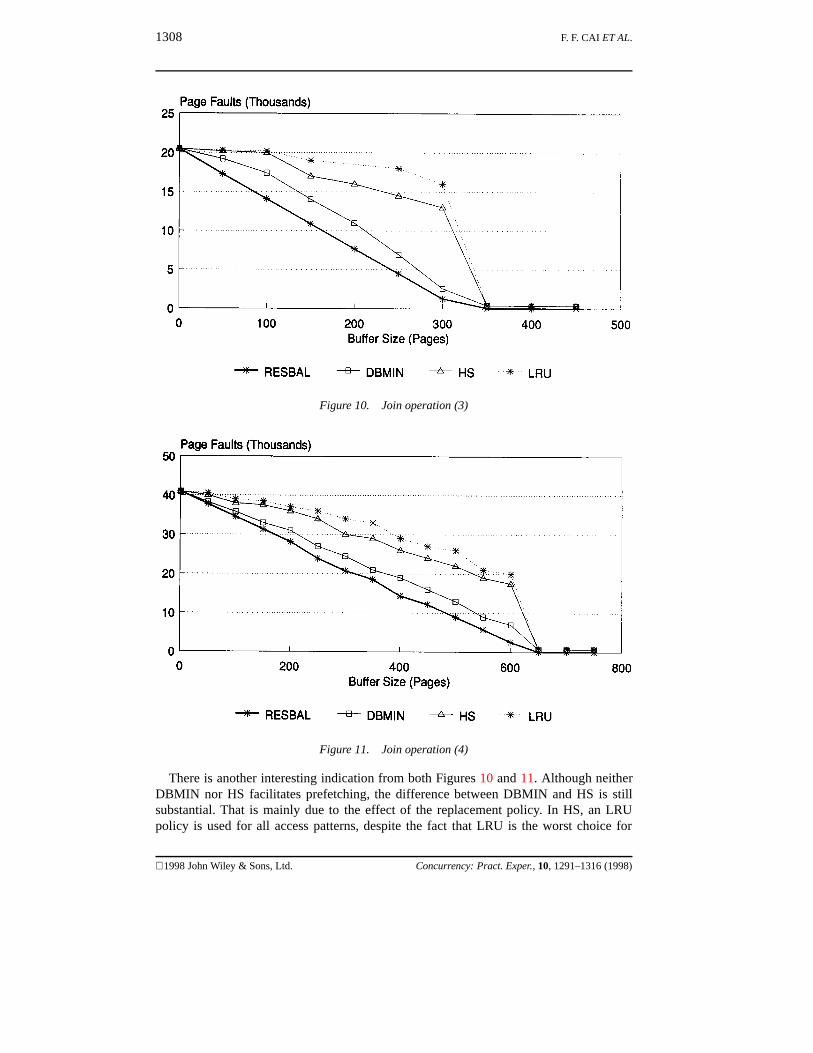
As opposed to the join operations shown in Figures 8 and 9, which involve smallerinner relations and bigger outer ones, Figures 10 and 11 depict two join operations, each ofwhich uses a bigger inner relation and a smaller outer relation. For Figure 10, the join wasoperated on R3.FIVEKT (with 5 k tuples organized as 320 pages) as the inner relation andon R1.ONEKT (with 1 k tuples, 64 pages) as the outer one. For Figure 11, the join usesR5.TENKT (with 10 k tuples, 640 pages) as the inner relation and R1.ONEKT (with 1ktuples, 64 pages) as its outer relation.
As expected, a significant reduction in buffer faults achieved by the RESBAL algorithmis demonstrated in both Figures 10 and 11. This again confirms the usefulness of the prefetchpolicy for nested loop joins. Together with the findings from Figures 8 and 9, an importantconclusion can be drawn from here. That is, the bigger the inner relation in a join operation,the more apparent the benefit of prefetching, the bigger the reduction in buffer faults, andhence the better performance the RESBAL algorithm offers.
1998 John Wiley & Sons, Ltd. Concurrency: Pract. Exper., 10, 1291–1316 (1998)
1308 F. F. CAI ET AL.
Figure 10. Join operation (3)
Figure 11. Join operation (4)
There is another interesting indication from both Figures 10 and 11. Although neitherDBMIN nor HS facilitates prefetching, the difference between DBMIN and HS is stillsubstantial. That is mainly due to the effect of the replacement policy. In HS, an LRUpolicy is used for all access patterns, despite the fact that LRU is the worst choice for
1998 John Wiley & Sons, Ltd. Concurrency: Pract. Exper., 10, 1291–1316 (1998)

BUFFER ALGORITHM FOR DATABASE MACHINES 1309
Figure 12. Select operation (1)
complete cyclic accesses. In contrast, both DBMIN and RESBAL implement an MRUpolicy which is more suitable for that access pattern.
5.2.2. In relation to select operations
Compared to a join, which is a multiple-relation operation, a select is a simpler operationwhich involves only one source relation. When no access structures are available, anindependent sequential access is the only way to execute a select operation.
Results of several select operation runs (with 10% selectivity) are shown in Figure 12,in which RESBAL and HS algorithms are evaluated and compared in terms of run-timeperformance. As an independent sequential access pattern is expected for this operation,RESBAL employs again the prefetch tactic when there is free space left in the buffer. Inthis case prefetching 10% of the total number of pages in a source relation is performed.The HS algorithm, on the other hand, simply exercises a simple demand–fetch policy.
From the results listed it is not difficult to understand that the long elapsed time (in CPUclock ticks) incurred for the HS algorithm is closely related to the increased number of diskaccesses, a reason confirmed by the very low buffer page hit-ratio associated with the HSimplementation. On the other hand, RESBAL offers substantial performance improvementin terms of a shorter elapsed time and higher buffer hit-ratio, thanks to the prefetch tactic.
The performance improvement of RESBAL over other algorithms is illustrated graphi-cally in Figure 13. It is associated with a select operation on the source relation R4.TENKT(with 10 k tuples, 640 pages). In these simulation runs, RESBAL prefetches as manyrelation pages as possible up to the size of the available buffer space.
As demonstrated in the Figure, a dramatic fall in buffer faults with the increase of buffersize is recorded for RESBAL. In contrast, the LRU, HS and DBMIN algorithms, withno provision of prefetches, performed poorly. The buffer faults remain high and almoststatic, regardless of the increase in available buffer space. This is the direct result of their
1998 John Wiley & Sons, Ltd. Concurrency: Pract. Exper., 10, 1291–1316 (1998)

1310 F. F. CAI ET AL.
Figure 13. Select operation (2)
demand–fetch policy, which is incapable of responding to the dynamic changes in buffersize.
5.2.3. In relation to project operations
A project operation, without elimination of duplicate tuples, usually involves a sourcerelation and an intermediate relation to collect the projected result. Attributes within asource tuple may be eliminated or transposed. No matter what is required for the project,however, the page reference to the source relation always follows the independent sequentialpattern.
Figure 14 presents the performance results of RESBAL and three other algorithms in aproject operation. It was executed on the source relation R3.FIVEKT, which has 5 k tuplesorganised as 320 pages. As expected, the patterns of all the curves representing differentbuffer algorithms are quite similar to those seen from Figure 13 for select operation. Thisis not strange because, although select and project are two different operations, both ofthem follow the independent sequential access pattern in the execution. Therefore, someearlier analysis and discussion on select operations in the last Section are also applicableto the project operation. When RESBAL exercises a prefetch buffer policy, a significantperformance improvement in terms of buffer page faults over other algorithms can beachieved.
5.2.4. In relation to aggregate operations
Simple aggregate operations, such as MIN, MAX and SUM, are provided by many databasesystems. In spite of the difference in semantics, the reference patterns of aggregate opera-tions to the source relation remain the same, namely independent sequential. Thus, the pagereference behaviour of an aggregate operation is again similar to that of a project operationand a select operation.
1998 John Wiley & Sons, Ltd. Concurrency: Pract. Exper., 10, 1291–1316 (1998)

BUFFER ALGORITHM FOR DATABASE MACHINES 1311
Figure 14. Project operation
Figure 15. Aggregate operation
Results of an aggregate operation are shown in Figure 15, which involves a MIN andMAX search operation on the source relation R2.TWOKT with 2 k tuples organized as 128pages. As all the discussions on project operations apply to aggregate operations as well,the detailed analysis of the graph is not repeated here.
5.3. Some observations
The evaluation outcome presented so far is intended to serve as a useful indication tothe relative efficiency of the buffer algorithms tested. They have provided insight into the
1998 John Wiley & Sons, Ltd. Concurrency: Pract. Exper., 10, 1291–1316 (1998)

1312 F. F. CAI ET AL.
merits and deficiencies of each individual algorithm, and allowed comparisons to be madebetween RESBAL and other buffer algorithms under the same environment. In general,the results from the evaluation experiments have suggested that the RESBAL algorithmoutperformed its counterparts in most cases due to its flexible strategies being availablefor different access patterns. Retaining the resident set pages of relations in the bufferconsiderably reduced buffer fault rate and page thrashing, henceforth increasing the overallsystem throughput.
For join operations performed in the evaluation, the RESBAL algorithm results in asubstantially lower level of buffer faults than the other algorithms when buffer space isinsufficient to hold the entire inner relation (which is repeatedly referenced). This reductionin buffer faults, which also leads to a sharp fall in the number of disk accesses, is a directresult of RESBAL’s prefetch policy. In contrast, other algorithms produce similar faultcurves due to their demand–fetch policy, which fails to take advantage of the availablebuffer space.
When the size of the inner relation is much smaller than the outer relation in a joinoperation, however, the benefit brought about by the prefetch policy becomes almostnegligible. This is because, in this circumstance, access to the outer relation pages producesmany more buffer faults than access to the inner relation pages. One conclusion can thereforebe drawn from here. The bigger the size of the inner relation, the more apparent is the benefitof prefetching and the bigger the buffer fault reduction which RESBAL produces.
Apart from the prefetch policy, page replacement policies also play an important part inperformance improvement. For example, the MRU policy performs better than LRU forcyclic accesses. This explains the outcome that RESBAL produces much better results thanthe HS algorithm for join operations even when the buffer is not big enough to keep thewhole inner relation (see Figure 9).
For select, project and aggregate operations conducted in the simulation, the results showconsistently a better performance of RESBAL over other algorithms when prefetching isagain employed. The performance improvement is manifested in terms of shorter queryexecution time, fewer buffer faults and reduced disk accesses.
Nevertheless, there are indeed situations where the RESBAL algorithm performs nobetter than its counterparts. These usually occur when the buffer space available is eithertoo small or too big for the buffer requirement of a given query operation. On one hand, whenthe available buffer area is too small (e.g. only a fraction of the required resident sets can beaccommodated) the replacement of buffer pages is forced to take place so frequently that theeffect of different buffer algorithms diminishes greatly. On the other hand, when the bufferis large enough to contain all the pages from relations pertinent to the operation (no pagereplacement is needed), even a very crude algorithm produces a similar performance to thatof a much more sophisticated algorithm. In these environments the extra level of complexityof the sophisticated algorithm, such as RESBAL, becomes an unjustifiable disadvantage,as its sophistication and flexibility contribute little to the performance improvement, onlyto add to the system overheads. However, these extreme situations only represent verylimited, if not extreme, cases in real world database environment.
Some general conclusions can be drawn here. The results from the evaluation study haveindicated that the RESBAL algorithm outperforms its counterparts in most cases thanks toits highly flexible paging strategies being available for different access patterns. A markeddecrease in buffer faults and page thrashing can be realised if pages forming the residentsets of relations are retained in the buffer during the query execution. Obviously, this
1998 John Wiley & Sons, Ltd. Concurrency: Pract. Exper., 10, 1291–1316 (1998)

BUFFER ALGORITHM FOR DATABASE MACHINES 1313
decrease improves the overall system performance. For queries where a prefetch policy isapplicable, a significant fall in disk accesses is observed.
6. SUMMARY
This paper has reported on a buffering algorithm named RESBAL for high-performancedatabase systems. The design philosophy behind RESBAL is to deliver both predictabilityand effectiveness for database buffer management This is achieved by the provision of aset of flexible paging policies, with a variety of mechanisms available. The main featurescan be summarized as: dynamic partitioning of buffers as a per-relation/per-query basis;employment of a prefetch policy combined with a demand fetch policy; implementation ofmulti-replacement policies for different accesses, and provision of multi-buffer pages forminimizing contention on shared pages. All these features combine to make the algorithma serious contender for high-performance database systems.
Our experiment with a prototype parallel database machine on which the RESBAL basedalgorithm has been implemented aims to design a system which offers both flexibility andefficiency in performance, while maintaining a simple yet extensible configuration. Wechose a structure based on the transputer architecture, since it offers a suitable approach forconstructing high-performance parallel machines using standard building blocks.
A performance study has been carried out to assess and compare the run-time efficiencyof the RESBAL algorithm with that of other buffer algorithms proposed previously. A setof example results obtained from the evaluation has suggested that the RESBAL algorithmperforms well in most cases due to its highly flexible paging policies tailored to the needsof database applications. The performance study indicates that the algorithm provides astep forward towards optimization of database buffer management and design of efficientdatabase systems based on parallel architectures.
While our experiment has shown the implementation of the RESBAL for a distributedmemory system based on the transputers, we believe that the results presented in this papercan be extrapolated to cover a range of architectures typically used by commercial databases.This could be achieved, for example, in a shared-memory architecture, by grouping andplacing together the partitioned buffers implemented here into the common memory.
As we enter the so-called Information Age, the performance of database systems hasbecome an increasingly critical issue. Efficient information retrieval and processing isessential to many new uses of database systems, such as multimedia systems, data miningand data warehousing[15]. It is hoped that this work will provide some useful input to theresearch on developing high-performance database systems.
APPENDIX: SCHEMA OF A SYNTHETIC DATABASE
The Appendix outlines the specifications of the synthetic database designed for the evalu-ation study.
1 Notation
The following symbols are used in the specifications:
TNT total number of tuples in a relationNDV total number of distinct values in an attribute
1998 John Wiley & Sons, Ltd. Concurrency: Pract. Exper., 10, 1291–1316 (1998)

1314 F. F. CAI ET AL.
PTR percentage of tuples retrieved by selecting a distinct value of an attributeNTR number of tuples retrieved by selecting a distinct value of an attribute.
It then follows that
NTR = TNT× PTR (1)
PTR = NTR/TNT (2)
NDV = TNT/NTR = 1/PTR (3)
2 Structures of source relations
The form below presents the structure of a source relation in which each tuple has tenattributes:
Key1 Key2 1per 2per 5per 10per 20per Str1 Str2 Str3
The descriptions of each attribute above are as follows:
Key1
1. comprising unique values ranging from 1 to TNT2. used as primary keys (unsorted).
Key2
1. having the same range of values as Key1, but with different ordering2. used as foreign keys, on which sorting operations can be performed, and also on
which a retrieval of 50% tuples of a relation can be executed by simply issuing acommand ‘Retrieve tuples Where Key2 = odd/even numbers’
3. used as primary index keys.
1per–20per
1. These are a set of integer-typed attributes that assume non-unique values, with thenumber of distinct values ranging from 5 to TNT, as shown below:
ATTR Key1 Key2 1per 2per 5per 10per 20perNDV TNT TNT 100 50 20 10 5
2. These values are assumed to be in a uniform distribution, i.e.
Number of V (i) = Number of V (j), where i, j = 1 . . .NDV.
3. Each attribute name implies the corresponding percentage of tuples to be retrievedby a single value selection within the domain, the number of tuples to be returned byselecting one of the distinct values being given by formula (1) above.
4. When PTR, NDV are fixed, NTR is proportional to TNT.5. With variations of selecting several values within an attribute, or across several
attributes, any percentage retrieval of tuples may be achieved.
1998 John Wiley & Sons, Ltd. Concurrency: Pract. Exper., 10, 1291–1316 (1998)

BUFFER ALGORITHM FOR DATABASE MACHINES 1315
Str1
1. consisting of a character string of six letters in a form: ‘$****$’. ‘*’ represents anyrandom letter, whereas ‘$’ denotes a capital letter within the domain {A. . .Z}
2. unique string values are assigned to this attribute, giving the number of variations tobe (26× 26)
3. used as primary string keys.
Str2
1. consisting of the same group of string values as Str1, but with different ordering2. used as foreign keys for string operation.
Str3
1. Similar to 1per–20per, used as selectivity factors in string retrieval operations.
3 Schema for Source Relations
R1.ONEKT = (Key1=i2, Key2=i2, Oneper=i2, Twoper=i2, Fiveper=i2, Tenper=i2,
twentyper=i2, Str1=c6, Str2=c6, Str3=c6)
R2.TWOKT = (Key1=i2, Key2=i2, Oneper=i2, Twoper=i2, Fiveper=i2, Tenper=i2,
twentyper=i2, Str1=c6, Str2=c6, Str3=c6)
R3.FIVEKT = (Key1=i2, Key2=i2, Oneper=i2, Twoper=i2, Fiveper=i2, Tenper=i2,
twentyper=i2, Str1=c6, Str2=c6, Str3=c6)
R4.TENKT1 = (Key1=i2, Key2=i2, Oneper=i2, Twoper=i2, Fiveper=i2, Tenper=i2,
twentyper=i2, Str1=c6, Str2=c6, Str3=c6)
R5.TENKT2 = (Key1=i2, Key2=i2, Oneper=i2, Twoper=i2, Fiveper=i2, Tenper=i2,
twentyper=i2, Str1=c6, Str2=c6, Str3=c6)
4 Size estimation
Tuple size
Attributes No. of attr. Each Subtotal Total
Key1–20per 7 @2 14Str1–Str3 3 @6 18 32
The numbers for ‘Each’, ‘Subtotal’ and ‘Total’ are allin bytes.
Page size
Page size (Bytes) No. of tuples contained
512 16
1998 John Wiley & Sons, Ltd. Concurrency: Pract. Exper., 10, 1291–1316 (1998)

1316 F. F. CAI ET AL.
Relation Size
Relation Size in KB Size in pages Total pages
R1.ONEKT 32.77 64 64R2.TWOKT 65.54 128 128R3.FIVEKT 163.84 320 320R4.TENKT1 327.68 640 640R5.TENKT2 327.68 640 640
REFERENCES
1. D. A. Bell, ‘Issues in relational database performance’, Data Knowl. Eng., 4(3) 49–61 (1998).2. M. E. C. Hull, F. F. Cai and D. A. Bell, ‘Buffer management algorithms for relational database
management systems’, Inf. Softw. Technol., 30(2), 66–80 (1988).3. P. Wegner and J. Doyle, ‘Editorial: strategic directions in computing research’, ACM Comput.
Surv., 28(4), 565–574 (1996).4. G. M. Sacco and M. Schkolnick, ‘Buffer management in relational database systems’, ACM
Trans. Database Syst., 11(4), 473–498 (1986).5. H. T. Chou and D. J. DeWitt, ‘An evaluation of buffer management strategies for relational
database systems’, Proceedings of 11th VLDB Conference, 1985, pp. 127–141.6. F. F. Cai, M. E. C. Hull and D. A. Bell, ‘Design of a predictive buffering scheme for an exper-
imental parallel database system’, in Computing and Information, Elsevier Science PublishersBV, 1989, pp. 291–300.
7. M. E. C. Hull, D. Crookes and P. J. Sweeney, (Eds.) ‘Parallel processing: the transputer and itsapplications’, Addison-Wesley, 1994.
8. F. F. Cai, M. E. C. Hull and D. A. Bell, ‘Buffer management for high performance databasesystems’, in High Performance Computing on the Information Superhighway (Proceedings ofHPC Asia’97 Conference, Seoul, Korea, April 1997), IEEE Computer Society Press, 1997,pp. 633–638.
9. G. M. Sacco, ‘Index access with a finite buffer’, Proceedings of 13th VLDB Conference, 1987,pp. 301–309.
10. M. Stonebraker, ‘Operating system support for database management’, Commun. ACM, 24(7),412–418 (1981).
11. H. Wedekind and G. Zoerntlein, ‘Prefetching in realtime database applications’, Proceedings ofACM SISMOD Conference, 1986, pp. 215–226.
12. D. DeWitt and J. Gray, ‘Parallel database systems: the future of high performance databasesystems’, Commun. ACM, 35(6), 85–98 (1992).
13. D. A. Bell, M. E. C. Hull, F. F. Cai, D. Guthrie and C. M. Shapcott, ‘A flexible parallel databasesystem using transputers’, in Computer Systems and Software Engineering (Proceedings of IEEECompuEuro Conference, The Netherlands, May 1992), IEEE Computer Society Press, 1992,83–88.
14. D. Bitton, D. J. DeWitt and C. Turbyfill, ‘Benchmarking database systems – a systematicapproach’, Proceedings of 9th VLDB Conference, 1983.
15. A. Silberschatz, M. Stonebraker and J. Ullman, ‘Database research: achievement and opportu-nities into the 21st century’, ACM SIGMOD Record, 25(1), 52–63 (1996).
1998 John Wiley & Sons, Ltd. Concurrency: Pract. Exper., 10, 1291–1316 (1998)