the campbell collaboration c2 training: may 9 – 10, 2011 interpretation of effect sizes
TRANSCRIPT

The Campbell Collaboration www.campbellcollaboration.org
C2 Training: May 9 – 10, 2011
Interpretation of Effect Sizes

C2 Training Materials – Oslo – May 2011 www.campbellcollaboration.org
Why Do We Need to Interpret Effect Sizes?
• The importance of some intervention effects are sometimes intuitively understood
– Change in earning power• “College graduates will earn $XX more in their lifetimes than non-
graduates.”– Risk ratio
• “…are 1.4 times more likely to …”– Grade level equivalency
• “students receiving the intervention scored 5.3 GLE while students not receiving the intervention scored 4.9 GLE.”
• But, most are not …– Statistically significant effect– Correlation of +.35, d = -.15
• In most cases, we’ll be working with effects that have to be translated so people will have some idea how to interpret them

C2 Training Materials – Oslo – May 2011 www.campbellcollaboration.org
Options for Expressing Study Results in an Understandable Metric
• Statistical significance– Sometimes naively used as a proxy for effect size
• But trivially small effects can be statistically significant• And large effects can be statistically nonsignificant
• Remember, a p-value expresses the likelihood of observing a result at least this big, assuming a true null hypothesis

C2 Training Materials – Oslo – May 2011 www.campbellcollaboration.org
More on ES and Statistical Significance
• Some students learn that if a statistical test fails to reject the null, it means that the population effect is zero– For example, that the intervention is ineffective– This is one reason people confuse statistical significance
with practical significance (as in, if it is not statistically significant it can’t be practically significant)
– However…

C2 Training Materials – Oslo – May 2011 www.campbellcollaboration.org
Point Estimation vs. Interval Estimation
• Interval estimation– Confidence intervals tell us the likely range of population values
• If a study has a confidence interval for IQ scores ranging from .1 to 10.1 points, that is the likely range of the treatment effect as suggested by this study
• Point estimation– Point estimates (e.g., the mean) tell us the most likely value of the
population parameter
Point estimation and interval estimation are best kept separateAsserting that the treatment effect is zero if the test is not statistically significant confounds these two activities

C2 Training Materials – Oslo – May 2011 www.campbellcollaboration.org
Counternull Value of an Effect Size
• The counternull value of an effect size points out this problem– Assume a study finds d = +.30, p = .10
– Classic H0: Counternull H0:
There is exactly as much evidence supporting the “classic” null hypothesis as there is the counternull hypothesis! (The ES is not statistically different from either 0 or +.60)
1 2
1 2 0
Y Y or
Y Y
1 2 .60Y Y

C2 Training Materials – Oslo – May 2011 www.campbellcollaboration.org
Proportion of Variance Explained
• Common for correlations (r2), multiple regression (R2)• Research suggests that neither experienced researchers nor
experienced statisticians have a good feel for the practical meaning of this type of effect size (Rosenthal, 1984)
– Typically, even well-trained individuals underestimate the importance of results when stated in terms of proportion of variance explained
– Not to mention policy makers and the general public

C2 Training Materials – Oslo – May 2011 www.campbellcollaboration.org
More on Proportion of Variance Explained
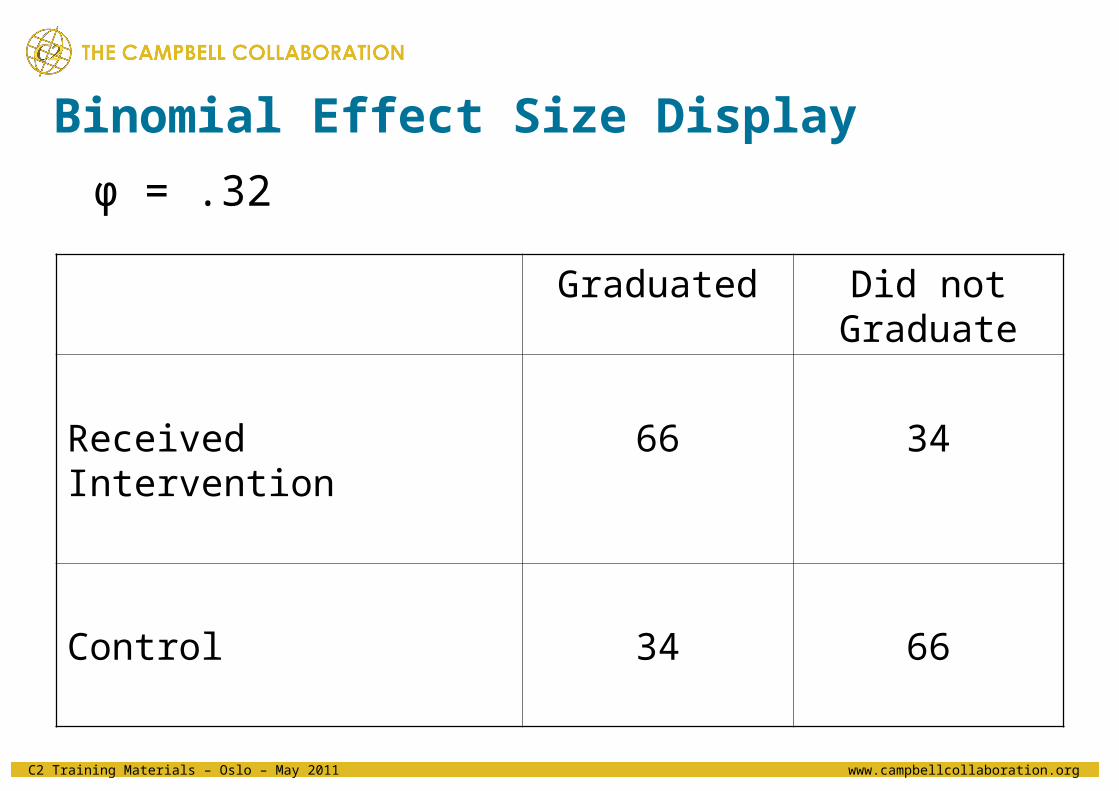
• Consider a study– Program designed to improve graduation rate among “at-risk”
students– φ = +.32, φ2 = .10
• Remember, φ is a correlation with 2 dichotomous variables
– Using proportion of variance as the effect size, one might be tempted to label this a small or even trivial effect, as only 10% of the variance in graduation rates can be attributed to the intervention. But …
C2 Training Materials – Oslo – May 2011 www.campbellcollaboration.org
Binomial Effect Size Display
Graduated Did not Graduate
Received Intervention 66 34
Control 34 66
φ = .32

C2 Training Materials – Oslo – May 2011 www.campbellcollaboration.org
Physician’s Aspirin Study
Subsequent heart attack rates No Heart Attack Heart Attack
Aspirin 10,933 104
Placebo 10,845 189
φ=.03, φ2=.0009, p<.0001, OR=.55, Risk ratio = .55 (55% fewer men who take aspirin have a second heart attack)
Fatality rates, given second heart attack
Aspirin 99 5
Placebo 171 18
φ=.08, φ2=.006, p = .16, OR=.48, Risk ratio = .51

C2 Training Materials – Oslo – May 2011 www.campbellcollaboration.org
Computing the BESD
• For dichotomous outcomes, the BESD illustrates change in “success rate” corresponding to particular values of r– For example, the number of additional graduates
• Computed as (simply)
Treatment group success rate = .50 + (r/2)
Control group success rate = .50 – (r/2)

C2 Training Materials – Oslo – May 2011 www.campbellcollaboration.org
Risk Ratios
• Defined as:
Events in the treatment group / treatment group n ÷ Events in the control group / control group n
• Interpreted as “The ratio of risk in the treatment group relative to the risk in the control group”
– Risk ratio for having a second heart attack was .55• 55% fewer men who take aspirin have a second heart attack

C2 Training Materials – Oslo – May 2011 www.campbellcollaboration.org
Odds vs. Risk Ratios
• OR and RR are very similar when events are rare
• When events become more common, they diverge
– Study 1: OR = .40 RR = .401– Study 2: OR = 1.25 RR = 1.50
• Generally, logged ORs have somewhat better properties for meta-analysis
– Can convert any OR to a RR for interpretation
Study 1 Event Non-event
Treatment 2 1000
Control 5 1000
Study 2 Event Non-event
Treatment 500 500
Control 400 600

C2 Training Materials – Oslo – May 2011 www.campbellcollaboration.org
Risk Difference
• Interpreted as– The difference in risks
between two groups
• Defined as(a ÷ (a+b)) - (c ÷ (c+d))
104 ÷ (104+10933) -189 ÷ (189+10845) =.0094-.0171 = -.0077 (or .77%)
No Heart Attack
Heart Attack
Aspirin 104 (a) 10,993 (b)
Placebo 189 (c) 10,845 (d)

C2 Training Materials – Oslo – May 2011 www.campbellcollaboration.org
Number Needed to Treat• Number needed to treat (NNT) is an additional way to interpret
dichotomous outcomes– How many people have to receive the intervention to produce one more positive
(or, one less negative) event?• Defined as
1/risk difference• Here, NNT = 1/.0077 ≈ 130
– So, 130 men who have had a heart attack need to take aspirin to prevent one additional second heart attack
– With the fictitious program designed to increase graduation rates among “at-risk” students,
RD = .66-.34 = .32NNT = 1/.32 = 3.125– for every 3.125 people who participate in the program, an additional one
person will graduate
C2 Training Materials – Oslo – May 2011 www.campbellcollaboration.org
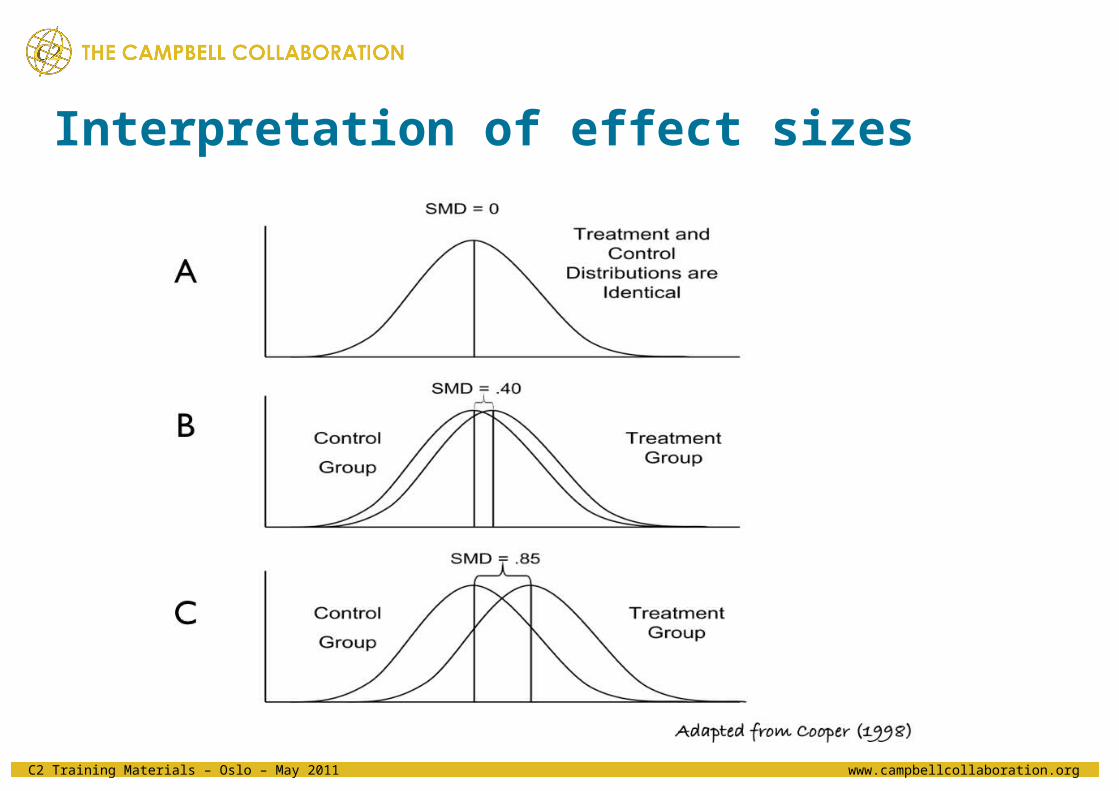
Interpretation of effect sizes

C2 Training Materials – Oslo – May 2011 www.campbellcollaboration.org
Cohen’s Benchmarks
• Jacob Cohen (1988) proposed general definitions for interpreting effect size estimates:
d-index r
Small .20 .10
Medium .50 .30
Large .80 .50

C2 Training Materials – Oslo – May 2011 www.campbellcollaboration.org
More on Cohen
• Lipsey & Wilson (1993) analyzed 183 meta-analyses in the social sciences
– 25th percentile d = .25– 50th percentile d = .38– 75th percentile d = .62
• Cohen intended these to be “rules of thumb”, and emphasized that they represent average effects from across the social sciences
– Cautioned that in some areas, smallish effects may be more typical due to:• Measurement error• Relative weakness of interventions
– He did not intend these to stand for estimates of practical significance!

C2 Training Materials – Oslo – May 2011 www.campbellcollaboration.org
Yet Another Cohen Metric
• U3 – See Cooper, pp. 126-130
(esp. table on p. 130)
d U3 (%)
0 50
.2 58
.4 66
.6 73
.8 79

C2 Training Materials – Oslo – May 2011 www.campbellcollaboration.org
More on U3
– “What percentage of scores in the lower- meaned group was exceeded by the average score in the higher-meaned group?”
– “What is the probability that a randomly selected member of the treatment group will outperform a randomly selected member of the control group?”
– Example:• For HS students, homework has a d of +.20. Imagine two high school with exactly 100
students. – If the average student in the homework high school moved to the high school with no
homework, her rank would improve from 50 to 42 (from the 50 th percentile to the 58th percentile).
– If you were to randomly select one student from the homework high school and one from the non-homework high school, and do that a bunch of times, you ’d expect the homework HS student to outscore the non-homework HS student 58% of the time.

C2 Training Materials – Oslo – May 2011 www.campbellcollaboration.org
Converting Back to Original Metric• It can sometimes be helpful to use the mean difference to translate back into a metric
people are more accustomed to working with– Example
• Assume we did a research synthesis and meta-analysis of the effects of homework on achievement among HS students. Outcomes included standardized test scores such as the SAT and ACT, and chapter tests. Assume overall result was d = +.20, and that type of outcome was not a moderator of effect sizes.
– SAT average = 500, SD = 100– ACT average = 21, SD = 5
» “The overall effect suggests, for example, that the average student doing homework would see an increase in SAT scores from 500 to 520, or in ACT scores from 21 to 22.”
– Cautions• Comparing different constructs (e.g., math achievement vs. attendance) is difficult to impossible• Even when tests are highly similar, if their distributions are different the comparisons can be
misleading

C2 Training Materials – Oslo – May 2011 www.campbellcollaboration.org
Basic Strategy for Comparing Effect Sizes
• Holding intervention constant, are there differential effects across outcomes?– Does summer school help math more than reading?
• Holding outcome constant, are there differential effects across interventions (or intervention components)?– Does mentoring affect graduation rates more than tutoring?

C2 Training Materials – Oslo – May 2011 www.campbellcollaboration.org
Other Considerations When Comparing Effect Sizes
• Are some important outcomes completely missing from the evidence base?
• Are some interventions or intervention components missing from the evidence base?
• Is there covariation between interventions and study methodology?
• Is there covariation between interventions and outcome choice?
– Caution about comparing different mediating variables

C2 Training Materials – Oslo – May 2011 www.campbellcollaboration.org
Reporting
1. Narrative2. Tables
Characteristics of included studiesExcluded studies: specific reasons for exclusionResults of any multivariate analyses
3. GraphsForest plots: study-level effects, pooled effects, homogeneity testsFunnel plots, trim & fill analysis

C2 Training Materials – Oslo – May 2011 www.campbellcollaboration.org
Interpretation of results
1. Quality of available evidence (number of studies in the review, risk of bias)
2. Precision of study-level effects3. Homogeneity of effects across studies4. Pooled effects
a. magnitude and direction of point estimateb. precision (confidence intervals)c. statistical and clinical significanced. potential sources of bias
5. Moderator analysis

C2 Training Materials – Oslo – May 2011 www.campbellcollaboration.org
Guidelines & Standards
1. Conduct of systematic reviews• Cochrane Handbook(s) for systematic reviews of
– Intervention effects (Higgins & Green, 2008)– Diagnostic test accuracy
2. Reporting• PRISMA (Moher et al., 2009) - preferred reporting items for
systematic reviews and meta-analysis• APA reporting guidelines (2008)3. Assessing methodological quality of SRsAMSTAR (Shea et al., 2007)

C2 Training Materials – Oslo – May 2011 www.campbellcollaboration.org
Conclusion: Review methods matter
• Systematic reviews can provide more accurate syntheses of empirical evidence than traditional reviews and stand-alone meta-analyses– Ought to be used (along with other information) to inform
policy and practice• Instead of traditional reviews & stand-alone meta-
analyses– Should follow current guidelines and standards (Higgins
& Green, 2008; Moher et al., 2009)

C2 Training Materials – Oslo – May 2011 www.campbellcollaboration.org
Informing practice and policy: The MST story continues
• Evidence from Cochrane/Campbell review– MST not more or less effective than alternatives– Findings of no difference mean that policy decisions must be
made other grounds• MST continues in Sweden – practitioners and administrators
like MST structure, documentation• MST discontinued in Ontario – more expensive than equally-
effective alternatives• Both decisions are based on best available evidence

C2 Training Materials – Oslo – May 2011 www.campbellcollaboration.org
Evidence for practice and policy
Adapted from: Gibbs (2003), Davies (2004)

C2 Training Materials – Oslo – May 2011 www.campbellcollaboration.org
The story continues
• MST review – update is underway now– New studies– New follow-up data on previous studies– Results could change (in either direction) or not
• Early studies may over-estimate effects– Novelty effects in cumulative meta-analysis (e.g.,
Trikalinos et al., 2004)

C2 Training Materials – Oslo – May 2011 www.campbellcollaboration.org
The story continues: The science of research synthesis is rapidly evolving
• Cochrane Handbook is a “living” document (available at http://www.cochrane-handbook.org/)
• New journal from the Society for Research Synthesis Methodology & Wiley/Blackwell: Research Synthesis Methods

C2 Training Materials – Oslo – May 2011 www.campbellcollaboration.org
The future of research synthesis
On the horizon:• Semi-automated screening of titles and abstracts (Wallace et al., 2010)• Integrated software to manage all stages of the SR process• Better access to data to counteract reporting and publication biases (e.g.,
WHO global platform for prospective registers)• Better tests and corrections for publication bias (e.g., Moreno et al., 2009)• Advances in meta-analysis for multivariate data, diagnostic and prognostic
tests• Adjustments for bias in primary studies (Turner et al., 2009)• Qualitative and mixed methods synthesesBeyond the horizon… ???