the allen ai science challenge
TRANSCRIPT

The Allen AI Science
Challenge &
DeepHack.Q&A
St. Petersburg Data Science Meetup #6, Feb 19th, 2016

Q: When athletes begin to exercise, their heart rates and respiration rates increase. At what level of organization does the human body coordinate these functions? A. at the tissue levelB. at the organ levelC. at the system levelD. at the cellular level
Wed 7 Oct 2015 – Sat 13 Feb 2016Stage 1: 800 teams (>1000 participants),Stage 2: 170 teams
https://www.kaggle.com/c/the-allen-ai-science-challenge
2700 questions - train set8132 questions - validation set21298 questions - final test set

DeepHack Q&A qa.deephack.me/
Qualification round: Top-50 participants with the highest scoresRough competition: Kaggle Top-40 to get to the Top-50 o_O
Winter ML school + hackathon: 31st, Jan - 5th Feb, 2016
GP team created at Jan, 31st from the four teams
The final 30 minutes of the hackathon: https://www.youtube.com/watch?v=tCKL5vbiHuo

Pavel Kalaidin (VK)
Marat Zainutdinov (Quantbrothers)
Roman Trusov (ITMO University)
Artyom Korkhov (Zvooq)
Igor Shilov (Zvooq)
Timur Luguev (Clevapi)
Ilyas Luguev (Clevapi)
Team Generation Gap
DeepHack: 1st, ~0.556Allen AI: 7th, 0.55059

Datasets
ck12.orgwikipedia.org (science subset)flashcards: studystack.com, quizlet.com
Topic at the forum: https://www.kaggle.com/c/the-allen-ai-science-challenge/forums/t/16877/external-data-repository

Hail to Lucene
Lucene
Questiona) ans1b) ans2c) ans3d) ans4
Question ans1
Question ans4
Question ans3
Question ans2
0.50.40.020.01...
0.50.40.020.01...
0.50.40.020.01...
0.50.40.020.01...
Wiki ck12
quizlets
Stem
ming, stopw
ords

Custom queries rule
Lucene scores: https://lucene.apache.org/core/3_5_0/api/core/org/apache/lucene/search/Similarity.html

AdaGram (a.k.a Reptil)
Breaking Sticks and Ambiguities with Adaptive Skip-gram: http:
//arxiv.org/abs/1502.07257
Reference implementation in Julia: https://github.
com/sbos/AdaGram.jl

reptil art cultur final play
signific role folklor
religion popular cultur moch
peopl noun coldblood anim
scale general move stomach
short leg exampl snake lizard
turtl noun aw person

Model trained like this: sh train.sh --min-freq 20 --window 5 --workers 40 --epochs 5 --dim 300 --alpha 0.1 corpus.txt adam.dict adam.modelNumber of prototypes is 5 by default.
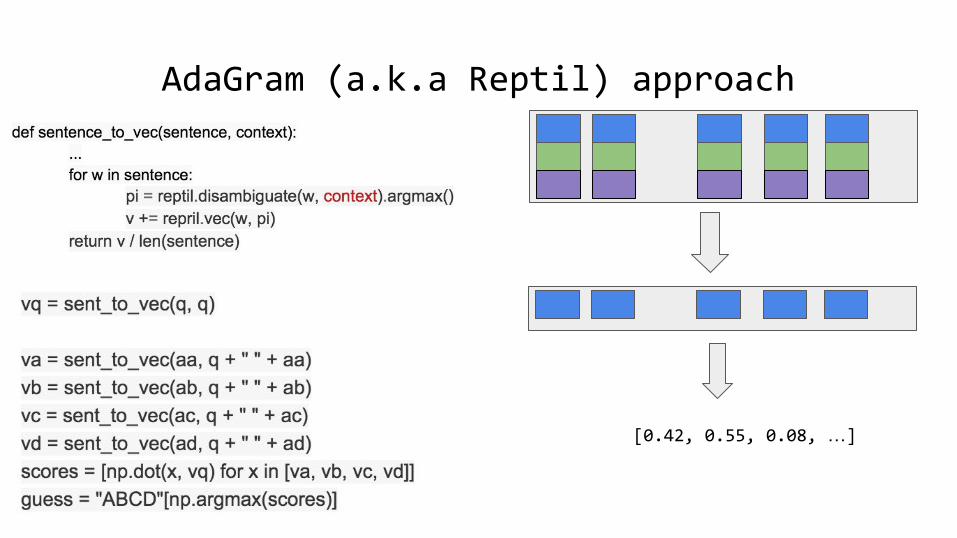
AdaGram (a.k.a Reptil) approach
[0.42, 0.55, 0.08, …]

N-grams PMI
x, y - Ngrams
Example 1-gram -> 1-gram
unit -> statemagnet -> fieldcarbon -> dioxidmillion -> yearyear -> agoamino -> acid
Example 1-gram -> 3-gram
around -> million year agoperiod -> million year agoforc -> van der waalfossil -> million year agonobel -> prize physiolog medicindate -> million year agomercuri -> venus earth mar

N-grams PMI
greatest contributor air pollut unit state
What is the greatest contributor to air pollution in the United States?
greatest
contributor
air...
greatest contributor
contributor air
air pollut...
1-grams 2-grams 3-grams
Power plants
power plant
power
plant
1-grams
power plant
2-grams
...

Scores

Fail Story
TL;DR wasted tons of time, got ~0.3 in almost all approaches

LSA + Lucene
CorpusLSA
TI_1
TI_2
TI_n
Lucene
qa pair 1
qa pair 2
qa pair 3
qa pair 4
Queries in topic indices
Result: for each qa pair, max(s1...sn)
Gave 1% improvement over basic Lucene; but took EXTREMELY long time to process :(

Syntax co-occurrence
nobel chemistry prize 517national science academy 445long time period 340also role play 306nobel physic prize 279national medical library 273carbon water dioxide 261second thermodynamics law 247
speed sound of_pobjdensity population compoundtake place dobjlink external compound 0.3 :(

word2vec combinations
Wanted to capture the intersection of meanings, but didn’t know how to combine word2vec representations
TFIDFqa pairs
Combinations of question tokens
Combinations of answer tokens
Cosine similarity
Max score ~ 0.3 :( even with careful kw filtering
word2gauss didn’t help too

Averaging Neural networks (1st encounter)
w2v_dim = 300
vec_q = mean(w2v(Q))
vec_c = mean(w2v(Ac))
vec_w = mean(w2v(Aw))
cos_sim(vec_q, vec_c) > cos_sim(vec_q, vec_w)

Averaging Neural networks (1st encounter)
w2v_dim = 300
vec_q = mean(w2v(Q))
vec_c = mean(w2v(Ac))
vec_w = mean(w2v(Aw))
a = CNN(w2v(X))
vec_x = mean(w2v(X) * a)
cos_sim(vec_q, vec_c) > cos_sim(vec_q, vec_w)

Semantic Neural networks (2nd encounter)
+ Paragraphs
LSTM = LSTM(w2v)
LSTM(s1 | s2) > LSTM(s1 | s3) if s1 and s2 are from the same
paragraph, while s1 and s3 are not
LSTM(a, b) is low then a and b are from the same paragraph (energy based learning)
Loss = max(0, M - LSTM(s1, s2) + LSTM(s1, s3))
Score: 0.26

Siamese architecture

Hinge Loss
Margin

Reading Neural networks (3rd encounter)
+ Lots of paragraphs
+ Search Engine
+ A survey:
- bigrams are not accounted
- main idea (keywords) of a sentence is not recognized

Reading Neural networks (3rd encounter)
+ Lots of paragraphs
+ Search Engine
+ A survey:
- bigrams are not accounted
- main idea (keywords) of a sentence is not recognized

Reading Neural networks (3rd encounter)
All we want is to know if a sentence is from a paragraph to be
able to rerank lucene scores.


Hinge Loss
Margin
LSTM(P)
LSTM(s1)
LSTM(s2)

Reading Neural networks (3rd encounter)
sentences -> LSTM -> Dense NN -> Embedding
w2v -> LSTM -> Dense NN -> Embedding
w2v -> Mean -> Dense NN -> Embedding

Neural networks. Learned lessons.
Start as small as possible
Corruption is important for siamese networks
Learning curve is misleading in NLP

Lessons learned
Start early - wasted two first months of the competition (but had a week
of 24/7 hackathon at the end)
No stickers in the team channel (except with Yann LeCun on a good submit)
Common toolbox is nice
A dedicated server is a good thing to have (no need in AWS spot instances)
Experiment fast, fail early
Team work means a lot