text learning tom m. mitchell aladdin workshop carnegie mellon university january 2003
Post on 19-Dec-2015
214 views
TRANSCRIPT

Text Learning
Tom M. Mitchell
Aladdin Workshop
Carnegie Mellon University
January 2003

1. CoTraining learning from labeled and unlabeled data

Redundantly Sufficient Features
Professor Faloutsos my advisor

Redundantly Sufficient Features
Professor Faloutsos my advisor

Redundantly Sufficient Features
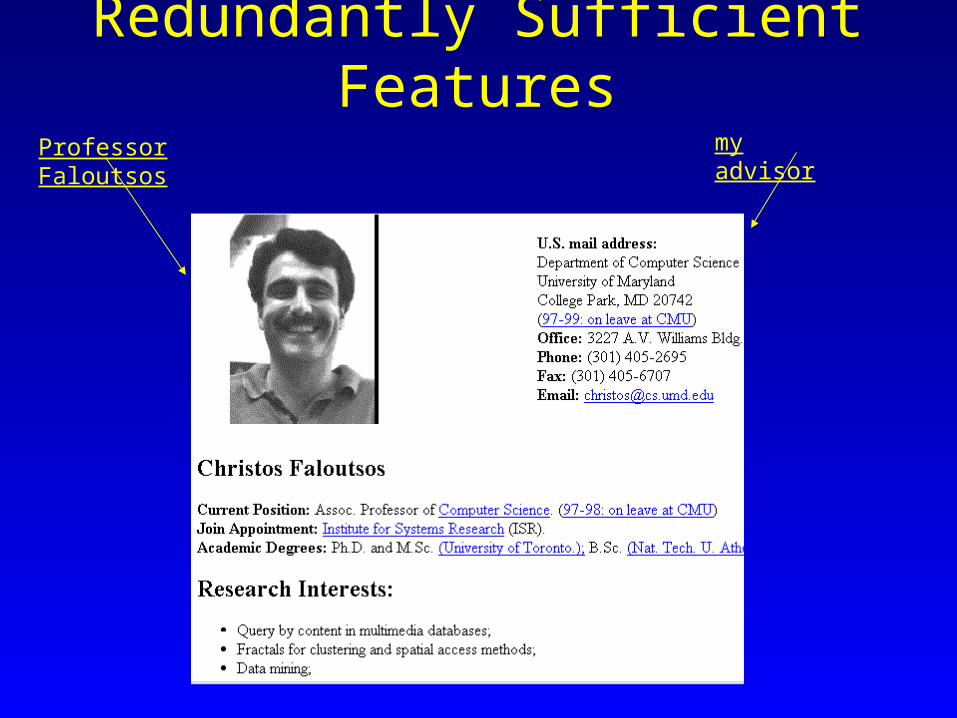
Redundantly Sufficient Features
Professor Faloutsos my advisor

CoTraining Setting
)()()()(,
:
221121
21
xfxgxgxggand
ondistributiunknownfromdrawnxwhere
XXXwhere
YXflearn
• If– x1, x2 conditionally independent given y– f is PAC learnable from noisy labeled data
• Then– f is PAC learnable from weak initial classifier
plus unlabeled data

Co-Training Rote Learner
My advisor+
-
-
pageshyperlinks

Co-Training Rote Learner
My advisor+
-
-
pageshyperlinks
-
--
-
+
+

Co-Training Rote Learner
My advisor+
-
-
pageshyperlinks
-
--
-
+
+
-
-
-
+
+

Co-Training Rote Learner
My advisor+
-
-
pageshyperlinks
-
--
-
+
+
-
-
-
+
++
+
-
-

Co-Training Rote Learner
My advisor+
-
-
pageshyperlinks
-
--
-
+
+
-
-
-
+
++
+
-
-
+
+
-

What if CoTraining Assumption Not Perfectly Satisfied?
-
+
+
+

What if CoTraining Assumption Not Perfectly Satisfied?
-
+
+
+

• Idea: Want classifiers that produce a maximally consistent labeling of the data
• If learning is an optimization problem, what function should we optimize?
What if CoTraining Assumption Not Perfectly Satisfied?
-
+
+
+

What Objective Function?
Lyx
Lyx
xgyE
xgyE
EEE
,
222
,
211
))(ˆ(2
))(ˆ(1
21
Error on labeled examples

What Objective Function?
Ux
Lyx
Lyx
xgxgE
xgyE
xgyE
EcEEE
22211
,
222
,
211
3
))(ˆ)(ˆ(3
))(ˆ(2
))(ˆ(1
321
Error on labeled examples
Disagreement over unlabeled

What Objective Function?
2
2211
,
22211
,
222
,
211
43
2
)(ˆ)(ˆ
||||
1
||
14
))(ˆ)(ˆ(3
))(ˆ(2
))(ˆ(1
4321
ULxLyx
Ux
Lyx
Lyx
xgxg
ULy
LE
xgxgE
xgyE
xgyE
EcEcEEE
Error on labeled examples
Disagreement over unlabeled
Misfit to estimated class priors

What Function Approximators?

What Function Approximators?
• Same fn form as Naïve Bayes, Max Entropy
• Use gradient descent to simultaneously learn g1 and g2, directly minimizing E = E1 + E2 + E3 + E4
• No word independence assumption, use both labeled and unlabeled data
j
jj xw
exg
1,
1
1)(ˆ1
jjj xw
exg
2,
1
1)(ˆ2

Gradient CoTraining
j
jj xw
exg
1,
1
1)(ˆ1
jjj xw
exg
2,
1
1)(ˆ2

Classifying Jobs for FlipDog
X1: job titleX2: job description

Gradient CoTraining Classifying FlipDog job descriptions: SysAdmin vs. WebProgrammer
Final Accuracy
Labeled data alone: 86%
CoTraining: 96%

Gradient CoTraining Classifying Upper Case sequences as Person Names
25 labeled
5000 unlabeled
2300 labeled
5000 unlabeled
Using labeled data only
Cotraining
Cotraining without fitting class priors (E4)
.73
.87.76
* sensitive to weights of error terms E3 and E4
.89 *.85 *
*

CoTraining Summary
• Key is getting the right objective function– Class priors is an important term– Can min-cut algorithms accommodate this?
• And minimizing it…– Gradient descent local minima problems– Graph partitioning possible?

The Problem/Opportunity
• Must train classifier to be website-independent, but many sites exhibit website-specific regularities
Question• How can program learn website-specific regularities
for millions of sites, without human labeling data?

Learn Local Regularities for Page Classification

Learn Local Regularities for Page Classification
1. Label site using global classifier
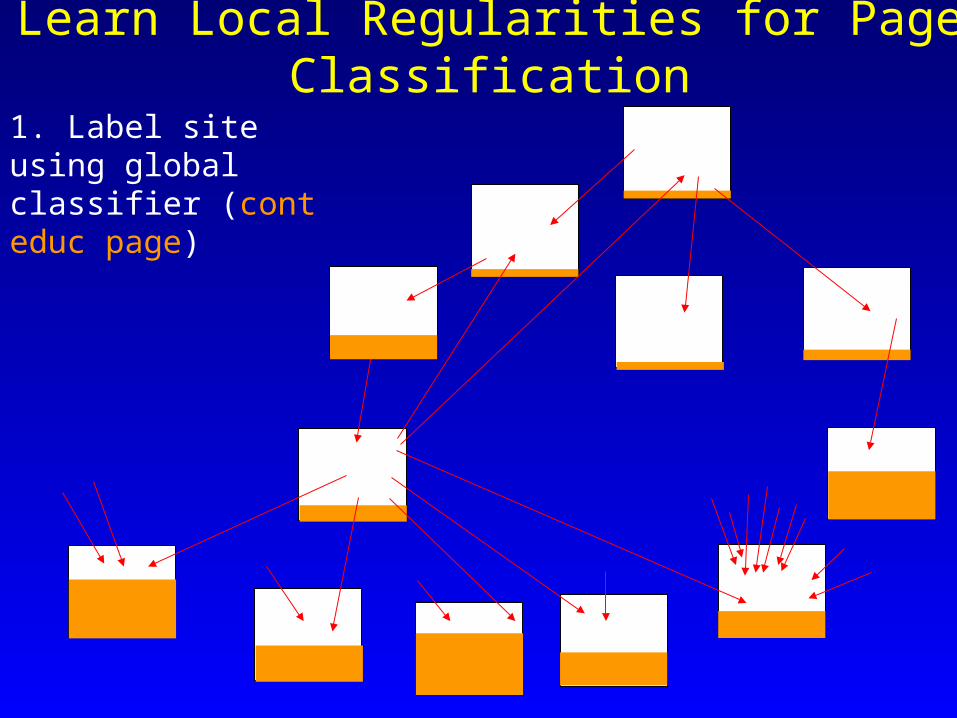
Learn Local Regularities for Page Classification
1. Label site using global classifier (cont educ page)

Learn Local Regularities for Page Classification
1. Label site using global classifier
2. Learn local classifiers
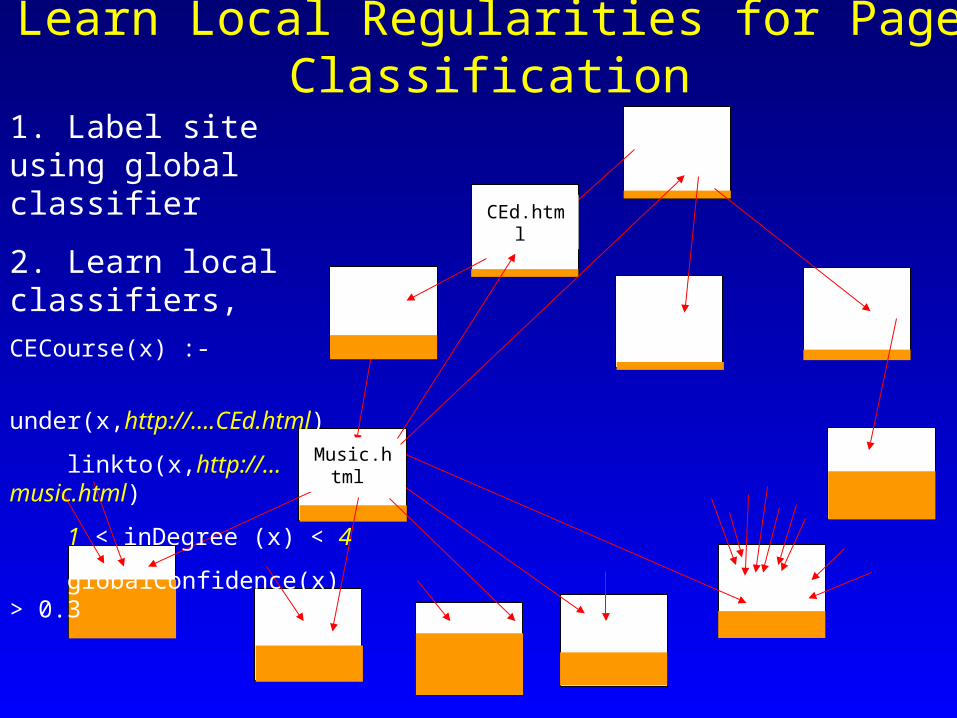
Learn Local Regularities for Page Classification
CEd.html
1. Label site using global classifier
2. Learn local classifiers,
CECourse(x) :-
under(x,http://….CEd.html)
linkto(x,http://…music.html)
1 < inDegree (x) < 4
globalConfidence(x) > 0.3 Music.html

Learn Local Regularities for Page Classification
CEd.html
1. Label site using global classifier
2. Learn local classifiers,
3. Apply local classifier, to modify global labels
Music.html

Learn Local Regularities for Page Classification
CEd.html
1. Label site using global classifier
2. Learn local classifier
3. Apply local classifier, to modify global labels
Music.html

Results of Local Learning: Cont.Education Course Page
• Learning global classifier only:– precision .81, recall .80
• Learning global classifier plus site-specific classifiers for 20 local sites:– precision .82, recall .90

Learning Site-Specific Regularities: Example 2
• Extracting “Course-Title” from web pages


Local/Global Learning Algorithm
• Train global course title extractor (word based)
• For each new university site:– Apply global title extractor– For each page containing extracted titles
• Learn page-specific rules for extracting titles, based on page layout structure
• Apply learned rules to refine initial labeling




X
X

Local/Global Learning Summary
• Approach:– Learn global extractor/classifier using content features– Learn local extractor/classifier using layout features– Design restricted hypothesis language for local, to
accommodate sparse training data
• Algorithm to process a new site:– Apply global extractor/classifier to label site– Train local extractor/classifier on this data– Apply local extractor/classifier to refine labels

Other Local Learning Approaches
• Rule covering algorithms: each rule a local model– But require supervised labeled data for each locality
• Shrinkage-based techniques, eg., for learning hospital-independent and hospital-specific models for medical outcomes – Again, requires labeled data for each hospital
• This is different – no labeled data for new sites

When/Why does this work??
• Local and global models use independent, redundantly sufficient features
• Local models learned within low-dimension hypothesis language
• Related to co-training!

Other Uses?
+ Global and website-specific information extractors
+ Global and program-specific TV segment classifiers?
+ Global and environment-specific robot perception?
– Global and speaker-specific speech recognition?
– Global and hospital-specific medical diagnosis?

Summary
• Cotraining:– Classifier learning as minimization problem– Graph partitioning algorithm possible?
• Learning site-specific structure:– Important structure involves long-distance
relationships– Strong local graph structure regularities are
highly useful