tensor core accelerated iterative refinement …
TRANSCRIPT

TENSOR CORE ACCELERATED ITERATIVE REFINEMENT SOLVERS AND ITS IMPACT ON SCIENTIFIC COMPUTING Azzam Haidar | Sr. Engineer – CUDA Math Libraries, NVIDIA
Harun Bayraktar | Sr. Manager – CUDA Math Libraries, NVIDIA
Abeynaya Gnanasekaran | Stanford University
SIAM CSE, March 4, 2021

2
THREE GENERATIONS OF TENSOR CORESWith increasing variety of data and compute types
262
624
1248
125 131
312
624
312
624
156
312
20
1
10
100
1000
10000
1st GenerationVolta (V100)
2nd GenerationTuring (TU102)
3rd GenerationAmpere (A100)
TFLO
PS o
r TO
PS
FP16
FP16
FP16
INT8
INT8
INT8
Spa
rse
FP16
Spa
rse
BF16
Spa
rse
TF32
Spa
rse
BF16
TF32
FP64
* TF32 is a Tensor Core compute mode and not a data type where FP32 mantissa is truncated by the HW
* Accumulation in Tensor Cores happen in FP32 decreasing the effect of rounding errors

3
LU factorization used to solve Ax=b is dominated by GEMMs
TENSOR CORE ACCELERATED LIBRARIES
9.7 19.5 19.5
156
312 312
0
50
100
150
200
250
300
350
FP64
FP64-TC
FP32
TF32-TC
FP16-TC
BF16-TC
GA100 Tflops
How about a multi-precision LU then?
Can it be accelerated using Tensor Cores and still get fp64 accuracy?
Multi-precision numerical methodsSolving linear system of equations Ax=b

4
# iterations10-20
10-15
10-10
10-5
TENSOR CORE ACCELERATED LIBRARIESAccuracy just after the reduced precision LU factorization
Accuracy of the obtained solution
Results obtained using CUDA 11.0 and A100 GPU.
FP64-TC provide a solution down to the FP64 accuracy
TF32 and FP16 provide a solution to around 1E-05 accuracy
Obtained solution has 11 digits loss compared to the FP64 one,
can we do better and achieve the FP64 accuracy?

5
# iterations10-20
10-15
10-10
10-5
TENSOR CORE ACCELERATED LIBRARIES
E. Carson, N. J. Higham, Accelerating the Solution of Linear Systems by Iterative Refinement in Three Precisions, SIAM J. Sci. Comput., 40(2), A817–A847.A. Haidar, S. Tomov, J. Dongarra, and N. J. Higham, Harnessing GPU Tensor Cores for Fast FP16 Arithmetic to Speed up Mixed-Precision Iterative Refinement Solvers, SC-18 Dallas, 2018A.Haidar, H. Bayraktar, S. Tomov, J. Dongarra, N. J. Higham Mixed-Precision Iterative Refinement using Tensor Cores on GPUs to Accelerate Solution of Linear Systems, submitted Royal Society Journal UK 2020.
How can we get to FP64 accuracy?
Idea: use reduced precision to compute the expensive flops (LU O(n3)) and then iteratively refine the solution (O(n2)) in order to achieve the FP64 level of accuracy
Iterative refinement for solving Ax = b:
Perform a factorization in reduced precision A = LU

6
Iterative refinement for solving Ax = b:
Perform a factorization in reduced precision A = LUrefineWHILE || r || > eps_FP64 1. Find correction c such that Ac = r, c = U\(L\r) 2. x = x + c3. r = b – Ax (with original A). END
TENSOR CORE ACCELERATED LIBRARIESHow can we get to FP64 accuracy?
Idea: use reduced precision to compute the expensive flops (LU O(n3)) and then iteratively refine the solution (O(n2)) in order to achieve the FP64 level of accuracy
E. Carson, N. J. Higham, Accelerating the Solution of Linear Systems by Iterative Refinement in Three Precisions, SIAM J. Sci. Comput., 40(2), A817–A847.A. Haidar, S. Tomov, J. Dongarra, and N. J. Higham, Harnessing GPU Tensor Cores for Fast FP16 Arithmetic to Speed up Mixed-Precision Iterative Refinement Solvers, SC-18 Dallas, 2018A.Haidar, H. Bayraktar, S. Tomov, J. Dongarra, N. J. Higham Mixed-Precision Iterative Refinement using Tensor Cores on GPUs to Accelerate Solution of Linear Systems, submitted Royal Society Journal UK 2020.
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17# iterations
10-20
10-15
10-10
10-5

7
2k4k6k8k10k 14k 18k 22k 26k 30k 34k 40kMatrix size
0 4 8 121620242832364044
Tflo
p/s
Performance of solving Ax=b to the FP64 accuracyFP16->64 dhgesvBF16->64 dbgesvTF32->64 dxgesvFP64 dgesv
TENSOR CORE ACCELERATED ITERATIVE REFINEMENT SOLVER
Flops = 2n3/(3 time) meaning twice higher is twice faster
Problem generated with Hilbert matrices.
Performance Behavior, A100
3.5X
Results obtained using CUDA 11.0 and V100, A100 GPU.
Speedup compared to FP64 has same trend on both hardware.
TF32 is 3.3X faster within a solution to the FP64 accuracy.
FP16 is 3.5X faster within a solution to the FP64 accuracy.
A100 provides about 1.8X speedup over V100 for both FP16 and FP64 variants

8
Matrices from SuiteSparse, A100
TENSOR CORE ACCELERATED ITERATIVE REFINEMENT SOLVER
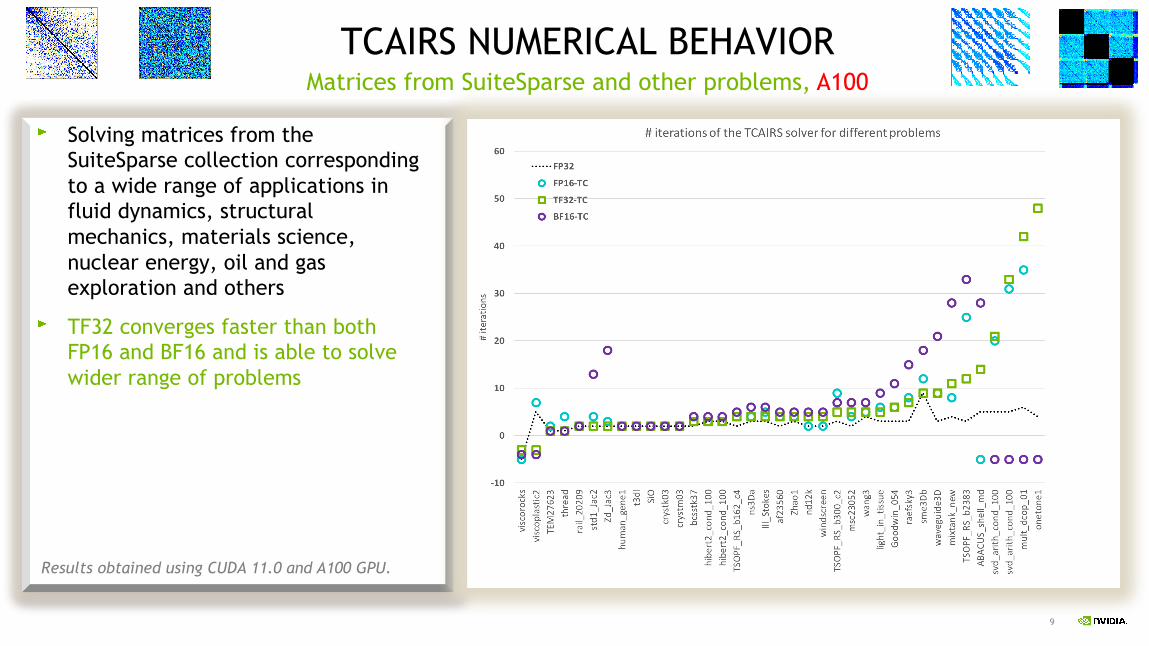
9
Results obtained using CUDA 11.0 and A100 GPU.
Matrices from SuiteSparse and other problems, A100TCAIRS NUMERICAL BEHAVIOR
Solving matrices from the SuiteSparse collection corresponding to a wide range of applications in fluid dynamics, structural mechanics, materials science, nuclear energy, oil and gas exploration and others
TF32 converges faster than both FP16 and BF16 and is able to solve wider range of problems

10
Results obtained using CUDA 11.0 and A100 GPU.
Matrices from SuiteSparse and other problems, A100
Performance Fallbackcases Notes
FP32 1x 1 Hardcase
TF32 2x 2 Hardcase
FP16scaled 2x 3 Scalingfixesmanycases
BF16 2x 6 Lossofprecisionisanissueforseveralcases
TCAIRS PERFORMANCE BEHAVIOR
TF32 converges faster than both FP16 and BF16 and is able to solve wider range of problems
In terms of performance TF32 provide time to solution close or better than both BF16 and FP16
In summary, TF32 can be considered the most robust and the fastest variant

11
cuSOLVERCUDA 11.0
10.2 + TCAIRS-QR real TCAIRS-QR complexTCAIRS-QR NRHSFP32, FP16-TCFP64-TC, TF32-TC, BF16-TCMany other advancements
Mixed Precision Solvers are gaining a lot of attention for their power to provide a solution up to 4X-5X faster and for their energy efficiency.
January 2019 Nov 2019 May 2020
cuSOLVERCUDA 10.2
TCAIRS-LU real TCAIRS-LU complexTCAIRS-LU NRHSFP64, FP32, FP16-TC
Magma 2.5.0
TCAIRS-LU realFP64, FP32, FP16-TC
Tensor Core Accelerated Iterative Refinement Solver (TCAIRS) for Dense Linear Algebra
TENSOR CORE ACCELERATED ITERATIVE REFINEMENT SOLVER

12
TENSOR CORE ACCELERATED ITERATIVE REFINEMENT SOLVER
0 10 20 30 40 50 60nz = 817
0
10
20
30
40
50
60
Proceed with same idea as for dense: use lower precision to compute a high-quality preconditioner (LU, LLT, LDLT) and then use it in classical iterative refinement or Krylov solvers like FGEMRes to achieve FP64 precision solutions
Prototype Research Project Sparse Direct Solver

13
TENSOR CORE ACCELERATED ITERATIVE REFINEMENT SOLVER
0 10 20 30 40 50 60nz = 817
0
10
20
30
40
50
60
Proceed with same idea as for dense: use lower precision to compute a high-quality preconditioner (LU, LLT, LDLT) and then use it in classical iterative refinement or Krylov solvers like FGEMRes to achieve FP64 precision solutions
Prototype Research Project Sparse Direct Solver
Only the diagonal tile will be factored in FP32
The TRSM/GEMM can be done in any lower precision such as
FP32, TF32, FP16, and BF16
For numerical study: it can be easily implemented viacublasSetMathMode(cublasHandle_t handle, cublasMath_t mode)
For performance study: It can be easily implemented via by converting A and B to FP16, communicate FP16, and use cublasGemmEX or cublasLtMatMul
cublasSetMathMode(handle, CUBLAS_TF32_TENSOR_OP_MATH);cublasStrsm(…)cublasSgemm(---)cublasSetMathMode(handle, CUBLAS_DEFAULT_MATH);

14
Proceed with same idea as for dense: use lower precision to compute a high-quality preconditioner (LU, LLT, LDLT) and then use it in classical iterative refinement or Krylov solvers like FGEMRes to achieve FP64 precision solutions
TENSOR CORE ACCELERATED ITERATIVE REFINEMENT SOLVER
0 10 20 30 40 50 60nz = 817
0
10
20
30
40
50
60
Prototype Research Project Sparse Direct Solver
Only the diagonal tile will be factored in FP32
The TRSM/GEMM can be done in any lower precision such as
FP32, TF32, FP16, and BF16
For numerical study: it can be easily implemented viacublasSetMathMode(cublasHandle_t handle, cublasMath_t mode)
For performance study: It can be easily implemented via by converting A and B to FP16, communicate FP16, and use cublasGemmEX or cublasLtMatMul
cublasSetMathMode(handle, CUBLAS_TF32_TENSOR_OP_MATH);cublasStrsm(…)cublasSgemm(---)cublasSetMathMode(handle, CUBLAS_DEFAULT_MATH);

15
Software is a research project not released.Results obtained on A100 GPU.
Prototype Research Project Sparse Direct SolverSPARSE TCAIRS PERFORMANCE BEHAVIOR
Preliminary results using our prototype in-house Research Tensor Cores Accelerated Sparse Direct Solver with TF32
Solution obtained is to the fP64 accuracy

Thank you very much
MS171 – Harun Bayraktar et al. Accelerating NVIDIA Math Libraries with Mixed-Precision and Tensor Cores
MS41 – Federico Busato
High-Performance Sparse Linear Algebra on NVIDIA GPUs with cuSPARSE
MS191 – Lung-Sheng ChienChallenges of Symmetric Eigenvalue Solver on Single Processor Multi-GPU