tech talks_25.04.15_session 3_tibor sulyan_distributed coordination with zookeeper
TRANSCRIPT


2CONFIDENTIAL
CAP Theorem by Eric Brewer
• Consistency
• Availability
• Partition Tolerance
Introduction
1
2
12
writeread
?1
2
2

3CONFIDENTIAL
Agenda
What is ZooKeeper?1
ZooKeeper features2
Coordination Recipes3
Using Curator with ZooKeeper4
Deploying ZooKeeper clusters5

4CONFIDENTIAL
„ZooKeeper is a centralized service for maintaining configuration information, naming,
providing distributed synchronization, and providing group services.”
What is ZooKeeper about?
P
P
P
ES
/root
/root/data
/root/state
/root/state/service-000000001
zk
zk
zk zk
client client client
zk
ZK API ZK API ZK API

5CONFIDENTIAL
• Filesystem-like hierarchical structure
– Elements are called zNodes
• zNode operations
– Basic CRUD
– Transactional execution of multiple operations
– Watches
– Versioned changes
• zNode metadata
– Data
– Children
– Metadata (Stat structure)
• zNode types
ZooKeeper Data Model
P persistent
E ephemeral
PS persistent sequential
ES ephemeral sequential
6CONFIDENTIAL
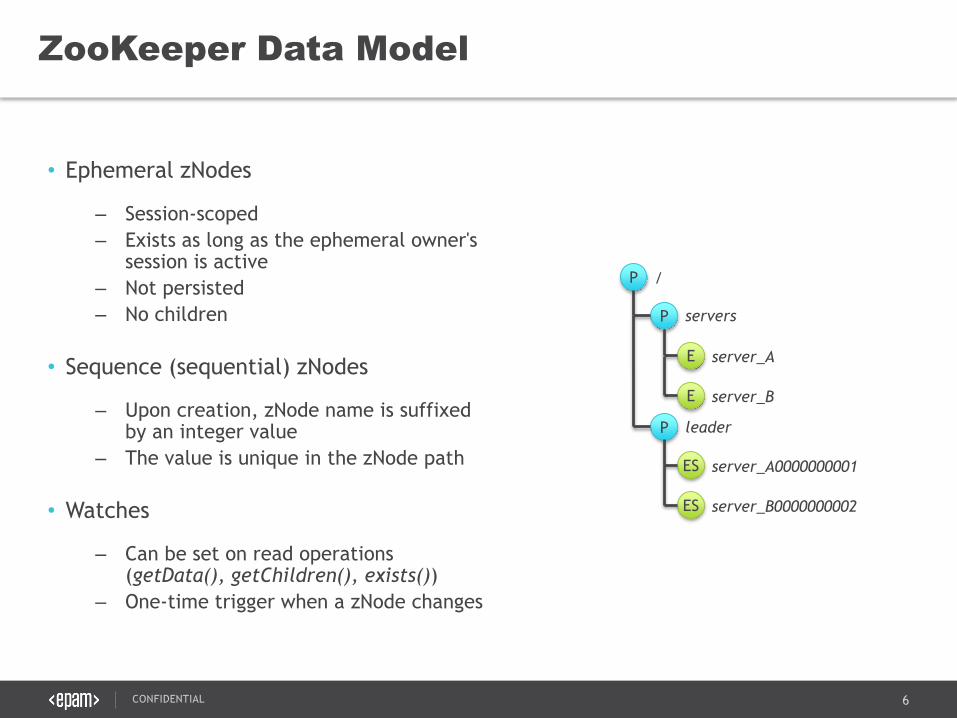
• Ephemeral zNodes
– Session-scoped
– Exists as long as the ephemeral owner's session is active
– Not persisted
– No children
• Sequence (sequential) zNodes
– Upon creation, zNode name is suffixed by an integer value
– The value is unique in the zNode path
• Watches
– Can be set on read operations (getData(), getChildren(), exists())
– One-time trigger when a zNode changes
ZooKeeper Data Model
P
P
/
servers
E server_A
E server_B
P leader
ES server_A0000000001
ES server_B0000000002

7CONFIDENTIAL
// this class will act as default watcher
class ZooKeeperClient implements Watcher {
...
// connect to the ensemble. 'this' refers to a watcher (aka default watcher)
ZooKeeper zooKeeper = new ZooKeeper("localhost:2181,localhost:2182,localhost:2183",
30_000, this);
@Override
public void process(WatchedEvent event) {
// zNode changes & connection state changes
// can be invoked before the constructor returns!
}
}
ZooKeeper API – connect, default watcher

8CONFIDENTIAL
// snyhronous node creation
try {
Stat stat = zooKeeper.create("/test", "data".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE,
CreateMode.EPHEMERAL);
} catch (KeeperException e) {
switch (e.code()) {
case CONNECTIONLOSS:
// retry operation
break;
}
}
// asynchronous node creation
zooKeeper.create("/test", "data".getBytes(), OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL, new
StringCallback() {
@Override
public void processResult(int rc, String path, Object ctx, String name) {
switch (Code.get(rc)) {
// handle errors (retry on CONNECTIONLOSS)
}
}
}, null /* no context passed to callback*/);
ZooKeeper API – create operations &
recoverable errors

9CONFIDENTIAL
// snyhronous update: sets "newdata" for /test1
// error handling omitted
Stat stat = zooKeeper.setData("/test", "newdata".getBytes(), -1);
// sets "newerdata" only if data version is 5
zooKeeper.setData("/test", "newerdata".getBytes(), 5);
ZooKeeper API – versioned update operations

10CONFIDENTIAL
// check if zNode exists using the default watcher
// error handling omitted
Stat stat = zooKeeper.exists("/parent/child1", false);
// get data & set default watcher
Stat stat = new Stat();
byte[] data = zooKeeper.getData("/parent/child1", true, stat);
// Use a separate Watcher
stat = zooKeeper.exists("/parent/child2", new Watcher() {
@Override
public void process(WatchedEvent event) {
// react to node deletion
}
});
ZooKeeper API – read operations & setting
watches

11CONFIDENTIAL
• Atomic updates
• Sequential Consistency
• Single System Image
• Timeliness
• Reliability
• Availability
ZooKeeper Guarantees
zk 5
zk 1
zk 2 zk 3
client 1 client 2 client 3
zk 4

12CONFIDENTIAL
notifycommitvoteproposepropagate
Sequential Consistency
client
follower
leader
follower
follower
setData
sync return
callback called
watch triggered
time
13CONFIDENTIAL
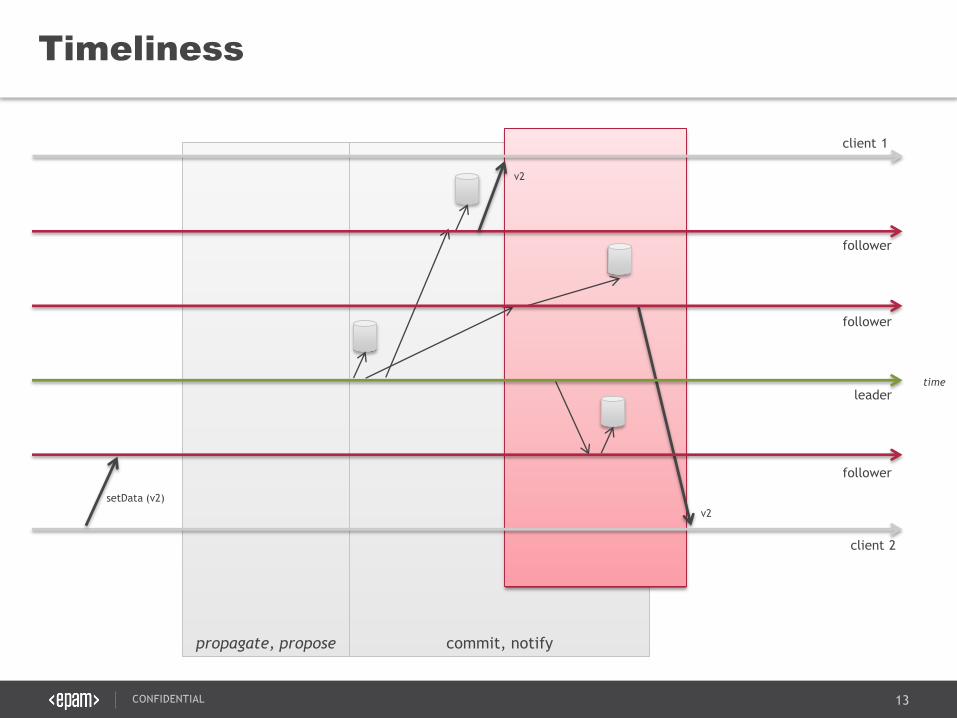
propagate, propose commit, notify
Timeliness
client 2
follower
leader
follower
follower
client 1
setData (v2)
v2
v2
time

14CONFIDENTIAL
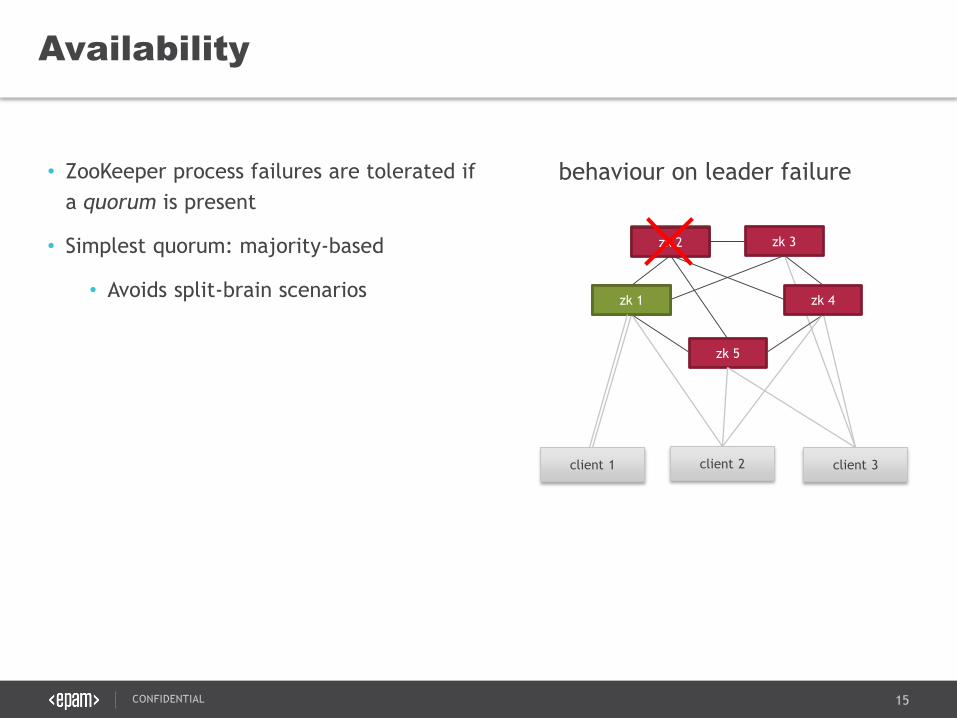
• ZooKeeper process failures are tolerated if
a quorum is present
• Simplest quorum: majority-based
• Avoids split-brain scenarios
Availability
zk 5
zk 1
zk 2 zk 3
client 1 client 2 client 3
zk 4
behaviour on follower failures
15CONFIDENTIAL
• ZooKeeper process failures are tolerated if
a quorum is present
• Simplest quorum: majority-based
• Avoids split-brain scenarios
Availability
zk 5
zk 1
zk 2 zk 3
client 1 client 2 client 3
zk 4
behaviour on leader failure
zk 1
zk 2

16CONFIDENTIAL
ZooKeeper Recipes

17CONFIDENTIAL
Distributed Coordination Recipes
Shared Data Group Membership
P
P
/
serviceInstances
E serverA
E serverB
Service Discovery
P
P
/
service
E serviceInfo
Lock
Mutex
Leader Election
P
P
/
service
ES service_0000000001
ES service_0000000002

18CONFIDENTIAL
Leader Election Recipe
P
P
/
service
ES service_0000000001
ES service_0000000002
zk 5
zk 1
zk 2 zk 3
service service service
zk 4
ES service_0000000003
service
watch
service_0000000001
watch
service_0000000001
watch
service_0000000001
watch
service_0000000001
service
watch
service_0000000002
n-1 watches are set on the same node
Improvment: watch the last sequence node
instead of the first one

19CONFIDENTIAL
Improved Leader Election Recipe
P
P
/
service
ES service_0000000001
ES service_0000000002
zk 5
zk 1
zk 2 zk 3
service service service
zk 4
ES service_0000000003
service
watch
service_0000000001
watch
service_0000000002
watch
service_0000000001
service
20CONFIDENTIAL
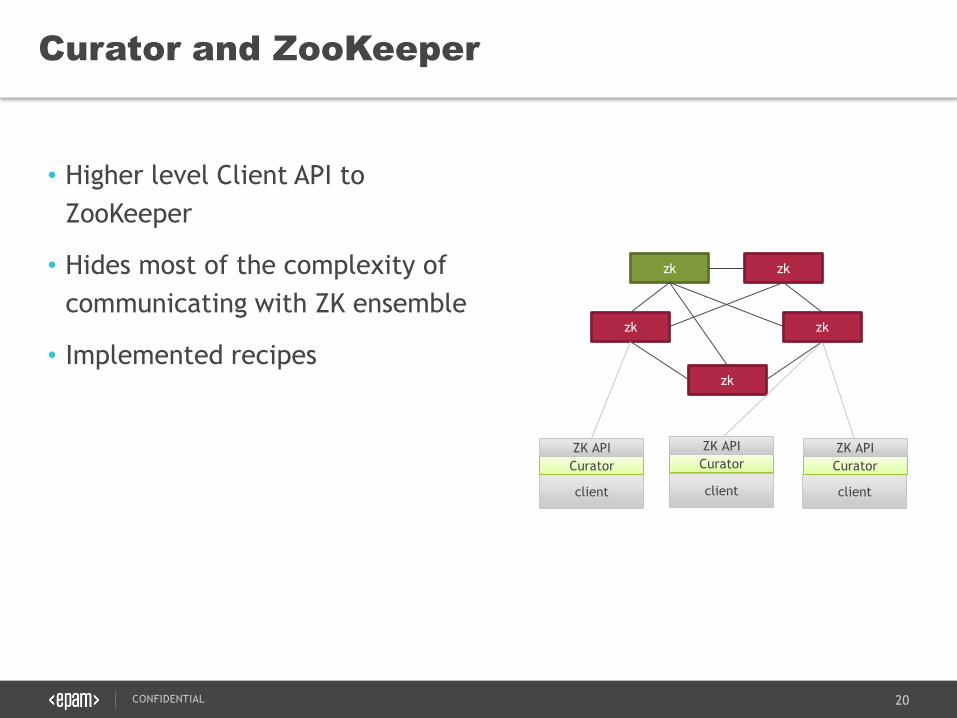
• Higher level Client API to
ZooKeeper
• Hides most of the complexity of
communicating with ZK ensemble
• Implemented recipes
Curator and ZooKeeper
zk
zk
zk zk
client client client
zk
Curator
ZK API
Curator
ZK API
Curator
ZK API
21CONFIDENTIAL
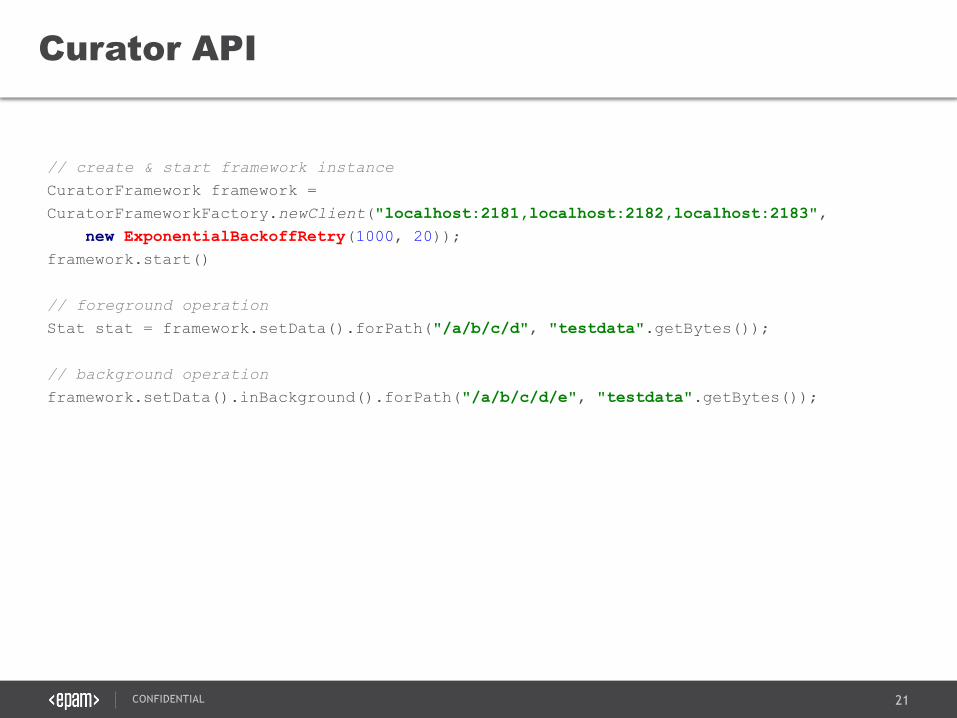
// create & start framework instance
CuratorFramework framework =
CuratorFrameworkFactory.newClient("localhost:2181,localhost:2182,localhost:2183",
new ExponentialBackoffRetry(1000, 20));
framework.start()
// foreground operation
Stat stat = framework.setData().forPath("/a/b/c/d", "testdata".getBytes());
// background operation
framework.setData().inBackground().forPath("/a/b/c/d/e", "testdata".getBytes());
Curator API
22CONFIDENTIAL
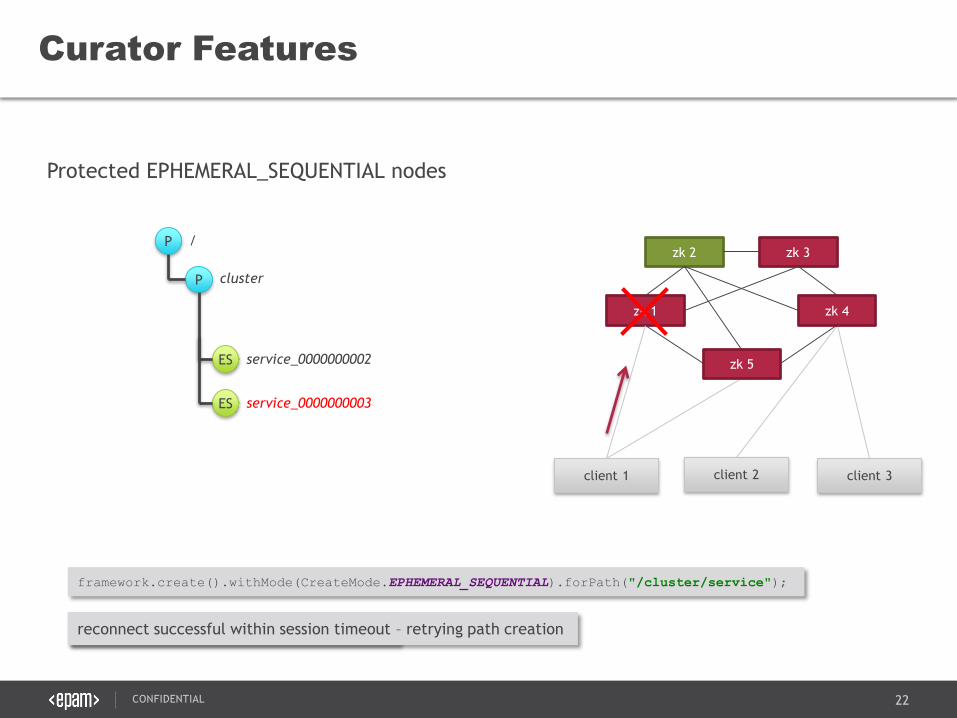
Protected EPHEMERAL_SEQUENTIAL nodes
Curator Features
zk 1
zk 2 zk 3
client 1 client 2 client 3
zk 4
P
P
/
cluster
framework.create().withMode(CreateMode.EPHEMERAL_SEQUENTIAL).forPath("/cluster/service");
ES service_0000000002
ES service_0000000003
zk 5
connection loss – reconnect attempt beginsreconnect successful within session timeout – retrying path creation

23CONFIDENTIAL
Protected EPHEMERAL_SEQUENTIAL nodes
Curator Features
zk 1
zk 2 zk 3
client 1 client 2 client 3
zk 4
P
P
/
cluster
framework.create().withMode(CreateMode.EPHEMERAL_SEQUENTIAL).withProtection().forPath("/cluster/service");
ES _c_16c39a25-87b4-4a54-bd05-1666a3e718de_service_0000000002
zk 5
connection loss – reconnect attempt beginsreconnect successful within session timeout – checkning zNode with same GUIDno extra zNode created

24CONFIDENTIAL
• Performance Considerations
• Using Observers to scale
• Using Hierarchical Quorums for multi-datacenter setup
• Surviving network partition with read-only mode
Zookeeper in the real world

25CONFIDENTIAL
• Replicated data is kept entirely in-memory by zookeper processes
• full GC can drop out a server from the ensemble
• Synchronous filesystem writes in commit phase
• can take seconds on an overloaded storage device
• use dedicated device for zookeeper transaction logs
• Maximum zNode size is 1M by default
• data + metadata should fit in
• configurable using a system property, but increasing it is not recommended
• Watches and performance
• Too many watches on a single node – herd effect
• Too many watches overall – increases memory footprint
Performance considerations

26CONFIDENTIAL
notifycommitvoteproposepropagate
Using Observers to scale
client
follower
leader
follower
follower
setData
sync return
callback called
watch triggered
observer
observers:
• no proposals
• no votes
• can’t be leaders
time

27CONFIDENTIAL
Hierarchical Quorums
zk5
zk4
zk6
zk8
zk7
zk9
zk2
zk1
zk3
Majority quorums:
• any 4 zk failures are tolerated
A datacenter goes down
• remaining ensemble becomes
much less resilient
Hierarchical quorums:
• Disjoint groups are formed
• Quorum requires majority of votes
from the majority of groups
• 5 failures can be tolerated
• Better for clusters spanning
multiple datacenters
group 1 group 2
group 3

28CONFIDENTIAL
Read-only mode
zk5
zk4
zk6
zk8
zk7
zk9
zk2
zk1
zk3
Network partitions,
a datacenter gets detached
Partitioned zookeepers can operate
in read-only mode
• not connected to the ensemble
• no writes allowed
• read requests are still served
By default read-only mode is disabled
zk2
zk1
zk3

29CONFIDENTIAL
• ACLs
• Quota support
• Authentication support
• Transaction logging
• Connection state handling
• Weighted hierarchical quorums
• Configuration
• Dynamic reconfiguration
• ...
• More info:
• ZooKeeper documentationhttp://zookeeper.apache.org/doc/trunk/index.html
• Curator resourceshttp://curator.apache.org
• ZAB protocol in detailhttp://web.stanford.edu/class/cs347/reading/zab.pdf
http://diyhpl.us/~bryan/papers2/distributed/distributed-systems/zab.totally-ordered-broadcast-
protocol.2008.pdf
• ZooKeeper bookhttp://shop.oreilly.com/product/0636920028901.do
Topics not covered

30CONFIDENTIAL
THANK YOU!