taming aggressive replication in the pangaea wide-area file system y. saito, c. kaamanolis, m....
Post on 21-Dec-2015
213 views
TRANSCRIPT

Taming Aggressive Replication in the Pangaea
Wide-area File System
Y. Saito, C. Kaamanolis, M. Karlsson, M. Mahalingam
Presented by Jason Waddle

Pangaea: Wide-area File System
o Support the daily storage needs of distributed users.
o Enable ad-hoc data sharing.

Pangaea Design Goals
I. Speed Hide wide-area latency,
file access time ~ local file system
II. Availability & autonomy Avoid single point-of-failure Adapt to churn
III. Network economy Minimize use of wide-area network Exploit physical locality

Pangaea Assumptions (Non-goals)
Servers are trusted
Weak data consistency is sufficient (consistency in seconds)

Symbiotic Design

Symbiotic Design
Autonomous
Each server operates when disconnected from network.

Symbiotic Design
Autonomous
Each server operates when disconnected from network.
Cooperative
When connected, servers cooperate to enhance overall performance and availability.

Pervasive Replication
Replicate at file/directory level Aggressively create replicas: whenever a
file or directory is accessed No single “master” replica A replica may be read / written at any time Replicas exchange updates in a peer-to-
peer fashion

Graph-based Replica Management
Replicas connected in a sparse, strongly- connected, random graph
Updates propagate along edges Edges used for discovery and removal

Benefits of Graph-based Approach
Inexpensive Graph is sparse, adding/removing replicas O(1)
Available update distribution As long as graph is connected, updates reach every
replica Network economy
High connectivity for close replicas,build spanning tree along fast edges

Optimistic Replica Coordination
Aim for maximum availability over strong data-consistency
Any node issues updates at any time Update transmission and and conflict
resolution in background

Optimistic Replica Coordination
“Eventual consistency” (~ 5s in tests) No strong consistency guarantees:
no support for locks, lock-files, etc.

Pangaea Structure
Region(<5ms RTT)
Server or Node
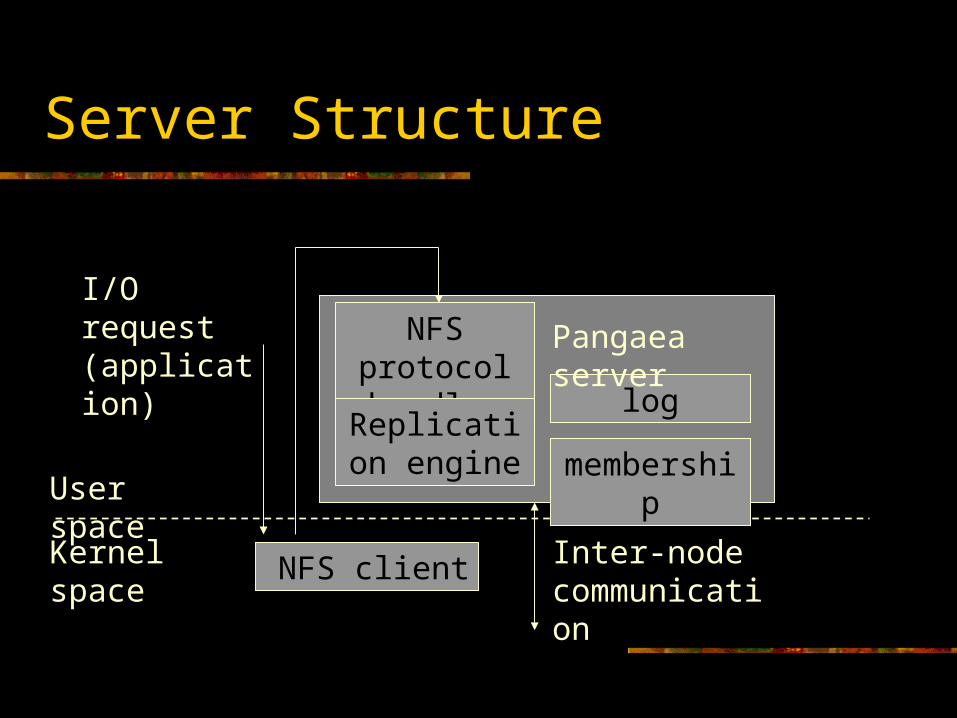
Server Structure
NFS client
User space
Kernel space
NFS protocol handler
membershipReplication
engine
log
Pangaea server
I/O request(application)
Inter-node communication

Server Modules
NFS protocol handler Receives requests from apps, updates local replicas,
generates requests to

Server Modules
NFS protocol handler Receives requests from apps, updates local replicas,
generates requests to Replication engine
Accepts local and remote requests Modifies replicas Forwards requests to other nodes

Server Modules
NFS protocol handler Receives requests from apps, updates local replicas,
generates requests to Replication engine
Accepts local and remote requests Modifies replicas Forwards requests to other nodes
Log module Transaction-like semantics for local updates

Server Modules
Membership module maintains: List of regions, their members, estimated RTT
between regions Location of root directory replicas Information coordinated by gossiping “Landmark” nodes bootstrap newly joining
nodes
Maintaining RTT information: main scalability bottleneck

File System Structure
Gold replicas Listed in directory entries Form clique in replica graph Fixed number (e.g., 3)
All replicas (gold and bronze) Unidirectional edges to all gold replicas Bidirectional peer-edges Backpointer to parent directory

File System Structure
/joe/foo
/joe

File System Structure
struct Replica
fid: FileID
ts: TimeStamp
vv: VersionVector
goldPeers: Set(NodeID)
peers: Set(NodeID)
backptrs: Set(FileID, String)
struct DirEntry
fname: String
fid: FileID
downlinks: Set(NodeID)
ts: TimeStamp

File Creation
Select locations for g gold replicas (e.g., g=3) One on current server Others on random servers from different regions
Create entry in parent directory Flood updates
Update to parent directory File contents (empty) to gold replicas

Replica Creation
Recursively get replicas for ancestor directories
Find a close replica (shortcutting) Send request to the closest gold replica Gold replica forwards request to its neighbor
closest to requester, who then sends

Replica Creation
Select m peer-edges (e.g., m=4) Include a gold replica (for future shortcutting) Include closest neighbor from a random gold
replica Get remaining nodes from random walks
starting at a random gold replica Create m bidirectional peer-edges

Bronze Replica Removal
To recover disk space Using GD-Size algorithm, throw out largest,
least-accessed replica Drop useless replicas
Too many updates before an access (e.g., 4) Must notify peer-edges of removal; peers
use random walk to choose new edge

Replica Updates
Flood entire file to replica graph neighbors Updates reach all replicas as long as the
graph is strongly connected Optional: user can block on update until all
neighbors reply (red-button mode) Network economy???

Optimized Replica Updates
Send only differences (deltas) Include old timestamp, new timestamp Only apply delta to replica if old timestamp
matches Revert to full-content transfer if necessary
Merge deltas when possible

Optimized Replica Updates
Don’t send large (e.g., > 1KB) updates to each of m neighbors
Instead, use harbingers to dynamically build a spanning-tree update graph Harbinger: small message with update’s
timestamps Send updates along spanning-tree edges Happens in two phases

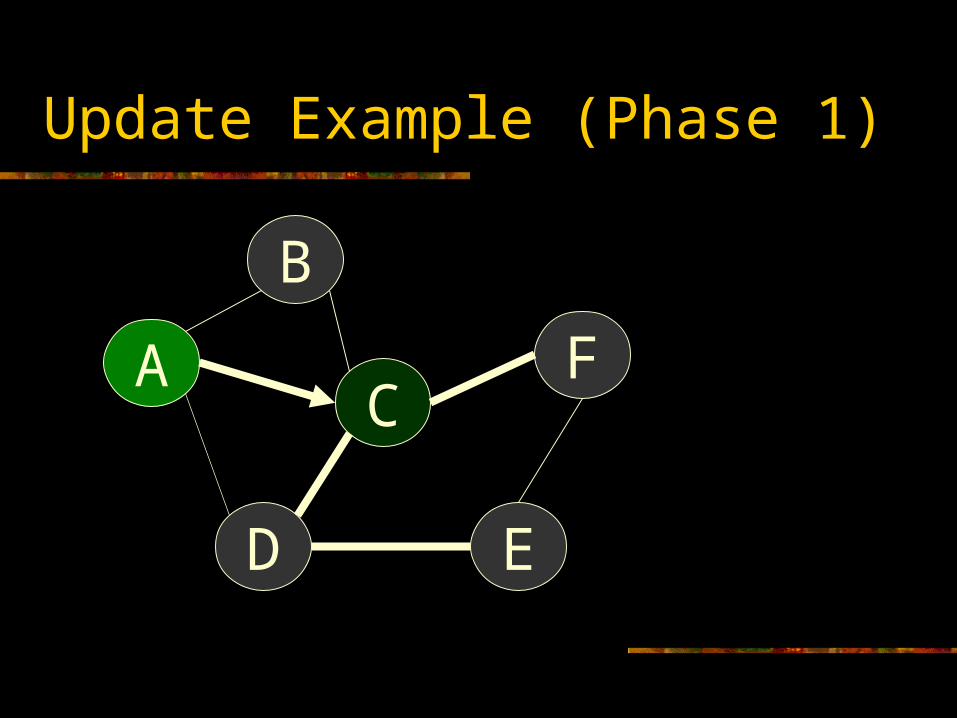
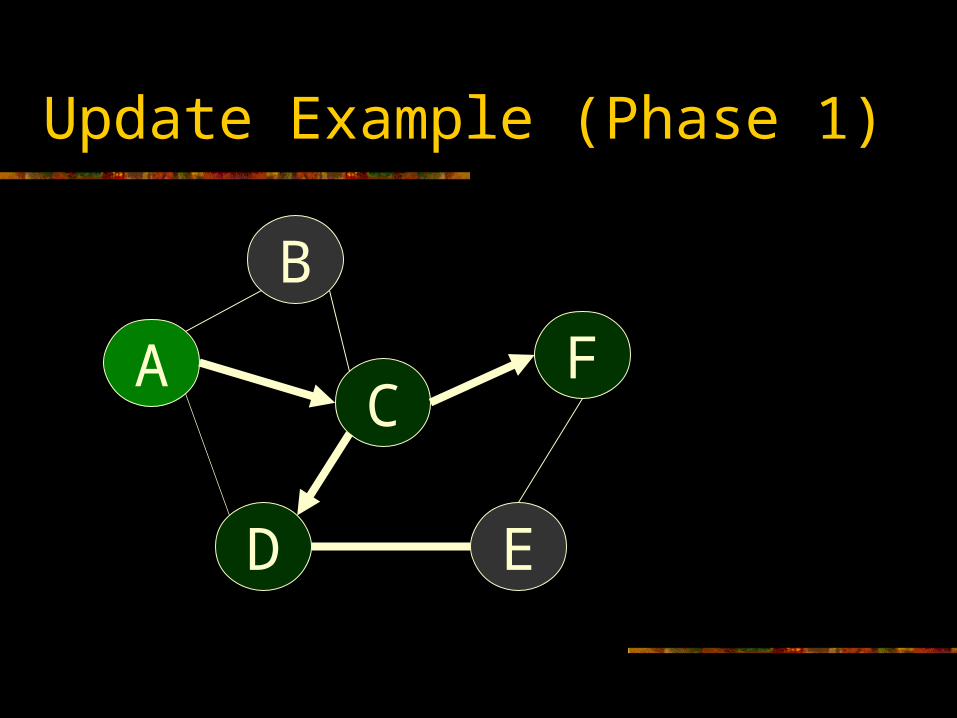
Optimized Replica Updates
Exploit Physical Topology Before pushing a harbinger to a neighbor,
add a random delay ~ RTT (e.g., 10*RTT) Harbingers propagate down fastest links first Dynamically builds an update spanning-tree
with fast edges

Update Example (Phase 1)
A
B
C
D E
F
Update Example (Phase 1)
A
B
C
D E
F
Update Example (Phase 1)
A
B
C
D E
F

Update Example (Phase 1)
A
B
C
D E
F

Update Example (Phase 1)
A
B
C
D E
F

Update Example (Phase 1)
A
B
C
D E
F
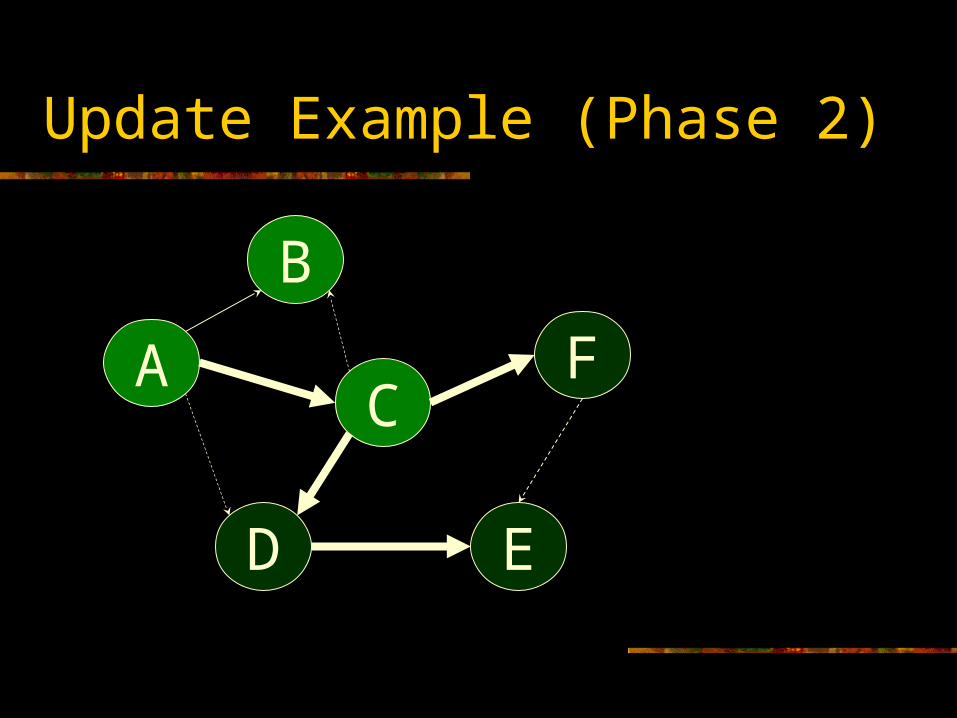
Update Example (Phase 2)
A
B
C
D E
F
Update Example (Phase 2)
A
B
C
D E
F

Update Example (Phase 2)
A
B
C
D E
F

Conflict Resolution
Use a combination of version vectors and last-writer wins to resolve
If timestamps mismatch, full-content is transferred Missing update: just overwrite replica

Regular File Conflict (Three Solutions)
1) Last-writer-wins, using update timestamps
• Requires server clock synchronization
2) Concatenate both updates • Make the user fix it
3) Possibly application-specific resolution

Directory Conflict
alice$ mv /foo /alice/foo bob$ mv /foo /bob/foo
Directory Conflict
alice$ mv /foo /alice/foo bob$ mv /foo /bob/foo
/alice replica set /bob replica set
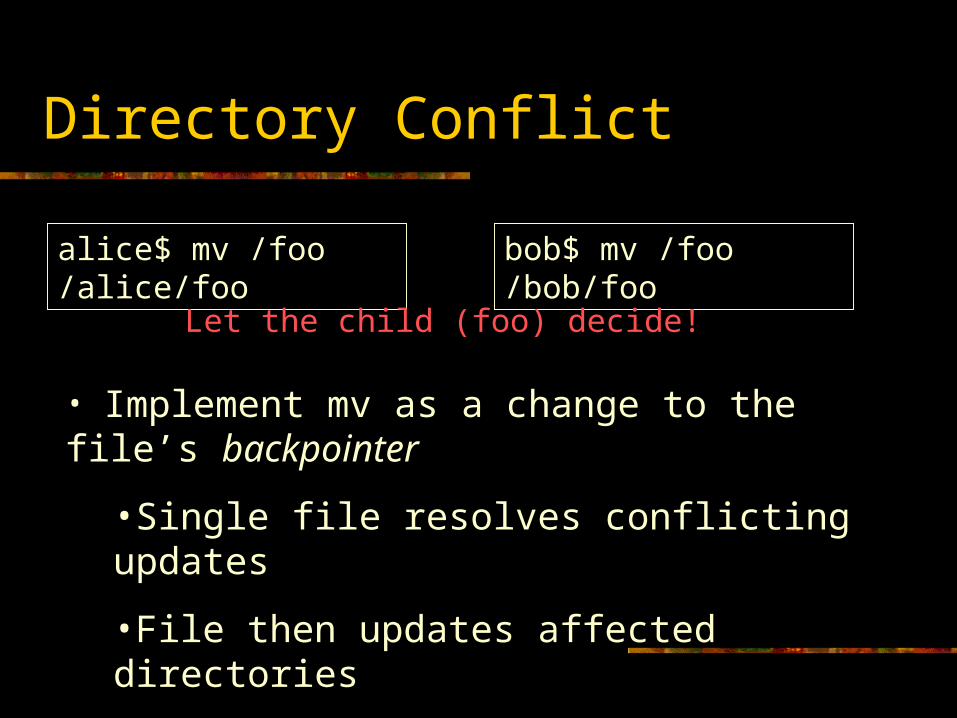
Directory Conflict
alice$ mv /foo /alice/foo bob$ mv /foo /bob/foo
Let the child (foo) decide!
• Implement mv as a change to the file’s backpointer
•Single file resolves conflicting updates
•File then updates affected directories

Temporary Failure Recovery
Log outstanding remote operations Update, random walk, edge addition, etc.
Retry logged updates On reboot On recovery of another node
Can create superfluous edges Retains m-connectedness

Permanent Failures
A garbage collector (GC) scans for failed nodes
Bronze replica on failed node GC causes replica’s neighbors to replace link
with a new peer using random walk

Permanent Failure
Gold replica on failed node Discovered by another gold (clique)
Chooses new gold by random walk Flood choice to all replicas Update parent directory to contain new gold
replica nodes Resolve conflicts with last-writer-wins Expensive!

Performance – LAN
Andrew-Tcl benchmarks, time in seconds
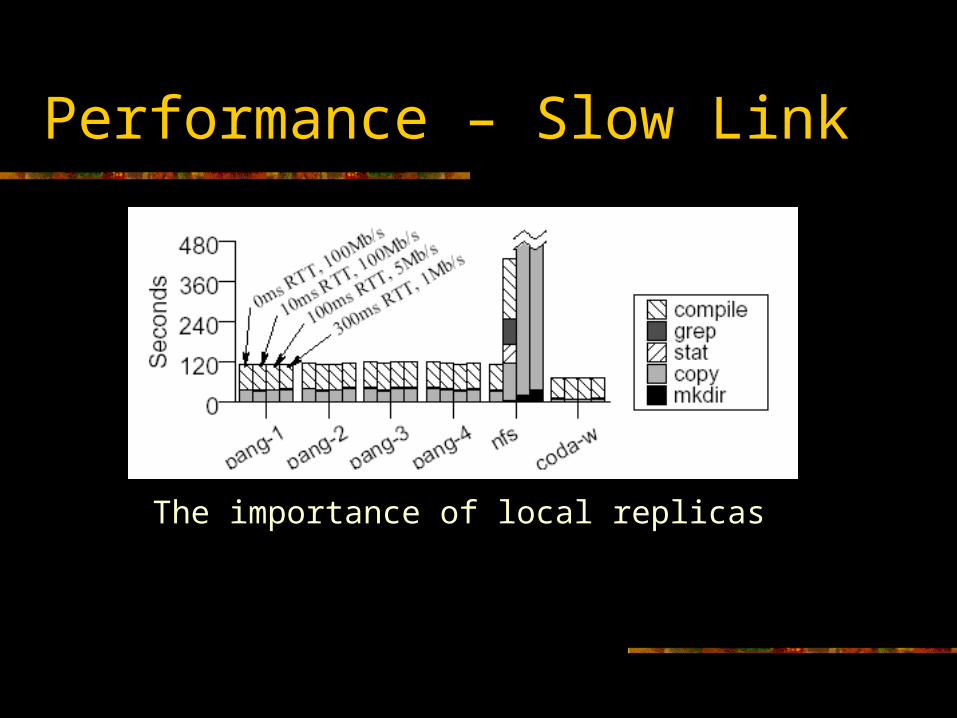
Performance – Slow Link
The importance of local replicas

Performance – Roaming
Compile on C1 then time compile on C2. Pangaea utilizes fast links to a peer’s replicas.

Performance: Non-uniform Net
A model of HP’s corporate network.
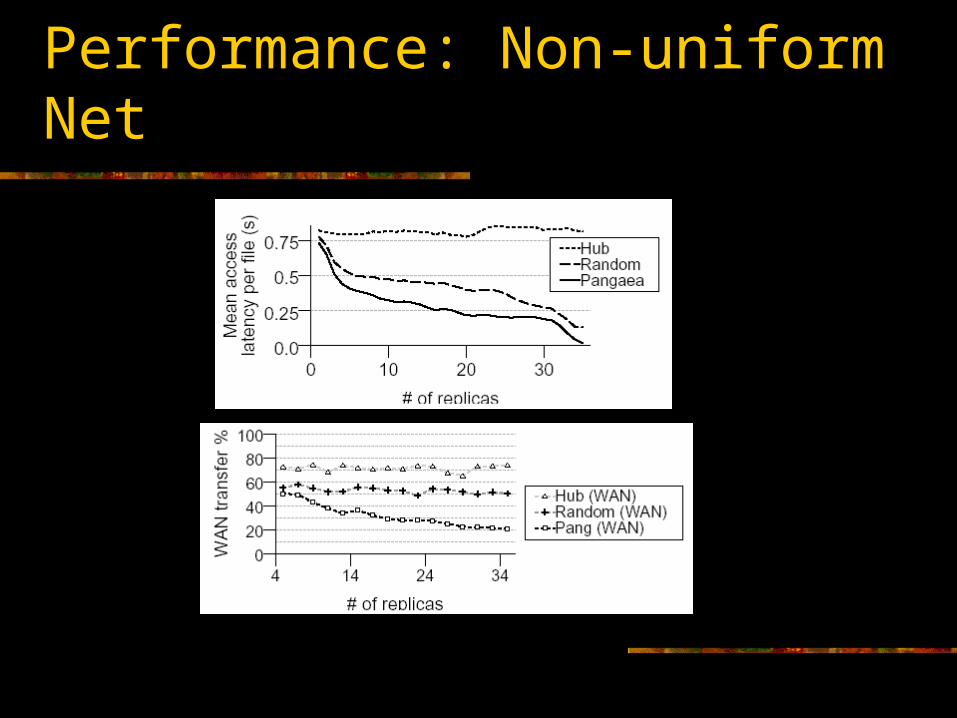
Performance: Non-uniform Net
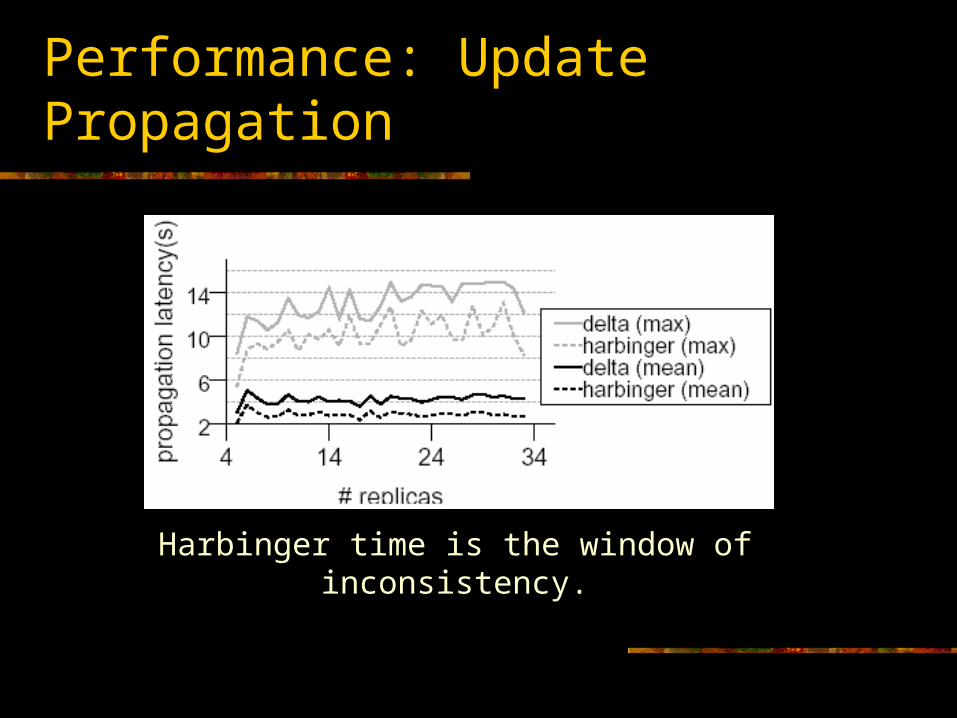
Performance: Update Propagation
Harbinger time is the window of inconsistency.

Performance: Large Scale
HP: 3000 Node 7-region HP Network
U: 500 regions, 6 Nodes per region, 200ms RTT 5Mb/s
Latency improves with more replicas.

Performance: Large Scale
HP: 3000 Node 7-region HP Network
U: 500 regions, 6 Nodes per region, 200ms RTT 5Mb/s
Network economy improves with more replicas.

Performance: Availability
Numbers in parenthesis are relative storage overhead.