taking patterns for chunks: is there any evidence of chunk learning in continuous serial...
TRANSCRIPT

Psychological Research (2008) 72:387–396
DOI 10.1007/s00426-007-0121-7ORIGINAL ARTICLE
Taking patterns for chunks: is there any evidence of chunk learning in continuous serial reaction-time tasks?
Luis Jiménez
Received: 14 March 2007 / Accepted: 23 June 2007 / Published online: 24 July 2007© Springer-Verlag 2007
Abstract When exposed to a regular sequence, peoplelearn to exploit its predictable structure. There have beentwo major ways of thinking about learning under these con-ditions: either as the acquisition of general statistical infor-mation about the transition probabilities displayed by thesequence or as a process of memorizing and using separatechunks that can later become progressively composed withextended practice. Even though chunk learning has beenadopted by some theories of skill acquisition as their mainbuilding block, the evidence for chunk formation is scarcein some areas, and is especially so in the continuous serialreaction-time (SRT) task, which has become a majorresearch tool in the study of implicit learning. This articlepresents a reappraisal, replication and extension of anexperiment that stands so far as one of the few allegeddemonstrations of chunk learning in the SRT task (Kochand HoVmann, Psychological Res., 63:22–35, 2000). Itshows that the eVects which were taken as evidence forchunk learning can indeed be obtained before any system-atic training and thus surely reXect a preexistent tendencyrather than a learned outcome. Further analyses of theeVects after extended practice conWrm that this tendencyremains essentially unchanged over continuous trainingunlike what could be expected from a chunk-based accountof sequence learning.
Introduction
One of the main issues concerning the mechanisms ofimplicit sequence learning is whether they could bedescribed as the continuous accrual of statistical informa-tion about the underlying sequence, or as a discrete processof memorizing and using sequence fragments. Learning ofseparate chunks has been surprisingly diYcult to substanti-ate empirically in the serial reaction-time (SRT) task, atleast by using the standard procedure with homogeneousintervals between responses and stimuli. Actually, there isonly one article that has reported clear evidence for chunk-ing processes in a continuous SRT task (Koch and HoVmann2000), and this evidence was obtained selectively when thesequence was structured to follow a highly salient pattern.The goal of this study is to explore an alternative interpreta-tion of these results, which might account for these eVectsas the result of some preexistent response tendencies spe-ciWc to the arranged patterns. A conceptual replication ofthe most relevant condition from Koch and HoVmann’sstudy does show that the eVects that were taken as evidencefor chunk learning can indeed be observed from the outsetof training, and thus could be considered as reXecting over-all response tendencies rather than an outcome of sequencelearning. Further analyses conducted over long periodsof practice show that this pattern remains essentiallyunchanged over training, unlike what could be expectedfrom a chunk-based account of sequence learning.
Statistical versus chunk learning
Perruchet and Pacton (2006) have recently highlighted thepotential interest of the comparison between statistical andchunk learning models for many research Welds, ranging
L. Jiménez (&)Facultad de Psicología, Campus Sur, Universidad de Santiago, 15782 Santiago, Spaine-mail: [email protected]
123

388 Psychological Research (2008) 72:387–396
from language acquisition to motor skill learning. Theauthors identiWed statistical learning (SL) with the type oflearning implemented in connectionist networks such as theSRN (Christiansen et al. 1998; Cleeremans 1993) anddescribed chunk learning (CL) as grounded on the exis-tence of perceptual and attentional limitations that wouldrestrict learning processes from spreading continuouslyover a large sequence. According to this limited-capacityperspective that is most explicitly stated in PARSER(Perruchet and Vinter 1998, 2002; Perruchet 2005), whenparticipants focus their attention on learning about a partic-ular fragment of a series they will learn speciWcally aboutthis fragment, but they will also tend to learn comparativelyless about the following transition between this chunk andits immediate successor.
Models of chunk learning, such as PARSER andCompetitive Chunking (Servan-Schreiber and Anderson1990), describe the initial outcome of learning as fragmen-tary, but they also allow learners to gradually build up amore general representation of the sequence with extendedpractice. Indeed, the developed chunks are assumed to beprocessed just like primitive units once they reach a givenstrength criterion, and so they are allowed to enter intosuccessive cycles of chunking that may eventually yield aunitary representation of larger parts of the sequence.
The recursive nature of this chunking process thusenable CL to end up producing representational outcomesvery similar to those yielded by SL, but they do so bymeans of diVerent learning mechanisms. Whereas SLassumes that responding to each trial is enough for the sys-tem to encode the relevant dimension, update the transitionprobabilities in accordance to the observed trial, and pre-pare for the next trial as predicted by the current context,CL tends to assume that all these computations cannot beaccomplished at the same time. Thus, over the course oflearning, these two models predict a diVerent learning tra-jectory. SL is compatible with a continuous acquisition pro-cess that would be shaped exclusively by statisticalconstraints, whereas CL is aVected by attentional con-straints, and thus will tend to encode sequences intodisjunctive chunks, at least early in training, before therecursive process can give place to the concatenation ofthese chunks into longer structures (cf. Perruchet andGallego 1997).
Chunk learning in the SRT task
The search for empirical evidence of chunk learning hasproduced some positive results in paradigms in which thestimuli are presented simultaneously, such as in artiWcial-grammar learning (Servan-Schreiber and Anderson 1990).In sequence learning paradigms, some eVects of chunk
learning have arisen when fragmentary encoding is forcedby the inclusion of pauses between chunks as it occurs inthe discrete sequence production tasks (Verwey and Eikel-boom 2003; Verwey et al. 2002), or when diVerent amountsof repetition of each fragment are provided by training on atrial-and-error basis (Sakai et al. 2003). Some related evi-dence has also been found when the sequence concerns theseries of tasks to be performed, rather than the series ofresponses produced to a single task (Koch et al. 2006;Schneider, in press). However, the evidence for chunklearning is surprisingly scarce in the SRT task, which hasbecome the most popular paradigm in the study of implicitlearning. In this task, participants are told to respond to aseries of successive trials by pressing as fast and accuratelyas possible on a set of corresponding keys. The series of tri-als follows a regular sequence, and participants learn toexploit this sequence as it is shown by the production offaster reaction times (RT) in response to the regular trials,even though they are not told about the existence of asequence, nor are they asked to learn about this predictablestructure (Nissen and Bullemer 1987).
In the SRT task, it has become a standard to arrange aWxed response-to-stimuli interval (RSI) and to use homoge-neous statistical structures such as the second-order condi-tional (SOC) structures (see Reed and Johnson 1994) inwhich all the responses are equally likely, and all transi-tions are equally predictable by relying on their relevantcontexts. With this type of structures, the principles of SLwould predict that participants will learn homogeneouslyabout all parts of the sequence, and therefore any system-atic departure from this Xat learning pattern could be takenas evidence of chunk learning.
In practice, however, this straightforward prediction isdiYcult to test because, even if participants learn by encod-ing disjunctive fragments of the sequence, each of themcould be making a diVerent partition of the structure, and sothe learning measures averaged over learners might conveythe wrong impression that they are all acquiring consistentinformation about the whole sequence (cf. Perruchet andGallego 1997). A simple way to circumvent this problem isto force all participants to break the sequence in preciselythe same fragments, either by introducing pauses at somepoints in the sequence (Stadler 1993, 1995; Frensch et al.1994) or by arranging relational patterns that make certainfragments to become more salient than other parts (Kochand HoVmann 2000). The observation that participantsrepresent disjunctive fragments when these fragments aretemporally separated over training is not particularly illu-minating for the debate about the “default” process oflearning that takes place when the learners respond to acontinuous sequence. On the contrary, if presenting partici-pants with a relational, but yet continuous, sequence doesproduce any evidence of chunk learning, this at least could
123

Psychological Research (2008) 72:387–396 389
be taken as showing that chunk learning occurs when thefragments are salient enough to capture learners’ attentionin predictable ways.
The Koch and HoVmann’s (2000) study
The most relevant results concerning this prediction werepresented by Koch and HoVmann (2000) in their Experi-ment 1. SpeciWcally, in the condition D + K + from thatexperiment, 10 participants responded to a series of digits(1–6) by pressing one of six diVerent keys depending on thedigit identity. In this condition, there was a compatiblemapping between the identity of the digit and the requiredresponse so that the six response keys were assigned fromleft to right to the digits 1–6. Over two practice blocks, par-ticipants got used to the task by responding to a controlsequence of 24 items, which was repeated eight times overeach block. Over the next three training blocks, participantswere presented with a repeated series of 24 trials that fol-lowed this relational structure: 123321456654123234345456. As it can be observed, this sequence is structured inascending and descending triplets of successive digits andkeystrokes, and there is also a series of relational patternsthat governs the succession between triplets, either as aninversion of the previous one or as a transposition of thatprevious run by one step. This structure is more easilyappreciated by separating the triplets in the following way:123 321 456 654 123 234 345 456. The training sequencewas presented eight times over each of these three trainingblocks (3–5), and it was repeated again over block 7. Block6 was designed as a control block that arranged eight repeti-tions of the control sequence. The measure of sequencelearning was taken as the diVerence between participants’responses to blocks 5 and 6.
According to this measure, participants learned to exploitthis relational structure very eYciently as they responded279 ms faster to the training structure than to the controlblock. Such a diVerence is unusually large for an SRT task,especially considering that (1) the sequence was 24 itemslong, (2) the participants had practiced it for only three train-ing blocks and (3) they had been trained with the controlsequence over the two initial practice blocks. Thus, over theblock 6, when the control structure is reintroduced, theamount of practice given with each of these two structures isalmost comparable, but the fact that participants’ responseswere much slower to that of the control sequence didstrongly indicate that responding was being driven by therelational patterns implemented over the training sequence.
In addition to showing such a strong learning eVect, theauthors presented two main sources of evidence for chunklearning. First, a representation of the average respondingover block 5 displayed separately for each of the 24 items
of the sequence did clearly indicate that responses werestructured in triplets, so that RT was slower for the Wrstitem of each triplet, and got faster over its second and thirditems. Second, a summary of this eVect was computed byaveraging responses given to the Wrst, second and thirditems over the eight triplets. This measure showed a signiW-cant advantage for the second and third positions, as com-pared to the Wrst position of the triplets.
The alternative account
The results of Experiment 1 from Koch and HoVmann(2000) appeared to bring about the clear conclusion that theuse of relational patterns resulted in a strong eVect of chunklearning. In the authors’ own words, these Wndings “...clearly support the notion that sequence learning in SRTtasks [...] can be conceptualized as a chunking process”(p. 33). In fact, the authors only discussed a minor caveatagainst this conclusion, concerned with the fact that thetypical pattern did not arise in a few triplets that included ahand-switch within a chunk. However, a radically diVerentpicture may arise by considering the speciWc transitions thatgive place to slow RT at the beginning of each chunk. Bylooking at these speciWc transitions (see Fig. 1), one can seethat half of the transitions between triplets correspondedprecisely to hand-switches and that all the remaining transi-tions produced either immediate repetitions of the previoustrial (at the beginning of the second and fourth triplets) orrepetitions of the n-2 trial (i.e., reversals, at the beginningof the sixth and eighth triplet). Moreover, the seventh tripletstarted with a trial that implemented simultaneously a hand-switch and a reversal movement. Vaquero et al. (2006)have recently reported that reversals tend to produce slowerresponses in SRT tasks, regardless of any learning eVect.Thus, if hand-switches produce slow responses, and if bothimmediate repetitions and reversals could also be expectedto slow down performance, then it becomes possible that allthese alleged eVects of chunk learning could boil down toresponse patterns unrelated to learning. To test this possi-bility, I designed a conceptual replication and extension ofthe condition D + K + from Koch and HoVmann’s (2000)Experiment 1. The main goals of this experiment were toassess whether: (1) the pattern of results that was taken asevidence for chunk learning could be observed from theoutset of training before learning has had time to develop,and (2) providing further practice with the structure couldallow for these chunk-learning eVects to develop. Accord-ing to the predictions of chunk learning models such asPARSER (e.g., Perruchet and Vinter 1998) or CompetitiveChunking (Servan-Schreiber and Anderson 1990), wecould expect to obtain an initially steeper learning curve forintra-chunk dependencies as compared to that observed for
123

390 Psychological Research (2008) 72:387–396
the transitions between chunks, which might be followedlater by a decline of such a diVerence when an extensivetraining could start producing the integration of formerchunks into larger hierarchical structures.
Method
Participants performed an SRT task that required them torespond as fast and accurately as possible to the identity of
a digit between 1 and 6, presented in black at the center of acyan computer screen, by pressing a key that was consis-tently mapped to each digit. Digits 1–6 were assignedrespectively to the keys “c”, “v”, “b”, “n”, “m”, and “,” on aSpanish “QWERTY” keyboard. The six digits kept writtenin white over the bottom row of the screen, approximatelyin front of the response keys, as a reminder of the mappingrequired between digits and response keys. Participantswere told to hold the ring, middle, and index Wngers fromtheir left hand on the Wrst three keys, and the index, middleand ring Wngers from their right hand on the following threekeys so as to make responding more eYcient. Instructionswere complemented with a Wrst practice block of 18 ran-dom and unrecorded trials and were then followed by 19experimental blocks, each composed of 192 trials.
Design
A relational structure identical to that used by Koch andHoVmann (2000) was used to generate the digits overblocks 2–18. Thus, on each of these training blocks, partici-pants responded to eight repetitions of the sequence: 123321 456 654 123 234 345 456. Blocks 1 and 19 werearranged as test blocks, composed also by eight series of 24trials. Instead of using a completely diVerent structure forthis test block and in order to have an initial block in whichthe response tendencies could be properly tested beforelearning took place, these blocks were designed to containsome exemplars of the training structure, together withother structures that could be useful for comparison pur-poses. SpeciWcally, test blocks 1 and 19 contained eightseries of 24 trials distributed in the following way. The Wrstand the eighth series implemented an instance of the train-ing sequence. The second and the seventh series involvedthe same triplets arranged over the training sequence, butwith their order switched between successive pairs, thusproducing the following series: 321 123 654 456 234 123456 345. The four central series were intended to break thetraining triplets in a systematic way. SpeciWcally, this wasachieved over the third and sixth series by replacing theWrst item of each triplet with the digit corresponding to thesame relative location from the other hand (so that the trip-let 123 became 423, and so on). Over the fourth and Wfthseries, Wnally, the illegal triplets were made by replacingthe third digit of each triplet in the same way so that thetriplet 123 became 126, and so on.
Participants
Twelve students of the University of Santiago participatedin the experiment in exchange for a fee of 5D. To furthermotivate them to cope with the speed and accuracy require-ments of the task, they were told that 10% of the participants
Fig. 1 Representation of the 24-item training sequence showing thecorrespondence between digits, response keys, and Wngers. The seriesis depicted in two successive columns, with the salient triplets sepa-rated by horizontal lines. Labels are included to mark special trialssuch as hand-switches (H), repetitions (R) and reversals (rv)
3
1
2
3
5
R
H
H
R
1
3
2
1
4
6
rv
H
H
rv
H
rv
Hrv
rv
rv
2
6
5
4
3
2
4
3
4
5
4
5
6
3
1
2
3
5
R
H
H
R
1
3
2
1
4
6
rv
H
H
rv
H
rv
Hrv
rv
rv
2
6
5
4
3
2
4
3
4
5
4
5
6
123

Psychological Research (2008) 72:387–396 391
who yielded the best scores would receive an additionalincentive of 3D.
Procedure
The experiment was designed using INQUISIT 1.33 (Milli-second Software, 2003). Upon arriving at the laboratory,participants were given written instructions about thenature of the SRT task. They were urged to optimizeresponding by keeping the response Wngers on the keys andwere informed that they would hear a brief tone upon theproduction of an error. Regardless of whether theyresponded accurately or produced an error, the next itemappeared 250 ms after the last response. Between blocks,they were allowed to rest for a few moments, and receivedinformation about the average RT and the percentage ofcorrect responses yielded over the last block. They werespeciWcally reminded to keep this rate above 92%, and wereinstructed to take note of their scores on a response sheet inorder to keep track of their own performance. When theywere ready to proceed with the next block, they did so bypressing the space bar.
Results
Over the whole experiment, participants performed at ahigh level of accuracy. The percentage of correct responsesamounted to 97.5% of the trials. The patterns of resultsobtained with RT and accuracy measures were generallyconsistent, and thus I will restrict this report to the RT data.For the rest of this section, I will focus successively on: (1)the eVects of sequence learning on performance over suc-cessive training blocks; (2) the purported eVects of chunklearning as analyzed by Koch and HoVmann (2000); and(3) the response tendencies that can be identiWed before thestart of the training blocks, which provide an alternativeaccount for the triplet eVect.
Sequence learning
Figure 2 represents the average RT for correct responsesover successive blocks, including both test (1 and 19) andtraining blocks (2–18). An Analysis of Variance (ANOVA)with block (19) as a repeated-measure variable indicatedthat the eVect of Block was signiWcant, F(18, 198) = 83.70;MSE = 2,032.8; P < 0.0001. The analysis conductedspeciWcally with the average RT to the 17 training blocksalso showed a signiWcant improvement with trainingF(16, 176) = 64.65; MSE = 1,584.3; P < 0.0001. The com-parison between participants’ performance over blocks 18and 19, which could be taken as the main measure ofsequence learning, further conWrmed the production of a
strong learning eVect, F(1, 11) = 218.41, MSE = 2,559.9;P < 0.0001. The average RT by the end of training was of236 ms, but it rebounded to the initial levels of performanceover the Wnal test block, reaching an average RT of 541 ms.
Purported chunk learning eVects
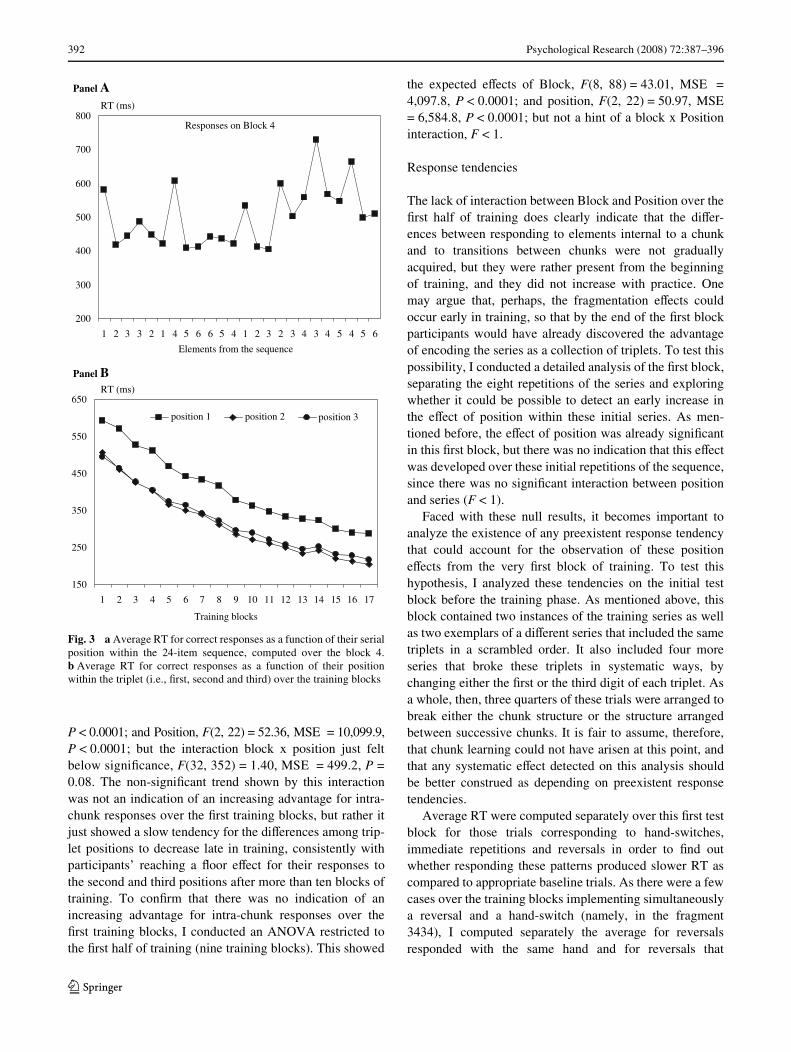
To get results comparable to those taken by Koch andHoVmann (2000), I analyzed RT over block 4, whichroughly corresponded to the same level of training with thestructure that was provided in Koch and HoVmann’s studyby their block 5. As shown in Fig. 3 (panel a), performanceover the 24 items of the series showed a pattern similar tothat found in the original study, producing an increase inRT at the beginning of each triplet. A summary of this posi-tion eVect was taken by Koch and HoVmann by computingthe mean RT separately for the keystrokes corresponding tothe Wrst, second and third positions over the eight triplets.Figure 3 (panel b) shows the results of such an aggregatedanalysis, not only for block 4, but also separately for all thetraining blocks. As it can be observed, the eVect of positionwas clearly observed on block 4, F(2, 22) = 25.97; MSE= 1,540.6; P < 0.0001, but the same eVect was already
present over the Wrst training block (i.e., block 2; F(2, 22) =39.63; MSE = 875.6, P < 0.0001), and it did not appear togrow progressively with training over the next few blocks.An ANOVA computed on these scores with block (17) andposition (3) as between-participants factors showed signiW-cant eVects of Block, F(16, 176) = 64.85, MSE = 4,758.6,
Fig. 2 Average RT for correct responses computed for each block oftrials. Blocks 1 and 19 were designed as test blocks, whereas blocks 2–18 were arranged as training blocks, containing eight repetitions of thetraining sequence
200
300
400
500
600
700
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
test
test
Practice blocks
RT (ms)
123
392 Psychological Research (2008) 72:387–396
P < 0.0001; and Position, F(2, 22) = 52.36, MSE = 10,099.9,P < 0.0001; but the interaction block x position just feltbelow signiWcance, F(32, 352) = 1.40, MSE = 499.2, P =0.08. The non-signiWcant trend shown by this interactionwas not an indication of an increasing advantage for intra-chunk responses over the Wrst training blocks, but rather itjust showed a slow tendency for the diVerences among trip-let positions to decrease late in training, consistently withparticipants’ reaching a Xoor eVect for their responses tothe second and third positions after more than ten blocks oftraining. To conWrm that there was no indication of anincreasing advantage for intra-chunk responses over theWrst training blocks, I conducted an ANOVA restricted tothe Wrst half of training (nine training blocks). This showed
the expected eVects of Block, F(8, 88) = 43.01, MSE =4,097.8, P < 0.0001; and position, F(2, 22) = 50.97, MSE= 6,584.8, P < 0.0001; but not a hint of a block x Positioninteraction, F < 1.
Response tendencies
The lack of interaction between Block and Position over theWrst half of training does clearly indicate that the diVer-ences between responding to elements internal to a chunkand to transitions between chunks were not graduallyacquired, but they were rather present from the beginningof training, and they did not increase with practice. Onemay argue that, perhaps, the fragmentation eVects couldoccur early in training, so that by the end of the Wrst blockparticipants would have already discovered the advantageof encoding the series as a collection of triplets. To test thispossibility, I conducted a detailed analysis of the Wrst block,separating the eight repetitions of the series and exploringwhether it could be possible to detect an early increase inthe eVect of position within these initial series. As men-tioned before, the eVect of position was already signiWcantin this Wrst block, but there was no indication that this eVectwas developed over these initial repetitions of the sequence,since there was no signiWcant interaction between positionand series (F < 1).
Faced with these null results, it becomes important toanalyze the existence of any preexistent response tendencythat could account for the observation of these positioneVects from the very Wrst block of training. To test thishypothesis, I analyzed these tendencies on the initial testblock before the training phase. As mentioned above, thisblock contained two instances of the training series as wellas two exemplars of a diVerent series that included the sametriplets in a scrambled order. It also included four moreseries that broke these triplets in systematic ways, bychanging either the Wrst or the third digit of each triplet. Asa whole, then, three quarters of these trials were arranged tobreak either the chunk structure or the structure arrangedbetween successive chunks. It is fair to assume, therefore,that chunk learning could not have arisen at this point, andthat any systematic eVect detected on this analysis shouldbe better construed as depending on preexistent responsetendencies.
Average RT were computed separately over this Wrst testblock for those trials corresponding to hand-switches,immediate repetitions and reversals in order to Wnd outwhether responding these patterns produced slower RT ascompared to appropriate baseline trials. As there were a fewcases over the training blocks implementing simultaneouslya reversal and a hand-switch (namely, in the fragment3434), I computed separately the average for reversalsresponded with the same hand and for reversals that
Fig. 3 a Average RT for correct responses as a function of their serialposition within the 24-item sequence, computed over the block 4.b Average RT for correct responses as a function of their positionwithin the triplet (i.e., Wrst, second and third) over the training blocks
Panel A
200
300
400
500
600
700
800
1 2 3 3 2 1 4 5 6 6 5 4 1 2 3 2 3 4 3 4 5 4 5 6
RT (ms)
RT (ms)
Elements from the sequence
Responses on Block 4
Panel B
150
250
350
450
550
650
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
position 1 position 2 position 3
Training blocks
123

Psychological Research (2008) 72:387–396 393
involved a hand-switch. As a comparison term, I computedthe baseline RT for those non-repeating and non-reversaltransitions that required responding with the same hand.Figure 4 represents the average RT for each of these typesof trials. As it can be observed, hand-switches took about135 ms longer than the baseline, F(1, 11) = 74.06; MSE= 1,474.3, P < 0.0001, whereas same-hand reversals
required an average of 93 ms more than other same-handtransitions, F(1, 11) = 13.51; MSE = 3,870.9, P < 0.005.When reversals also implied a hand-switch, they also pro-duced RT slower than the baseline, F(1, 11) = 22.66; MSE= 5,555.2, P < 0.001, but they did not result in a further
delay with respect to other hand-switches, F < 1. Surpris-ingly, immediate repetitions did not result in slower RT, butthey actually produced responses faster (55 ms) than thebaseline, F(1, 11) = 14.47; MSE = 1,254.5, P < 0.005.
As a whole, the response tendencies observed beforetraining are strong enough to account for the early appear-ance of the position eVect observed in this study. As it canbe conWrmed from a cursory inspection of Fig. 1, the Wrstposition of the triplets contained four hand-switches, threereversals and two immediate repetitions, whereas most ofthe transitions corresponding to the second and third posi-tions were made with the same hand. It should not be sur-prising, therefore, that responding to the Wrst position of thetriplets would take more time, in general, than respondingto their second or third elements.
The only evidence obtained in this study that could betaken as showing that participants learn to respond moreslowly to the Wrst elements of the triplets has to do with thechange produced over training in the responses given toimmediate repetitions. Within the initial test block, partici-
pants were shown to respond faster to repetitions than toother baseline trials, but this initial trend got progressivelyinverted over the next few blocks, and it reached a signiW-cant diVerence against repetitions over the block 8,F(1, 11) = 5.01; MSE = 3,494.6; P < 0.05. This speciWcchange could indicate that participants were chunking thesequence at these particular joints and thus using the repeti-tions as markers of the limits between successive chunks.However, an alternative account of this eVect might also bebuilt on the fact that the sequence arranged in this studywas not statistically homogeneous and thus that a form ofstatistical learning could also account for the appearance ofdiVerences in learning between parts of the sequence.
An inspection of the sequence does make clear that notall its transitions are equally predictable. In fact, the condi-tional probabilities of appearance of those trials containingimmediate repetitions are especially low, and thus thiscould account for the relatively lower improvementobserved in those speciWc trials. For instance, the probabil-ity of appearance of digit 3 immediately after another 3 isonly of .20, and it only grows to .33 by considering itsprobability of appearance in the context of the two previousevents (“23”). Similar Wgures hold for the repetition of digit6. In contrast, the averaged conditional probability ofappearance of any other same-hand transition in its relevantcontext amounts to .56 considering contexts of length 1,and goes up to .81 by considering contexts of length 2.Plainly, then, it is perfectly reasonable to assume that aform of statistical learning could account for the lowerimprovement observed in performance in response toimmediate repetitions, without assuming that learners areusing those repetitions as markers of the limits betweensuccessive chunks.
To further explore the idea that statistical learning couldbe compatible with the obtained results, I conducted alinear regression analysis on each training block, predictingthe average RT obtained by all participants on each item ofthe sequence by relying on the distributions of conditionalprobabilities of orders 0, 1 and 2. The results of these anal-yses were signiWcant through all the training blocks andshowed that the transition probabilities could account foralmost a third of the relevant variance in average RT overthe Wrst training block, R = 0.62; Adjusted R2 = 0.29;F(3, 20) = 4.19, P < 0.05. This multiple correlation tendedto grow with training, and it reached a maximum of predic-tive value by block 8, when they accounted for more than ahalf of the variance, R = 0.76; Adjusted R2 = 0.53; F(3, 20)= 9.54; P < 0.001. Figure 5 shows the evolution of theslopes � for each predictor with training. As it can beobserved, the conditional probabilities of orders 1 and 2were negatively correlated with RT, thus showing that morepredictable successors tended to produce faster RT, andwith practice second order transitional probabilities tended
Fig. 4 Average RT for correct responses computed over the Wrst testblock for baseline same-hand transitions, repetitions, same-handreversals, reversals with a hand-switch and other hand-switchtransitions
250
300
350
400
450
500
550
600
650
700
750
hand-switchreversal +hand-switch
reversal repetition baseline(same-hand)
RT (ms)
123

394 Psychological Research (2008) 72:387–396
to outscore the Wrst-order distribution. Surprisingly, how-ever, there was a positive relation between conditionalprobabilities of order 0 (i.e., item frequency) and RT. Thispositive relation tended to decrease with practice, but it wassigniWcant over the Wrst two-thirds of training, indicatingthat participants tended to respond faster precisely to thosetrials that occurred less frequently. This could be inter-preted as a consequence of the speciWc trials that happenedto occur less frequently in that particular series (digits 1 and6, requiring extreme responses), or perhaps as a tendencynot to expect that the digits would reappear very often, andthen responding slowly when they recur more frequently. Inany case, regardless of the interpretation of this particulartrend, what these regression analyses more generally indi-cate is that the evolution of RT with training is generallycompatible with the predictions of a statistical learning pro-cess.
Discussion
This study was inspired by previous work reported by Kochand HoVmann (2000) on the role of relational patterns andchunking processes in the acquisition of sequence learning.The conclusions raised by this extension of the originalstudy converge with their conclusions concerning the rele-vance of relational patterns, but they stand in sharp contrast
with their interpretation of the eVects produced by thesepatterns as evidence of chunk learning.
The analysis conducted on the eVects of these relationalpatterns over the Wrst test block indicated that the relationalpatterns that had been designed as tools to force chunklearning produced other eVects on performance that wereindependent from learning. Hand-switches and reversalsproduced signiWcantly slower RT than did other transitionsand they tended to occur at the beginning of the runs thatwere intended to force the segmentation of the sequenceinto triplets. Thus, the observation of slower RT at thebeginning of a triplet could not be unequivocally taken asevidence of chunk learning. Moreover, the observed stabil-ity of this position eVect, which arose on the very Wrst blockof training and was extended without changes over a longperiod of practice, is consistent with an interpretation of theeVect as a result of these preexistent response tendencies,rather than as an evidence of chunk learning.
Despite possible diVerences in their detailed assump-tions, the core of any chunk learning model (e.g., Perruchetand Vinter 1998; Servan-Schreiber and Anderson 1990)relies on the assumption that the representation of a chunktends to improve performance diVerentially for those partsof the task that are represented within a chunk and for thosethat correspond to transitions between chunks. Thus,regardless of whether participants were able to learn toanticipate next chunk while responding to the current one(Verwey and Eikelboom 2003) or whether some composi-tion process could arise later in practice to soften the diVer-ence between internal and external transitions, thediVerence between them should arise at some point in train-ing for the chunk hypothesis to be grounded in empiricaldata. The analyses conducted in this study have shown thatno such a diVerence arose in this experiment, neither earlyin practice, where these trends were analyzed in epochs of24 trials to look for Wne-grained diVerences, nor later on,where an extensive period of practice was provided. Somemight argue that Xoor eVects may have prevented theadvantage of chunk internal events to arise in these condi-tions. Indeed, this could be a good point if participantsreached a Xoor level of performance very early in training,but Fig. 3 (panel b) appears to show that performance overboth the transition and internal trials kept improving withpractice over a long training period, and thus that there wasroom enough for a relative diVerence between them to ariseearly in training.
In sum, the results obtained in this experiment do notsustain the claim that participants’ performance in this par-ticular task is being aVected by chunk learning, and theyrather suggest that sequence learning aVected performancein a continuous way throughout the whole sequence. At thispoint, however, it might be advisable to state moreprecisely what this conclusion may or may not imply.
Fig. 5 Evolution with training of the slopes (� of the regression func-tions) which predict RT to each of the 24 elements of the sequence,based on the distributions of conditional probabilities of order zero,one and two. CP (0), � for the conditional probabilities of order 0, orunconditional digit frequency. CP(1), � for the conditional probabili-ties of each digit in the context deWned by the previous digit. CP(2), �for the conditional probabilities of each digit in the context deWned bytwo previous digits
-0,8
-0,6
-0,4
-0,2
0
0,2
0,4
0,6
0,8
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
CP(0) CP(1) CP(2)
β
Training blocks
123

Psychological Research (2008) 72:387–396 395
SpeciWcally, this does not amount to claim that chunklearning eVects could not be expressed in other discontinu-ous settings in which sequence learning has been investi-gated, such as in the discrete sequence production task(Verwey and Eikelboom 2003; Verwey et al. 2002) or inthe task sequence learning domain (Koch et al. 2006;Schneider, in press). It does not even imply that participantsin the present SRT task have not noticed the existence of therelational patterns or that they have not learned anythingabout these speciWc patterns. Indeed, in their Experiment 2,Koch and HoVmann (2000) did show that learning was farlower when participants responded to a sequence that wasstatistically analogous to that employed in their Experiment1, but that diVered in that the triplets were not made ofcontinuous runs. Thus, it appears that including a relationalpattern does produce an improvement in sequence learningthat is arguably due to the fact that these relational patternsmake the existence of a sequence far more salient, and thusimprove sequence learning in general.
Although Koch and HoVmann (2000) did not report onany direct measures of sequence learning, and measures ofawareness are not included in the present experiment, infor-mal comments made by some participants suggest that theywere largely aware of the existence of these patterns. Thelarge eVect of learning can also be considered as a clueindicating that learning was explicit. However, in this con-text, it is particularly remarkable that the explicit acquisi-tion of information about some speciWcally salient patternswere not selectively expressed in performance as a localimprovement in response to these particular fragments ofthe sequence. This appears to indicate that, in these SRTtasks, explicit knowledge of fragments cannot be immedi-ately translated into an eVect of performance. One mayargue that participants may have learned explicitly andsimultaneously about the whole structure and therefore thatthe eVect of learning could be immediately translated intoan overall eVect of performance over the whole sequence.However, this account does not seem very plausible, giventhe well known limits of human working memory. An alter-native account for these results could be built by assumingthat learning of some disjunctive chunks may haveoccurred explicitly, as participants noticed the relationalpatterns, but that this explicit knowledge could not beimmediately translated into a local advantage for respond-ing to those fragments because participants’ resources werealready occupied in coping with the response demandsmade by each speciWc trial. If that were the case, chunklearning could still be reinforced from the continuous repe-tition of such salient patterns, but this learning would turnout to produce diVuse inXuences, rather than local eVects inperformance, by modulating participants’ reliance on anyother source of sequence information. A similar eVect ofindirect modulation of the implicit eVects derived from the
learners’ explicit beliefs has been reported by Jiménez et al.(2006) who found that decreasing the validity of a sequencein intentional learners resulted in slower RT not only for thecontrol trials, but also for those trials that were generatedaccording to the sequence. In a similar vein, it is likely thatnoticing the existence of some repeated chunks couldincrease participants’ reliance on their implicit knowledge,thus producing a general advantage in performance thatshould not be restricted to the explicit chunks. This hypoth-esis about the modulating role of explicit chunk learninghas the advantage of reconciling the observation of a rela-tively fast learning rate with the absence of the local eVectsthat should be attributed to chunk learning without the needto assume that the whole sequence of 24 items has beenlearned explicitly and almost instantaneously. At the sametime, this modulation hypothesis could contribute to changethe research focus from one centered on solving thedilemma between chunk and statistical learning to anotherone more focused on the analysis of the potential interac-tions that may arise between them. As scientists, we havebeen trained to look for crisp dilemmas and to avoid the un-parsimonious calls for complex interactions. However, cog-nitive science appears to be full of examples indicating thatnature does not always select the clean designer’s view, butthat it Xows perfectly Wne through interactions.
Acknowledgements This research has been supported by theSpanish Ministerio de Educación y Ciencia with grants BSO2003-05095, SEJ2005 25754-E and SEJ2006 27564-E. The author wishes tothank Gustavo Vázquez for his assistance in data collection, and PeterFrensch, Iring Koch, Pierre Perruchet and an anonymous reviewer fortheir thoughtful suggestions on an earlier version of the manuscript.
References
Christiansen, M. H., Allen, J., & Seidenberg, M. S. (1998). Learning tosegment speech using multiple cues: A connectionist model.Language and Cognitive Processes, 13, 221–268.
Cleeremans, A. (1993). Mechanisms of implicit learning: A connec-tionist model of sequence processing. Cambridge: MIT Press.
Frensch, P. A., Buchner, A., & Lin, J. (1994). Implicit learning ofunique and ambiguous serial transitions in the presence andabsence of distractor task. Journal of Experimental Psychology:Learning, Memory, and Cognition, 20, 567–584.
Inquisit 1.33 [Computer software]. (2003). Seattle, WA: MillisecondSoftware L.L.C.
Jiménez, L., Vaquero, J. M. M., & Lupiáñez, J. (2006). QualitativediVerences between implicit and explicit sequence learning.Journal of experimental psychology: Learning, Memory, andCognition, 32, 475–490.
Koch, I., & HoVmann, J. (2000). Patterns, chunks, and hierarchies inserial reaction-time tasks. Psychological Research, 63, 22–35.
Koch, I., Philipp, A. M., & Gade, M. (2006). Chunking in tasksequences modulates task inhibition. Psychological Science, 17,346–350.
Nissen, M. J., & Bullemer, P. (1987). Attentional requirementes oflearning: Evidence from performance measures. CognitivePsychology, 19, 1–32.
123

396 Psychological Research (2008) 72:387–396
Perruchet, P. (2005). Statistical approaches to language acquisition andthe self-organizing consciousness: A reversal of perspective.Psychological Research, 69, 316–329.
Perruchet, P., & Gallego, J. (1997). A subjective unit formationaccount of implicit learning. In D. Berry (Ed.), How implicit isimplicit learning (pp. 124–161). Oxford, UK: Oxford UniversityPress.
Perruchet, P., & Vinter, A. (1998). PARSER: A model for wordsegmentation. Journal of Memory and Language, 39, 246–263.
Perruchet, P., & Vinter, A. (2002). The self-organizing consciousness.Behavioral and Brain Sciences, 25, 297–388.
Perruchet, P., & Pacton, S. (2006). Implicit learning and statisticallearning: One phenomenon, two approaches. Trends in CognitiveSciences, 10, 233–238.
Reed, J., & Johnson, P. (1994). Assessing implicit learning with indi-rect tests: Determining what is learned about sequence structure.Journal of Experimental Psychology: Learning, Memory, andCognition, 20, 585–594.
Sakai, K., Kitaguchi, K., & Hikosaka, O. (2003). Chunking duringhuman visuomotor sequence learning. Experimental BrainResearch, 152, 229–242.
Schneider, D. W. (2007). Task-set inhibition in chunked task sequences.Psychonomic Bulletin and Review (in press).
Servan-Schreiber, E., & Anderson, J. R. (1990). Learning artiWcialgrammars with competitive chunking. Journal of ExperimentalPsychology: Learning, Memory, and Cognition, 16, 592–608.
Stadler, M. A. (1993). Implicit learning: Questions inspired by Hebb(1961). Memory and Cognition 21, 819–827.
Stadler, M. A. (1995). Role of attention in implicit learning. Journal ofExperimental Psychology: Learning, Memory, and Cognition, 21,674–685.
Vaquero, J. M. M., Jiménez, L., & Lupiáñez, J. (2006). The problem ofreversals in assessing sequence learning with serial reaction timetasks. Experimental Brain Research, 175, 97–109.
Verwey, W., & Eikelboom, T. (2003). Evidence for lasting sequencesegmentation in the discrete sequence-production task. Journal ofMotor Behavior, 35, 171–181.
Verwey, W., Lammens, R., & Van Honk, J. (2002). On the role of theSMA in the discrete sequence production task: A TMS study.Neuropsychologia, 40, 1268–1276.
123