taghelper: user’s manual carolyn penstein rosé ([email protected]) carnegie mellon university...
Post on 21-Dec-2015
220 views
TRANSCRIPT

TagHelper:TagHelper:User’s ManualUser’s Manual
Carolyn Penstein RosCarolyn Penstein Rosé é ([email protected])([email protected])Carnegie Mellon UniversityCarnegie Mellon University
Funded through the Pittsburgh Science of Learning Center and The Office of Naval Research, Cognitive and Neural Sciences Division

Copyright 2007, Copyright 2007,
Carolyn Penstein RosCarolyn Penstein Rosé, é,
Carnegie Mellon UniversityCarnegie Mellon University
Licensed under GNU General Public License

Setting Up Your DataSetting Up Your Data

Setting Up Your DataSetting Up Your Data

Creating a Trained ModelCreating a Trained Model

Training and TestingTraining and Testing
Start TagHelper tools by Start TagHelper tools by double clicking on the double clicking on the portal.bat icon in your portal.bat icon in your TagHelperTools2 folderTagHelperTools2 folder
You will then see the You will then see the following tool palletfollowing tool pallet
The idea is that you will train The idea is that you will train a prediction model on your a prediction model on your coded data and then apply coded data and then apply that model to uncoded datathat model to uncoded data
Click on Train New ModelsClick on Train New Models

Loading a FileLoading a FileFirst click on Add a File
Then select a file

Simplest UsageSimplest Usage
Click “GO!”Click “GO!” TagHelper will use its TagHelper will use its
default setting to train default setting to train a model on your a model on your coded examplescoded examples
It will use that model It will use that model to assign codes to the to assign codes to the uncoded examplesuncoded examples
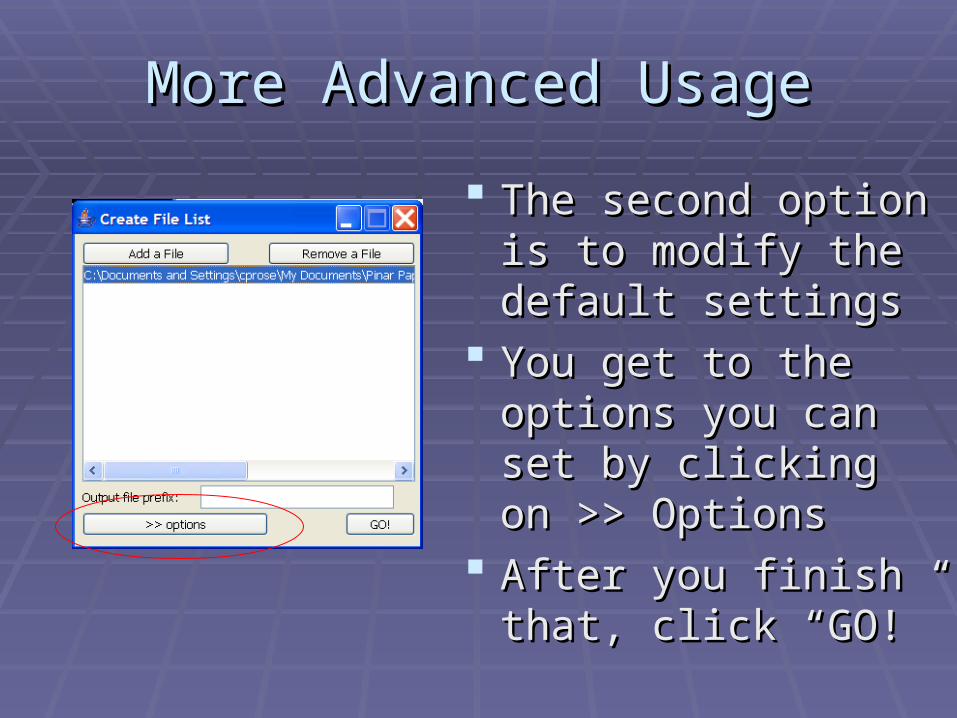
More Advanced UsageMore Advanced Usage
The second option is The second option is to modify the default to modify the default settings settings
You get to the options You get to the options you can set by clicking you can set by clicking on >> Optionson >> Options
After you finish that, After you finish that, click “GO!”click “GO!”

OptionsOptions
Here is where you set Here is where you set the optionsthe options
They are discussed in They are discussed in more detail belowmore detail below

OutputOutput
You can find the output in the OUTPUT You can find the output in the OUTPUT folderfolder
There will be a text file named Eval_[name There will be a text file named Eval_[name of coding dimension]_[name of input file].txtof coding dimension]_[name of input file].txt This is a performance reportThis is a performance report E.g., Eval_Code_SimpleExample.xls.txtE.g., Eval_Code_SimpleExample.xls.txt
There will also be a file named [name of There will also be a file named [name of input file]_OUTPUT.xlsinput file]_OUTPUT.xls This is the coded outputThis is the coded output E.g., SimpleExample_OUTPUT.xlsE.g., SimpleExample_OUTPUT.xls
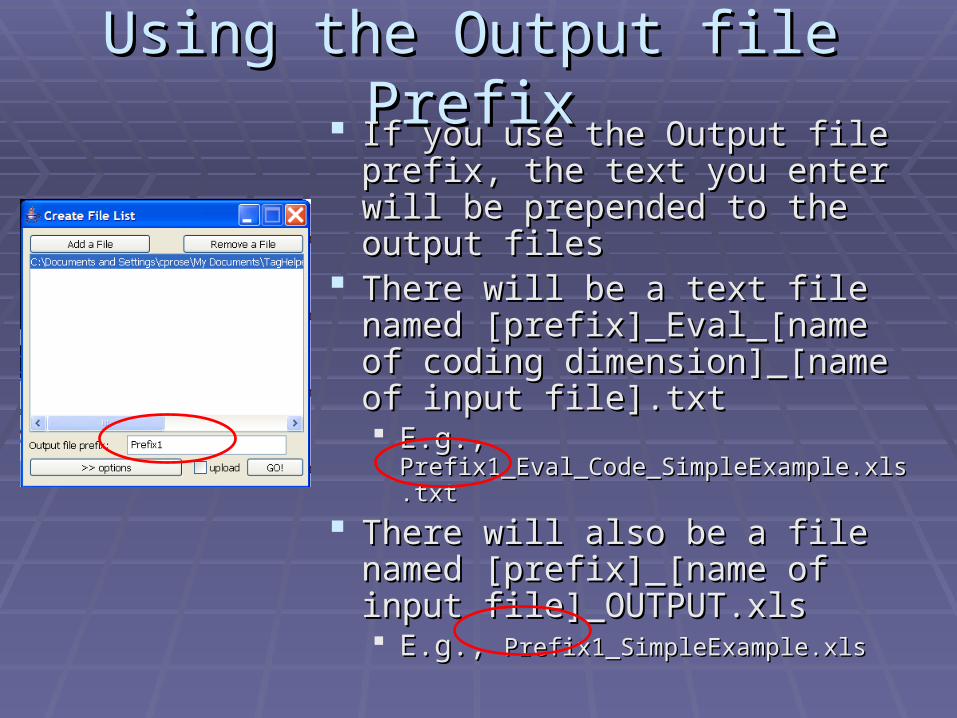
Using the Output file PrefixUsing the Output file Prefix If you use the Output file prefix, If you use the Output file prefix,
the text you enter will be the text you enter will be prepended to the output filesprepended to the output files
There will be a text file named There will be a text file named [prefix]_Eval_[name of coding [prefix]_Eval_[name of coding dimension]_[name of input dimension]_[name of input file].txtfile].txt E.g., E.g.,
Prefix1_Eval_Code_SimpleExample.xls.txtPrefix1_Eval_Code_SimpleExample.xls.txt
There will also be a file named There will also be a file named [prefix]_[name of input [prefix]_[name of input file]_OUTPUT.xlsfile]_OUTPUT.xls E.g., E.g., Prefix1_SimpleExample.xlsPrefix1_SimpleExample.xls

Evaluating PerformanceEvaluating Performance

Performance reportPerformance report
The performance report tells you:The performance report tells you: What dataset was usedWhat dataset was used

Performance reportPerformance report
The performance report tells you:The performance report tells you: What dataset was usedWhat dataset was used What the customization settings wereWhat the customization settings were

Performance reportPerformance report
The performance report tells you:The performance report tells you: What dataset was usedWhat dataset was used What the customization settings wereWhat the customization settings were At the bottom of the file are reliability statistics and a At the bottom of the file are reliability statistics and a
confusion matrix that tells you which types of errors are confusion matrix that tells you which types of errors are being madebeing made

Output FileOutput File The output file The output file
containscontains The codes for each The codes for each
segmentsegment Note that the Note that the
segments that were segments that were already coded will already coded will retain their original retain their original codecode
The other segments The other segments will have their will have their automatic predictionsautomatic predictions
The prediction The prediction column indicates the column indicates the confidence of the confidence of the predictionprediction

Using a Trained ModelUsing a Trained Model

Applying a Trained ModelApplying a Trained Model
Select a Select a model filemodel file
Then select Then select a testing a testing filefile

Applying a Trained ModelApplying a Trained Model
Testing data should be set up with ? on Testing data should be set up with ? on uncoded examplesuncoded examples
Click Go! to process fileClick Go! to process file

ResultsResults

Overview of Basic Feature Overview of Basic Feature Extraction from TextExtraction from Text
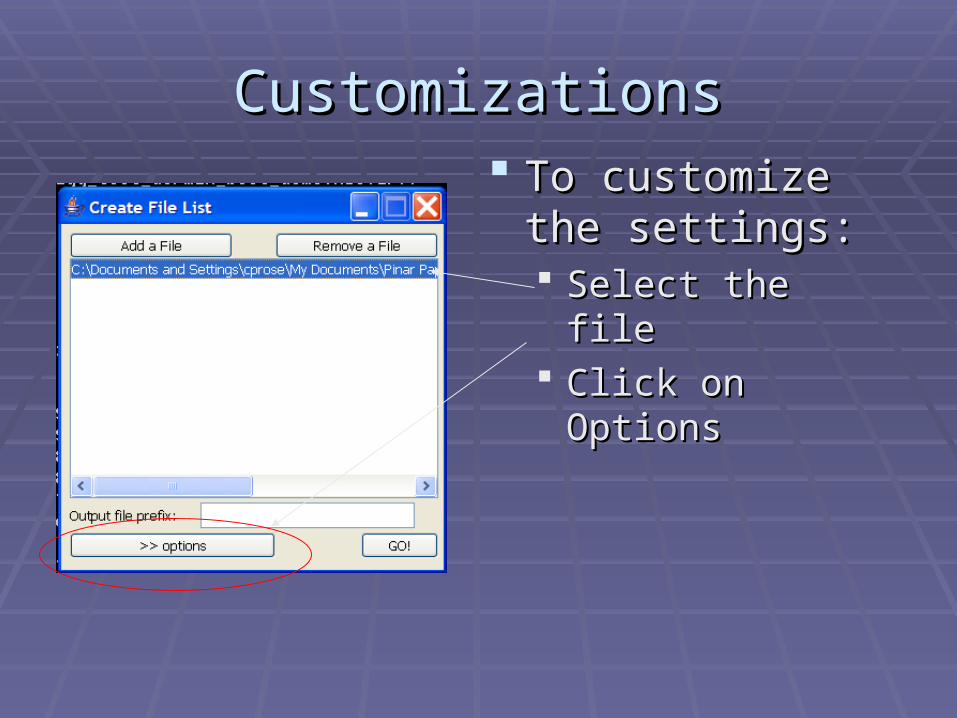
CustomizationsCustomizations To customize the To customize the
settings:settings: Select the file Select the file Click on OptionsClick on Options

Setting the LanguageSetting the Language
You can change thedefault language fromEnglish to German
Chinese requires anadditional license to Academia Sinica inTaiwan

Preparing to get a performance Preparing to get a performance reportreport
You can decidewhether youwant it to preparea performancereport for you.(It runs faster when this is disabled.)

Classifier OptionsClassifier Options
Rules of thumb:Rules of thumb: SMO is state-of-the-art for SMO is state-of-the-art for
text classificationtext classification J48 is best with small J48 is best with small
feature sets – also handles feature sets – also handles contingencies between contingencies between features wellfeatures well
Naïve Bayes works well for Naïve Bayes works well for models where decisions are models where decisions are made based on made based on accumulating evidence accumulating evidence rather than hard and fast rather than hard and fast rulesrules

Basic IdeaBasic Idea
Represent text as a vector Represent text as a vector where each position where each position
corresponds to a termcorresponds to a term
This is called the “bag of words” This is called the “bag of words” approachapproach
Cows make cheeseCows make cheese110001110001
Hens lay eggsHens lay eggs001110001110
CheeseCowsEggsHensLayMake

What can’t you conclude from “bag What can’t you conclude from “bag of words” representations?of words” representations?
Causality:Causality: “ “X caused YX caused Y” versus “” versus “Y caused XY caused X””
Roles and Mood:Roles and Mood: “ “Which person ate the food Which person ate the food that I prepared this morning and drives the big that I prepared this morning and drives the big car in front of my catcar in front of my cat” versus “” versus “The person, which The person, which prepared food that my cat and I ate this morning, prepared food that my cat and I ate this morning, drives in front of the big cardrives in front of the big car.”.” Who’s driving, who’s eating, and who’s preparing Who’s driving, who’s eating, and who’s preparing
food?food?
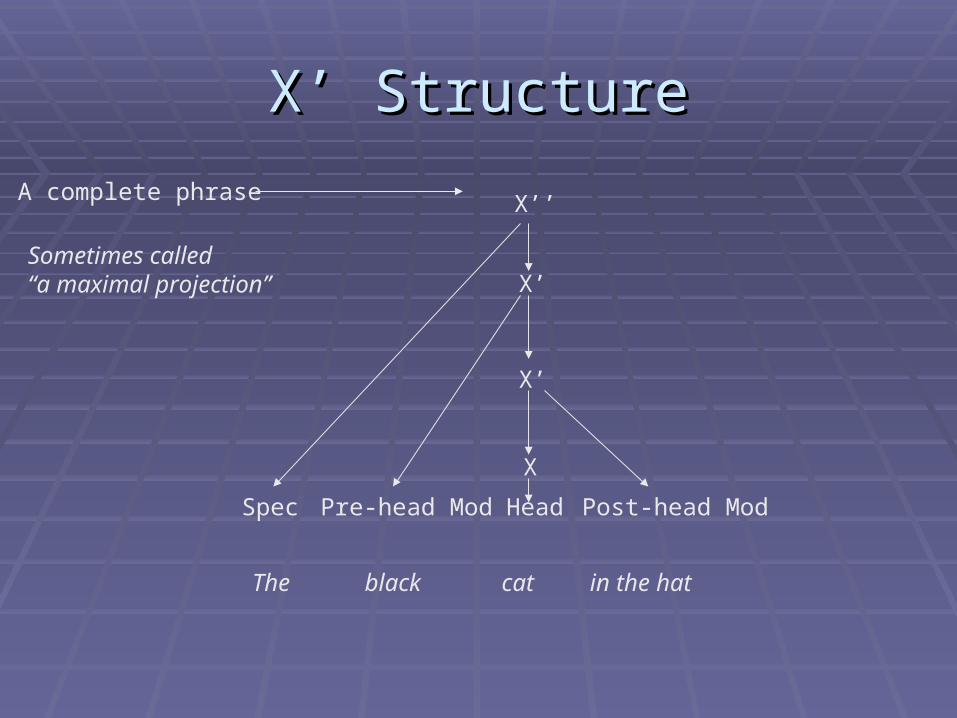
X’ StructureX’ Structure
X’’
X’
X
Pre-head ModSpec Post-head Mod
X’
Head
The black cat in the hat
A complete phrase
Sometimes called “a maximal projection”

Basic Anatomy: Layers of Basic Anatomy: Layers of Linguistic AnalysisLinguistic Analysis
PhonologyPhonology: The sound structure of language: The sound structure of language Basic sounds, syllables, rhythm, intonationBasic sounds, syllables, rhythm, intonation
MorphologyMorphology: The building blocks of words: The building blocks of words Inflection: tense, number, genderInflection: tense, number, gender Derivation: building words from other words, transforming part of Derivation: building words from other words, transforming part of
speechspeech SyntaxSyntax: Structural and functional relationships between : Structural and functional relationships between
spans of text within a sentencespans of text within a sentence Phrase and clause structurePhrase and clause structure
SemanticsSemantics: Literal meaning, propositional content: Literal meaning, propositional content PragmaticsPragmatics: Non-literal meaning, language use, language : Non-literal meaning, language use, language
as action, social aspects of language (tone, politeness)as action, social aspects of language (tone, politeness) Discourse AnalysisDiscourse Analysis: Language in practice, relationships : Language in practice, relationships
between sentences, interaction structures, discourse between sentences, interaction structures, discourse markers, anaphora and ellipsismarkers, anaphora and ellipsis

Part of Speech TaggingPart of Speech Tagging
1. CC Coordinating conjunction
2. CD Cardinal number 3. DT Determiner 4. EX Existential there 5. FW Foreign word 6. IN Preposition/subord 7. JJ Adjective 8. JJR Adjective,
comparative 9. JJS Adjective, superlative 10.LS List item marker 11.MD Modal
12.NN Noun, singular or mass
13.NNS Noun, plural 14.NNP Proper noun,
singular 15.NNPS Proper noun, plural 16.PDT Predeterminer 17.POS Possessive ending 18.PRP Personal pronoun 19.PP Possessive pronoun 20.RB Adverb 21.RBR Adverb, comparative 22.RBS Adverb, superlative
http://www.ldc.upenn.edu/Catalog/docs/treebank2/cl93.html

Part of Speech TaggingPart of Speech Tagging
23.RP Particle
24.SYM Symbol 24.SYM Symbol
25.TO to 25.TO to
26.UH Interjection 26.UH Interjection
27.VB Verb, base form 27.VB Verb, base form
28.VBD Verb, past tense 28.VBD Verb, past tense
29.VBG Verb, 29.VBG Verb, gerund/present participle gerund/present participle
30.VBN Verb, past participle 30.VBN Verb, past participle
31.VBP Verb, non-3rd ps. 31.VBP Verb, non-3rd ps. sing. present sing. present
32.VBZ Verb, 3rd ps. sing. 32.VBZ Verb, 3rd ps. sing. present present
33.WDT wh-determiner 33.WDT wh-determiner
34.WP wh-pronoun 34.WP wh-pronoun
35.WP Possessive wh-35.WP Possessive wh-pronoun pronoun
36.WRB wh-adverb 36.WRB wh-adverb
http://www.ldc.upenn.edu/Catalog/docs/treebank2/cl93.html

TagHelper CustomizationsTagHelper Customizations
Feature Space DesignFeature Space Design Think like a computer!Think like a computer! Machine learning algorithms look Machine learning algorithms look
for features that are good for features that are good predictors, not features that are predictors, not features that are necessarily meaningfulnecessarily meaningful
Look for approximationsLook for approximations If you want to find questions, you If you want to find questions, you
don’t need to do a complete syntactic don’t need to do a complete syntactic analysisanalysis
Look for question marksLook for question marks Look for wh-terms that occur Look for wh-terms that occur
immediately before an auxilliary verbimmediately before an auxilliary verb

TagHelper CustomizationsTagHelper Customizations
Feature Space DesignFeature Space Design Punctuation can be a “stand in” for Punctuation can be a “stand in” for
moodmood ““you think the answer is 9?”you think the answer is 9?” ““you think the answer is 9.”you think the answer is 9.”
Bigrams capture simple lexical Bigrams capture simple lexical patternspatterns ““common denominator” versus common denominator” versus
“common multiple”“common multiple” POS bigrams capture syntactic or POS bigrams capture syntactic or
stylistic informationstylistic information ““the answer which is …” vs “which the answer which is …” vs “which
is the answer”is the answer” Line length can be a proxy for Line length can be a proxy for
explanation depthexplanation depth

TagHelper CustomizationsTagHelper Customizations
Feature Space DesignFeature Space Design Contains non-stop word can be a Contains non-stop word can be a
predictor of whether a predictor of whether a conversational contribution is conversational contribution is contentfulcontentful ““ok sure” versus “the common ok sure” versus “the common
denominator”denominator” Remove stop words removes some Remove stop words removes some
distracting featuresdistracting features Stemming allows some Stemming allows some
generalizationgeneralization Multiple, multiply, multiplicationMultiple, multiply, multiplication
Removing rare features is a cheap Removing rare features is a cheap form of feature selectionform of feature selection Features that only occur once or Features that only occur once or
twice in the corpus won’t twice in the corpus won’t generalize, so they are a waste of generalize, so they are a waste of time to include in the vector spacetime to include in the vector space

Group ActivityGroup ActivityUse TagHelper features to make up rules to identify thematic Use TagHelper features to make up rules to identify thematic
roles in these sentences?roles in these sentences?
Agent:Agent: who is doing the action who is doing the action Theme:Theme: what the action is what the action is
done todone to Recipient:Recipient: who benefits from who benefits from
the actionthe action Source:Source: where the theme where the theme
startedstarted Destination:Destination: where the theme where the theme
ended upended up Tool:Tool: what the agent used to what the agent used to
do the action to the themedo the action to the theme Manner:Manner: how the agent how the agent
behaved while doing the actionbehaved while doing the action
1. The man chased the intruder.
2. The intruder was chased by the man.
3. Aaron carefully wrote a letter to Marilyn.
4. Marilyn received the letter.
5. John moved the package from the table to the sofa.
6. The governor entertained the guests in the parlor.

New Feature CreationNew Feature Creation

Why create new features?Why create new features?
You may want to generalize across sets of You may want to generalize across sets of related wordsrelated words ColorColor = {red,yellow,orange,green,blue} = {red,yellow,orange,green,blue} FoodFood = {cake,pizza,hamburger,steak,bread} = {cake,pizza,hamburger,steak,bread}
You may want to detect contingenciesYou may want to detect contingencies The text must mention both The text must mention both cakecake and and
presentspresents in order to count as a birthday party in order to count as a birthday party You may want to combine theseYou may want to combine these
The text must include a The text must include a ColorColor and a and a FoodFood

Why create new features by hand?Why create new features by hand?
RulesRules For simple rules, it might be easier and faster For simple rules, it might be easier and faster
to write the rules by hand instead of learning to write the rules by hand instead of learning them from examplesthem from examples
FeaturesFeatures More likely to capture meaningful More likely to capture meaningful
generalizationsgeneralizations Build in knowledge so you can get by with Build in knowledge so you can get by with
less training dataless training data

Rule LanguageRule Language
ANY() is used to create listsANY() is used to create lists COLOR = ANY(red,yellow,green,blue,purple)COLOR = ANY(red,yellow,green,blue,purple) FOOD = ANY(cake,pizza,hamburger,steak,bread)FOOD = ANY(cake,pizza,hamburger,steak,bread)
ALL() is used to capture contingenciesALL() is used to capture contingencies ALL(cake,presents)ALL(cake,presents)
More complex rulesMore complex rules ALL(COLOR,FOOD)ALL(COLOR,FOOD)

Group Project: Group Project: Make a rule that will match against Make a rule that will match against
questions but not statementsquestions but not statements
Question Tell me what your favorite color is.
Statement I tell you my favorite color is blue.
Question Where do you live?
Statement I live where my family lives.
Question Which kinds of baked goods do you prefer
Statement I prefer to eat wheat bread.
Question Which courses should I take?
StatementYou should take my applied machine learning course.
Question Tell me when you get up in the morning.
Statement I get up early.

Possible RulePossible Rule
ANY(ALL(tell,me),BOL_WDT,BOL_WRB)ANY(ALL(tell,me),BOL_WDT,BOL_WRB)

Advanced Feature EditingAdvanced Feature Editing
* For small datasets, first deselect Remove rare features.
* Click on Adv Feature Editing

Types of Basic FeaturesTypes of Basic Features Primitive features Primitive features
inclulde unigrams, inclulde unigrams, bigrams, and POS bigrams, and POS bigramsbigrams

Types of Basic FeaturesTypes of Basic Features The Options change The Options change
which primitive features which primitive features show up in the Unigram, show up in the Unigram, Bigram, and POS bigram Bigram, and POS bigram listslists You can choose to remove You can choose to remove
stopwords or notstopwords or not You can choose whether or You can choose whether or
not to strip endings off not to strip endings off words with stemmingwords with stemming
You can choose how You can choose how frequently a feature must frequently a feature must appear in your data in appear in your data in order for it to show up in order for it to show up in your listsyour lists

Types of Basic FeaturesTypes of Basic Features
* Now let’s look at how to createnew features.

Creating New FeaturesCreating New Features
*The feature editor allows you to createnew feature definitions
* Click on + to add your new feature

Examining a New FeatureExamining a New Feature
•Right click on a feature toexamine where it matches inyour data

Examining a New FeatureExamining a New Feature

Adding new features by scriptAdding new features by script
Modify the ex_features.txt fileModify the ex_features.txt file Allows you to save your definitionsAllows you to save your definitions Easier to cut and pasteEasier to cut and paste

Error AnalysisError Analysis

Create an Error Analysis FileCreate an Error Analysis File

Use TagHelper to Code Uncoded Use TagHelper to Code Uncoded FileFile
•The output file containsthe codes TagHelperassigned.
•What you want to do now is to remove prediction column and insert the correct answers next tothe TagHelper assignedanswers.

Load Error Analysis FileLoad Error Analysis File

Error Analysis StrategiesError Analysis Strategies
Look for large error cells in the confusion Look for large error cells in the confusion matrixmatrix
Locate the examples that correspond to Locate the examples that correspond to that cellthat cell
What features do those examples share?What features do those examples share? How are they different from the examples How are they different from the examples
that were classified correctly?that were classified correctly?

Group ProjectGroup Project From NewGroupTopic.xls create NewsGroupTrain.xls, From NewGroupTopic.xls create NewsGroupTrain.xls,
NewsGroupTest.xls, and NewsGroupAnswers.xlsNewsGroupTest.xls, and NewsGroupAnswers.xls
Load in the NewsGroupTrain.xls data setLoad in the NewsGroupTrain.xls data set What is the best performance you can get by playing with What is the best performance you can get by playing with
the standard TagHelper tools feature options?the standard TagHelper tools feature options? Train a model using the best settings and then use it Train a model using the best settings and then use it
to assign codes to NewsGroupTest.xlsto assign codes to NewsGroupTest.xls Copy in Answer column from NewsGroupAnswers.xlsCopy in Answer column from NewsGroupAnswers.xls Now do an error analysis to determine why frequent Now do an error analysis to determine why frequent
mistakes are being mademistakes are being made How could you do better?How could you do better?

Feature SelectionFeature Selection

Why do irrelevant features hurt Why do irrelevant features hurt performance?performance?
They might confuse a classifierThey might confuse a classifier They waste timeThey waste time

Two SolutionsTwo Solutions
Use a feature selection algorithmUse a feature selection algorithm Only extract a subset of possible featuresOnly extract a subset of possible features

Feature SelectionFeature Selection
* Click on the AttributeSlectedClassifier
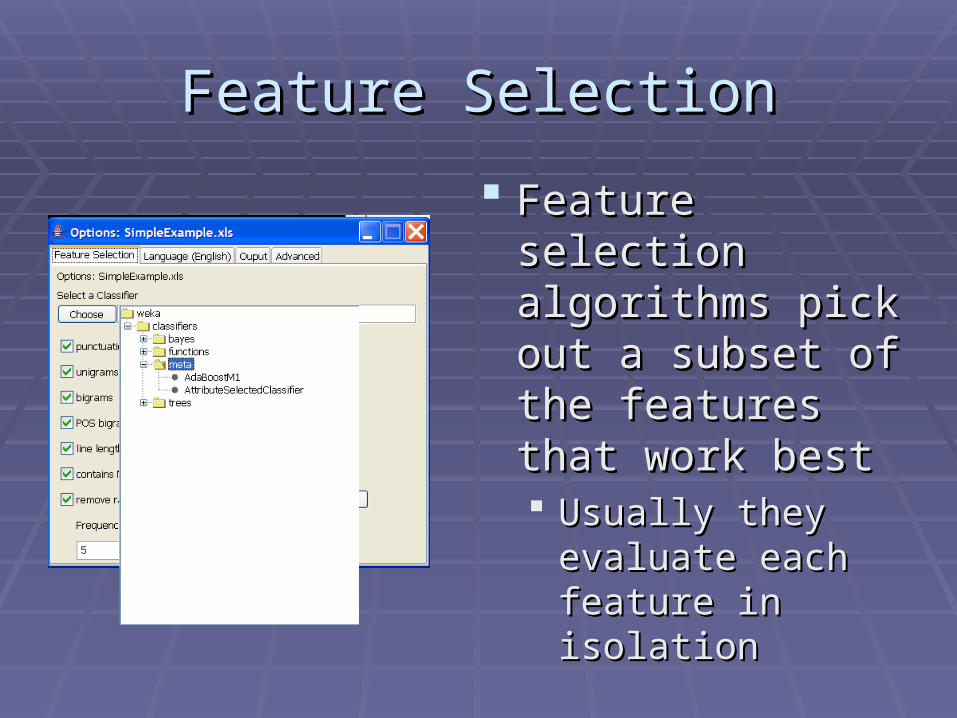
Feature SelectionFeature Selection
Feature selection Feature selection algorithms pick out a algorithms pick out a subset of the subset of the features that work features that work bestbest Usually they evaluate Usually they evaluate
each feature in each feature in isolationisolation
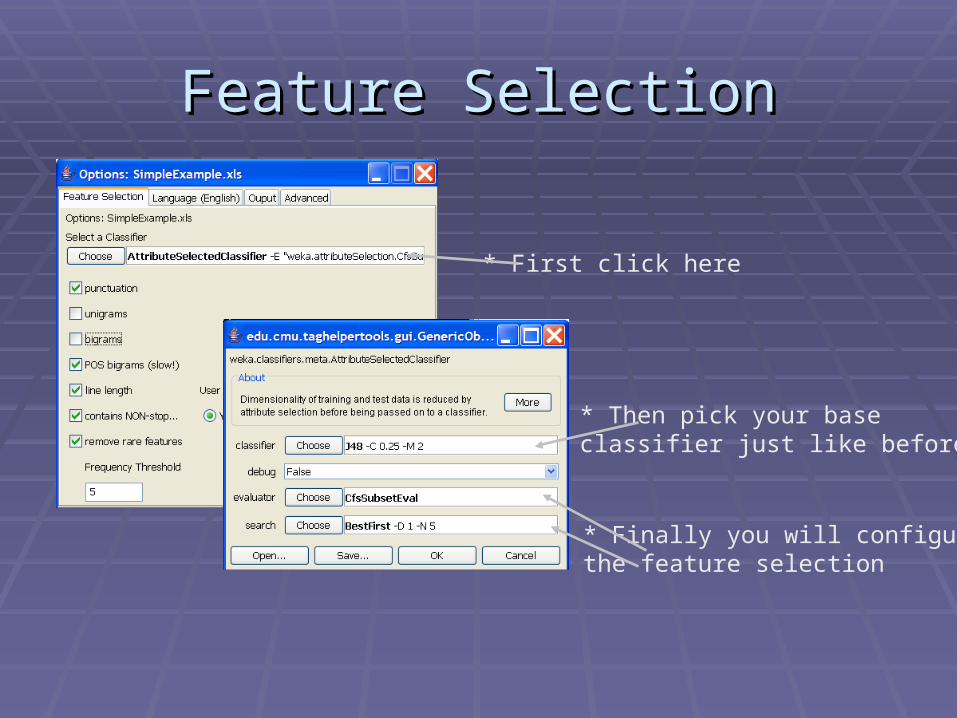
Feature SelectionFeature Selection
* First click here
* Then pick your baseclassifier just like before
* Finally you will configurethe feature selection
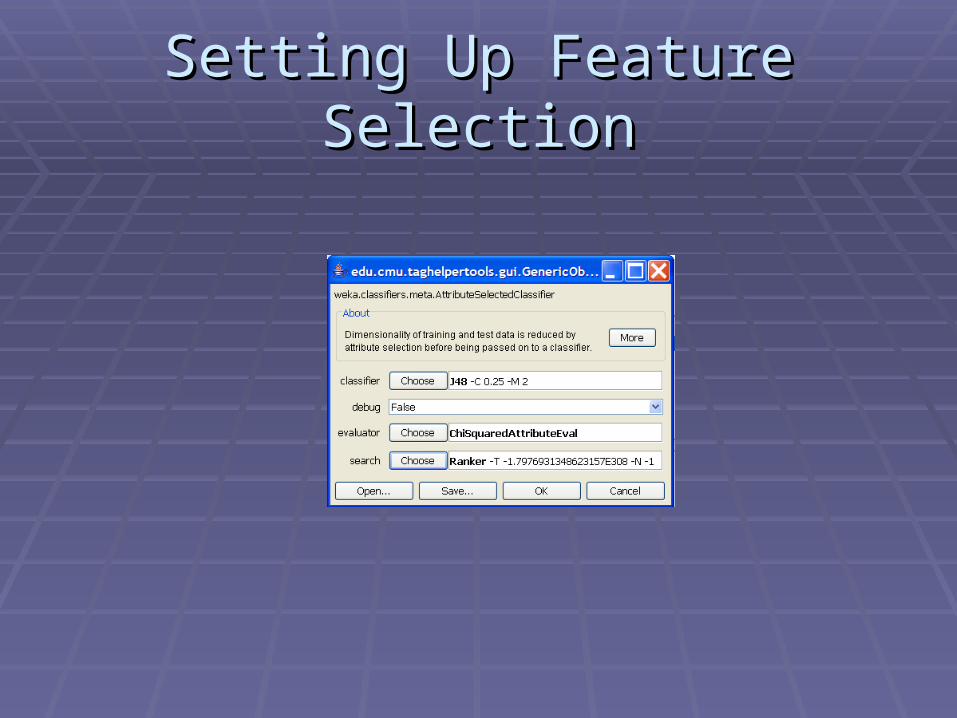
Setting Up Feature SelectionSetting Up Feature Selection

Setting Up Feature SelectionSetting Up Feature Selection
The number of The number of features you pick features you pick should not be larger should not be larger than the number of than the number of features availablefeatures available
The number should The number should not be larger than not be larger than the number of coded the number of coded examples you haveexamples you have

Examining Which Features are Examining Which Features are Most PredictiveMost Predictive
You can find a You can find a ranked list of ranked list of features in the features in the Performance Performance Report if you use Report if you use feature selectionfeature selection
* Predictiveness score
* Frequency

OptimizationOptimization

Key idea:Key idea:combine multiple views on the combine multiple views on the
same data in order to same data in order to increase reliabilityincrease reliability

BoostingBoosting
In boosting, a series of models are trained and In boosting, a series of models are trained and each trained model is influenced by the each trained model is influenced by the strengths and weaknesses of the previous strengths and weaknesses of the previous modelmodel New models should be experts in classifying New models should be experts in classifying
examples that the previous model got wrongexamples that the previous model got wrong
It specifically seeks to train multiple models that It specifically seeks to train multiple models that complement each othercomplement each other
In the final vote, model predictions are weighted In the final vote, model predictions are weighted based on their model’s performancebased on their model’s performance

More about BoostingMore about Boosting
The more iterations, the more confident The more iterations, the more confident the trained classifier will be in its the trained classifier will be in its predictions predictions But higher confidence doesn’t necessarily But higher confidence doesn’t necessarily
mean higher accuracy!mean higher accuracy! When a classifier becomes overly confident, it When a classifier becomes overly confident, it
is said to “over fit”is said to “over fit” Boosting can turn a weak classifier into a Boosting can turn a weak classifier into a
strong classifierstrong classifier A simple classifier can learn a complex ruleA simple classifier can learn a complex rule

BoostingBoosting
Boosting is an Boosting is an option listed in the option listed in the Meta folder, near Meta folder, near the Attribute the Attribute Selected ClassifierSelected Classifier
It is listed as It is listed as AdaBoostM1AdaBoostM1
Go ahead and click Go ahead and click on it nowon it now

BoostingBoosting
* Now click here

Setting Up BoostingSetting Up Boosting
* Select a classifier
* Set the number of cycles ofboosting

Semi-Supervised Semi-Supervised LearningLearning

Using Unlabeled DataUsing Unlabeled Data
If you have a small amount of labeled data If you have a small amount of labeled data and a large amount of unlabeled data:and a large amount of unlabeled data: you can use a type of bootstrapping to learn a you can use a type of bootstrapping to learn a
model that exploits regularities in the larger model that exploits regularities in the larger set of data set of data
The stable regularities might be easier to spot The stable regularities might be easier to spot in the larger set than the smaller setin the larger set than the smaller set
Less likely to overfit your labeled dataLess likely to overfit your labeled data

Semi-supervised LearningSemi-supervised Learning
Remember the Basic idea:Remember the Basic idea: Train on a small amount of dataTrain on a small amount of data Add the positive and negative example you Add the positive and negative example you
are most confident about to the training dataare most confident about to the training data RetrainRetrain Keep looping until you label all the dataKeep looping until you label all the data

Semi-supervised learning in Semi-supervised learning in TagHelper toolsTagHelper tools