superpixels generating from the pixel-based k-means clustering · superpixels generating from the...
TRANSCRIPT

Journal of Multimedia Processing and Technologies Volume 6 Number 3 September 2015 77
Superpixels Generating from the Pixel-based K-Means Clustering
Shang-Chia Wei, Tso-Jung YenInstitute of Statistical ScienceAcademia SinicaTaipei, Taiwan 11529, [email protected], [email protected]
ABSTRACT: Image segmentation is a basic but important preprocessing to image recognition in computer vision applications.In this paper, we propose a pixel-based k-means (PKM) clustering to generate superpixels, which comprise many pixels withsimilar colors and neighbor positions. In contrast with conventional center-based clustering, the PKM method traces severalnearer clustering centers for a pixel in advance, and then the pixel find the highest similar colors as its clustering center.Besides, we adopt the regional clustering of the SLIC (Simple Linear Iterative Clustering) in the PKM method to improve theperformance of image segmentations. The MSRC dataset is used to quantitatively compare the PKM with the SLIC performances,such as under-segmentation errors, boundary recall, detection precision, and computation efficiency.
Keywords: Superpixels, Image Segmentation, Clustering, Pixel-based K-means
Received: 10 June 2015, Revised 9 July 2015, Accepted 14 July 2015
© 2015 DLINE. All Rights Reserved
1. Introduction
Superpixel representation is a kind of dimensionality reduction technique in computer vision applications. The technique formssignificant blocks of image pixels across row or column space. Thus the technique supports feature selection or saliencyextraction for an image or a video [1]-[4]. Since a region of an image has color and location similarities, the region, called asuperpixel is displayed by a single color, averaging out the colors in the region. In comparison the original image with superpixelimage, we expect that there are a few differences, which is not influenced on subsequent image processing algorithms, such assalient detection, tracking, etc.
Superpixel algorithm is able to divide an image into few pieces (viz. under-segmentation) or redundant pieces (viz. over-segmentation). An image with under-segmentation maybe causes noises like textures, shadows, or lighting conditions occurringin some image segments. In contrast, images with appropriate over-segmentation perhaps preserve boundaries of salientfeatures, and then eliminate noise, improve inner object definition, or smooth image lighting for explicit saliency detection. Thus,an excellent superpixel algorithm should define correct but excess boundaries to magnify partial salient features through a fineover-segmentation preprocessing.

78 Journal of Multimedia Processing and Technologies Volume 6 Number 3 September 2015
Superpixel is generated from two main clustering methods, one of which is graph-based algorithms and another is gradient-ascent-based algorithms [5]-[7]. In the graph-based algorithms, each pixel is regarded as a node, and the similarity between twoneighbor pixels represents the weight of an edge linking two nodes. The algorithms intend to maximize linkage of pixels (viz.superpixel) over the graph. For the gradient-ascent-based algorithms, arbitrary image pixels as starting points are iterativelyrefined into clustering centers according to some convergence criterion. Then, image pixels are partitioned off into superpixels bythe refined clustering centers. However, there are still poor boundary adherence and slow computation time in these superpixelalgorithms.
In the recent superpixel algorithms, SLIC (Simple Linear Iterative Clustering) [6] having extremely fast convergence is a fine over-segmentation method, which preserves pixel blocks in salient features of a tracing object. The SLIC method can reduce not only thecomplexity of image segmentations by pixel-positioned clustering, but also smooth the noises (e.g., lighting, refraction, shadow, snow,etc.) by uniform color level within image boundaries. Experiment result indicated that the SLIC rivals the other advanced superpixelalgorithms based on MSRC (Microsoft Research Cambridge) image database.
In a conventional SLIC the data clustering method is implemented by k-means algorithm within a grid region. However, the k-meansalgorithm is a center-based clustering algorithm whose performance (MSE) hinges upon the initialization of the centers and thetradeoff between color and spatial proximity [8]. The k-means algorithm is sensitive to initial clustering data points and is uncertain ofthe area of spatial search with the color-coordinated tolerance. For the reason, the initialization of clustering centers and the relationbetween centers and pixels of each search space are discussed in the paper.
In this work, we propose to compute the boundaries of superpixels to portray image over-segmentation in an image plane using pixel-based k-means (PKM) clustering. In sections 2, we explain the differences between center-based and pixel-based k-means clustering.Then, section 3 presents the experimental design for the PKM method while the experiment results with discussed visual object datasetare given in section 4. Finally, conclusion is drawn in section 5.
2. Pixel-based K-means Clustering
A conventional k-means method involves spatially blind and center-based clustering in certain parameter spaces, such asfeatures or attributes [4], [9], [10]. However, each pixel of an image is represented by a 5-dimensional feature vector. Superpixelalgorithm is used for pixel clusters with similar color value (CIE l, a, b) and neighbor location in two-dimensional (x, y) image space.Thus, we suppose that the superpixel representation is 2-D partitioned clustering problem, which aims to minimize the colordifferences among clustered pixels in a superpixel.
The k-means method usually depends on the current partitioned centers (C1,…,Ck) to cluster all objects (viz. pixels). Ourapproach is different from the center-based k-means method and has two steps. 1) We first detect b centers (C1,…,Cb; b < k) thatare closer to pixel i based on Euclidean-distance (Eq. (1)).
{ ( C1,...Cj...,Cb) | Pi C1 < ... < Pi Cj<... < Pi Cb<...< Pi Ck},
where Pi Cj = ( xj- xi ) 2 + ( yj- yi )
2 . (1)
2) Then pixel i is assigned into one of the b neighbor centers according to fine color proximity, di,j So, our approach is calledpixel-based k-means (PKM) clustering, which performance from pixel to center is based upon the Euclidean-distance-basedmeasure, where the distance, di,j indicates the color difference between pixel i and center-pixel j as below:
di,j = ( lj- li ) 2 + (aj- ai )
2 + (bj- bi ) 2 . (2)
Based on Equation. (2), the mathematical formation of the 2-D image segmentation clustering problem can be described asfollows:

Journal of Multimedia Processing and Technologies Volume 6 Number 3 September 2015 79
Min E = ( di ) = ( min di ,j ) . (3)N
i = 1 j = 1
b
i = 1
N
where N is the number of image pixels, b is the number of neighbor current centers close to clustered pixel i.
For optimization problem shown in Eq. (3), we generate initial partitioned centers (C1,…,Ck) and each pixel had been associatedto nearer b cluster centers. Then, an update step in Eq. (4), that is, iterative gradient descent will keep adjusting the clustercenters to be the mean Cj=[x, y, l, a, b] vector of all the pixels Pi= [x, y, l, a, b] belonging to the superpixel (viz. pixel cluster) untilthe total color difference E (Equation. (3)) converges on an acceptable threshold. Finally, a post-processing step will join trivialpixels to nearby superpixels. The pixel-based k-means clustering is summarized as below.
C jnew = .
∑ Ij ( i ) × Pi
Ij ( i ).
, where Ij ( i ) = .{1, pixel i ∈center j .0, o.w. (4)
i = 1N
i = 1N
Algorithm: Pixel-based K-Means (PKM) clustering
I Original image (Matrix of having N pixels)
O Super-pixel image (Matrix of having k super-pixels)
1: Initialize k cluster centers C k×5
= [l, a, b, x, y]k×5
2:repeat
3: for each pixel Pi do
4: Find b neighbor centers Cj close to pixel P
i (Equation.(1));
5: for each neighbor center (C1,..C
j.., C
b) do
6: Computer di,j
between pixel i and center j;
7: Find center j with minimal di, j
(Equation.(2));
8: set d (i)= di, j
;
9: set pixel i ∈ center j;10: end for
11: end for
12: Update new cluster centers (Equation.(4));
13: Compute total color difference E (Equation.(3));
14: until E < threshold or attained maximal iterations
Table 1. Pseudo code for the PKM clustering
3. Experimental Design for PKM
We examined the PKM with different initial methods, the number of neighbor centers and post-processing methods to verify thequality of PKMs by under segmentation error (USE), boundary recall and boundary precision. All optimization computationswere performed on an Intel Core i7 3.4GHz PC with 16 GB memory. We used the MS Windows 7 operating system and theMATLAB® 2013b compiler.
3.1 The Quality of Superpixel AlgorithmFor evaluation of segmentation quality, under segmentation error (USE), boundary recall and boundary precision are standardmeasures for boundary adherence. A superpixel algorithm should adhere to the three error metrics. Under segmentation error

80 Journal of Multimedia Processing and Technologies Volume 6 Number 3 September 2015
(USE) is able to measure the overlap between superpixels and ground truth segments. In [6], the USE formula requires that anoverlap of a superpixel and the ground truth is at least 5% of the superpixel size. There is a serious penalty for large superpixels.For this reason, this study adopts a new USE [11] that is defined as below.
use = [ ( min (pin , pout) ) ] (5) 1
N s GT P | P s
where N denotes the total number of pixels, and an in-part Pin and an out-part Pout from a superpixel P is divided by a segmentS of ground truth GT border.
For the rest of boundary performances, boundary recall is the proportion of true positive pixels to ground truth edges within acertain tolerance of pixel d. Boundary precision is the proportion of true positive pixels to superpixel boundary within a certaintolerance d. The true positive pixels means that the number of edge pixels in ground truth for whose exist a boundary pixel ofsuperpixels in range d. In this work, the tolerance of pixel is set to 2.
Figure 1. Illustration of superpixel boundary, ground truth edge and true positives
3.2 InitializationArgyle pattern and grid pattern are used to initialize k starting points (viz. clustering centers) for the PKM (Figure. 2). The twoinitializations resulted from the Forgy and random partition methods [12]. In the initialization of the PKM argyle pattern and gridpattern would generate k* centers that uniformly spread out over the 2-D image space. If k* is less than k, the shortage ofcenters will be generated at random.
0
240
0
0
320(b) Grid Pattern
Random Point
(a) Argyle Pattern
240
0320
Figure 2. Illustration of argyle pattern and grid pattern

Journal of Multimedia Processing and Technologies Volume 6 Number 3 September 2015 81
3.3 Post-processing MethodsThe clustering procedure of PKM and SLIC would generate superpixels with some trivial pixels in anfractuous boundary or verysmall pixels within a complete superpixel. To correct for this inadequacy, such pieces of trivial pixels are reassigned the label ofthe neighbor superpixels according to 1) adjoining frequency or 2) color similarity (Figure. 3). Besides, the 4-connected componentsalgorithms would be implemented in PKM and SLIC.
Superpixel-pink
Superpixel-green
Trivalpixels- lihtgreen
Figure 3. Illustration of adjoining frequency f and color similarity s of connecting neighbor superpixels4. Experiment Analysis
We experimented the three main effects, namely the number of neighbor center (nbor), initialization methods (initial) and post-processing methods (postp), to analyze performances for PKM. The performances, USE, boundary recall and precision describedin [11]; sixteen original images and high-quality ground-truths obtained on the MSRC image dataset [8] using the method.Considering multiple effects of PKM, we performed a full experimental design (three-way ANOVA) for 5 levels in nbor, 2 levelsin initial and 2 levels in postp. In the formulation of SLIC [6], when the weight, m is large, spatial proximity is more important; tothe contrary, color proximity is more important. The weight m is regarded as a vital factor of the SLIC. Thus, we also performeda full experimental design (two-way ANOVA) for 3 levels in weight m and 2 levels in postp.
For PKM and SLIC based on k-means clustering, the n-iterative gradient descent method with an initialization almost convergeson the same clustering solution. Thus, there is only one observation (viz. clustering solution) per treatment. Interaction effectbetween two or three factors cannot be measured in two- or three-way ANOVA without replication (single observation). In theUSE using the PKM for 32 superpixels (TABLE 2), the output vector [6 2 4] of MAIN effects represents 6 significant results for 1st
effect (nbor), 2 significant results for 2nd effect (initial) and 4 significant results for 3rd effect (postp). For the robust performance,the number of significant results of main or interaction effect should be more than the half of total testing numbers (16 high-quality ground-truth images).
USE B-Recall B-PrecisionKc Effect
p<0.05 Effect p<0.05 Effect p<0.05 Effect
32 MAINa [6 2 4] - [6 3 3] - [9 5 7] 1 INTERb [2 1 0] - [2 0 0] - [4 3 0] -64 MAIN [9 3 7] 1 [11 3 4] 1 [9 1 7] 1
INTER [2 2 1] - [4 0 0] - [1 1 0] -128 MAIN [13 7 6] 1 [10 3 5] 1 [14 3 8] 1, 3
INTER [3 2 2] - [4 2 1] - [3 2 1] -256 MAIN [15 2 7] 1 [14 1 8] 1, 3 [13 3 5] 1
INTER [1 1 0] - [6 2 1] - [3 2 2] -512 MAIN [15 7 4] 1 [14 3 5] 1 [15 3 7] 1
INTER [8 3 0] 1&2 [4 0 0] - [6 2 1] -1024 MAIN [15 6 2] 1 [16 11 4] 1, 2 [13 8 5] 1, 2
INTER [10 0 0] 1&2 [14 2 0] 1&2 [10 2 0] 1&22048 MAIN [16 16 2] 1, 2 [16 15 3] 1, 2 [16 16 4] 1, 2
INTER [16 2 0] 1&2 [16 0 0] 1&2 [16 1 0] 1&2
a MAIN denotes three main effects: [1: nbor, 2: initial, 3:postp].b INTER denotes interaction effects: [1&2, 1&3, 2&3].
c K is the number of superpixels
v
v vTable 2. Three-way ANOVA to PKM

82 Journal of Multimedia Processing and Technologies Volume 6 Number 3 September 2015
USE B-Recall B-PrecisionK Effect
p<0.05 Effect p<0.05 Effect p<0.05 Effect
32 MAINa [1 4] - [2 1] - [1 6] -64 MAIN [1 3] - [2 3] - [2 2] -128 MAIN [2 4] - [2 1] - [0 2] -256 MAIN [5 3] - [4 1] - [4 4] -512 MAIN [4 2] - [3 4] - [5 5] -1024 MAIN [11 1] 1 [10 0] 1 [7 1] -2048 MAIN [9 2] 1 [7 3] - [10 3] 1
a MAIN denotes three main effects: [1:weight, 2: postp].
Table 3. Two-way ANOVA to SLIC
In small clustering centers, K = [32, 64, 128, 256], we mostly obtained high segmentation performances (USE, boundary recall andprecision) when the pixel-based k-means (PKM) clustering set the number of neighbor centers (nbor) equal to 2 and imple-mented frequency method for post-processing (postp) to enforce connectivity of trivial pixels and superpixels (see TABLE II). Inlarge number of clustering centers, K = [512, 1024, 2048], the high segmentation performances resulted from the PKM thatadopted argyle pattern as initialization method with 2 neighbor centers (nbor effect). Moreover, in large number of clusteringcenters, K = [1024, 2048], the weight m is set to 12 that is beneficial to the three performances of SLIC (Table 3)
In Figures. 4 - 6, we compare the USE, boundary recall and precision for the superior SLIC (m =12) and the superior PKM (b = 2)for increasing numbers of superpixels. Experiment results showed the PKM is better than the SLIC in the three segmentationperformances over 64 clustering centers (superpixel size). In Table 4, the superior number of PKM/SLIC in the three performancesdisplayed that the PKM is useful to large number of superpixel clustering. Meanwhile, we compare the time required for the SLICand the PKM (Figure. 7), and found that the PKM spends CPU time that is higher than the SLIC does over 1600 clusteringcenters. Thus, we suggested that the superpixel algorithm, PKM (b = 2) is implemented within the range [100, 1500] of clusteringcenters for image segmentations.
Figure 4. Boxplot and averaged USE of PKM and SLIC

Journal of Multimedia Processing and Technologies Volume 6 Number 3 September 2015 83
Figure 5. Boxplot and averaged recall of PKM and SLIC
Figure 6. Boxplot and averaged precision of PKM and SLIC
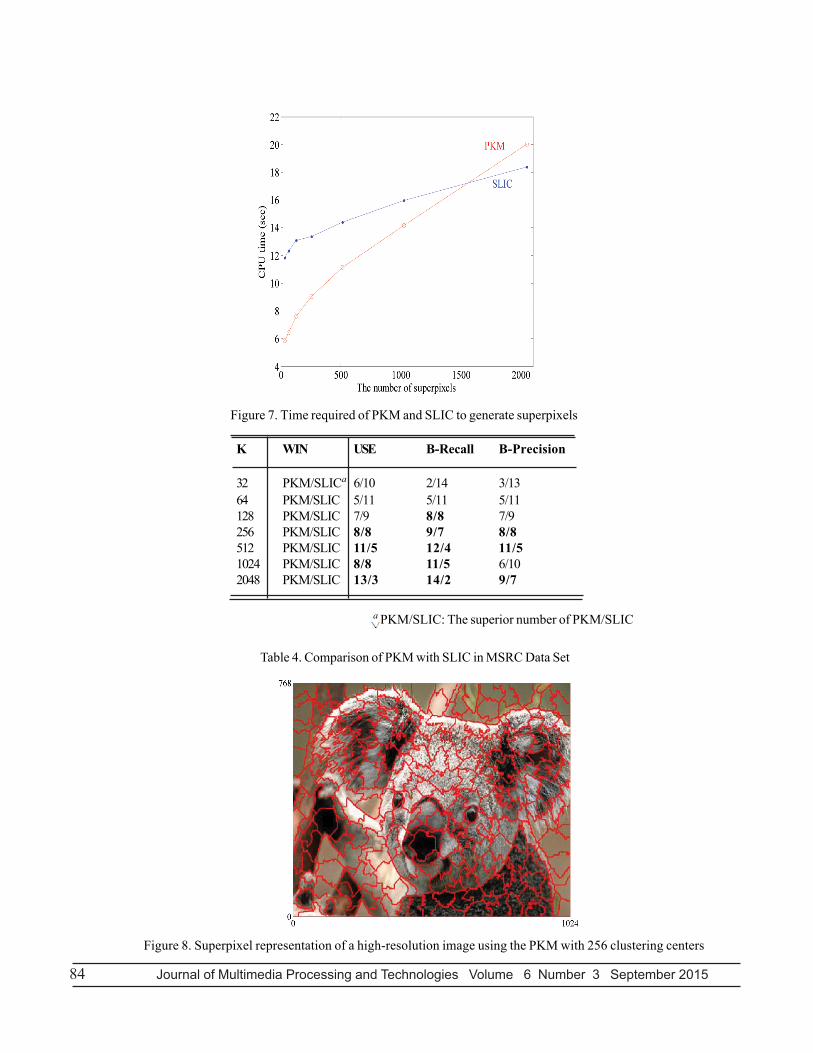
84 Journal of Multimedia Processing and Technologies Volume 6 Number 3 September 2015
Figure 7. Time required of PKM and SLIC to generate superpixels
K WIN USE B-Recall B-Precision
32 PKM/SLICa 6/10 2/14 3/1364 PKM/SLIC 5/11 5/11 5/11128 PKM/SLIC 7/9 8/8 7/9256 PKM/SLIC 8/8 9/7 8/8512 PKM/SLIC 11/5 12/4 11/51024 PKM/SLIC 8/8 11/5 6/102048 PKM/SLIC 13/3 14/2 9/7
a PKM/SLIC: The superior number of PKM/SLIC
Table 4. Comparison of PKM with SLIC in MSRC Data Set
Figure 8. Superpixel representation of a high-resolution image using the PKM with 256 clustering centers

Journal of Multimedia Processing and Technologies Volume 6 Number 3 September 2015 85
Figure 9. Superpixel representation of a high-resolution image using the SLIC with 256 clustering centers
5. Conclusion
Superpixel representations have come into common use for image segmentations. These mid-level features’ clustering methodsare able to reduce the computation load like video surveillance. We provide a pixel-based k-means (PKM) clustering that is ableto summarize color information within a regular spatial size. In this work we perform a classical comparison of the PKM withstate-of-the-art superpixel algorithm, SLIC based on the boundary adherence and segmentation speed. For boundary performanceand computational time, this paper claims that the PKM with 2 neighbor centers adopts argyle pattern as initialization methodand adjoining frequency method for post-processing, and is implemented within the range [100, 1500] of clustering centers forimage segmentations. In addition, while a high-resolution image (1024´768) is examined on 256 clustering centers, the PKM (171sec) is also better than the SLIC (319 sec) in CPU time (Figures. 8 and 9) under the MATLAB® compiler.
References
[1] Chang, J., Wei, D., Fisher III, J. W. (2013). A video representation using temporal superpixels, in Computer Vision and PatternRecognition (CVPR), 2013 IEEE Conference on, p. 2051-2058.
[2] Xiang, D., Tang, T., Zhao, L., Su, Y. (2013).Superpixel generating algorithm based on pixel intensity and location similarity forSAR image classification.
[3] Morerio, P., Georgiu, G. C., Marcenaro, L., Regazzoni, C. (2015). Optimizing superpixel clustering for real-time egocentric-vision applications, Signal Processing Letters, IEEE, 22, p. 469-473.
[4] Vantaram, S. R., Saber, E. (2012). Survey of contemporary trends in color image segmentation, Journal of Electronic Imaging,21, p. 040901-1-040901-28.
[5] Veksler, Boykov, Y., Mehrani, P. (2010). Superpixels and supervoxels in an energy optimization framework, In: ComputerVision–ECCV ,ed. Springer, p. 211-224.
[6] Achanta, R., Shaji, A., Smith, K., Lucchi, A., Fua, P., Susstrunk, S. (2012). SLIC superpixels compared to state-of-the-artsuperpixel methods, Pattern Analysis and Machine Intelligence, IEEE Transactions on, 34, p. 2274-2282.
[7] Levinshtein, Stere, A., Kutulakos, K. N., Fleet, D. J.,Dickinson, S. J. Siddiqi, K. (2009).Turbopixels: Fast superpixels usinggeometric flows, Pattern Analysis and Machine Intelligence, IEEE Transactions on, 31, p. 2290-2297.
[8] Kanungo, T., Mount,,D. M., Netanyahu, N. S., Piatko, C. D., Silverman, R., Wu, A. Y. (2002). An efficient k-means clusteringalgorithm: Analysis and implementation, Pattern Analysis and Machine Intelligence, IEEE Transactions on, 24, p. 881-892,
[9] Saraswathi, S., Allirani, A. (2013). Survey on image segmentation via clustering, In: Information Communication and EmbeddedSystems (ICICES), International Conference on, p. 331-335.

86 Journal of Multimedia Processing and Technologies Volume 6 Number 3 September 2015
[10] Ngai, W. K., Kao, B., Chui, C. K., Cheng, R., Chau, M., Yip, K. Y. (2006). Efficient clustering of uncertain data, in DataMining. ICDM’06. Sixth International Conference on, p. 436-445.
[11] Neubert, P., Protzel, P. (2012). Superpixel benchmark and comparison, In: Proc. Forum Bildverarbeitung.
[12]Hamerly, G.., Elkan, C. (2002). Alternatives to the k-means algorithm that find better clusterings, In: Proceedings of theeleventh international conference on Information and knowledge management, p. 600-607.