super-computer architecture
TRANSCRIPT

11/16/2014
Copyright @IITBHU_CSE
Jagjit Singh(12100EN003)
Vivek Garg(12100EN009)
Shivam Anand(12100EN012)
Kshitij Singh(12100EN061)

Introduction
Supercomputer architectures were first
introduced in the 1960s. A lot of changes
have since been made since that time.
Early supercomputer architectures
pioneered by Seymour Cray relied on
compact innovative designs and local
parallelism to achieve superior
computational performance. However, in
time the demand for increased
computational power ushered in the age
of massively parallel systems.
While the supercomputers of the 1970s
used only a few processors, in the 1990s,
machines with many thousands of
processors began to appear and as the
20th century came to an end, massively
parallel supercomputers with tens of
thousands of "off-the-shelf" processors
were the norm. In the 21st century,
supercomputers can use as many as
100,000 processors connected by very fast
connections.
Systems with a massive number of
processors generally take one of two
paths: in one of the approaches, e.g.,
in grid computing the processing power of
a large number of computers in
distributed. Diverse domains are
opportunistically used whenever a
computer is available. Another approach
is to utilize many processors in close
proximity to each other, e.g., in
a computer cluster. In such
centralized massively parallel system the
speed the flexibility of the inter-connect
becomes very important, and modern
supercomputers have used approaches
ranging from enhanced Infiniband systems
to three-dimensional torus interconnects.
As the price/performance of general
purpose graphic processors (GPGPUs) has
improved, many petaflop supercomputers
such as Tianhe-I and Nebulae have started
to depend on them. However, other
systems such as the K computer continue
to use conventional processors such
as SPARC-based designs and the overall
applicability of GPGPUs in general purpose
high performance computing applications
has been the subject under consideration,
in that while a GPGPU may be tuned to
perform well on specific benchmarks its
overall applicability to everyday
algorithms may be limited unless
significant effort is spent to tune the
application towards it. But GPUs are
gaining ground and in 2012 the Jaguar
supercomputer was transformed
into Titan by replacing CPUs with GPUs.
As the number of independent processors
in a supercomputer increases, the method
by which they access data in the file
system and how they share and
access secondary storage resources
becomes prominent. Across the years a
number of systems for distributed file
management were made, e.g., the IBM
General Parallel File System, FhGFS,
theParallel Virtual File System, Hadoop,
etc. A number of supercomputers on
the TOP100 list such as the Tianhe-I
use Linux's Lustre file system.

Background
The CDC 6600 series of computers were
very early attempts at supercomputing
and gained their advantage over the
existing systems by relegating work
to peripheral devices, freeing the CPU
(Central Processing Unit) to process
valuable data. With the
Minnesota FORTRAN compiler the 6600
could sustain 500 kiloflops on standard
mathematical operations.
Other early supercomputers like the Cray
1 and Cray 2 that appeared afterwards
used a small number of fast processors
that worked in harmony and were
uniformly connected to the largest
amount of shared memory that could be
managed at the time.
Parallel processing at the processor level
were introduced by these early
architectures, with innovations such
as vector processing, in which the
processor can perform several operations
during one clock cycle, rather than having
to wait for successive cycles.
In time, as the number of processors
increased, different issues regarding
architecture emerged. Two issues that
need to be addressed as the number of
processors increases are the distribution
of processing and memory. In the
distributed memory approach, each
processor is packaged physically close
with some local memory. The memory
that is associated with other processors is
then "further away" based on
bandwidth and latency parameters in non-
uniform memory access.
Pipelining was an innovation of the 1960s,
and by the 1970s the use of vector
processors had been well established.
Parallel vector processing had gained
ground by 1990. By the 1980s, many
supercomputers used parallel vector
processors.
In early systems the relatively small
number of processors allowed them to
easily use a shared memory architecture,
hence processors are allowed to access a
common pool of memory. Earlier a
common approach was the use of uniform
memory access (UMA), in which access
time to a memory location was similar
between processors. The use of non-
uniform memory access (NUMA) allowed
a processor to access its own local
memory faster than other memory
locations, whereas cache-only memory
architectures(COMA) allowed for the local
memory of each processor to be used like
a cache, thus requiring coordination as
memory values changed.
As the number of processors increases,
efficient inter-processor
communication and synchronization on a
supercomputer becomes a challenge.
Many different approaches may be used
to achieve this goal. For example, in the
early 1980s, in the Cray X-MP system used
shared registers. In this approach, shared
registers could be accessed by all
processors that did not move data back
and forth but were only used for inter-
processor synchronization and
communication. However, inherent
challenges in managing a large amount of
shared memory among many processors
resulted in a move to more distributed architectures.
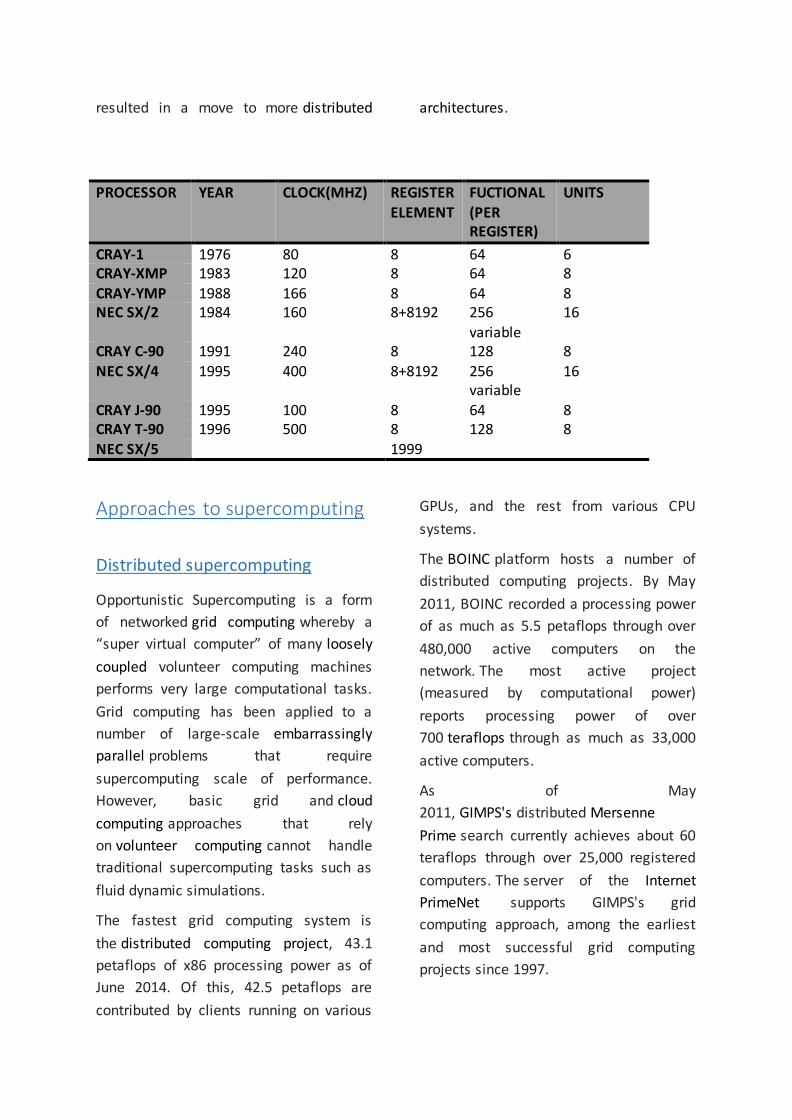
PROCESSOR YEAR CLOCK(MHZ) REGISTER
ELEMENT
FUCTIONAL
(PER REGISTER)
UNITS
CRAY-1 1976 80 8 64 6 CRAY-XMP 1983 120 8 64 8
CRAY-YMP 1988 166 8 64 8 NEC SX/2 1984 160 8+8192 256
variable
16
CRAY C-90 1991 240 8 128 8
NEC SX/4 1995 400 8+8192 256 variable
16
CRAY J-90 1995 100 8 64 8 CRAY T-90 1996 500 8 128 8 NEC SX/5 1999
Approaches to supercomputing
Distributed supercomputing
Opportunistic Supercomputing is a form
of networked grid computing whereby a
“super virtual computer” of many loosely
coupled volunteer computing machines
performs very large computational tasks.
Grid computing has been applied to a
number of large-scale embarrassingly
parallel problems that require
supercomputing scale of performance.
However, basic grid and cloud
computing approaches that rely
on volunteer computing cannot handle
traditional supercomputing tasks such as
fluid dynamic simulations.
The fastest grid computing system is
the distributed computing project, 43.1
petaflops of x86 processing power as of
June 2014. Of this, 42.5 petaflops are
contributed by clients running on various
GPUs, and the rest from various CPU
systems.
The BOINC platform hosts a number of
distributed computing projects. By May
2011, BOINC recorded a processing power
of as much as 5.5 petaflops through over
480,000 active computers on the
network. The most active project
(measured by computational power)
reports processing power of over
700 teraflops through as much as 33,000
active computers.
As of May
2011, GIMPS's distributed Mersenne
Prime search currently achieves about 60
teraflops through over 25,000 registered
computers. The server of the Internet
PrimeNet supports GIMPS's grid
computing approach, among the earliest
and most successful grid computing
projects since 1997.

Quasi-opportunistic approaches
Quasi-opportunistic supercomputing is a
form of distributed computing whereby
the “super virtual computer” of a large
number of networked geographically
disperse computers performs computing
tasks that demand huge processing
power. Quasi-opportunistic
supercomputing aims to provide a higher
quality of service than opportunistic grid
computing by achieving more control over
the assignment of tasks to distributed
resources and the use of intelligence
about the availability and reliability of
individual systems within the
supercomputing network. Whereas quasi-
opportunistic distributed execution of
demanding parallel computing software in
grids should be achieved through
implementation of grid-wise agreements
of allocation, co-allocation subsystems,
communication topology-aware allocation
mechanisms, message passing libraries
that are fault tolerant and data pre-
conditioning.
Massive, centralized parallelism
During the 1980s, as the computing power
demand increased, the trend to a much
larger number of processors began,
bringing in the age of massively
parallel systems, with distributed
memory and file systems, provided
that shared memory architectures could
not scale to a large number of
processors. Hybrid approaches such
as distributed shared memory also
appeared after the early systems.
The computer clustering approach
connects a number of readily available
computing nodes (e.g. personal
computers used as servers) via a fast,
private local area network. The activities
of the computing nodes are orchestrated
by "clustering middleware" which is a
software layer that sits atop the nodes
and allows the users to treat the cluster as
by and large one cohesive computing unit,
for example via a single system
image concept.
Computer clustering relies on a
centralized management approach which
makes the nodes available as
orchestrated shared servers. It is different
from other approaches such as peer to
peer or grid computing which also use a
large number of nodes, but with a far
more distributed nature. By the 21st
century, the TOP500 organization's semi
annual list of the 500 fastest
supercomputers often includes many
clusters like the world's fastest in 2011,
the K computer which had a distributed
memory and a cluster architecture.
When a large number of local semi-
independent computing nodes are used
(e.g. in a cluster architecture) the speed
and flexibility of the interconnect
becomes very important. Modern
supercomputers have taken various
approaches to resolve this issue,
e.g. Tianhe-1 uses a proprietary high-
speed network based on
the Infiniband QDR, enhanced
with FeiTeng-1000 CPUs. On the other
hand, the Blue Gene/L system uses a
three-dimensional torus interconnect with
auxiliary networks for global

communications. In this approach each
node is connected to its six nearest
neighbours. Likewise a torus was used by
the Cray T3E.
Massive centralized systems at times use
special-purpose processors designed for a
specialised application, and may use field-
programmable gate arrays (FPGA) chips to
gain performance by sacrificing generality.
Such special-purpose supercomputers
have examples like Belle, Deep
Blue, and Hydra, for
playing chess, MDGRAPE-3 for protein
structure computation molecular
dynamics and Deep Crack for breaking
the DES cipher.
Massive distributed parallelism
Grid computing uses a large number of
computers in diverse, distributed
administrative domains which makes it an
opportunistic approach which uses
resources whenever they are available. An
example is BOINC a volunteer-based,
opportunistic grid
system. Some BOINC applications have
reached multi-petaflop levels by using
close to half a million computers
connected on the web, whenever
volunteer resources become
available. However, these types of results
often do not appear in the TOP500 ratings
because they do not run the general
purpose Linpack benchmark.
Although grid computing has had success
in parallel task execution but demanding
supercomputer applications such
as weather simulations or computational
fluid dynamics have not been successful,
partly due to the barriers in reliable sub-
assignment of a large number of tasks as
well as the reliable availability of
resources at a given time.
In quasi-opportunistic supercomputing a
large number of geographically disperse
computers are orchestrated with built-in
safeguards. The quasi-opportunistic
approach goes beyond volunteer
computing on a highly distributed systems
for example BOINC, or general grid
computing on a system such as Globus by
allowing the middleware to provide
almost seamless access to many
computing clusters so that existing
programs in languages such
as Fortran or C can be distributed among
multiple computing resources.
Quasi-opportunistic supercomputing aims
to provide a higher quality of service
than opportunistic resource sharing. The
quasi-opportunistic approach enables the
execution of demanding applications
within computer grids by establishing grid-
wise resource allocation agreements;
and fault tolerant message passing to
abstractly shield against the failures of the
underlying resources and maintaining
some opportunism as well as allowing a
higher level of control.
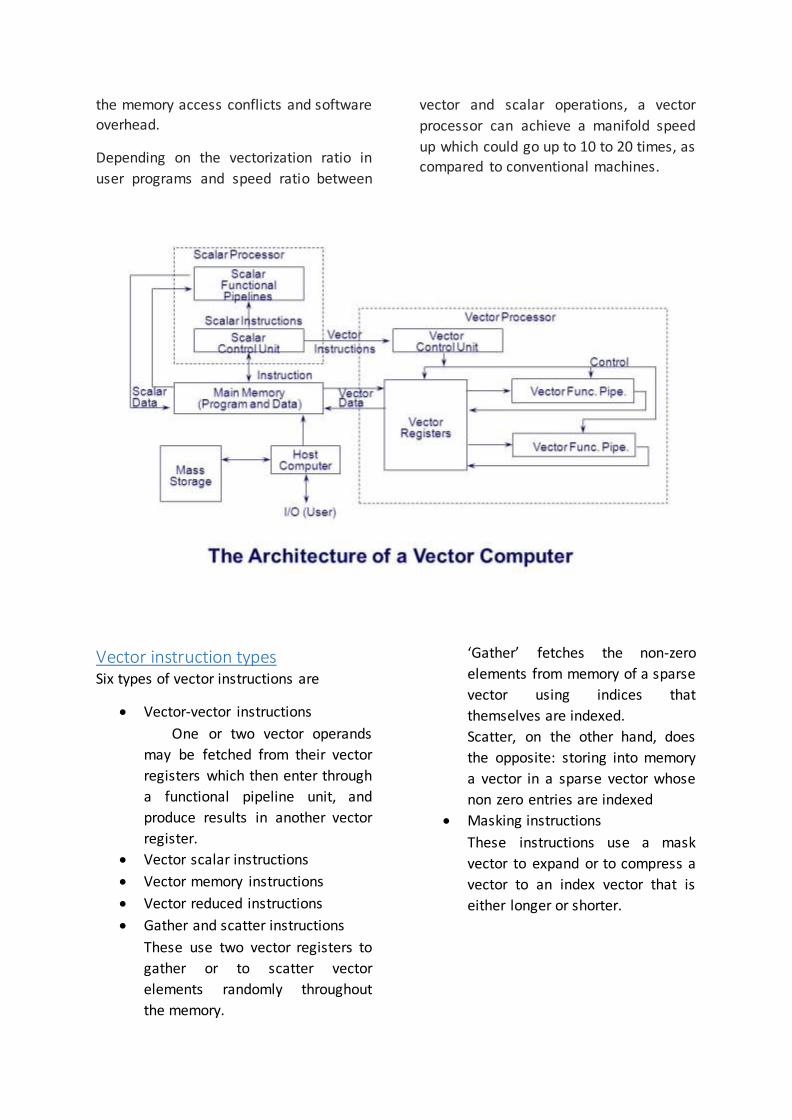
Vector processing principles Ordered set of scalar data items is known
as vector. all the data items are of same
type stored in memory. generally the
vector elements are ordered to have fixed
addressing increment between successive elements , called stride.
Vector processor includes processing
elements, vector registers, register
counters and functional pipelines, to
perform vector operations. Vector

processing involves arithmetic or logical
operations applied to vectors whereas
scalar processing operates on one datum.
The conversion from scalar code to vector code is called vectorization
Vector processors are special purpose
computers that match a range of computing (scientific) tasks. These tasks
usually consist of large active data sets, poor locality, and long run times and in
addition, vector processors provide vector instructions.
Vector processors are special purpose computers that match a range of
(scientific) computing tasks. These tasks usually consist of large active data sets,
often poor locality, and long run times. In addition, vector processors provide vector
instructions. These instructions operate in a pipeline
(sequentially on all elements of vector registers), and in current machines. Some properties of vector instructions are
Since the calculation of every result is independent of the calculation of previous results it allows a very deep pipeline without any data issues.
A vector instruction requires a huge amount of work since it is the same as executing an entire loop. Hence, the instruction bandwidth requirement is decreased.
Vector instructions that require memory have a predefined access
pattern that can easily be predicted. If the vector elements
are all near each other, then obtaining the vector from a set of
heavily interleaved memory banks works extremely well. Because a
single access is initiated for the entire vector rather than to a
single word, the high latency of starting a main memory access
against accessing a cache is
amortized. Thus, the cost of the latency to main memory is seen only once for the entire vector,
rather than once for each word of the vector.
Control hazards are no longer present since an entire loop is
replaced by a vector instruction whose behaviour is determined
beforehand .
Typical vector operations include (integer and floating point:
Add two vectors to produce a third.
Subtract two vectors to produce a third
Multiply two vectors to produce a third
Divide two vectors to produce a third
Load a vector from memory
Store a vector to memory. These instructions could be augmented to do typical array operations:
Inner product of two vectors (multiply and accumulate sums)
Outer product of two vectors (produce an array from vectors)
Product of (small) arrays (this would match the programming
language APL which uses vectors and arrays as primitive data
elements.)
Hence vector processing is faster and
much more efficient than scalar
processing. Both SIMD computers and
pipelined processors can perform vector
operations. Vector processing generates
one result per clock cycle by continuously
matching with the pipelining and
segmentation concepts. It also reduces
the memory access conflicts and software overhead.
Depending on the vectorization ratio in
user programs and speed ratio between
vector and scalar operations, a vector
processor can achieve a manifold speed
up which could go up to 10 to 20 times, as
compared to conventional machines.
Vector instruction types Six types of vector instructions are
Vector-vector instructions
One or two vector operands
may be fetched from their vector
registers which then enter through
a functional pipeline unit, and
produce results in another vector
register.
Vector scalar instructions
Vector memory instructions
Vector reduced instructions
Gather and scatter instructions
These use two vector registers to
gather or to scatter vector
elements randomly throughout
the memory.
‘Gather’ fetches the non-zero
elements from memory of a sparse
vector using indices that
themselves are indexed.
Scatter, on the other hand, does
the opposite: storing into memory
a vector in a sparse vector whose
non zero entries are indexed
Masking instructions
These instructions use a mask
vector to expand or to compress a
vector to an index vector that is
either longer or shorter.

Vector access memory schemes Usually, multiple access paths pipeline the
flow of vector operands between the
main memory and vector registers.
Vector operand specifications
Vector operands can be arbitrarily
long. Vector elements may not be
stored in memory locations that
are contiguous.
To access a vector, its base
address, stride, and length must be
described. Since every vector
register has a predefined number
of component registers, in a fixed
number of cycles, only a small part
of the vector can be loaded to the
vector register.
C-Access memory organisation.
S-Access memory organisation.
C/S-Access memory organisation.
The Effect of cache design into
vector computers Cache memories have proven to be very
successful in the case of general purpose computers to boost system performance.
However, their use in vector processing has not yet been fully established.
Generally, the existing supercomputer vector processors do not have cache
memories because of the results drawn from the following points:
Generally the data sets of numerical programs are too large
for the cache sizes provided by the present technology. Sweep
accesses of a large vector may end up completely reloading the cache
before the processor can even reuses them.
Sequential addresses which are a crucial assumption in the
conventional caches may not prove to be as effective in
vectorised numerical algorithms
that usually acquire data with certain stride which is the distinction between addresses
associated with consecutive vector elements.
Register files and highly interleaved memories are usually
used to achieve a high memory bandwidth required for vector
processing.
It is not clear whether cache memories can boost the performance of such
systems. Although cache memories have the
capability for boosting the performance of future vector processors, numerous
reasons counter the use of vector caches. A single miss in the vector cache results in
a number of processors. Stall cycles equal to the entire memory access time,
however the memory accesses of a vector processor without cache are fully pipelined. In order to benefit from a vector cache, the miss ratio must be kept extremely small. In general, cache misses can be classified into these categories:
Compulsory miss
Capacity miss
Conflict miss
The compulsory misses occur in the initial loading of data, which are easily pipelined
in a vector computer. Next, the capacity misses are because of the size restrictions of a cache to retain data between
references. If algorithms are blocked as mentioned, the capacity misses can be
linked to the compulsory misses during the initial loading of every block of data
given that the block size is lesser than that of cache. Finally, conflict misses, plays a
deciding role in the vector processing environment. Conflicts occur when
elements of the same vector are mapped directly to the same cache elements or
line from two different vectors compete

for the same cache line. Since conflict misses that reduce vector cache performance to do with vector access
stride, size of an application problem can be adjusted to make a good access stride
for a machine. This approach burdens a programmer for knowing architecture
details of a machine as well as it is infeasible for many applications.
Ideas like prime-mapped cache schemes have been studied. The new cache
organization reduces cache misses due to cache line interferences that are critical in
numerical applications. Also, the cache lookup time of the new mapping scheme
stays the same as conventional caches. Creation of cache addresses for accessing the prime-mapped cache can be done parallel along with normal address calculations. This address creation takes lesser time than the normal address calculation because of the special properties of the Messene prime. Thus, the new mapping scheme doesn’t cause any performance penalty in terms of the cache access. With this new mapping scheme, the cache memory can show a large amount of performance boost, which will increase as the speed gap between processor and memory is increased.
GPU based supercomputing
The demand for an increased Personal Computer (PC) graphics subsystem
performance never ceases. The GPU is an ancillary coprocessor subsystem,
connected to an internal high-speed bus and memory-mapped into global memory
resources. Computer vision, gaming, and advanced graphics design applications have led to sharp MIPS performance
boosts and increased variety and algorithmic efficiency on part of relevant graphics standards. All this is a part of a larger evolutionary trend whereby PCs
supplant dedicated workstations for a host of compute intensive applications. At a deeper level GPU evolution depends on
the assumption of a processing model that can achieve the highest possible
performance for a wide variety of graphics algorithms. This then drives all relevant
aspects of hardware architecture and design. The most efficient GPU processing
model is Single Instruction Multiple Data (SIMD). The SIMD model has been of great
use in traditional vector processor/supercomputer designs, (e.g.
Cray X-MP, Convex C1, CDC Star-100), by capability to boost datapath calculation
based upon concurrent execution of processing threads. The SIMD concept has been employed in recent CPU architectural advancements, like the IBM Cell processor, x86 with MMX extensions, SPARC VIS, Sun MAJC, ARM NEON etc. SIMD processing model adopted for GPU can be used for general classes of scientific computation not specifically associated with graphics applications. This was the start of the General Purpose computing on GPU (GPGPU) movement and basis for many examples of GPU accelerated scientific processing. GPGPU closely depends upon Application Programming Interface (API) access to resources of GPU processing; GPU API
abstracts much of the complexity
associated with manipulation of hardware resources and provides convenient access
to I/O, memory management, and thread management functionality in form generic
programming function calls, (e.g. C, C++, Python, Java). Thus, GPU hardware is
virtualized as a standard programming resource, facilitating uninhibited application development incorporating GPU acceleration. APIs that are currently in use include NVIDIA’s Compute Unified Device Architecture (CUDA) and ATI’s Data Parallel Virtual Machine (DPVM).

GPU Architecture SIMD GPU is organized as a collection of ‘N’ distinct multiprocessors, each consisting of ‘M’ distinct thread processors. Multiprocessor operation is modulo an ensemble of threads managed and scheduled as a single entity, (i.e.
‘warp’). Like this, SIMD instruction fetch and execution, shared-memory access,
and cache operations are completely synchronized. Memory usually is
organized hierarchically where Global/Device memory transactions are
understood as mediated by high-speed bus transactions, (e.g.PCIe,
HyperTransport). A feature associated with the CPU/GPU
processing architecture is GPU processing is essentially non-blocking. Hence, CPU
may continue processing as soon as a work-unit has been written to the GPU
transaction buffer. GPU work unit assembly/disassembly and I/O at the GPU
transaction buffer may to large extent be
hidden. In these case, GPU performance will effectively dominate the performance
of the entire system. Optimal GPU processing gain is achieved at an I/O
constraint boundary whereby thread processors never stall due to lack of data.
The maximum achievable speedup is governed by Amdahl’s Law: any
acceleration (‘A’) due to thread parallelization will critically depend upon:
The fraction of code than can be parallelized (‘P’)
The degree of parallelization (‘N’), and
Any overhead associated with parallelization
This indicates a theoretical maximum
acceleration for the application. CPU code pipelining (i.e. overlap with GPU
processing) must also be factored into any
calculation for ‘P’; pipelining effectively parallelizes CPU and GPU code segments reducing the non-parallelized code
fraction '(1- P)'. Thus, under circumstances where decrease is sufficient to claim (P).
Hence, well-motivated software architecture design can take advantage of
this effect, greatly increasing acceleration potential for the complete application.
21st-century architectural trends
The air cooled IBM Blue
Gene supercomputer architecture trades
processor speed for low power
consumption so that a larger number of
processors can be used at room
temperature, by using normal air-
conditioning. The second generation Blue
Gene/P system is distinguished by the fact
that each chip can act as a 4-
way symmetric multiprocessor and also
includes the logic for node-to-node
communication. And at
371 MFLOPS/W the system is very energy
efficient.
The K computer has water cooling system,
homogeneous processor and distributed
memory system with a cluster
architecture. It uses more than 80,000
processors which are SPARC based, each
with eight cores, for a total of over
700,000 cores – almost twice as many as
any other system and more than 800
cabinets, each with 96 computing nodes
,each with 16 GB of memory , and 6 I/O
nodes although it is more powerful than
the next five systems on the TOP500 list
combined, at 824.56 MFLOPS/W but it
has the lowest power to performance
ratio of any current major supercomputer
system. The follow up system, called the
PRIMEHPC FX10 uses the same six-

dimensional torus interconnect, but only
one SPARC processor per node.
Unlike the K computer, the Tianhe-
1A system uses a hybrid architecture and
integrates CPUs and GPUs. It uses more
than 14,000Xeon general-purpose
processors and greater than 7,000 Nvidia
Tesla graphic-based processors on about
3,500 blades. It has 112 computer
cabinets and 262 terabytes of distributed
memory; 2 petabytes of disk storage is
implemented via Lustre clustered
files. Tianhe-1 uses a proprietary high-
speed communication network to connect
the processors. The proprietary
interconnect network was based on
the Infiniband QDR, along with Chinese
made FeiTeng-1000 CPUs. In the case of
the interconnect the system is twice as
fast as the Infiniband, but is slower than
some interconnects on other
supercomputers.
The limits of specific approaches continue
to be tested through large scale
experiments, such as in 2011 IBM ended
its participation in the Blue
Waters petaflops project at the University
of Illinois. The Blue Waters architecture
was based on the IBM POWER7 processor
and intended to have 200,000 cores with
a petabyte of "globally addressable
memory" and 10 petabytes of disk
space. The goal of a sustained petaflop led
to design choices that optimized single-
core performance, and a lower number of
cores which is then expected to help
performance on programs that did not
scale well to a large number of
processors. The large globally addressable
memory architecture aimed to solve
memory address problems in an efficient
manner, for the same type of
programs. Blue Waters had been expected
to run at sustained speeds of at least one
petaflop which relied on the specific
water-cooling approach to manage heat.
The National Science Foundation spent
about $200 million on the project in the
first four years of operation. IBM released
the Power 775 computing node derived
from that project's technology soon , but
effectively abandoned the Blue Waters
approach.
Architectural experiments are continuing
in a number of directions, for example
the Cyclops64 system uses a
supercomputer on a chip approach,
contrasting the use of massive distributed
processors. Each 64-bit Cyclops64 chip
contains 80 processors with the entire
system using a globally
addressable memory architecture. The
processors are connected with non-
internally blocking crossbar switch and
communicate with each other via global
interleaved memory with no data cache in
the architecture, while half of
each SRAM bank can be used as a
scratchpad memory. Although this type of
architecture allows unstructured
parallelism in a dynamically non-
contiguous memory system but it also
produces challenges in the efficient
mapping of parallel algorithms to a many-
core system.
Issues and challenges
we could significantly increase the
performance of a processor by issuing
multiple instructions per clock cycle and
by deeply pipelining the execution units

to allow greater exploitation of instruction
level parallelism. But there are serious
difficulties in exploiting ever larger
degrees of instruction level parallelism.
As we increase both the width of
instruction issue and the depth of the
machine pipelines, we as well increase the
number of independent instructions
required to keep the processor busy with
useful work. This means an increase in the
number of partially executed instructions
that can be in flight at one time. For a
dynamically-scheduled machine
hardware structures, such as reorder
buffers, instruction windows ,and rename
register files, must grow to have sufficient
capacity to hold all in-flight instructions,
and worse, the number of ports on each
element of these structures must grow
with the issue width. The logic to track
dependencies between all in-flight
instructions grows quadratically in the
number of instructions. Even a VLIW
machine, which is statically scheduled and
shifts more of the scheduling burden to
the compiler, needs more registers, more
ports per register, and more hazard
interlock logic (assuming a design where
hardware manages interlocks after issue
time) to support more in-flight
instructions, which similarly cause
quadratic increases in circuit size and
complexity. This rapid increase in circuit
complexity makes it difficult to build
machines that can control large numbers
of in-flight instructions which limits
practical issue widths and pipeline depths.
Vector processors were successfully
commercialized long before instruction
level parallel machines and take an
alternative approach to controlling
multiple functional units with deep
pipelines. Vector processors provide high-
level operations that work on vectors. A
typical vector operation might add two
floating-point vectors of 64 elements to
obtain a single 64-element vector result.
This instruction is equivalent to an entire
loop, in which each iteration is computing
one of the 64 elements of the result and
updating the indices, and branching back
to the beginning. Vector instructions have
several important properties that solve
most of the problems mentioned above:
A single vector instruction describes a
great deal of work—it is equivalent to
executing an entire loop where each
instruction represents tens or hundreds of
operations, and so the instruction fetch
and decode bandwidth needed to keep
multiple deeply pipelined functional units
busy is dramatically reduced.
By using a vector instruction, the compiler
or programmer indicates that the
computation of each result in the vector is
independent of the computation of other
results in the same vector and so
hardware does not have to check for data
hazards within a vector instruction. The
elements in the vector can be computed
using an array of parallel functional units,
or a single very deeply pipelined
functional unit, or any mixed
configuration of parallel and pipelined
functional units.

Hardware need only check for data
hazards between two vector instructions
once per vector operand and not once for
every element within the vectors. That
means the dependency checking logic
required between two vector instructions
is approximately the same as that
required between two scalar instructions,
but now many more elemental operations
can be in flight for the same complexity of
control logic.
Vector instructions that access memory
have a known access pattern then
fetching the vector from a set of heavily
interleaved memory banks works very
well if the vector’s elements are all
adjacent. The high latency of initiating a
main memory access versus accessing a
cache is amortized as a single access is
initiated for the entire vector not just to a
single word. Hence the cost of the latency
to main memory is seen only once for the
entire vector and not for each word of the
vector.
Because an entire loop is replaced by a
vector instruction whose behaviour is
predetermined the control hazards that
would normally arise from the loop
branch are non-existent. For these
reasons, vector operations can be made
faster than a sequence of scalar
operations on the same number of data
items, and if the application domain can
use them frequently, designers are
motivated to include vector units. As
mentioned above, vector processors
pipeline and parallelize the operations on
the individual elements of a vector. The
operations include not only the arithmetic
operations, but also memory accesses and
effective address calculations. Also, most
high-end vector processors allow multiple
vector instructions to be in progress at the
same time, creating further parallelism
among the operations on different
vectors.
Vector processors are particularly useful
for large scientific and engineering
applications, such as car crash simulations
and weather forecasting, for which a
typical job might take dozens of hours of
supercomputer time running over multi
gigabyte data sets. Multimedia
applications can also benefit from vector
processing, as they contain abundant data
parallelism and process large data
streams. A high-speed pipelined processor
will usually use a cache to avoid forcing
memory reference instructions to have
very long latency. Unfortunately, big
scientific programs often have very large
active data sets that are sometimes
accessed with low locality hence yielding
poor performance from the memory
hierarchy. This problem could be
overcome by not caching these structures
if it were possible to determine the
memory access patterns and pipeline the
memory accesses efficiently. Compiler
assistance and novel cache architectures
through blocking and prefetching are
decreasing these memory hierarchy
problems, but still they continue to be
serious in some applications.

Application
The machine can be used in scientific and
business applications, but more suited to
scientific applications. Large multinational
banks and corporations are using small
supercomputers. Some of the applications
include; special effects in film, weather
forecasting, processing of geological data
and data regarding genetic decoding,
aerodynamics and structural designing,
mass destruction weapons and
simulation. The users include; Film
makers, Geological data processing
agencies, National weather forecasting
agencies, Space agencies, Genetics
research organizations, Government
agencies, Scientific laboratories,, Military
and defence systems, research groups and
Large corporations.
Simulation
Duplicating an environment is called
simulation. It is done for reasons like;
Training of the users
Predict/forecast the result
If physical experimentation is not possible If physical experimentation is very
expensive
All the expensive machines are
simulated before their actual
construction to prevent economic
losses and saving of time. Life
threating stunts are simulated before
performed which can predict any
technical or other fault and prevent
damage.
Movies
These are used to produce special effects.
Movies like The Star trek, Star fighter,
Babylon 5, Terminator’s sequel, Dante’s
Peak, Asteroid, Jurassic Park, The Lost
World, Matrix’s sequel, Lord of the Rings,
Godzilla and all the latest movies have special effects generated on
supercomputers.
Weather forecasting
Data is collected from worldwide network
of space satellites, ground stations and
airplanes, is fed in to supercomputer for
analysis to forecast weather. Thousands
of variables are involved in weather
forecasting and can only be processed on
a supercomputer. Accurate predictions
cannot be made beyond one month
because we need more powerful
computers to do so.
Oil Exploration To determine the most productive oil
exploration sites millions of pieces of data
is processed. Processing of geological data
involves billions of pieces of data and
thousands of variables, a very complex
calculation requiring very large computing
power.
Genetics engineering
Used for the processing and decoding of
genetic data this is used by genetics

scientists and engineers for research and
development to immune human beings from heredity diseases. Since genetics
data processing involves thousands of
factors to be processed supercomputers
are the best choice. The latest developments, like gene mapping and
cloning also require the capabilities of
supercomputers.
Space exploration Great achievements are simply impossible
without supercomputers. The remarkable
accuracy and perfection in the landing of
pathfinder on the Mars is another proof of
the capabilities of this wonderful machine.
Famous IBM processor technology
RISC/6000 used as in flight computer, that
was modified for the project, made
hardened and called RAD/6000.
Aerodynamic designing of airplanes In manufacturing of airplanes,
supercomputer to use to simulate the
passage of air around separate pieces of
the plane and then combine the results,
Today’s super computers are still unable
to simulate the passage of air around an
entire aircraft.
Aerospace and structural designing
Simulation in aerospace and structural designing was used for the space station
and space plane. These projects required
extensive experiments, some of which are
physically impossible. Such as, the
proposed space station would collapse
under its own weight if built in the gravity
of Earth. The plane must be able to take off from a runway on Earth and accelerate
directly into orbit at speeds greater than
8,800 miles per hour. Most of these
conditions cannot be duplicated; the
simulation and modelling for these
designs and tests include processing of billions of pieces of data and solving
numerous complex mathematical
calculations for supercomputers.
Nuclear weapons
Simulation is also used for the production
of mass destruction weapons to simulate
the results of an atomic or nuclear bomb
formula. For this reason, USA government
is very cautious about the production and export of this computer to several
nations. Some of the famous export deals
include.
• America provided Cray supercomputer
of type XMP to India for weather data
processing.
• USA supplied a supercomputer to China
for peaceful nuclear research.
• International Business Machines
Corporation exported supercomputer
RISCJ6000 SP to Russia, and they used it
for their nuclear and atomic research
purposes. This deal put International
Business Machines Corporation under
strong criticism by the US government.
Conclusion and future work
Given the current progress rate, industry
experts estimate that supercomputers will
reach 1 exaflops (1018, one quintillion
FLOPS) by 2018. China describes plans to
have a 1 exaflop supercomputer online by 2018. Using the Intel multi-core processor,
which is Intel's response to graphics
processor unit (GPU) systems, SGI plans to
achieve a 500 times increase in performance by 2018, in order to achieve
one extra flop. Samples of MIC chips with

32 cores, which combine VPU with
standard CPU, have become available. The government of India has also stated
ambitions for an exaflop-range
supercomputer, which they hope to
complete by 2017.].In November 2014 it was reported that India is working on the
Fastest supercomputer ever which is set
to work at 132 Exaflops per second.
Supercomputers with this new
architecture could be out within the next
year. The aim is to improve data
processing at the memory, storage and
I/O levels.
That will help break down parallel computational tasks into small parts,
reducing the compute cycles required to
solve problems. That is one way to
overcome economic and scaling limitations of parallel computing that
affect conventional computing models.
Memory, storage and I/O work in tandem
to boost system performance, but there
are bottlenecks with present
supercomputing models. A lot of energy and time is wasted in continuously moving
large chunks of data between processors,
memory and storage. Decreasing the
amount of data that has to be moved, which could help process data increase
three times faster than current
supercomputing models.
When working with petabytes and
exabytes of data, moving this amount of data is extremely inefficient and time
consuming, so processing to the data can be moved by providing compute capability
throughout the system hierarchy. IBM has built the world's fastest
computers for decagon, including the third- and fifth-fastest, according to a
recent Top 500 list. But the amount of data being put to servers is outpacing the growth of supercomputing speeds.
Networks are not going faster, the chip clock speeds are not increasing and there
is not a huge increase in data-access time. Applications no longer live in the classic
compute microprocessors; instead application and workflow computation are
distributed throughout the system hierarchy.
A simple example of reducing the size of data sets by decomposing information in
storage, which can then be moved to memory of the computer. That type of
model can be applied to oil and gas workflow -- which typically takes months -- and it would significantly shorten the time required to make decisions about drilling. A hierarchy of storage and memory including non-volatile RAM, which means much lower latency, higher bandwidths, without the requirement to move the data all the way back to central storage. Following conventional computing architectures such as the Von Neumann's approach, in which data is put into a processor, calculated and put back in the memory. Most of the computer systems today work on the type of architecture only, which was derived in the 1940's by
mathematician named John von
Neumann. At the individual compute element level,
we continue the Von Neumann's approach. At the level of the system,
however, an additional way to compute, which is to move the evaluate to the data
is provided. There are multiple ways to reduce latency in a system and reduce the amount of data which has to be moved. This saves energy as well as time. Moving computing closer to data in storage or memory is not a new concept. appliances and servers with CPUs targeted at specific workloads, and with

disaggregating storage, memory and processing subsystems into separate boxes are built which can be improved by
optimizing entire supercomputing workloads that involve simulation,
modeling, visualization and complex analytics on massive data sets.
The model will work in research areas like oil and gas life sciences, exploration,
materials research and weather modelling. Applications will need to be
written and well-defined for processing at different levels and IBM is working with
institution, companies and researchers to define software models for key sectors.
The fastest supercomputers today are calculated with the LINPACK benchmark, a simple measurement based on fractional (float) point operations. IBM is not ignoring Top 500, but providing a different approach to enhance supercomputing. LINPACK is good to measure speed, but has under-represented the utility of supercomputers and the benchmark does not fully account for specialized processing elements like int processing and FPGAs. The Top 500 list measures some elements of the behaviour of compute nodes, but it is not complete in terms of its characterization of workflows that require merging modelling, simulation and
analytics but many classic applications
are only moderately related to the measure of LINPACK
Different organizations building supercomputers have studied to build
software to take advantage of LINPACK, which is worse measurement of
supercomputing performance. The actual performance of some specialized applications goes far beyond LINPACK, and IBM's seems convincing. There are companies developing computers that give a new spin on how data is accessed and interpreted. System (D-Wave) is offering what is believed to be
the world's first and only quantum based computer, which is being used by NASA, Lockheed Martin and Google for specific
tasks. The others are in phase of experiments. IBM has built an
experimental computer with a chip designed to mimic a human brain.

References
1. Sao-Jie Chen; Guang-Huei Lin;
Pao-Ann Hsiung; Yu-Hen Hu (9 February 2009).Hardware
Software Co-Design of a Multimedia Soc Platform.
Springer. pp. 70–72.ISBN 978-1-4020-9622-8. Retrieved 15 June 2012.
2. Hoffman, Allan R. (1989). Supercomputers:
directions in technology and
applications. Washington, D.C.:
National Academy Press. pp. 35–47. ISBN 0-309-04088-4.
3. Hill, Mark D.; Jouppi, Norman P.;
Sohi, Gurindar (2000). Readings in
computer architecture. San Francisco: Morgan Kaufmann. pp. 40–49. ISBN 1-55860-539-8.
4. i Yang, Xue-Jun; Liao, Xiang-Ke; Lu, Kai; Hu, Qing-Feng; Song, Jun-
Qiang; Su, Jin-Shu (2011). "The TianHe-1A Supercomputer: Its
Hardware and Software". Journal
of Computer Science and
Technology 26 (3): 344–351. doi:10.1007/s02011-011-1137-8.
5. Murray, Charles J. (1997). The
supermen : the story of Seymour
Cray and the technical wizards
behind the supercomputer. New
York: John Wiley. pp. 133–135. ISBN 0-471-04885-2.
6. e Biswas, edited by Rupak
(2010). Parallel computational fluid dynamics : recent advances
and future directions : papers from the 21st International
Conference on Parallel Computational Fluid Dynamics.
Lancaster, Pa.: DEStech Publications. p. 401. ISBN 1-60595-022-X.
7. c Yongge Huáng, ed.
(2008). Supercomputing research advances. New York: Nova Science
Publishers. pp. 313–314. ISBN 1-60456-186-6.
8. Tokhi, M. O.; Hossain, M. A.;
Shaheed, M. H. (2003). Parallel computing for real-time signal
processing and control. London
[u.a.]: Springer. pp. 201–202. ISBN 978-1-85233-599-1.
9. Vaidy S. Sunderam, ed.
(2005). Computational science -- ICCS 2005. 5th international
conference, Atlanta, GA, USA, May
22-25, 2005 : proceedings (1st
ed.). Berlin: Springer. pp. 60–67. ISBN 3-540-26043-9.
10. Prodan, Radu; Thomas Fahringer
(2007). Grid computing experiment management, tool
integration, and scientific
workflows. Berlin: Springer. pp. 1–4. ISBN 3-540-69261-4.