sub-pj-operation scalable computing -...
TRANSCRIPT

Luca BeniniIIS-ETHZ & DEI-UNIBO
Sub-pJ-Operation Scalable Computing The PULP Experience
http://www.pulp-platform.org

2
IoT: Near-Sensor Processing
Image
Voice/Sound
Inertial
Biometrics
Extremely compact output (single index, alarm, signature)
Computational power of ULP µControllers is not enough
Tracking:
Speech:
Kalman:
SVM:
80 Kbps
INPUT BANDWIDTH
COMPUTATIONALDEMAND
OUTPUT BANDWIDTH
1.34 GOPS 0.16 Kbps
256 Kbps 100 MOPS 0.02 Kbps
2.4 Kbps 7.7 MOPS 0.02 Kbps
16 Kbps 150 MOPS 0.08 Kbps
[*Nilsson2014]
[*Benatti2014]
[*Lagroce2014]
[*VoiceControl]
Parallel worloads
COMPRESSION FACTOR
500x
12800x
120x
200x

3
System View
Battery + Harvesting powered a few mW power envelope
Long range, low BW
Short range, BW
Low rate (periodic) data
SW update, commands
Transmit
Idle: ~1µWActive: ~ 50mW
Analyze and Classify
µController
IOs
1 ÷ 25 MOPS1 ÷ 10 mW
e.g. CotrexM
Sense
MEMS IMU
MEMS Microphone
ULP Imager
100 µW ÷ 2 mW
EMG/ECG/EIT
L2 Memory
1 ÷ 2000 MOPS1 ÷ 10 mW

Near-Threshold Multiprocessing

Minimum energy operation
0.0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 1.1 1.2
Total EnergyLeakage EnergyDynamic Energy
0.55 0.55 0.55 0.55 0.6 0.7 0.8 0.9 1 1.1 1.2
Ener
gy/C
ycle
(nJ)
32nm CMOS, 25oC
4.7X
Logic Vcc / Memory Vcc (V)
Source: Vivek De, INTEL – Date 2013
Near-Threshold Computing (NTC): 1. Don’t waste energy pushing devices in strong inversion
2. Recover performance with parallel execution5

Micro-MMU (demux)
L1 TCDM+T&SMB0 MBM
. . . . .
Near-Threshold Multiprocessing
4-stage, in-order RiscVand OpenRISC ISAs
I$I$B0 I$Bk
Shared L1 I$ with Multi-instruction load
IL0 IL0 Private Loop/Prefetch Buffer
Ultra-low power scalable computing
Shared L1 DataMem + Atomic Variables
NT but parallel Max. Energy efficiency when Active + strong PM for (partial) idleness
PE0 PEN-1
DMA
Tightly Coupled DMA
Periph+ExtM
N Cores
6
1.. 8 PE-per-cluster, 1…32 clusters

7
Technology UTBB FD-SOI 28nm
Transistors Flip wellL = 24 nm
Cluster area 1.3 mm2
VDD range(memories)
0.32V - 1.15V(0.45 – 1.15V)
BB range
0V - 1.75V
SRAM macros
8 x 32 kbit (TCDM)
SCM macros
16x4 kbit (TCDM)4x 2x4 kbit (I$)
Gates 200K
Frequency range
NO BB: 40.5-710 MHz MAX FBB: 63.5 - 825 MHz
Power range
NO FBB: 0.56 - 85 mWMAX FBB: 6.9 - 480 mW
PULP Chips
ISSCC15 (student presentations), Hot Chips 15, ISSCC16 (paper+student presentation)7

8
Technology UTBB FD-SOI 28nm
Transistors Flip wellL = 24 nm
Cluster area 1.3 mm2
VDD range(memories)
0.32V - 1.15V(0.45 – 1.15V)
BB range
0V - 1.75V
SRAM macros
8 x 32 kbit (TCDM)
SCM macros
16x4 kbit (TCDM)4x 2x4 kbit (I$)
Gates 200K
Frequency range
NO BB: 40.5-710 MHz MAX FBB: 63.5 - 825 MHz
Power range
NO FBB: 0.56 - 85 mWMAX FBB: 6.9 - 480 mW
PULP Chips
ISSCC15 (student presentations), Hot Chips 15, ISSCC16 (paper+student presentation)8

9

Near threshold FDSOI technology
10
Body bias: Highly effective knob for power & variability management!

11
Body Biasing forVariability Management
120°C
-40°C25 MHz ± 7 MHz (3σ)
Thermal inversionProcess variation
FBB/RBB
FREQUENCY + LEAKAGE
COMPENSATION WITH ± 0.2 BB
FREQUENCY + LEAKAGE
COMPENSATIONWITH -1.8 to +0.5 BB
RVT transistors
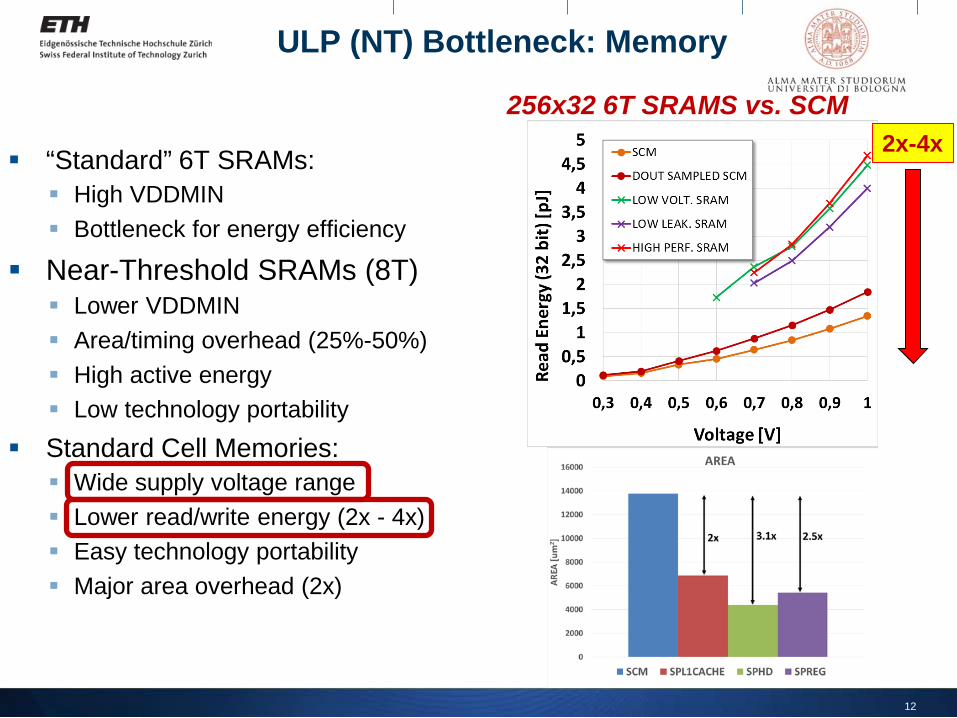
ULP (NT) Bottleneck: Memory
12
“Standard” 6T SRAMs: High VDDMIN Bottleneck for energy efficiency
Near-Threshold SRAMs (8T) Lower VDDMIN Area/timing overhead (25%-50%) High active energy Low technology portability
Standard Cell Memories: Wide supply voltage range Lower read/write energy (2x - 4x) Easy technology portability Major area overhead (2x)
2x-4x256x32 6T SRAMS vs. SCM

Static vs. Dynamic again…
L2MEMORY
PERIPHERALS
BRID
GE
BRID
GE
SoCVOLTAGE DOMAIN(0.8V)
INSTRUCTION BUS
I$ I$ I$PE#0
PE#1
PE#N-1
BRID
GES
CLUSTER VOLTAGEDOMAIN(0.5V-0.8V)
LOW LATENCY INTERCONNECT
DMA...
...CL
UST
ER B
US
PERI
PHER
AL
INTE
RCO
NN
ECT
PER
IPH
ERAL
S
to RMUs
...
RMU RMURMU
SRAM#0
SRAM#1
SRAM #M-
1
SCM #0
SCM #M-1
SCM #1
SRAM VOLTAGE DOMAIN (0.5V – 0.8V)
Hybridmemorysystem
13
Near-threshold + ULP architecture + Dynamic adaptation 2-3pJ/OP

High-Dynamic Range Energy-efficient Computing

HDR Arithmetic1 - 10 mW
HDR Arithmetic Desirable
• Fixed-point: labor intensive, error-prone, quality losses
• Energy-efficient, low-cost HDR arithmetic desirable
ULP Processing
System
100 µW - 2 mW Idle: ~1µWActive: ~ 50mW

Logarithmic Number System (LNS)
• Alternative for standard Floating Point (FP)
• A = sign * 2(fixed point number)
• Nonlinear ADD, SUB, I2F, F2I
• function interpolator → large LNS FPU (LNU)
1 8 23
LNS: fixed-point exponent
FP: integer exponent FP: integer mantissa

Efficient LNS operations
Multiplication/ Division:
• C = A */ B with A = 2a, B = 2b, C = 2c
• c = log2(2a */ 2b) = log2(2a ± b) = a ± b
Square-roots:
• C = sqrt(A) with A = 2a, C = 2c
• c = log2(sqrt(2a)) = log2(20.5a) = 0.5a = a >> 1
Simple integer operations!

Core 0 Core 1 Core 2 Core 3
FPU FPU FPU FPU
INT operations
HDR-ADD/SUB/MUL
Private Floating Point Units

Core 0 Core 1 Core 2
FPU
Core 3
INT operations
LNU
• Area: 1 LNU ≈ 5 × standard IEEE compliant FPU (no DIV)
• Poor LNU utilization ~ 0.2
Logarithmic Number Unit (LNU)
FPU
LNU
FPU
LNU
FPU
LNU
HDR MUL/DIV/SQRTADD/SUB

Shared LNU
Core 0 Core 1 Core 2 Core 3Core 0
Interconnect
Arbiter
LNU
INT operationsHDR-MUL/DIV/SQRT
HDR-ADD/SUB/EXP/LOG
Shared pipelined LNU: amortize area overhead, good utilizazion and low contention

Chip Micrographs
Area breakdown Private FPU Shared LNUTotal area [kGE] 719 749FPU/LNU area [kGE] 4 x 10.8 53.1
1.25
mm
1.25 mm
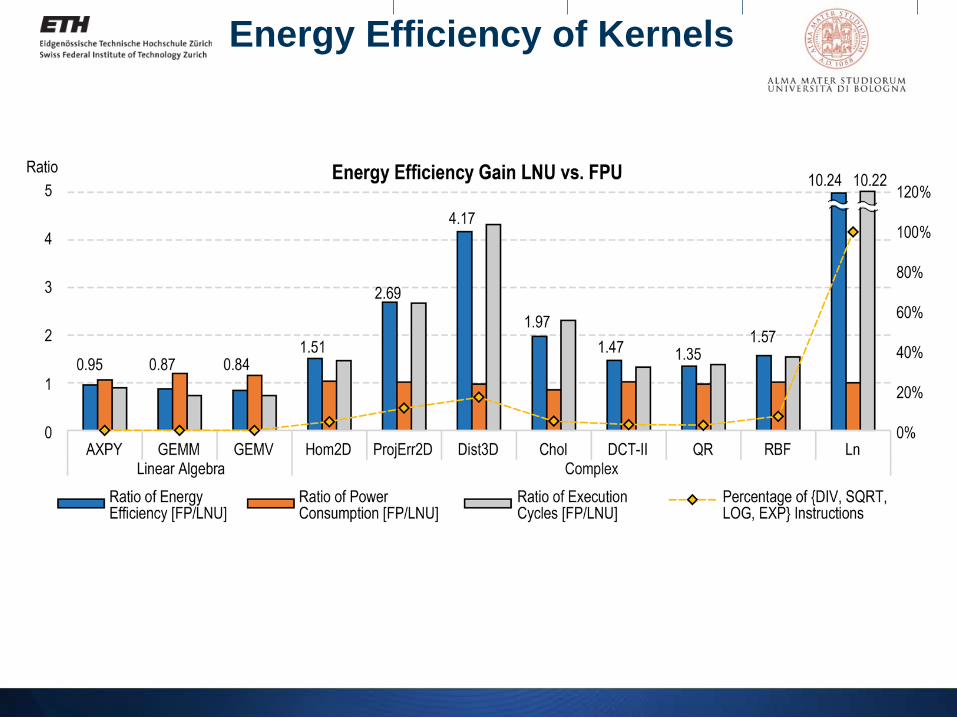
Energy Efficiency of Kernels

Comparison
[1] J.N. Coleman et al. "The European Logarithmic Microprocessor" IEEE TC, 2008[2] R.C. Ismail et al. "ROM-less LNS" IEEE ARITH, 2011
Implementation Details Private FPU Shared LNU ELM [1,2]Technology 65nm LVT 65nm LVT 180nmMax speed [MHz] 374 337 125
Functionality +, -, *, casts +, -, *, /, exp,log, casts +, -, *
Precision (max err) [ulp] 0.5 0.478 0.454Avg. LNU/FPU utilization 0.21 0.37 -Avg. # stalls due to contentions - 4% -Power @100MHz, 1.2V, 25°C [mW] 41.84 44.0 -
Leakage @ 1.2V, 25°C [mW] 2.823 3.019 -Energy efficiency gain (complex) 1 1.35 - 4.17

Pushing Beyond pJ/OP

Recovering more silicon efficiency
1 > 1003 6
CPU GPGPU HW IP
GOPS/W
Accelerator Gap
SW HWMixed
ThroughputComputing
General-purposeComputing
Closing The Accelerator Efficiency Gap with Agile Customization
25

Learn to Accelerate
Brain-inspired (deep convolutional networks) systems are high performers in many tasks over many domains
Image recognition[Russakovsky et al., 2014]
Speech recognition[Hannun et al., 2014]
26
Flexible acceleration: learned CNN weights are “the program”
CNN: 93.4% accuracy (Imagenet 2014)Human: 85% (untrained), 94.9% (trained)
[Karpahy15] Spiking NN Accelerator

27
Computational Effort
Computational effort 7.5 GOp for 320x240 image 260 GOp for FHD 1050 GOp for 4k UHD
~90%
Origami chip

Origami: A CNN Accelerator
FP needed? 12-bit signals sufficient Input to classification double-vs-12-bit
accuracy loss < 0.5% (80.6% to 80.1%)
28

Sub pJ/OP and more…
0% bit flips
1% bit flips67% energy improvement
29
From 0.5 to 0.1pJ/OP!

30
Open SourceParallel ULP computing for the IoT
(sub)-pJ/op computing platform - let’s make it Open!
VirtualizationLayer
CompilerInfrastructure
Programming Model
Processor &Hardware IPs

Main PULP chips (ST 28nm FDSOI) PULPv1 (see slide 7) PULPv2 (see sliee 7) PULPv3 (under test) PULPv4 (in progress)
PULP development (UMC 65nm) Artemis - IEEE 754 FPU Hecate - Shared FPU Selene - Logarithic Number System FPU Diana - Approximate FPU Mia Wallace – full system Imperio - PULPino chip Fulmine – Secure cluster + CNN
RISC-V based systems (GF 28nm) Honey Bunny
Early building blocks (UMC180) Sir10us Or10n
Mixed-signal systems (SMIC 130nm) VivoSoC EdgeSoC (in planning)
IcySoC chips approx. computing platforms (ALP 180nm) Diego Manny Sid
More to come….
06.01.20 31
PULP related chips
180nm
130nm
28nm 28nm 28nm 65nm 65nm 65nm 65nm 65nm
180nm 180nm 180nm
180nm
28nm

Conclusions
IoT a Challenge and an opportunity Computing Everywhere!
Energy efficiency requirements: pj/OP and below Technology scaling alone is not doing the job for us Ultra-low power architecture and circuits are needed, but not
sufficient in the long run
HDR computing (FP equivalent) is feasible at a reasonableenergy budget
Non-Von-Neumann + Approximation… Jackpot potential! Open Source HW & SW approach for building an
innovation ecosystem
32

Thanks for your attention!!!
www.pulp-platform.orgwww-micrel.deis.unibo.it/pulp-project
iis-projects.ee.ethz.ch/index.php/PULP