streaming data with apache kafka
TRANSCRIPT

Marko Bonaći

Apache Kafka general info● originated at LinkedIn● open sourced in early 2011● implemented in Scala, client libraries in Java● many other client libraries:
○ C++, Go, JS/Node, Clojure, Ruby, ...

Motivation at LinkedIn
● many disparate data sources and destinations● a need to move data around reliably● existing solutions not adequate

Requirements
● low latency● huge throughput● online and offline consumers● zero data loss● fault-tolerance
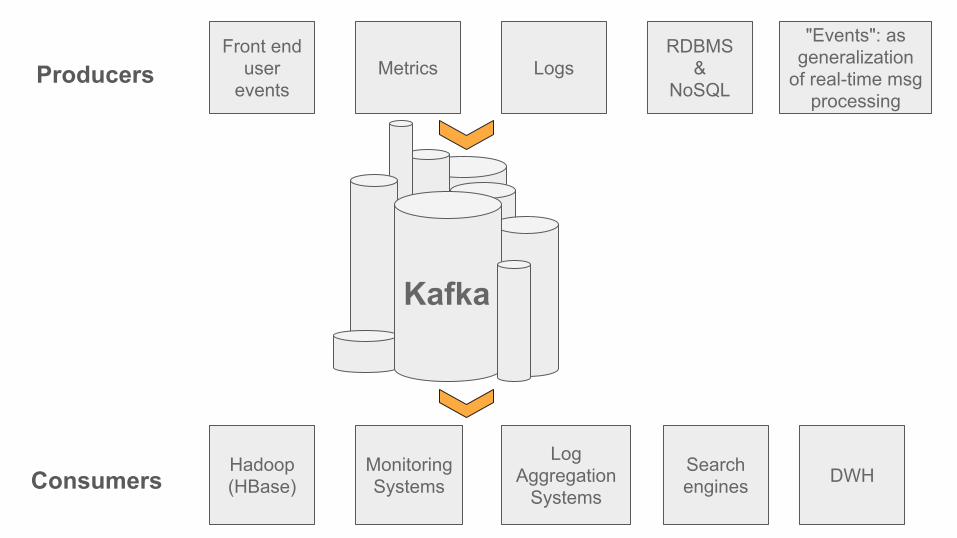
Hadoop(HBase)Consumers
Front enduser
eventsProducers Metrics Logs
RDBMS&
NoSQL
Kafka
MonitoringSystems
LogAggregation
Systems
Search engines DWH
"Events": asgeneralization
of real-time msg processing

Terminology
● Kafka broker = serverhosts
● Topic = queueconsists of
● Partition = piece of a sliced queueis mirrored by
● Replica = backup of a Partition
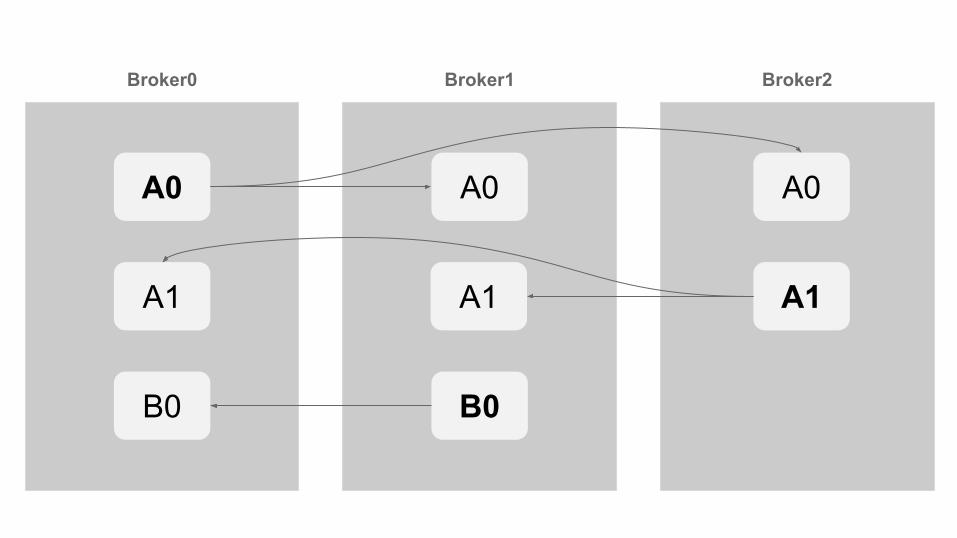
A0 A0 A0
A1 A1 A1
Broker0 Broker1 Broker2
B0 B0
0 1 2 3 Producer
0 1 2 3 4
0 1 2 3 4
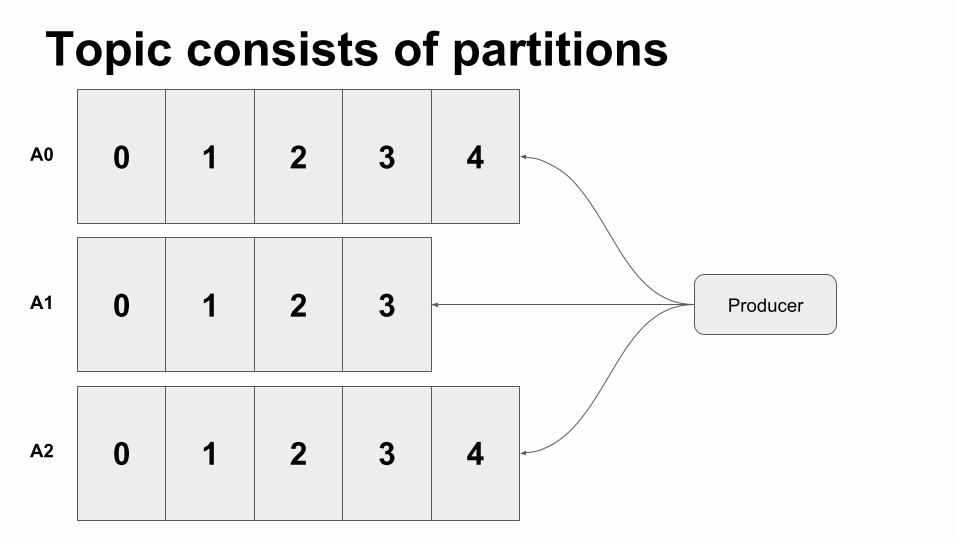
Topic consists of partitions
A0
A1
A2
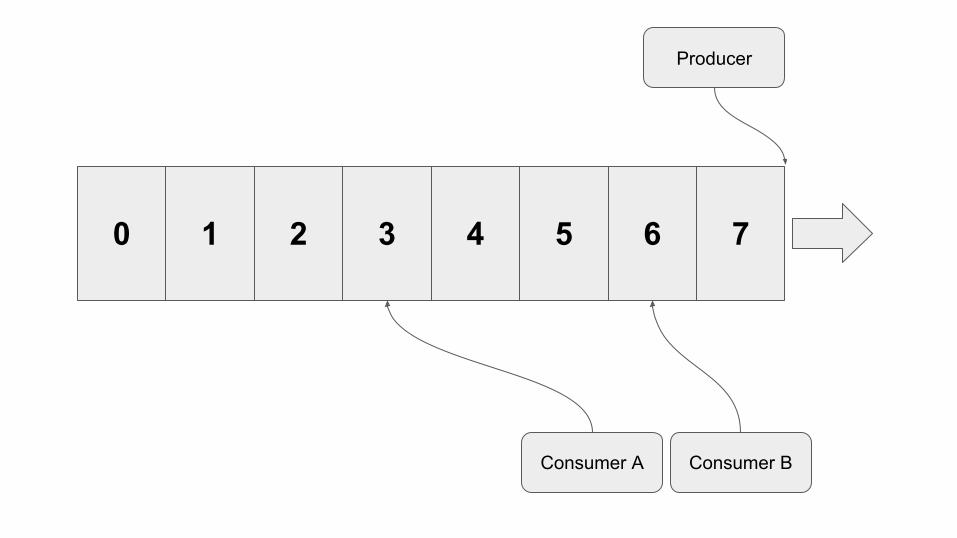
0 1 2 3 4 5 6 7
Producer
Consumer BConsumer A

Consumer offsets
● previously kept in Zookeeper● from 0.8 added ability to store offsets in a
special Kafka topic● brokers are dumb - consumers track their
offsets● ZK only needed to keep track of cluster state

Retention
● size based● time based● per-topic

Ordered and immutable
● strict ordering within partition● low and high level consumers in 0.8● number of partitions = parallelism● 1 partition = max 1 consumer thread● 1 consumer thread = one or more partitions

Impressive performance
● 3 cheap machines○ 6-core Intel Xeon 2.5GHz, 32GB RAM, 7 x 7200 RPM SATA, Gb ethernet○ 3 async producers (1 per machine, since network became saturated)
● 2M msgs/s● tens of milliseconds latency end-to-end

Impressive volumes: Kafka at LinkedIn
● 600 brokers● 30k topics● 300k partitions (not counting replicated ones)● Trillion messages per day● 120 TB/day in & 500 TB/day out● Peak load:
○ 6M messages/s○ 15 Gb/s in & 60 Gb/s out