statistical modelling(upscaling) of gross primary...
TRANSCRIPT

Statistical modelling (upscaling) of Gross Primary Production (GPP)
Martin JungMax‐Planck‐Institute of Biogeochemistry, Jena, Germany
Department of Biogeochemical Integrationmjung@bgc‐jena.mpg.de

Motivation
• Substantial uncertainty of GPP simulations of Land Surface / Terrestrial Ecosytem Models
• Independent, complementary, more observation‐based data stream with least assumptions about ecosystem functioning
• Improved diagnostics, cross‐consistency checks, LSM evaluations
Huntzinger et al 2012
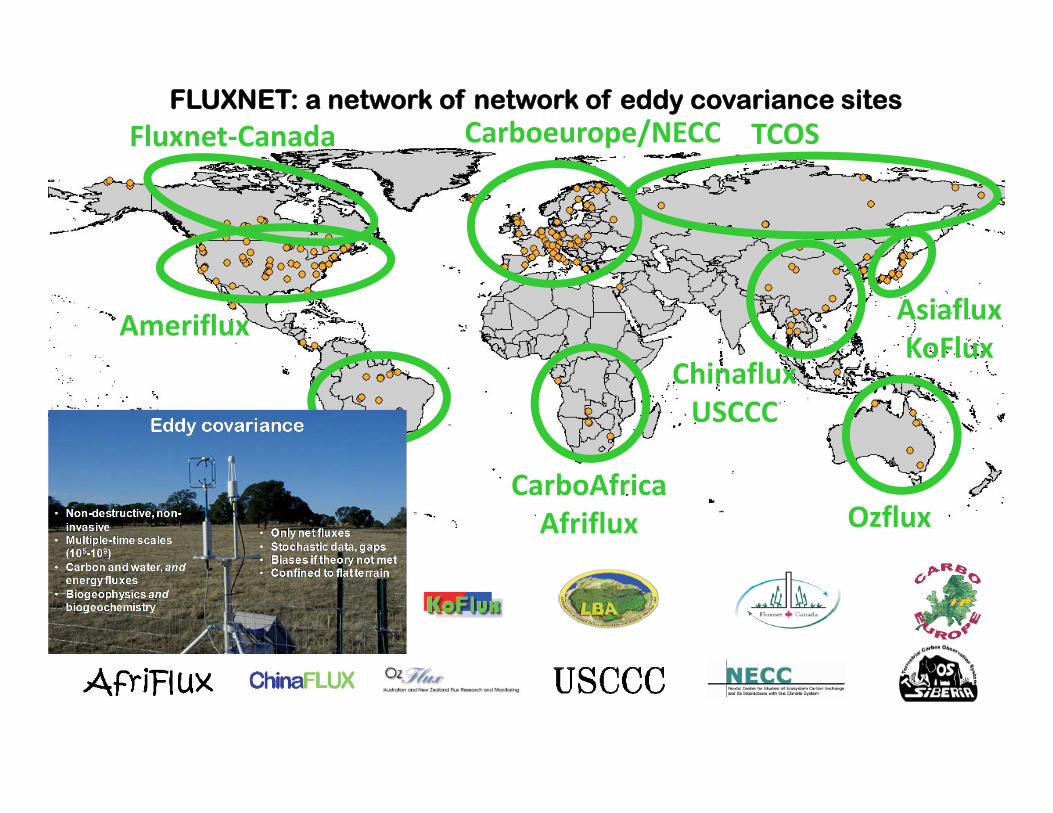
Fluxnet‐Canada
Ameriflux
LBA
CarboAfricaAfriflux
Carboeurope/NECC TCOS
AsiafluxKoFlux
Ozflux
ChinafluxUSCCC
FLUXNET: a network of network of eddy covariance sites

FLUXNET gridded products rationale:
(Direct) observations
(Free-running) C4-models
OfflineDGVM
Remote sensingmodels (CASA,
MOD17)
Empirical ‘models’
Assumptions about systemAssumptions about system
Observational inputObservational input
… be as much as possible on observational side!

remote sensingof CO2
Tem
pora
l sca
le
Spatial scale [km]
hour
day
week
month
year
decade
century
local 0.1 1 10 100 1000 10 000 globalCountries EUplot/site
talltowerobser-
vatories
Gridded Forest/soil inventories
Eddycovariance
towers
Landsurface remote sensing
From point to globe via integration with remote sensing
Tree rings

fSite-level explanatory variables• Meteorology• Vegetation type• Remote sensing
indices
Target variableecosystem-atmosphere flux
The same gridded explanatory variables
Gridded targetvariable
Application
General Principle


‘Proof of concept’

FLUXNET representativeness

Upscaling strategy using a model tree ensemble (MTE)
Jung et al. (2009) BG
A Model TREE
Advantages:
• ‚Functional‘ stratification
• Intuitive• Can cope with
switches• Seemless integration
of categorical variables
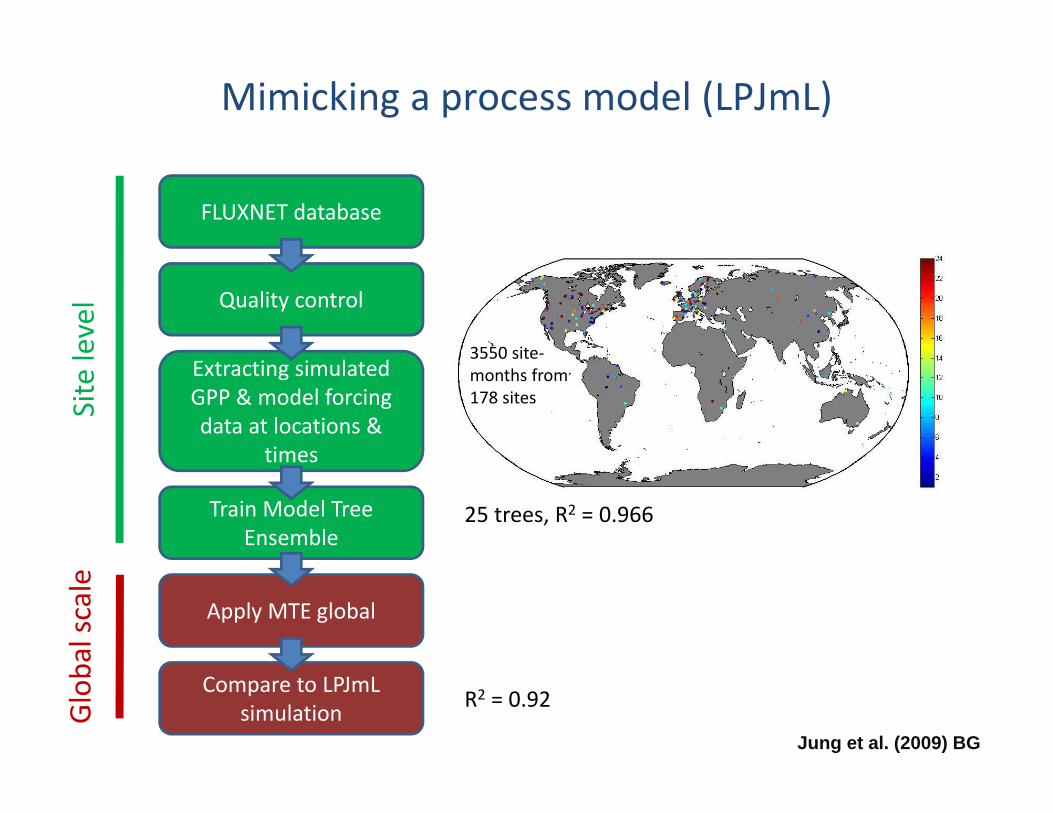
Mimicking a process model (LPJmL)
FLUXNET database
Quality control
Extracting simulated GPP & model forcing data at locations &
times
Train Model Tree Ensemble
Apply MTE global
Compare to LPJmL simulation
25 trees, R2 = 0.966
3550 site‐months from 178 sites
R2 = 0.92
Jung et al. (2009) BG
Site level
Global scale
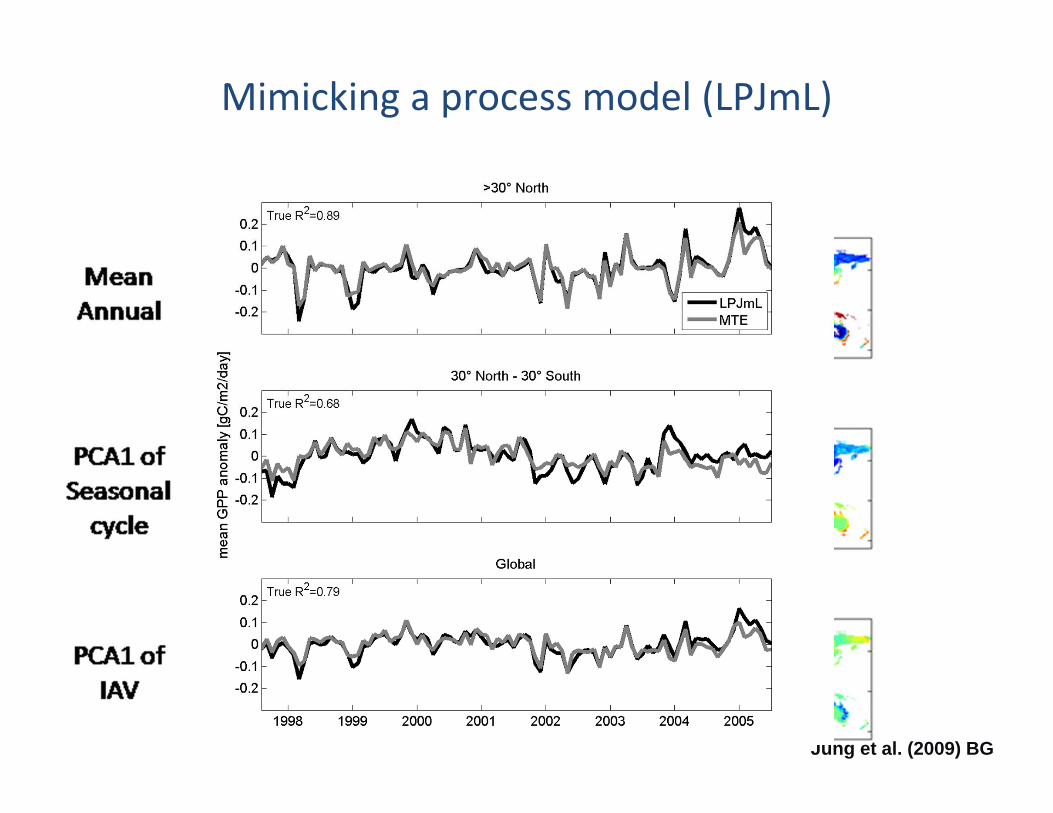
=‚observed‘ =emprically upscaled
Jung et al. (2009) BG
Mimicking a process model (LPJmL)

The value of ‘ensemble magic’

Moving to upscaling with real world observations

Comparison of two flux partitioning methods
Lasslop et al 2010

0 40 80 120160200240280320360400GPP_ust_range_full [gC m-2 year-1]
0.00.1
0.2
0.3
0.40.5
77
118
6148
28 2413 9 8
2 5 1 1 3 2 2 0 3 2 0
Uncertainty due to u* filtering
Reichstein et al in prep

Quality control
• Remove data points with more than 20% of gapfilling
• Remove outliers from the comparison of Reichstein vs Lasslop flux partitioning methods (monthly data)
• Remove 5% of data that show largest uncertainty due to u* filtering (monthly data)

Inputs

Cross‐validation resultsdata from EACH SITE were partitioned into 5 parts
Site 1Site 2Site 3Site 4Site 5
time… … … … … …
data from entire sites were left out
Site 1Site 2Site 3Site 4Site 5
time… … … … … …

Possible reasons why anomalies are (apparently) predicted poorly
• low signal to noise ratio of monthly anomalies of eddy covariance data
• Large noise in site‐level remote sensing data• Substantial ‘non‐climatically’ caused anomalies in FLUXNET data (e.g. management, disturbances, manipulations)
• Anomalies due to ecophysiological variations that change the sensitivity to meteo and biophysical properties

Global Results
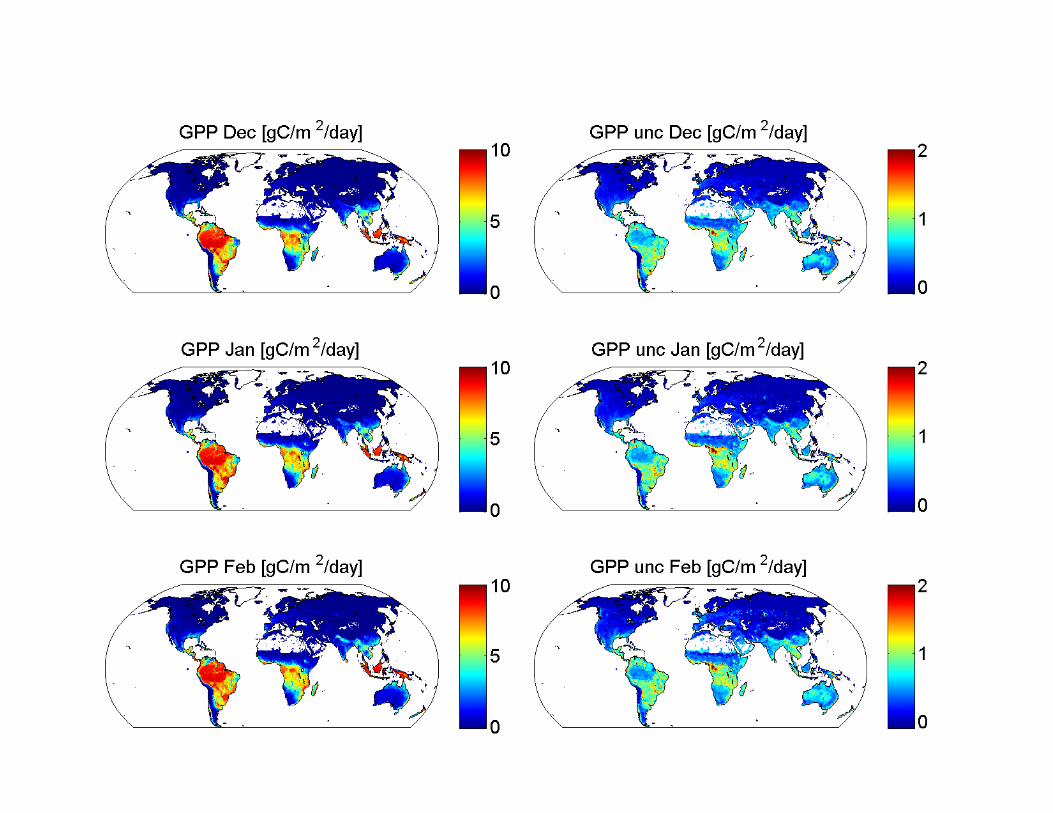



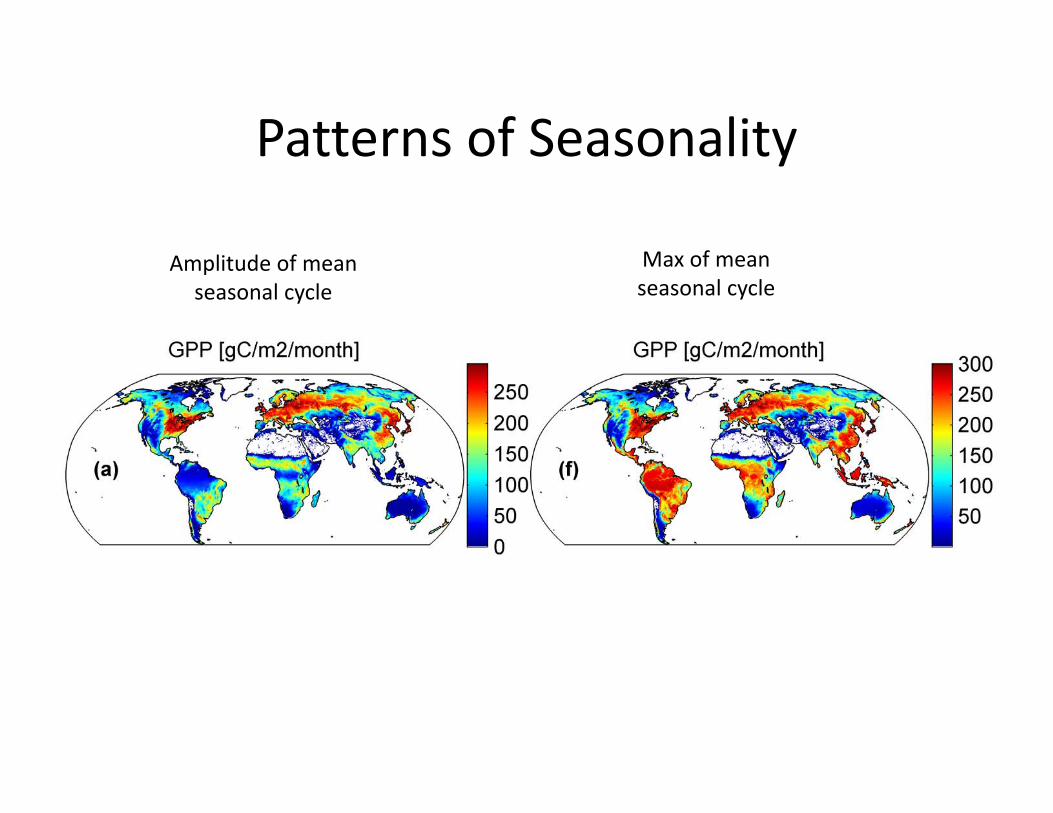
Patterns of Seasonality
Amplitude of mean seasonal cycle
Max of mean seasonal cycle

Hot spots of interannual variability

Towards improving …

The 4 principal dimensions
Injected Information
Data quality Data quantity
Regression Algorithm
Where is the bottleneck?

Sandbox analysis I: Do we use a suitable algorithm?

Sandbox analysis II: Are we limited by the number of sites?
A monte‐carlo test with Random Forests

Aerial photo
Remote sensing data quality issues
Landsat
MODIS
1 km

Towards a coordinated set of experiments and intercomparisons:

Concrete FLUXCOM goals
• To deliver a best estimate ensemble product of carbon and energy fluxes from an ensemble of diverse data‐oriented and FLUXNET based approaches.
• To study and if possible quantify sources of uncertainty which hopefully leads to improved strategies with reduced uncertainty along the way of the FLUXCOM activity.
• To come up with a practice guidance regarding regionalization of FLUXNET data.
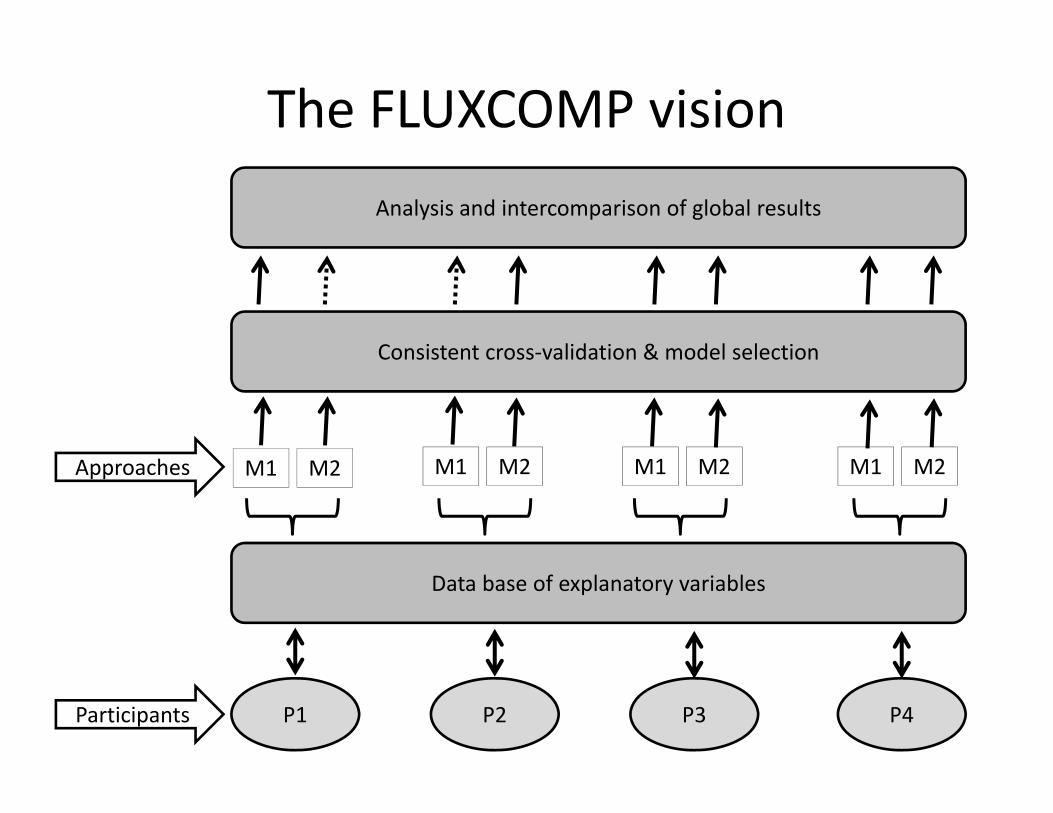
Data base of explanatory variables
P1 P3P2 P4
M1 M2 M1 M2 M1 M2 M1 M2
Consistent cross‐validation & model selection
Analysis and intercomparison of global results
Participants
Approaches
The FLUXCOMP vision

Current Participants
Name Method/Model Approach
Kazuhito Ichii SVM Machine Learning
Dario Papale ANN Machine Learning
Antje Moffat ANN Machine Learning
Gustavo Camps‐Valls ANN Machine Learning
Christopher Schwalm ANN Machine Learning
Martin Jung MTE, RF Machine Learning
Enrico Tomelleri MOD17+ Model‐Data‐Fusion
Nuno Carvalhais CASA Model‐Data‐Fusion
Timothy Hilton VPRM Model‐Data‐Fusion
Anthony Bloom DALEC Model‐Data‐Fusion

Some quick pre‐FLUXCOM comparison (fully unharmonized)
• SVM (Kazuhito Ichii)• ANN ensembles (Dario Papale)• MTE (Martin Jung)• MOD17+ (Enrico Tomelleri)

GPP Mean annual fluxesgC
m-2
y-1
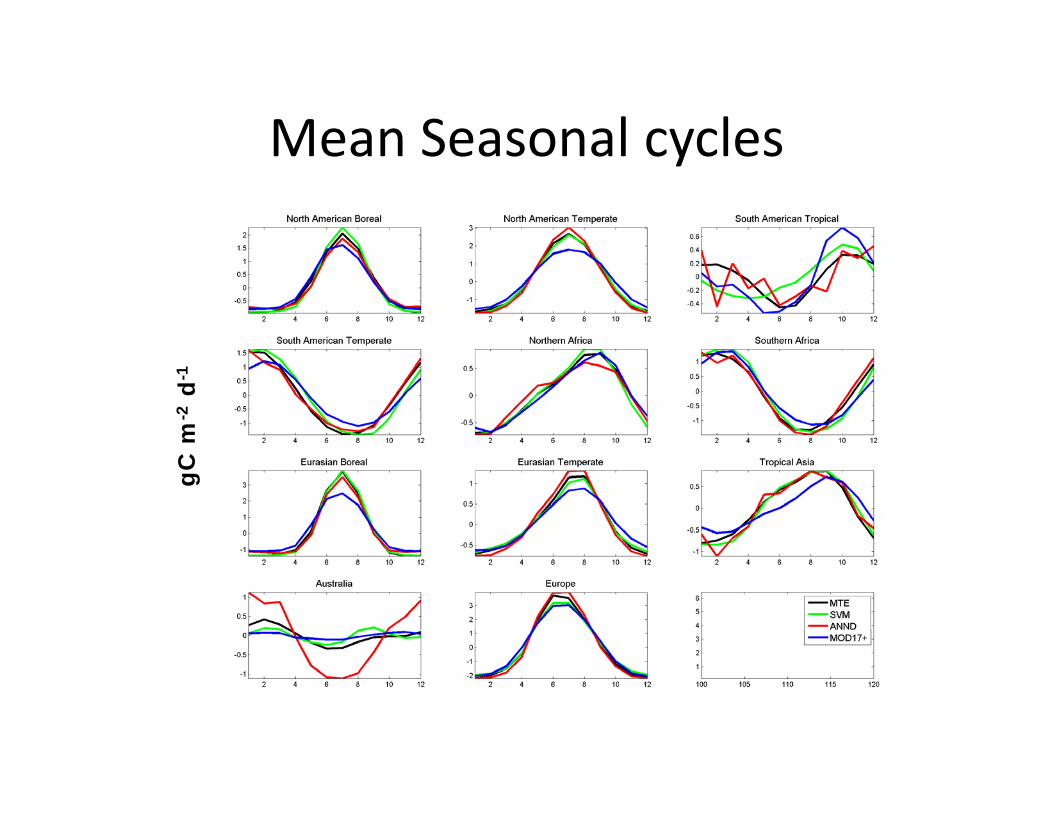
Mean Seasonal cyclesgC
m-2
d-1

FLUXCOM products will capitalize on:
• An ensemble (of ensembles ) of estimates• Higher temporal and spatial resolution• More injected information (variables)• ~twice the amount of La Thuille FLUXNET data

The 4 principal dimensions
Injected Information
Data quality Data quantity
Regression Algorithm

Which and how many variables are needed?
• Injected Information = f(availability, imagination)• potentially large set feature selection problem
• Consider some trade‐offs … Climate variables
Precise in‐situ measurements
Need coarse resolution climate data for global upscaling
Uncertainty and biases of global climate fields
Satellite variables
No product switch necessary from site to globe
High res global output possible
Very noisy at site‐levelTower satellite footprint mismatch
gaps

# candidate variables
# selected
CLIM+SAT 166 10
CLIM+SAT (ANO) 166 16
SAT 165 9
CLIM 61 7
Some experiments with a feature selection algorithm and Random
Forests?

Results based on 10‐fold cross‐validation and bootsrapping

On the evaluation of the productsSite‐level cross‐validation is important and valuable to compare different approaches and set‐ups but…
Is a not sufficient evaluation of global fields because:
• Biased sampling of biosphere by tower sites• Noise and site‐specific peculiarities at site‐level• Doesn’t capture uncertainties of global driversNeed for an independent, observational based approach
Fluorescence

If photosynthesis is so complicated why can we get the big picture of gpp relatively easily from sparse data?
- Adaptation to the environment
- At ecosystem scale everything scales with LAI/FPAR
What is the added value of fluoresence?
Does it track physiological regulations that control interannual variability?

Thank you very much for your attention!

Interannual variabilitygC
m-2
d-1

Conclusions
• Global upscaling from FLUXNET is feasible• A new observation driven data stream• Known issues:
– Spatial distribution of mean NEE– Underestimation of interannual variability
• Largest potential for future improvements: adding informative variables
• Plan of a coordinated intercomparison(FLUXCOMP)
• Global products are available on request
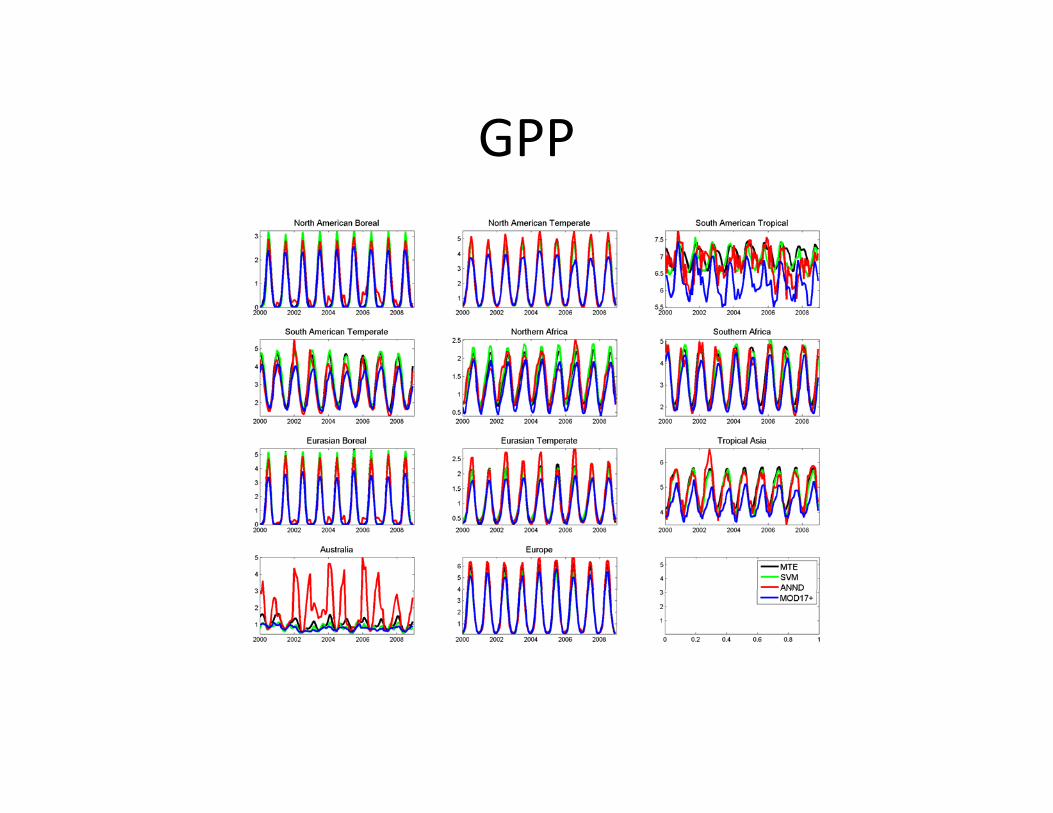
GPP

Uncertainties of empirical upscaling
Empirical model/Upscaling tool
Global gridded datasets
In‐situ data (FLUXNET)
Quality control:‐ Gap filling‐ u* uncertainty‐ Consistency of flux partitionings‐ Consistency of energy budget
‐ Avoiding problematic variables (e.g. VPD)‐ Identify & use good quality products‐ sensitivity studies with various forcings
‐ use various approaches‐ ensemble methods‐ artificial experiments

GPP anomaly snapshots (gC m-2 mo-1)
Jung et al. in prep 52