statistical learning: pattern classification, prediction, and control peter bartlett august 2002, uc...
Post on 22-Dec-2015
220 views
TRANSCRIPT

Statistical Learning:Pattern Classification, Prediction, and Control
Peter Bartlett
August 2002, UC Berkeley CIS

Statistical Learning
• Pattern classification• Key issue: balancing complexity• Large margin classifiers• Multiclass classification• Prediction• Control

Pattern Classification
• Given training data, (X1,Y1 ),… ,(Xn,Yn ), find a prediction rule f to minimize
• For example:– Recognizing objects in an image.– Detecting cancer from a blood serum mass
spectrogram.

• The key issues:• Approximation error• Estimation error• Computation
Mass Spectrometer
Serumsamples
ClassifierNormalCancer
5000 7500 10000 12500
5000 7500 10000 12500
Weak cation exchange pH 4.5 wash
Pattern Classification

Pattern Classification Techniques
• Linearly parameterized (perceptron)• Nonparametric (nearest neighbor)• Nonlinearly parameterized
– Decision trees– Neural networks
• Large margin classifiers– Kernel methods– Boosting

Pattern Classification• A key problem in pattern classification is
balancing complexity.• A very complex model class has
– good approximation, but– poor statistical properties.
• It is important to know how the model complexity and sample size affect the performance of a classifier.
Motivation: Analysis and design of learning algorithms.

Minimax Theory for Pattern Classification
• Optimize the performance in the worst case over classification problems (probability distributions).
• The minimax performance of a learning system is characterized by the capacity of its model class (VC-dimension).
• For many model classes, this is closely related to the number of parameters, d:– Linearly parameterized (=d)– Decision trees, neural networks (¼ d log d)– Kernel methods, boosting (¼ d=1)
(Vapnik and Chervonenkis, et al)

Regularization
• Choose model to minimize (empirical error) + (complexity
penalty)
• e.g.
complexity
approximationerror
estimationerror/penalty

Data-Dependent Complexity Estimates
• More refined: use data to measure (and penalize) complexity.
• Performance can be significantly better than minimax.

Data-Dependent Complexity Estimates
• Minimizing the regularized criterion is hard.
• Large margin classifiers solve a simpler version of this optimization problem. For example,– Support vector machines– Adaboost

Large Margin Classifiers
• Two class classification: Y 2 {§ 1}.
• Aim to choose a real-valued function f to minimize risk,
• Consider the margin, Yf(X):– Positive if sign of f is correct,– Magnitude indicates confidence of prediction.
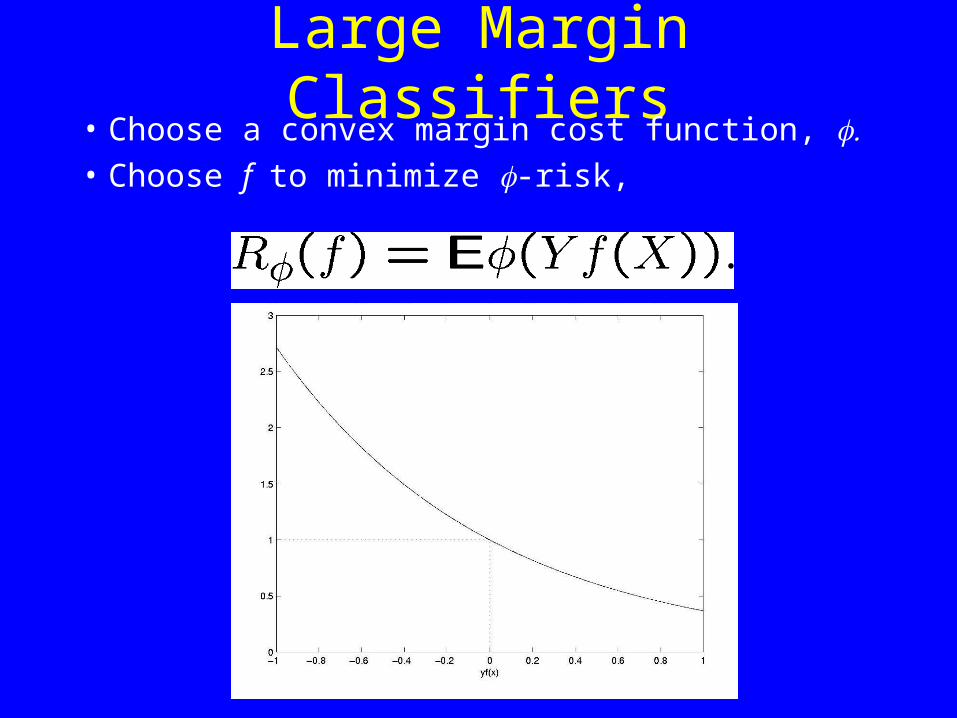
Large Margin Classifiers• Choose a convex margin cost function, • Choose f to minimize -risk,

Large Margin Classifiers
• Adaboost: ()=exp(-).
• Support vector machine: ()=max(0,1-).
• Other kernel methods: ()=max(0,1-)2.
• Neural networks: ()=(1-)2.
• Logistic regression: ()=log(1+exp(-2)).

Large Margin Classifiers: Results
• Optimizing (convex) risk:– Computation becomes tractable,– Statistical properties are improved, but– Worse approximation properties.
• Universal consistency. (Steinwart)
• Optimal estimation rates; with low noise, better than minimax.

More Complex Decision Problems
• Two-class classification…• There are many challenges in more
complex decision problems:– Data analysis:
• multiclass pattern classification,• anomaly detection,• ranking,• clustering, etc.
– Prediction– Control

Multiclass Pattern Classification
• In many pattern classification problems, the number of classes is large, and different mistakes have different costs. For example,– Computer vision: Recognizing objects in an
image.– Bioinformatics: Predicting gene function from
expression profiles.

Multiclass Pattern Classification
• The most successful approach in practice is to convert multiclass classification problems to binary classification problems.
• Issues:– Code design.– Simultaneously optimize code and classifiers. (Minimal
statistical penalty for choosing the code after seeing the data.)
– Optimization?
• More direct approach?

Prediction with Structured Data
• These problems arise, for example, in– Natural language processing,
– WWW data analysis,
– Bioinformatics (gene/protein networks), and
– Analysis of other spatiotemporal signals.
• Simple heuristics (n-grams, windows) are limited.• Challenge: automatically extract from the data
relevant structure that is useful for prediction.

Control: Sequential Decision Problems
• Examples:– Robotics.
– Choosing the right medical treatment.
– In drug discovery, choosing a suitable sequence of candidate drugs to investigate.
• Approximation/Estimation/Computation:– Complexity of a model class?
– Can it be measured from data and experimentation?

Control: Sequential Decision Problems
• Reinforcement learning + control theory:– Adaptive control schemes with performance,
stability guarantees?
• For control problems with discrete action spaces, are there analogs of large margin classifiers, with similar advantages - improving estimation properties by sacrificing approximation properties?

Statistical Learning
• We understand something about two-class pattern classification.
• More complex decision problems:– prediction– control