statistical analysis and machine learning using hadoop seungjai min samsung sds
TRANSCRIPT

Statistical Analysis and Machine Learning using Hadoop
Seungjai Min
Samsung SDS

Knowing that…
Hadoop/Map-Reduce has been successful
in analyzing unstructured web contents
and social media data
Another source of big data is semi-
structured machine/device generated logs,
which require non-trivial data massaging
and extensive statistical data mining
2

Question
Is Hadoop/Map-Reduce the right
framework to implement statistical
analysis (more than counting and
descriptive statistics) and machine
learning algorithms (which involve
iterations)?
3

Answer and Contents of this talk
Yes, Hadoop/Map-Reduce is the right
framework– Why is it better than MPI and CUDA?
– Map-Reduce Design Patterns
– Data Layout Patterns
No, but there are better alternatives– Spark/Shark (as an example)
– R/Hadoop (it is neither RHadoop nor Rhive)
4

Contents
Programming Models– Map-Reduce vs. MPI vs. Spark vs. CUDA(GPU)
Map-Reduce Design Patterns– Privatization Patterns (Summarization / Filtering / Clustering)
– Data Organization Patterns (Join / Transpose)
Data Layout Patterns– Row vs. Column vs. BLOB
Summary– How to choose the right programming model for your
algorithm
5

6
Parallel Programming is Difficult
Too many parallel programming models (languages)
P-threads
OpenMP UPC
Co-array Fortran
Chapel
X10
MPI
Cilk
Fortress
RapidMind
Titanium
OpenCL
PVM
Intel TBB
CUDA
Brook
Erlang

MPI Framework
7
myN = N / nprocs;for (i=0; i<=myN; i++) { A[i] = initialize(i); }
left_index = …;right_index = …;
MPI_Send(pid-1, A[left_index], sizeof(int), …);MPI_Recv(pid+1, A[right_index], sizeof(int), …);
for (i=0; i<=myN; i++) { B[i] = (A[i]+A[i+1])/2.0;}
100 101 200 201 300 301
Assembly Language of the Parallel Programming
1 400
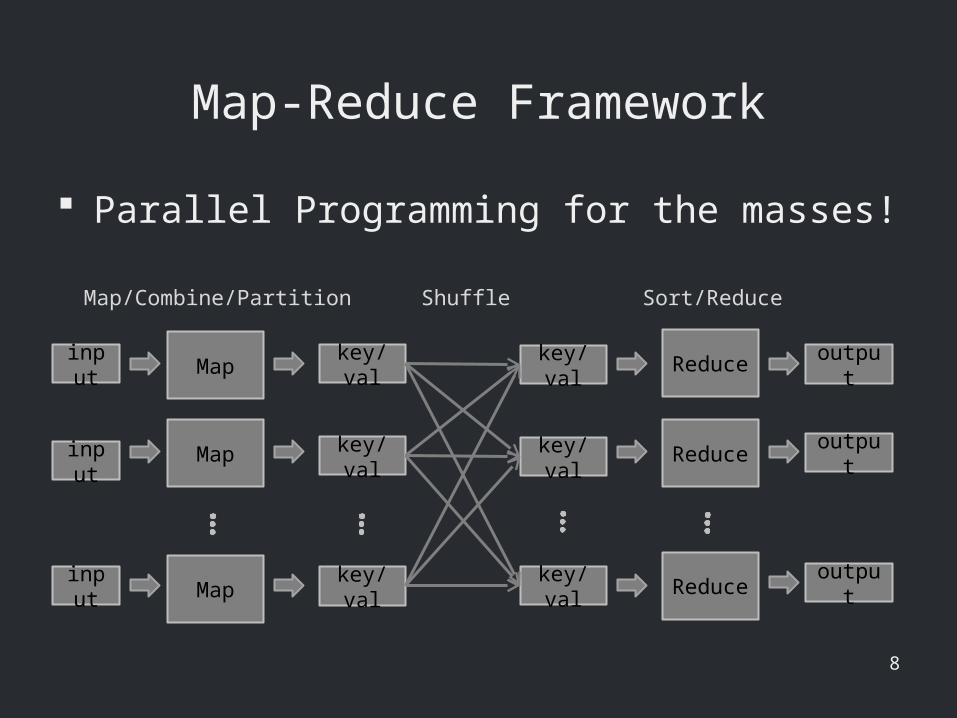
Map-Reduce Framework
8
Map
Parallel Programming for the masses!
Map
Map
Map/Combine/Partition Shuffle
Reduce
Reduce
Reduce
key/val
key/val
key/val
key/val
key/val
key/val
output
output
output
input
input
input
Sort/Reduce

Map-Reduce vs. MPI
Similarity– Programming model
• Processes not threads
• Address spaces are separate (data communications are explicit)
– Data locality • “owner computes” rule dictates that computations
are sent to where data is not the other way round
9

Map-Reduce vs. MPI
Differences
10
Map-Reduce MPI
Expressing Parallelism
Embarrassingly Parallel (Filter +Reduction)
Almost all parallel forms but not good for task parallelism
Data Communication
Under the hood Explicit / User-provided
Data Layout (Locality)
Under the hood Explicit / User-control
Fault Tolerance Under the hood None (as of MPI1.0 and MPI 2.0)

GPU
GPGPU (General Purpose Graphic Processing Units)
10~50 times faster than CPU if an algorithm fits this model
Good for embarrassingly parallel algorithms (e.g. image)
Costs ($2K~$3.5K) and Performance (2 Quad-cores vs. One
GPU)
11
GPU
Global Memory
Local Mem Local Mem
Shared memory
$
CPU
$
CPU
$
CPU
Multi-core CPUs

12
Programming CUDA
cudaArray* cu_array; // Allocate array cudaMalloc(&cu_array, cudaCreateChannelDesc<float>(), width, height); // Copy image data to array cudaMemcpy(cu_array, image, width*height, cudaMemcpyHostToDevice); // Bind the array to the texture cudaBindTexture(tex, cu_array); dim3 blockDim(16, 16, 1); dim3 gridDim(width / blockDim.x, height / blockDim.y, 1); kernel<<< gridDim, blockDim, 0 >>>(d_odata, width, height); cudaUnbindTexture(tex);
__global__ void kernel(float* odata, int height, int width) { unsigned int x = blockIdx.x*blockDim.x + threadIdx.x; unsigned int y = blockIdx.y*blockDim.y + threadIdx.y; float c = texfetch(tex, x, y); odata[y*width+x] = c; }
Hard to program/debug hard to find good engineers hard to maintain codes

13
Design Patterns in Parallel Programming
Privatization Idiom
p_sum = 0;#pragma omp parallel private(p_sum){ #pragma omp for for (i=1; i<=N; i++) { p_sum += A[i]; }
#pragma omp critical { sum += p_sum; }}

14
Design Patterns in Parallel Programming
Reduction Idiom
#define N 400#pragma omp parallel forfor (i=1; i<=N; i++) { A[i] = 1;}sum = 0;#pragma omp parallel for reduction(+:sum)for (i=1; i<=N; i++) { sum += A[i]; // dependency}printf(“sum = %d\n”, sum);

15
Design Patterns in Parallel Programming
Induction Idiom
x = K;for (i=0; i<N; i++) { A[i] = x++;}
x = K;for (i=0; i<N; i++) { A[i] = x + i;}

16
Design Patterns in Parallel Programming
Privatization Idiom
p_sum = 0;#pragma omp parallel private(p_sum){ #pragma omp for for (i=1; i<=N; i++) { p_sum += A[i]; }
#pragma omp critical { sum += p_sum; }}
Map Map
Reduce
Map
Perfect fit for
Map-Reduce
framework

17
MapReduce Design Patterns
Book written by Donald Miner & Adam Shook
1. Summarization patterns
2. Filtering patterns
3. Data organization patterns
4. Join patterns
5. Meta-patterns
6. Input and output patterns

18
Design Patterns
Linear Regression (1-dimension)
y
x
y1
y2
y3
y4
y5
x1
x2
x3
x4
x5
e1
e2
e3
e4
e5
xi
yi
b
= b * +
Y = bX + e

19
Design Patterns
Linear Regression (2-dimension)
y
x1
y1
y2
y3
y4
y5
x21
x22
x23
x24
x25
e1
e2
e3
e4
e5
= b * +
Y = bX + e
x2
x11
x12
x13
x14
x15
m
n
m: # of observationsn : # of dimension

20
Design Patterns
Linear Regression (distributing on 4 nodes)
XTX = m
n
m
n
n
n=*

21
Design Patterns
Linear Regression
(XTX)-1 = inverse of
n
n
If n2 is sufficiently small enough Apache math
library
n should be kept small Avoid curse of
dimensionalty

22
Design Patterns
Join
ID age name … … …
100 25 Bob … … …
210 31 John … … …
360 46 Kim … … …
ID time dst … … …
100 7:28 CA … … …
100 8:03 IN … … …
210 4:26 WA … … …
A.ID A.age A.name … … …
100 25 Bob … … …
210 31 John … … …
100 25 Bob … … …
100 7:28 CA … … …
100 8:03 IN … … …
210 4:26 WA … … …
B.ID B.time B.dst … … …
Inner join

23
Design Patterns
Join
… … … … … …
100 25 Bob … … …
210 31 John … … …
360 46 Kim … … …
… … … … … …
100 7:28 CA … … …
100 8:03 IN … … …
210 4:26 WA … … …
Map
Map
Map
Reduce
Reduce
Reduce
100 25 Bob …
100 25 Bob …
210 31 John …
360 46 Kim …
Networkoverhead Reduce-side Join

Performance Overhead (1)
Map-Reduce suffers from Disk I/O bottlenecks
24
Map
Map
Map
Map/Combine/Partition Shuffle
Reduce
Reduce
Reduce
key/val
key/val
key/val
key/val
key/val
key/val
output
output
output
input
input
input
Reduce
DiskI/O
DiskI/O

Performance Overhead (2)
25
Map
Map
Map
Reduce
Reduce
Reduce
Map
Map
Map
Reduce
Reduce
Reduce
Join Groupby
Map
Map
Map
Reduce
Reduce
Reduce
Decision-Tree
DiskI/O
DiskI/O
Iterative algorithms & Map-Reduce Chaining

HBase Caching
HBase provides Scanner caching and Block
caching– Scanner caching
• setCaching(int cache);
• tells the scanner how many rows to fetch at a time
– Block caching• setCacheBlocks(true);
HBase caching helps read/write performance
but not sufficient to solve our problem
26

Spark / Shark
Spark– In-memory computing framework
– An Apache incubator project
– RDD (Resilient Distributed Datasets)
– A fault-tolerant framework
– Targets iterative machine learning algorithms
Shark– Data warehouse for Spark
– Compatible with Apache Hive 27

Spark / Shark
Scheduling
28
Mesos
Spark
Hadoop
MapReduce
Mesos / YARN
SparkHadoop
MapReduce
SparkHadoop
MapReduce
LinuxLinuxLinux
- Stand-alone Spark- No fine-grained scheduling within Spark
- No fine-grained scheduling btw Hadoop and Spark
- Mesos: Hadoop dependency - YARN

29
Time-Series Data Layout Patterns
Ti1
Ti2
Ti3
Ti4
Ti5
Ti6
Ti7
Ti8
…
Ti1Ti2Ti3Ti4Ti5Ti6Ti7Ti8 … bin
Column RowBLOB
(uncompressed)
+ : no conversion- : slow read
+ : fast read/write- : slow conversion
+ : fast read/write- : slow search

30
Time-Series Data Layout Patterns
Ti1
Ti2
Ti3
Ti4
Ti5
Ti6
Ti7
Ti8
Ti9
…
RDB
RDB is columnar
Ti1Ti2Ti3Ti4Ti5Ti6Ti7Ti8 …
ColumnRow
When loading/unloading from/to RDB,
it is really important to decide whether to store in column or row format

31
R and Hadoop
R is memory-based Cannot run data
that cannot fit inside a memory
R is not thread-safe Cannot run in a
multi-threaded environment
Creating a distributed version of each and
every R function Cannot take advantage
of 3500 R packages that are already built!

32
Running R from Hadoop
t1
t2
t3
t4
…
t1M
What if the data are wide and fat?6000~7000
1M
Pros: can re-use R packages with no modification Cons: cannot handle large data that cannot fit
into memory– But, do we need large number of time-series data to
predict the future?

33
Not so big data
“Nobody ever got fired for using Hadoop on a
cluster?” – HOTCDP’12 paper
– Average Map-Reduce like jobs handle less than 14 GB
Time-series analysis for data forecasting– Sampling every minute for two-years to forecasting
next year
less than 2M rows
– It becomes big when sampling at sub-second resolution
34
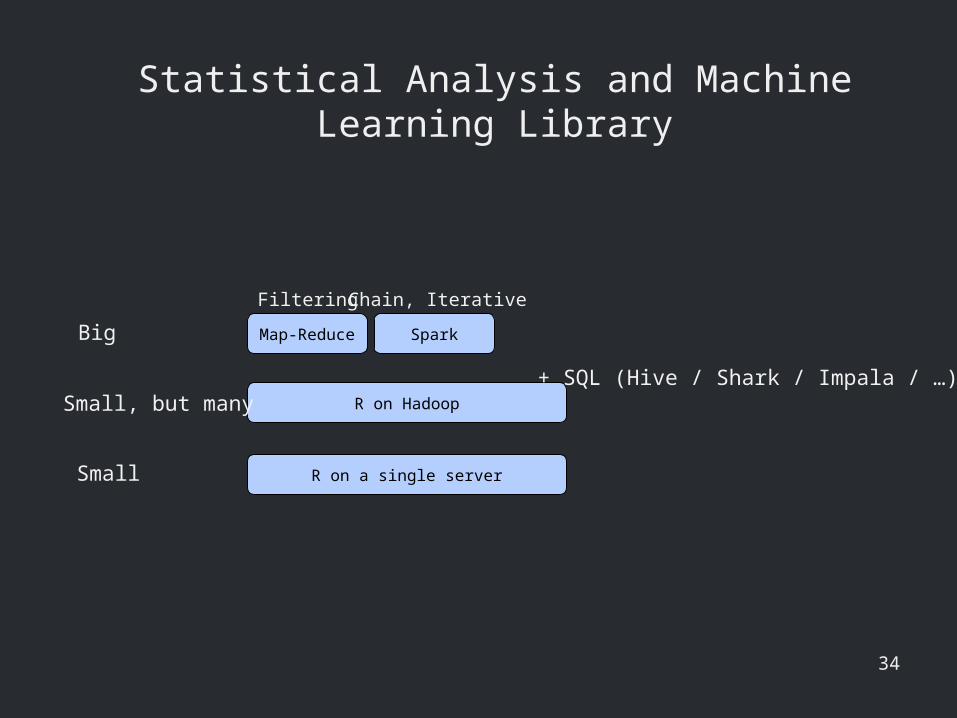
Statistical Analysis and Machine Learning Library
Map-Reduce
R on Hadoop
Spark
R on a single server
+ SQL (Hive / Shark / Impala / …)
Small
Small, but many
Big
Filtering Chain, Iterative

35
Summary
Map-Reduce is surprisingly efficient framework
for most filter-and-reduce operations
As for data massaging (data pre-processing),
in-memory capability with SQL support is a
must
Calling R from Hadoop can be quite useful
when analyzing many but, not-so-big data and
is a fastest way to increase your list of
statistical and machine learning functions

36
Thank you!