speech rhythm in english and serbian -...
TRANSCRIPT

A Critical Study of Traditional and Modern Approaches
SPEECH RHYTHM IN
ENGLISH AND SERBIAN:
Maja Bjelica
ISBN 978-86-6065-112-1
Novi Sad
2012.

Maja Bjelica
SPEECH RHYTHM IN ENGLISH AND SERBIAN:A Critical Study of
Traditional and Modern Approaches

FILOZOFSKI FAKULTET U NOVOM SADUOdsek za anglistiku
Za izdavača:prof. dr Ljiljana Subotić, dekan
Recenzenti:prof.dr Tatjana Paunović
doc. dr Biljana Radić - Bojanićdoc. dr Nataša Bikicki
ISBN 978-86-6065-111-4
Zabranjeno preštampavanje i kopiranje.Sva prava zadržava izdavač i autor.

Maja Bjelica
SPEECH RHYTHM IN ENGLISH AND SERBIAN:A Critical Study of
Traditional and Modern Approaches
ИК ФС АФ КО УЗ ЛО ТЛ Е
И Т
Ф
Novi Sad, 2012

Filozofski fakultet u Novom SaduOdsek za anglistiku
Dr Zorana Đinđića 221 000 Novi Sad
Tel: +381214853900 +381214853852
www.ff.uns.ac.rs

5
Preface
The book called Speech Rhythm in English and Serbian: a Critical Study of Traditional and Modern Approaches is a revised version of my unpublished Master’s Thesis called “Characteristics of Speech Rhythm in English and Serbian” and an attempt to draw attention to the confus-ing situation in the theory of speech rhythm, as well as to emphasize the importance of studying this topic more thoroughly by Serbian linguists and of integrating the rhythm of speech into the language pronuncia-tion classes at an early age. The book offers a classification of existing approaches which shows a gradual movement from the traditional and descriptive to modern and experimental as the development of instru-mental means constantly progressed. It identifies the biggest problem in the approaches to the study, which is the lack of any universal agreement on basic principles and methodologies in the research process, which consequently results in the plethora of different and even opposing ap-proaches which need to be critically analysed and classified.
I became interested in this particular topic when I became aware of a huge clash between the traditional theory and modern approaches based on experimental research. I cannot remember if there exists a situation like this in which you have the existing theory still taught in English phonology classes which has been proved to be wrong but there has not yet been offered a better solution. I was also intrigued by the fact that this topic had been widely neglected by Serbian phonologists and for no obvious reason. It has been quite a challenging job to write a critical overview of the existing theories since all of them have their good points as well as the drawbacks.
I would like to thank first and foremost my dear colleague Biljana who encouraged me to take this leap of faith and start appreciating my own work by publishing this book. Also, I would like to thank my mentor, assistant professor Maja Marković, who gave me immense support and advice during the process of writing my Master’s Thesis, the members of my Master’s Thesis Committee, assistant professor Gordana Petričić and Tanja Milićev, and the reviewers of this book, assistant professors Tatjana Paunović, Nataša Bikicki, and Biljana Radić-Bojanić, for their effort and suggestions which helped me finalize this book. I would like to

6
give my special thanks to my family, my father, mother and my brother, my dear friends and, most of all, my patient fiancé, who were extremely supportive and understanding in the process of writing the Thesis first and then this book. And finally, I would like to dedicate this book to my beloved sister Nataša who was my biggest fan in the world, who believed in me even when nobody else did, even when I did not believe in myself, and who contributed to writing my Thesis by proofreading the Serbian abstract at the point when I was so lost in English phrases and English rhythm that at times forgot my own native language.
Hopefully, this book will serve as a good starting point for some fu-ture studies of speech rhythm in Serbian and help some future phonolo-gists or students of English find all the relevant information about speech rhythm in one place.
I take full responsibility for any omissions and deficiencies that may be found in this book.
The author
Novi Sad, May 2012

7
Contents
1 INTRODUCTION: Why Speech Rhythm? .........................................9
2 WHERE TO START: Problems in Defining Basic Conceptsand Research Methodologies ................................................................11
2.1 Rhythm in Speech ...........................................................................112.2 The Relationship between Syllables and Stresses...........................132.3 Accent, Stress or Stress Accent: a Problem of Terminology ...........182.4 Characteristics of Serbian Accentual System .................................222.5 Speech Segmentation: Syllable, Foot, Timing ................................24
3 BETWEEN TRADITION AND REALITY: Classification of Different Approaches to Rhythmic Studies ...............28
3.1 Typological Approach to the Study of Speech Rhythm ..................293.1.1 The Rhythm Class Hypothesis: Stress-timed andSyllable-timed Languages................................................................303.1.2 Isochrony Accepted: Physiology of Speech Production ........343.1.3 Isochrony Questioned: Full-vowel Timing Theory ...............393.1.4 Isochrony Rejected: Setting Grounds for FutureExperimental Studies .......................................................................413.1.5 Rhythmic Studies in Serbian ..................................................45
3.2 Phonological Approach to the Study of Speech Rhythm ...............463.3 Perceptual Approach to the Study of Speech Rhythm ....................54
3.3.1 Languages in the Middle: the Existence of Intermediate Languages ...................................................................553.3.2 Corpus Selection .....................................................................583.3.3 Data Segmentation ..................................................................633.3.4 Is There Rhythm to Begin with: Instrumental Studies ofRhythm ............................................................................................663.3.5 Nobody Puts Babies in the Corner: the Role of RhythmPerception in Language Acquisition ................................................683.3.6 It’s Not That Easy: Drawbacks of InstrumentalStudies ..............................................................................................77

8
3.3.7 Serbian: the Scarcity of Instrumental Studies .........................80
4 HOW TO APPLY THE STUDY OF SPEECH RHYTHM:Speech Synthesis and Rhythm Teaching ..............................................85
4.1 Why Should Speech Rhythm Be Taught inLanguage Classes? ................................................................................90
5 CONCLUSION ..................................................................................93
REFERENCES .....................................................................................95

9
1 INTRODUCTION: Why Speech Rhythm?
The interest in speech rhythm comes from the observation that dif-ferent languages give rise to the perception of different types of rhythm. Being one of the basic prosodic features, rhythm has been a topic of debates for many years, and even today, linguists cannot find the most appropriate theory to account for all the things related to this issue across languages. It has also been one of the most controversial and thus very often neglected issues in prosodic studies. It is said to be the most prob-lematic of all prosodic variables, and there have been many different and even opposing approaches to the issue of rhythm in speech. Indi-vidual languages are often perceived as having distinct rhythmic styles, which was the basis for the theory about speech rhythm. According to the existing and still widely applied theory, all the languages in the world are classified into three distinct rhythmic classes: stress-timed, syllable-timed, and mora-timed.
These typological labels rely on the hypothesis that isochrony holds either at the level of stressed syllables or at the level of individual syl-lables, depending on the language. However, a wealth of research done in this area over the last few decades shows little phonetic evidence to support the existing classification. The aim of the current study is to pre-sent both sides of the coin, compare the existing approaches to speech rhythm, both traditional and modern, and try to apply the existing theory in the study of Serbian speech rhythm, in order to prepare the ground for some future empirical studies on Serbian corpora.
Apart from being so controversial and complex, the study of speech rhythm in terms of contrast between the two languages under study has encountered a huge problem of disproportion between English and Ser-bian sources on the topic in question.
Due to a very small amount of work done on the topic of speech rhythm in Serbian, the current study mostly evolves around different ap-proaches to speech rhythm in English, since all the hypotheses have been presented after studying the English corpora, as well as the corpora in some other widely studied languages like Spanish and French. The book

10
stresses the necessity of studying this issue more thoroughly by Serbian phonologists, as well as the necessity to establish some universal para-meters and methodologies for doing research in this area. Due to the lack of such universal approach to research, the study of speech rhythm lacks a universal theoretical basis, which in turn creates confusion and op-posing views, which will not take us anywhere unless we do something about it. Hopefully, this book may be one small step towards reaching this goal since it will try to compare and contrast the existing approaches by pointing out similarities and differences between them and present their good sides as well as the drawbacks.
To explain the necessity of studying speech rhythm, it is important to emphasize that rhythm of language is one of its fundamental features, one of those which are acquired early by a child and quite difficult for an adult to learn, change, or even modify when they want to learn to pronounce a foreign language. It is said to play an essential role in the first stages of language acquisition by a newborn child, a basis for an early language discrimination process. However, rhythm seems to be a much neglected factor not only in studying English prosody but also in English language teaching. Moreover, the study of speech rhythm is very important in developing a reliable speech synthesis programme which will generate and reproduce more natural and thus more accurate speech. Consequently, the messages sent via such programme will take much less time to be understood.

11
2 WHERE TO START:Problems in Defining Basic Concepts and Research Methodologies
The first problem this study was faced with is the lack of universal definitions of basic concepts related to speech rhythm. These basic con-cepts have been some of the most controversial issues in linguistics and the description and explanation of such concepts and features raise some general theoretical questions. However, it is necessary to establish the phonetic principles required as a frame of reference for the specific dis-cussions about speech rhythm in English and Serbian.
The first major problem in defining the basic concepts is that many linguists have approached them from different points of view. More-over, due to different methodologies used by various authors as a result of these different approaches, it is rather difficult to find a uniform way to compare their research results, which further complicates the whole story about speech rhythm.
2.1 Rhythm in Speech
Although the term “rhythm” occurs in many different contexts be-sides speech, like music, poetics, or neurology (most of the definitions are listed in The Oxford Companion to the English Language, 1992: 869), the definition which will be used in this paper only concerns the rhythm of speech.
Unfortunately, there is no universally accepted definition of rhythm. According to Roach (2002), speech is defined as a sequence of events in time and the way these events are distributed in time is said to be the rhythm of speech (Roach 2002: 67). Since people do not normally per-ceive speech rhythm in everyday communication, they tend to say that in comparison to the only rhythm they know, which is the rhythm of music, speech cannot have rhythm.
As the most obvious examples of speech having rhythm, Roach (2002) mentions chanting as a part of children’s games (such as chil-dren calling words while skipping, or football crowds calling their team’s name) or in connection with work of some kind (the same as sailors use

12
chants in order to synchronise the pulling on an anchor rope). However, conversational speech is by far more complicated, but most phonolo-gists agree that some kind of regular timing is definitely present, even in speech.
Generally speaking, rhythm is said to be a repetition of an event at more or less regular intervals of time. In other words, the rhythm of speech, as any other rhythm, arises from the periodic recurrence of spe-cific units, producing an expectation that the regularity of succession will continue (Abercrombie 1967: 96). However, these specific units of rhythmic succession are the things which stir up trouble among pho-nologists because they are said to vary across languages. In English, the abovementioned repetition basically concerns the distribution of stresses in utterances, which means that a foot is taken to be the basic unit which occurs periodically. In some other languages, like Spanish or Italian, this repetition concerns the distribution of syllables in time, a syllable being that basic unit of speech rhythm.
However, more recent approaches to the theory of speech rhythm point out that this picture is everything but “black and white”, as it was thought earlier. On the other hand, Patel (2008) warns us to be careful when we define rhythm in terms of periodicity, i.e. a pattern repeating regularly in time. Although it has been said that rhythm denotes perio-dicity since it arises out of the periodic recurrence of some sort of move-ment (Abercrombie 1967), Patel points out a crucial difference between the terms “periodic” and “rhythmic”.
Namely, Patel (2008: 96) says: “Although periodic patterns are rhyth-mic, not all rhythmic patterns are periodic.” This means that not all re-currences of particular units, which are perceived to be rhythmic, are necessarily repeated after regular intervals of time. Thus, periodicity is only one type of rhythmic organization, although speech rhythm has had a long and largely unfruitful association with the notion of periodicity throughout history. Having this in mind, Patel thinks that it is highly im-portant to leave open the issue of periodicity in any definition of rhythm, and he himself defines it as “the systematic patterning of sound in terms of timing, accent, and grouping” (Patel 2008: 96). Therefore, speech, as well as music, is characterized by systematic temporal, accentual, and phrasal patterning.

13
2.2 The Relationship between Syllables and Stresses
In order to describe the pronunciation of a language and compare it to the pronunciation of other languages, it is necessary to analyse speech into units. Many different approaches have been proposed, but the most applicable approach here seems to be the one where the starting point in the speech analysis is the syllable1.
Although the approaches to the syllable vary among phoneticians and phonologists, most of them agree that the syllable seems to be the most basic unit of speech: every language has syllables; also, babies learn to produce syllables before they learn any word in their native language, while people with speech disorders still display syllabic organization (Roach 2002: 77).
Defining the concept of syllable has always been a problematic issue, although it appears to be a concept which can be intuitively recognized by more or less speakers of every language in the world. In many lan-guages, including Serbian, the syllable is very often defined in terms of its hierarchically organised structure which consists of consonantal and vocalic segments. A syllable always has one vowel (or a syllabic conso-nant) as its nucleus and a number of consonants preceding and following it (in onset and coda respectively). In English, the number of consonants that precede the nucleus ranges from zero to three, while the number of consonants that follow the nucleus does not exceed four consonants in a syllable.
Gimson (1978) provides two definitions of syllable based on two different approaches: phonetic and linguistic. The phonetic approach to syllable seeks to find a universal definition in phonetic terms, while the linguistic approach treats syllable as a language specific issue and stresses the importance of having language specific definitions of syl-lable rather than a universal one.
The phonetic approach in defining the notion of syllable has been divided into two theories: the Prominence Theory and the Pulse Theory. According to the Prominence Theory, there are sounds in an utterance
1 The analysis of individual phonemes will be put aside for now, since it is not that relevant for the study of speech rhythm.

14
which are perceived to be more prominent than the rest of the sounds in a sequence, i.e. to stand out in relation to their neighbouring sounds. On the basis of this approach, an utterance contains as many syllables as there are peaks of prominence or those sounds that are perceived to be more prominent than others. Vowels are perceived to be more promi-nent than other sounds (consonants) and that is why they are taken to be central parts of each syllable. Consequently, syllable boundaries occur at the points of relatively weak prominence (so-called “valleys”). Since this approach is mainly based on auditory judgements, its major draw-back is its inability to sometimes determine to which syllable the “weak” sound at the syllabic boundary belongs, especially in large consonant clusters. For example, the word ‘extra’ //, which is said to show three peaks of prominence but intuitively has only two syllables, can be segmented in the two following ways: [] or [] (Gimson 1978: 52). Similarly, Daniel Jones (1962: 327) points out that it is often impossible to specify points at which a syllable begins and ends. For ex-ample, although the sound /t/ in the word ‘letter’ has no sonority at all, it is impossible to say at which part of the sound /t/ the syllable separation takes place (is // segmented as [] or []?).
On the other hand, the Pulse Theory is a syllabic theory originally proposed by R.H. Stetson in his book called Motor Phonetics, a Study of Speech Movements in Action (1951), later adopted by David Abercrombie (1967) and postulated in terms of the pulmonic air-stream mechanism. It is concerned with the muscular activity controlling lung movement which takes place during speech. The syllable-producing movement of the respiratory muscles has been called a chest pulse (because the in-tercostal muscles in the chest are responsible for it), or breath-pulse, or syllable pulse (the term “pulse” being used because of its recurrent and periodic nature, thus defining rhythm of speech in terms of periodicity). There are a number of chest-pulses accompanied by increases in air pres-sure which determine the number of syllables in an utterance. Therefore, such a pulse serves as the basis for the syllable and a flow of such pulses creates a series of beats in the flow of syllables. According to Abercrom-bie (1967), the syllable is essentially a movement of the speech organs, and not a characteristic of the sound of speech. This means that the defi-nition of syllable does not have to do with the structure of the sounds

15
that make them, but to the mere process happening in our speech organs when we utter sentences.
“A syllable is the minimum utter-ance, and nothing less than a syllable can be produced” (Abercrombie 1967: 35). The syllable is essentially an audi-ble movement (at least, in most cases) of speech organs. After the air is released from the lungs, the pulse is then associ-ated with the movement of other speech organs like vocal cords, velum, and eventually tongue and lips in order to articulate sounds. “All these movements, combined together, are superimposed on the fundamental syllable- and stress-producing processes of the pulmo-nic mechanism, and they are felt by both speaker and hearer to constitute one single speech-producing act” (Abercrombie 1967: 37). Due to these unitary actions, the syllable is an integrated whole, although it is a com-plex act2. That is why it is taken to be the smallest unit of speech, and nothing less can be produced.
Another approach to syllable mentioned by Gimson (1978: 52) is the so-called linguistic approach. Gimson states that this type of approach is more useful than the phonetic one in defining the notion of syllable, i.e. “with reference to the structure of one particular language rather than in general, phonetic terms with universal application” (Gimson 1987: 52). It may be more appropriate to divide a similar sound sequence dif-ferently in different languages depending on the language specific rules concerning the possible combinations of segments (phonemes) in a par-ticular language. However, this approach has also failed to explain the division of the English word ‘extra’ // into syllables since both
2 A perfect example of one such complex act is given by Abercrombie (1967). Namely, he gives an example of a golf swing, where movements of fingers, wrists, arms, trunk, legs, and other body parts are involved and coordinated in order to produce a single effect, so much so that the ingredient parts of the swing, i.e. the movement of each organ independently, are not easily disentan-gled.

16
/-k/ and /-ks/ are found at the end of English words, while both /str-/ and /tr-/ are possible initial consonant clusters in English (Gimson 1978: 52). Similarly to Abercrombie, Serbian authors Stanojčić and Popović (1999) define syllable as a phonetic unit which is pronounced with one articula-tory movement of speech organs. It can be composed of only one sound as long as it is a vowel3 (e.g. u ’in’ as in u torbi ’in the bag’) but usually it is composed of one vowel preceded by one or more consonants. The general rule for the placement of syllabic boundaries is that the boundary is placed after the vowel of one syllable but before the consonant (onset) of the following syllable. For example:
(1) raditi ‘to do’ [ra-di-ti](2) lasta ‘swallow’ [la-sta](3) avioni ‘airplanes’ [a-vi-o-ni] but: avion ‘airplane’ [a-vi-on] (4) leptir ‘butterfly [lep-tir]
(Stanojčić and Popović 1999: 37)
As it is obvious from the last two examples, every rule has its excep-tions which are stated by Stanojčić and Popović (1999: 37). However, from the examples they give, it can be concluded that phonotactic rules do not play the same role in Serbian as they do in English. Namely, on the basis of the abovementioned rule, words such as grožđe ’grapes’ or voćka ‘fruit’ are divided into syllables in the following way: [gro-žđe] and [vo-ćka]. This division seems to be problematic since consonant clusters /žđ/ and /ćk/ do not normally occur word initially in Serbian and a better so-lution would be to divide the words in the following way: [grož-đe] and [voć-ka]. It can be thus concluded that Stanojčić and Popović adopt the phonetic approach to syllable. However, certain words sometimes opt for the so-called semantic (also called psychological) approach over the phonetic one. An example can be the word razljutiti ‘make somebody an-gry’ in which the phonetic approach divides the word into [ra-zlju-ti-ti],
3 Words like rđati ‘to rust’ prove that this is not really true since the first syllable in the word is constituted of a syllabic consonant alone

17
while the semantic approach into [raz-lju-ti-ti] (Stanojčić and Popović 1999: 37). According to the linguistic approach as well, the first division is not justified since the /zlj/ cluster does not occur word initially in Ser-bian. However, the word isterati ‘to cast out’ is a more problematic case: the phonetic approach would divide this word into [i-ste-ra-ti], where the initial cluster /st/ is possible in Serbian, while the semantic one would divide it into [is-te-ra-ti]. The latter approach is said to be more appropri-ate in this case (Stanojčić and Popović 1999: 37).
Whichever approach to syllable we decide to adopt, it is clear that the syllable is a starting point of any discussion on speech rhythm. Not only do syllables differ in structure, they also differ in the effort made in producing them, i.e. the amount of air expelled from the lungs when they are uttered in connected speech. Thus, there are some syllables that are in some sense stronger and more prominent than others. Abercrom-bie (1967) says that a chest pulse, the abovementioned movement which produces syllables, can also be produced by exceptionally great muscu-lar action. The pulse produced in this way is called a stress-pulse (Ab-ercrombie 1967: 37).
As a result of this process, a stronger puff of air than usual is expelled from the lungs, which causes a louder noise, among other things. A syl-lable produced in such manner is said to be a stressed one or that the stress is placed on it. According to Roach (2002), although stress has been a widely discussed and extensively studied topic, there still remain many areas of disagreement or lack of understanding. It seems likely that stressed syllables are produced with greater effort than unstressed, and that this effort is manifested in the air-pressure generated in the lungs for producing the syllable and also in the articulatory movements in the vocal tract. These effects produce different audible results, like the one of pitch prominence where a stressed syllable stands out from its context (a feature of Serbian accent); then, length of the stressed syllable, since stressed syllables tend to be longer than unstressed ones (a feature which is highly noticeable in English but much less in other languages); also, stressed syllables tend to be louder than unstressed, etc.
Stretches of connected speech are combinations of stressed and un-stressed syllables. Certain words, like lexical or content words, are pre-disposed by their function in a language to receive stress or accent, while

18
functional words, such as auxiliary verbs, conjunctions, prepositions, pronouns, etc, are more likely to be unstressed or unaccented in con-nected speech. “In an extended dialogue in normal conversational style, the number of weak syllables (unaccented) tends to exceed that of those carrying an accent (primary or secondary)” (Gimson 1978: 259).
2.3 Accent, Stress or Stress Accent: a Problem of Terminology
At the end of the previous section, the confusion made by the use of two terms, stress and accent, was intentional. Before we go any further, it is very important to clarify the usage of the two terms in order to avoid ambiguity.
According to Steiner (2004), accent is a phonological feature which, when realized, promotes the perception of one particular syllable in rela-tion to others. This means that stressed syllables are marked as having a specific accent.
On the other hand, stress is just a phonetic realization of a certain accent. However, since nothing seems to be universal in the theory of speech rhythm, the situation is similar with the use of these two terms. Namely, very often authors tend to use them interchangeably, without clarifying any difference between them.
The problem with the comparative studies of English and Serbian is the problem of defining stress since this phenomenon differs signifi-cantly in the two languages. The way the stress is manifested in these languages is highly language dependant.
Namely, languages like Serbian, ancient Greek, Latin, and even Japa-nese use variations in pitch to give prominence to a syllable (or mora) within a word. These languages are said to have pitch accent4 (or tonic accent) and use phonemic tone to mark prominence of a specific syllable in a word. On the other hand, languages like English and Spanish are said to exhibit stress accent (or dynamic accent), which uses the impression of loudness to mark the difference between the most prominent syllable in a word and less prominent ones.
4 This usage of the term ‘pitch accent’ was proposed by Dwight Bolinger, taken up by Janet Pierrehumbert (1980), and described in Robert D. Ladd.

19
Pitch-accented languages usually have a more complex accentual system than stress-accented languages. Serbian distinguishes four types of pitch accent, which is the result of different combinations of the tone and quality of syllables, while in English there are no such variations: accented syllables are just louder.
Moreover, while in English stress accent is said to give rise to the most prominent syllables in an utterance, without adding any particular meaning to it, the placement of the tone or the way pitch accent is real-ized in a Serbian word influences the meaning of the word – the misuse of pitch accent can lead to misunderstanding among the participants in conversation.
In order to illustrate the changes in meaning depending on the type of accent, the following examples are given:
(5) short-falling pitch accent ( ) vs. long-falling pitch accent ( )
luk (n.) a round white vegetable which has a strong taste and smell (Eng. onion, or garlic)luk (n.) part of a curved line or a circle (Eng. arc)

20
grad (n.) frozen rain drops which fall as hard balls of ice (Eng. hail)grad (n.) a large area with houses, shops, offices etc. where people live and work (Eng. town)
(6) short-rising pitch accent ( ) vs. long-rising pitch accent ( )
vajati (v.) to be goodvaljati (v.) to roll
(7) pitch accent placed on the second syllable in the word vs. pitch accent placed on the first syllable of the word
govoriti (v, infinitive) to speakgovorim (v, 1st person sg Present of “to speak”) I’m speaking
However, it is not entirely true that stress accent in English does not influence the meaning of words. Namely, according to Roach (2002:73), the position of stress in a word can change the meaning of the word. For example:
(8) ‘import’ (noun) // vs. ‘import’ (verb) //

21
(9) ‘permit’ (noun) /()/ vs. ‘permit’ (verb) /()/
While syllable is said to recur regularly in some languages, stressed syllables define units which tend to do so in languages like English. Units defined by stress are called feet. Foot is a term used by phoneticians and phonologists to describe the unit of rhythm in languages such as English, for example. This term describes the distance between two consecutive stressed syllables. Each foot consists of one stressed and a number of unstressed syllables (or one stressed syllable and no unstressed sylla-bles at all). Feet which consist of not more than two syllables are called “bounded feet”, while a foot which contains only one syllable is called “a degenerate foot” (Crystal 2008: 234).
The problem with the definition of a foot is that not all linguists agree where a foot starts and where it ends. Namely, most of them define foot as a sequence of syllables which start with a stressed syllable and ends with an unstressed one before some other stressed syllable, which means that the following foot again starts with a stressed syllable (“the next foot begins when another stressed syllable is produced”, Roach 2002: 29). For example:
(10) Here is the news at nine o’clock. |Here is the |news at |nine o’|clock|5
(Roach 2002: 29)
However, in metrical phonology, there are two types of feet: left-headed feet are those where the leftmost syllable of the foot is stressed, i.e. the most prominent syllable comes first (as in the abovementioned example given by Roach 2002), while right-headed feet are those where the rightmost syllable is stressed, i.e. the most prominent syllable comes last (Crystal 2008: 193).
For the purpose of this paper, Roach’s “left-headed” approach to the segmentation of utterances into feet will be adopted. For a detailed clas-sification of feet in English, see Bjelica (2010: 19).
5 Stressed syllables are underlined while foot divisions are marked with vertical lines.

22
2.4 Characteristics of Serbian Accentual System
Given the complexity of accent in Serbian, we need to inspect this prosodic feature of Serbian in more detail than in English. In Serbian, the term “accent” is used rather than the term “stress” (used in English) due to the fact that pitch and length are involved rather than intensity. Jovičić (1999: 407) points out the difference between Serbian and English with respect to accented syllable. Namely, English accented (stressed) syl-lable is characterised by intensity (which results in such syllables being the most prominent in an utterance), longer duration, and higher fun-damental frequency F0. On the other hand, Serbian accented syllable is characterised by longer duration and pitch change in relation to the unaccented syllable, while intensity does not make much difference be-tween accented and unaccented (especially post-accented) syllables, nor between different types of accent. Moreover, the duration of the accented syllable and pitch change are directly responsible for the perception of different types of accent. Similarly, Crystal (1969) defines stress in Eng-lish as variations in linguistically contrastive prominence primarily due to loudness, while Lehiste and Ivić (1986) state that the decisive cue for “stressedness” in Serbian is duration. The Serbian language is a system where both tone and stress play a role in phonology. According to Inke-las and Zec (1988: 227), the accents of Serbian “are decomposed into two independent subcomponents within the accentual system: tone and stress”, which are said to be separate phenomena in Serbian. Stress is manifested as increase in relative duration, while tone is manifested as relative difference in pitch. While tone is said to participate in lexical contrasts (since accent in Serbian sometimes makes distinction between otherwise the same words, as is shown in some previous examples), the location of stress is said to be predictable from that of tone and makes no contribution to lexical contrasts. This means that, for example, high tone can be assigned lexically to any syllable in the word whereas stress can only be assigned to a syllable containing this high tone (Inkelas and Zec 1988: 244). The system of pitch accents in Serbian is traditionally described in terms of two tonal movements within the accented syllable, “falling” and “rising” (Lehiste and Ivić 1986: 1). Accented syllables, both long and short, are termed as either rising or falling. Thus, Serbian

23
recognizes four lexically contrastive accents, based on the combinations of the two criteria: long-rising ( ), long-falling ( ), short-rising ( ), and short-falling ( ). For example:
(11) long-rising: ra zlika ‘difference’ ra azli ka long-falling: za stava ‘flag’ za astava short-rising: pa prika ‘pepper’ papri ka short-falling: je zero ‘lake’ je zero
(Inkelas and Zec 1988: 228)
The pitch contours of words are given in the rightmost column of the example (11). As it can be noticed from the given contours, the fall-ing accents “reside” within a single syllable, while the rising accents “stretch” over two syllables, the first of which is perceived as stressed (in example (11), the stressed syllables are bolded). As a result, there are some distributional constraints on the four accents. Namely, the accent in Serbian is said to be relatively free as it can occur on any syllable in the word but the last one (unless the word is monosyllabic). The term “relatively free” is used since, although the main accent always falls on a particular syllable of any given word (so the accentual pattern of Serbian is fixed in a way), it is not tied to any particular syllable in the sequence of syllables which constitutes a word (like in French, Polish, or Czech). However, not every type of accent can occur on every syllable. Falling accents generally occur in monosyllabic words or in the first syllable of a polysyllabic word. On the other hand, rising accents generally occur in every syllable of a polysyllabic word except the last one and never in monosyllabic words. This last point is understandable having in mind their pitch contour (see examples above). As it can be seen in the ex-ample given, all four accents can occur on the first syllable of the word (unless the word has only one syllable).
When vowel length is concerned, long and short vowels are possible in both accented and unaccented syllables (the long unaccented syllables are usually related to post-accentual positions). Short unaccented syl-lables are sometimes (for the purpose of marking all the syllables in a word) marked with ( ), while long unaccented syllables are marked with ( ). Thus a word nacionalni ‘national’ can be marked as follows:

24
(12) nacionalni (five syllables: short accented + 2 short unaccented + long unaccented + short unaccented)
2.5 Speech Segmentation: Syllable, Foot, Timing
In order to achieve rhythmic succession, each language needs to de-termine its own segments which tend to occur more or less regularly6. According to the existing works on the present topic, this choice can be made according to two types of units mentioned previously: a language can persevere with the syllable as a common unit of sound (as many lan-guages do) or select a larger unit consisting of a number of syllables (the foot). According to some linguists, there is also the third unit of rhythmic organization called the mora. Moras7 are often said to be units which consist mostly of consonant–vowel (CV, V or CjV) combinations, single vowels, or the nasal /n/ (e.g. na-ka-mu-ra and to-o-kyo-o each comprises four moras). Some authors do not make the distinction between mora and syllable since they treat mora as nothing more than a type of syllable which is simple and reflects the simple structures of Japanese (Grabe and Low 2002). Others say that mora is a unit out of which all other units of rhythmic succession are composed. All in all, since a precise definition of mora is difficult to determine, different authors define the term in ways which suit their own theoretical or descriptive principles. For more on moras, see Bjelica (2010: 21) and Arai and Greenberg (1997).
If we compare all three units, mora seems to be the smallest unit of rhythmic succession, while foot is taken to be the largest, consisting of a number of syllables, both stressed and unstressed8. What is the most
6 The controversial issue of the regularity of succession will be discussed in detail in the later chapters of the book.7 The plural form ‘morae’ is also used in some papers because the word is of Latin origin (in Latin, ‘mora’ means ‘linger, delay, space of time’). In this paper, the anglicized plural ‘moras’ will be used.8 Gore (2004: 65) gives an example in order to illustrate how these three types of units are perceived: if a heavy syllable is followed by a light syllable, it can be perceived either as three moras, two syllables, or one foot, depending on the language and its specific rules about speech segmentation.

25
important here is that the choice on which rhythmic unit will be used is determined by language specific rules. From all that has been mentioned previously, we can conclude that the syllable seems to be the starting point for all other segmentations, since it is the general unit out of which all other units are composed (Gore 2004: 65), given that most phonolo-gists treat mora as a simple syllable of the CV type. However, until a general phonological definition of syllable is presented, it cannot be re-garded as a universal segment of rhythmic succession.
The traditional consonant/vowel segmentation does not seem to be problematic, since every language has its inventory of consonants and vowels. However, it is more complicated in connected speech. Although consonant/vowel segmentation varies across languages, it is formulated in general terms, considering not consonants and vowels in the narrow sense of the word, but rather highs and lows in the universal sonority curve – “highs” being vowels, since they are more sonorous than con-sonants, which are represented as “lows” on the sonority curve (Ramus, Nespor, and Mehler 1999). The problem with consonant/vowel segmen-tation is the treatment of certain phonemes in connected speech. For ex-ample, the treatment of syllabic consonants varies among linguists, as well as the treatment of glides. This particular problem can directly affect the placement of segment boundaries, which consequently influences the interpretation of data attained during the experiments (especially those experiments based on the measurements of vocalic and consonantal in-tervals, e.g. Ramus, Nespor, and Mehler 1999).
If syllable is defined in linguistic terms and is determined by language specific rules, even a non-linguist can often, without any difficulties, seg-ment an utterance into syllables. However, stress is a more problematic issue, as it was mentioned earlier in the text. It is still unclear what the general rules for segmenting utterances into feet are. Bertrán (1999), for example, used a traditional method of segmentation. He segmented the utterances under study into feet, from the onset of the stressed vowel until the next stressed vowel, in order to measure the absolute duration of feet.
Once the stretches of speech are segmented, the question of the rhyth-mic succession of units occurs. Language timing is a rhythmic quality of speech in a particular language to distribute its rhythmic units across

26
time. According to this feature of speech, there are three types of timing: syllable-timing, stress-timing, and mora-timing9, depending on which units are taken to be the units of rhythmic succession: syllable, foot, or mora, respectively. Each language belongs to one of the three classes. However, some linguists, including Roach (1982), claim that there is no language which is totally stress-timed or syllable-timed (leaving mora-timed languages on the side, for now, since this is not a widely accepted classification). Since each language is a mixture of different segments, Roach (1982) states that every language displays both sorts of timing depending on the context and occasion. The main difference between languages, however, lies in the distribution of the two types of timing in a language, i.e. which type of timing predominates in the particular language.
Gore (2004: 64) gives a very interesting example which illustrates the fact that languages do look alike at some points with respect to rhythmic properties. Namely, he points out that linguistic similarity in prosodic tim-ing can be seen in the rhythm of counting from one to ten. The counting is based on the timing of the heavy syllable and does not vary noticeably from language to language, or among different age groups. Moreover, an example from Japanese is also given. Although mora-timing prevails in Japanese (according to more recent studies), some larger units can also be found in common, everyday greetings. “In such utterances, the heavy syllable is clearly the most prominent unit and the one that determines the rhythm of the whole phrase” (Gore 2004: 64). Such examples can be found even in English. The language of the advertisements usually tends to use such heavy syllables in order for an advertisement slogan to sound more exciting and to draw attention of potential customers. For example:
(13) “Never stop playing” (McDonald’s 2007) (14) “What you want is what you get” (McDonald’s 1993)
However, we should be careful with all the examples mentioned pre-viously since their language is highly marked in some way, and such
9 Although not mentioned in earlier works on the topic of speech rhythm, mora-timing is becoming more popular in contemporary works.

27
examples cannot be taken as typical representatives of the rhythmic pat-terns in their respective languages.
The classification of languages into the three classes mentioned above is the most disputable topic in the study of speech rhythm and will be dealt with in this book. However, before doing any further study on speech rhythm in different languages, it is highly important to come to a general agreement on how to segment utterances. Moreover, it would be necessary for the present study as well because, in doing so, the studies done by different linguists and the results of those studies could be easily comparable.

28
3 BETWEEN TRADITION AND REALITY: Classification of Different Approaches to Rhythmic Studies
Although pauses, hesitations, and other forms of interrupting the con-tinuous flow of speech tend to disguise that fact, it can be said that all human languages have rhythm. However, there are some languages, like Chinese or Japanese, that may sound like “a machine-gun” (Lloyd James 1940), while when we hear an Italian speaking, it sounds like music. Due to these perceptions, many people would disagree that all languages have rhythm. Although many theories about language rhythm exist, the question is whether they are valid since there is no empirical evidence to support them.
Even though the studies of rhythm in poetry date back to ancient Greek, Latin, and even Indian texts, the study of speech rhythm is rela-tively recent in linguistics (for more on this, see Bjelica 2010: 28). Re-searchers have taken at least three different approaches to this topic, so their research methodologies differ in this respect (Patel 2008). All the important studies analysed here can be classified into three differ-ent groups depending on the approach taken in the study of rhythm in spoken language.
The first approach is typological and it seeks to understand the rhyth-mic similarities and differences among human languages. According to this approach, languages are grouped into distinct categories according to their speech rhythm property. One of the most influential and wide-spread typological classifications is based on the notion of periodicity in speech and classifies languages on the basis of whether they have stress-timed rhythm (like English, Arabic, and Thai), or syllable-timed rhythm (like French, Hindi, and Yoruba).
This approach was introduced by Kenneth Pike (1945) and accepted later by many of his successors. As is evident from these few examples of languages which fall into either of the two categories, membership in a rhythmic class is not determined by the historical relationship of classi-fied languages. This means that, on the basis of the typological approach, rhythm can group languages which are otherwise quite distant both his-torically and geographically.

29
The second approach to speech rhythm is theoretical or phonologi-cal, and seeks “to uncover the principles that govern the rhythmic shape of words and utterances in a given language or languages” (Patel 2008: 118). This type of research includes an area called metrical phonology and tries to bring the study of speech rhythm in line with the rest of modern linguistics by formalising rules and using these rules to observe the phenomena of speech rhythm. The first linguist who proposed the phonological account of rhythm, putting forward the rhythmic properties of languages, was Rebecca Dauer (1987).
The third approach is perceptual and is said to examine the role that rhythm plays in the perception of ordinary speech. The research done in this area includes the perceptual segmentation of words from connected speech and examining the effects of rhythmic predictability in speech perception. Some later works use this particular approach (e.g. Ramus, Nespor, and Mehler 1999, Ramus et al. 2000, Tatham and Morton 2001, Ramus 2002, Setter and Ordin 2008, etc.).
3.1 Typological Approach to the Study of Speech Rhythm
Daniel Jones (1978: 240), in his book called An Outline of English Phonetics (1918, reprinted in 1978), notices that in every spoken word or phrase there is at least one sound which is perceived as louder than the sounds next to it. This high prominence of certain sounds may be the result of inherent sonority, length, stress, or special intonation, or the combination of all of these factors (Jones 1978: 55). These “peaks of prominence” (as he calls them in opposite to “troughs” which denote minimal prominence) are said to be easily counted in a word or a phrase. He also noticed the pattern in speech according to which these highly prominent syllables, i.e. stressed syllables, tend to follow each other “as nearly as possible at equal distances” in connected speech (Jones 1978: 237).
Jones (1978: 242) pointed out that those syllable quantities which tend to regularly follow each other are not the lengths of syllables but the lengths separating the “stress-points” or “peaks of prominence” of the syllables. He claims that one of the principal characteristics of rhythm in the English language is that these “interstress spaces” are approximately

30
of equal length, i.e. that they are isochronous. By interstress spaces he means the stretch of speech between the two consecutive stressed syl-lables. Also, many other authors who dealt with this issue give similar definitions. For example, M. A. K. Halliday, in his book called An In-troduction to Functional Grammar (1985) expresses his opinion in the following way: “[…] there is a strong tendency in English for the salient syllables to occur at regular intervals; speakers of English like their feet to be all roughly the same length” (quoted in Bertrán 1999: 2).
André Classe, in his book called The Rhythm of English Prose (1939), measured the quantity of syllables of different phonetic types, in differ-ent phonetic places in relation to stress groups and grammatical struc-ture. He tested some of the rhythm theories of Daniel Jones and con-cluded that “an English sentence is normally composed of a number of more or less isochronous groups which include a varying number of syl-lables” (quoted in Steiner 2004: 3).He also concluded that, while the length of syllables must vary, stress groups tend to have approximately the same duration, although containing a different number of syllables. He explained this as an effect of the increased speed articulation for the longer groups, which seems to be the result of a desire to make stress groups isochronous. This approach was adopted and further elaborated by Kenneth Pike (1945), among others.
3.1.1 The Rhythm Class Hypothesis: Stress-timed and Syllable-timed Languages
Arthur Lloyd James in his work called Speech Signals in Telephony (1940) was one of the first writers to discuss in detail speech rhythm in language and even to note down differences among languages concern-ing this issue. He says in his work that languages like Spanish or French have a type of rhythm in language which he described as a “machine-gun rhythm”.
He used this metaphor because each underlying rhythmical unit is of the same duration, similar to the transient bullet noise of a machine-gun. On the other hand, languages like English tend to sound more like the Morse code, and hence the term “Morse code rhythm” for such languag-es. James coined these terms “machine-gun rhythm” and “Morse code

31
rhythm”10 in order to draw attention to different perceptions of speech in different languages11. His principle of classifying languages according to the perception of the hearer was adopted by his followers like Kenneth L. Pike and David Abercrombie, but was criticised in much later works by Roach and Dauer, among others. They criticised this perceptual approach because it is said to observe the phenomenon of speech rhythm from only one point of view – the perception of speech, while its acoustics is left aside, maybe due to the lack of empirical evidence.
This difference between languages on the perceptual level was adopt-ed by Kenneth L. Pike in his book called Intonation of American Eng-lish (1945). He created the most influential typology of language rhythm based on the notion of periodicity in speech. Namely, his theory of speech rhythm was based on a dichotomy between languages in terms of syllable and stress patterns. Pike (1945) changed James’s metaphors to more convenient terms “syllable-timed rhythm” (for his “machine-gun rhythm”) and “stress-timed rhythm” (for his “Morse code rhythm”).
These terms were coined on the basis of Pike’s theory according to which languages differ from each other in as to which movements will
10 Found in Abercrombie (1965).11 Besides terms “Morse-code like” and “machine-gun like” rhythm, Crystal (1996: 8) also mentions terms like “bouncing”, “heart-beat”, and “tum-te-tum” for the former type of rhythm, and “staccato”, “pattering”, and “rat-a-tat” for the later type of rhythm, which characterize these different auditory impressions.

32
periodically recur12. According to his classification, languages like Span-ish and French are said to be “syllable-timed”, based on the idea that syl-lables last roughly the same amount of time, i.e. they are pronounced in roughly equal temporal intervals. On the other hand, according to Pike, there are languages such as English that are said to be “stress-timed”, based on the assumption that they have roughly equal temporal intervals between stresses, stress-points, or peaks of prominence, as James (1978) calls them. To illustrate stress-timed rhythm in English, Pike points out that in the following example the reader can notice “the more or less equal lapses of time between the stresses in the sentence” (Pike 1945: 34):
(1) The teacher is interested in buying some books. The |teacher is| interested in| buying some| books|
(Pike 1945: 34)
The vertical lines in the example show the division of the sentence into rhythmic units which, according to Pike, tend to last approximately an equal amount of time. Each unit has one stressed and a number of un-stressed syllables following or preceding it. For comparison, he provides yet another example in order to show that despite the different number of syllables, the intervals between stressed syllables are approximately equal:
(2) Big battles are fought daily. |Big |battles are| fought |daily|
(Pike 1945: 34)
Apparently, rhythmic units have a different number of syllables (only one stressed and an uneven number of unstressed syllables), but they have a similar time value. In order to achieve this, to pronounce them
12 Since this book deals with both English and Serbian, it would be appropriate to offer a terminology in Serbian as well. However, I have not come across any translation of the terms “syllable-timed” and “stress-timed,” so I am forced to offer the Serbian descriptive equivalents “ritmično ponavljanje slogova” and “ritmično ponavljanje naglašenih slogova” for the two terms respectively.

33
in a roughly equal amount of time, unstressed syllables of longer rhythm units need to be somehow “crushed to-gether” and pronounced very rapidly. In order to achieve evenly timed feet, syllables need to be contracted and compressed to fit into the typical foot duration. De-pending on the number of syllables per foot, these unstressed syllables are thus contracted that sometimes they are barely audible. This is how Pike (1945) accounts for many abbreviations which exist in English, in which syllables may be omitted entirely, not only in pronunciation, but in orthography as well13.
Jones (1978) also talks about the processes which make feet last ap-proximately the same amount of time. Namely, if a stressed syllable is followed by a number of unstressed syllables, that vowel or diphthong of the stressed syllable is generally shorter than if the stressed syllable is followed by another stressed syllable or at syntactic boundaries. Moreo-ver, “the greater the number of following unstressed syllables the shorter is the stressed vowel” (Jones 1978: 237). As it is obvious, not only un-stressed syllables but stressed ones as well are affected by the processes of contraction and compression in order for the feet to be of equal dura-tion in time, thus producing the rhythmic succession of units.
On the other hand, languages like Spanish and French, which are characterized by having a syllable-timed rhythm, according to Pike (1945), have individual syllables which tend to come at approximately evenly recurrent intervals of time. In this case, phrases with more than one syllable are said to take proportionally more time and their syllables, or vowels in those syllables, are less likely to be compressed, shortened, or even omitted.
13 Some linguists, like Dauer (1987), tried to modify Pike’s theory on the basis of the phenomenon of vowel reduction, which will be further elaborated in one of the later sections.

34
Since it is said that in such languages syllables tend to last the same amount of time, it seems that all syllables are thus of equal prominence and duration. This consequently means that no syllable compression or reduction is necessary. The syllables which are stressed more in the pro-cess of word or phrase accentuation are said to be just extra strong and extra long, but that it does not affect the pattern of recurrent syllabic prominence.
3.1.2 Isochrony Accepted: Physiology of Speech Production
The Rhythm Class Hypothesis proposed by Pike (1945) was adopted by David Abercrombie in his books called Studies in Phonetics and Lin-guistics (1965) and Elements of General Phonetics (1967). Abercrombie went further on with the theory of speech rhythm by proposing a physi-ological basis for Pike’s stress- versus syllable-timing. His contribution to the theory was based on a specific hypothesis on how syllables are produced. According to Abercrombie (1965), the most appropriate ap-proach in defining the notion of syllable is the one that explains the syl-lable in terms of the pulmonic air-stream mechanism. Speech depends on breathing since the sounds of speech are produced when the air is released from the lungs (by an air-stream from the lungs). However, this air-stream is not released from the lungs in a continuous flow, but the flow is rather “pulse-like” in nature.
There is a continuous and rapid fluctuation in the air-pressure, which is the result of alternate contractions and relaxations of the breathing muscles. Each of these muscular contractions, and the consequent rise in the air-pressure, is a chest-pulse, since intercostal muscles in the chest are responsible for it. Each chest-pulse is said to constitute a syllable. That is why this process is called a syllable producing process, which is the basis of human speech (Abercrombie 1965: 16-17). However, there is yet another system relevant for human speech. This system, in part, depends on the first one and consists of a series of less frequent, but more powerful contractions of the breathing muscles which every now and then coincide with, and reinforce, a chest-pulse, and cause more sig-nificant and more sudden rise in the air-pressure. These movements in the air-pressure constitute the system of stress-pulses. In human speech,

35
these two processes, the syllable producing process and the stress pro-ducing process are combined and their rhythm constitutes the rhythm of speech.
Abercrombie (1965) proposed that in any given language one or the other kind of pulse occurs rhythmically, equating rhythm with periodic-ity, like Pike did before him (1945):
“Rhythm, in speech as in other human activities, arises out of the peri-odic recurrence of some sort of movement, producing an expectation that the regularity of succession will continue”.
(Abercrombie 1967: 96)
Speech rhythm is a product of the way these two processes are com-bined in producing an air-stream for talking. Abercrombie (1965: 17) points out that, in fact, the rhythm is there in the air-stream even be-fore the actual vowels and consonants are produced in order to make words. Furthermore, since the combination of these two processes and their rhythm does not depend on the actual sounds of a language, we can thus conclude that all the languages in the world have speech rhythm, regardless of what their sound inventory is. People of all languages, in order to speak, need to start from releasing the air-stream from the lungs, and since the rhythm is in the air-stream itself, we can then conclude that rhythm is a universal feature of all languages.
However, studies have shown that not all languages have the same type of speech rhythm. This is because different languages co-ordinate the two processes differently. The status of Serbian in this classification is not clear since there seems to be a lack of studies in this area. In the later chapters of this book some general conclusions will be made for rhythmic properties of Serbian in order to see whether it is reasonable to believe that Serbian is closer to syllable-timed than stress-timed lan-guages.
Abercrombie (1967), thus, agrees with Pike (1945) that not all lan-guages have the same type of rhythm, adopting his classification of lan-guages into stress-timed and syllable-timed. Not only does he accept his Rhythm Class Hypothesis, but he also proposes that one language cannot belong to both groups at the same time, i.e. that the two types of speech

36
rhythm are mutually exclusive (Abercrombie 1967: 97). This means that one language cannot have both stress-producing and syllable-producing processes isochronous at the same time, but it is one or the other. For example, if English has the stress-pulses isochronous, then the syllable pulses cannot be isochronous, i.e. they will occur at unequal intervals of time, and vice versa. This actually means that, if a language shows a tendency towards uniform spacing between the stresses in feet with different number of syllables, that language cannot have syllables of the same utterance last an equal amount of time, i.e. either a language will have all the syllables that last approximately an equal amount of time, or only stressed syllables. One of the most problematic points he made and the most criticized one is the fact that he grouped all the languages in the world into the two proposed classes. Not only is this approach a bit utopian in thinking that such a large variety of languages in the world can be put in nothing more than two groups on the basis of their rhyth-mic properties, but it is a result of testing a small number of languages in comparison to all the languages that exist and a great deal of languages whose properties were not available to linguists at that time.
Furthermore, Abercrombie agrees with Pike in saying that in order to equalize the duration of interstress intervals in languages like Eng-lish which are said to have stress-timed rhythm, some adjustments need to be done “in order to fit varying numbers of syllables into the same time interval” (Abercrombie 1967: 98). Since the unstressed syllables are unequally distributed between the stressed ones, therefore they are said to be spoken at varying speeds to fill the spaces between the stressed syllables. This produces an impression that the stressed syllables are pro-nounced at equal intervals resulting in unstressed syllables being some-times contracted and compressed so as to fill the intervals between two stressed syllables.
The number of unstressed syllables is not important here and their number does not count. What is important is that the more of them, the shorter they will be in speech, thus producing the impression of isoch-rony in language, or in other words, a tendency in English to place stress at approximately equal intervals of time. As a result of the process of contracting unstressed vowels is producing the weakest vowel in English – // (schwa). In certain contexts, an unstressed vowel is so contracted

37
that it is pronounced as if it does not exist in a word. An example of simple sentences can be given to illustrate the phenomenon of vowel contraction:
(3) |John was| late.| first foot: 2 syllables [stressed + unstressed]; second foot: one
syllable [stressed](4) |Jenny was| late.| first foot: 3 syllables [stressed + 2 unstressed]; second foot: one
syllable [stressed](5) |Jennifer was| late.| first foot: 4 syllables [stressed + 3 unstressed]; second foot: one
syllable [stressed]
Each of these three sentences consists of two stressed syllables com-bined with a number of unstressed ones, but the number of unstressed syllables varies as we change the subject of the sentence. In order for the stressed syllables to follow one another at equal time distances, the unstressed syllables of the first foot need to be compressed. According to Jones (1978), some contractions affected the stressed syllable as well.
Here is one more example to illustrate this. In the sentence:
(6) What’s the difference between a sick elephant and a dead bee? 2 5 1 5 1 1
(Cruttenden 1986: 20)
although the number of syllables in each rhythmic unit varies consider-ably due to the fact that there are more unstressed than stressed syllables, the rhythmic units will be said in roughly the same amount of time, even the group which has five syllables and the groups of only one syllable (Cruttenden 1986: 20).
Abercrombie (1967: 97) (like Pike before him) approaches the issue of rhythm from a point of view of perception. As he points out, “’the identity of speaker and hearer’ is essential to an understanding of many aspects of speech perception” (Abercrombie 1967: 97). Not only the speaker (since he/she is the one uttering a stretch of speech) but also the

38
hearer experiences the rhythm of movement. He thus talks about “hear-ing” the rhythm of a language, which was criticized by some linguists later on. This is due to the fact that he does not provide any experimental ways to prove the theory about speech rhythm, but he rather leaves it to our mere perception. Also, some later linguists, like Ramus et al. (1999), tried to find correlates of linguistic rhythm in the speech signal which is perceived by the hearer, i.e. what in speech signal triggers the perception of rhythm in speech. However, since it is rather elusive what physical events contribute to the acceptance of rhythm as a feature of speech, it is widely believed that rhythm is just a perceived effect which may or may not have reliable acoustic correlates. Abercrombie (1967) further elabo-rates his theory of rhythm perception by saying that the rhythm is intui-tively experienced by “phonetic empathy”. This can only be achieved if both the speaker and the hearer have the same mother tongue. It can be illustrated by taking verse as a perfect example of rhythm in language. English poetry will not be appreciated in the same way by a native speak-er of English and a native speaker of French who learned English at school, for example, due to different rhythmic patterns of their native languages. The same thing would happen if a French speaker tried to compose a verse in English. He would use the rhythmic patterns of his/her own language (which differs from English in this respect) and many native English speakers would probably not feel it as an English verse at all. This kind of a clear-cut theory seems to be rather neat, but it has its drawbacks. Since there has been no empirical evidence for this classifi-cation, the Rhythm Class Hypothesis seems to be weak and thus prone to criticism. It is said that this classification rather relies on the perception of speech as such than on any real evidence. Listeners get such an im-pression that there are two different kinds of rhythm. That is the reason why the first classification of this kind, that done by Lloyd James (1940), uses the terms which are a mere description of what people hear com-pared to some other similar sounds.
Actually, the terms “machine-gun rhythm” and “Morse code rhythm” best describe what people concluded many years later. Rhythm is not in the production of speech but rather in its perception. Some authors, like Tatham and Morton (2001), pose a question whether speakers can control isochrony of speech, or if it is just perceived isochrony. The answer to

39
this question would help people in trying to discover how to synthesize speech which would sound natural. Empirical measurements failed to provide any support for Pike’s theory of speech rhythm. It failed to pro-vide any valid evidence that the isochrony of stresses or syllables really exists. Abercrombie’s theory about chest pulses has also been attacked by later linguists. They tested it experimentally but came to conclusions which oppose the theory (Roach 1982, Dauer 1983, Ramus 1999, etc.). However, the existing theory, despite its many flaws, still persists.
One reason may be that it matches our subjective intuitions about rhythm. Abercrombie (1967: 171) suggests that the idea of isochronous stress in English dates back to the eighteenth century, although it was first pointed out by Arthur Lloyd James in Speech Signals in Telephony (1940), and further elaborated by K.L. Pike (1945). This means that even without modern technology people were able to identify that stresses in English tend to be isochronous. Another reason for the persistence of this theory may be that it correctly groups together languages that are perceived as rhythmically similar, even if the physical basis for this grouping is not clearly understood.
3.1.3 Isochrony Questioned: Full-vowel Timing Theory
Yet another account of speech rhythm comes from a study done by Dwight Bolinger in his book called Two Kinds of Vowels, Two Kinds of Rhythm (1981). He adopts Abercrombie’s hypothesis which says that vowels undergo some kind of reduction in unstressed positions so stressed syllables could follow one another at equal temporal distances. However, he goes one step further in proposing that there are actual-ly two types of syllables – those containing full vowels, which Aber-crombie calls “stressed syllables” and those containing reduced vowels, which Abercrombie calls “unstressed syllables”. Bolinger suggests that the most important factor is neither the number of syllables nor the num-ber of stresses, but the pattern made in any section of continuous speech by the mixture of syllables containing full vowels with syllables contain-ing reduced vowels.
According to Bolinger, the basic unit of speech rhythm is a full-vow-elled syllable together with any number of reduced-vowelled syllables

40
that follow it. Each rhythm unit must thus contain one and only one full-vowelled syllable.
There is one fundamental difference between Pike’s stress-timing theory and Bolinger’s full-vowel timing theory which can be illustrated using the following examples taken from Cruttenden (1986: 22):
(7) Those porcupines aren’t dangerous.Abercrombie: |Those|por|cu|pines| aren’t| dan|ge|rous|
U S U U U S U U
Bolinger: Those| por|cu|pines| aren’t| dan|ge|rous. F F F F F F R R
The wallabies are dangerous.Abercrombie: |The |wal|la|bies| are| dan|ge|rous|
U S U U U S U U
Bolinger: The| wal|la|bies| are| dan|ge|rous. R F R R R F R R
Stress-timed isochrony (Pike 1945 and Abercrombie 1967) would suggest the same rhythm in both sentences: namely, the two sentences are said to contain two “rhythm-groups” (Cruttenden 1986: 20) with an unstressed syllable at the very beginning (Cruttenden 1986: 21 calls those types of unstressed syllables at the beginning of syntactic bounda-ries “anacrusis”). Contrary to this, Bolinger’s full-vowel timing suggests that there are six rhythmic units in the first example (three syllables of “dangerous” makes one single unit) and only two units in the second example (since there are only two full vowels and a number of reduced vowels which are combined with the full vowels to make units). The central idea which stands behind the full-vowel timing is that a reduced-vowel syllable which follows a full-vowel syllable “borrows” time from the full vowel, so that together they are roughly equal to a full-vowel syllable timing, which can be a rhythmic unit on its own.
However, any other reduced-vowelled syllable succeeding a reduced-vowelled syllable which is right next to a full-vowelled syllable does not

41
borrow time from the full-vowel syllable, which means that it adds to the length of a rhythmic unit.
wal|la|bies a reduced-vowel syllable which does not borrow time form the full-vowel syllablea reduced-vowel syllable which borrows time from a pre-ceding full-vowel syllablea full-vowel syllable
Full-vowel timing, thus, seems to account for the instrumentally measured facts of English syllable durations more successfully than stress-timed isochrony. According to it, rhythm-groups which consist of an unequal number of syllables (one full-vowelled and a number of re-duced-vowelled syllables) cannot have the same duration since only the first reduced-vowelled syllable borrows time from the full-vowelled syl-lable while the other reduced-vowelled syllables which follow only add to the duration of that particular rhythm-group. It cannot, however, lead us to completely discount some tendencies towards stress-timed isoch-rony, since without it there would be no reason for the reduction of some syllables, i.e. the reduction of vowels which make the unstressed sylla-bles. Therefore, Bolinger (1965) showed that the duration of interstress intervals is influenced by the specific types of syllables they contain as well as the position of the interval within the utterance. Interstress inter-vals thus do not seem to have a constant duration as it was predicted by the theory of isochrony proposed by Abercrombie (1967) and rejected for the first time by Roach’s experimental study (1982).
3.1.4 Isochrony Rejected: Setting Grounds for Future Experimental Studies
One of the turning points in the study of speech rhythm was Peter Roach’s paper called “On the distinction between ‘stress-timed’ and ‘syl-lable-timed’ languages” (1982), which criticised Pike and Abercrombie’s Rhythm Class Hypothesis. According to Roach, Abercrombie’s theory of speech rhythm has several drawbacks. First of all, he attacks Abercrom-bie (1967) for being too explicit in saying that all languages in the world

42
belong to either of the two categories – syllable-timed or stress-timed, without setting out clear rules for assigning a language to one or the other category. Although giving examples of utterances from different languages which support this account of speech rhythm is easy, the ques-tion of how to set out certain rules for classifying languages into the two groups seems rather problematic. The answer to such a question seems to be hard to test experimentally, and there is no empirical evidence that languages really belong to either of the two groups. Rather, Roach (1982) says that Abercrombie’s claims that the phonetician needs to “em-pathize” with the speaker to apprehend speech rhythm and that people need to learn to listen differently in order to be able to analyse speech rhythm suggest that the distinction between stress-timed and syllable-timed languages may rest entirely on perceptual skills acquired through training. However, if someone is “trained” to classify languages to one or the other category, it would consequently stress the need for a person who already knows how to do so to act as a “trainer”.
As the second major problem of the existing theory, Roach points out the lack of empirical evidence to support it and states the major problems which linguists have been faced with in measuring aspects of rhythm in continuous speech. He identified the need to test Abercrombie’s hy-pothesis on spoken data by measuring time intervals in speech. Roach wanted to test the hypothesis concerning the difference in syllable length between syllable-timed and stress-timed languages, according to which stress-timed languages have considerable variation in syllable length, while syllable-timed languages have syllables that tend to last the same amount of time. For this purpose, he set up a small corpus which consist-ed of stretches of spontaneous, uninterrupted speech in all the languages used in Pike’s studies (English, Russian, and Arabic as stress-timed, and French, Telugu, and Yoruba as syllable-timed languages). The results of his experiment show that there is no empirical evidence to support the claim that in syllable-timed languages syllables are equal in length.
Another claim that Roach wanted to test in his experiment was that in syllable-timed languages stress-pulses are unevenly spaced, while lan-guages like English experience regular stress beats. He concludes that the abovementioned isochrony in language is everything but straightfor-ward. Namely, he does not negate it entirely, but rather points out that it

43
is more apparent than real and that “listeners tend to perceive isochrony even in sequences of interstress intervals that are manifestly far from equal” (Roach 1982: 2). However, instead of rejecting isochrony alto-gether on the basis of the corpus he himself tested, Roach was realistic about his results: he became aware of the scarcity of the data used in this experiment and, instead of making generalisations, he prepared the ground for further studies which would reject the hypothesis by instru-mental means. Not only did he identify the necessity of further research in order to test Abercrombie’s claims, but he stressed the importance of testing more syllable-timed languages, since there is a disproportion be-tween the studies done for this group of languages and the ones done for English as a typical representative of the stress-timed category. One of the languages which should obviously be included in this type of study is Serbian.
Furthermore, in order to run a relevant instrumental study of languag-es, some agreement needs to be reached about the characteristics of a test which is to be used for the experiment in question. Roach (1982) recog-nizes three major problems in designing a measurement-based test. First of all, one of the problems is the identification of stresses, i.e. deciding on what a stressed syllable is and what it is not. Since at that time there was no instrumental technique for identifying stressed syllables, a phoneti-cian needed to do it by himself auditorily. He did so by identifying the peaks of prominence and, consequently, the stress placement in an utter-ance, something which is difficult for a non-phonetician to do, especially in spontaneous speech. Although a specialist in this area, a phonetician can be subjected to many influences, since his intuitions about his native language may interfere with the judgements about other languages. An additional problem can arise from the disagreement among phoneticians on what a syllable is and how to segment a stretch of speech into syl-lables. The same problem occurs when it comes to defining stress and the division of speech into feet, which makes this problem even more serious. The second problem, according to Roach (1982), is the problem of identifying and, consequently, measuring the interstress intervals in an utterance since it is rather disputable from where to start measuring such an interval. Some researchers have measured it from the intensity peak of the vowel in the stressed syllable to the intensity peak of the following

44
stressed syllable, while others, including Roach, thought that it would be intuitively more satisfying to start from the phonological beginning of the stressed syllable, including not only the vowel of the stressed syllable but also a consonant cluster if a syllable starts with one. Additionally, Roach admits that although spontaneous, uninterrupted speech seems to be the most suitable for research, it is likely to be “heavily influenced by tempo variations” (Roach 1982:3) if put in different contexts and social occasions. Consequently, a language would experience different types of timing depending on the context and occasion, which leads to the con-clusion that no language is exclusively stress-timed or syllable-timed. Some later authors support this view by saying that one and the same utterance can have different timing patterns depending not only on the communicative situation (context) and on speech tempo, but also on the emotional expression of the speaker uttering that stretch of speech (Cum-mins 2002: 2).
Finally, if we decide to adopt the notion of isochrony and the existing types of rhythm, Roach warns us that there is no language which is said to be totally syllable-timed or totally stress-timed, as Abercrombie be-lieved, but rather, every language is said to display both sorts of timing. “Languages will, however, differ in which type of timing predominates” (Roach 1982: 5). Moreover, the theory which divides languages into syl-lable-timed and stress-timed depends only on the intuitions of speakers of various Germanic, mostly stress-timed, languages, and more effort needs to be made to examine more languages, especially those belonging to the syllable-timed group, in order to see whether the dis-tinction is empirically supported or just based on subjective impressions of the listener. The only way to prove the validity of Pike’s clas-sification is by designing a test which would measure the acoustic or articulatory infor-mation and thus prove or reject the idea that certain information which is “hidden” in the acoustic signal triggers the perception of one or the other type of rhythm.

45
3.1.5 Rhythmic Studies in Serbian
At the very beginning it must be said that speech rhythm has been a neglected topic in Serbian linguistics. This may be due to the fact that accent in Serbian is a more complex issue than accent in English, encom-passing not only the prominence of a stressed syllable but also the infor-mation on tone, duration, and intonation. The problem which this study was faced with at the very beginning was the lack of relevant rhythmic studies done on a Serbian corpus. Some of the linguists who dealt with this issue were Pavle Ivić and Ilse Lehiste, Jelica Jokanović–Mihajlov, and Slobodan T. Jovičić.
Jelica Jokanović–Mihajlov (1990) discusses the models of rhythmic organization in utterances, more precisely the prosodic features of Serbi-an spoken utterances, focusing mainly on temporal organization of their segments. She points out that focusing only on one element of prosody, neglecting all the others, is rather difficult, especially having in mind that Serbian pitch accent is composed of several elements.
This groundbreaking study suggests a unit of rhythmic organisation which extremely resembles that of English. Although syllable is said to be the basic articulatory and acoustic unit of speech in Serbian, the basic unit of rhythmic organisation is said to be something beyond syllable. The combination of different syllables produces a word which has its prosodic contour and such a word, which has its own prosodic organi-sation, is said to be an accentual word. Most lexical words in Serbian have their own accents and some words need to lean on a word in front of them or behind them in order to receive an accent. This means that an accentual word does not always correspond to a phonological word. Thus an accentual word is said to be a word or a word combination with only one accentual pattern (Jokanović–Mihajlov 1990: 108). In con-nected speech, utterances are organised as sequences of accentual words. Between the accented syllables in an utterance there are a number of unaccented syllables which are inferior both in prominence and quantity. Thus an utterance is, actually, the succession of pulses which correspond to the accented syllables with all the unaccented ones in between.
Many Serbian linguists negate the existence of rhythmic organisation of prose. They say that it should be only reserved for poetry since poetry

46
is interested in producing such rhythmic effect. However, Jokanović–Mihajlov (1990) did an experiment on Serbian data in order to show that this type of rhythmic organization is present also in prose texts and in everyday conversation. She points out that our impression that rhythm does not exist in speech comes from the fact that in such contexts listen-ers tend to concentrate on semantic and syntactic units while rhythmic pulses are neutralized and thus hardly perceivable.
According to Jokanović–Mihajlov (1990), semantic properties of an utterance cannot be neglected because the listener’s attention is concen-trated on them.
Thus, instead of having syllable as a unit of rhythmic organization, she suggests a rhythmic group which encompasses one or more pho-netic words. Such groups are said to be both semantically and syntacti-cally coherent, and, as such, are perceived as basic units of rhythmic organization. One rhythmic group is said to be a semantic unit with only one accentual pattern.
Syllables, on the other hand, do not carry any semantic content un-less combined with other syllables: such combinations usually consist of one accented and a number of unaccented syllables since one accentual pattern is said to have only one syllable which bears accent. We can-not help but notice that in this respect, Serbian looks a lot like English and that these rhythmic groups are nothing more than units similar to English feet. This brings us to the conclusion that in this respect Serbian behaves like a typical stress-timed language, since the orientation point in segmentation and thus understanding of an utterance is said to be the stressed (accented) syllable.
3.2 Phonological Approach to the Study of Speech Rhythm
Over the years of studying speech rhythm, people have tried to devel-op methods and reliable means which would test the perceived isochrony of rhythmic units. After the turning point in the study due to Roach’s experiment which rejected isochrony in speech reality and left it in the scope of subjective perception, there have been numerous approaches to speech rhythm which set aside the notion of isochrony. After developing a reliable instrumental means which would be used for further research,

47
most of these approaches have relied upon them to refute the Rhythm Class Hypothesis proposed by Pike (1945) and Abercrombie (1967). However, it should be stressed that although it seems that the idea of isochrony is more apparent than real, the idea of speech rhythm should not be discarded.
In order to test the claim given by Roach that stress-timed languages are likely to have more complex syllable structure than syllable-timed languages and exhibit vowel reduction, unlike syllable-timed languag-es, Rebecca Dauer (1983, 1987) developed a phonological account of speech rhythm due to the fact that languages seem to exhibit different properties in speech production. After realizing that rhythm was nothing more than a total effect of a number of different components – phonetic and phonological, as well as segmental and prosodic in nature – and a property of all languages, she set grounds for creating a general pho-nological theory. The need for creating such an account came from the fact that one of the major drawbacks of Pike’s classification seems to be that it groups languages into the two categories without stating any parameters for assigning languages to one or the other category. Roach’s experiment proved that the classification could not be based only on the measurements of time intervals in speech. Moreover, since the concepts of both syllable and stress lack general phonetic definitions, all these fac-tors make a purely phonetic definition impossible.
According to Dauer (1987), some of those components of speech which allow us to compare languages on the basis of speech rhythm include the rela-tive length, pitch, and segmental quality of accented and unaccented syllables, as well as some of the phonological compo-nents such as syllable structure and the function of accent. Dauer points out that rhythm can be broken down into these components, and as any other distinc-tive feature they can be assigned a plus or a minus value. According to her, the languages and language varieties differ

48
according to different combinations of these values as rhythm is said to be the total effect of combining all the features mentioned above.
Dauer recognized three features of speech which are said to influence rhythm in spoken language and to which she assigned [+], [0], and [-] values14:
1) Duration;2) Syllable structure;3) Vowel reduction.
A language is assigned one of the three values on the basis of the extent to which a particular value is exhibited. Namely, if a language is marked positively with respect to duration, accented heavy syllables tend to be longer than unaccented light syllables. As examples of such languages which have regularly longer accented than unaccented syl-lables, Dauer mentions English and Serbo-Croatian. On the other hand, in languages which are assigned the [-] value syllables are not affected by accent, i.e. accent does not influence the duration of syllables, either accented or unaccented.
Concerning the second property – syllable structure, or more appro-priately syllable complexity, languages which are marked positively have a high percentage of complex syllables. In such languages, like English or German, a great number of syllables have complex consonant clusters in both the onset and the coda (three or even four consonants in the cluster), whereas in languages which are marked negatively for this feature, like Italian, most complex syllables have a maximum double consonant coda and a single consonant in the onset. Moreover, those lan-guages are said to have simpler syllable structures, predominant syllable types being CV and CVC. Such languages are also said to exhibit many active processes which break up or prevent the formation of particularly heavy syllables (an example of such a language is Japanese). Simple syl-lable structures include the syllables which lack consonant clusters in ei-ther the onset or coda, namely, structures such as CV, V, VC15, and CVC
14 Dauer (1987) mentions yet another feature – quantity distinctions, but it will not be mentioned in the present study since not all languages (including English) exhibit this feature.15 Dauer (1987) does not make difference between syllables and moras.

49
(and even C structure if there is a syllabic consonant). On the other hand, all syllable structures which involve any kind of consonant clusters will be treated as complex (CCV, VCC, CCVC, CVCC, CCCV, among oth-ers). However, some authors like Dankovičová and Dellwo (2007) treat even CVC structures as complex, so in order to compare the statistics done for several languages, including Serbian (Jovičić 1999), the same principle will be adopted in this study.
With respect to vowel reduction or whether there is the same vowel system and similar articulation in all syllables, regardless of the context, or not, languages which are positively marked for this feature are said to exhibit vowel reduction in unaccented syllables, while a maximal vowel system is used only in accented syllables (English). Unaccented weak forms undergo the reductions in the length of sounds, centralisation of vowels towards / /, and very often the elision of vowels and con-sonants (Gimson 1978: 263). On the other hand, languages which lack this feature (and are marked negatively for it) are said to have the same vowel system and a similar articulation for all syllables, independent of accentuation. If any of the processes like reduction in the length of vow-els or elision do exist, they affect both accented and unaccented syllables equally and are determined by the phonetic environment rather than by accent. Such languages are Spanish and Japanese (Dauer 1987).
What is obvious from the combination of values assigned to each fea-ture, languages with more “pluses” than “minuses” are said to be stress-timed. Such languages are said to have “strong stress” (Dauer 1987) and tend to maximize the differences between accented and unaccented syl-lables. Because of a dynamic and “expiratory” accent, accented syllables have longer duration and their vowels are fully realized, while unaccent-ed syllables have shorter duration and tend to be reduced in length or centralized. On the other hand, languages with more “minuses” are said to be syllable-timed, since they have all the vowels of equal duration and vowels fully realized in all positions.
Moreover, stress-timed languages have more complex syllable struc-tures than syllable-timed languages and as a result, the syllables in stress-timed languages tend to be heavier, making them suitable for carrying stress. On the other hand, in syllable-timed languages, stress and syllable weight tend to be independent. “This in turn, creates the impression that

50
there are different types of rhythm” (Ramus, Nespor and Mehler 1999: 5). What is interesting about Dauer’s approach is the third value that she introduced – [0] (zero). Languages which are marked [0] for a certain feature are said to partially exhibit a particular feature. For example, if a language is marked [0] for syllable length, that language is said to have accented syllables only slightly longer than unaccented ones. Moreo-ver, if a language is thus marked for vowel reduction, it is said to have both accented and unaccented syllables, but the unaccented ones are not necessarily reduced or centralized. However, there are some processes, like devoicing or raising, which still occur in such languages (the exam-ples are Russian and Portuguese). By introducing this third value, Dauer (1987) tried to contribute to the forming of the theory by suggesting that the distinction between different types of languages on the basis of speech rhythm is not bimodal but scalar. Thus, languages should not be put in either of the two existing categories but placed along a continuum depending on the extent to which each feature is present in a language. This means that these properties are cumulative, giving the impression that there are less typical stress-timed and syllable-timed languages put on the continuum with typical stress-timed and syllable-timed languages at either end of the continuum.
To support these claims, Dankovičová and Dellwo (2007) performed an experiment which showed that the languages traditionally classified as syllable-timed (French and Italian) indeed have a much lower per-centage of complex syllables than those traditionally classified as stress-timed (English and German). Namely, in French, about 80% of syllables consist of a single vowel or a consonant and a vowel (CV or, less fre-quently, VC structure). In Italian, this percentage is even higher – 90%. On the other hand, the percentage of complex CVC or CCV syllables is not more than 10% in Italian and 18.3% in French, with a negligible number of CVCC and CCVC syllables – 1.2% in Italian and 2.3% in French (Dankovičová and Dellwo 2007: 1241).
On the other hand, English and German spoken examples consisted of a considerably high percentage of complex syllables: in German, for instance, the number of complex syllables prevails over the number of simple syllables (only 35% of simple syllables). In English, the percent-age of complex syllables is a little over 50%. However, both languages

51
contain a considerable amount of complex syllables, which classifies them into the stress-timed group, according to Dauer’s parameters.
Czech has been traditionally classified as a syllable-timed language. However, the studies of Dankovičová and Dellwo (2007), as well as oth-er linguists, have shown that this picture is far from clear. Czech’s syl-lable complexity is far from that typical for syllable-timed languages like French and Italian. Interestingly enough, their experiment showed that Czech contains 65% of simple syllables, which is obviously less than in typical syllable-timed languages like French and Italian, but much more than in typical stress-timed language such as German. This result goes in favour of Dauer’s approach that there are certain languages which are somewhere in the middle between typically stress-timed and typically syllable-timed languages.
Figure 1: Syllable complexity for Czech, English, French, German, and Italian (Dankovičová and Dellwo 2007: 1242)
Serbian has a variety of syllable structures but obvious preference for simple syllables. According to Jovičić (1999: 95), 73% of Serbian syl-lables have simple structures: V, CV, VC, or C, a property of typical syl-lable-timed languages. In this respect, Serbian is similar to Czech since it exhibits a great percentage of simple syllables. However, this percentage is higher than in Czech and thus more similar to that of French, a typical syllable timed language. On the other hand, a slightly over 22% of syl-lables exhibit CVC, CCV, or VCC structure, 3% of syllables have CVCC or CCVC structure, while a negligible number of syllables (only 2% in the data examined) have other complex structures like CCCV, CCCVC, CCVCC, CCCVCC, CVCCC, etc. Although Serbian has a high percent-age of simple syllables, this great variety of possible syllable types is similar to those of typical stress-timed languages.

52
Table 1: The frequency of existing syllable structures in Serbian(examined on the data consisting of 401,076 syllables) –
taken from Jovičić (1999: 95)16
Rang Frequency SyllableStructure Total [%]
1 242,591 CV 60.48516 2 45,965 CCV 11.4583 43,565 CVC 10.8624 38,939 V 9.7085 11,327 CCVC 2.8246 10,112 VC 2.5217 3,046 CCCV 0.7598 2,593 CC 0.6469 1,007 CVCC 0.25110 554 C 0.13811 486 CCCVC 0.12112 415 CCC 0.10313 331 CCVCC 0.082514 98 VCC 0.024415 40 CCCC 0.009716 7 CCCVCC 0.001717 5 CCCCV 0.001218 3 CVCCC 0.000719 1 CCCCC 0.0002
16 Jokanović-Mihajlov (1990: 109) reaches a similar conclusion from her data: the CV structure prevails in Serbian.
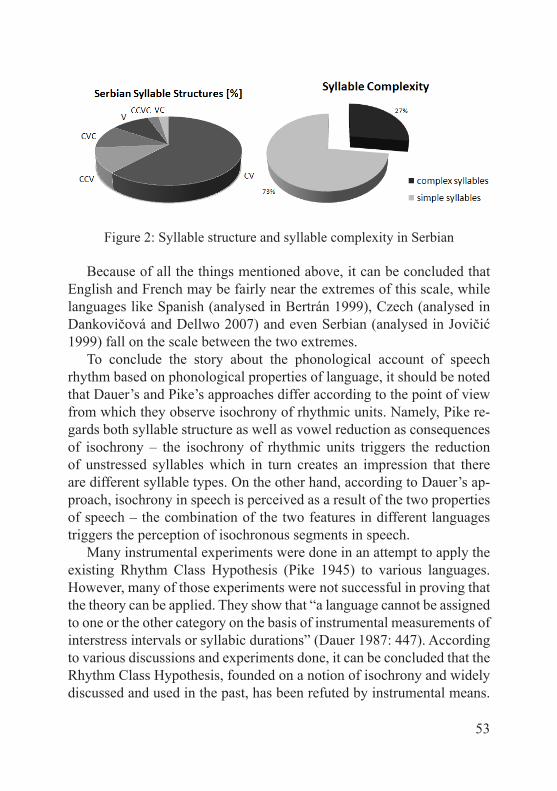
53
Figure 2: Syllable structure and syllable complexity in Serbian
Because of all the things mentioned above, it can be concluded that English and French may be fairly near the extremes of this scale, while languages like Spanish (analysed in Bertrán 1999), Czech (analysed in Dankovičová and Dellwo 2007) and even Serbian (analysed in Jovičić 1999) fall on the scale between the two extremes.
To conclude the story about the phonological account of speech rhythm based on phonological properties of language, it should be noted that Dauer’s and Pike’s approaches differ according to the point of view from which they observe isochrony of rhythmic units. Namely, Pike re-gards both syllable structure as well as vowel reduction as consequences of isochrony – the isochrony of rhythmic units triggers the reduction of unstressed syllables which in turn creates an impression that there are different syllable types. On the other hand, according to Dauer’s ap-proach, isochrony in speech is perceived as a result of the two properties of speech – the combination of the two features in different languages triggers the perception of isochronous segments in speech.
Many instrumental experiments were done in an attempt to apply the existing Rhythm Class Hypothesis (Pike 1945) to various languages. However, many of those experiments were not successful in proving that the theory can be applied. They show that “a language cannot be assigned to one or the other category on the basis of instrumental measurements of interstress intervals or syllabic durations” (Dauer 1987: 447). According to various discussions and experiments done, it can be concluded that the Rhythm Class Hypothesis, founded on a notion of isochrony and widely discussed and used in the past, has been refuted by instrumental means.

54
However, because of its universality (which is the tendency in all other language theories) it has remained a popular view among many linguists. Moreover, on the basis of all the tests mentioned so far which tested the physical reality of the isochrony theory on stress- and syllable-timed languages, it can be concluded that isochrony seems to exist only on the level of subjective perception since there is no physical evidence to the contrary. Future studies aim at the reformulation of the theory so that it still includes isochrony, but on the perceptual level only.
3.3 Perceptual Approach to the Study of Speech Rhythm
Ever since people started noticing that languages are spoken in a cer-tain manner which is perceived to be rhythmic, they started describing their impressions of how these languages “sound” to them. Rhythmic beats in the acoustic signal which is sent to the listener sound similar to either a machine gun (Spanish or Italian) or Morse code (English or Dutch), according to Lloyd James (1940). This description of our per-ception of spoken word in several languages gave us, as a result, the classification of languages made by Pike (1945) and widely used even today: languages are spoken with either stress-timed or syllable-timed rhythm (according to some other authors, there is also the third, mora-timed, category).
If we want to scientifically explain the process of speech production, we have to take into account something more objective than a simple description of what we hear. When the appropriate technology for testing this type of data was established, instrumental studies showed a great inconsistency with the starting hypothesis: the perceived isochrony in the speech signal, either of syllables or feet, does not have much to do with the physical reality. However, it seems that both the listener and the speaker are aware of the perception of this “patterned temporal oc-currence of pre-defined rhythmic units” (Tatham and Morton 2001: 3). That challenged the phonologists to try to discover what was there in the acoustic signal which triggered such perception, what the correlates of linguistic rhythm in speech signal were.
An extensive study in this area was done by Franck Ramus, Marina Nespor and Jacques Mahler (1999). They realized the importance of

55
finding correlates of linguistic rhythm in acoustic signal without relying entirely on the subjective perception of isochrony. They support Dauer’s view that languages differ in speech rhythm because their rhythm is a product of their phonological properties, of which the most important are syllable structure and vowel reduction.
Moreover, Dauer proposes the independent and cumulative nature of the properties in question, which places languages along the continuum depending on how much each property is present in a language. Typical stress-timed and syllable-timed languages would be placed on the two ends of the continuum, while the less typical ones, like Spanish, Polish, or Catalan (among others) would be scattered along the continuum, de-pending on how much each property is present.
The language can be near to either of the ends depending on whether it has more properties characteristic for stress-timed or syllable-timed languages, or as Antonio Pamies Bertrán (1999: 1) calls them languages of accentual isochrony and languages of syllabic isochrony, respectively.
3.3.1 Languages in the Middle: the Existence of Intermediate Languages
By assigning the values of the abovementioned properties to languag-es, it is obvious that there are languages which will not have all the “plus-es” or all the “minuses”. There will be languages, like Spanish, which seem to have some properties of the syllable-timed group as well as share some properties with the stress-timed group of languages. This is one of the reasons why Dauer (1987) suggested the existence of the continuum on whose ends are the two extremes – languages which are typically stress-timed, like English, on one end, and languages which are typically syllable-timed, like French17, on the other end of the continuum. In the middle of the continuum there are so-called “intermediate languages”, i.e. languages whose phonological properties match neither those of typi-cal stress-timed nor those of typical syllable-timed languages, or they
17 Although French is widely accepted to be a typical representative of syl-lable-timed rhythm, some French linguists do not agree with this (Wenck and Wioland 1982). Ramus, Nespor and Mehler (1999) are also very careful when French is concerned.

56
share some properties typical of both types of languages. Examples of such languages are Polish, Catalan, and Czech.
Catalan has often been described as a syllable-timed language, since it has a syllable structure similar to Spanish, which means that Catalan does not have a great variety of syllable types. However, studies done for this particular language have shown that it exhibits the vowel reduc-tion phenomenon, a property typically associated with stress-timed lan-guages. On the other hand, there are languages, like Polish, which paint the opposite picture: although having a great variety of syllable types and showing remarkable syllable complexity, it does not exhibit vowel reduction at normal speech rates. Although being traditionally classified as a syllable-timed language, the case of Czech still remains unclear. Dankovičová and Dellwo (2007) follow the rationale that syllable struc-ture of languages is responsible for their rhythmic characteristics. On the basis of this, they studied the complexity of Czech syllables. Czech’s syllable complexity is far from that typical of syllable-timed languages like French and Italian. With slightly less than 65% of simple syllables, it is closer to the stress-timed group with German and English as typical representatives (with the percentage of simple syllables 35% and slight-ly over 50% respectively) than to the syllable-timed group (French has 80% while Italian 90% of simple syllables). However, Czech does not allow vowel reduction, a fact which places this language in the group of syllable-timed languages. This property might be “stronger” from the point of view of perception, neutralizing the syllable complexity feature, which may be the reason why Czech is perceived to be a syllable-timed language.
On the basis of syllable structure property, Serbian should be treated as a syllable-timed language (see Chapter 3.2). However, Jokanović–Mi-hajlov (1990) suggests a kind of rhythmic organization similar to those of English: the unit of rhythmic succession is said to be a so-called rhyth-mic group which consists of one accented and a number of unaccented syllables, a unit which resembles an English foot.
Thus, the event which tends to occur periodically is not any syllable but the accented one. Moreover, Dauer (1987) suggests that Serbian is similar to English concerning the difference in duration between accent-ed and unaccented syllables. Accented syllables in Serbian, as well as in

57
English, are said to last longer than unaccented syllables, a fact which may contribute to the perception of the rhythmic groups mentioned by Jokanović–Mihajlov (1990). However, the other phonological property which is used to determine the status of a language in the existing typol-ogy, vowel reduction, has not yet been thoroughly studied by Serbian phonologists. Therefore, the crucial step in classifying Serbian on the basis of the existing rhythmic typology would be to determine whether Serbian allows vowel reduction or not.
Before Dauer (1987) placed these types of languages on her “rhyth-mic continuum”, languages such as Catalan and Polish (and even Czech) did not have their rhythmic status in phonology (Ramus, Nespor, and Mehler 1999: 5). However, Dauer’s approach, although perfectly ac-ceptable and sensible, fails to explain how rhythm is extracted from the speech signal by the perceptual system. Also, Dauer does not explicitly state where each intermediate language is placed on the rhythmic con-tinuum. She does not offer the exact parameters which determine the status of each language along the continuum. Rather, she states that these “intermediate languages” are just “scattered along a continuum.” Moreo-ver, she does not say how much each phonological property contributes to the perception of rhythm, nor how these properties interact with each other. For example, it is not clear whether in an intermediate language like Catalan its exhibited vowel reduction property is “stronger” than its variety of syllable types, which will place this language near the end of the continuum reserved for typically stress-timed languages like English, or it is the other way around.
Due to this drawback of Dauer’s approach, Ramus, Nespor and Me-hler (1999) go one step further and pose a question whether there is a possibility that there are more classes instead of a continuum. This idea should be taken into serious consideration. For instance, because of a number of different possible syllable types, it seems likely that there are more classes in which these different syllable types are grouped, three of which should correspond to the three existing classes (syllable-timed, stress-timed, and mora-timed). All in all, this is an empirical question which can only be answered after a detailed study of a great number of unrelated languages, which requires an exhaustive research to be done in this particular area.

58
In order to do such an exhaustive research, it is necessary to establish the steps according to which the research will be carried out:
I. The first thing that needs to be done before any kind of analysis takes place is data collection. In order to obtain easily comparable data, the same method needs to be applied for all the languages in question.
II. Secondly, some universal and more appropriate methodology needs to be established for studying this phenomenon.
III. In the end, both things need to be approached: empirical research and its possible interpretation, but without any presuppositions. This means that we start from the very beginning, not bearing in mind the existing typology of rhythm, not even presupposing that languages have rhythm. That is the only way we can make an ob-jective study and not be constrained by something which already exists and for which we are not yet sure whether it is true or not.
3.3.2 Corpus Selection
In order to do a research which would give us reliable results in the study of speech rhythm, a corpus of study needs to be defined. Since the topic at issue deals with the spoken language, some recorded speech data needs to be gathered. As it is obvious from the typological approaches to speech rhythm, most of the studies presented here deal with a limited number of languages, probably the ones which were at the disposal of researchers. That is why most of the things they hypothesized about can be easily applied to English but not to many other languages.When con-ducting such an experiment, it is highly important to select the corpus properly. Most of the experiments use a corpus of authentic data such as literary works, like Dauer (1983) who uses a fragment of literary prose, or recordings of spontaneous speech, like Ramus, Nespor, and Mehler (1999), among many others, who use sentences taken from a multi-lan-guage corpus initially recorded by Nazzi and his associates (Language discrimination by newborns: towards an understanding of the role of rhythm, 1998, mentioned in Ramus et al 1999). Given all the works dis-cussed in this book, the corpora used can be categorized as follows:

59
Table 2: Types of corpora1819
Type Examples Found in
Read text
Independent sentences
Ramus, Nespor, & Mehler 1999, Bertrán 1999Lehiste and Ivić (1986)
Literarypassages18
Poetry Navarro Tomás 192219
Literary prose Cummins 2002Dellwo 2002
Newspaper articles
Tatham & Morton 2001Jokanović–Mihajlov (1999)
Segments from radio programmes Jokanović–Mihajlov (1999)
Spon-taneous speech
On the particu-lar topic
Informaltelephoneconversation
Arai & Greenberg 1997
In-classpresentation Setter 2008
Radio programmes (monologues and dialogues)
Jokanović–Mihajlov (1999)
Picture description Setter 2008
Re-telling of a pre-read text not found in analysed works
For the purpose of their study, Ramus, Nespor, and Mehler (1999) used a multi-language corpus which consisted of short news-like declar-ative statements, whose number of syllables per sentence was in range
18 For more on what literary works were used in the studies of speech rhythm, see Bjelica 2010: 62 & Appendix.19 Mentioned by Bertrán (1999: 6).

60
of 15 to 19, and each sentence had an average duration of about 3 sec-onds. Every sentence was translated into all eight languages under study (English, Dutch, French, Spanish, Italian, Japanese, Polish, and Catalan) so that they have similar semantic content. What is interesting about the corpus used is that all the sentences were initially in French, but were later translated into the other seven languages. The exact translation was not as important as the number of syllables each translation contained. Bertrán (1999), on the other hand, did not use semantically similar sen-tences in all seven languages he studied. On the contrary, he mainly concentrated on the sentences which have rhythmic units of different length so that he could measure them without any difficulties. Tatham and Morton (2001) chose to use four articles from the front page of The Los Angeles Times issued on 25th December 2000, which was read by only one female speaker with the general accent of Southern California. The corpus consisted of a half a dozen stories in marginally different journalistic styles20.
Most of the researchers used several already created databases for the purpose of studying speech properties (especially speech rhythm). Some of those databases used are BonnTempo Corpus, OGI TS Corpus (The Oregon Graduate Institute Telephone Speech Corpus), and SCRIBE Cor-pus (Spoken Corpus Recordings in British English). BonnTempo Corpus is a collection of read speech which uses a short passage from a novel by Bernhard Schlink Selbs Betrug translated into several languages under investigation by philologically educated native speakers of the target lan-guages. OGI TS Corpus contains recordings of telephone conversations in which speakers responded in their native language to an automatically generated series of prompts, while SCRIBE Corpus consists of a mixture of read speech and spontaneous speech, where the speakers are given pictures to describe. For more on these databases, see Bjelica (2010: 62).
In each of the corpora used, the input is quantitatively valuable, because a very small corpus cannot be relevant in studying language phenomena since in such cases, the attained results may not reflect the
20 For the purpose of this pilot investigation, the current data was enough. If a more extensive research should be done, more data and a number of different speakers are to be provided.

61
true state of the particular phenomenon in a language. Besides this, the abovementioned corpora are qualitatively heterogeneous “and therefore susceptible to uncontrolled variables that determine the result of the measurements” (Bertrán 1999: 108). However, one needs to be careful with this kind of corpus. For example, if one uses a literary work, es-pecially a poem, as a corpus for studying speech rhythm, they could be committing a methodological mistake. Namely, the isochrony of rhyth-mic units within lines of verse in a poem is intentional rather than ac-cidental since very often, the organization of verse dictates the regularity of the occurrence of rhythmic units. Therefore, Bertrán (1999) poses a very interesting question which casts a shadow over many of the studies which used poetry for studying rhythmic organizations in a language:
“How can the basis of normal speech rhythm be the same as that in verse? Why should the poet and the critic worry about the isochronic distribution of stress if it is an inherent property of the language in question?”
(Bertrán 1999: 107).
Therefore, it is better practice to use fragments of every day speech for the purpose of studying this particular phenomenon.
In studying Serbian prosodic system, Lehiste and Ivić (1986) based their research primarily on the acoustic analysis of a corpus which con-sisted of 272 sentences of several types (different types of statements, questions, exclamation sentences, etc.) produced by two informants (one of them being one of the authors, Pavle Ivić, himself). Sentences were constructed in such manner to encompass the words with all four types of accent in Serbian. Although they tried to include as many different struc-tures as they could in order to avoid repetition, it seems that repeated pro-ductions of a smaller set of sentences would have produced more reliable data (Lehiste and Ivić 1986: 180). They are realistic about their corpus in saying that it does not provide enough material to answer all the ques-tions relevant for their research. Similarly, Jelica Jokanović–Mihajlov (1990) ran an experiment on the spoken corpus of Serbian. She included different examples of spoken language in her corpus for the purpose of studying Serbian prosody: segments of read text from radio programmes,

62
samples of spontaneous speech (monologues as well as dialogues) from radio programmes and everyday conversations, and read passages taken from literary prose and newspaper articles. This last type of texts is espe-cially used in the study of speech rhythm in Serbian. What is common to most of the studies presented in this book is the use of a controlled corpus for the purpose of the research. Bertrán (1999) used a series of “artifi-cially” created utterances which were similar, but which had the vari-able distance between the stresses, i.e. the variable number of unstressed syllables between the stressed ones. Ramus, Nespor, and Mehler (1999) created their corpus out of short news-like declarative statements, whose number of syllables per sentence was in range of 15 to 19, and each sen-tence had an average duration of about 3 seconds. Every sentence was translated into all eight languages under study so that they have similar semantic content. Tatham and Morton (2001) also used a controlled cor-pus made out of read speech. They excluded short sentences or unnatural utterances within frames, since these types of utterances tend to develop a rhythm of their own. Also, they decided to exclude ordinary conversa-tion because it is made out of too many “interruptions”, such as false starts, pauses, hesitations, and other interruptive effects. Lehiste and Ivić (1986) included as many different structures as they could in order to avoid repetition and to include all four accents equally.
The importance of making such a controlled environment for con-ducting a research concerning rhythmic properties of language is in con-centration on one particular point of speech process neglecting all the factors which may influence the flow of speech. For the purpose of de-signing a reliable speech synthesis programme, for example, it is more useful to analyse a stretch of read speech than recorded conversations or short sentences because the programme is more likely to produce speech in a read speech manner (for example, when reciting some retrieved in-formation form a database). However, utterances created ad hoc seem to be more reliable than fragments of literary language if we want to isolate the variables which are to be studied, as well as neutralize other factors. For example, since Bertrán’s “artificially” created utterances served the purpose of determining whether the addition of unstressed syllables af-fected the duration of the stressed syllable in a foot, it was necessary to create feet of different sizes and to measure their absolute durations.

63
The older studies suggested the compression of all the unstressed syl-lables within a foot, in order to preserve the perceived isochrony. Ac-cording to Bertrán, if this was the case, then the process of compression would not only affect the unstressed syllables within a foot, but also the stressed one. Bertrán mentions intrinsic duration of every vowel, the type of consonant following the vowel, the type of syllable (open or closed), as well as intonation pattern of the utterance to be the factors which may also influence the duration of a stressed vowel. For the purpose of this study, all these other factors were neglected, while special attention was paid to the accents which followed one another at variable distances. Syllables were more or less similarly structured. If it was not such a controlled environment, other factors would intervene and make the data more difficult to analyze.
3.3.3 Data Segmentation
One of the major problems of the rhythmic studies throughout history has been the lack of a consistent principle of data segmentation. Differ-ent methods in segmenting utterances are used and they consequently produce different results, which are difficult to compare.
According to some linguists, including Roach (1982), there is no lan-guage which is totally stress-timed or syllable-timed. He says that each language displays both sorts of timing, which only means that each spo-ken language is a mixture of different segments. Since these segments are not equally distributed within a language, languages differ with re-spect to the dominant segments and types of timing. This view was sup-ported by Tatham and Morton (2001), who say that rhythmic differences are not only detectable between two languages but also within the same language, depending on the style and context21.
For the purpose of his study, Roach (1982) segmented his recorded utterances by hand into syllables and feet. He also identified two ma-jor problems of speech segmentation: the first problem was identifying stresses in an utterance, while the second was identifying the beginning and the end of an interstress interval. Roach (1982) decided to measure
21 Examples given by Gore (2004) are already mentioned in the Chapter 2.5.

64
feet from the beginning of the stressed syllable (its onset) rather than from the intensity peak of the vowel in the stressed syllable, as many linguists before him did. Bertrán (1999) does this in the same way in order to measure the absolute duration of feet. However, unlike Roach (1982) who manually segmented utterances, Bertrán (1999) segmented his utterances using the system of computational prosodic analysis called C.E.C.I.L (Computerised Extraction of Components of Intonation in Language).
Ramus, Nespor, and Mehler (1999) segmented their utterances in eight different languages into vocalic and consonantal (i.e. intervocalic) intervals. Vowels and consonants were defined as highs and lows in a universal sonority curve.
The “highs” on that curve represent vowels, since they are the most sonorous sounds, while the “lows” on the curve represent consonants, sounds less sonorous than vowels. However, possible problems may oc-cur with syllabic consonants, especially liquids and glides. Glides, for example, were treated both as consonants and vowels depending on their position within an utterance. Namely, pre-vocalic and intervocalic glides (i.e. glides which are placed before a vowel and between two vowels) were treated as consonants, while post-vocalic glides (the ones that fol-low a vowel) were treated as vowels, for example:
(8) English: pre-vocalic: // “queen” intervocalic: // “vowel” post-vocalic: // “how”
(Ramus, Nespor, and Mehler 1999: 7)
On the other hand, Grabe and Low (2002) approached the data seg-mentation from acoustic point of view and not phonological. Namely, they segment utterances into vocalic and intervocalic intervals on the basis of the vowel formants –
“vocalic intervals were defined as the stretch of signal between vowel onset and vowel offset, characterized by vowel formants, regardless of the number of vowels included in the section”
(Grabe and Low 2002: 5).

65
Consequently, intervocalic intervals were defined as the stretch of signal between vowel offset and vowel onset, regardless of the number of consonants included. One major difference between Ramus et al.’s approach to segmentation and Grabe and Low’s is that not all vowels in an utterance are regarded as belonging to vocalic intervals. There are languages, like Japanese, where devoicing of vowels between voiceless consonants is common, and thus such vowels have different formant pat-terns from voiced vowels. Because of this, they are included in intervo-calic intervals (due to their acoustic properties, and not phonological), which consequently influences the duration of intervocalic segments, triggering the difference in results from those of Ramus et al.’s study.
However, Ramus, Nespor and Mehler (1999), as well as Grabe and Low (2002), manually determined interval boundaries, which seems to be one major limitation common to both of these studies. Despite the best efforts of phoneticians to provide clear labelling principles, the manual segmentation still seems to be largely subjective. Ensuring that different researchers will employ exactly the same criteria, especially in the studies of new languages, is virtually impossible (Ramus 2002: 5). Not only is it highly subjective, but it is also a time-consuming and tedious process. In BonnTempo corpus as well, the collected recordings were manually segmented into syllables, as well as into consonantal and vocalic intervals, based on acoustic and visual cues (Steiner 2004: 2).
On the other hand, Setter (2008) segmented utterances the same way Ramus, Nespor and Mehler (1999) did, but she used a programme for automatic processing of the speech corpus called Speech Analyser 2.2 (SIL software). The duration of vocalic and intervocalic (consonantal) segments was measured using wide-band spectrograms and waveforms (Setter 2008: 2). One of the most popular programmes for speech analy-sis and synthesis today is Praat (see Boersma and Weenink, 1992–2001). Moreover, there is a special collection of Praat based software used to facilitate access and analysis of the BonnTempo Corpus called the BonnTempo-Tools (see Dellwo et al. 2002).
The initial data preparation which includes the segmentation of re-corded data is everything but an easy work to do. As mentioned at the beginning, in order to do this, there should be an agreement on where to place the segment boundaries. The lack of a unique methodology has led

66
to different approaches and thus different results in instrumental studies, since all the conclusions based on the measures derived from segmen-tal durations crucially depend on the placement of segment boundaries. Consequently, results attained this way are rather difficult to compare.
3.3.4 Is There Rhythm to Begin with: Instrumental Studies of Rhythm
A number of studies and experiments have shown that the existing Rhythm Class Hypothesis proposed by Pike (1945) and adopted by Ab-ercrombie (1967) and many other linguists is based mainly on the sub-jective perception of speech. Even the early research done by Roach (1982) and Dauer (1983) showed a completely different picture from the one proposed by the abovementioned linguists. After doing an ex-periment involving six languages, three stress-timed and three syllable-timed, Roach (1982) came to the conclusion that not only was the vari-ation in syllable duration similar in all six languages, thus contradicting the existing hypothesis about stress-timed languages, but also the stress pulses were not more evenly spaced in stress-timed languages than in syllable-timed languages.
The results of the research thus questioned the classification of lan-guages on the basis of these properties. Similarly, Dauer (1983) con-ducted an experiment on the four typical representatives of stress-timed and syllable-timed languages (English being stress-timed, while Span-ish, Italian, and Greek were syllable-timed). She came to the very same conclusion that the stresses recurred no more regularly in English than in all other languages tested. Additionally, she concluded that the duration of interstress intervals for all languages analysed was directly propor-tional to the number of syllables they contained, i.e. the more syllables, the longer the interstress intervals will get. On the basis of all the tests which examined the physical reality of the isochrony theory on stress- and syllable-timed languages, it can be concluded that the isochrony seems to exist only on the level of subjective perception since there is no physical evidence to the contrary. As some linguists predicted, the instru-mental studies did not prove the existence of isochrony: moreover, they completely negated the very basis of the theory. For example, the results

67
of the study done by Antonio Pamies Bertrán (1999), which included Romance languages (Spanish, Catalan, Portuguese, Italian, and French) as well as English and Russian, prove that feet tend to last longer with the increase of syllables, which confirms the lack of accentual isoch-rony. Furthermore, syllables tend to last longer when they contain more sounds, which thus confirms the lack of syllabic isochrony. His results also prove that stressed vowels are not affected by the addition of syl-lables, i.e. there is no compression of stressed syllables in feet. On the basis of the results of Bertrán’s study, it seems that not only does the concept of isochrony fail, but the typology of languages based on it fails too. This is because all the languages studied responded similarly to the three tests he used22, which can only mean that in this respect languages behave the same.
The purpose of Bertrán’s study was not to negate only the concept of isochrony, so widely accepted in the past, but to negate the existence of rhythm in everyday speech. He starts by saying that the very term “rhythm” is a metaphor borrowed from music to explain certain aspects of verse and thus everyday language cannot be treated the same as the language of verse. He also mentions the fact that even in music rhythm is not always isochronic, but that there are even symbols to transcribe all kinds of anisochronic phenomena. If music is not always isochronic, there is no reason for speech to be isochronic at all. Although the main idea of speech rhythm originated from music, even music does not jus-tify this simplistic view of speech rhythm where all the languages in the world are said to posses either of the two types of isochrony: accentual or
22 Bertrán (1999) studied Romance languages (Spanish, Catalan, Portuguese, Italian, and French) and compared them to English and Russian. He reached the abovementioned results by using three tests which he applied to the data gathered through the experiment. First, he compared the feet durations to the number of syllables they consist of. Also, he compared the duration of a syllable to the number of sounds it contains. Secondly, he compared the temporal ratio between formally similar feet that started having more and more syllables in ut-terances which do not differ in any other way except this. Thirdly, he measured the time variation of stressed vowels in relation to the increase of syllables per foot in order to test whether the addition of syllables caused the compression of sounds inside the feet.

68
syllabic. Although this kind of symmetry can seem attractive to phonolo-gists, it is far from reality since the inherited vision of rhythm contradicts the empirical data attained through numerous analyses. Bertrán (1999) suggests that rhythm does not necessarily need to be isochronic, and that there are languages which have what he calls anisochronic rhythm (like in music). Additionally, he does not rule out the possibility that there are languages in the world which lack any kind of rhythm. However, most linguists did not completely discard the notion of isochrony, instead they reformulated the theory so that it accounts for isochrony on the percep-tual level only. One of such studies was done by Franck Ramus, Marina Nespor, and Jacques Mehler (1999).
Since syllable duration highly correlates with both syllable complexi-ty and vowel reduction, Ramus, Nespor, and Mehler (1999) support Dau-er’s approach by arguing that indeed there are some languages “whose features match neither those of typical stress-timed languages, nor those of typical syllable-timed languages” (Ramus, Nespor, and Mehler 1999: 5) and can be placed on the abovementioned continuum somewhere be-tween the typical representatives of the two classes. While Dauer (1987) proposes that languages which contain properties of both classes are ran-domly placed along the continuum, Ramus, Nespor, and Mehler (1999) go a step further and suggest the possibility that there are more classes than those originally proposed by Pike (1945) rather than a continuum (Dauer 1987). They conclude that this is an empirical question which can only be answered after a series of empirical investigations on a number of languages belonging to unrelated families (Ramus, Nespor, and Me-hler 1999: 5).
3.3.5 Nobody Puts Babies in the Corner: the Role of Rhythm Perception in Language Acquisition
Ramus, Nespor, and Mehler (1999) did a research from which an acoustic account of speech rhythm developed. This account classifies languages on the basis of statistical measures of duration of the two seg-ments: vocalic and consonantal. Moreover, the measures they attained correlate with the two rhythm class parameters mentioned previously: syllable complexity and vowel reduction. Their study was based on a

69
consonant/vowel segmentation of utterances in eight languages (English, Polish, Dutch, French, Spanish, Italian, Catalan, and Japanese).
The aim of their research was to determine the correlates of linguistic rhythm in speech signal in order to explain how infants extract rhythm of their native language from speech signal and use it to discriminate languages on the basis of rhythm perception and segmentation of speech. Moreover, they wanted to explain the role of rhythm perception in lan-guage acquisition. Namely, psycholinguists have relied on the existing classification of languages on the basis of their rhythmic properties to explain the infants’ capacity to discriminate languages. Despite exten-sive research done over the last thirty years, scientists have failed to identify reliable acoustic properties of language classes. From the results of many studies explained so far (Roach1982, and Dauer 1987), it can be concluded that the existing hypothesis was negated due to various instrumental measurements. Ramus, Nespor, and Mehler (1999) pose a question whether the instrumental means should be discarded altogether since they fail to explain the rhythmic classification of languages, or we should try to find more effective instrumental measurements that could account for the perception of speech rhythm. Although the phonological account, which explains rhythmic classes through phonological proper-ties (Dauer 1987) seems preferable, it fails to explain how rhythm is extracted from speech signal by the perceptual system. To clarify some of these questions, Ramus, Nespor, and Mehler (1999) did a comparative study of eight languages belonging to different rhythm classes.
They examine infants and not adults for the purpose of hypothesiz-ing about speech perception and language discrimination simply because adults use not only speech signal but also some other cues to differen-tiate between their mother tongue and other languages or between the two native languages in a bilingual environment. Apart from language rhythm extracted from speech signal, adults use intonation, phonetics and phonotactics, recognition of known words, and more generally, any knowledge or experience related to the target languages and to languages in general.
On the other hand, infants (the “newborns”) do not have any previ-ous knowledge, so they have to look for the cues in the speech signal they are exposed to from the very beginning of their lives. They rely on

70
the speech signal alone and extract every possible piece of information available through speech signal. Since language rhythm is the only thing infants can extract from speech signal at an early age, Ramus, Nespor, and Mehler (1999) claim that infants’ language discrimination behaviour relies on the stress-timed/syllable-timed dichotomy.
As it has already been mentioned, their main interest was to explain how infants learn a part of the phonology of their native language. In order to do so, Ramus, Nespor, and Mehler (1999) hypothesized that the rhythm type should be correlated with the speech representation unit in any given language. These representations may be feet (stress-timed languages), syllables (syllable-timed languages), or moras (mora-timed languages). Infants “decide” which representation to use by detecting the rhythm type of their native language in the speech signal they are exposed to. Ramus, Nespor, and Mehler (1999) tried to discover devices which help infants make this decision, since it seems to be crucial in acquiring their native language.

71
In doing so, Ramus, Nespor, and Mehler (1999) started with the pre-dictions about bilingual environments. If the two languages belong to the same rhythm class and thus have the same representation unit, in-fants will have no trouble selecting it and acquire both languages easily. On the other hand, if the two languages have different representation units, children will receive contradictory data and unless they are able to discriminate between the two languages without speech segmentation, acquiring is said to be much more difficult. Infants are said to use rhythm to do the discrimination process when they are exposed to languages of different rhythmic classes.
However, a problem which this approach may encounter has to do with the fact that only well-classified languages have been used in the experiments which tested the abovementioned predictions, and thus it cannot be predicted how infants would deal with the issue of intermedi-ate languages.
The question of intermediate languages, those which seem to belong to both rhythmic categories (stress-timed and syllable-timed, leaving mo-ra-timed aside for now) or which are placed in the middle of the rhythm scale (Dauer 1987), is inevitable. It is questionable whether infants are able to discriminate between languages such as Catalan and Polish (Ra-mus, Nespor, and Mehler 1999), or Catalan and any other stress-timed language (since Catalan is said to share some properties of stress-timed languages).
Answering all the questions stated so far would be crucial in under-standing how infants perceive speech rhythm, how they learn the pho-nology of their native language, and how they deal with any kind of bilingual environment.
Since vowels are more sonorous than consonants, Ramus, Nespor and Mehler (1999) point out that infant speech perception is concentrated on vowels.
“Vowels carry most of the energy in the speech signal, they last longer than most consonants, and they have greater stability. They also carry accent and signal whether a syllable is strong or weak”
(Mehler et al 1996: 112, quoted by Ramus,Nespor, and Mehler 1999: 6).

72
To support this assumption, many experiments were carried out (Ber-toncini, Bijeljac-Babić, Jusczyk, Kennedy, and Mehler 1988, among oth-ers) and their results show that infants do pay more attention to vowels than to consonants. Also, it is said that newborns are able to “count” syllables in a word, independently of syllable structure or weight. Ra-mus, Nespor, and Mehler (1999) thus assume that “an infant primarily perceives speech as a succession of vowels of variable durations and in-tensities, alternating with periods of unanalyzed noise (i.e. consonants)” (Ramus, Nespor, and Mehler 1999: 7). By proposing a hypothesis about simple speech segmentation into consonants and vowels, Ramus, Ne-spor, and Mehler (1999) wanted to show that this type of segmentation can account for the standard stress-timed/syllable-timed dichotomy, as well as to investigate the possibility of other types of rhythm. Moreover, such simple segmentation should also account for language discrimina-tion behaviour of infants, and in the end, it should be able to clarify how rhythm might be extracted from speech signal. Ramus, Nespor, and Mehler (1999) did not measure the duration of every single phoneme individually, since infants are still not able to tell the difference between the phonemes. Rather, infants have the capacity to tell the difference only between vowels and consonants. This is why Ramus, Nespor, and Mehler (1999) measured the durations of sequences of consecutive vow-els, which they called vocalic intervals, and the durations of consecu-tive consonants, better known as consonantal intervals, or as they, more conveniently, termed them “intervocalic intervals”.
For example, if we take a random utterance and transcribe it, we can segment the utterance as follows:
(9) We’re going to the playground / d/ [| | | | | | | | | | d] C V C V C V C V C V C This sentence is said to have 21 individual phonemes, but five vocalic
and six consonantal intervals23.
23 Because of its pre-vocalic position, the glide /w/ is treated as a consonant.

73
From the measurements of the two types of segments, Ramus, Ne-spor, and Mehler (1999: 7) derived three variables, each of them present-ing values derived for one sentence only:
1. The proportion of vocalic intervals in the sentence, marked as %V;2. The standard deviation of vocalic intervals within the sentence,
marked as ΔV;3. The standard deviation of consonantal intervals within the sen-
tence, marked as ΔC.The percentage of vocalic intervals of the overall utterance duration
is referred to as %V. This parameter shows how much the duration of vo-calic intervals takes from the duration of entire utterance, or the portion of vocalic intervals within the utterance. On the other hand, standard deviation24 is a parameter which shows us how much variation there is from the average; in this case, how much variation in duration there is from the average duration of vocalic or consonantal intervals. This pa-rameter, termed as ΔC or ΔV, is important because a low standard devia-tion indicates that the data points tend to be very close to average, which means that intervals tend to last the same amount of time. On the other hand, a high standard deviation indicates the differences in duration of vocalic or consonantal intervals, which indicates a greater variety of syl-lable types.
After measuring vocalic and consonantal intervals and calculating the three parameters, Ramus, Nespor, and Mehler (1999) concluded several things. Namely, it seems that ΔC and %V are directly related to syllable structure. As it was already mentioned, higher ΔC means more variabil-ity in the number of consonants which in turn means a greater variety of complex syllable types, while consequently the percentage of vowels (%V) is lower. On the other hand, higher %V means the opposite – the higher percentage of vowels in an utterance can only mean that the lan-guage in question has a high percentage of simple syllables, and thus lower standard deviation in the duration of consonantal intervals (ΔC). However, ΔV parameter cannot be as transparently interpreted as the previous two since there are number of factors which influence the vari-ability of vocalic intervals: vowel reduction (English, Dutch, Catalan),
24 Gauss used the term “mean error”.

74
contrastive vowel length (Dutch, Japanese), vowel lengthening in spe-cific contexts (Italian), etc. Dauer (1987) proposed that the two factors which directly influence rhythm are only vowel reduction and contras-tive vowel length. Ramus, Nespor, and Mehler (1999: 9) thus conclude that ΔV still tells us something about the phonology of languages, but it remains an empirical question whether it tells us something about the perception of rhythm.
Due to this observation, the two parameters which are relevant for the present study are ΔC and %V.
Table 3: Proportion of vocalic intervals (%V) and standard deviation of consonantal intervals (ΔC) over a sentence, averaged by language
(taken from Ramus, Nespor, and Mehler 1999: 25)Language %V ΔC (*100)English 40.1 5.35Polish 41.0 5.14Dutch 42.3 5.33French 43.6 4.39Spanish 43.8 4.74Italian 45.2 4.81Catalan 45.6 4.52Japanese 53.1 3.56
After doing extensive research on eight different languages, Ra-mus, Nespor, and Mehler (1999) concluded that the measurements of the speech signal seem to support the idea that rhythmic classes do re-ally exist, not only in our intuitions about speech rhythm, but also as meaningful categories which reflect the actual properties of speech sig-nal in different languages. Not only do they support the Rhythm Class Hypothesis, but they also include Dauer’s approach by stating that not all languages belong to the three categories. Since they studied only eight languages selected from those studied by other linguists in order to sup-port the existing three classes, the data measured perfectly fit the story about the rhythmic classes, which only led to a conclusion that more

75
languages must be measured to get the complete picture on the issue of speech rhythm. However, Ramus, Nespor, and Mehler (1999) are real-istic about future studies by stating that the further research and adding more languages could dissolve the existing rhythmic categories. Since the languages used in the study are well classified as belonging to the three existing categories, Ramus, Nespor, and Mehler (1999) propose that the spaces between the three categories may become occupied by already mentioned intermediate languages. The idea of continuous dis-tribution of languages would challenge the notion that languages cluster into classes and diminish the very existence of the rhythmic categories, supporting the idea that languages are placed along a continuum (Dauer 1987). Alternatively, adding new languages to the study about speech rhythm could also reveal the existence of more than three rhythmic classes. For example, an attempt to do so came from Levelt and van de Vijver (1998). They used syllable complexity as a property directly influencing the rhythmic properties of languages. On the basis of increas-ing rhythmic complexity among languages under study, they proposed the existence of five different classes. Three of those correspond to the existing three rhythmic groups. In one of the other two groups, there are languages which are said to have properties of both syllable-timed and stress-timed languages – so-called intermediate languages. The fifth group is reserved for languages which have the simplest syllables of all, strictly CV languages.
Table 4: Different rhythmic classes based on syllable complexity(Levelt, van de Vijver 1998)25
complexMARKED I: stress-timed languages (English, Dutch)MARKED II: intermediate languages (Catalan, Polish)MARKED III: syllable-timed languages (Spanish, Italian, French)MARKED IV: mora-timed (Japanese)UNMARKED: strictly CV languages
simple
25 Mentioned by Ramus, Nespor, and Mehler (1999: 17).

76
To conclude their story, Ramus, Nespor, and Mehler (1999) state that the notion of three distinct and exclu-sive rhythmic classes has not yet been definitely proven, but it is, in their opinion, the best description of the cur-rent evidence. Everything mentioned so far only fur-ther stresses the importance of collecting more evidence from less studied languages which need to be included in the present study. Ramus, Nespor, and Mehler (1999) are aware of the problem of incomplete data and have solutions to overcome it. They also suggest a line of research which needs to be pursued. However, they draw conclu-sions from the evidence they collected and preserve the notions of rhyth-mic groupings since no other evidence is presented by the data they used in their study. Moreover, if we take a closer look at the parameters they
used, it seems like they sub-consciously went for the most appropriate combina-tion of parameters (Figure 3) – the combination which would eventually prove the existence of the three rhyth-mic categories. No other combination of the three pa-rameters they used presented the desirable results, so they conveniently decided to ig-nore them (Figures 4 and 5).
Ramus, Nespor and Mehler (1999) do not discard the idea that lan-guages have some kind of rhythmic organisation, on the contrary. They compare spoken language to any other well-organised motor sequences which require precise and predictable timing, thus there is every reason

77
to expect a spoken language to have such rhythmical or-ganisation like walking or typ-ing. Due to this, the temporal organisation of speech should not be arbitrary. In the light of Chomsky’s Universality Theory and Principles and Pa-rameters, Ramus, Nespor and Mehler (1999) suggest the ex-istence of a basic rhythm of all languages, and the differences are due to a few adjusted “settings” (parameters). This approach looks quite tempting since it is heading towards the universality of rhythmic theory, but in order to answer all the questions about this and further develop this universal idea, more research needs to be done and more languages need to be included in the study.
3.3.6 It’s Not That Easy: Drawbacks of Instrumental Studies
Some linguists criticize Ramus et al.’s approach for several reasons. First of all, the corpus that they use is said to be too controlled and does not go in favour of the generalisation of the results. Ramus (2002) real-izes this problem and states that any further extension of corpus would have one major problem – extensions would need to follow an identical method in order to produce comparable results, i.e. the same methodol-ogy needs to be applied to all the languages in question, although the strict control of the data can sometimes be too subjective and limiting. He realizes the importance of controlling speech rates when recording the data since their durational measurements would be affected by dif-ferent speech rates.
In order to control it, Ramus, Nespor and Mehler (1999) chose a cor-pus which matches both the number of syllables per sentence and sen-tences’ duration across languages. This approach is questionable since it requires that the speech rate is predefined and the speakers are asked to adopt it, thus altering their own spontaneous speech to something which

78
is pseudo-spontaneous. Ramus (2002) states that future research would need to contain not only more languages and more speakers per each language, but also more speech samples which will be said in different speech rates, different registers, etc.
Esther Grabe and Ee Ling Low (2002) tried to overcome this prob-lem by introducing more languages, but not constraining the data used – speakers were asked to speak at their own speech rates. Although the number of languages tested is considerably higher than in Ramus et al. (1999) (18 languages were tested, those well classified according to the existing rhythmic classification as well as those less studied and not yet classified languages), the number of speakers per language is smaller – namely, only one speaker per language was recorded. This can be a seri-ous problem since it can reflect that speaker’s speech characteristics and personal style as well as language characteristics, so the need of having more speakers in order to average the data across several speakers is not questionable at all. “The more numerous the speakers, the safer the con-clusions” (Ramus 2002: 2). Instead of tightly controlling the data used, Grabe and Low (2002) normalized their results for changes in speech rate (which will be discussed in detail later).
The main methodological difference between the two studies was the segmentation of the data used. Namely, Ramus, Nespor, and Mehler (1999) segmented their utterances into vocalic and consonantal intervals by using their phonological properties – the vowels are said to be more sonorous than consonants. On the other hand, Grabe and Low (2002) approached the segmentation from the acoustic point of view. They seg-mented the utterances into vocalic and intervocalic segments on the basis of their acoustic properties, which means that they measured the duration of a vowel only if there was evidence of a voiced vowel in the acoustic signal. Due to the existence of devoiced vowels in some languages (like Japanese), instead of using the term “consonantal intervals”, they decid-ed to use more convenient term “intervocalic”, since not only consonants can be included in these segments (see Data Segmentation). This in turn created a serious methodological problem since the results of the two experiments were considerably different for some languages due to the increase in the duration of intervocalic intervals after including devoiced vowels.

79
Furthermore, Grabe and Low (2002) introduced a different parameter for calculating the differences in the duration of vocalic and intervocalic intervals. Pairwise Variability Index (PVI) calculates the average dif-ference in duration between two successive vowels over a whole utter-ance. It allows us to determine the difference in prominence in the pairs of analysed segments and expresses the level of variability in successive measurements. In order to control the speech rate and not let it influence the results, they normalized each difference between two intervals by their average duration. Ramus (2002) criticised this approach by saying that if we perform normalisation for all the data from all the languages tested, it would mean neglecting the language specific rules of phono-tactics and segmental inventories of languages under study. To defend themselves in some way, Grabe and Low (2002) sensibly argue that nor-malisation is desirable for vocalic, but not for intervocalic intervals since they depend on the abovementioned language specific properties. So, they compute normalized PVI (nPVI) for vocalic, and raw (unnormal-ized) PVI (rPVI) for intervocalic intervals. Moreover, rPVI should be definitely computed for intervocalic intervals of Japanese data.
Just like in Ramus et al.’s study (1999), the duration measurements in Grabe and Low’s study provide acoustic evidence for the rhythmic clas-sifications of speech. When they computed an acoustic variability index which expresses the level of variability in vocalic and intervocalic inter-vals, their data supported a weak categorical distinction between stress-timing and syllable-timing. Namely, stress-timed languages are said to exhibit high vocalic nPVI as well as high intervocalic rPVI values. This is due to the fact that languages like English (stress-timed) have both full and reduced vowels, which contributes to a high level of variability in vowel durations.
Consequently, intervocalic intervals show a high level of duration variability as well. On the other hand, syllable timed languages are said to lack vowel reduction and their syllables are simple and more or less of similar duration. Because of that, their level of duration variability in both vocalic and intervocalic segments is expectedly low. However, due to the existence of intermediate languages and their durational measures which show that languages can be more or less stress-timed or syllable-timed, Grabe and Low (2002: 10) opt for a gradient nature of rhythmic

80
classification rather than a strict categorical distinction between the two groups (as Ramus et al. 1999 propose).
A problem which occurred in their approach was the inability to clas-sify the newly studied languages into either of the two categories26. Ra-mus (2002) gives as a possible explanation an insufficient number of speakers per language. He thus concludes that in order to do reliable research it is essential to have a variety of speakers for each language and to control for speech rate either by constraining the corpus (Ramus, Nespor, and Mehler 1999) or by using a normalization procedure (Grabe and Low 2002).
3.3.7 Serbian: the Scarcity of Instrumental Studies
Given the scarcity of instrumental studies of speech rhythm in Ser-bian, a classification of this language on the basis of the traditional stress-timing/syllable-timing dichotomy is left without firm evidence. Namely, phonology teachers tend to make a distinction between English and Serbian in this respect and classify Serbian as a syllable-timed lan-guage. However, without empirical evidence, this is nothing but a set of words on a piece of paper. From the studies of Serbian speech rhythm which have been analysed in this book, it can be concluded that a pic-ture of Serbian speech rhythm characteristics is far from clear. These studies (Jokanović–Mihajlov 1990, Jovičić 1999) show that Serbian ex-hibits both sorts of timing and has characteristics of both stress-timed and syllable-timed languages. Supporting the view that there is either a rhythmic continuum or more rhythmic classes, it can be concluded that Serbian, in this respect, looks quite like Czech and belongs to the group of so-called “intermediate languages”.
As it has been already mentioned in previous chapters of the book, Jokanović–Mihajlov (1990: 109), in her study of speech rhythm in Serbi-an, discusses the structure of Serbian rhythmic groups. Namely, she pro-poses a groundbreaking theory in suggesting a unit of Serbian rhythmic organisation which extremely resembles that of English. She discards
26 They exclude mora-timed as a third category and regard Japanese as a syl-lable-timed language.

81
syllable as a unit of rhythmic organisation and instead she introduces rhythmic groups. Her study shows that most of these rhythmic groups in Serbian are made out of two or three syllables, mostly CV in struc-ture (61.6%). Then come groups with four (21.1%) and five syllables (8.62%), while monosyllabic groups which have their own accents are very rare (only 3%). This last percentage was expected due to the fact that a large number of monosyllabic words in Serbian are clitics (either proclitics or enclitics), words which do not have an accentual pattern on their own but need to group with the word which precedes them (enclit-ics) or the word which follows them (proclitics) to receive an accent (consequently, they are treated as unaccented weak syllables). According to the analysis done by Jokanović–Mihajlov (1990: 110), most monosyl-labic rhythmic groups which have their own accents are of the CVC type (clitics are of the CV type mostly).
Since most Serbian syllables are of the CV type, rhythmic groups are made out of such syllables. Disyllabic rhythmic groups are of the CV-CV type, trisyllabic and other polysyllabic of the CV-CV-CV-… type, with the possibility of having V or VC type syllables as well. Not only do these groups consist of a miscellaneous set of syllables, but the variety of their structures is even higher due to different positions of accent in similar structures. The duration of such segments is also measured on the corpus used in the study.
The mean duration of vowels in accented syllables, regardless of the accent type, was 79.19 ms for the corpus in question. Long accented vowels lasted about 96.92 ms, while the average duration of short ac-cented syllables was 73.69 ms. Unaccented syllables have the average duration of 52.01 ms. Although it is said that accented syllables are sig-nificantly longer than unaccented syllables in Serbian, Jokanović–Mi-hajlov’s results show that the difference in duration between these two types of syllables is not as great as it was expected, and that this differ-ence is even more negligible when a word is pronounced in a sequence than in isolation. This brings us to the conclusion that even Serbian syl-lables, especially the accented ones, undergo some kind of contraction in speech (discussed by Jones 1978). Jokanović–Mihajlov (1990) states that this is evidence that syllables need to be modified inside a rhyth-mic group in order for a stretch of speech to be rhythmically organised

82
(Jokanović–Mihajlov 1990: 110). Jokanović–Mihajlov even notices the reduction in length of vowels in post-accented syllables in some con-texts, as well as a general tendency of reducing vowels in pre-accented syllables inside a rhythmic group in order for the ones in post-accented syllables to be lengthened (Jokanović–Mihajlov 1990: 110). The longer the rhythmic group, the shorter will its segments be, an idea which is well-known from the typological studies of speech rhythm based on the notion of perceived isochrony.
When vowel reduction is concerned, it is a well-known fact that speakers of the dialect of Serbian spoken in some parts of Bosnia and Herzegovina tend to reduce their vowels considerably in post-accentual positions. According to Brown and Alt (2004), they tend to reduce their post-accentual short vowels (especially /i/ and /u/), while the long ones are heard clearly. Not only do they reduce short post-accentual vowels, but they very often drop them completely, for example: Zen’ca instead of ZenIca (the name of the town in Bosnia), slan’na instead of slanIna (‘bakon’), napomen’ti instead of napomenUti (‘to remark’), etc. How-ever, Bosnians are said to make fewer accent and length distinctions than speakers in Serbia do. Moreover, even in the dialect(s) of Serbian spoken in Serbia, the syllable following the falling accent is said to have a weak vowel (even voiceless, according to Trager 1940, although Serbian does not have voiceless vowels), while it is not the case with a syllable after the rising accent which is said to have a full vowel (Trager 1940: 30). It thus seems that the vowels of post-accentual syllables are prone to reduction if preceded by a falling accent. Nevertheless, the weakening of a post-accentual syllable is a good starting point for the vowel reduction process to take place. Obviously, some kind of vowel reduction does oc-cur in Serbian data.
If we dared to classify Serbian according to the existing rhythm typo-logy of languages, Serbian would be somewhere between those typically stress-timed and syllable-timed languages, just like Czech. As it has al-ready been mentioned, Serbian has a high percentage of simple syllables (73% – Jovičić 1999), a property of typically syllable-timed languages. Moreover, the difference between accented and unaccented syllables in terms of duration and intensity (prominence) is not as high as we ex-pected – again, a characteristic of syllable-timed languages. However,

83
the basic unit of rhythmic organisation is not a syllable but something more complex than syllable – it is a rhythmic group, a semantic unit con-sisting of one accented and a number of unaccented syllables, which has one accentual pattern. Furthermore, according to the results of a study done on Serbian data, it seems likely that Serbian unaccented (either pre-accented or post-accented syllables) undergo some kind of vowel reduc-tion in connected speech – a property of a typical stress-timed language. The problem with Dauer’s phonological account of speech rhythm, as it has already been mentioned, is the fact that she does not state how much each property contributes to the perception of rhythm, which property is “stronger” and is thus more important in determining the exact position of a language on the rhythmic continuum.
However, due to the scarcity of the studies concerning speech rhythm in Serbian, such conclusion will be left open, with the hope that some day valid research will be done on a Serbian corpus, similar to the ones done for many other languages by Bertrán (1999), Ramus et al. (1999), Dankovičová and Dellwo (2007), Setter (2008), among others. The fu-ture studies about speech rhythm in Serbian should thus involve some kind of empirical research which has already been done for some other languages, including English, French, Italian, Spanish, and even Arabic, Japanese, and Czech. First of all, in order to collect the data for small research on the topic of speech rhythm in Serbian, some kind of a corpus would need to be established.
Such corpus could be constructed similarly to some other corpora used in the abovementioned studies. For example, Serbian data should be included in the BonnTempo Corpus and some other multilanguage corpora. Moreover, it is necessary to agree on an appropriate methodol-ogy which would be applied for this type of research. Due to the con-troversial and delicate nature of speech rhythm, the experiment needs to be conducted in a highly controlled environment. Secondly, the corpus should be segmented in several ways depending on what we want to examine. Namely, we should measure consonantal and vocalic segments in order to calculate the proportion of vocalic intervals (%V) as well as the standard deviation of consonantal intervals within the utterance (ΔC). On the basis of these measurements, Serbian could be placed on the %V/ΔC diagram in order to precisely determine its position in relation to

84
the existing rhythmic classes. Moreover, since the syllable structure has been widely studied on Serbian corpora, the vowel reduction phenom-enon deserves more attention. When both of these properties are studied carefully, Serbian could be described in relation to these properties and placed on the rhythmic continuum proposed by Dauer (1987).

85
4 HOW TO APPLY THE STUDY OF SPEECH RHYTHM:Speech Synthesis and Rhythm Teaching
The reasons for studying prosodic features are both scientific and non-scientific in nature. Not only do these sorts of information help lis-teners segment speech utterances and enhance their understanding, as well as help learners of foreign languages sound more native-like, but they can also help develop or improve programmes for speech synthesis and speech-recognition devices. Consequently, the speech produced by a machine can sound more natural, as if pronounced by humans, and thus more accurate. It is of great importance to create a reliable speech synthesis programme, as well as to introduce some exercises into English language classes which would help students master the accurate English way of speaking and, consequently, enable listeners to understand the message more quickly and easily.
Mark Tatham and Katherine Morton’s (2001) study about speech rhythm was aimed to help in designing a reliable speech synthesis pro-gramme. As in all other studies based on the perceptual approach to speech rhythm, they concluded that the assumed isochrony was only perceived by the speaker and they sought to find the correlates of that perceived isochrony in the acoustic signal. The question they pose in the paper is concerned with why listeners hear the rhythmic succession of units if that succession does not exist in the speech signal produced by the speaker. Many researchers before them tried to find some measure-able parameters in the acoustic signal which triggers the perception of a regular rhythmic succession of pre-determined speech units (cf. Ramus, Nespor, and Mehler 1999). Although many of the extensive statistical studies done on different corpora negate the existence of any kind of isochrony, researchers had hard time leaving the existing theory behind and in the process of study they made a number of methodological mis-takes. Instead of stating that isochrony does not exist in physical reality of speech and looking for some other explanation for the perceived isoch-rony, they manipulated their data in order to find any isochrony model in the acoustic signal. In this manner, they did not follow the uniform path of data segmentation but segmented the utterances in different ways to

86
find the segmentation which best fit the frame they wanted to present. It is well known that in order to have a uniform approach to rhythmic theory and comparable results, specific rules for data segmentation must be set. Tatham and Morton (2001) set such rules for their data analysis.
Tatham and Morton (2001) state that both the listener and the speaker are aware of isochrony in speech. If isochrony is an expected feature of human speech, the acoustic effects which would trigger the perceived isochrony in the listener seem to be highly important in designing a reli-able synthesis system. If isochrony is lost due to the lack of such infor-mation, the results of the synthesis process would sound unnatural and difficult to perceive.
So the question which they pose is concerned with the way people successfully generate the acoustic signal in order to cause an appropri-ate response in the listener. Contrary to expectations, the results of most studies show the lack of isochrony in the acoustic signal, so the task gets more complicated since we obviously need to synthesise rhythm which is not isochronic in nature but which gives rise to the perception of isoch-rony in the listener.
Tatham and Morton (2001) did a pilot research in order to test wheth-er their expectations about speech signal are true or not. The starting hypotheses are the ones which exist in the theory of speech rhythm proposed by Pike (1945) and Abercrombie (1967) and their supporters. Namely, they start from the proposition that isochrony exists, that the rhythmic units which will be tested are isochronous. Also, they assume that there is no correlation between the duration of a rhythmic unit and the number of syllables it contains.
This means that there has to be some kind of compression and con-traction of the syllables which are added to the rhythmic unit. In the end, they propose that the syntactic boundaries have no effect on the rhythmic units, i.e. rhythmic units will not increase in duration before particular syntactic boundaries, nor will they decrease in duration right after the boundaries (however, this can only affect the so-called “hanging” rhyth-mic units which occur at the beginning of syntactic units but do not have any stressed syllables within).
As they expected, their research negated all of the hypotheses pro-posed at the very beginning. Tatham and Morton (2001) showed in their

87
study that isochrony does not exist, but that there is some stability in the duration of rhythmic units, i.e. that rhythmic unit duration is not random and that variations in the duration of rhythmic units, though wide, show a remarkable consistency (marked by v in the table):
Table 5: Durations of rhythmic units for the newspaper articles used in the study (Tatham and Morton 2001: 15)
They speculate that this may be the reason why these variations in duration are neutralized easily by the perceptual system of the listener, which consequently leads towards the perceived isochrony (Tatham and Morton 2001: 15).
Furthermore, their investigation confirmed the correlation between the duration of a rhythmic unit and a number of syllables it contains. Their study shows a regular increase in the duration of rhythmic units as the number of syllables in the unit increases. Tatham and Morton (2001) even calculated a correlation coefficient of +0.54, which is a fair positive correlation of 95% confidence.
This increase in the duration can only mean one thing: there is no contraction of existing syllables in order for rhythmic units to have the same duration, thus there is no isochrony of rhythmic units, at least not isochrony of this type.
The real contribution of Tatham and Morton’s study (2001) lies in an attempt to create the perceived isochrony for the purpose of speech synthesis by constructing the predicative rhythm unit duration model. They defined the basic rhythmic unit, on the basis of which they generat-ed a consistency in speech signal in the following way: the basic rhythm

88
unit is said to be of a model “stressed + unstressed” (i.e. two syllables), which is marked by L and has an average (or mean) duration of 436.7ms. All the other rhythmic units are calculated according to it as follows:
One-syllable unit: L - (L*20/100)Two-syllable unit: L = basic rhythm unit (duration = 436.7 ms)Three-syllable unit: L + (L*15/100)Four-syllable unit: L + (L*35/100)Five-syllable unit: L + (L*55/100)The ratio is basically as follows: [62] : 80 : 100 : 115 : 135 : [155]
(Tatham and Morton 2001: 16)
They calculated the predicted durations of all the syllables they used in their data and compared them to the measured values. The two types of data showed very few inconsistencies, which means that their predic-tions were correct.
However, in order to make predictions even more reliable, Tatham and Morton needed to test the third hypothesis they had posed at the very beginning. They stated that the syntactic boundaries had no influence on the duration of rhythmic units, but as they had expected, this proved to be wrong.
That is why they took into account that the units before syntactic boundaries tend to last longer (even around 20% greater in duration). Moreover, there are units which occur right after a syntactic boundary and do not include any stressed syllable. Such units tend to last shorter. In order to account for these “irregularities” in the speech signal, they calculated the unit that immediately follows a pause as a value of L which corresponds to a unit with one fewer syllable.
On the other hand, a unit which immediately precedes a pause (a syn-tactic boundary) uses a value of L which corresponds to a unit with one more syllable. When they calculated all these pauses in the data, the pre-dicted and measured results fit almost perfectly:

89
Figure 6: Predicted rhythm unit durations shown against measured unit durations in the test data with utterance block end corrections before each
pause (Tatham and Morton 2001: 18)
Many researchers before them (Bertrán 1999, Ramus, Nespor, and Mehler 1999, among others) neglected the influence of syntactic bounda-ries, and only measured perfectly defined rhythmic units, which is one of the examples of data manipulation in order to get expected results. What Tatham and Morton wanted to show is that although there seems to be no isochrony of rhythmic units in the acoustic signal, there are some regularities in speech signal which the listener perceives as isochronous. If there is something which is regular in speech, there has to be a way to create a model which would predict the durations of the rhythmic units in speech production. The results of this study can be used to generate a model of speech synthesis that would produce sound which is natural and closer to real human speech. Since their analysis revolves around English and generates a model for English, it would be useful to test their predicative model on other languages as well. The importance of studying prosodic properties of speech is by far the most important in the process of creating a reliable program for speech synthesis. Such projects require multidisciplinary teams of experts: acoustic, linguistic, programming, mathematic, as well as signal processing. Such a Research and Development group at the Faculty of Technical Sciences (Univer-sity of Novi Sad, Serbia), named AlfaNum, has developed Automatic Speech Recognition (ASR) and Text-To-Speech (TTS) engines for the Serbian language. The ASR programme has a goal to train computers to understand human speech. On the other hand, TTS synthesis has to teach computers to read any text.

90
Due to a great variability in speech signal, it is impossible to create reliable programmes to perform such complicated tasks without study-ing prosodic features of a language – in this case, Serbian. It is crucial in creating a programme which would synthesise speech that would sound natural and human-like. This is important not only because such speech is nice to hear but also because it is easier to understand – listen-ers have a hard time identifying words and sentence boundaries and thus understanding the message if the natural flow of speech is in any way interrupted. Many such programmes for speech synthesis are designed to produce speech that has a constant fundamental frequency, which in turn creates a problem for the listeners who make additional effort to concentrate on understanding what is being said.
While processing the information about phoneme inventory in a lan-guage is easier, the processing of prosodic information is everything but an easy work to do. Especially in Serbian, it is important to have proper intonation and accentuation since very often words change meaning or lexical category depending on the type and the position of accent within a word, which in turn creates confusion in processing the message.
As it has already been mentioned (see Data Selection), for the purpose of designing a reliable speech synthesis programme, it is more useful to analyse a stretch of read speech than recorded conversations or short sen-tences because the programme is more likely to produce speech in a read speech manner, when reciting retrieved information from a database.
4.1 Why Should Speech Rhythm Be Taught in Language Classes?
Gilbert (2008: 2) states that “time spent helping students concentrate on the major rhythmic and melodic signals of English is more important than any other efforts to improve their pronunciation”. However, in Eng-lish teaching practice, the study of pronunciation has been mainly con-centrated on the segmental aspects of English and speech rhythm contin-ues to be a much neglected part of language teaching courses. Students have been taught phonemes, phoneme contrasts, as well as phoneme sequences, while stress and rhythm have been traditionally neglected, especially in the classes of English as a foreign language. According to Sabater (1991: 145), “an appropriate stress and rhythmic pattern is more

91
important for intelligibility than the correct pronunciation of isolated segments”, since these two prosodic features are said to determine the correct pronunciation of segments in English. This is so because stress and rhythm give overall shape to the word or sequence of words.
Rhythm is as problematic for teaching as it is for learning. If taught in the first stages of language learning, many segmental and any other problems can be avoided. It is difficult to teach rhythmic patterns since it is hard to concentrate on rhythmic patterns as a separate unit of speech, without paying attention to other speech properties (segments, for exam-ple). Sabater (1991) points out that when the pronunciation of the right rhythmic pattern is required, students tend to concentrate on the stress pattern, neglecting all the other properties of speech and thus making un-necessary mistakes. However, teachers can try to help learners develop, at least, an awareness of rhythm by highlighting rhythmic patterns apart from words and meaning. A good practice for doing so is to “divorce” rhythm from its context and content. In that way, teachers can draw learners’ attention to it, help them acquire it, and then, finally, practice meaningful phrases with it. One way of divorcing the rhythm from its environment is to practice nonsense phrases with appropriate rhythmic patterns. Once students are able to hear and also reproduce the selected patterns themselves using the nonsense syllables, they can try to distin-guish actual phrases. Moreover, rhythm practice is most effective when physical activity is included which is a good way of showing students the difference between stressed and unstressed syllables in an utterance. Such activities can include tapping, clapping, using some rubber materi-als to stretch if a syllable is perceived as stressed or to squash it if a syl-lable is perceived as unstressed, etc.
The importance of mastering foreign language rhythmic properties lies in the fact that a person who studies the particular language will have much better communication with people whose native language he or she has been learning. Not only would they sound more natural and native-like, but the listeners would not have hard time understanding the message presented in a manner which is more natural and more usual for their native language. Speech segmentation would thus be much easier to do if the speaker used the representation units which are characteristic for the language he or she is trying to speak. Although many people think

92
that the message can be understood even if different rhythmic patterns are used as long as the segments, words, and phrases are intelligible, the appropriate segmentation of speech utterances has the same value as spaces in written texts – the message would indeed be understood but it would take more time to come to it.

93
5 CONCLUSION
This book is a critical overview of the existing theories of speech rhythm, both traditional and more modern ones. It compares different ap-proaches and methodologies and classifies them into three groups, on the basis of their attitude towards speech rhythm and types of research they did: 1) typological approach, which is based on the notion of isochrony and classifies languages into two (sometimes three) different categories, 2) phonological approach, which seeks to find phonological features re-sponsible for the perception of isochrony, 3) perceptual approach, which either questions the existence of speech rhythm altogether due to exten-sive instrumental research or seeks to find correlates of the perceived rhythm in speech signal in order to explain how infants extract rhythm from the speech signal and use it to discriminate languages. Moreover, it ponders over the application of studying speech rhythm both in teaching a foreign language and creating a reliable programme for speech synthe-sis and recognition.
Being one of the most controversial issues in language theory, the is-sue of speech rhythm has caused a lot of problems and controversies for many linguists who have dealt with this problem so far. To make things even more difficult, some contrastive study needed to be done in order to see whether languages such as English and Serbian differ and to which extent in terms of this language feature. However, one of the major prob-lems appeared at the very beginning of this research: the disproportion between the literature about English and that about Serbian related to the topic of speech rhythm. Comparing the abundance of papers and books related to this topic in English and the scarcity of such studies done on Serbian data, we immediately start wondering whether this feature plays the same role in the two languages. The true reason for this disproportion of studies is still unknown, but it can be speculated that Serbian linguists do not regard the rhythm of speech as a relevant language feature. Inter-estingly enough, most linguists who dealt with this issue are not native speakers of Serbian (Ilse Lehiste, G.L. Trager, R.G.A. de Bray, etc). Due to this disproportion, the current study needs to observe all the phenom-ena concerning speech rhythm through the rhythmic studies of English

94
and to try to apply the proposed rules to the rhythm of Serbian in order to see whether these languages differ and to which extent.
Many problems in forming the theory of speech rhythm come from different approaches to this particular issue. First of all, research meth-odologies vary significantly across different studies, which contributes to them having different outcomes. Also, the point of view seems to be a problem since linguists cannot agree whether to define it from the point of view of the speaker or the hearer. Furthermore, the lack of empirical evidence to support the earlier approaches is their serious drawback and thus these early theories are susceptible to criticism. However, recent approaches to speech rhythm, although very critical towards the exist-ing theory, have not yet offered a valid, fully-fledged, empirically-based rhythm theory, although the experimental means have helped clarifying many problematic issues of the early theories.
The aim of this study is to give an overview of the existing approach-es to the issue of speech rhythm, to point the differences between them, but without trying to decide which of these seems to be the most appro-priate one. Moreover, it stresses the importance of doing similar studies on the topic in question for the Serbian language. It also offers some guidelines for future studies of Serbian rhythmic organization, as well as some guidelines for teachers on how to integrate the topic of speech rhythm into their teaching practice. Finally, this book can help those who want to study speech rhythm to find all relevant pieces of information in one place, which is a small but not insignificant contribution to the study of speech rhythm.

95
REFERENCES
1. Abercrombie, D. (1965). A phonetician’s view of verse structure. Ox-ford: OUP.
2. Abercrombie, D. (1967). Elements of General Phonetics. Edinburgh University Press.
3. Arai, T, Greenberg, S. (1997). “The temporal properties of spoken Japanese are similar to those of English”. Proceedings of the 5th European Conference on Speech Communication and Technology (Eurospeech-97): 1011-1014. http://www.splab.ee.sophia.ac.jp/pa-pers/1998/1998_13.pdf
4. Bjelica, M. (2010). Characteristics of Speech Rhythm in English and Serbian. Unpublished Master’s Thesis. Novi Sad: Faculty of Phi-losophy.
5. Boersma, P, Weenink, D. (1992-2001). “Praat: A system for doing phonetics by computer”. Available from: http://www.praat.org/
6. Bolinger, D. (1981). Two Kinds of Vowels, Two Kinds of Rhythm. Indiana University Linguistics Club.
7. Brown, W, Alt, T. (2004). A Handbook of Bosnian, Serbian, and Cro-atian. SEELRC. http://seelrc.org:8080/grammar/pdf/stand_alone_bcs.pdf
8. Chela Flores, B. (1997). “Rhythmic Patterns as Basic Units in Pro-nunciation Teaching”. Chile: ONOMAZEIN 2: 111-134: http://on-omazein.net/2/patterns.pdf
9. Cruttenden, A. (1986). Intonation. Cambridge: CUP.10. Crystal, D. (1995). The Cambridge Encyclopedia of the English Lan-
guage. Cambridge: CUP.11. Crystal, D. (1996). ”The past, present and future of English rhythm”.
Speak Out, Newsletter of the IATEFL Pronunciation Special Inter-est Group, 18: 8-13: http://www.davidcrystal.com/DC_articles/Eng-lish46.pdf
12. Crystal, D. (2008). A Dictionary of Linguistics and Phonetics 6th edi-tion. Oxford: Blackwell Publishing.
13. Cummins, F, Gers, F, Schmidhuber, J. (1999). “Comparing Prosody Across Many Languages”. I.D.S.I.A. Technical Report IDSIA-07:

96
ftp://ftp.idsia.ch/pub/techrep/IDSIA-07-99.ps.gz14. Cummins, F, Port, R. F. (1998). “Rhythmic constraints on stress tim-
ing in English”. Journal of Phonetics, 26(2): 145–171. http://www.asel.udel.edu/icslp/cdrom/vol4/437/a437.pdf
15. Cummins, F. (2002). “Speech rhythm and rhythmic taxonomy”. Pro-ceedings of speech prosody, Aix-en-Provence: 121-136.
16. Dankovičová, J, Dellwo, V. (2007). “Czech Speech Rhythm and the Rhythm Class Hypothesis”. Proceedings of the 16th ICPhS, Saar-bruecken: 1241-1244: http://www.icphs2007.de/conference/Pa-pers/1538/1538.pdf
17. Dauer, R. M. (1983). “Stress-timing and syllable-timing reanalysed”. Journal of Phonetics, vol.11: 51-62.
18. Dauer, R. M. (1987). “Phonetic and phonological components of language rhythm”. Proceedings of the XIth ICPhS, Tallinn, Estonia, vol. 5: 447-450.
19. Dauer, R. M. (1993). Accurate English: A Complete Course in Pro-nunciation. Englewood Cliffs, NJ: Prentice Hall Regents.
20. De Bray, R. G. A. (1960). “The Pitch of Serbo-Croatian Word Ac-cent in Statements and Questions”. The Slavonic and East European Review, vol. 38 (91). The Modern Humanities Research Association and University College London, School of Slavonic and Eastern Eu-ropean Studies: 380-393: http://www.jstor.org/pss/4205174
21. Dellwo, V, Koreman, J. (2008). “How speaker idiosyncratic is meas-urable speech rhythm?” Proceedings, IAFPA 2008, Swiss Federal In-stitute of Technology Lausanne (EPFL): http://www.hf.ntnu.no/isk/koreman/Publications/2008/IAFPA2008abstract_DellwoKoreman.pdf
22. Dellwo, V, Steiner, I, Aschenberner, B, Dankovičová, J, Wagner, P. (2004). “The BonnTempo-Corpus and BonnTempo-Tools: A data-base for the combined study of speech rhythm and rate”. Proceed-ings of the 8th ICSLP, Jeju Island, Korea: http://www.phonetiklabor.de/Phonetiklabor/Inhalt/Ver%F6ffentlichungen/PDFs/BonnTempo.pdf
23. Dellwo,V, Wagner, P. (2003). “Relations between language rhythm and speech rate”. Proceedings of the International Congress of Pho-netics Science, Barcelona: 471-474: http://www.phonetiklabor.de/

97
Phonetiklabor/Inhalt/Ver%F6ffentlichungen/PDFs/Rhythm&Rate.pdf
24. Fenk-Oczlon, G, Fenk, A. (2006). “Speech Rhythm and Speech Rate in Crosslinguistic Comparison”. In: Sun, R, Miyake, N. (eds.). Proceedings of the 28th Annual Conference of the Cognitive Science Society. Mahwah, NJ: Erlbaum: 2480: http://wwwu.uni-klu.ac.at/gfenk/Speech%20Rhythmfinal.pdf
25. Fox, A. (2002). Prosodic Feature and Prosodic Structure: the Pho-nology of Suprasegmentals. Oxford: OUP.
26. Gilbert, J. (2005). Clear Speech: Pronunciation and Listening Com-prehension in North American English. Cambridge: CUP.
27. Gilbert, J. (2008). Teaching Pronunciation: Using the Prosody Pyra-mid. Cambridge: CUP
28. Gimson, A.C. (1978). An Introduction to the pronunciation of Eng-lish. 2nd ed. London: Arnold.
29. Gore, M. (2004). “A Review of Perceptual Approaches to Lan-guage Rhythm”. http://ir.kagoshima-u.ac.jp/bitstream/10232/864/1/KJ00004193565.pdf
30. Grabe, E, Low, E. L. (2002). “Durational variability in speech and the rhythm class hypothesis”. Papers in laboratory phonology (7): 515-546: http://wwwhomes.uni-bielefeld.de/gibbon/AK-Phon/Rhythmus/Grabe/Grabe_Low-reformatted.pdf
31. Hamdi, R, Barkat-Defradas, M, Ferragne, E, Pellegrino, F. (2004). “Speech Timing and Rhythmic Structure in Arabic dialects: a compar-ison of two approaches”. INTERSPEECH-2004: 1613-1616: http://www.isca-speech.org/archive/archive_papers/interspeech_2004/i04_1613.pdf
32. Harris, J. (1994). English Sound Structure. Oxford: OUP.33. Inkelas, S, Zec, D. (1988). “Serbo-Croatian pitch accent: the interac-
tion of tone, stress, and intonation”. Language, vol. 64 (2). Linguistic Society of America: 227-248: www.jstor.org/stable/415433
34. Jokanović-Mihajlov, J. (1990). „O modelima ritmičke organizacije iskaza“. Naučni sastanak slavista u Vukove dane: 105-113.
35. Jokanović-Mihajlov, J. (2007). Akcenat i intonacija govora na radiju i televiziji. Beograd: Društvo za srpski jezik i književnost Srbije.
36. Jones, D. (1978). An Outline of English Phonetics. Cambridge: CUP.

98
37. Jovičić, S. T. (1999). Govorna komunikacija: fiziologija, psihoakus-tika i percepcija. Beograd: Izdavačko preduzeće „Nauka“.
38. Lehiste, I, Ivić, P. (1986). Word and Sentence Prosody in Serbocroa-tian. Cambridge, MA: MIT Press.
39. Levelt, C, Van de Vijver, R. (1998). “Syllable types in cross-linguis-tic and developmental grammars”. The Third Biannual Utrecht Pho-nology Workshop, Utrecht.
40. McArthur, T. (ed.). (1992). The Oxford Companion to the English Language. Oxford: OUP.
41. Nava, E, Zubizarreta, M. L. (2008).“Prosodic Transfer in L2 Speech: Evidence from Phrasal Prominence and Rhythm”. Speech Prosody 2008. Campinas, Brazil: 335-338: http://www.isca-speech.org/ar-chive/sp2008/papers/sp08_335.pdf
42. O’Connor, J. D. (1991). Phonetics. London: Penguin Books.43. Ordin, M.Yu, Setter, J.E. (2008a). “Objective Indicators of Rhyth-
mic Russian-English Transfer”. XX Session of the Russian Acousti-cal Society, Moscow: 649-652: http://www.akin.ru/Docs/Rao/Ses20/AR15.PDF
44. Ordin, M.Yu, Setter, J.E. (2008b). “Comparative Research of Tem-poral Organization of the Syllable Structure in Hong Kong English, Russian English, and British English”. XX Session of the Russian Acoustical Society, Moscow: 653-656: http://www.akin.ru/Docs/Rao/Ses20/AR16.PDF
45. Pamies Bertrán, A. (1999). “Prosodic Typology: On the Dichotomy between Stress-Timed and Syllable-Timed Languages”. Language Design, vol.2: 103-130: http://elies.rediris.es/Language_Design/LD2/pamies.pdf
46. Patel, A. (2008). Music, Language, and the Brain. Oxford: OUP.47. Pierrehumbert, J. (1980). The phonology and phonetics of English
intonation. PhD thesis. MIT: Indiana University Linguistics Club: http://faculty.wcas.northwestern.edu/~jbp/publications/Pierrehum-bert_PhD.pdf
48. Pike, K. L. (1945). Intonation of American English. Ann Arbor: Uni-versity of Michigan Press.
49. Ramus, F, Dupoux, E, Mehler, J. (2003). “The psychological real-ity of rhythm classes: Perceptual studies”. Proceedings of the 15th

99
International Congress of Phonetic Sciences, Barcelona: 337-342: http://www.ehess.fr/lscp/persons/ramus/docs/ICPhS03.pdf
50. Ramus, F, Dupoux, E, Zangl, R, Mehler, J. (2000). “An empirical study of the perception of language rhythm”. EHESS/CNRS: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.35.9167&rep=rep1&type=pdf.
51. Ramus, F, Nespor, M, Mehler, J. (1999). “Correlates of linguistic rhythm in the speech signal”. Cognition, vol.73(3): 265-292.
52. Ramus, F. (2002). “Acoustic correlates of linguistic rhythm: Per-spectives”. Proceedings of Speech Prosody 2002, Aix-en-Provence: 115-120: http://www.ehess.fr/lscp/persons/ramus/docs/ramus_sp02.pdf
53. Roach, P. (1982). “On the distinction between ‘stress-timed’ and ‘syllable-timed’ languages”. In: D. Crystal (ed.). Linguistic contro-versies, Essays in linguistic theory and practice. London: Edward Arnold: 73-79.
54. Roach, P. (1998). “Some Languages are Spoken More Quickly than Others”. In: Bauer, L, Trudgill, P (eds.). Language Myths. Penguin: 150-158: http://www.personal.rdg.ac.uk/~llsroach/phon2/tempopr.htm
55. Roach, P. (2002). A Little Encyclopedia of Phonetics h t t p : / / w w w. 1 i n s a a t . c o m / u p l o a d s / Tr b B l o g s / p d f s _ 4 / 40625_1232781196_70.pdf
56. Sabater, M-J. S. (1991). “Stress and Rhythm in English”. Revista Alicantina de Estudios Ingleses 4: 145-62: http://rua.ua.es/dspace/bitstream/10045/5496/1/RAEI_04_13.pdf
57. Schiering, R. (2006). “Towards a Typology of Linguistic Rhythm”. 14th Manchester Phonology Meeting, University of Manchester: http://www.rene.punksinscience.org/Schiering_Rhythm_14mfm.pdf
58. Sečujski, M. (2002). „Akcenatski rečnik srpskog jezika namenjen sintezi govora na osnovu teksta“. DOGS: 17-20: http://alfanum.ftn.ns.ac.yu/radovi/TTS.3.pdf
59. Setter, J. (2008). “L2 Prosody Research: Rhythm and Intonation”. Talking English Phonetics: Proceedings of the 1st Belgrade Inter-national Meeting of English Phoneticians (BIMEP 2008), Belgrade: 93-104.

100
60. Stanojčić, Ž, Popović, Lj. (1999). Gramatika srpskog jezika. Beo-grad: Zavod za udžbenike i nastavna sredstva.
61. Steiner, I. (2003). “On the Analysis of Rhythm through Acoustic Parameters (Zur Rhythmusanalyse mittels akustischer Parameter)”. MA thesis. Institute for Communications Research & Phonetics, University of Bonn: http://www.coli.uni-saarland.de/~steiner/pdf/MA-Abstract.pdf
62. Steiner, I. (2004). “Tutorial 5: Analyzing Speech Rhythm”. 5th Euro-pean Masters in Language and Speech Summer School, Institute for Communications Research & Phonetics, University of Bonn: http://www.cstr.ed.ac.uk/emasters/previous_summer_schools/2004_bonn/steiner.pdf
63. Tajima, K, Zawaydeh, B. A, Kitahara, M. (1999). “A Comparative Study of Speech Rhythm in Arabic, English, and Japanese”: http://www.cs.indiana.edu/hyplan/mkitahar/Papers/0
64. Tajima, K. (1998). “Speech Rhythm in English and Japanese: Exper-iments in Speech Cycling”. PhD thesis. Indiana University, Bloom-ington, IN: http://ftp.cs.indiana.edu/hyplan/ktajima/thesis-1s
65. Tatham, M, Morton K. (2001). “Intrinsic and Adjusted Unit Length in English Rhythm Synthesis”. Proceedings of the Institute of Acous-tics – WISP 2001. St. Albans: Institute of Acoustics: 189-200: http://www.morton-tatham.co.uk/publications/from1995/Tatham_Mor-ton_2001.pdf
66. Trager, G. L. (1940). “Serbo-croatian Accents and Quantities”. Lan-guage, vol. 16 (1). Linguistic Society of America: 29–32: www.jstor.org/stable/409091
67. Vidović, V. (1967). Engleski glasovi, naglasak, ritam i intonacija. Beograd: Zavod za izdavanje udžbenika.
68. Wagner, P. S, Dellwo, V. (2004). “Introducing YARD (Yet Another Rhythm Determination) and Re-Introducing Isochrony to Rhythm Research”. Proceedings of Speech Prosody, Nara: http://aune.lpl.univ-aix.fr/~sprosig/sp2004/PDF/Wagner-Dellwo.pdf
69. Zec, D, Zsiga, E. (2009). “Interactions of tone and stress in Stand-ard Serbian: phonological and phonetic evidence”. FASL 18. Cor-nell University, New York: http://conf.ling.cornell.edu/FASL18/Ab-stracts/Zec-Zsiga.pdf

CIP - Kаталогизација у публикацијиБиблиотека Матице српске, Нови Сад
811.111'342.9811.163.41'342.9
BJELICA, Maja
Speech rhythm in English and Serbian : a critical studyof traditional and modern approaches / Maja Bjelica. - NoviSad : Filozofski fakultet, Odsek za anglistiku, 2012 (Novi Sad : Feljton). - 1 elektronski optički disk (CD-ROM) ; 12 cm
Tiraž 150, - Napomene i bibliografske reference uz tekst. - Bibliografija.
ISBN 978-86-6065-111-4
a) Eнглески језик - Говор - Ритам b) Српски језик -Говор - РитамCOBISS.SR-ID 272612871
Filozofski fakultet u Novom SaduOdsek za anglistikuDr Zorana Đinđića 2
21 000 Novi sadTel: +381214853900 +381214853852
www.ff.uns.ac.rs
Štampa i prelom:Štamparija FELJTON, Novi Sad
Stražilovska 17, Tel: 021/6622-867, 424-527
Tiraž:150

A Critical Study of Traditional and Modern Approaches
SPEECH RHYTHM IN
ENGLISH AND SERBIAN:
Maja Bjelica
ISBN 978-86-6065-112-1
Novi Sad
2012.9 788660 651114
ISBN 866065111-1