speech recognition
DESCRIPTION
dspTRANSCRIPT

B.Tech Project Interim Report I
CHAPTER 1
INTRODUCTION
The current practice of taking attendance in a lecture class is simply calling
the roll numbers by each student and marking it by the teacher. This is a time
consuming process and the accuracy of this process is low. It's found that the
students those who are not present in the classroom, get attendance by doing some
malpractices. There is a great chance for doing malpractices by the student. And
it's complex to enter and calculate student's overall attendance, and sometimes
may have chance not to get attendance even though he/she is present in the class.
It seems to be very difficult to avoid these limitations, even if effectively the
process had followed.
In determining the internals of every student’s, the attendance has a 10%
role. The malpractices in taking attendance, thus will affect the internals of the
students. The idea about this project had developed in our mind, while thinking
about a scientific way to register the attendance. Thus the defects in the ordinary
attendance taking practice can be reduced by a large extent. The various biometric
characteristics that are generally used are the face, iris, fingerprints palm prints
hand geometry and the behavioral characteristics include signature voice pattern.
Biometrics is the science or technology which analyses and measures the
biological data. In computer science it refers to science or technology that
measure and analyzes physical or behavioral characteristics of a person, for
authentication.
Voice recognition or speaker recognition systems extract features from the
speech using MATLAB and model them to use for recognition these systems use
the acoustic features present in the speech which are unique for each individual.
These acoustic pattern depend on the physical characteristics of individual (e.g.:
the size of mouth and throat) as well as behavioral characteristics like speaking
styles and voice pitch. Everyone has a distinct voice, different from all others;
almost like a fingerprint, one’s voice is unique and can act as an identifier. The
Department of ECE 1 Thejus Engineering College

B.Tech Project Interim Report I
human voice is composed of a multitude of different components, making each
voice different; namely Pitch and Tone.
Speech is one of the natural forms of communication recent developments
have made it possible to use this in the security system. In speaker identification
task use a speech sample to select the identity of person that produce the speech
from a population of speakers. In speaker verification the task is to use a speech
sample to test whether a person who claims to have produced the speech has in
fact done so. This technique makes it possible to use the speaker voice to verify
their identity and control access to services such as voice dialing banking by
telephone ,attendance marking ,telephone shopping ,data base access
services ,information services ,voice mail ,security control for confidential
information areas and remote access to computers.
Speaker recognition methods can be divided into text independent and text
dependent methods. In a text independent system, speaker models capture
characteristics of somebody’s speech which show up irrespective what one is
saying. In a text dependent system, on the other hand, the recognition of the
speaker’s identity is based on his or her speaking one or more specific phases, like
password, card numbers, PIN codes. Every technology of speaker
recognition ,identification and verification whether text independent and text
dependent ,each has its own advantages and disadvantages and may require
different treatment and techniques the choice of which technology to use is
application specific. At the highest level all the speaker recognition system
contain two main modules feature extraction and feature matching.
Overview of the project
VoDAR (Voice Detected Attendance Register), is a system that register
the attendance of each student, at high accuracy. Matlab is the tool for our project.
The main aim of this project is speaker identification, which consists of
comparing a speech signal from an unknown speaker to a database of known
speaker. The system can recognize the speaker, which has been trained with a
number of speakers. Feature extraction and feature matching are the main process
in this project. Feature extraction done using MFCC.
Department of ECE 2 Thejus Engineering College

B.Tech Project Interim Report I
The main purpose of the MFCC processor is to mimic the behavior of the
human ears. In addition MFCCs are shown to be less susceptible to mentioned
variations. Speaker identification is done by vector quantization, which consists of
comparing a speech signal from an unknown speaker database to a database of
known speakers.
A sequence of feature vectors {x1,…, xT}, is compared with the codebooks
in the database. For each codebook a distortion measure is computed, and the
speaker with the lowest distortion is chosen. VQ based clustering approach is best
as it provides us with the faster speaker identification process.
Report organization
In chapter two a literature review is conducted. This chapter presents the
detailed data collections necessary for our project. Information from international
journals are included here. This chapter gives insight to our project by clarifying
various steps of voice recognition such as feature extraction and feature matching.
In chapter three a comparative study with the existing system has been
done. Here comparative study with other biometric attendance systems are made
which include face recognition attendance system, Finger print attendance system,
Iris recognition attendance system, Palm print recognition attendance system,
Hand geometry recognition attendance system, signature recognition attendance
system etc. This chapter also deals with the advantages of VoDAR..
Detailed description of working of VODAR has been done in chapter four.
Human voice generation and types of speech recognition are also main contents of
this chapter. The feature extraction by MFCC (Mel filter Cepstral Coefficient) [3]
and speaker identification by vector quantization [4] are also included here.
Finally the reason for choosing Matlab is also included here. In chapter five we
concluded that, from various biometric systems, voice recognition is best suited
for our application. In the end the list of references are included. In appendix,
codes for recording speech signal and pre-emphasis of speech signal that were
implemented in this project are provided.
Department of ECE 3 Thejus Engineering College

B.Tech Project Interim Report I
CHAPTER 2
OVERVIEW OF VOICE RECOGNITION
Speech is one of the most dominating and natural means of
communication for expressing our ideas, emotions. Voice recognition involves the
process of extracting usable information from speech signal and using which the
person identification is performed.
Speaker recognition is the computing task of validating a user's claimed
identity using characteristics extracted from their voices. Voice recognition uses
learned aspects of a speaker’s voice to determine who is talking. Such a system
cannot recognize speech from random speakers very accurately, but it can reach
high accuracy for individual voices it has been trained with, which gives us
various applications in day today life. This study introduced various methods of
speaker identification involving LPC, MFCC [3] feature extraction. Linear
prediction is a mathematical operation which provides an estimation of the current
sample of a discrete signal as a linear combination of several previous samples.
The prediction error which is the difference between the predicted and actual
value is called the residual. Using this idea feature extraction is implemented in
LPC feature extraction method, where as in MFCC the log of signal energy is
calculated.
Mrs. Arundhathi proposes design of an automatic speaker recognition
system [4] utilizing the concept of MFCC. MFCC [4] are derived from a type of
cepstral representation of the audio clip. The difference between the cepstrum and
the Mel Frequency Cepstrum (MFC) [4] is that the frequency bands are equally
spaced on the Mel scale, which approximates the human auditory system's
response more closely than the linearly-spaced frequency bands used in the
normal cepstrum. The cepstrum is a common transform used to gain information
from a person’s speech signal. It can be used to separate the excitation signal
(which contains the words and the pitch) and the transfer function (which contains
the voice quality). It is the result of taking Fourier transform of decibel spectrum
as if it were a signal. We use cepstral analysis in speaker identification because
the speech signal is of the particular form above, and the "cepstral transform" of it
Department of ECE 4 Thejus Engineering College

B.Tech Project Interim Report I
makes analysis incredibly simple. Mathematically, cepstrum of signal =
FT[log{FT(the windowed signal)}] MFCC[4] are commonly calculated by first
taking the Fourier transform of a windowed excerpt of a signal and mapping the
powers of the spectrum obtained above onto the Mel scale, using triangular
overlapping windows. Next the logs of the powers at each of the Mel frequencies
are taken; Discrete Cosine Transform is applied to it (as if it were a signal). The
MFCC’s are the amplitudes of the resulting spectrum. The speech input is
typically recorded at a sampling rate above 10000 Hz. This sampling frequency
was chosen to minimize the effects of aliasing in the analog-to-digital conversion.
These sampled signals can capture all frequencies up to 5 kHz, which cover most
energy of sounds that are generated by humans. The main purpose of the MFCC
[5] processor is to mimic the behavior of the human ears. In addition MFCCs [5]
are shown to be less susceptible to mentioned variations. The feature extraction
using MFCC [5] is utilized for speaker identification.
Mr. Manoj kaur describes the vector quantization based speaker
identification [6] such that, a speaker recognition system must be able to estimate
probability distributions of the computed feature vectors. Storing every single
vector that generate from the training mode is impossible, since these distributions
are defined over a high-dimensional space. It is often easier to start by quantizing
each feature vector to one of a relatively small number of template vectors, with a
process called vector quantization. VQ [6] is a process of taking a large set of
feature vectors and producing a smaller set of measure vectors that represents the
centroids of the distribution. By using these training data features are clustered to
form a codebook for each speaker. In the recognition stage, the data from the
tested speaker is compared to the codebook of each speaker and measure the
difference. These differences are then use to make the recognition decision.
Survey of biometric recognition systems and their applications (journal of
theoretical and applied information technology) [7] is a journal which describes
about various biometric systems available and their peculiarities. The human
physical characteristics like fingerprints, face, voice and iris are known as
biometrics. This study helped us to understand various biometric systems
available. There by choosing voice recognition system as best suited for our
Department of ECE 5 Thejus Engineering College

B.Tech Project Interim Report I
application that is, as an attendance register. Facial recognition have
disadvantages like complex system, time consuming compared to voice. As well
recognition is affected by changes in lighting, the age and if the person wears
glasses. It requires camera equipment for user identification which is costly. Iris
recognition has disadvantages such as large storage requirement and expensive.
Finger tip recognition can make mistakes due to the dryness or dirt in the finger’s
skin, as well as with the age . It demands a large memory and Compression is
required (a factor of 10 approximately). Hence out of all most suitable for our
application is voice which is cheap and speaker verification time is only 5
seconds.
MFCC and its applications in speaker recognition [8] describes that
Speech processing is emerged as one of the important application area of digital
signal processing. Various fields for research in speech processing are speech
recognition, speaker recognition, speech synthesis, speech coding etc. The
objective of automatic speaker recognition is to extract, characterize and
recognize the information about speaker identity. Feature extraction is the first
step for speaker recognition. Many algorithms are developed by the researchers
for feature extraction. In this work, the Mel Frequency Cepstrum Coefficient
(MFCC) feature has been used for designing a text dependent speaker
identification system. Some modifications to the existing technique of MFCC for
feature extraction are also suggested to improve the speaker recognition
efficiency. Another important point emerged from this paper is that, as no. of filter
in filter bank increases the efficiency also increases. Also these reveled that
compared to rectangular window hanning window has more efficiency.
Vector quantization using speaker identification [9] describes about the
methodology followed in this paper for speaker identification, which consists of
comparing a speech signal from an unknown speaker to a database of known
speakers. The methodology followed in this paper for Speaker identification is
using Feature Extraction process and then Vector Quantization of extracted
features is done using k-means algorithm. The K-means algorithm is widely used
in speech processing as a dynamic clustering approach. “K” is pre-selected and
simply refers to the number of desired clusters. In the recognition phase an
unknown speaker, represented by a sequence of feature vectors {x1,…, xT}, is
Department of ECE 6 Thejus Engineering College

B.Tech Project Interim Report I
compared with the codebooks in the database. For each codebook a distortion
measure is computed, and the speaker with the lowest distortion is chosen. VQ
based clustering approach is best as it provides us with the faster speaker
identification process.
Department of ECE 7 Thejus Engineering College

B.Tech Project Interim Report I
CHAPTER 3
CURRENT SCENARIO
3.1 DRAWBACKS OF EXISTING SYSTEMS
The study of existing systems such as face recognition system, finger print
recognition system, iris recognition system, palm recognition system, hand
recognition system, hand geometry, signature recognition ,voice recognition
system were analyzed for our particular application of attendance marking.
3.1.1 Face recognition attendance system:
Humans have a remarkable ability to recognize fellow beings based on
facial appearance. So, face is a natural human trait for automated biometric
recognition. Face recognition systems typically utilize the spatial relationship
among the locations of facial features such as eyes, nose, lips, chin, and the global
appearance of a face. The forensic and civilian applications of face recognition
technologies pose a number of technical challenges for static photograph matching
(e.g., for ensuring that the same person is not requesting multiple passports). The
problems associated with illumination, gesture, facial makeup, occlusion, and
pose variations adversely affect the face recognition performance. While face
recognition is non-intrusive, robust face recognition in non-ideal situations
continues to pose challenges.
3.1.2 Fingerprint recognition attendance system:
Fingerprint-based recognition has been the longest serving, and popular
method for person identification. Fingerprints consist of a regular texture pattern
composed of ridges and valleys. These ridges are characterized by several
landmark points, known as minutiae, which are mostly in the form of ridge
endings and ridge bifurcations. The spatial distribution of these minutiae points is
claimed to be unique to each finger; it is the collection of minutiae points in a
fingerprint that is primarily employed for matching two fingerprints. In addition to
minutiae points, there are sweat pores and other details (referred to as extended)
Department of ECE 8 Thejus Engineering College

B.Tech Project Interim Report I
which can be acquired in high resolution fingerprint images. However, there are
some disadvantages in this system. If the surface of the finger gets damaged
and/or has one or more marks on it, identification becomes increasingly hard.
Furthermore, the system requires the user’s finger surface to have a point of
minutiae or pattern in order to have matching images. This will be a limitation
factor for the security of the algorithm
3.1.3 Iris recognition attendance system:
The iris is the colored annular ring that surrounds the pupil. Iris images
acquired under infrared illumination consist of complex texture pattern with
numerous individual attributes, e.g. stripes, pits, and furrows, which allow for
highly reliable personal identification. The iris is a protected internal organ whose
texture is stable and distinctive, even among identical twins (similar to
fingerprints), and extremely difficult to surgically spoof. However, relatively high
sensor cost, along with relatively large failure to enroll (FTE) rate reported in
some studies, and lack of legacy iris databases may limit its usage in some large-
scale government application.
3.1.4 Palm print recognition attendance system:
The image of a human palm consists of palm are friction ridges and
flexion creases (lines formed due to stress). Similar to fingerprints, latent palm
print systems utilize minutiae and creases for matching. Based on the success of
fingerprints in civilian applications, some attempts have been made to utilize low
resolution palm print images for access control applications .These systems utilize
texture features which are quite similar to those employed for iris recognition.
Palm print recognition systems have not yet been deployed for civilian
applications (e.g., access control), mainly due to their large physical size and the
fact that fingerprint identification based on compact and embedded sensors works
quite well for such applications.
Department of ECE 9 Thejus Engineering College

B.Tech Project Interim Report I
3.1.5 Hand Geometry recognition attendance system:
It is claimed that individuals can be discriminated based on the shape of
their hands. Person identification using hand geometry utilizes low resolution
hand images to extract a number of geometrical features such as finger length,
width, thickness, perimeter, and finger area. The discriminatory power of these
features is quite limited, and therefore hand geometry systems are employed only
for verification applications in low security access control and for attendance
marking application, geometry systems require large physical size, so they cannot
be easily embedded in existing security systems.
3.1.6 Signature recognition attendance system:
Signature is a behavioral biometric model that is used in daily business
transactions (e.g., credit card purchase). However, attempts to develop highly
accurate signature recognition systems have not been successful. This is primarily
due to the large variations in a person’s signature over time. Attempts have been
made to improve the signature recognition performance by capturing dynamic or
online signatures that require pressure-sensitive pen-pad. Dynamic signatures help
in acquiring the shape, speed, acceleration, pen pressure, order and speed of
strokes, during the actual act of signing. This additional information seems to
improve the verification performance (over static signatures) as well as
circumvent signature forgeries. Still, very few automatic signature verification
systems have been deployed, because of increased interference such as dirtiness,
injury, roughness.
Department of ECE 10 Thejus Engineering College

B.Tech Project Interim Report I
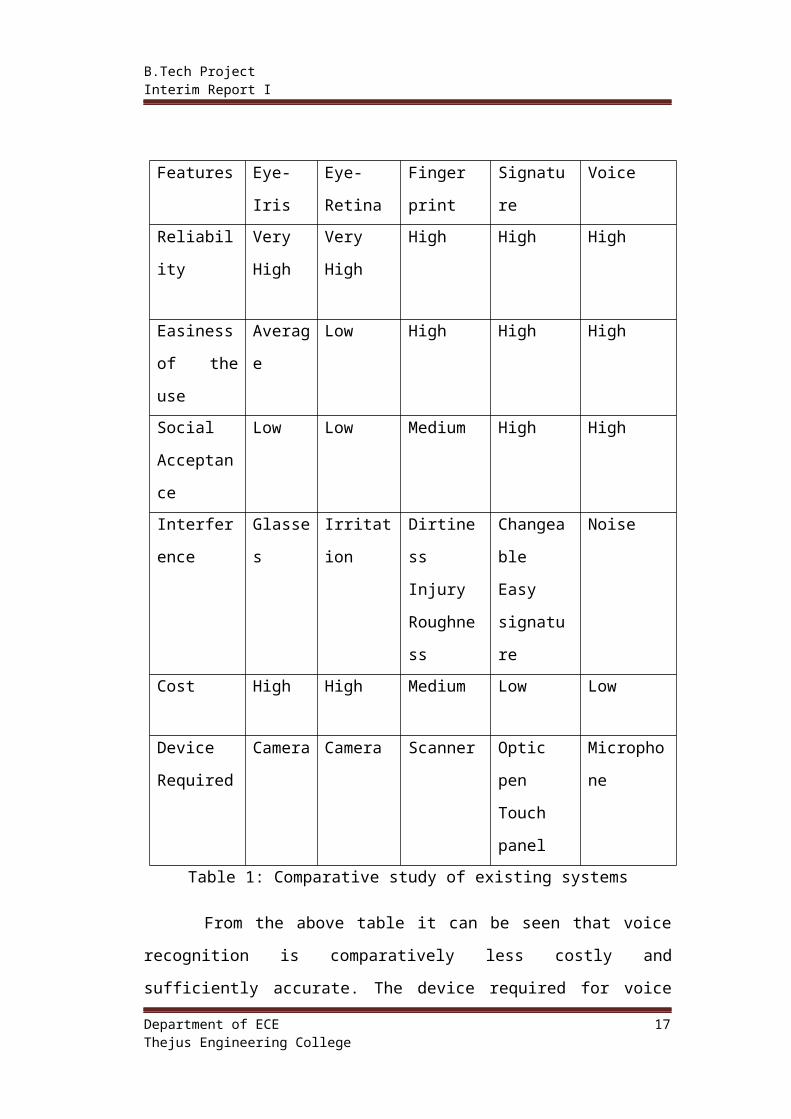
3.2 COMPARITVE STUDY OF EXISTING SYSTEMS
Features Eye-Iris Eye-
Retina
Finger
Signature Voice
Reliability Very
High
Very High High High High
Easiness of
the use
Average Low High High High
Social
Acceptance
Low Low Medium High High
Interference Glasses Irritation Dirtiness
Injury
Roughness
Changeable
Easy
signature
Noise
Cost High High Medium Low Low
Device
Required
Camera Camera Scanner Optic pen
Touch
panel
Microphone
Table 1: Comparative study of existing systems
From the above table it can be seen that voice recognition is
comparatively less costly and sufficiently accurate. The device required for voice
recognition is easily available and low cost compared to other systems. Hence it’s
preferred over other systems for attendance marking.
3.3 ADVANTAGES OF VoDAR OVER EXISTING SYSTEMS
The advantage of VoDAR is listed below. Mainly there are five
advantages. They are ability to use technology remotely, low cost of using it, high
reliability rate, ease of use and ease of implementation and minimally invasive.
Department of ECE 11 Thejus Engineering College

B.Tech Project Interim Report I
3.3.1 Ability to Use Technology remotely
One of the main advantages of voice verification technology is the ability
to use it remotely. Many other types of biometrics cannot be used remotely, such
as fingerprints, retina biometrics or iris biometrics one of the advantages of speech
recognition technology is that, it’s easy to use over the phone or other speaking
devices, increasing its usefulness to many companies. The ability to use it
remotely makes it stand out among many other types of biometric technology
available today.
3.3.2 Low Cost of Using It
The low cost of this technology is another advantage of voice recognition.
The price of acquiring a voice recognition system is usually quite reasonable,
especially when compared to the price of other biometric systems. These systems
are relatively low cost to implement and maintain and the equipment needed is
low priced as well. Very little equipment is needed for these systems, making it a
cost effective option for businesses. In many cases, all that is required for these
systems to function is the right biometric software if the technology is being used
remotely over the phone. The phone acts as the speaking device, so there is no
investment in this device. For systems being used for authentication and
verification on sites, businesses only have to worry about purchasing a device that
users can speak into along with the speech recognition software.
3.3.3 High Reliability Rate
Another advantage of voice recognition is this technology’s high reliability
rate. 10-20 years ago, the reliability rate of speech recognition technology was
actually quite low. There were many problems that produced reliability problems,
such as the inability to deal with background noise or the inability to recognize
voices when an individual had a slight cold. However, these problems have been
dealt with successfully today, giving this biometric technology a very high
reliability rate. Vocal prints now can easily be used to identify an individual, even
if their speech sounds a bit different due to a cold. One of the advantages of these
Department of ECE 12 Thejus Engineering College

B.Tech Project Interim Report I
types of systems is that they are designed to ignore background noise and focus on
the voice, which also has given the reliability rate a huge boost.
3.3.4 Ease of Use and Implementation
Many companies really appreciate the ease of use and implementation that
comes with voice recognition biometrics. Some biometric technologies can be
difficult to implement into a company and difficult to begin using. Since these
systems require minimal equipments, so they can usually be implemented without
the addition of new equipment and systems. Since they are so easy to use,
companies can often reduce their personnel and make use of them elsewhere in
the company to improve performance and customer satisfaction.
3.3.5 Minimally Invasive
One of the major advantages of this system is that it is minimally invasive,
which is one of the big advantages of voice recognition. This is very important to
individuals that use these security devices. Many consumers today do not like
many forms of biometric technology, since other forms seem so invasive. The
advantages of speech technology are that it only requires individuals to speak and
offer a vocal sample, which is minimally invasive. Since this technology has a
high approval rate among consumers, it can help businesses keep their customers
happy with the service they are providing.
Department of ECE 13 Thejus Engineering College

B.Tech Project Interim Report I
CHAPTER 4
SYSTEM DESIGN FOR VoDAR
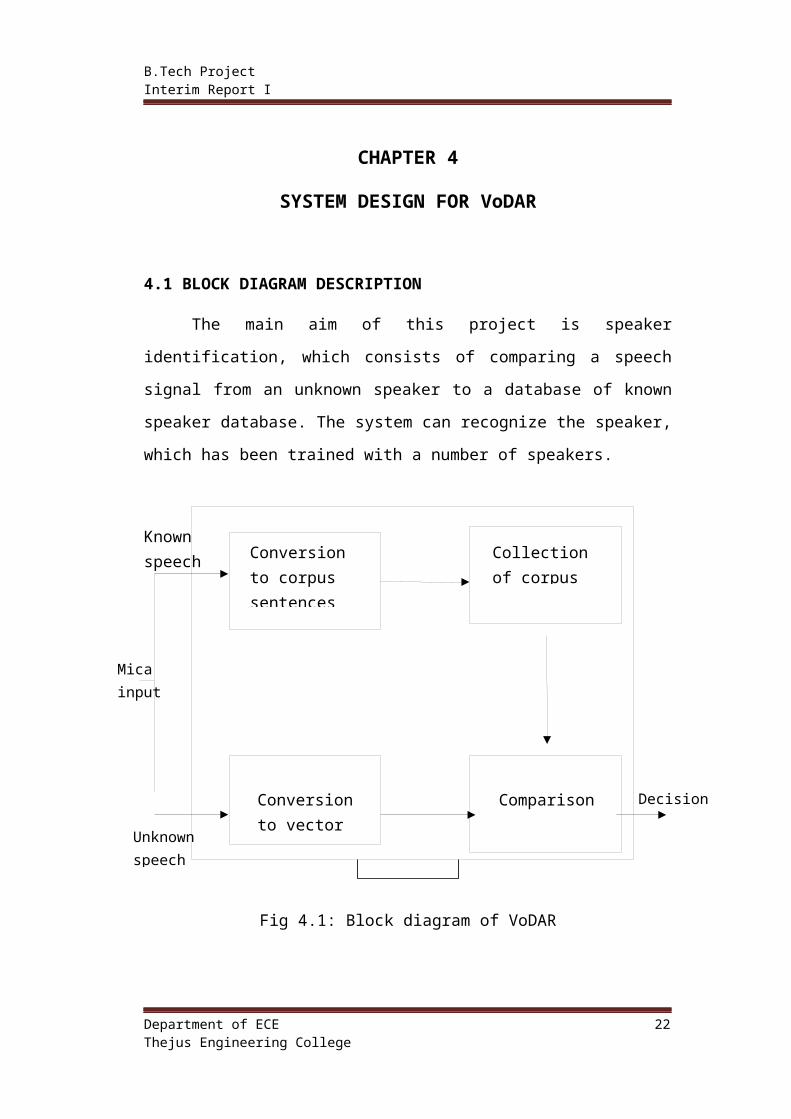
4.1 BLOCK DIAGRAM DESCRIPTION
The main aim of this project is speaker identification, which consists of
comparing a speech signal from an unknown speaker to a database of known
speaker database. The system can recognize the speaker, which has been trained
with a number of speakers.
Fig 4.1: Block diagram of VoDAR
Above figure shows the fundamental formation of speaker identification
and verification systems. Where the speaker identification is the process of
determining which registered speaker provides a given speech. On the other hand,
speaker verification is the process of rejecting or accepting the identity claim of a
speaker. In most of the applications, voice is used as the key to confirm the
identities of a speaker which is known as speaker verification .The system consists
Department of ECE 14 Thejus Engineering College
Conversion to vector form
Conversion to corpus sentences
Collection of corpus sentences
Comparison
Mica input
Known speech
Unknown speech
Decision

B.Tech Project Interim Report I
of a microphone connected to a computer system. The voice inputs of each student
are recorded via mice, and each input is analyzed by the system by the MATLAB
software. MATLAB is the software tool of our project. First we have to store
some reference voice signal wave form, with the help of a microphone and the
computer. These stored speech signals are called corpus sentences .By the help
of MATLAB software, these waveforms get analyzed and we convert each speech
signal into vector form. Now the input voice signals from the students are also
converted into the vector form. After comparing this vector sentence with the
corpus sentences, the most similar corpus sentence will be determined. Thus
speaker identification is carried out and corresponding attendance will be marked.
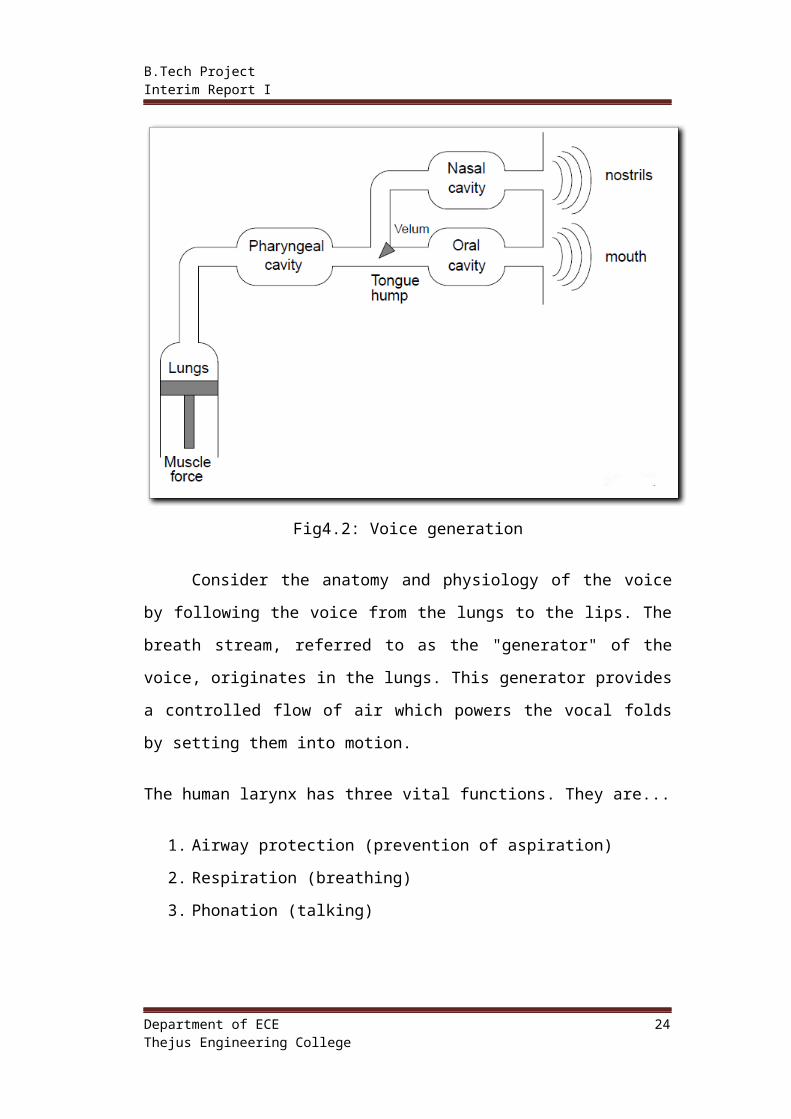
4.2 HUMAN VOICE GENERATION
Fig4.2: Voice generation
Consider the anatomy and physiology of the voice by following the voice
from the lungs to the lips. The breath stream, referred to as the "generator" of the
Department of ECE 15 Thejus Engineering College

B.Tech Project Interim Report I
voice, originates in the lungs. This generator provides a controlled flow of air
which powers the vocal folds by setting them into motion.
The human larynx has three vital functions. They are...
1. Airway protection (prevention of aspiration)
2. Respiration (breathing)
3. Phonation (talking)
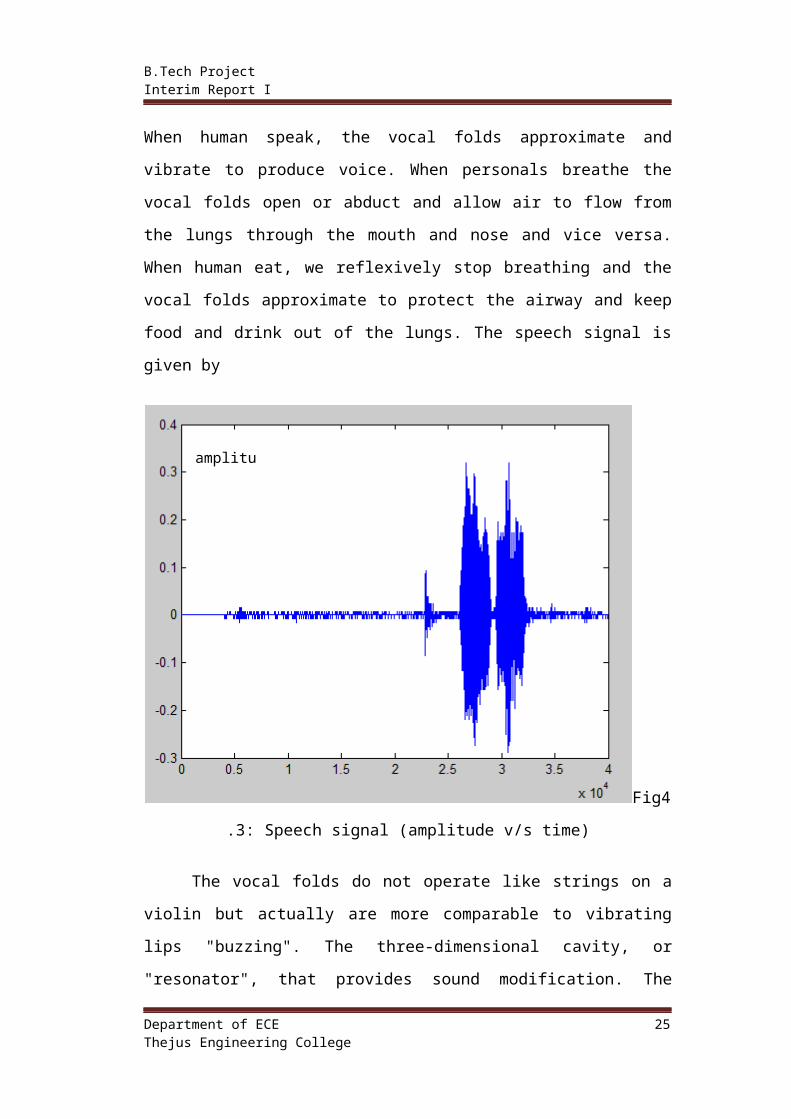
When human speak, the vocal folds approximate and vibrate to produce voice.
When personals breathe the vocal folds open or abduct and allow air to flow from
the lungs through the mouth and nose and vice versa. When human eat, we
reflexively stop breathing and the vocal folds approximate to protect the airway
and keep food and drink out of the lungs. The speech signal is given by
Fig4.3: Speech signal (amplitude v/s time)
The vocal folds do not operate like strings on a violin but actually are more
comparable to vibrating lips "buzzing". The three-dimensional cavity, or
Department of ECE 16 Thejus Engineering College
amplitude
B.Tech Project Interim Report I
"resonator", that provides sound modification. The articulators (the parts of
the vocal tract above the larynx consisting of tongue, palate, cheek, lips,
etc.) articulate and filter the sound emanating from the larynx and to some degree
can interact with the laryngeal airflow to strengthen it or weaken it as a sound
source. Adult men and women have different sizes of vocal fold; reflecting the
male-female differences in larynx size. Adult male voices are usually lower-
pitched and have larger folds. The male vocal folds (which would be measured
vertically in the opposite diagram), are between 17 mm and 25 mm in length.] The
female vocal folds are between 12.5 mm and 17.5 mm in length. The difference in
vocal folds size between men and women means that, they have differently
pitched voices. Additionally, genetics also causes variances amongst the same sex,
with men's and women's singing voices being categorized into types.
4.3 SPEECH RECOGNITION
The structure of a typical speech recognition system mainly consists of
feature extraction, training and recognition. Because of the instability of speech
signal, feature extraction of speech signal becomes very difficult. There exist
different features between each word. For each word there are differences among
different person, such as the differences between adults and children, male and
female. Even for the same person and the same word there also exists changes for
different time. Nowadays, there is several feature extraction methods used in
speech recognition systems. All of them have good performance when used in
clean condition. In the adverse condition, we still can’t find a good way in speech
recognition system.
Compared with them, human auditory system always has good
performance under clean and noisy condition. So a way solve this is to research
our auditory system and use the result in speech recognition system developed.
There are two major approaches available for feature extraction: modeling human
voice production and perception system. For the first approach, one of the most
popular features is the LPC (Linear Prediction Coefficient) feature. For the second
approach, the most popular feature is the MFCC (Mel-Frequency Cepstrum
Department of ECE 17 Thejus Engineering College

B.Tech Project Interim Report I
Coefficient) feature. In MFCC, the main advantage is that it uses Mel frequency
scaling which is very approximate to the human auditory system. Hence MFCC is
more effective than LPC.
Figure 4.4: Voice recognition algorithm classification
A. Definition of speech recognition:
Speech Recognition (is also known as Automatic Speech Recognition
(ASR), or computer speech recognition) is the process of converting a speech
signal to a sequence of words, by means of an algorithm implemented as a
computer program.
B. Types of Speech Recognition:
Speech recognition systems can be separated in several different classes by
describing what types of utterances. They have the ability to recognize. These
classes are classified as the following:
Isolated Words:
Isolated word recognizers usually require each utterance to have quiet (lack of an
audio signal) on both sides of the sample window. It accepts single words or
single utterance at a time. These systems have "Listen/Not-Listen" states, where
they require the speaker to wait between utterances (usually doing processing
during the pauses). Isolated Utterance might be a better name for this class.
Department of ECE 18 Thejus Engineering College
Voice recognition algorithm
Training phase
Each speaker has to provide samples of their voice so that reference template model can be build
Testing phase
To ensure input test voice is matched with stored reference template model and recognition decision made accordingly

B.Tech Project Interim Report I
Connected Words:
Connected word systems (or more correctly 'connected utterances') are similar to
isolated words, but allows separate utterances to be 'run-together' with a minimal
pause between them.
Continuous Speech:
Continuous speech recognizers allow users to speak almost naturally, while the
computer determines the content. (Basically, it's computer dictation). Recognizers
with continuous speech capabilities are some of the most difficult to create
because they utilize special methods to determine utterance boundaries.
Spontaneous Speech:
At a basic level, it can be thought of as speech that is natural sounding and not
rehearsed. An ASR system with spontaneous speech ability should be able to
handle a variety of natural speech features such as words being run together,
"ums" and "ahs", and even slight stutters.
4.4 FEATURE EXTRACTION
Fig 4.5: Block diagram feature extraction
Step 1: Pre–emphasis
This step processes the passing of signal through a filter which emphasizes
higher frequencies. This process will increase the energy of signal at higher
frequency.
Department of ECE 19 Thejus Engineering College

B.Tech Project Interim Report I
Y[n] = X[n]- a X[n-1].
a = 0.95, which make 95% of any one sample is presumed to originate from
previous sample.
Step 2: Framing
The process of segmenting the speech samples obtained from analog to
digital conversion (ADC) into a small frame with the length within the range of 20
to 40 msec. The voice signal is divided into frames of N samples. Adjacent
frames are being separated by M (M<N). Typical values used are M = 100 and N=
256.
Step 3: Windowing
A traditional method of spectral evaluation is reliable in case of stationary
signal. Nature of signal changes continuously with time. For voice reliability can
be ensured for a short time. Audio signal is continuous. Processing cannot wait for
last sample. Processing complexity increases exponentially. It is important to
retain short term features. Short time analysis is performed by windowing the
signal. Normally Hamming Window is used. The Hamming function is given by
Hamming window:
W(n) = 0.54 – 0.46 cos(2πn/L-1) 0 ≥ n≥ L-1
0 otherwise.
Step 4: Fast Fourier Transform
To convert each frame of N samples from time domain into frequency
domain. The Fourier Transform is to convert the convolution of the glottal pulse
U[n] and the vocal tract impulse response H[n] in the time domain. This statement
supports the equation below:
Y(W) = FFT [h(t)*X(t)] = H(W) *X(W)
If X (w), H (w) and Y (w) are the Fourier Transform of X (t), H (t) and Y (t)
respectively.
Department of ECE 20 Thejus Engineering College

B.Tech Project Interim Report I
Step 5: Mel Filter Bank Processing
The frequencies range in FFT spectrum is very wide and voice signal does
not follow the linear scale. The bank of filters according to Mel scale as shown in
figure 4 is then performed. This figure below shows a set of triangular filters that
are used to compute a weighted sum of filter spectral components so that the
output of process approximates to a Mel scale. Each filter’s magnitude frequency
response is triangular in shape and equal to unity at the centre frequency and
decrease linearly to zero at centre frequency of two adjacent filters.
Fig.4. 6: Mel filter bank
Step 6: Discrete Cosine Transform
This process converts the log Mel spectrum into time domain using
Discrete Cosine Transform (DCT). The result of the conversion is called Mel
Frequency Cepstrum Coefficient. The set of coefficient is called acoustic vectors.
Therefore, each input utterance is transformed into a sequence of acoustic vector.
Step 7: Delta Energy and Delta Spectrum
The voice signal and the frames changes, such as the slope of a formant at
its transitions. Therefore, there is a need to add features related to the change in
Department of ECE 21 Thejus Engineering College
B.Tech Project Interim Report I
cepstral features over time. 13 delta or velocity features (12 cepstral features plus
energy), and 39 features a double delta or acceleration feature are added. The
energy in a frame for a signal x in a window from time sample t1 to time sample
t2, is represented at the equation below:
Energy = ∑ X2 [t]
Procedure for forming MFCC
Fig.4.7: Flow chart for determination of MFCC
4.5 VECTOR QUANTIAZTION
Vector quantization (VQ) is a lossy data compression method based on
the principle of block coding. It is a fixed-to-fixed length algorithm. In the earlier
days, the design of a vector quantizer (VQ) is considered to be a challenging
problem due to the need for multi-dimensional integration. In 1980, Linde, Buzo,
and Gray (LBG) proposed a VQ design algorithm based on a training sequence.
The main advantage of VQ in pattern recognition is its low computational
burden when compared with other techniques such as dynamic time
warping (DTW) and hidden Markov model (HMM). A VQ is nothing more than
Department of ECE 22 Thejus Engineering College

B.Tech Project Interim Report I
an approximator. The idea is similar to that of ``rounding-off'' (say to the nearest
integer). An example of a 1-dimensional VQ is shown below:
Fig.4.8: One dimensional vector quantization
Here, every number less than -2 is approximated by -3. Every number
between -2 and 0 are approximated by -1. Every number between 0 and 2 are
approximated by +1. Every number greater than 2 are approximated by +3. Note
that the approximate values are uniquely represented by 2 bits. This is a 1-
dimensional, 2-bit VQ. It has a rate of 2 bits/dimension.
An example of a 2-dimensional VQ is shown below: Here, every pair of
numbers falling in a particular region are approximated by a star associated with
that region. Note that there are 16 regions and 16 stars -- each of which can be
uniquely represented by 4 bits. Thus, this is a 2-dimensional, 4-bit VQ. Its rate is
also 2 bits/dimension. In the above two examples, the stars are called code
vectors and the regions defined by the borders are called encoding regions. The set
of all code vectors is called the codebook and the set of all encoding regions is
called the partition of the space. The performances of VQ are typically given in
terms of the signal-to-distortion ratio (SDR):
SDR=10log10 σ2/Dave (in dB), Where σ is the variance of the source and
Dave is the average squared-error distortion. The higher the SDR the better the
performance
In verification systems two key performance measures are popular, the
false rejection rate (FRR), the number of times the true speaker is incorrectly
rejected, and false acceptance rate (FAR), the number of times an imposter
speaker is incorrectly accepted. By varying the decision threshold the FAR and
FRR will change in opposing directions. For example raising the threshold will
lower FAR but increase the FRR as true claims will start to be rejected since the
Department of ECE 23 Thejus Engineering College
B.Tech Project Interim Report I
bar is raised, conversely if the threshold is lowered the FRR is reduced but FAR
will increase since not only are all true claims now accepted but more false ones
will as well. The typical operating point for the selection of the threshold is when
FAR = FRR, termed the equal error rate (EER) condition.
Fig.4.9: Two dimensional vector quantization
4.6 SOFTWARE USING: MATLAB
MATLAB is a high-level language and interactive environment for
numerical computation, visualization, and programming. MATLAB can be used
for analyzing data, developing algorithms, and creating models and applications.
The language, tools, and built-in math functions enable you to explore multiple
approaches and reach a solution faster than with spreadsheets or traditional
programming languages, such as C/C++ or Java .MATLAB has a range of
applications, including signal processing and communications, image and video
processing, control systems, test and measurement, computational finance, and
computational biology. Hence we prefer MATLAB as our software tool. More
Department of ECE 24 Thejus Engineering College
B.Tech Project Interim Report I
than a million engineers and scientists in industry and academia use MATLAB,
the language of technical computing. MATLAB has built-in mathematical
functions in MATLAB to solve science and engineering problems.
MATLAB (matrix laboratory) is a numerical computing environment and fourth-
generation programming language. Developed by Math Works, MATLAB
allows matrix manipulations, plotting of functions and data, implementation
of algorithms, creation of user interfaces, and interfacing with programs written in
other languages, including C, C++, Java, and Fortran.( Cleve Moler the chairman
of computer science department started developing MATLAB in late 1970’s. Jack
Little recognized its commercial potential and joined with Moler and Steve
Banjert. They rewrote MATLAB in Cand founded mathworks in 1984)
.
Department of ECE 25 Thejus Engineering College

B.Tech Project Interim Report I
CHAPTER 5
CONCLUSION
From the comparison study of various biometric systems we came into a
conclusion that voice recognition is best suitable for our application. As it is
having reliability, easiness of use, more social acceptance and less cost. The
devices required for the implementation of VoDAR are mat lab software and
microphone which are easily available. The Mel filter is best suitable for feature
extraction.
The Mel filter is best suitable for feature extraction. The advantage of
using Mel frequency cepstral coefficients over others are that it uses Mel
frequency scaling which are very approximate to the human auditory system.
Hence MFCC (Mel frequency cepstral coefficients) more effective than LPC
(Linear predictive coding).Vector quantization technique is more desired for
feature matching. The main advantage of VQ in pattern recognition is its low
computational burden when compared with other techniques.
Department of ECE 26 Thejus Engineering College

B.Tech Project Interim Report I
BIBLIOGRAPHY
[1]. Martinez j. “Speaker identification using Mel frequency Cepstral coefficients .”ieee paper vol.2. Feb. 2012[2]. Roberto Togneri,”An Overview of Speaker Identification: Accuracy and
Robustness Issues (IEEE magazine) march 2012 ”.
[3]. Shivanker Dev Dhingra , Geeta Nijhawan, Poonam Pandit,” isolated speech
recognition using mfcc and dtw: Issue 8, August 2013”.
[4]. Ms. Arundhati S. Mehendale and Mrs. M. R. Dixit,” An International Journal
(SIPIJ) Vol.2, No.2, June 2011 :Speaker identification”
[5]. Manjot kaur gill ,reetkamal kaur ,jagdev kaur,”vector quantization based
speaker identification,international journal issue 4,2010”
[6]. Sulochana sonkamble, dr. Ravindra thool, balwant sonkamble:” survey of
biometric recognition systems And their applications: journal of theoretical and
applied information technology(2010)”.
[7]. Vibha Tiwari:”MFCC and its applications in speaker recognition international
journal on engineering technology 2010”
[8]. Priyanka Mishra, Suyash Agrawal: “Recognition of Speaker Using Mel
Frequency Cepstral Coefficient & Vector Quantization international journal on
computer applications 2010”
[9]. Proakis,” A matlab program based speech processing”.
[10]. “Speech Production” Available in
http://www.ise.canberra.edu.au/un7190/Week04Part2.html.
Department of ECE 27 Thejus Engineering College

B.Tech Project Interim Report I
APPENDIX
A1. RECORDING OF SPEECH SIGNAL
recobj=audiorecorder;% Creating an audiorecorder object
disp('start speaking');
recordblocking(recobj,5);% Call the record or recordblocking method
disp('stop speaking');
myrecording=getaudiodata(recobj);% Creating a numeric array corresponding to
%the signal data using the getaudiodata method.
plot(myrecording);
xlabel('time');
ylabel('amplitude');
A2. PRE-EMPHASIS OF SPEECH SIGNAL
x=[1,-0.95];
y=filter(x,1,myrecording);% filtering of speech signal using pre-emphasis filter.
subplot(2,2,1);
plot(y);
xlabel('sample index(n)')
ylabel('filtered output')
Department of ECE 28 Thejus Engineering College