specification aspects of vdm
TRANSCRIPT

Specification aspects of VDM DEREK ANDREWS
Abstract: The Vienna development method is a mathematically based set of techniques for the specification, development, and proof of correctness of computer systems. One aspect of the method is the concept of mathematically based abstract data types which can be used for specifications. This paper introduces the data types and their use in the specification of computer systems.
Keywords: software engineering, formal methods, VDM.
o ne of the main specification languages used today is the English language. It was an excellent tool in the hands of such people as
Shakespeare for writing plays and sonnets; it can provide entertainment and stimulate the imagination if used to write novels and plays; it can educate and disperse ideas when used to write learned books. However , as a specification language English has major shortcomings. Two areas where it is used as such are law and in computing. In the former, various levels of Appeal Court are used to resolve any ambiguities and difficulties that occur by the use of the language. Thus after a law has been carefully drawn up (specified) and inspected by the ruling Government , it goes into the statute books. The actual interpretation of the law is made by the law courts and any 'bugs' in the statute are removed by the 'user'. A similar mechanism is available for specification for computer systems written in English, the final product is judged by the user who helps the manufacturer remove the problems of the system - the one problem being that the user is not too keen on his or her role as an arbitrator for the correctness of a computer system.
Why should English be unsuitable for writing specifications? Because it allows imprecision; it lends itself to ambiguity and, in the wrong hands can be incredibly verbose. The fault is not with the language itself but with the user and here the reason is probably cultural. At school the writing of good English is both taught and encouraged; great writers and poets are used as examples of good English: a style of writing which is easy to read, does not lead to boredom and stimulates the imagination of the reader. This clashes with the need for precision in a specification, since repetitive text would be considered bad style and the only way to avoid ambiguity in a specification is to write in such a
Department of Computing Studies, University of Leicester, Univer- sity Road, Leicester LE1 7RH, UK
way that there is absolutely no possibility of it being misunderstood; this requires using the same words to describe the same idea which is not considered 'good' writing style. The writer(s) of a specification, having established a written framework to express ideas, must use exactly the same phraseology where the same ideas are intended. This, of course, will lead to an exceptionally boring document to read. A classic example of this being the PL/I language standard which is written in very precise English using well-defined phrases - there is little or no ambiguity in the document and in no sense could the standard be considered 'Shakespearian' .
There is a further problem: written English makes specific assumptions about the understanding and background of the reader and these are not precise. Different cultural divisions even within the UK can lead to misunderstandings about the use of a particular word or teminology. Across the Atlantic, the divide is even greater. Thus the need for more precision when writing specifications can be identified.
What can be done to replace English as a specifica- tion language? One possibility is to use a programming language; the higher the level of the programming language the better. Because of the need of the computer , such languages by necessity are precise. There is no possibility of ambiguity and once it is known how the computer 'understands' the language, it is fairly easy to see how a specification written in a programming language should be read and what it means. Although using a high-level language as a specification language can be made to work, it does involve one major problem - that the specification needs to be given in terms of an algorithm. Although this is not bad in itself, it is much easier to give a specification of the requirements of the answer than try and actually write down how to fill those requirements. This can be seen in other branches of engineering where a specification of what the final product should look like is given before detailed consideration of how it should be built. What is needed is a high level language which allows the writer of a software specification to specify what the system will do rather than how it should be done - a computer equivalent of a 'blue-print' .
Although the above points were made with respect to English, the reader can substitute any natural language, substituting an appropriate writer for Shakespeare.
There already exists a ready made tool for writing specifications; the tool is mathematics. Using mathe-
164 0950-5849/88/030164-13503.00 © 1988 Butterworth & Co (Publishers) Ltd. information and software technology

matics it is possible to write down the details of a system that is required with as much, or as little, precision as is required• Detail can either be left in or left out. From the work of computer science theoreti- cians, it is known that anything than can be executed on a computer can be specified in mathematics, therefore the language is adequate for the purpose of defining computer systems; in fact it is rather too adequate! It is possible to write down specifications for things that cannot be built. This could be thought of as an excuse for not using mathematics, but the problem does not go away, it is also possible to write specifications in English for things which cannot be built; the problem has always been there, it is just more obvious using mathematics•
Are there disadvantages of using mathematics as a specification language? The answer is yes - the language has to be learnt, but then so would any new specification language• Are there any advantages? Again the answer is yes. A mathematical specification can be used as the basis of development• When the program is written proofs of correctness can be produced to show how the program exactly matches the specification. The culture of using mathematics as a modelling tool is well known in other subjects such as physics and engineering, this culture should be exploited. These subject areas use mathematics as a modelling language and the experience gained can be imported into computing, thus perhaps avoiding some of the difficulties of introducing and using a new technique• (One cultural aspect of using mathematics is to use it without paying too much attention to foundations - if the mathematics works, it is used. This could be learnt with advantage in software engineering where far too much attention is paid to the foundations of the mathematics used for specifying programs, and not enough to making them usable• The foundations of mathematics are important, but so is the use of mathematics•)
The concept of abstraction is well known; most programmers know and use pseudocode, a language in which it is possible to avoid or postpone the details of an algorithm - a language for abstraction. If mathema- tics is to be used as a specification language it should be at least as good as pseudocode for abstraction; it should allow decisions and detail to be postponed• A further guide as to what a mathematically based specification language should be like can be seen from the current view of software developers, which is to concentrate on the data aspects of the system - an abstraction tool for data is required• There is a need to specify the information that a computer system will process, without going into the detail of how this information should be represented at the bit and byte level. What is needed is a pseudocode for data.
There are thus two major requirements of a mathematical specification language:
• it should allow the specification of what a system does rather than how it does it,
• it should allow the information content of data rather than the actual representation itself to be specified.
These two requirements can both be met by using the two basic tools of mathematics - that of the theory of logic and the theory of sets. Systems can be specified using these two (related) concepts alone• The tools will work for simple programs such as an electronic address book through to specification of large operating system components such as portable common tool environ- ment (PCTE). Logic and set theory can also be given syntactic 'sugar' to make them more like a high level programming language, and thus more familiar to specification writers. How can these two tools be used, the remainder of the paper will illustrate the uses of mathematics to write specifications•
Bui ld ing specif ications: logic - the mortar
The connectives - basic tools
A computer program is to be specified without giving an algorithm; this implies a notation to express what
rather than how. A way of accomplishing this is to write down the properties required of the answer; consider how shelving for books might be specified:
• . . the book shelves should be made of hard wood and be capable of holding 25 kilograms per metre length• They should be 400 mm deep a n d . . .
Alternatively the shelves may be manufactured from metal; in this case they must be either black or brown in colour a n d . . .
What is needed is some mathematical notation which is the equivalent of such phrases as
not and or in this case etc
Any ambiguity in the meaning of these 'connectives' (for this is what they do, they connect together components of the specification) should also be removed - ambiguity has no place in specifications• A specification should be written down as a series of proposals or propositions about the answer - the properties required of the system will be specified, the properties being linked together with the connectives described above•
Mathematics supplies a version of these connectives called propositional operators• These are described below in order of decreasing priority (in the same manner that* has a higher priority than +).
- A Not A.
The negation of the proposition A. If A is some property, then its negation is something not having that property:
A ^ B AandB
vol 30 no 3 april 1988 165

This describes the conjunction of the propositions (properties) A and B; a solution that must satisify the proper ty A and must also satisfy the proper ty B can be said to satisfy the proper ty A ^ B.
A v B A o r B .
This describes the disjunction of the propositions A and B. An answer that may either satisfy the proper ty A or may also satisfy the proper ty B can be said to satisfy the proper ty A or B. There is a possible ambiguity here in what happens to an answer that satisfies both propert ies? If the propert ies are mutually exclusive (i.e. like the material the shelving is to be built f rom in the example above) there is no problem - it is impossible to find an answer that satisfies both properties. If the specification calls for either of two propert ies to be satisfied, there is unlikely to be a problem if both are satisfied. In the shelving example above there are requirements for the shelving to be either strong or good- looking , the customer is hardly likely to complain if they are both ! Thus the proper ty A or B is satisfied if either A or B or both are satisfied.
A ~ B Implication, A implies B.
This connective is modelling the idea that if the particular condition A is satisfied, it should follow that the proper ty B should also hold (a very precise version of ' . . . in this case . . . ' ) . If the condition is not satisfied, then there is no requirement on the proper ty B. Using the shelving example again, the specifications might have said:
If the shelving is to be made from metal then it must not show more than 1 mm deflection under a load of 25 kilograms per metre
If the shelving is not metal, nothing is implied - it may or may not show a 1 mm deflection if the shelving is made from wood. Of course, another part of the specification may cover this case, but it has no effect on the above requirement.
A ¢:> B Equivalence of the two propositions A and B.
This connective is equivalent to the two propert ies being equivalent. Property A holds if and only if proper ty B holds. The connective can be defined in terms of ' implies ' and 'and' :
A ¢:> B is equivalent to (A ~ B)/x (B ~ A)
The above can be made more formal. For example if one introduces the idea that for a property A to hold the s ta tement of the property (proposition) A is true. If the proper ty does not hold, A is false. Each of the above operators can be described in terms of a truth table.
A - B A B A A B
true false true true true true false true false false
false true false false false false
A B
true true true false false true false false
A v B
true true true false
A B A ~ B
true true true true false false false true true false false true
Quantifiers
In a specification it is frequently necessary to write down a proper ty which holds for all objects of a particular class, mathematics again provides a mechan- ism of dealing with this. Objects of a particular class are described by defining sets (see below). The way that a class or set is defined is by stating the proper ty or propert ies that any member of that set should have. Having identified a class of objects by that means - in mathematical terms having defined a set of objects - it is useful to say that every elements in that set (object of that class) has a particular property; this is expressed using the universal quantifier which is written as an upside down A:
Vx~X. P(x) The Universalquantifier
The above statement means that for all elements in the set X, the property P holds.
Somet imes it is necessary to express that at least one e lement in a set has a particular property, this is written as a backwards E:
3xEX. P(x) The existential quantifer
The meaning of this s tatement is that there exists one or more elements in the set X such that the property P holds; note that there must be at least one element in X with the required proper ty for the above statement to be true.
Finally to restrict the property to only one element it is possible to write:
3 !x~X. P(x)
There exists exactly one element in the set X such that the proper ty P holds.
S e t n o t a t i o n - t h e b r i c k s
A set is in an unordered collection of distinct elements (or 'objects ' ) . New sets are constructed ( 'built ' ) f rom existing sets by adding elements to the collection, or by removing elements. Because the collection is un- ordered, there is no record of the order in which its elements were added, duplicates are not r emembered either. The only proper ty that a set has is the ability to answer the question 'does a particular e lement belong to it ' , the concept associated with this question is that of membership; an element or object is either a memb er of a set or it is not.
The first set to describe is the empty set, the set with no members ; this set is represented by an empty pair of brackets:
{)
166 information and software technology

A set which is not empty can be represented by an explicit description of the elements it contains; the set containing the elements 'a' and 'b' (where 'a' and 'b' denote something or other) is written.
Ca, b} Notice that the order in which the elements are written down is meaningless, as is the number of times they occur; for example:
{ a,6) = {b,a}= { a ,a ,b} = Cb, a ,b) = . . .
all denote the same set, since all the sets in the example above answer true to the questions does 'a' belong to the set, and does 'b' belong to the set; and no to any other object. In general, to explicitly define a set, its elements are just listed:
{ x l , X2, • " • , Xn }
For example the set containing the numbers 1, 2, 3, and 7 is represented by:
{1,2,3,7}
Though it is not wrong to repeat an element when writing out an explicit definition of a set, it is rather like writing 4 down as 1 + 1 + 1 + 1: correct, but 'not done' .
The main property of a set is the concept of membership - the answer to the question 'does a particular element belong to a set?'. This property be written as:
eES
this is a predicate and is true if and only if e is a member of the set S; it is false otherwise. For example:
a~Ca, b,c } is true z~ {a,b,c} is false
There is an operation that expresses the negation of set membership. The predicate that an element e is not a member of the set S can be written:
e~S
This predicate is true if and only if x is not a member of the set S. The connection between these two operators is:
e~S is equivalent to - (eCS)
or more 'mathematically':
e~S ¢~ - (eES)
where the ' ~ ' operator can be read as 'is equivalent to'.
Note that x,y~S is an abbreviation for xES ^ yES
Listing all the elements of a set explicitly is difficult, if not impossible, for large sets, it is certainly impossible for infinite sets, some other technique is required. Since a set is characterized by its elements a set could be defined by giving the membership criteria. A set is defined by defining a predicate such that elements that satisfy the predicate are in the set:
e~S if and only if P(e)
The predicate P defines the set S. This implicit description of a set, the set of those elements which satisfy the predicate (property) P, can be written:
S = {x I P(x) }
This notation can be extended by writing a function to give the following implicit definition of a set:
{ f(x)] P(x) } function predicate
When defining a set like this, the function f needs to be defined on those elements for which the predicate is true.
Some examples of implicit set notation:
{ xE,N" I 0<_x<_5 } = {0, 1, 2, 3, 4, 5} {nZl0_<n} = {0,1,4,9 .... } { 2n I 0<_n_<3 } = {0,2,4,6}
The concept of membership can be extended to a collection of elements - a set $1 is called a subset of $2 if all of the elements of the $1 also members of the set $2. The predicate that tests for the subset property is written:
S1 C $2
For examples, (a, b, c} C {a, b, c, d, e} is true. A definition of the subset operator can be written:
S 1 C 82,¢:~ V x E S 1 . x E S 2
Occasionally the concept of being a proper subset is required; that one set really is a subset, and not equal to, another:
S 1 C S 2
$1 is a proper subset of $2 if it is a subset of $2, but not equal to it; this can be written:
$1 C $2 ¢:~ $1 _C S2 A $1 =1:$2
One final operator on sets - equality, two sets are equal if they contain the same elements:
S1 = 82 ~z~ V x ~ S 1 . x f ~ S 2 A V X ~ _ S 2 . x f ~ S 1
This can be written:
S 1 = $2~:~ S 1 C S 2 A S 2 C S 1
If two sets are to be proved equal, one possible strategy is to exploit this definition; first one set is shown to be a subset of the other, and then vice versa.
So far, all the operations only allow membership of an element to be determined, and sets to be compared; the following operators are used to construct new sets from old. First, the set union operator which builds a set of elements from two sets by combining all the elements:
X ~ (S 1 U 82) (z : ) ' x~S l v x ~ S 2
The set $1 U $2 is the set all of whose members are either in $1 or $2 (or both). This can be written using an implicit set definition:
S 1 U S 2 ~ { e I e ~ S l v e f~S 2 }
vol 30 no 3 april 1988 167
The ope ra to r 'A ' can be read as 'is def ined to be equal to ' - it is a special version of equali ty where the te rm on the left is being defined.
This ope ra to r can be used to and an e lement to a set:
{x} u s
This set contains all the e lements that were in S, toge ther with the e lement x.
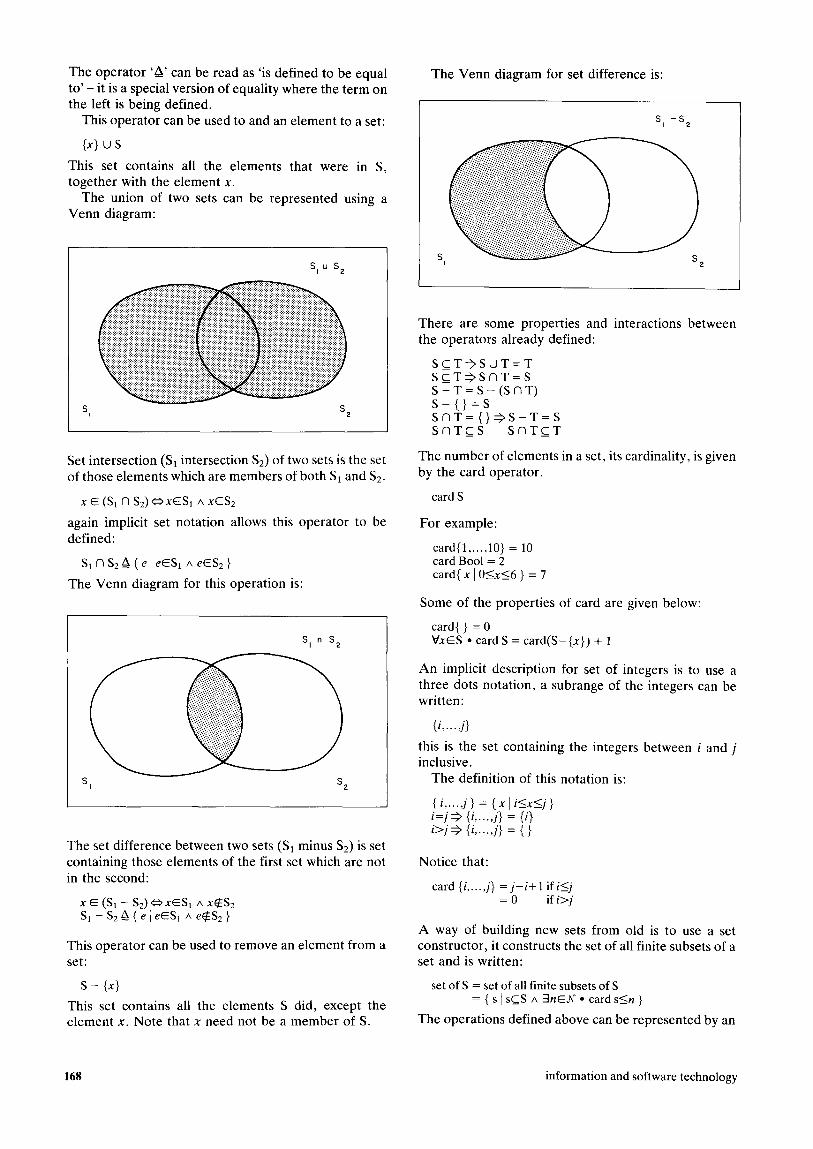
The union of two sets can be represen ted using a V e n n diagram:
S I S 2 S I u S 2
S I S 2
Set intersect ion (S~ intersection $2) of two sets is the set of those e lements which are member s of both $1 and $2.
X ~ (S 1 n 52) ~ : : ) x ~ S 1 ^ x ~ S 2
again implicit set nota t ion allows this opera to r to be defined:
SIN $2 A { e ] eES1 ^ eES2 }
The V e n n d iagram for this opera t ion is:
S I n S 2
S I S a
The set difference be tween two sets ($1 minus $2) is set conta in ing those e lements of the first set which are not in the second:
X E (S 1 -- 52) g : : : )x~S 1 A x ~ S 2
S 1 - S 2 ~ ( e [ e E S ~ ^ e ~ S 2 }
This opera to r can be used to remove an e lement f rom a set:
s - {x}
This set contains all the e lements S did, except the e lement x. No te that x need not be a m e m b e r of S.
The Venn diagram for set difference is:
S t - S a
There are some propert ies and interactions be tween the opera tors already defined:
S C _ T ~ S U T = T S C T ~ S A T = S S - T = S - ( S N T ) s - ( } = s S N T = { } ~ S - T = S S N T _ C S S N T _ C T
The n u m b e r of e lements in a set, its cardinality, is given by the card opera tor .
card S
For example:
card{1 ..... 10} = 10 card Bool = 2 card{ x ] 0_<x_<6 } = 7
Some of the proper t ies of card are given below:
card{ } = 0 VxES ° card S = card(S-{x}) + 1
A n implicit description for set of integers is to use a three dots nota t ion, a subrange of the integers can be writ ten:
{i .... ,j}
this is the set containing the integers be tween i and j inclusive.
The definit ion of this notat ion is:
{ i .... ,j } = { x [ i<_x<_j } i = j ~ {i . . . . . j} = {i} i > j ~ { i . . . . . j } = {}
Notice that:
card {i ..... j} = j - i + 1 if i<_j = 0 if i>j
A way of building new sets f rom old is to use a set const ructor , it constructs the set of all finite subsets of a set and is writ ten:
set of S = set of all finite subsets of S = { s I s_CS ̂ 3nEX ° card s_<n }
The opera t ions defined above can be represented by an
168 information and software technology

u ,n , - , 0
A D J diagram that shows the domain and ranges of the operat ions, and their signatures.
Basic sets
The basic (predefined) sets are:
the set of Boolean values:
Bool = { true,false }
the set of all natural numbers is written as N
or= { 0,1,2 .... }
the set of all positive natural numbers is written as d~ 1
• ~ 1 • { 0,1,2 . . . . } = o r - { o )
the set of all integers is written as
= { .... - 2 , - 1,0,1,2 .... }
The set of all rational numbers is written as ~, and finally the set of all real numbers is written as 3t. Note that:
or~ c o r c ~ c ~ c ~
Example o f using sets: an operating system scheduler
As an example of sets being used in a specification, cons ider the schedul ing p rob lems of a multi- p rogramming computer system. In such a system many executing programs, or processes, share the resources of the computer under the control of the operating system.Since only one process can use the CPU at a t ime, there is a need for some sort of mechanism to decide which of the many processes that are capable of running actually can and should. The mechanism to describe the scheduling can be modelled using sets and operat ions on those sets. Much detail will be left out, but the essence of the scheduling process can be specified.
The various states a process can be in during its life-time are:
• running - the process is currently being executed and owns the CPU resource,
• ready - the process is ready to run, but cannot as the CPU resource is currently being used by another process,
Wakeup
Figure 1. Conditions a process can be in
• waiting - the process cannot run because it is waiting for I/O to complete, or for store to be allocated, or may be waiting for another program to return a resource it needs (e.g. a piece of data, an I/O device etc.).
When a program is initially loaded into store, a corresponding process is created and placed in the set of ready processes. /~t some point the process will 'deserve ' a slice of the CPU and will be dispatched.
When a process (program) is running, at some point control will return f rom the process to the operating system kernel, either by the process issuing a service call, or perhaps an interrupt occurring (the interrupt handling by the kernel and its subsidiary processes will not be modelled). As a result of the kernel gaining control, the scheduler will be asked to dispatch either the same or another process which will run until control returns again to the kernel.
The relationship between the various conditions that a program can be in are described by Figure 1. The operat ing system commands which change the condi- tion of a particular process are also shown in the illustration.
Each of the processes can be in one of the conditions described above, so that the collection of processes in a particular condition can be modelled using a set containing just those processes. Note that there can only be one running process at a t ime, so a set is not necessary to model this. The next problem is how to model a process? Each process in the system can be allocated a unique identifier (in real life this could well be the address of a control block which represents the process) and this identifier will be used to represent a process. The possible states for the system can be described as follows:
current : [Process-id] (* the current process *) ready : set of Process-id (* the set of processes that are
ready and eligible for scheduling *)
blocked : set of Process-id (* the set of processes that are waiting for a resource etc *)
vol 30 no 3 april 1988 169

The square brackets around the description of the current process denote the possibility that there may be no value present, i.e. no current process.
The operations of the system are:
dispatch(pid : Process-id) choose a process from the set of ready processes for dispatch; the chosen process becomes the current process.
time-run-out(pid : Process-id) a running process has used up its allotted time- slice, how this operation is called is left out of the specification for simplicity.
block(pid : Process-id) a process issues a request which causes it to block; i.e. it cannot continue to run until the request (for a resource or for a service) can be granted.
unbiock(pid : Process-id) a blocked process can continue; the resource it has been waiting for is now available, or the request it has been waiting for has been granted and has completed.
create-process(pid : Process-id) create a new process.
destroy-process(pid : Process-id) a process has completed its execution.
Given that the system has been modelled using sets, how can the operat ions be specified? Rather than just define each of them using some sort of functional or programming language notation, they will be described by defining how the output of each operat ion is related to the input. All that is needed is a f ramework for such a specification.
The f ramework will allow a program fragment, function, or procedure to be given a name. There will be a way of describing storage in an abstract manner ; there will be a section for describing the valid input, and finally a section that will describe how the input to the operat ion relates to the output.
OPNAME(...) ~ Describes arguments to operation ext • Abstraction tool describes State pre • Relevant input post ~ Input/output pairs
pre-OPNAME : State ~ Bool post-OPNAME : State x State ~ Bool
The pre-condition is a predicate on the initial values of the operat ion and the post-condition is a predicate between the input values of the operat ion and the output from the operation. The pre-condition specifies the acceptable input to the operation, the implementor of the code that satisfies the specification can assume that the pre-condition holds for any input. The post-condition specifies how the output from the
operat ion must be related to the input. The pre- condition can be thought of as a contract for the user of the operat ion - the input must satisfy the pre-condition for the operat ion to work correctly. The post-condition is the contract for the implementor , he/she may assume any input data satisfies the pre-condition; the code must produce results that satisfy the post-condition.
The first operat ion to be specified will be 'unblock' . The storage locations of interest are the current process, the set of ready processes and the set of blocked processes. The set of blocked and ready processes will be changed by the operat ion, the current process will be unchanged. All this can be summarized by writing:
ext rd current : Process-id, wr ready : set of Process-id, wr blocked : set of Process-id
This formula describes the state for the unblock operat ion. To help read the specification, note that 'ext ' , ' rd ' and 'wr ' are abbreviations for external, read and write respectively.
Next, the valid input values need to be defined. It can be safely assumed that the current process will not be woken-up, if the system is in a state were this is true then there is a bug! This property is written as follows:
pre pid*current
The post-condition describes the results that the operat ion must produce; the process mentioned in the argument is to be made ready - it will be removed from the set of blocked processes and added to the set of ready processes:
post ready=refidy U {pid} ^ blocked=bloCked- {pid}
When writing a post-condition, the input values for an operat ion are decorated with a hook, the output values are undecorated.
These formulae can be put together to give the following specification for unblock:
unblock(pid : Process-id) ext rd current : Process-id,
wr ready : set of Process-id, wr blocked : set of Process-id pre pid~:current post ready=re~dy U {pid} ^
blocked=bloCked- {pid}
The specification describes the data needed by the unblock operat ion in an abstract form, processes are
-T -i pre -OP
y
post - OP
Black box specification
170 information and software technology

represented by a (at present undefined) process identifiers. The pre-condition specifies what propert ies the input to the operat ion must satisfy for the operat ion to be guaranteed to work. The post-condition is a relationship between the input and the output which must be satisfied by the results of the implementat ion of the operation. Notice that this specification describes exactly what the program that satisfies the specification should do, and gives little or no indication as to how it should be done; this is the hallmark of a good specification. All questions of representat ion and implementat ion have been ignored. When writing a specification there should be no interest in irrelevant detail as to how the problem is to be solved - the algorithms - only what the problem is. Note that possible implementat ion strategies can (and should) be kept in the background - no engineer or architect would specify and design a building that cannot be built. Knowledge and experience will be used during the construction of the specification to guarantee that what is being proposed can be constructed, but this information is not part of the specification, it is part of the design and development process.
The specification describes the propert ies of the required answer. It is a description of what is wanted. The algorithm is the how of the solution, and is one of many possible ways of satisfying the specification.
The other operat ions can be specified in a similar manner .
time-run-out 0 ext wrcurrent : Process-id,
wr ready : set of Process-id, post current=nil A ready=ready U {current}
The current process has completed its slice of the CPU, and is returned to the set of ready processes. The current process is set to nil which represents no process. As no access is made to the blocked component of the state, it is not written in the external component of the operat ion specification. The absence of a pre-condition means that the pre-condition is true - the implementa- tion must always work for any input values.
dispatch(pid : Process-id) ext wr current : Process-id
rd ready : set of Process-id, pre pidEready post current=pid ^ ready=ready - {pid}
It can be assumed that the process to be dispatched is ready; the current process is set to the process identifier
of this process.
block(pid : Process-id) ext wr current : Process-id
wr ready : set of Process-id wr blocked : set of Process-id,
pre pid~blocked post (current=pid ^
current=nil ^ blocked=bloCked U {current} A ready=ready) v
( current~pid A ready=ready- {pid} ^ blocked= blocked U {pid} )
It is assumed that the process to be blocked is not already blocked, it is either running, or waiting to run; either way it is added to the set of blocked processes.
create-process0 r : Process-id ext rd current : Process-id,
ready : set of Process-id, blocked : set of Process-id
post r~Process-id- ({ current } U ready U blocked)
A process identifier is assigned to the new process; the identifier must not be one that is currently in use.
The 'destroy-process ' operat ion is complicated; there are three cases depending on whether the process to be destroyed is the current process, a ready process, or a blocked process. If it is the current process, all that is necessary is to set the current process to nil which signifies not having a current process:
pid=cuffent ^ current=nil A ready=ready A blocked=bloCked
If it is a ready process, then the process will need to be removed from the set of ready processes:
pidEready A ready=ready - { pid } A blocked=bloCked ^ current=current
If the process to be destroyed is a blocked process, then it will need to be removed from the set of blocked process:
pidEbto~ked A blocked=bloCked - { pid } A ready=ready A current=current
The post-condition will be the combination of these three possibilities - the specification of destroy-process is thus:
destroy-process(pid : Process-id) ext wr current : Process-id,
ready : set of Process-id, blocked : set of Process-id
ore pidE ({ current } U ready U blocked) post (pid=current A current=nil A
ready=refidy A blocked=bloEked ) v ( pidEready A ready=ready - { pid } A
blocked=bloEked A current=current) v (pidEbloEked A blocked=bloEked - ( pid } A ready=ready A current=cuffent )
It is assumed that the process to be destroyed exists and is removed from the system.
Finally the initial state should be specified:
State = ( nil, {), {)
)
There is no current process, there are no processes that are ready and eligible for scheduling, and there are no processes that are waiting for a resource.
There is a property of the state which can be recorded as a predicate; it models the fact that the ready processes and the blocked processes must all be different: a process cannot be ready and current, or blocked and current, or blocked and ready. This proper ty can be written:
vol 30 no 3 april 1988 171

inv: Process-id x set ofProcess-id x set ofProcess-id---~ Bool inv(c,r,b) A let S={{c},r,b} in is-disjoint(S)
Note: the is-disjoint operation returns true if all of the sets contained in its argument (which is a set of sets) are disjoint.
This property is established in the initial state, and preserved by all the operations. If the property is true before the operation, then it is true after the operation is completed. This fits in with the perception of the real world - the predicate represents some property of the real-world which is 'preserved' by the operations; thus the model of the real world should also preserved the property. The property is called a data type invariant.
/ ~ -.__1 oP /
INIT
There is proof rule that must be satisfied by all operations in a specification, it is:
V~EState. inv(~) A pre-OP(g) ^ post-OP(Ls) f f inv(s)
The rule states the following - if a value satisfied the invariant and is acceptable to the operation (i.e. satisfied the pre-condition), then the corresponding output value must satisfy the invariant too. Remember that decorated variables represent values before the operation is executed. The reader should convince him/her self that all the operations above preserve the invariant.
M o r e bricks - m a p p i n g notat ion
A mapping consists of two sets and a rule that associates an element from one with a unique element from the other. A mapping can be represented by pairs of elements, one element from the first set, and one from the second. Thus if the two sets are denoted by A and B, a mapping could be represented by a subset of a set called the product set of A and B, with a predicate that encapsulates the unique element rule. The product set of A and B is the set of all pairs with the first element coming from set A and the second element coming from the second set B.
A x B = {(a,b) t aEA ^ bEB }
A mapping from A to B is a subset of this product set:
a mapping from A to B C_ { (a, b) I aEA A bEB A some property to define the map }
To reinforce the concept of a mapping (or map), a--~b will be written in place of (a,b) for a pair of values which is an element of a mapping.
The empty mapping is represented by the empty set:
(}
this mapping contains no information. A mapping can be defined explicitly by listing the
pairs of values of which it consists, the order in which the pairs of values are written down is not important:
{d I --~ r l , d2 --~ r 2 . . . . dn ~ rn)
For any map m, the following must be true:
if a--,bEm and a- . cEm then b=c
Two examples of mappings are given below, the second could be associating the ages of a child with that child's name.
{ 2---~ 4, 3---~ 9, 4--~ 16,5--'5 } {tom--,10,dick~5,harry~10,mary~5}
For large mappings, as with sets, listing all the elements is obviously impractical, so there is a way of implicitly defining a mapping. This defines a map by giving the first element of a pair that satisfies a predicate P, and the second element is derived from the first by applying a function f, which describes a rule for the mapping. The function need not be defined over the domain of the predicate, but it must be defined over those elements that satisfy P.
{ x --~ f(x) I P(x) }
function predicate
Some examples of this are:
{x- -~xZlxE{2 ..... 5} } = { 5--. 2 5 , 2 ~ 4, 3 ~ 9, 4--* 16} { x---~ x21 -l_<x<_l } = { - 1 ~ 1, 0--. 0, 1 ~ 1 }
The set of all mappings from the set A to the set B is defined by:
map A to B
From the explanation of a mapping given above it is known that a mapping m is a subset of A x B, it is possible to write:
m = { a---~b I aEA ^ b~B A P(a,b) } C { (a,b) laEA A bE B }
remembering that a ~ b is written for the pair (a,b). For any map m, the domain of mapping is the set of
all the first elements of the pairs that make up the maping:
m E m a p D t o R dommC_D ifm = { a--.blP(a,b) } domm = { a I a---~bEm }
For example:
ifm = { x---~x2 I 1_<x<_3 } : domrn = { 1, 2, 3 } dora{ 1---~ 3, 4--~ 7, 3--* 3 } = { 1, 3,4} dom{x---~f(x) lP(x) } = {x I P(x) }
A mapping can be 'applied' to the element d of its domain, it behaves just like a function, for example:
172 information and software technology

i f m = {x--* x2 I l<_x<_3 } : m(3) = 9 m(4) is undefined {tom-.10,dick-- .5,harry-.10,mary-.5}(tom) = 10
A m a p is undef ined for e l emen t s not con ta ined in its domain .
T h e set conta ining all the second e l emen t s of the pairs in the m a p p i n g m is given by the range opera to r :
rngm
For any m a p p i n g m the fol lowing holds:
m E m a p D t o R rngmC_R
Some examples will i l lustrate the use of the range ope ra to r :
i fm = { x - * x 2 [ l<x<_3 } : rngm = { 1,4, 9 } rng{ 1--->3,4---,7,3--->3} = {3 ,7} rng{x ---* f(x) I P(x) } = { f(x) I P(x) }
T h e rng o p e r a t o r can be def ined as follows:
rngm A { m(d) I dEdomm }
A n ope ra t ion to combine two m a p s is the m a p overwr i t e ope ra to r ; this o p e r a t o r combines all of the in fo rmat ion f rom the second m a p and tha t in fo rmat ion f rom the first which is not con t rad ic ted ( ' ove rwr i t t en ' ) by the second:
m t n
For example :
{ 2---, 4,1---, 3 } t { 3---, 5,1---~ 2} = { 1---, 2, 2---~ 4, 3 ~ 5 }
T h e overwr i te o p e r a t o r can be defined:
ml t m2 A { d--* r l dEdomm2 ^ r=rn2(d) v d ~ ( d o m m l - domm2) ^ r=ml(d) }
T h e doma in restr ict ion o p e r a t o r yields a m a p p i n g whose first e l ements are res t r ic ted to be in a set.
S<3m
T h e m a p m is res t r ic ted so tha t the domain of the resul t ing m a p is the set S, for example :
i fm = { x ~ x : l l<_x_<6 } : { 1 ,3 ,5 } <3m = { 1 ~ 1 , 3 ~ 9 , 5 ~ 25 } { 2 , 3 , 4 } <3 { 1 ~ 3, 4---~ 7, 3---~ 3 } = { 4---, 7, 3---, 3 }
the m a p doma in restr ict ion o p e r a t o r is defined:
S <3 mA_ { d---*m(d)[dE(domm A S) }
D o m a i n subt rac t ion is an o p e r a t o r tha t yields the m a p p i n g whose domain does not conta in any e lements f rom a set.
S ' ~ m
For example :
i fm = { x ~ x 2 [ 1<_x<_6 } : { 1 , 3 , 5 , 6 } ~ m = { 2---~ 4, 4---~ 16 } { 2, 3,4 },~ { 1--, 3, 4---~ 7, 3--~ 3 } = { 1---~ 3 }
T h e opera t ion is def ined:
S ,~ m A { d-~ re(d) I d~ (domm - S) }
The A D J d i ag ram for these ope ra t ions is given below.
B u i l d i n g w i t h m a p p i n g s - a n e l e c t r o n i c a d d r e s s
b o o k
A n example using mappings will be a specif icat ion for an e lect ronic address book . The address b o o k will s tore the names and addresses of people ; for simplicity it will be assumed that a pe r son can have only one address . T h e opera t ions to be def ined for the sys tem will be:
• to add a n a m e and the cor responding address to the address book ,
• to look-up an address , • to change an address , ' • to dele te a name and the cor responding address .
It will also be useful to have an ope ra t ion to check if a par t icular ent ry is p resen t in the address book . The s tate for this sys tem is a mapp ing f rom N a m e to Address . The re is no need to say anyth ing abou t the s t ructure of e i ther a n a m e or an address , except that there is an order ing def ined on names which is the usual a lphabe t ic order . The state for the sys tem is then:
Book = map Name to Address
T h e initial s ta te for the sys tem is:
Booko = { }
T h e opera t ions on the address b o o k are def ined below.
add( nm : Name, addr : Address) ext wr bk : Book pre nm~dom bk post bk = 5k t { nm --~ addr }
The add opera t ion takes a n a m e and address and 'wr i tes ' it into the address book . The i m p l e m e n t o r can as sume the n a m e (and address) are not current ly in the address book .
look-up(nm : Name) r : Address ext rd bk : Book pre nmEdom bk post r=bk(nm)
The look-up opera t ion finds a name in the address b o o k and re turns the cor responding address . The i m p l e m e n t o r of this ope ra t ion can assume tha t the n a m e of the person is in the address book .
change(nm : Name, addr: Address) ext wr bk : Book
vol 30 no 3 april 1988 173

pre nmEdom bk post bk = 15k t { nm-- , addr }
T h e change opera t ion upda tes an address for an exist ing entry. T h e i m p l e m e n t o r can assume the address b o o k current ly contains the n a m e (and cor respond ing address) .
delete(nm : Name) ext wr bk : Book pre nmEdom bk post bk = {nm} ~ lSk
The dele te ope ra t ion r e m o v e s an ent ry f rom the address book .
is-listed(nm : Name) r : Bool ext rd bk : Book post r ¢:> nmEdom bk
This ope ra t i on checks to see if a n a m e is p resen t in the address book .
M o r e b r i c k s - s e q u e n c e n o t a t i o n
Sequences are similar to sets but with two addi t ional p roper t i e s , they r e m e m b e r bo th o rder and duplicates .
T h e e m p t y sequence , the sequence with no e lements , is deno ted by:
I] Sequences can be def ined explicitly, the sequence with exact ly the given e lements in the o rder shown is de no t ed by:
[l1,12,13 ..... In]
For example :
[1,4,2,7,7]
deno tes the sequence with five e l emen t s in the o rde r shown. In contras t to sets:
• the o rde r in which the e lements in a sequence are wri t ten is significant,
• mul t ip le sequence e lements are r ega rded as distinct.
For examples the fol lowing sequence defini t ions are not equivalent :
[1,2,3] :~ [2,1,3] * [3,1,2] :~ ... [1,2,1,3,3] 4: [1,2,1,3] * [1,2,3]
T w o sequences are equal if and only if they conta in the s ame n u m b e r of e l ements in the s ame order .
T h e first e l emen t , or head , of a sequence is given by the head ope ra to r . I f P is the sequence [c, a, b, b, d, c, c, e] then:
head P = c
The o p e r a t o r tha t yields the sequence which remains the head of the sequence has been r e m o v e d is cal led tail. I f P is the sequence [c,a,b,b,d,c,c,e], then:
tail P = [a,b,b,d,c,c,e] Both head and tail are given as pr imit ive opera t ions , and thus a defini t ion cannot easily be given, but their mean ing when appl ied to any n o n - e m p t y list should be obvious .
Sequences can be indexed (or subscr ipted) . The e l emen t of a sequence 1 with index i is wri t ten l(i). For e x a m p l e if P is the sequence [c ,a ,b ,z ,d ,c ,c ,e] then:
P(4) = z P(9) is underfined as 9 is not a valid index for P [3,3,1,2](3) = 1
Indexing a list can be def ined using the head and tail opera to r s :
_(_) : seq of X - ~ X l(i) _A if i=1 then head I else (tail l ) ( i - 1)
The length of a sequence is given by the len opera to r ; it yields the n u m b e r of e lements in a list.
len_ : seq of X ~ gf len 1 A if l=[ ] then 0 else l+len(tail l)
Thus:
len[1,4,2,5,7] = 5
and if P is the sequence [c,a,b,b,d,c,c,e] then:
len P = 8
The head and the tail opera t ions , and indexing are means by which sequences can be t aken apar t ; an ope ra t i on to build sequences is conca tena t ion . The conca tena t ion of two sequences is the sequence conta in ing the e lements of the first fol lowed by the e l emen t s of the second and is writ ten:
m r/
For example :
[3,5,1] "-" [7,3] = [3,5,1,7,3] [4,1] "-" [] = [4,1]
The final or last e l emen t of a sequence is p roduced by the last ope ra to r .
last 1 = l(len l)
if P is the sequence [c,a,b,b,d,c,c,e] then:
last P = e
T h e f ront o p e r a t o r yields the sequence that remains if the last e l emen t is r emoved .
front l pre-front(1) A_ 1 =~ [ ]
if P is the sequence [c,a,b,z,d,x,x,c,e] then:
front P = [c,a,b,z,d,x,x,c]
Note that:
• tail and front always yields a sequence , • head and last yield an e l emen t of the same type as
the sequence is cons t ruc ted f rom, • head , tail, f ront , and last are all undef ined on the
e m p t y sequence .
T h e fol lowing proper t i es hold:
head([x] ~ 1) = x tail([x] ~ 1) = 1 last(1 ~ [x]) = x front(1 ~ [x]) = 1
174 information and software technology

The set of indices of a sequence is the set of natural numbers which can be used as valid indices into the sequence; the operat ion that constructs this set is called
dom.
dom 1 _A {1 ,..., len 1 } dom[3,5,1] = (1,2,3)
The set of elements of a sequence 1 is the given by the rng operator .
rng 1 A_ (l(i) I i~dom 1 )
if P is the sequence [c,a,b,z,d,x,x,c,e] then:
rng P= {1,b,c,d,e,x,z, }
The two operators dom and rng are like the domain and range operators for maps; dom give the valid indexes, and rng gives the set which contains all the elements of a sequence. If a sequence is thought of as a mapping whose domain is a set of consecutive natural numbers starting f rom 1 and whose range is a set, the reason for the names dom and rng becomes more obvious. There is no possibility of ambiguity between the map version of these two operations, and the sequence version.
The ith through flh element of a sequence is given by:
1(i ..... j) _( . . . . . . . ) : seq of X x ~ x ~f ---> seq of X 1(i ..... j) A if]<i then
[] else if i= 1 then
[headl] ' -" (taill)(1 .... , j - l ) else
(tail 1)(i- 1 .... , j - l )
For example if P is the sequence [a,a,b,d,e,x,x,a] then:
P(3 ..... 5)=[b,d,e]
The concatenate opera tor can now be defined:
_ ~ _ : seq of X x seq of X --> seq of X rn~n A t lESEQ, lenl=lenm+lenn A
l(1 ..... lenm)=m(i) A l(lenm+ 1 ..... lenm+lenn)=n(i)
The t opera tor used in the above operat ion is ra ther like 3! , except that it actually 'materializes ' the unique object. The above should be read as ' that (unique) list whose length is equal to the sum of the lengths of the other two lists, and whose first part of which is equal to the m and whose second part is equal to n' .
X'~'~e~.~ Head, ,'~
Front
It is sometimes useful to know if one sequence is a continguous subsequence of another:
_in_ : seq of X x seq of X--) Bool I in m A_ 3c,dEseq of X. c "" I "" d = m
For example:
[2,3,4] in [1,2,3,4,5,6]
is true, but:
[2,4,3] in [1,2,3,4,5,6]
is not.
P r i o r i t y q u e u e
A queue is a data type for storing and retrieving data where the order of access of the data is first in, first out (FIFO). A priority queue is a queue in which the elements are kept in order of increasing priority. For this specification it will be assumed that there is a global state which contains the queue. The queue will be a sequence of items.
Queue = seq of Qitem
Each item in the queue will record its priority and the data it manages.
Qitem :: s-priority : Priority s-data : Data
The operations on the queue are one to initialize it:
init0 ext wr q : Queue postq = []
The queue is initialized to the empty sequence. Place an element in the queue according to its
priority:
enq( i : Qitem) ext wr q : Queue post is-ordered(q) A
3jEdomq. q(1 .... , j - 1) ~ q(j+ 1 ..... len q) = ~ A l(j)=i
The new item is placed in the queue according to its priority; thus if the new item is deleted f rom the new queue, the result would be the same as the old queue. The new queue must still be ordered according to priority.
Remove the first element from the queue:
deqO r : Qitem ext wr q : Queue pre q 4: [] post[r] ~ q =
The head of the queue (sequence) is removed and returned.
The is-empty operat ion checks to see if the queue is empty:
is-emptyO r: Bool ext rd q : Queue post r <==:,q = []
The queue is empty if it is equal to the empty sequence. To complete the specification, the operat ion is
ordered should be defined.
vol 30 no 3 april 1988 175

is-ordered : Queue --~ Bool is-ordered(l) _A Vi,jEdomq • i=j
v s-priority(q(i))_<s-priority(q(j))
in the above notation, q(i) gives the i th element of a sequence, which is an object of type Qitem, and s-priority selects the priority component.
Summary
The requirements of a turorial paper are such that the examples considered can only be small. VDM has been used to specify all sizes of systems; the bibliography lists many of those that have been published. The task of writing such specifications has given the writer a better insight into how the eventual system should look; unfortunately most of these systems were specified after their design and implementation.
What advantages can be obtained from using mathematics as a modelling tool? The examples above show that detail can be avoided, some of the large specifications which are available show how detail can be handled as and when necessary. Mathematics can be used as a thinking tool because of the ability to postpone details until later, the system can be sketched adding information as necessary.
A formal, mathematical, specification can be used as the basis for the development of the system; detail can be added to data models to produce executable code. The specifications can be decomposed into sub- specifications to give algorithms; both these activities can be done with associated proofs of correctness. This approach leads to an implementation in which, because of the proofs, there is an increase in confidence of the correctness of the final program. Even if this is not done, even if a formal specification is written and then thrown away - providing the same people who wrote the specification go on to design and implement the system, the greater understanding they get from writing the specification helps in the development of a higher quality product with far less errors in the final code.
Bibliography
History and development of VDM
Bjorner, D and Jones, C B (Eds) 'The Vienna Development Method: the meta-language' Vol 61 of Lecture Notes in Computer Science Springer-Verlag (1978)
Bjorner, D and Rasmussen, A 'An annotated VDM bibliography' Technical Report Dept. of Computer Science, Technical University of Denmark, DK-2800 Lyngby, Denmark (March 1987)
Bjorner, D, Mac an Airchinnigh, M, Neuhold, E and Jones, C B 'VDM a formal method at work' Proc. VDM-Europe Syrup. '87 Lecture Notes in Computer Science Springer-Verlag (1987)
Duee, D A and Fielding, E V C 'Better understanding through formal specification' Comput. Graph. Forum Vol 4 No 4 pp 333-348 (December 1985)
Jackson, M I, Denvir, B T and Shaw, R C 'Experience of introducing the Vienna Development Method into an industrial organisation' Theory and Practice of Software Development (TAPSOFT) Vol 186 of Lecture Notes in Computer Science, Springer-Verlag (March 1985)
Books and papers describing the VDM method
Andrews, D 'Overview of software engineering' Data Process. Vol 28 No 2 (March 1986) pp 64-78
Bjorner, D 'The Vienna Development Method: soft- ware abstraction and program synthesis' Vol 75 Mathematical Studies of Information Processing of Lecture Notes in Computer Science Springer-Verlag, (1979)
Bjorner, D and Jones, C B (Eds) Formal Specification and Software Development Prentice-Hall Int. (1982)
Crispin, R J 'Experience using VDM in STC' pp 19-32 Springer-Verlag (1987)
Hekmatpour, S and Ince, D C Software Prototyping, Formal Methods and VDM Open University, Faculty of Mathematics (1987)
Jackson, M I 'Developing Ado programs using the Vienna Development Method' Software Pract. & Exper. Vol 15 No 3 (March 1985)
Jones, C B 'Formal definition of programming develop- ment' Programming Methodology Vol 23 of Lecture Notes inComputer Science, Springer-Verlag, (1975) pp 287-443
Jones, C B Software Development: A Rigorous Approach Prentice-Hall, (1980)
Jones, C B 'Specification verification and testing in software development' Anderson, T (Ed.) Software Requirements Specification and Testing Blackwell Scientific Publications (1985) pp 1-13
Jones, C B Systematic Software Development Using VDM Prentice-Hall (1986)
Systems which have been specified in VDM
Andrews, D and I-Ienhapl, W 'Pascal' Bjorner, D and Jones, C B (Eds) Formal Specification and Software Development Prentice-Hall (1982) pp 175-252
Bekic, H, Bjorner, D, Henhapl, W, Jones, C B and Lucas, P 'A formal definition of a PL/I subset' Technical Report 25.139, IBM Laboratory, Vienna (December 1974)
Bjorner, D and Oest, O (Eds) 'Towards a formal description of Ado' Vol 98 Lecture Notes in Computer Science Springer-Verlag (1980)
Bjorner, D 'Programming languages: formal develop- ment of interpreters and compilers' Int. Comput. Symp. '77 pp 1-21, European ACM, North-Holland Publishing Co., Amsterdam (1977)
Bjorner, D and Lovengreen, H H 'Formal semantics of data bases' 8th Int. Very Large Data Base Conf. Mexico City (September 8-10 1982)
Cottam, I D 'The rigorous development of a system version control program' IEEE Trans. Software Eng. Vol 10 No 2 (March 1984) pp 143-154 [ ]
176 information and software technology