spatial computation mihai budiu cmu cs calcm seminar, oct 21, 2003
Post on 21-Dec-2015
217 views
TRANSCRIPT

Spatial Computation
Mihai BudiuCMU CS
CALCM Seminar, Oct 21, 2003

2
CPU Problems
• Design Complexity
• Power
• Global Signals
• Limited issue window ) limited ILP

3
Communication vs. Computation
5ps 20ps
gate wire
Power consumption on wires is also dominant

4
Network
Global Communication
Reg
Instruction unit

5
Our Approach: ASH
Application-Specific Hardware

6
1) Unroll Pipeline
NetworkReg Network NetworkReg Reg
Instruction unit
originalprocessor

7
1.
2.
1.
2.Programs
Programs
Resource Binding Time
CPU ASH

8
2) Specialize Pipeline
NetworkReg Network NetworkReg Reg
Instruction unit
Fixed program

9
2) Specialize Pipeline:Functional Units
NetworkReg Network NetworkReg Reg
Instruction unit
Fixed program

10
2) Specialize Pipeline: Interconnection Network
Reg Reg Reg
Instruction unit
Fixed program

11
Instruction unit
2) Specialize Pipeline: Register Files
Fixed program
1
0

12
Instruction unit
2) Specialize Pipeline: Shrink Wires
Fixed program
1
0

13
2) Specialize Pipeline: No Instruction Fetch, Decode, Issue
1
0
14
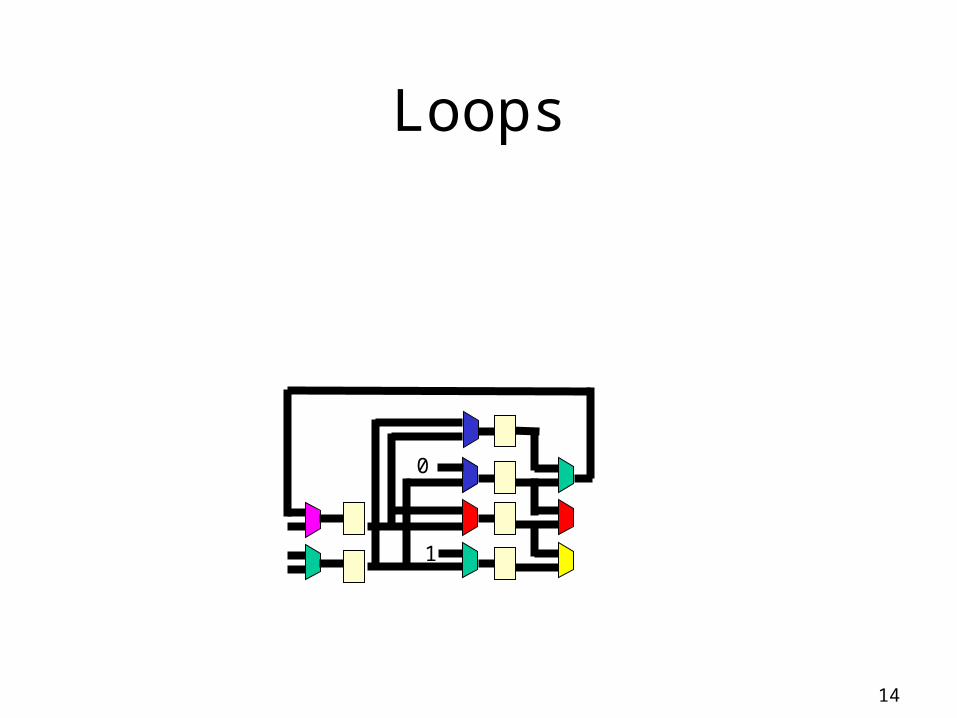
Loops
1
0

15
Memory
LSQ To memory
1
0

16
Outline• Introduction• CASH: Compiling for ASH
• ASH vs CPU• Analyzing the Results• Conclusions

17
Application-Specific HardwareC program
Compiler
Dataflow IR
Reconfigurable/custom hw

18
Asynchronous Computation
+
data
datavalid
ack
latch

19
Distributed Control Logic
+ -
ackrdy
FSM
more info

20
Forward Branches
if (x > 0) y = -x;
elsey = b*x;
*
xb 0
y
!
- >
Conditionals ) Speculation

21
Control Flow ) Data Flow
datapredicate
Merge
Gateway
data
data
Split (branch)p
!

22
i
+1< 100
0
*
+
sum
0
Loops
int sum=0, i;
for (i=0; i < 100; i++)
sum += i*i;
return sum;return sum; !
ret

23
Outline• Introduction• Compiling for ASH• ASH vs CPU
• Analyzing the Results• Conclusions

24
ASH vs:
1. 4- & 8-wide VLIWs
2. Superscalar, media kernels
3. Superscalar, SpecInt95

25
OpenDIVX IDCT, Normalized Running Time
0
10
20
30
40
50
60
70
80
90
100
Norm cycles 100 48.8 28.7 33.9 18.7
4-way OOO 4-way VLIW 8-way VLIW CASH CASH,unroll

26
OpenDIVX IDCT,Sustained IPC
0
2
4
6
8
10
12
14
16
IPC 3.26 6.46 8.53 15.07
4-way OOO 4-way VLIW 8-way VLIW CASH CASH,unroll
includes speculative ops
no data

27
Media Kernels, vs 4-way OOO
0
0.5
1
1.5
2
2.5
3ad
pcm
_d
adpc
m_e
epic
_d
epic
_e
g721
_d
g721
_e
gsm
_d
gsm
_e
jpeg
_d
jpeg
_e
mes
a
mpe
g2_d
mpe
g2_e
pegw
it_d
pegw
it_e
rast
a
Tim
es f
aste
r
125.85.8

28
Media Kernels, IPC
0
5
10
15
20
25
adpc
m_d
adpc
m_e
epic
_d
epic
_e
g721
_d
g721
_e
gsm
_d
gsm
_e
jpeg
_d
jpeg
_e
mes
a
mpe
g2_d
mpe
g2_e
pegw
it_d
pegw
it_e
rast
a
Base IPC
ASH IPC
4

29
Cost of Performance
0
1
2
3
4
5
6
7
8
9
10ad
pcm
_d
adpc
m_e
epic
_d
epic
_e
g721
_d
g721
_e
gsm
_d
gsm
_e
jpeg
_d
jpeg
_e
mes
a
mpe
g2_d
mpe
g2_e
pegw
it_d
pegw
it_e
rast
a
Tim
es b
igg
er
Speed-up
IPC Ratio
12

30
This Is Obvious!
ASH runs at full dataflow speed, so CPU cannot do any better(if compilers equally good)

31
SpecInt95, ASH vs 4-way OOO
-50
-40
-30
-20
-10
0
10
20
300
99
.go
12
4.m
88
ksim
12
9.c
om
pre
ss
13
0.li
13
2.ij
pe
g
13
4.p
erl
14
7.v
ort
ex
Pe
rce
nt
slo
we
r /
fas
ter

32
Outline• Introduction: spatial computation• CASH: Compiling for ASH• ASH vs CPU• Dissection
• Conclusions

33
The (Loop) Body
for(i = 0; i < 64; i++) {
for (j = 0; X[j].r != 0xF; j++)
if (X[j].r == i)
break;
Y[i] = X[j].q;
}
SpecINT95:124.m88ksim:init_processor, stylized

34
Dynamic Critical Path
for (j = 0; X[j].r != 0xF; j++)
if (X[j].r == i)
break;
load predicate
loop predicate
sizeof(X[j])
definition

35
MIPS gcc CodeLOOP:
L1: beq $v0,$a1,EXIT ; X[j].r == i
L2: addiu $v1,$v1,20 ; &X[j+1].r
L3: lw $v0,0($v1) ; X[j+1].r
L4: addiu $a0,$a0,1 ; j++
L5: bne $v0,$a3,LOOP ; X[j+1].r == 0xF
EXIT:
L1! L2 ! L3 ! L5 ! L14-instructions loop-carried dependence
for (j = 0; X[j].r != 0xF; j++)
if (X[j].r == i)
break;

36
If Branch Prediction Correct
L1! L2 ! L3 ! L5 ! L1Superscalar is issue-limited!2 cycles/iteration sustained
for (j = 0; X[j].r != 0xF; j++)
if (X[j].r == i)
break;
LOOP:
L1: beq $v0,$a1,EXIT ; X[j].r == i
L2: addiu $v1,$v1,20 ; &X[j+1].r
L3: lw $v0,0($v1) ; X[j+1].r
L4: addiu $a0,$a0,1 ; j++
L5: bne $v0,$a3,LOOP ; X[j+1].r == 0xF
EXIT:

37
SpecInt95, perfect prediction
-60
-40
-20
0
20
40
60
09
9.g
o
12
4.m
88
ksim
12
9.c
om
pre
ss
13
0.li
13
2.ij
pe
g
13
4.p
erl
14
7.v
ort
ex
Pe
rce
nt
slo
we
r/fa
ste
r
Speed-up
prediction
no data

38
Critical Path with Prediction
Loads are notspeculative
for (j = 0; X[j].r != 0xF; j++)
if (X[j].r == i)
break;

39
Prediction + Load Speculation
~4 cycles!Load not pipelined(self-anti-dependence)
ack edge
for (j = 0; X[j].r != 0xF; j++)
if (X[j].r == i)
break;

40
OOO Pipe Snapshot
IF DA EX WB CT
L5L1L2
L1L2L3L4
L1L3
L5L3L2
L1L3L3
registerrenaming
LOOP:
L1: beq $v0,$a1,EXIT ; X[j].r == i
L2: addiu $v1,$v1,20 ; &X[j+1].r
L3: lw $v0,0($v1) ; X[j+1].r
L4: addiu $a0,$a0,1 ; j++
L5: bne $v0,$a3,LOOP ; X[j+1].r == 0xF
EXIT:

41
Unrolling?
for(i = 0; i < 64; i++) {
for (j = 0; X[j].r != 0xF; j+=2) {
if (X[j].r == i)
break;
if (X[j+1].r == 0xF)
break;
if (X[j+1].r == i)
break;
}
Y[i] = X[j].q;
}
when 1 iteration

42
ASH Problems• Both branch and join not free• Static dataflow (no re-issue of same instr)• Memory is “far”• Fully static
– No branch prediction– No dynamic unrolling– No register renaming
• Calls/returns not lenient• No virtualization• No dynamic optimization

43
Outline
Introduction: spatial computation
+ CASH: Compiling for ASH
+ ASH vs CPU
+ Result Analysis
= Conclusions

44
Conclusions
• ASH promising for media processing; to evaluate
– power – performance– cost
• Prediction does much more than avoid issue stalls
• von Neumann model of computation very powerful• hardware resources are not everything

45
Backup Slides
• Evaluation model• Control logic • Pipeline balancing• Lenient execution• Dynamic Critical Path

46
How Performance Is Evaluated
C
Unlimited ILP
LSQ
limited BW(2 words/c)
L18K
L21/4M
Mem
2
8
72

47
Simulation Parameters
back
• Compared to 4-wide OOO SimpleScalar• Same operation latencies• Same cache hierarchy• No measurements in library functions/OS• 3-cycle multiply, 20 cycle divide

48
Control Logic
C
C
Reg
rdyin
ackin
rdyoutackout
datain dataout
back back to talk

49
Outline• Introduction• Compiling for ASH• ASH at run-time
• ASH vs CPU• Conclusions

50
Critical Paths
if (x > 0) y = -x;
elsey = b*x;
*
xb 0
y
!
- >

51
Lenient Operations
if (x > 0) y = -x;
elsey = b*x;
*
xb 0
y
!
- >
Solve the problem of unbalanced pathsback

52
Pipeliningi
+
<=
100
1
*
+
sum
pipelinedmultiplier(8 stages)
int sum=0, i;
for (i=0; i < 100; i++)
sum += i*i;
return sum;
cycle=1

53
Pipeliningi
+
<=
100
1
*
+
sum
cycle=2

54
Pipeliningi
+
<=
100
1
*
+
sum
cycle=3
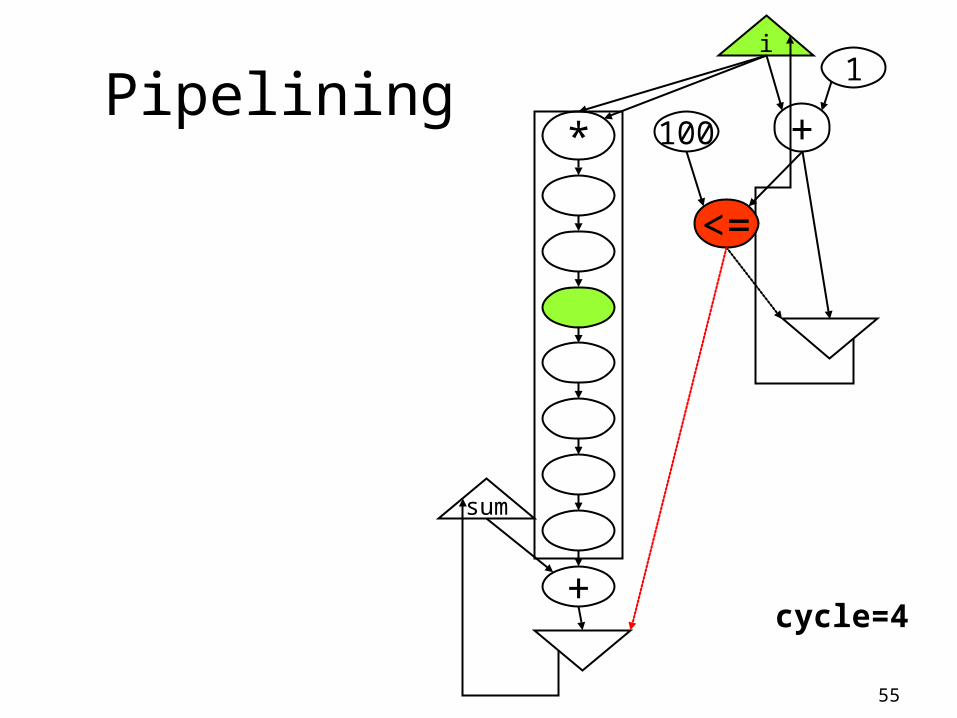
55
Pipeliningi
+
<=
100
1
*
+
sum
cycle=4

56
Pipeliningi
+
<=
100
1
*
+
sum
i’s loop
sum’s loop
Longlatency pipe
cycle=5

57
Pipeliningi
+
<=
100
1
*i=1
i=0
+
sum
cycle=6

58
Pipeliningi
+
<=
100
1
*
+
sum
i’s loop
sum’s loop
Longlatency pipe
predicate
cycle=7

59
Predicate ackedge is on thecritical path.
Pipeliningi
+
<=
100
1
*
+
sum
critical pathi’s loop
sum’s loop

60
Pipelinine balancing i
+
<=
100
1
*
+
sum
i’s loop
sum’s loop
decouplingFIFO
cycle=7
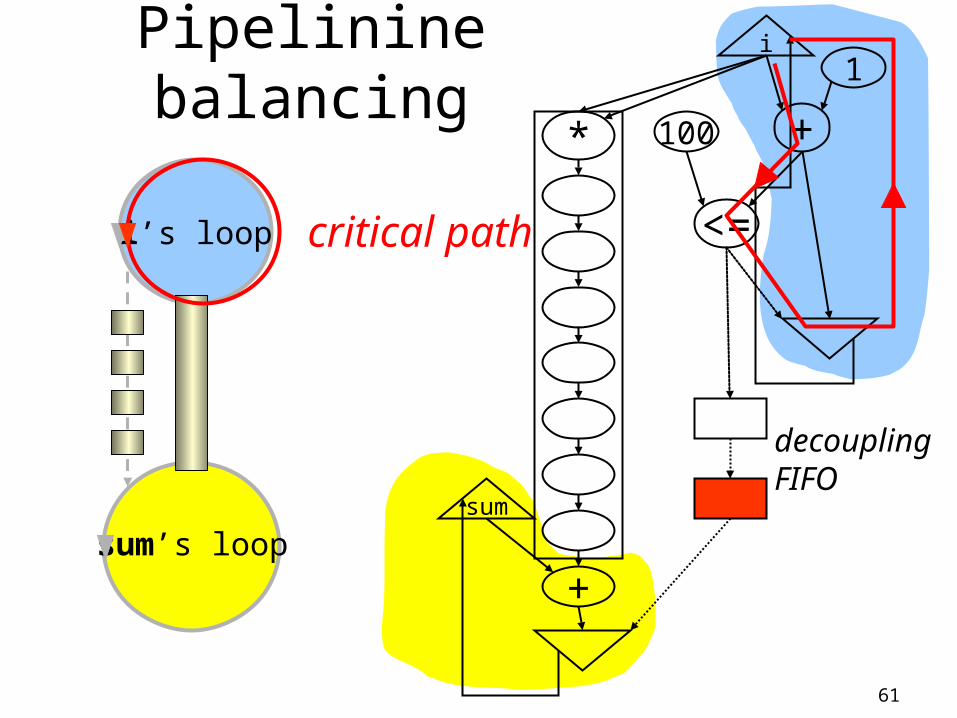
61
Pipelinine balancing i
+
<=
100
1
*
+
sum
i’s loop
sum’s loop
critical path
decouplingFIFO

62
FIFO Impact
* Pipe FIFO Cycles
N 0 903
N 1 903
Y 0 653
Y 1 474
Y 2 408
Y 3 408
i
+
<=
100
1
*
+
sum
decouplingFIFO

63
Pipelining Potential, Mediabench
1
4
7
10
0
50
100
150
200
250
300
350
Mediabench
adpcm_e
adpcm_d
gsm_e
gsm_d
epic_e
epic_d
mpeg2_e
mpeg2_d
jpeg_e
jpeg_d
pegwit_e
pegwit_d
g721_e
g721_d
pgp_e
pgp_d
rasta
mesa

64
Dataflow Loop Pipelining
• Related to software pipelining
• Copes with unknown latencies– control-flow– memory accesses
• Does not require parallelization
• Applicable to memory accesses as well
back

65
Last-Arrival Events
+
data
valid
ack
• Event enabling the generation of a result• May be an ack• Critical path=collection of last-arrival edges

66
Dynamic Critical Path
3. Some edges may repeat 2. Trace back along
last-arrival edges
1. Start from last node
back back to talk

67
• low power?
• simple verification?
• specialized to app.
• unlimited ILP
• simple hardware
• no fixed window
• economies of scale
• highly optimized
• branch prediction
• register renaming
• full-dataflow
• global signals/decision
Strengths