space & order (1) jing li 2003.1.27. the visual design and control of trellis display r. a....
TRANSCRIPT

Space & OrderSpace & Order(1)(1)
Jing Li
2003.1.27

The Visual Design and Control of Trellis Display R. A. Becker, W. S. Cleveland, and M. J. Shyu (1996). Source: http://cm.bell-labs.com/stat/doc/trellis.jcgs.col.ps
VisDB: Database Exploration using Multidimensional Visualization, Daniel A. Keim and Hans-Peter Kriegel, IEEE CG&A, 1994 Source: http://www.dbs.informatik.uni-muenchen.de/ dbs/projekt/papers/visdb.ps
TopicsTopics

The Visual Design and Control The Visual Design and Control of Trellis Displayof Trellis Display
A framework for the visualization of multivariable data

IntroductionIntroduction
Trellis Basics: A three-way rectangular array of panels with
columns, rows, and pages Panel Variables and Conditioning Variables Strip labels at the top of each panel with a
dark bar indicating the value of the variable Packet: info sent to each panel, including the
values of the panel variables to be graphed on the panel.

IntroductionIntroduction
Display method: used to uncover the structure of data. (i.e. a dot plot, a scatter plot, a box plot…)
Control method: a technique for specifying info (i.e. layout and packets’ assignment) so that a Trellis display can be drawn.
But the precise boundary between them is sometimes fuzzy.
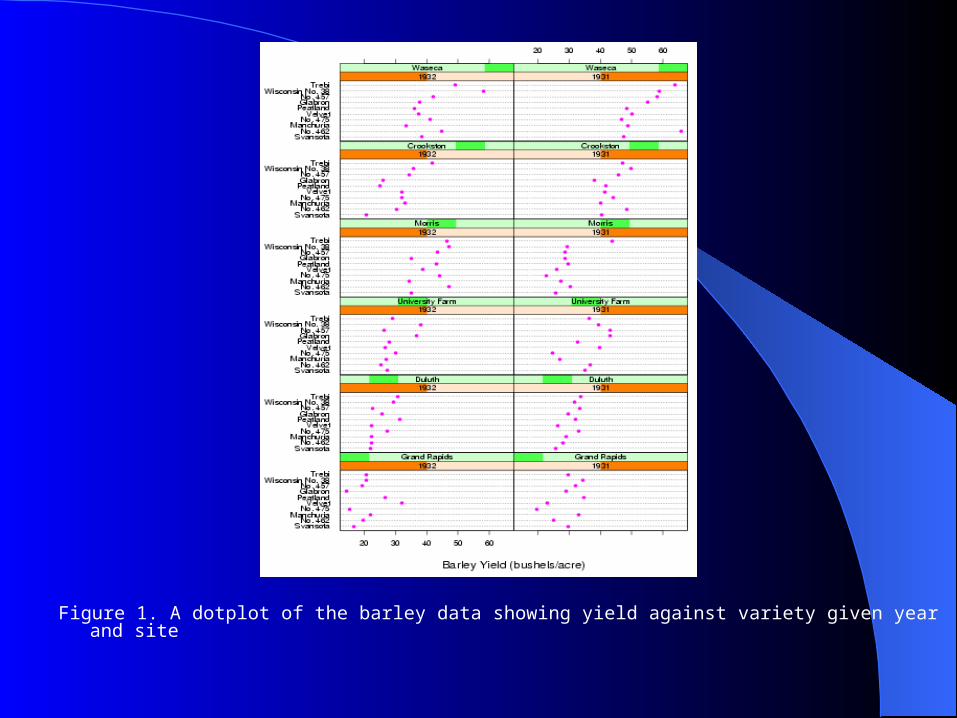
Figure 1. A dotplot of the barley data showing yield against variety given year and site

Main-Effects OrderingMain-Effects Ordering
Order the variety levels (unique values) of a variable by its median on each panel
Allow the user to discover the anomalous behavior
But better to use the natural order of the variable if a categorical variable is naturally ordered and there are more than two levels.

Figure 2. A dotplot of the barley data showing yield against site and year given variety

Multiple ConditioningsMultiple Conditionings
From figure 1, how can we compare the six values of yield for each combination of variety and year?
Need another Trellis display. The dependence changes as the value of the conditioning variables change.
Make multiple Trellis displays so that each explanatory variable appears at least once as a panel variable.

Figure 4. Yield against site given variety and year

Partial ResidualsPartial Residuals
Take the mean from all the measurements in each panel
Subtract the mean from each measurement Graph the residuals as the response by
Trellis display Partial residuals plots allow subtler effects to
emerge by removing gross main effects.

Figure 5. Differences of barley yield against variety given site

Trellising MechanismTrellising Mechanism
Dimensions: columns, rows and pages Order for conditioning variables and order for
the levels of each con variable Packet Order: the levels of the first
conditioning variable vary the fastest… Panel Order: bottom left panel of the first
page, columns, rows, pages Packet assignments to Panels: match the
packet order and the panel order

TrellisingTrellising Different Trellising
Dimension (2, 6, 1) Dimension (6, 2, 1) Flexible Trellising
The numbers of levels of the conditioning variables and the trellis dimensions are independent
Breaking: Enhance our perception Skipping: Assign packets with an irregular
structure to the rectangular trellis. If the sequence specified is smaller than the number of the panels, then skip the repeated sequence

Conditioning on A Numeric Conditioning on A Numeric Variable of Discrete ValuesVariable of Discrete Values
Response:
F -- the operating temperature of the fuse Variables:
A – the ambient temperature (75°, 110°)
S – the start condition of the fuse in a run
(cold or hot)
V – the voltage (110V, 120V, 126V)

Figure 6. Fuse temperature vs. Partial residual fuse temperature against voltage given start and ambient temperature

Conditioning on IntervalsConditioning on Intervals
Shingle: The intervals for a numerical variable together with the measured values of the variable. The intervals often overlap.
Equal Count Algorithm: Choose the number of intervals and the percentage of overlap. The endpoints are chosen to make the number of points in the intervals nearly equal while maintaining the percentage of points shared by successive intervals as close to the target percentage as possible.

Equal Count IllustratedEqual Count Illustrated

Banking to 45Banking to 45°°
Principle: Orientations of line segments are most accurately judged when the absolute slopes are centered on 45°
Choose the right aspect ratio, the height of the data region of the graph divided by the width.
Example: Sunspot cycles

Figure 7. Sunspot numbers vs. year
(source: http://www.research.att.com/~rab/trellis/sunspot.html)

High-Level Design for SoftwareHigh-Level Design for Software
The trellising mechanism:
The conceptual framework as well as the control mechanism for users
Conditioning variables use appropriate data structure:
Category for categorical variables;
Shingle for numerical variables, etc. Program a panel function instead of a high-
level routine

Trellis Display SummaryTrellis Display Summary
Bring substantial generality to multi-panel display as an overall framework
Can be scatter plots, dot plots, curve plots, wireframes, etc.
The use of strip labels to make panels self-contained
Implementation: The S-PLUS system for graphics and data analysis

VisDB: Database Exploration Using VisDB: Database Exploration Using Multidimensional VisualizationMultidimensional Visualization
A tool to support
Exploration of large databases
By using
Human Visual System
To analyze large database

ReasonsReasons
Scientific and Geographic databases tend to have large amounts of data.
Some of the challenges in dealing with these databases are:
– Mining these databases for useful information is a difficult task due to the sheer volume of data

ReasonsReasons
– Users do not know what they are looking for exactly.
– With traditional query specification languages, it is not possible to specify vague queries and thus not possible to get approximate results.
– There is no feedback. Result set may contain too few or too many points.

RequirementsRequirements
Requirements for a good Visualization System to explore large databases:
Flexible Query Specification Good Query Feedback Interactive system

RequirementsRequirements
Also, the users should be able to view as many data points as possible to see the patterns and clusters.
Necessary to display the interdependencies between data attributes, Hotspots (anomalies).

VisDB ConceptVisDB Concept
The basic idea for visualizing the data is to map the distances to colors and represent each data item resulting from a query by one or multiple colored pixels.
The goal of the VisDB system is to address the tasks of visualization of the results and to provide an effective way of incrementally refining the query to find interesting data properties.

FeaturesFeatures
More feedback on the results of the queries provided
Interactivity allows immediate feedback from a modified query
Configurable tool, that allows various forms of data visualization techniques
Using the human vision system for pattern recognition

ApproachApproach
Use each pixel of the screen to visualize the results.
Display size and resolution are limiting factors
Provide data items not only fulfilling the result exactly , but also those that match approximately.

ApproachApproach
Approximate results are determined by a relevance factor.
The relevance factor of a data item is obtained by calculating distances for each selection predicate and combining them.
The less the combined distance, the higher the relevance factor of the data point.

Basic TechniqueBasic Technique
Sort query data w.r.t. the relevance, and map relevance factors to colors
Highest relevance factor in the centerYellow-Green-Blue-Red-Black in
decreasing order of relevance.Plot the sorted, colored points starting
from the center of the screen moving outwards in a rectangular spiral fashion.

Overall Result PlotOverall Result Plot
Figure 8. Spiral Shaped Arrangement of One Dimension

Basic TechniqueBasic TechniqueTo relate the visualization of the overall
result to the visualization of different selection predicates, separate windows for each selected predicate of the query are created and shown along with the result window.
The position of the data items in all the other windows is determined by their position in the overall result window.

Arrangement of Windows for 5D DataArrangement of Windows for 5D Data
Figure 9. Arrangement of Windows for Displaying Five- Dimensional Data

Mapping 2D To The AxesMapping 2D To The Axes
Visualization of inherently 2D or 3D data is not handled in VizDB
Use of two axes for two dimensions and arrange the relevance factors according to the directions of the distance. Positive and negative values displayed.
Some space may be wasted. (i.e. some quadrant may be almost empty, while others are saturated)

2D Arrangement2D Arrangement
Figure 10. 2D-Arrangement of One Dimension

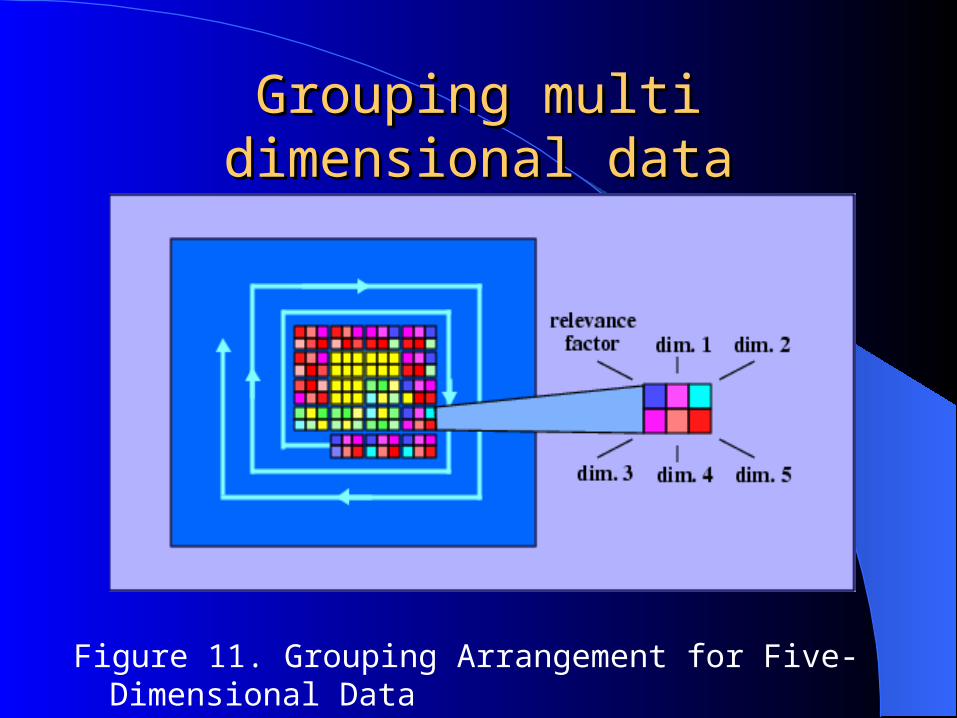
Grouping the DimensionsGrouping the DimensionsThe pixels corresponding to the different
dimensions of one data item are placed in one area instead of distributing them in different windows
Coloring is similar to the previous methodrequire more pixels per dimension per data
item. Data in multiple dimensions are represented as clusters of pixels
Useful for data sets with larger dimensionality
Grouping multi dimensional dataGrouping multi dimensional data
Figure 11. Grouping Arrangement for Five-Dimensional Data

Interactive Data ExplorationInteractive Data Exploration
Dynamic Query Modification Techniques Feedback on the results
– Change in color means change in values that are “relevant”
– Change in structure means overall distribution of data has changed
Sliders for discrete as well as continuous values
Initial Query is SQL or “Gradi”

CalibrationsCalibrations
Calculation of “relevance” factor can be calibrated by the user
Starting and ending values for various numeric data – eg: Blood samples count
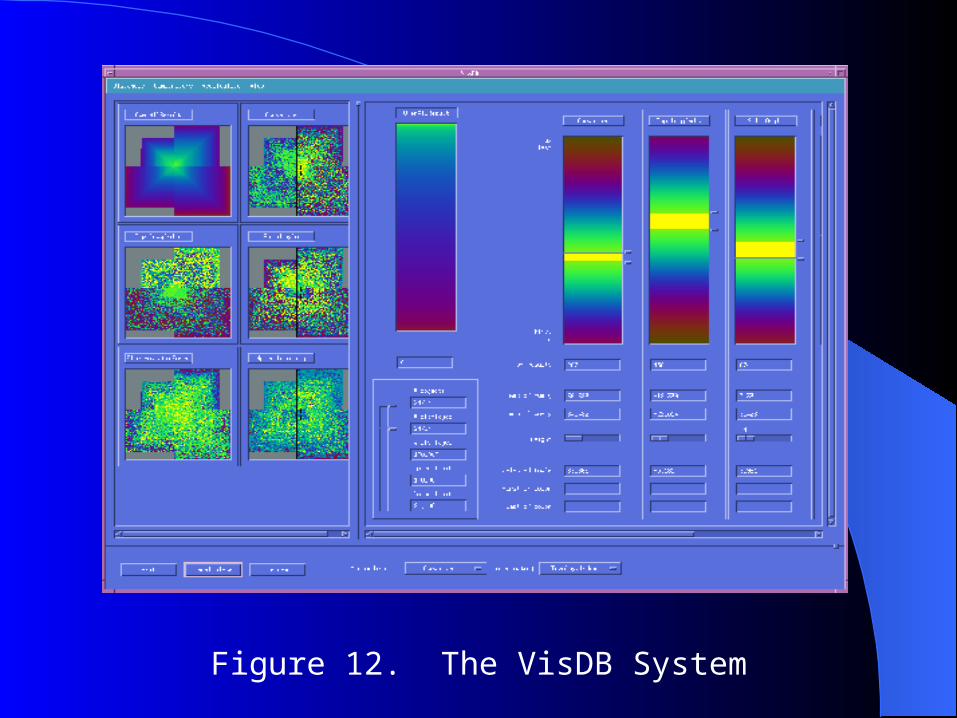
Figure 12. The VisDB System

How about complex queries?How about complex queries?
Multiple layers of windows for complex queries using nested AND and OR operators
Data that satisfies ALL join conditions is yellow. The rest is colored based on the number of criteria met
Works well with the relational databases

ApplicationsApplications
Molecular Biology - to find possible docking regions by identifying sets surface points with distinct characteristics.
Database of geographical dataEnvironmental DataNASA Earth observation data

Future ExtensionsFuture Extensions
Automatic generation of queries that correspond to data in specific regions (Select some data, and the SQL query that matches that data will get generated…)
Time series visualization
Cool !!

VisDB SummaryVisDB Summary
Useful for identifying and isolating clusters, correlations and hotspots in large databases.
Good Query specification system.No Zoom for the visualizations

Thank You!Thank You!