software and services group intel corporation - qast © 2014, intel corporation. ... libraries tbb2,...
TRANSCRIPT

Stepwise Optimization Framework
Software and Services Group
Intel Corporation

Copyright © 2014, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others. Optimization Notice
2
Agenda
Programming Tools and programming Models
Stepwise Optimization Framework
§ Step 1: Leverage on Optimized Tools and Library
§ Step 2: Scalar/Serial Optimization
§ Step 3: Vectorization
§ Step 4: Parallelization
§ Step 5: Scale from Multicores to Manycores
Case Studies
Summary

Copyright © 2014, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others. Optimization Notice
Programming Tools and Programming Models
Copyright © 2014, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others. Optimization Notice
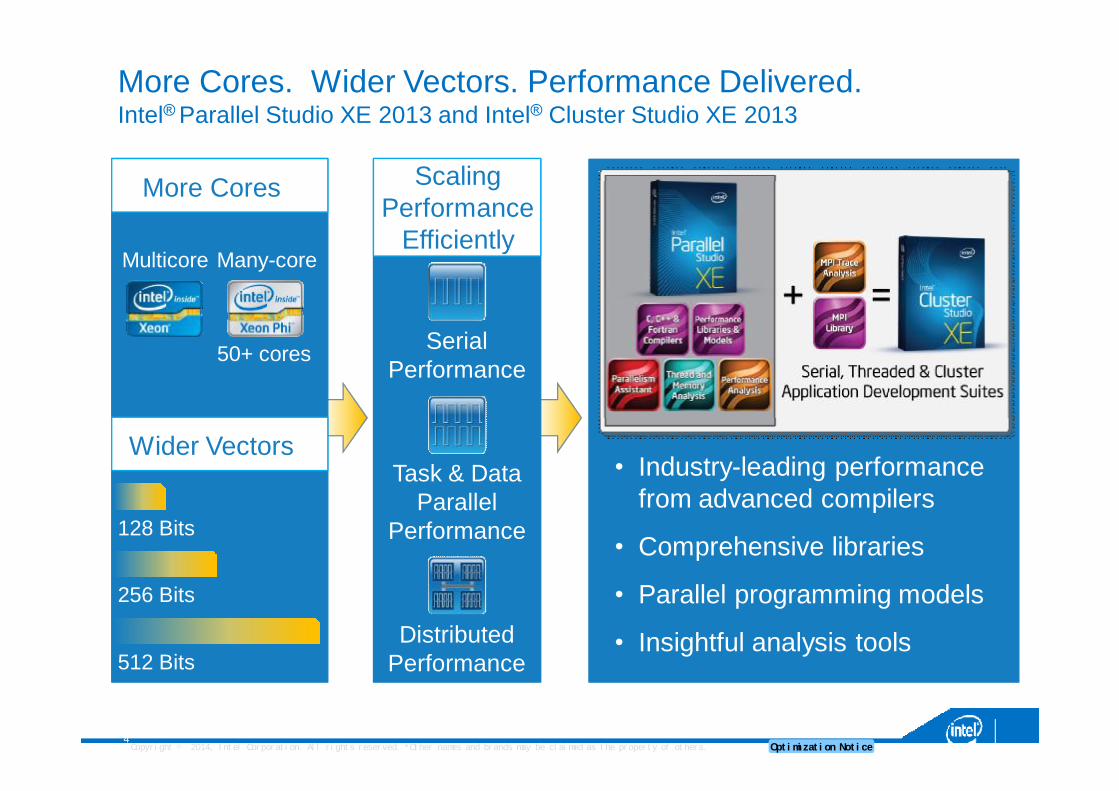
• Industry-leading performance from advanced compilers
• Comprehensive libraries
• Parallel programming models
• Insightful analysis tools
More Cores. Wider Vectors. Performance Delivered.Intel® Parallel Studio XE 2013 and Intel® Cluster Studio XE 2013
4
Serial Performance
Scaling Performance
EfficientlyMulticore Many-core
128 Bits
256 Bits
512 Bits
50+ cores
More Cores
Wider VectorsTask & Data
Parallel Performance
Distributed Performance
Copyright © 2014, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others. Optimization Notice5
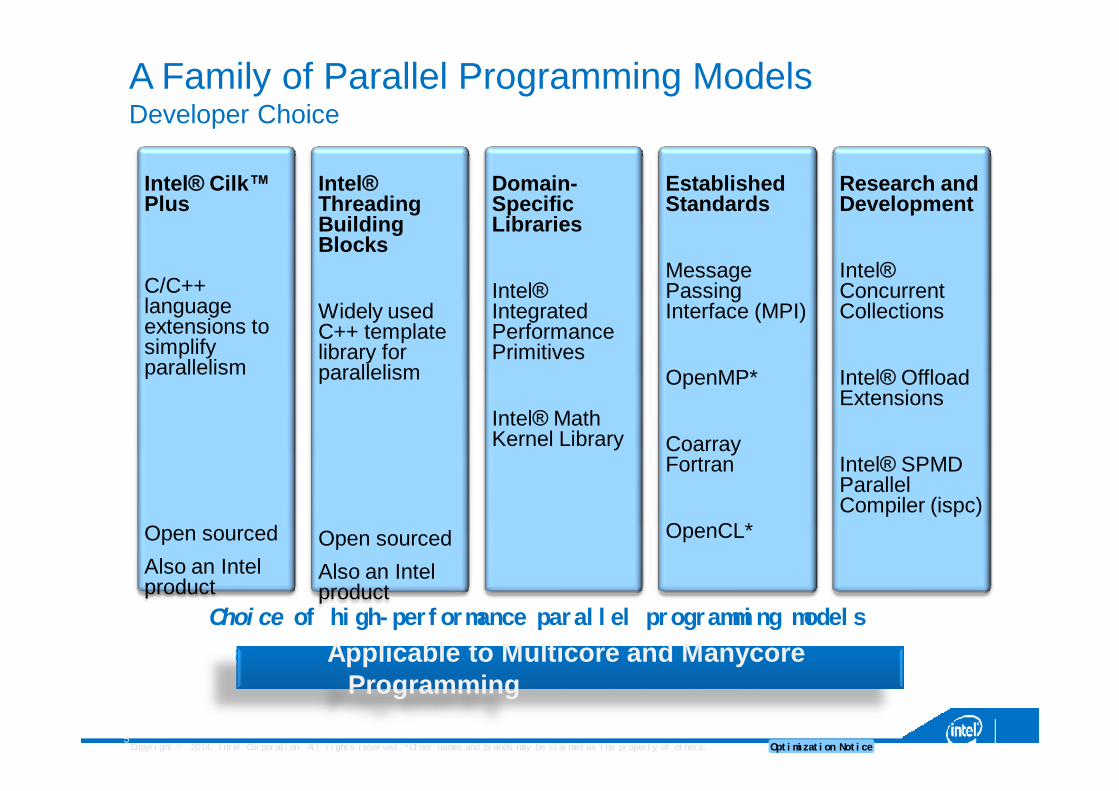
A Family of Parallel Programming ModelsDeveloper Choice
Choice of high-performance parallel programming models
Intel® Cilk™ Plus
C/C++ language extensions to simplify parallelism
Open sourcedAlso an Intel product
Intel® Threading Building Blocks
Widely used C++ template library for parallelism
Open sourcedAlso an Intel product
Domain-Specific Libraries
Intel® Integrated Performance Primitives
Intel® Math Kernel Library
Established Standards
Message Passing Interface (MPI)
OpenMP*
CoarrayFortran
OpenCL*
Research andDevelopment
Intel® Concurrent Collections
Intel® Offload Extensions
Intel® SPMD Parallel Compiler (ispc)
Applicable to Multicore and Manycore Programming

Copyright © 2014, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others. Optimization Notice
Cluster
Intel® Xeon Processors
6
Consistent Tools & Programming ModelsHigh Performance Computing
Intel tools, libraries and parallel models extend from multicore to many-core and back to optimize, parallelize and vectoriz
Code
CompilerLibraries
Parallel Models
Intel® Xeon Processors &
Intel® Xeon Phi™Coprocessors
Manycore
Intel® Xeon Processor Intel®
Xeon Phi™Coprocessor
Multicore
Intel® Xeon Processors
Develop & Parallelize Today for Maximum Performance

Copyright © 2014, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others. Optimization Notice7
Intel® Xeon Phi™ CoprocessorsBeyond Acceleration
Off-load ModelSerial code is run on the processor and parallel code is moved to coprocessor for execution. Language Extensions for Offload and x86 architecture offer significant improvements in compute flexibility.
Intel Xeon• Main ()• MPI ()• Func ()
MPI ranks only from Intel® Xeon Phi™coprocessor cores. Single node or cluster. Ranks are homogeneous --- Standard MPI, standard compilers, standard tools.
Intel Xeon Phi Coprocessor• Main ()• MPI ()• Func ()
Cluster Models
MPI ranks from processors and coprocessors.Standard MPI, standard compilers, standard tools. Single node or cluster. Ranks are heterogeneous opening up new possibilities.
Intel® Xeon Phi™ coprocessor• Main ()• MPI ()• Func ()
Intel Xeon• Main ()• MPI ()• Func ()
Intel® Xeon®Processor
Intel Xeon Phi Coprocessor
• Func ()
It’s your Code; It’s your Choice
Copyright © 2014, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others. Optimization Notice
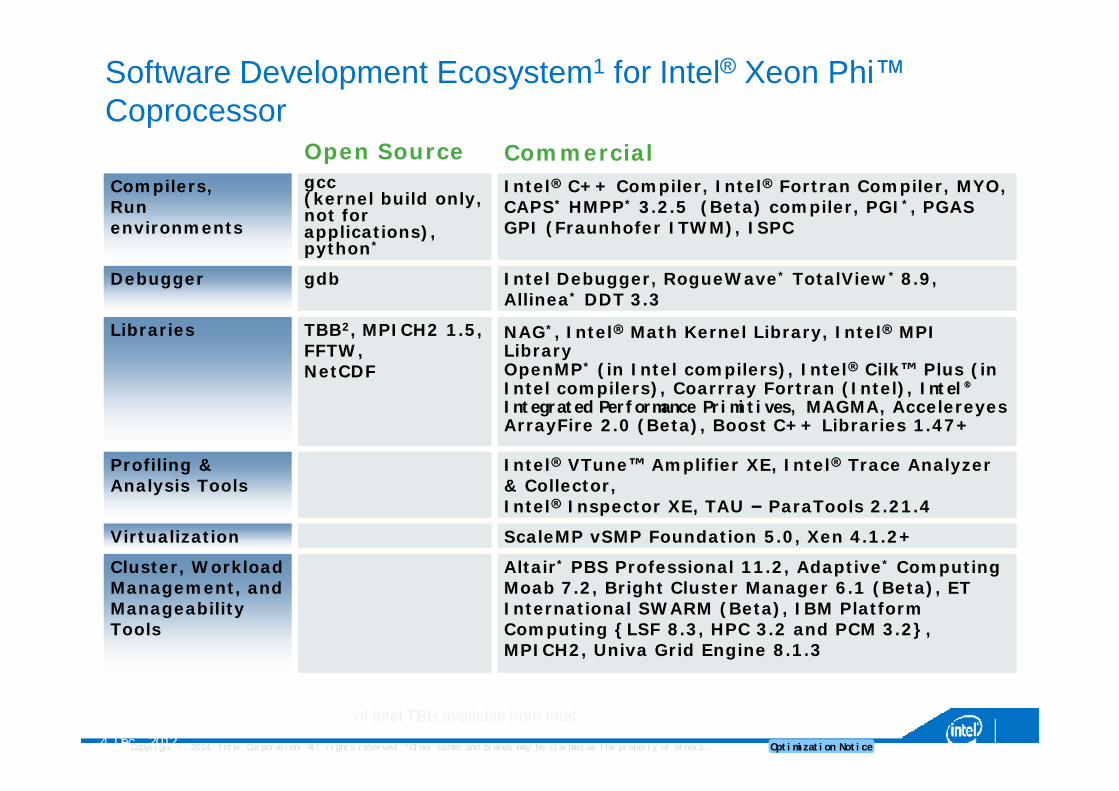
Open Source CommercialCompilers,Run environments
gcc(kernel build only, not for applications), python*
Intel® C++ Compiler, Intel® Fortran Compiler, MYO, CAPS* HMPP* 3.2.5 (Beta) compiler, PGI*, PGAS GPI (Fraunhofer ITWM), ISPC
Debugger gdb Intel Debugger, RogueWave* TotalView* 8.9, Allinea* DDT 3.3
Libraries TBB2, MPICH2 1.5, FFTW,NetCDF
NAG*, Intel® Math Kernel Library, Intel® MPI LibraryOpenMP* (in Intel compilers), Intel® Cilk™ Plus (in Intel compilers), Coarrray Fortran (Intel), Intel®Integrated Performance Primitives, MAGMA, AccelereyesArrayFire 2.0 (Beta), Boost C++ Libraries 1.47+
Profiling &Analysis Tools
Intel® VTune™ Amplifier XE, Intel® Trace Analyzer & Collector,Intel® Inspector XE, TAU – ParaTools 2.21.4
Virtualization ScaleMP vSMP Foundation 5.0, Xen 4.1.2+
Cluster, Workload Management, and Manageability Tools
Altair* PBS Professional 11.2, Adaptive* Computing Moab 7.2, Bright Cluster Manager 6.1 (Beta), ET International SWARM (Beta), IBM Platform Computing {LSF 8.3, HPC 3.2 and PCM 3.2}, MPICH2, Univa Grid Engine 8.1.3
Software Development Ecosystem1 for Intel® Xeon Phi™ Coprocessor
4 Dec. 2012
1These are all announced as of November 2012. Intel has said there are more actively being developed but are not yet announced. 2Commercial support of Intel TBB available from Intel.

Copyright © 2014, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others. Optimization Notice
Stepwise Optimization Framework

Copyright © 2014, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others. Optimization Notice
Stepwise Optimization FrameworkA collection of methodology and tools that enable the developers to express parallelism for Multicore and Manycore Computing
• Step 1: Leverage Optimized Tools, Library
• Step 2: Scalar, Serial Optimization
• Step 3: Vectorization
• Step 4: Parallelization
• Step 5: Scale from Multicore to Manycore
Objective: Turning unoptimized program into a scalable, highly parallel application on multicore and manycore architecture

Copyright © 2014, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others. Optimization Notice
Step 1: Leverage Optimized Tools, Library
Use Optimizing Compiler
§ Enable the targeted optimization –xAVX
§ Maximize compiler generated code
§ Use intrinsic as last resort
Use Optimized Library
§ Math Kernel Library
§ Thread Building Blocks
Level Description
"-O0" No optimization
"-O1" Optimization without code size increase
"-O2" Most common optimization
vectorization, loop unrolling
function call inlining
"-O3" Advanced optimization
loop fusion, interchanging
cache blocking, loop splitting
Linear Algebra
•BLAS•LAPACK•Sparse solvers•ScaLAPACK
Fast Fourier Transforms
•Multidimensional •FFTW interfaces•Cluster FFT
Vector Math
•Trigonometric•Hyperbolic •Exponential, Logarithmic•Power / Root•Rounding
Vector Random Number
Generators
•Congruential•Recursive•Wichmann-Hill•Mersenne Twister•Sobol•Neiderreiter•RDRAND-based
Summary Statistics
•Kurtosis•Variation coefficient•Quantiles, order statistics•Min/max•Variance-covariance•…
Data Fitting
•Splines•Interpolation•Cell search
Objective: Minimize the amount of development work, avoid reinventing the wheel

Copyright © 2014, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others. Optimization Notice
12
Step 2: Scalar, Serial Optimization
Choose and stay at right accuracy
§ Intel MKL Accuracy Mode HA, LA, EP: vmlSetMode(VML_EP);
§ Compiler: –fimf_precision=low,high,medium
Choose and stay in right precision
§ Type your constants: const NUM = 1.0f
§ Use right function API exp() for DP, expf() for SP
Minimize the impact of Denormals
§ Much higher cost to manycore –fp-modal fast=2-fimf_domain_exclusion=15
§ Calculate the Compute to Data Access Ratio
Use EBS from Intel VTune Performance Analyzer
§ CPU_CLK_UNHALTED/INSTRUCTION_ECECUTED
§ Investigate is CPI per thread > 4
Objective: Optimize core computation logic, Understand the scaling potential of your application

Copyright © 2014, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others. Optimization Notice
Step 3 Vectorization
Vector intrinsics (mm_add_ps, vaddps)
C++ Vector Classes (F32vec16, F64vec8)
Intel® Cilk Plus™ Elemental function
Compiler-based autovectorization
Array Notation: Intel® Cilk™ Plus
• SIMD Parallelism Require data alignment
– Convert the input from Array Of Struct to Struct Of Array
– Memory declaration __attribute__((aligned(64)) float a;
– Memory allocation _mm_malloc(size, align)– TBB: scalable_aligned_malloc(size, align)
• Branch Breaks SIMD Execution
– Conditional logic has to be masked at a cost
– Functional calls can be hazardous
• Start with Compiler-based auto vectorization
– Provide hints on Alignment, Aliases, Data Dependency
• Calculate the VPU usage ratio
– VPU_ELEMENTS_ACTIVE/VPU_INSTRUCTION_EXECUTED– Investigate if ratio is < 8 for DP, < 16 in SP
Objective: Fill up all SIMD Lanes, Full utilization of one Core.
Copyright © 2014, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others. Optimization Notice
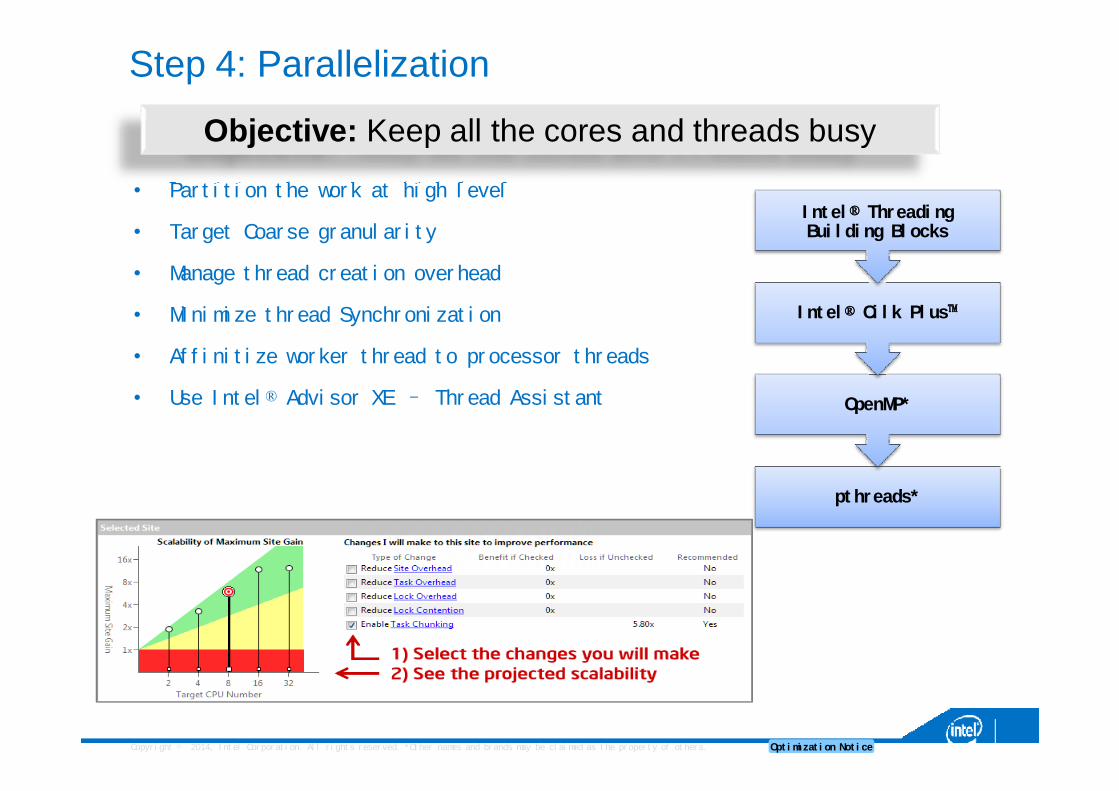
Step 4: Parallelization
• Partition the work at high level
• Target Coarse granularity
• Manage thread creation overhead
• Minimize thread Synchronization
• Affinitize worker thread to processor threads
• Use Intel® Advisor XE – Thread Assistant
pthreads*
OpenMP*
Intel® Cilk Plus™
Intel® Threading Building Blocks
Objective: Keep all the cores and threads busy

Copyright © 2014, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others. Optimization Notice
Step 5: Scale from Multicore to Manycore
Reduce the memory footprint to bare minimum
§ Use registers and Caches wisely
§ Inline function calls
§ Recalculate
Improve Data Affinity
§ Memory allocation from the worker threads
Block the data
§ Improve Memory access efficiency
Objective: Take Parallel/Vectorized Program from 10s to 100s threads

Copyright © 2014, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others. Optimization Notice
Case Study

Copyright © 2014, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others. Optimization Notice17
Black-Scholes: Workload Detail
S X T R V C
S: Current Stock priceX: Option strike priceT: Time to ExpiryR: Risk free interest rateV: Volatility
c: European callp: European put
)()( )( )(
12
21
dSCNDdCNDeXpdCNDeXdSCNDc
rT
rT
−−−=
−=−
−
TvdTv
TvrXS
d
Tv
TvrXS
d
−=−+
=
++=
1
2
2
2
1
)2()ln(
)2()ln(P
rTrT eXceSp −− +=+
)2
1(21
21)( xERFxCND +=

Copyright © 2014, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others. Optimization Notice
float CND(float d){
const float A1 = 0.31938153;const float A2 = -0.356563782;const float A3 = 1.781477937;const float A4 = -1.821255978;const float A5 = 1.330274429;const float RSQRT2PI =
0.39894228040143267793994605993438;
floatK = 1.0 / (1.0 + 0.2316419 * abs(d));
floatcnd = RSQRT2PI * exp(- 0.5 * d * d) * (K
* (A1 + K * (A2 + K * (A3 + K * (A4 + K * A5)))));
if(d > 0)cnd = 1.0 - cnd;
return cnd;}
18
Compiled with GCCgcc –o bs_step0 –O2 bs_step0.cpp
0
1
2
3
4
5
6
Baseline Code
Million Opt/sec
Stepwise Optimization
Configurations: Dual socket server system with two 2.6 GHz Intel® Xeon™ processor E5-2670 32GB, 8 x 4GB DDR3-1600MHz. GCC version 4.4.6.
void BlackScholesCalc(float& callResult,float& putResult,float S, float X, float T, float R, float V )
{callResult = putResult = 0;float sqrtT = sqrt(T);float d1 = (logf(S / X) + (R + 0.5 * V * V) * T) / (V * sqrtT);float d2 = d1 - V * sqrtT;float CNDD1 = CND(d1);float CNDD2 = CND(d2);
float expRT = expf(- R * T);callResult += S * CNDD1 - X * expRT * CNDD2;putResult += X * expRT * (1.0 - CNDD2) - S * (1.0 - CNDD1);
}
voidBlackScholesReference(
float *CallResult,float *PutResult,float *StockPrice,float *OptionStrike,float *OptionYears,float Riskfree,float Volatility,int optN)
{for(int i = 0; i < REPETITION; i++)
for(int j = 0; j < DATASIZE; j++)BlackScholesCalc(CallResult[j],
PutResult[j],StockPrice[j],OptionStrike[j],OptionYears[j],Riskfree,Volatility);
}

Copyright © 2014, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others. Optimization Notice
Step 1: Leverage on Optimized Tools, Library• Use Intel® Parallel Composer XE 2013
icc –o bs_step1 –O2 bs_step1.cpp• Use Intel C Runtime Library libm
§ erf(x) is error function related to cndf(x)
• Performance: from 5.37 to 22.75 million opts/sec;improvement 4.23X
0
5
10
15
20
25
Baseline Code Step 1 ComposeXE 2013
Million Options/sec
坐标轴标题
Configurations: Dual socket server system with two 2.6 GHz Intel® Xeon™ processor E5-2670 32GB, 8 x 4GB DDR3-1600MHz. GCC version 4.4.6.
float CND(float d){
return HALF + HALF*erff(M_SQRT1_2*d);}

Copyright © 2014, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others. Optimization Notice
Step 2: Scalar, Serial Optimization• Focus on the inner loop
§ Factor out loop invariant code
§ Take advantage of put-call parity
• Performance: 22.75 to 39.15 million opts/sec;improvement: 1.72X
0
5
10
15
20
25
30
35
40
Baseline Code Step 1 ComposeXE 2013
Step 2 Scalar, Serial
Opt
Million Options/sec
Stepwise Optimization
void BlackScholesCalc(float& callResult,float& putResult,float S, float X, float T, float R, float V )
{float sqrtT = sqrtf(T);float VsqrtT = V*sqrtT;float d1 = logf(S / X)/VsqrtT + RVV * sqrtT;float d2 = d1 - VsqrtT;float CNDD1 = CND(d1);float CNDD2 = CND(d2);float XexpRT = X*expf(- R * T);callResult = S * CNDD1 - XexpRT * CNDD2;putResult = callResult + XexpRT - S;
}

Copyright © 2014, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others. Optimization Notice21
Step 3: Vectorization• Compiler based autovectorization
§ Mark #pragma simd in inner loop
• Aligned memory allocation
• Inline function calls
• Performance: 39.15 to 220.51 million opt/secimprovement: 5.63X
0
50
100
150
200
250
Million Options/sec
Stepwise Optimization
#pragma simdfor(int j = 0; j < DATASIZE; j++){
float T = OptionYears[j];float X = OptionStrike[j];float S = StockPrice[j];float sqrtT = sqrtf(T);float VsqrtT = VOLATILITY*sqrtT;float d1 = logf(S / X)/VsqrtT + RVV * sqrtT;float d2 = d1 - VsqrtT;float CNDD1 = HALF + HALF*erff(M_SQRT1_2*d1);float CNDD2 = HALF + HALF*erff(M_SQRT1_2*d2);float XexpRT = X*expf(-RISKFREE * T);float callResult = S * CNDD1 - XexpRT * CNDD2;CallResult[j] = callResult;PutResult[j] = callResult + XexpRT - S;
}
{int msize = sizeof(float) * DATASIZE;CallResult = (float *)_mm_malloc(msize, 64);PutResult = (float *)_mm_malloc(msize, 64);StockPrice = (float *)_mm_malloc(msize, 64);OptionStrike = (float *)_mm_malloc(msize, 64);OptionYears = (float *)_mm_malloc(msize, 64);
BlackScholesReference ( …);
_mm_free(CallResult);_mm_free(PutResult);_mm_free(StockPrice);_mm_free(OptionStrike);_mm_free(OptionYears);
}
Copyright © 2014, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others. Optimization Notice22
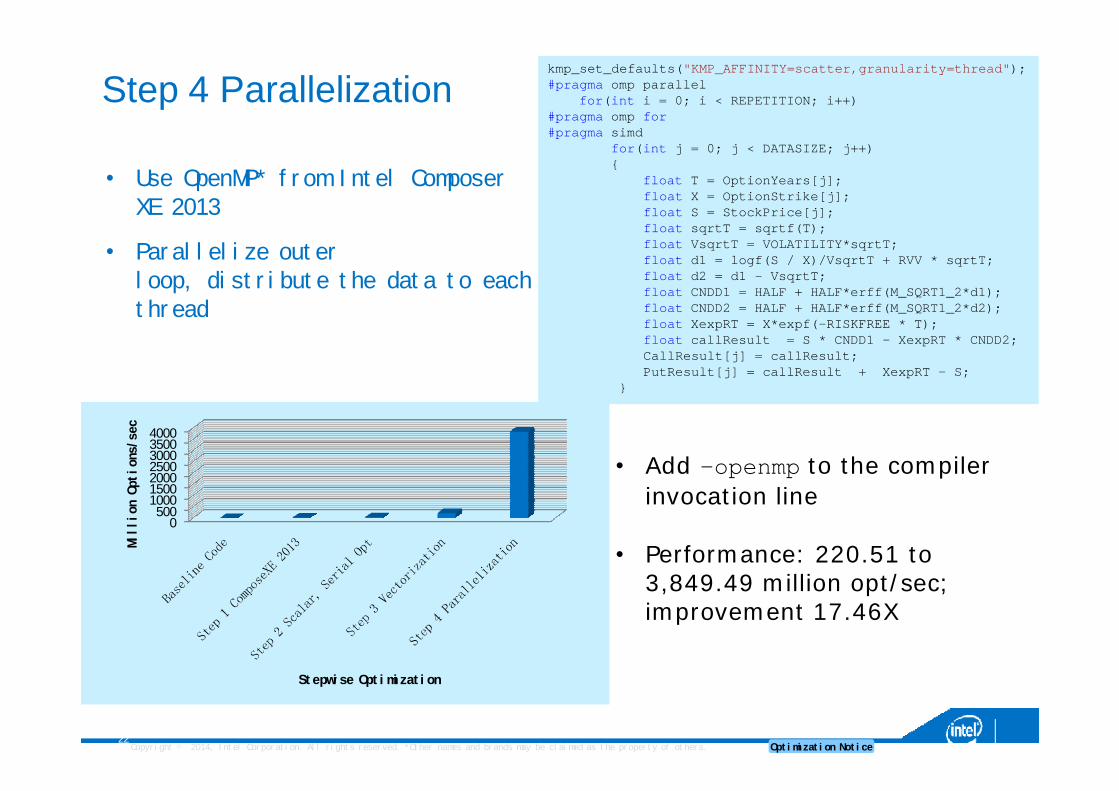
Step 4 Parallelization
• Use OpenMP* from Intel Composer XE 2013
• Parallelize outer loop, distribute the data to each thread
0500
1000150020002500300035004000
Million Options/sec
Stepwise Optimization
kmp_set_defaults("KMP_AFFINITY=scatter,granularity=thread");#pragma omp parallel
for(int i = 0; i < REPETITION; i++)#pragma omp for#pragma simd
for(int j = 0; j < DATASIZE; j++){
float T = OptionYears[j];float X = OptionStrike[j];float S = StockPrice[j];float sqrtT = sqrtf(T);float VsqrtT = VOLATILITY*sqrtT;float d1 = logf(S / X)/VsqrtT + RVV * sqrtT;float d2 = d1 - VsqrtT;float CNDD1 = HALF + HALF*erff(M_SQRT1_2*d1);float CNDD2 = HALF + HALF*erff(M_SQRT1_2*d2);float XexpRT = X*expf(-RISKFREE * T);float callResult = S * CNDD1 - XexpRT * CNDD2;CallResult[j] = callResult;PutResult[j] = callResult + XexpRT - S;
}
• Add –openmp to the compiler invocation line
• Performance: 220.51 to 3,849.49 million opt/sec; improvement 17.46X

Copyright © 2014, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others. Optimization Notice
Configurations: Intel Xeon Phi SE10 61 core 1.1 GHz 8GB GDDR5.5 GB/s
23
Step 5 Scale from Multicore to Manycore• NUMA friendly memory allocation
§ scalable_aligned_malloc(size, align);§ scalable_aglined_free();
• Affinitize the OpenMP worker threads
§ KMP_AFFINITY=“compact, granularity=fine”
• Data Blocking
• Streaming Write
• Optimize exp/log
exp(x) = exp2(x*M_LOG2E)
ln(x) = log2(x)*M_LN2
for (int chunkBase = 0; chunkBase < OptPerThread; chunkBase += CHUNKSIZE){#pragma simd vectorlength(CHUNKSIZE)#pragma simd#pragma vector aligned#pragma vector nontemporal (CallResult, PutResult)
for(int opt = chunkBase; opt < (chunkBase+CHUNKSIZE); opt++){
float CNDD1;float CNDD2;float CallVal =0.0f, PutVal = 0.0f;float T = OptionYears[opt];float X = OptionStrike[opt];float S = StockPrice[opt];float sqrtT = sqrtf(T);float d1 = log2f(S / X) / (VLOG2E * sqrtT) + RVV *
sqrtT;float d2 = d1 - VOLATILITY * sqrtT;CNDD1 = HALF + HALF*erff(M_SQRT1_2*d1);CNDD2 = HALF + HALF*erff(M_SQRT1_2*d2);float XexpRT = X*exp2f(RLOG2E * T);CallVal = S * CNDD1 - XexpRT * CNDD2;PutVal = CallVal + XexpRT - S;CallResult[opt] = CallVal ;PutResult[opt] = PutVal ;
}}

Copyright © 2014, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others. Optimization Notice24
Build Native Intel® Xeon Phi™ Application
Connect to Intel Xeon Phi:sudo ssh mic0root> cd /tmpEnvironment variables:export LD_LIBRARY_PATH=.export NUM_THREADS_NUM=240export KMP_AFFINITY=compact
Invoke the programroot>./bs_step5.micIntel® Xeon® Processor
§ 3,859 million opt/sec
Intel® Xeon Phi™ Coprocessor
§ 20,259.84 million opt/sec
0
5000
10000
15000
20000
25000
5.377 22.75 39.15 220.51
3,849.49
20,259.84
Multicore:icpc -o bs_step4 -xAVX -openmp -ltbbmalloc bs_step4.cManycore:icpc -o bs_step5.mic -mmic -openmp –ltbbmaloc bs_step5.csudo scp bs_step5.mic mic0:/tmp

Copyright © 2014, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others. Optimization Notice25
Summary
• 5 Steps Optimization Framework
• Seamlessly migrate your application on Intel® Xeon Pil.
• Forward scale your application using Intel® Parallel Studio XE 2013

Q&A

Copyright © 2014, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others. Optimization Notice
Intel's compilers may or may not optimize to the same degree for non-Intel microprocessors for optimizations that are not unique to Intel microprocessors. These optimizations include SSE2, SSE3, and SSE3 instruction sets and other optimizations. Intel does not guarantee the availability, functionality, or effectiveness of any optimization on microprocessors not manufactured by Intel.
Microprocessor-dependent optimizations in this product are intended for use with Intel microprocessors. Certain optimizations not specific to Intel microarchitecture are reserved for Intel microprocessors. Please refer to the applicable product User and Reference Guides for more information regarding the specific instruction sets covered by this notice.
Notice revision #20110804
Optimization Notice
27

Copyright © 2014, Intel Corporation. All rights reserved. *Other names and brands may be claimed as the property of others. Optimization Notice
Legal Disclaimer• Intel® 64 architecture requires a system with a 64-bit enabled processor, chipset, BIOS and software. Performance will
vary depending on the specific hardware and software you use. Consult your PC manufacturer for more information. For more information, visit http://www.intel.com/info/em64t
• Intel® Trusted Execution Technology (Intel® TXT): No computer system can provide absolute security under all conditions. Intel® TXT requires a computer with Intel® Virtualization Technology, an Intel TXT enabled processor, chipset, BIOS, Authenticated Code Modules and an Intel TXT compatible measured launched environment (MLE). Intel TXT also requires the system to contain a TPM v1.s. For more information, visit http://www.intel.com/technology/security
• Intel® Virtualization Technology (Intel® VT) requires a computer system with an enabled Intel® processor, BIOS, and virtual machine monitor (VMM). Functionality, performance or other benefits will vary depending on hardware and software configurations. Software applications may not be compatible with all operating systems. Consult your PC manufacturer. For more information, visit http://www.intel.com/go/virtualization
• Intel® Turbo Boost Technology requires a system with Intel Turbo Boost Technology. Intel Turbo Boost Technology and Intel Turbo Boost Technology 2.0 are only available on select Intel® processors. Consult your PC manufacturer. Performance varies depending on hardware, software, and system configuration. For more information, visit http://www.intel.com/go/turbo
Built-In Security: No computer system can provide absolute security under all conditions. Built-in security features available on select Intel® Core™ processors may require additional software, hardware, services and/or an Internet connection. Results may vary depending upon configuration. Consult your PC manufacturer for more details.
Enhanced Intel SpeedStep® Technology - See the Processor Spec Finder at http://ark.intel.com or contact your Intel representative for more information.
Intel® Hyper-Threading Technology (Intel® HT Technology) is available on select Intel® Core™ processors. Requires an Intel® HT Technology-enabled system. Consult your PC manufacturer. Performance will vary depending on the specific hardware and software used. For more information including details on which processors support Intel HT Technology, visit http://www.intel.com/info/hyperthreading.