snowplow analytics: from nosql to sql and back again
TRANSCRIPT

Snowplow Analytics – From NoSQLto SQL and back
London NoSQL, 17th November 2014

Introducing myself
• Alex Dean
• Co-founder and technical lead at Snowplow, the open-source event analytics platform based here in London [1]
• Weekend writer of Unified Log Processing, available on the Manning Early Access Program [2]
[1] https://github.com/snowplow/snowplow
[2] http://manning.com/dean

So what’s Snowplow?

Snowplow is an event analytics platform
Collect event data
Warehouse event data Data warehouse
Unified logUnified log
Unified log
Publish event data to a unified log
Perform the high value analyses that drive the
bottom line
Act on your data in real-time

Snowplow was created as a response to the limitations of traditional web analytics programs:
• Sample-based (e.g. Google Analytics)
• Limited set of events e.g. page views, goals, transactions
• Limited set of ways of describing events (custom dim 1, custom dim 2…)
Data collection Data processing Data access
• Data is processed ‘once’
• No validation
• No opportunity to reprocess e.g. following update to business rules
• Data is aggregated prematurely
• Only particular combinations of metrics / dimensions can be pivoted together (Google Analytics)
• Only particular type of analysis are possible on different types of dimension (e.g. sProps, eVars, conversion goals in SiteCatalyst
• Data is either aggregated (e.g. Google Analytics), or available as a complete log file for a fee (e.g. Adobe SiteCatalyst)
• As a result, data is siloed: hard to join with other data sets

We took a fresh approach to digital analytics
Other vendors tell you what to do with your data
We give you your data so you can do whatever you want

How do users leverage their Snowplow event warehouse?
Agile aka ad hoc analytics
Enables…
Marketing attribution modelling
Customer lifetime value calculations
Customer churn detection
RTB fraud detection
Product rec’ s
Event warehouse

Early on, we made a crucial decision: Snowplow should be composed of a set of loosely coupled subsystems
1. Trackers 2. Collectors 3. Enrich 4. Storage 5. AnalyticsA B C D
D = Standardised data protocols
Generate event data from any environment
Log raw events from trackers
Validate and enrich raw events
Store enriched events ready for analysis
Analyzeenriched events
These turned out to be critical to allowing us to evolve the above stack

Our data storage journey: starting with NoSQL
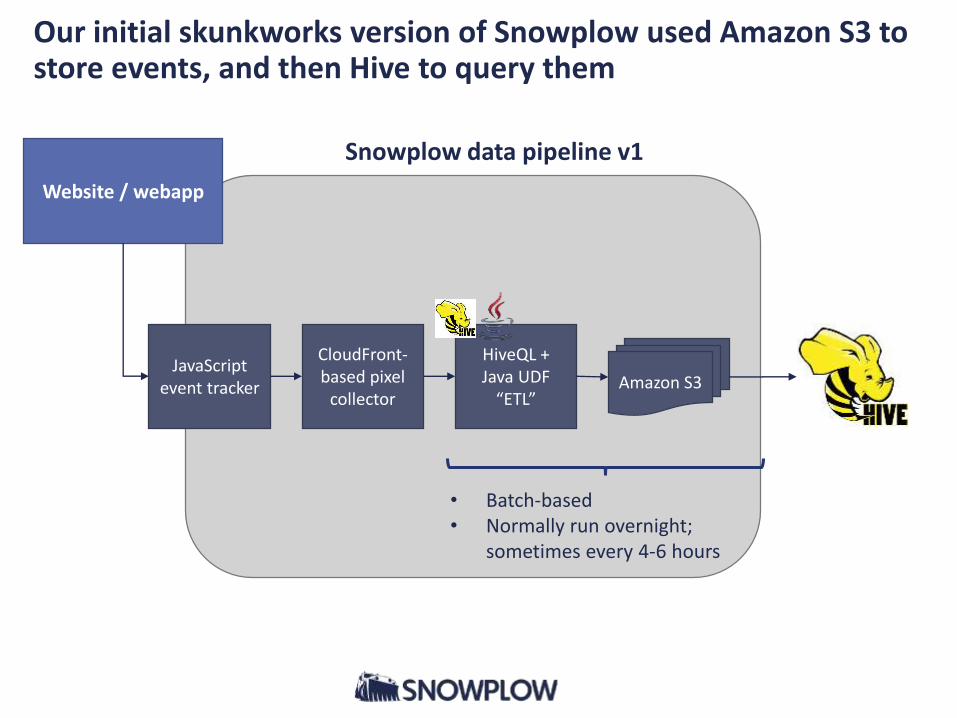
Our initial skunkworks version of Snowplow used Amazon S3 to store events, and then Hive to query them
Website / webapp
Snowplow data pipeline v1
CloudFront-based pixel
collector
HiveQL + Java UDF
“ETL” Amazon S3
JavaScript event tracker
• Batch-based• Normally run overnight;
sometimes every 4-6 hours

We used a sparsely populated, de-normalized “fat table” approach for our events stored in Amazon S3

This got us started, but “time to report” was frustratingly slow for business analysts
Amazon S3
How many unique visitors did we have in October?
What’s our average order value this year?
What royalty payments should we invoice for this month?
• Spin up transient EMR cluster
• Log in to master node via SSH
• Write HiveQL query (or adapt from our cookbook of recipes)
• Hive kicks off MapReduce job
• MapReduce job reads events stored in S3 (slower than direct HDFS access)
• Result is printed out in SSH terminal

From NoSQL to high-performance SQL

So we extended Snowplow to support columnar databases – after a first fling with Infobright, we integrated Amazon Redshift*
Website, server, application or
mobile app
Hadoop-based
enrichment
Snowplow event
tracking SDK
Amazon Redshift
Amazon S3
HTTP-based event
collector
Infobright
* For small users we also added PostgreSQL support, because Redshift and PostgreSQL have extremely similar APIs

Our existing sparsely populated, de-normalized “fat tables” turned out to be a great fit for columnar storage
• In columnar databases, compression is done on individual columns across many different rows, so the wide rows don’t have a negative impact on storage/compression
• Having all the potential events de-normalized in a single fat row meant we didn’t need to worry about JOIN performance in Redshift
• The main downside was the brittleness of the events table:
1. We found ourselves regularly ALTERing the table to add new event types
2. Snowplow users and customers ended up with customized versions of the event table to meet their own requirements

We experimented with Redshift JOINs and found they could be performant
• As long as two tables in Redshift have the same DISTKEY (for sharding data around the cluster) and SORTKEY (for sorting the row on disk), Redshift JOINs can be performant
• Yes, even mega-to-huge joins!
• This led us to a new relational architecture:
• A parent table, atomic.events, containing our old legacy “full-fat” definition
• Child tables containing individual JSONs representing new event types or bundles of context describing the event

Our new relational approach for Redshift
• A typical Snowplow deployment in Redshift now looks like this:
• In fact, the first thing a Snowplow analyst often does is “re-build” in a SQL view a company-specific “full-fat” table by JOINing in all their child tables

We built a custom process to perform safe shredding of JSONs into dedicated Redshift tables

This is working well – but there is a lot of room for improvement
• Our shredding process is closely tied to Redshift’s innovative COPY FROM JSON functionality:
• This is Redshift-specific – so we can’t extend our shredding process to other columnar databases e.g. Vertica, Netezza
• The syntax doesn’t support nested shredding – which would allow us to e.g. intelligently shred an order into line items, products, customer etc
• We have to maintain copies of the JSON Paths files required by COPY FROM JSON in all AWS regions
• So, we plan to port the Redshift-specific aspects of our shredding process out of COPY FROM JSON into Snowplow and Iglu

Our data storage journey: to a mixed SQL / noSQL model

Snowplow is re-architecting around the unified logCLOUD VENDOR / OWN DATA CENTER
Search
Silo
SOME LOW LATENCY LOCAL LOOPS
E-comm
Silo
CRM
SAAS VENDOR #2
Email marketing
ERP
Silo
CMS
Silo
SAAS VENDOR #1
NARROW DATA SILOES
Streaming APIs / web hooks
Unified log
LOW LATENCY WIDE DATA
COVERAGE
Archiving
Hadoop
< WIDE DATA
COVERAGE >
< FULL DATA
HISTORY >
FEW DAYS’ DATA HISTORY
Systems monitoring
Eventstream
HIGH LATENCY LOW LATENCY
Product rec’sAd hoc
analytics
Management reporting
Fraud detection
Churn prevention
APIs

CLOUD VENDOR / OWN DATA CENTER
Search
Silo
SOME LOW LATENCY LOCAL LOOPS
E-comm
Silo
CRM
SAAS VENDOR #2
Email marketing
ERP
Silo
CMS
Silo
SAAS VENDOR #1
NARROW DATA SILOES
Streaming APIs / web hooks
Unified log
Archiving
Hadoop
< WIDE DATA
COVERAGE >
< FULL DATA
HISTORY >
Systems monitoring
Eventstream
HIGH LATENCY LOW LATENCY
Product rec’sAd hoc
analytics
Management reporting
Fraud detection
Churn prevention
APIs
The unified log is Amazon Kinesis, or Apache Kafka
• Amazon Kinesis, a hosted AWS service
• Extremely similar semantics to Kafka
• Apache Kafka, an append-only, distributed, ordered commit log
• Developed at LinkedIn to serve as their organization’s unified log

“Kafka is designed to allow a single cluster to serve as the central data backbone for a
large organization” [1]
[1] http://kafka.apache.org/

“if you squint a bit, you can see the whole of your organization's systems and
data flows as a single distributed database. You can view all the individual
query-oriented systems (Redis, SOLR, Hive tables, and so on) as just particular
indexes on your data. ” [1]
[1] http://engineering.linkedin.com/distributed-systems/log-what-every-software-engineer-should-know-about-real-time-datas-unifying

In a unified log world, Snowplow will be feeding a mix of different SQL, NoSQL and stream databases
ScalaStream
Collector
Raw event
stream
Enrich Kinesis
app
Bad raw events stream
Enriched event
stream
S3Redshift
S3 sink Kinesis app
Redshift sink
Kinesis app
SnowplowTrackers
= not yet released
Elastic-Search sink Kinesis app
DynamoDBElastic-Search
Event aggregator Kinesis app
Analytics on Read (for agile exploration of event stream, ML, auditing,
applying alternate
models, reprocessing
etc)
Analytics on Write (for dashboarding, audience segmentation, RTB, etc)

We have already experimented with Neo4J for customer flow/path analysis [1]
[1] http://snowplowanalytics.com/blog/2014/07/31/using-graph-databases-to-perform-pathing-analysis-initial-experimentation-with-neo4j/

During our current work integrating Elasticsearch we discovered that common “NoSQL” databases need schemas too
• A simple example of schemas in Elasticsearch:
• Elasticsearch is doing automated “shredding” of incoming JSONs to index that data in Lucene
$ curl -XPUT 'http://localhost:9200/blog/contra/4' -d
'{"t": ["u", 999]}'
{"_index":"blog","_type":"contra","_id":"4","_version":1,"c
reated":true}
$ curl -XPUT 'http://localhost:9200/blog/contra/4' -d
'{"p": [11, "q"]}'
{"error":"MapperParsingException[failed to parse [p]];
nested: NumberFormatException[For input string: \"q\"];
","status":400}

We are now working on our second shredder
• Our Elasticsearch loader contains code to shred our events’ heterogeneous JSON arrays and dictionaries into a format that is compatible with Elasticsearch
• This is conceptually a much simpler shredder than the one we had to build for Redshift
• When we add Google BigQuery support, we will need to write yet another shredder to handle the specifics of that data store
• Hopefully we can unify and generalize our shredding technology so it works across columnar, relational, document and graph databases – a big undertaking but super powerful!

Questions?
http://snowplowanalytics.com
https://github.com/snowplow/snowplow
@snowplowdata
To meet up or chat, @alexcrdean on Twitter or [email protected]
Discount code: ulogprugcf (43% off Unified Log Processing eBook)