signal processing on gpus for radio telescopes - gtc...
TRANSCRIPT

May 14-17, 2012May 14-17, 2012 1GTC'12GTC'12
Signal Processing on GPUs for Radio TelescopesSignal Processing on GPUs for Radio Telescopes
John W. RomeinJohn W. Romein
Netherlands Institute for Radio Astronomy (ASTRON)Dwingeloo, the Netherlands

May 14-17, 2012May 14-17, 2012 2GTC'12GTC'12
Overview
radio telescopes six radio telescope algorithms on GPUs
part 1: real-time processing of telescope data 1) FIR filter 2) FFT 3) bandpass correction 4) delay compensation 5) correlator
part 2: creation of sky images 6) gridding (new GPU algorithm!)

May 14-17, 2012May 14-17, 2012 3GTC'12GTC'12
Intro: Radio Telescopes

May 14-17, 2012May 14-17, 2012 4GTC'12GTC'12
LOFAR Radio Telescope
largest low-frequency telescope distributed sensor network
~85,000 sensors

May 14-17, 2012May 14-17, 2012 5GTC'12GTC'12
LOFAR: A Software Telescope
different observation modes require flexibility standard imaging pulsar survey known pulsar epoch of reionization transients ultra-high energy particles …
need supercomputer real time
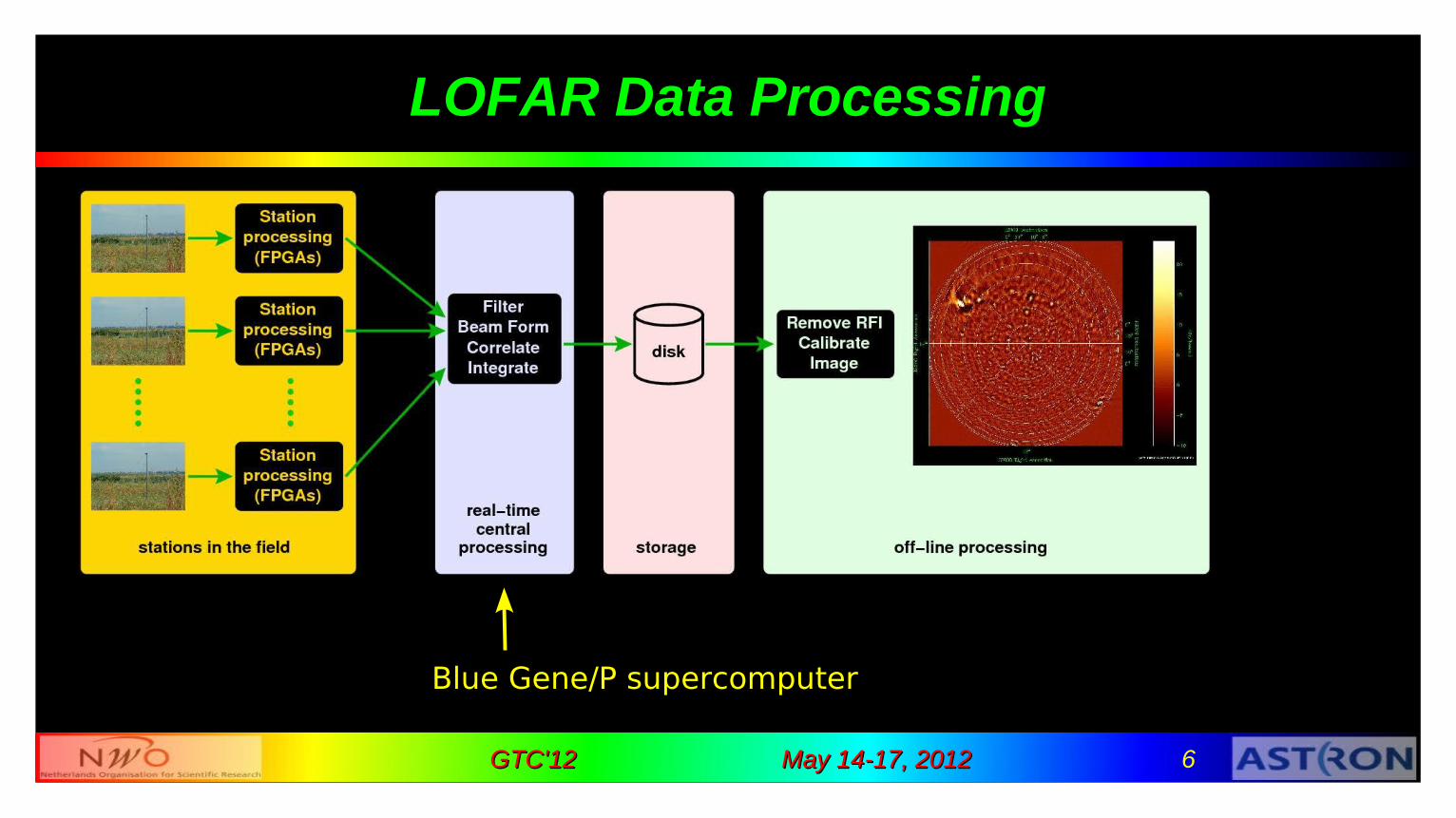
May 14-17, 2012May 14-17, 2012 6GTC'12GTC'12
LOFAR Data Processing
Blue Gene/P supercomputer

May 14-17, 2012May 14-17, 2012 7GTC'12GTC'12
Square Kilometre Array
TFLOPS
LOFAR (2012) ~30
SKA 10% (2016) ~30,000
Full SKA (2020) ~1,000,000
future radio telescope huge processing requirements

May 14-17, 2012May 14-17, 2012 8GTC'12GTC'12
Part 1: Real-Time Processing of Telescope Data

May 14-17, 2012May 14-17, 2012 9GTC'12GTC'12
Rationale
2005: LOFAR needed supercomputer 2012: can GPUs do this work?

May 14-17, 2012May 14-17, 2012 10GTC'12GTC'12
Blue Gene/P Algorithms on GPUs
BG/P software complex several processing pipelines
try imaging pipeline on GPU computational kernels only
other pipelines + control software: later

May 14-17, 2012May 14-17, 2012 11GTC'12GTC'12
CUDA or OpenCL?
OpenCL advantages vendor independent runtime compilation: easier programming (parameters constant)
float2 samples[NR_STATIONS][NR_CHANNELS][NR_TIMES][NR_POLARIZATIONS];
OpenCL disadvantages less mature
e.g., poor support for FFTs cannot use all GPU features
go for OpenCL

May 14-17, 2012May 14-17, 2012 12GTC'12GTC'12
Poly-Phase Filter (PPF) bank
splits frequency band into channels like prism
time resolution ➜ freq. resolution

May 14-17, 2012May 14-17, 2012 13GTC'12GTC'12
Poly-Phase Filter (PPF) bank
FIR filter + FFT

May 14-17, 2012May 14-17, 2012 14GTC'12GTC'12
1) Finite Impulse Response (FIR) Filter
history & weights (in registers) no physical shift
many FMAs
operational intensity = 32 ops / 5 bytes

May 14-17, 2012May 14-17, 2012 15GTC'12GTC'12
Performance Measurements
maximum foreseen LOFAR load ≤ 77 stations 488 subbands @ 195 KHz dual pol 2x8 bits/sample ≤ 240 Gb/s
GTX 580, GTX 680, HD 6970, HD 7970 need Tesla quality for real use

May 14-17, 2012May 14-17, 2012 16GTC'12GTC'12
FIR Filter Performance
GTX 580 performs best restricted by memory bandwidth

May 14-17, 2012May 14-17, 2012 17GTC'12GTC'12
2) FFT
1D complex ➜ complex 16-256 points tweaked “Apple” FFT library
64 work items: 1 FFT 256 work items: 4 FFTs
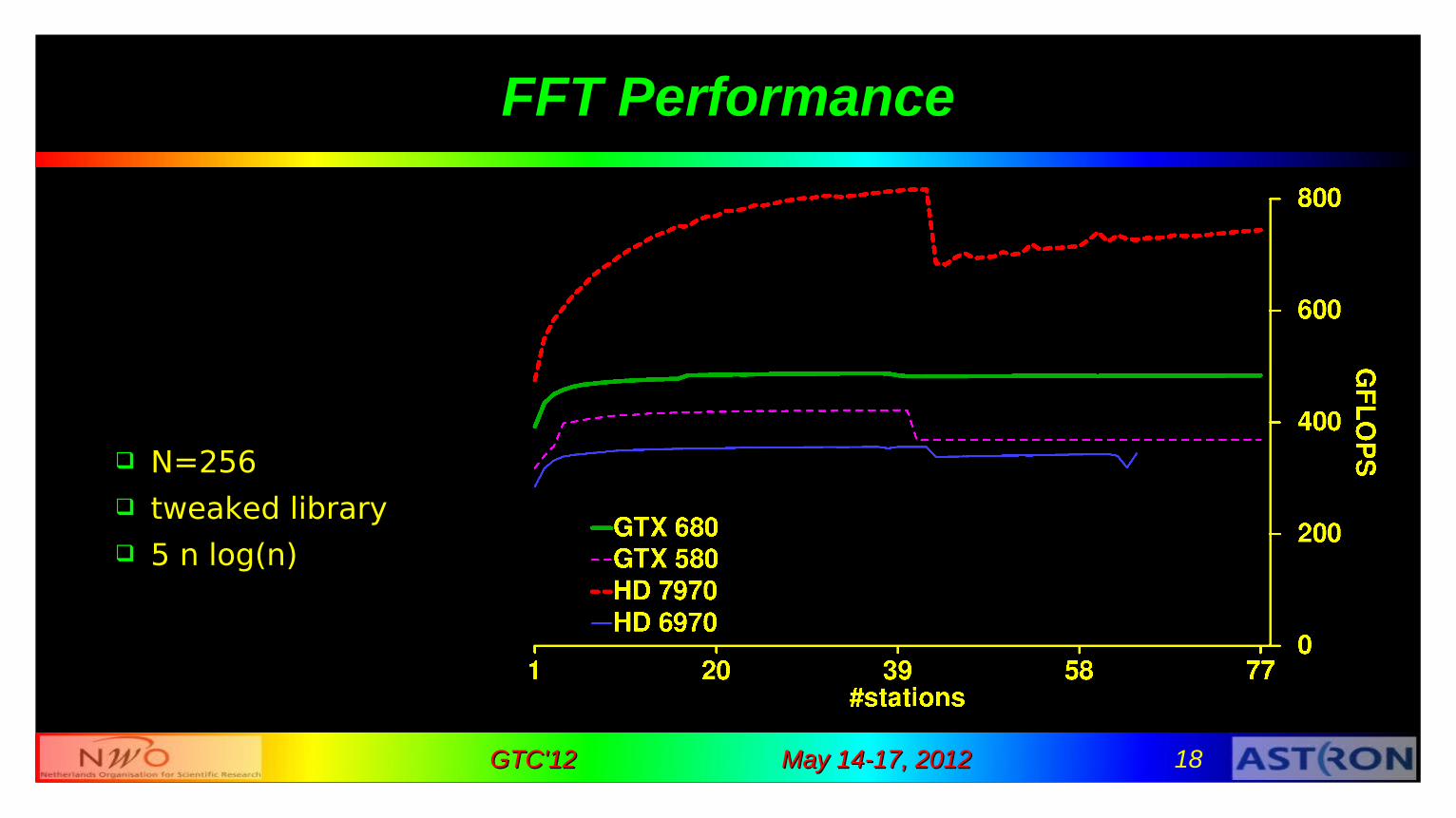
May 14-17, 2012May 14-17, 2012 18GTC'12GTC'12
FFT Performance
N=256 tweaked library 5 n log(n)

May 14-17, 2012May 14-17, 2012 19GTC'12GTC'12
corrects cable length errors merge with next step (phase delay)
Clock Correction
May 14-17, 2012May 14-17, 2012 20GTC'12GTC'12
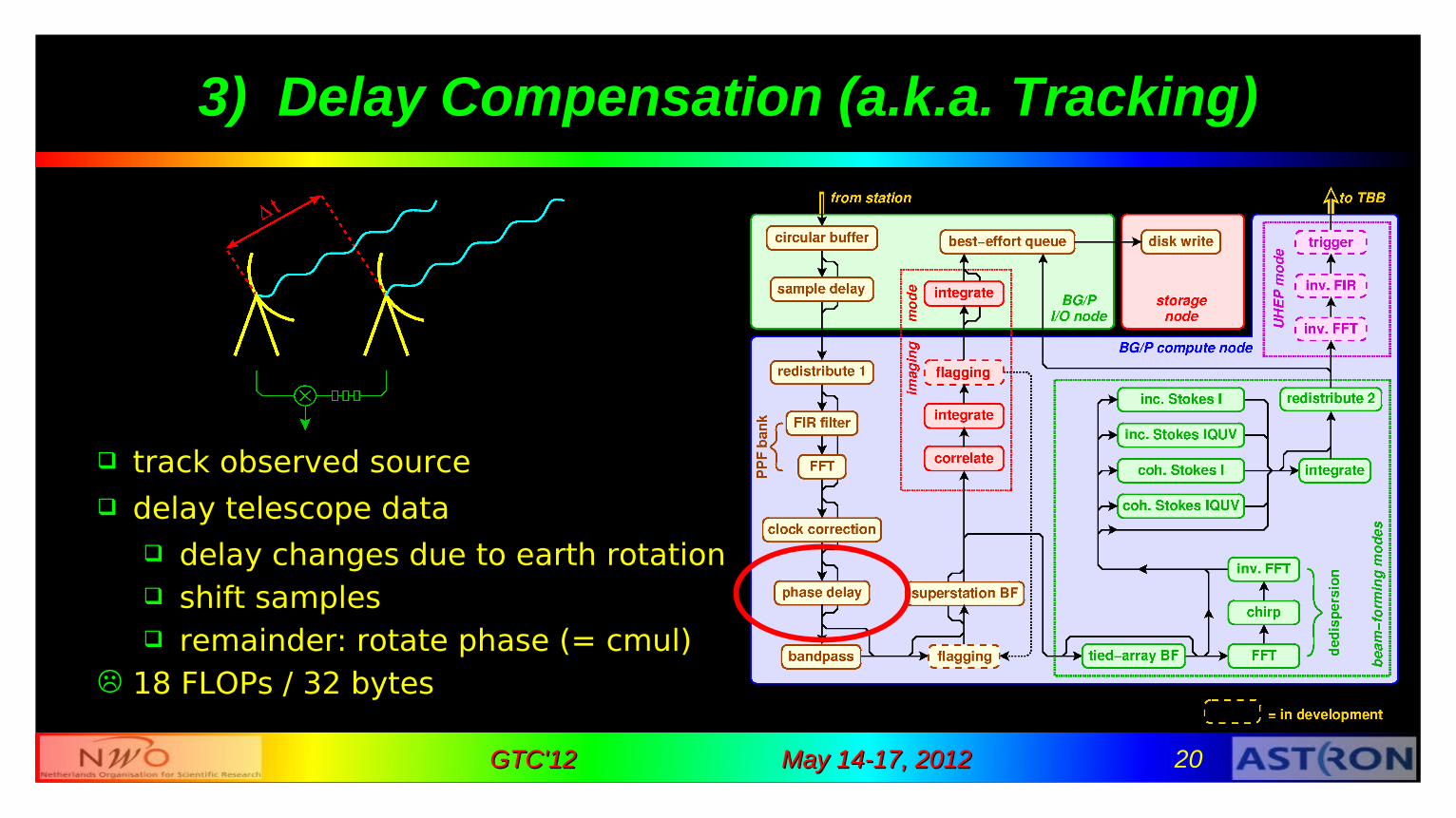
track observed source delay telescope data
delay changes due to earth rotation shift samples remainder: rotate phase (= cmul)
18 FLOPs / 32 bytes
3) Delay Compensation (a.k.a. Tracking)
May 14-17, 2012May 14-17, 2012 21GTC'12GTC'12
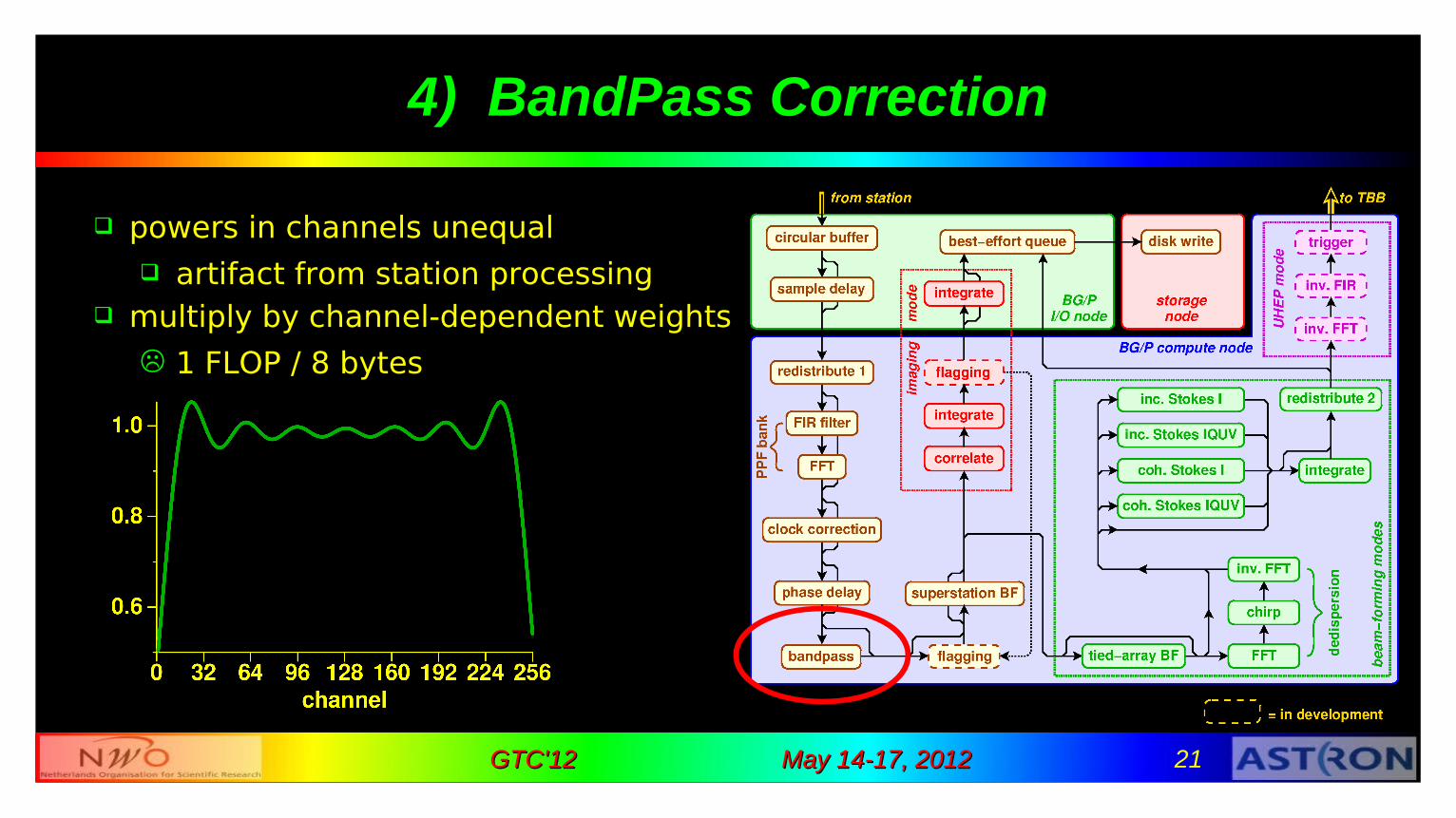
4) BandPass Correction
powers in channels unequal artifact from station processing
multiply by channel-dependent weights
1 FLOP / 8 bytes

May 14-17, 2012May 14-17, 2012 22GTC'12GTC'12
Transpose
reorder data for next step (correlator) through local memory
see talk S0514

May 14-17, 2012May 14-17, 2012 23GTC'12GTC'12
Combined Kernel
combine: delay compensation bandpass correction transpose
reduces global memory accesses
18 FLOPs / 32 bytes

May 14-17, 2012May 14-17, 2012 24GTC'12GTC'12
Delay / Band Pass Performance
poor operational intensity 156 GB/s!

May 14-17, 2012May 14-17, 2012 25GTC'12GTC'12
5) Correlator
see previous talk (S0347) multiply samples from each pair of
stations integrate ~1s

May 14-17, 2012May 14-17, 2012 26GTC'12GTC'12
Correlator Implementation
one thread
global memory ➜ local memory 1 thread: 2x2 stations (dual pol)
4 float4 loads ➜ 64 FMAs 32 accumulator registers

May 14-17, 2012May 14-17, 2012 27GTC'12GTC'12
Correlator #Threads
HD 6970 / HD 7970 need multiple passes!
20
39
58
77
0
256
512
768
1024
#stations
#th
rea
ds
max #threads
GTX 580 1024
GTX 680 1024
HD 6970 256
HD 7970 256

May 14-17, 2012May 14-17, 2012 28GTC'12GTC'12
Correlator Performance
HD 7970: multiple passes register usage ➜ low occupancy
May 14-17, 2012May 14-17, 2012 29GTC'12GTC'12
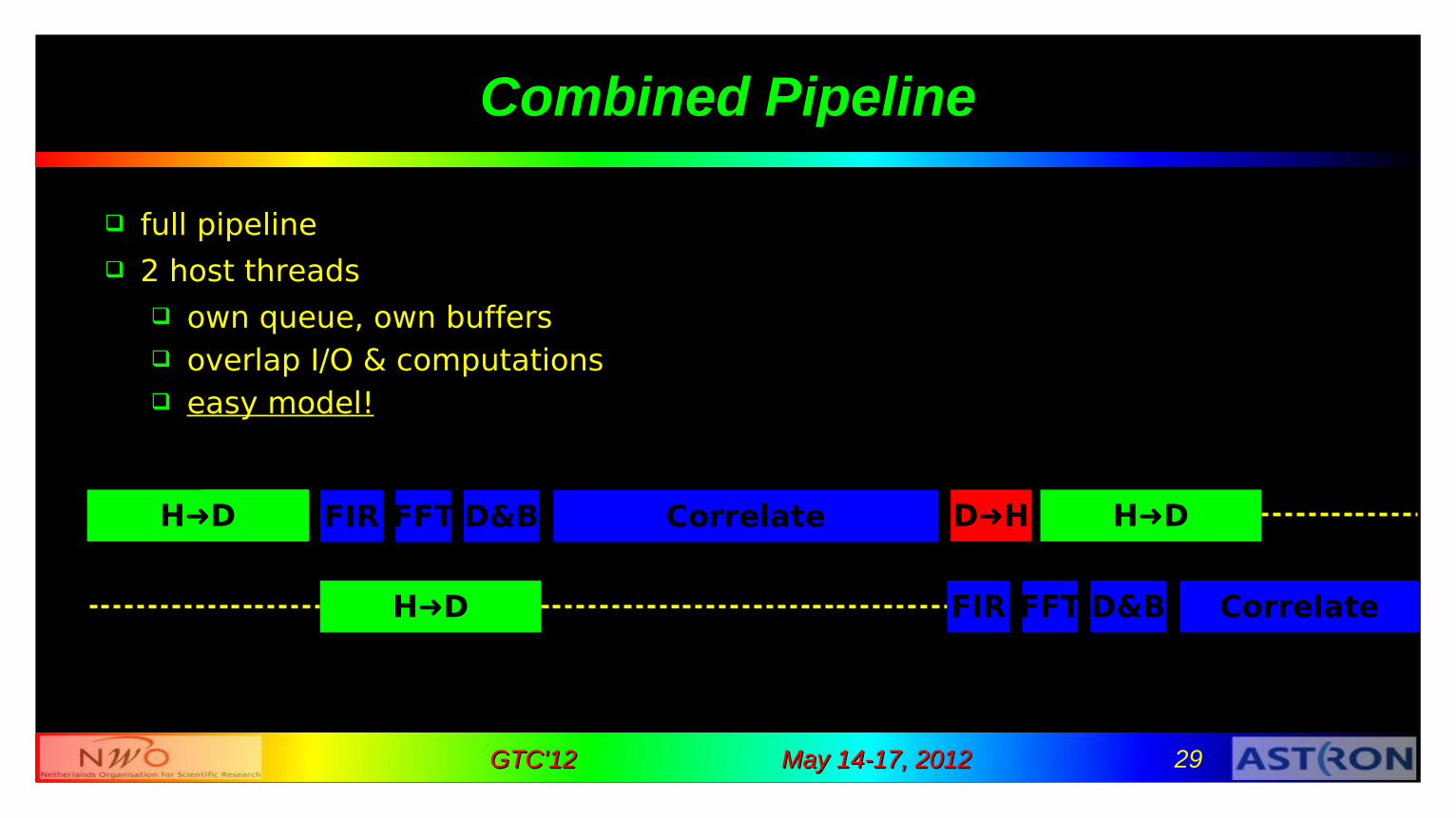
Combined Pipeline
full pipeline 2 host threads
own queue, own buffers overlap I/O & computations easy model!
H➜D FIR
H➜D
H➜D FFT D&B Correlate
FIR FFT D&B Correlate
D➜H H➜D

May 14-17, 2012May 14-17, 2012 30GTC'12GTC'12
Overall Performance Imaging Pipeline
#GPUs needed for LOFAR GTX 680 (marginally) fastest
~13 GPUs HD 7970 real improvement over HD 6970

May 14-17, 2012May 14-17, 2012 31GTC'12GTC'12
Performance Breakdown GTX 580
dominated by correlator correlator: compute bound others: memory I/O bound PCIe I/O overlapped

May 14-17, 2012May 14-17, 2012 32GTC'12GTC'12
Performance Breakdown GTX 680
~20% faster than GTX 580

May 14-17, 2012May 14-17, 2012 33GTC'12GTC'12
Performance Breakdown HD 7970
multiple passes correlator visible poor overlap I/O
May 14-17, 2012May 14-17, 2012 34GTC'12GTC'12
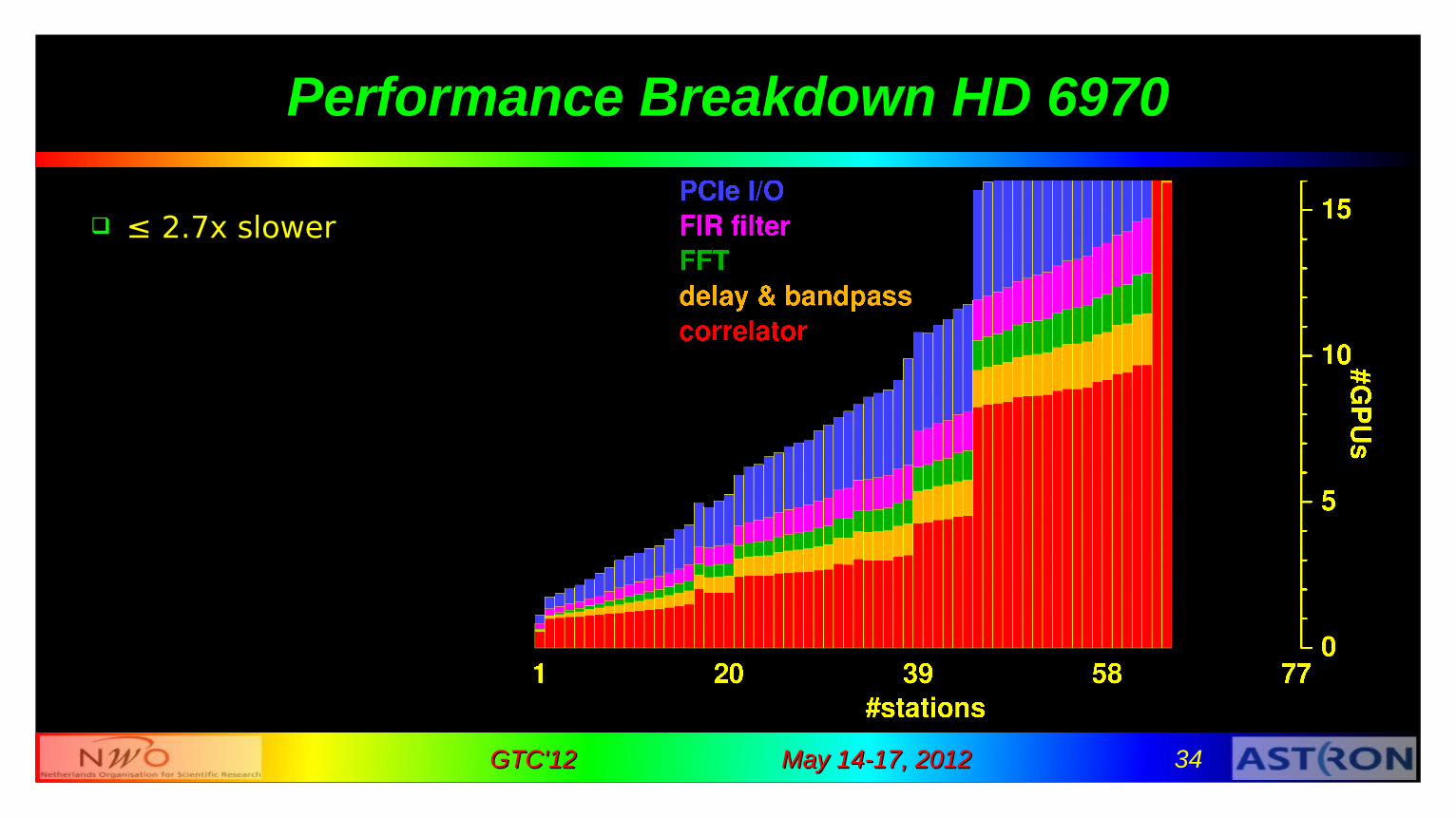
Performance Breakdown HD 6970
≤ 2.7x slower

May 14-17, 2012May 14-17, 2012 35GTC'12GTC'12
Are GPUs Efficient?
Blue Gene/P: better compute-I/O balance & integrated network
few tens of GPUs as powerful as 2 BG/P racks
GTX 680 Blue Gene/P
FIR filter ~21% 85%
FFT ~17% 44%
Delay / BandPass ~2.6% 26%
Correlator ~35% 96%
% of FPU peak performance

May 14-17, 2012May 14-17, 2012 36GTC'12GTC'12
Feasible?
imaging pipeline ~13 GTX 680s (≈ 8 Tesla K10)
+ RFI detection? other pipelines
? 240 Gb/s FDR InfiniBand transpose

May 14-17, 2012May 14-17, 2012 37GTC'12GTC'12
Future Optimizations
combine more kernels fewer passes over global memory FFT: difficult invoke FFT from GPU kernel, not CPU

May 14-17, 2012May 14-17, 2012 38GTC'12GTC'12
Conclusions Part 1
OpenCL ok FFT support = minimal
GTX 680 (Kepler) marginally faster than HD 7970 (GCN)
<35% of FPU peak: memory I/O bottleneck
heavy use of FMA instructions
LOFAR imaging pipeline on GPUs = feasible

May 14-17, 2012May 14-17, 2012 39GTC'12GTC'12
Part 2: Creation of Sky Images

May 14-17, 2012May 14-17, 2012 40GTC'12GTC'12
Context
after observation: remove RFI calibrate create sky imagecreate sky image
calibration/imaging loop possibly repeated

May 14-17, 2012May 14-17, 2012 41GTC'12GTC'12
Creating a Sky Image
convolve correlations and add to convolve correlations and add to ggridrid 2D FFT ➜ sky image

May 14-17, 2012May 14-17, 2012 42GTC'12GTC'12
Gridding
corrconv
grid
(~100x100)
(~4096x4096)
convolve correlation and add to grid for all correlations

May 14-17, 2012May 14-17, 2012 43GTC'12GTC'12
Two Problems
1. lots of FLOPS
2. add to memory: slow!
corrconv
grid
(~100x100)
(~4096x4096)

May 14-17, 2012May 14-17, 2012 44GTC'12GTC'12
Two Solutions
1. lots of FLOPS ➜ use GPUs
2. add to memory: slow! ➜ avoid
corrconv
grid
(~100x100)
(~4096x4096)
May 14-17, 2012May 14-17, 2012 45GTC'12GTC'12
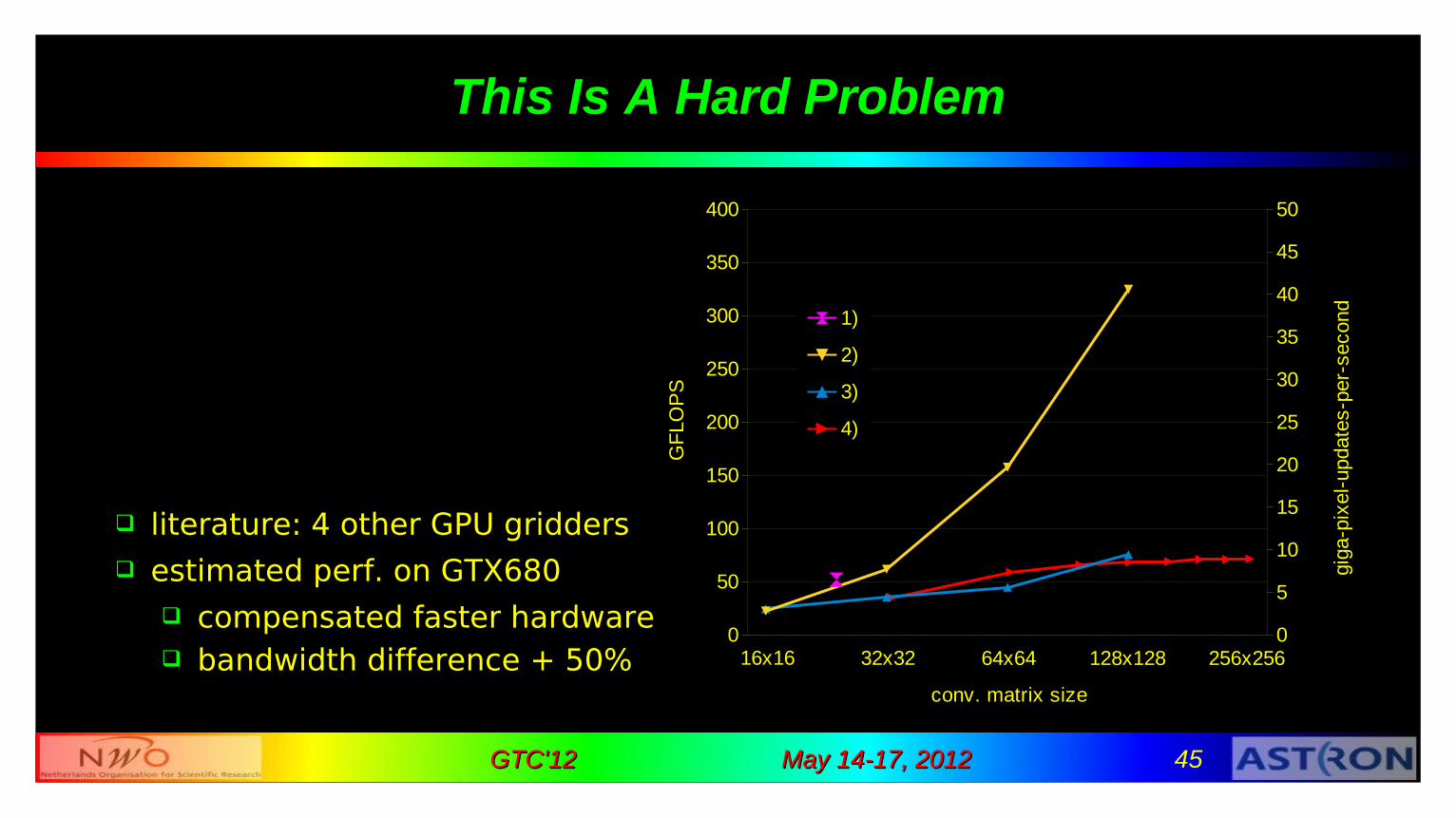
This Is A Hard Problem
literature: 4 other GPU gridders estimated perf. on GTX680
compensated faster hardware bandwidth difference + 50%
0
50
100
150
200
250
300
350
400
0
5
10
15
20
25
30
35
40
45
50
1)
2)
3)
4)
conv. matrix sizeG
FLO
PS
giga
-pix
e l-u
pdat
e s-p
er-s
econ
d
16x16 32x32 64x64 128x128 256x256

May 14-17, 2012May 14-17, 2012 46GTC'12GTC'12
This Is A Hard Problem
1)MWA (Edgar et. al. [CPC'11]) search correlations
2)Cell BE (Varbanescu [PhD,'10]) local store
3)van Amesfoort et. al. [CF'09] private grid per block ➜
very small grids4)Humphreys & Cornwell
[SKA memo 132, '11] adds directly to grid in memory
0
50
100
150
200
250
300
350
400
0
5
10
15
20
25
30
35
40
45
50
1)
2)
3)
4)
conv. matrix sizeG
FLO
PS
giga
-pix
e l-u
pdat
e s-p
er-s
econ
d
16x16 32x32 64x64 128x128 256x256

May 14-17, 2012May 14-17, 2012 47GTC'12GTC'12
This Is A Hard Problem
~3% of FPU peak performance! SKA: exascale
0
50
100
150
200
250
300
350
400
0
5
10
15
20
25
30
35
40
45
50
1)
2)
3)
4)
conv. matrix sizeG
FLO
PS
giga
-pix
e l-u
pdat
e s-p
er-s
econ
d
16x16 32x32 64x64 128x128 256x256

May 14-17, 2012May 14-17, 2012 48GTC'12GTC'12
W-Projection Gridding
correlation has associated (u,v,w) coords (u,v) not exact grid points use different convolution matrices
choose most appropriate one
(int(u), int(v))depends on frac(u), frac(v), w
corrconv
grid
May 14-17, 2012May 14-17, 2012 49GTC'12GTC'12
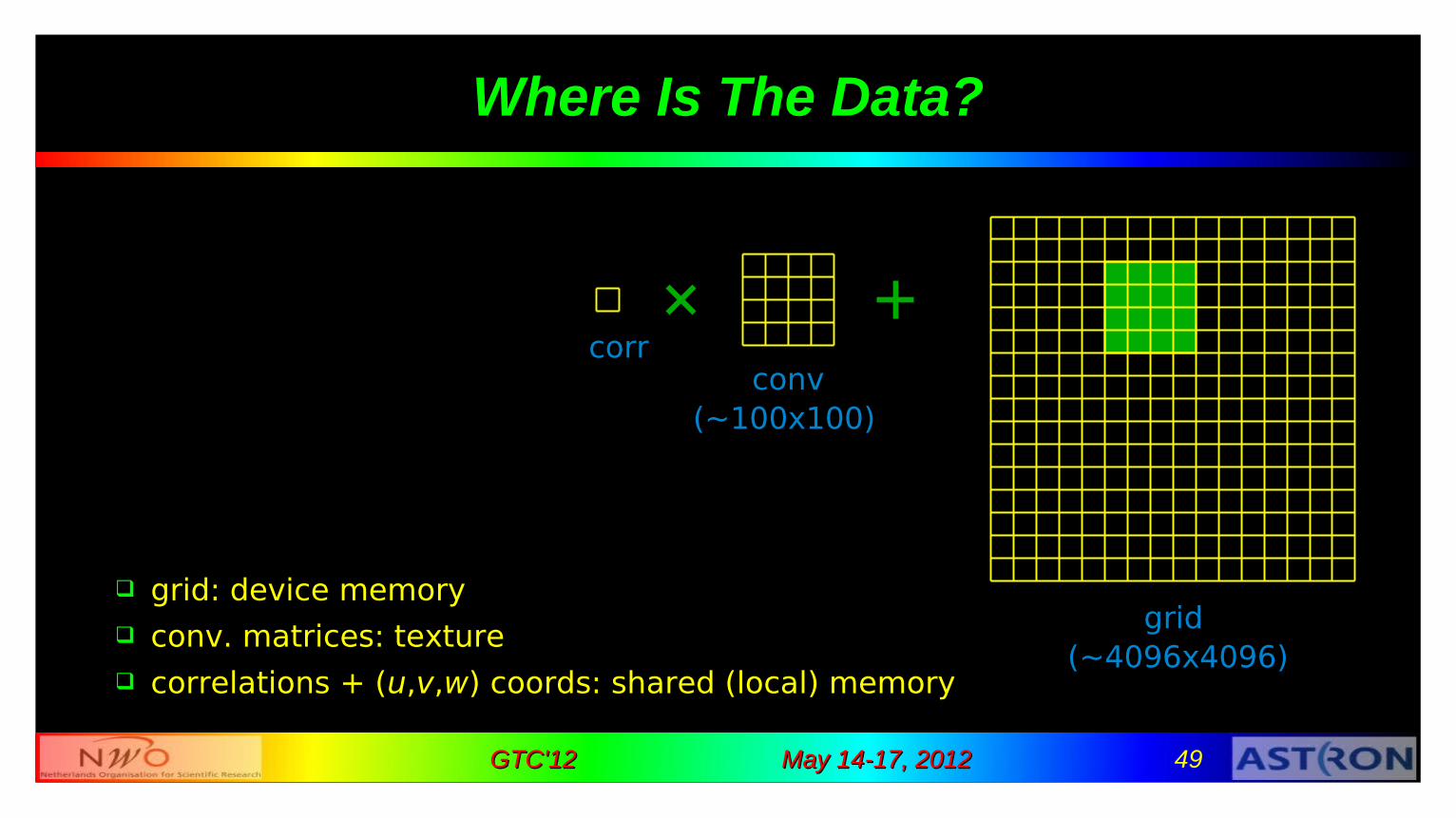
Where Is The Data?
grid: device memory conv. matrices: texture correlations + (u,v,w) coords: shared (local) memory
corrconv
grid
(~100x100)
(~4096x4096)

May 14-17, 2012May 14-17, 2012 50GTC'12GTC'12
Placement Movement
per baseline: (u,v,w) changes slowly grid locality
corrconv
grid
f
t

May 14-17, 2012May 14-17, 2012 51GTC'12GTC'12
Use Locality
reduce #memory accesses X: one thread accumulate additions in register until conv. matrix slides off
corrconv
grid
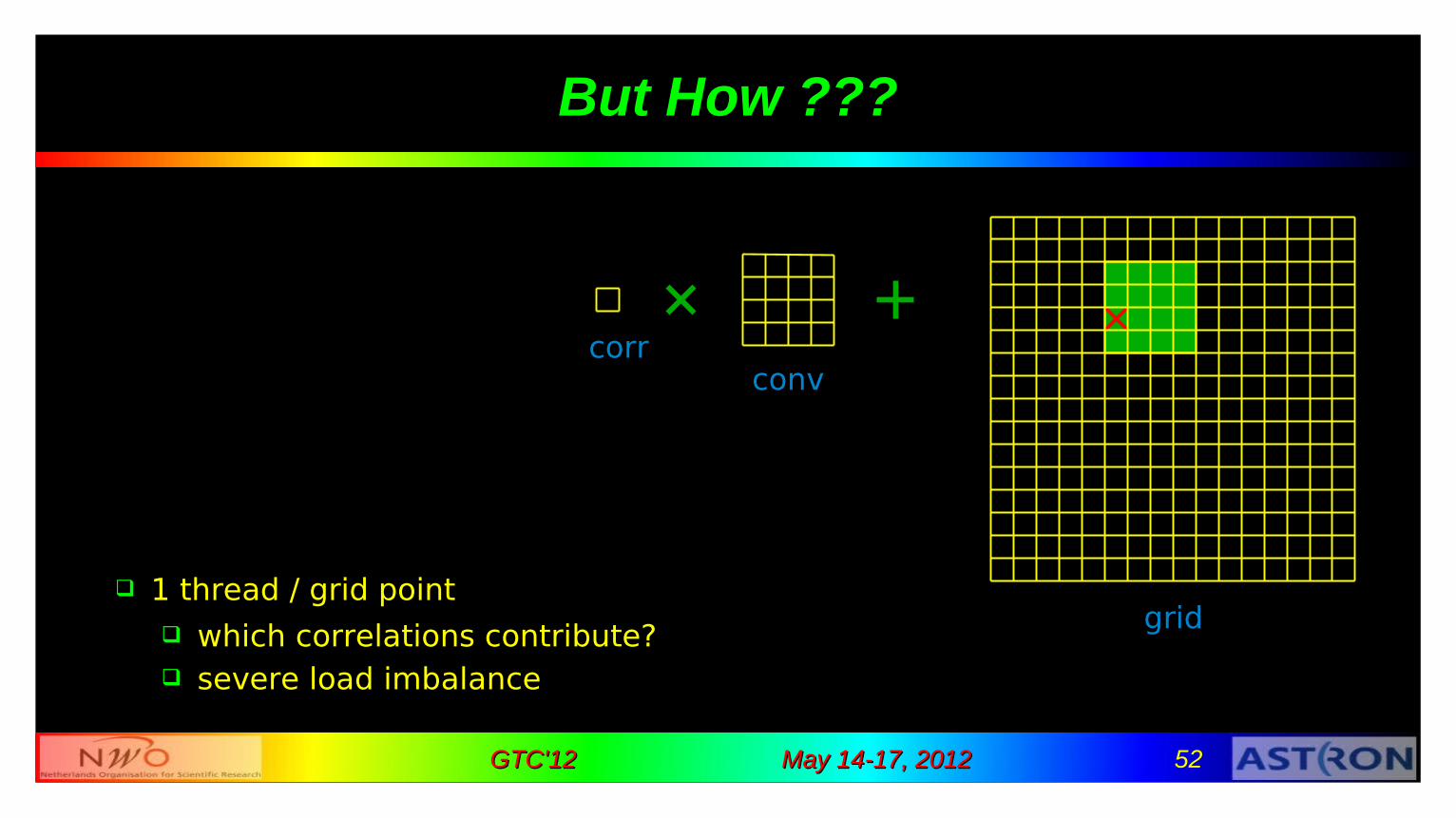
May 14-17, 2012May 14-17, 2012 52GTC'12GTC'12
But How ???
1 thread / grid point which correlations contribute? severe load imbalance
corrconv
grid

May 14-17, 2012May 14-17, 2012 53GTC'12GTC'12
An Unintuitive Approach
conceptual blocks of conv. matrix size
corrconv
grid

May 14-17, 2012May 14-17, 2012 54GTC'12GTC'12
An Unintuitive Approach
1 thread monitors all X at any time: 1 X covers conv. matrix!!!
corrconv
grid

May 14-17, 2012May 14-17, 2012 55GTC'12GTC'12
An Unintuitive Approach
thread computes current: X grid point X conv. matrix entry
corrconv
grid

May 14-17, 2012May 14-17, 2012 56GTC'12GTC'12
An Unintuitive Approach
(u,v) coords change
corrconv
grid

May 14-17, 2012May 14-17, 2012 57GTC'12GTC'12
An Unintuitive Approach
(u,v) coords change more
corrconv
grid

May 14-17, 2012May 14-17, 2012 58GTC'12GTC'12
An Unintuitive Approach
(atomically) adds data if switching to another X
corrconv
grid

May 14-17, 2012May 14-17, 2012 59GTC'12GTC'12
An Unintuitive Approach
#threads = block size too many threads ➜ do in parts
corrconv
grid

May 14-17, 2012May 14-17, 2012 60GTC'12GTC'12
(Dis)Advantages
☹ overhead
☺ < 1% grid-point memory updates
corrconv
grid

May 14-17, 2012May 14-17, 2012 61GTC'12GTC'12
Performance Measurements
May 14-17, 2012May 14-17, 2012 62GTC'12GTC'12
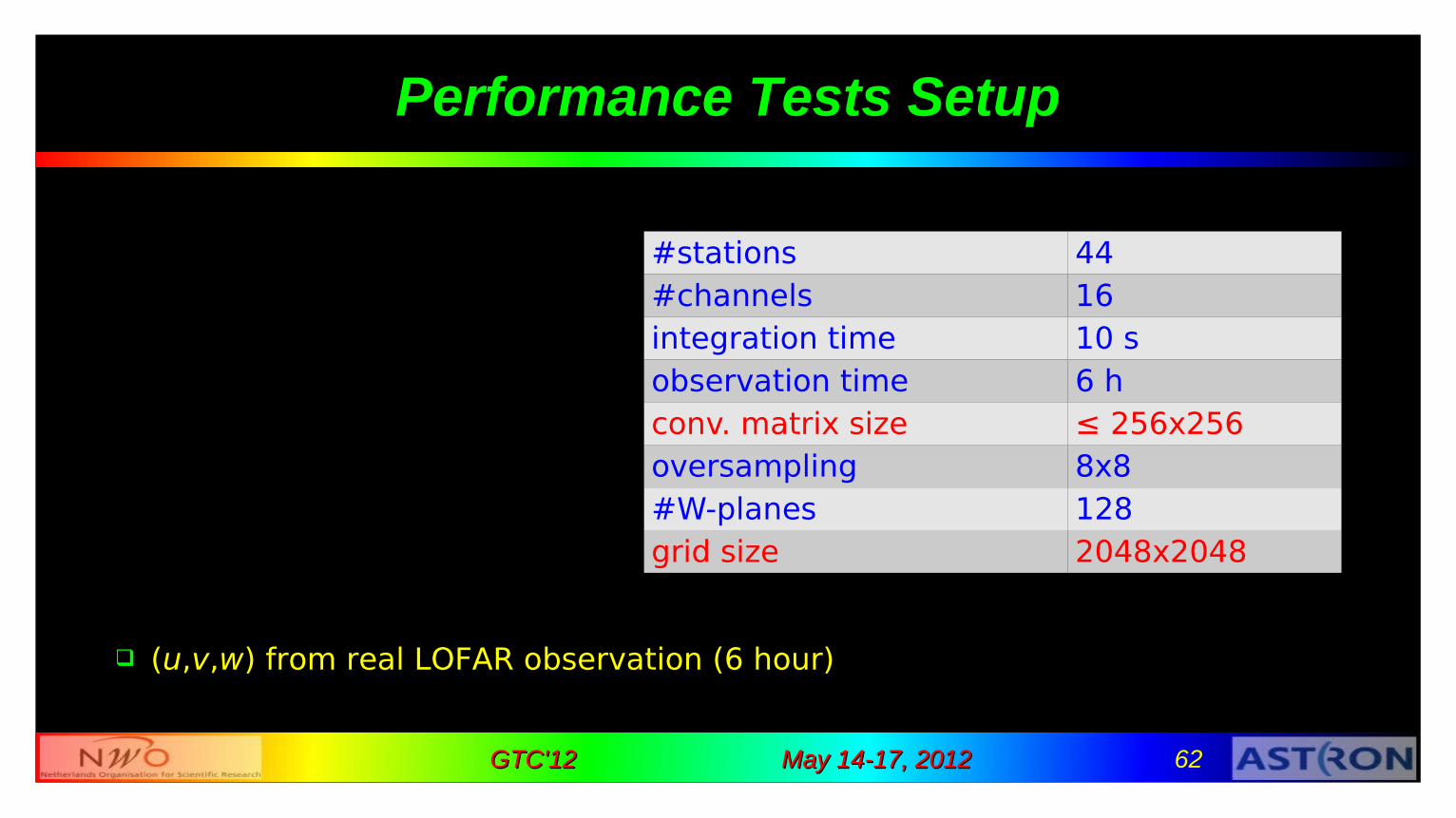
Performance Tests Setup
(u,v,w) from real LOFAR observation (6 hour)
#stations 44#channels 16integration time 10 sobservation time 6 hconv. matrix size ≤ 256x256oversampling 8x8#W-planes 128grid size 2048x2048
May 14-17, 2012May 14-17, 2012 63GTC'12GTC'12
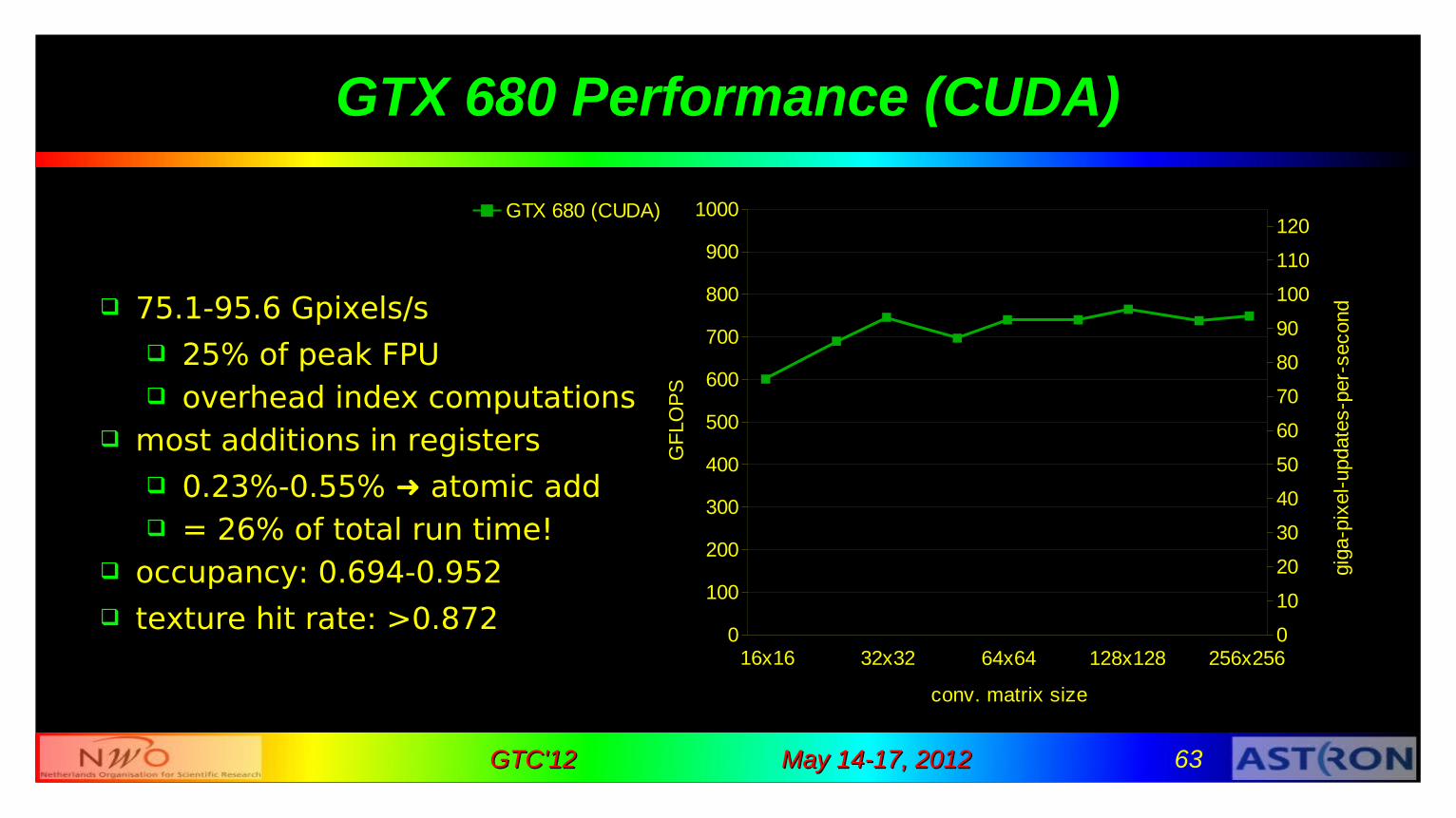
GTX 680 Performance (CUDA)
75.1-95.6 Gpixels/s 25% of peak FPU overhead index computations
most additions in registers 0.23%-0.55% ➜ atomic add = 26% of total run time!
occupancy: 0.694-0.952 texture hit rate: >0.872
0
100
200
300
400
500
600
700
800
900
1000
0
10
20
30
40
50
60
70
80
90
100
110
120GTX 680 (CUDA)
conv. matrix sizeG
FLO
PS
giga
-pix
e l-u
pdat
e s-p
er-s
econ
d
16x16 32x32 64x64 128x128 256x256

May 14-17, 2012May 14-17, 2012 64GTC'12GTC'12
GTX 680 Performance (OpenCL)
OpenCL slower than CUDA no atomic FP add!
use atomic cmpxchg V1.1: no 1D images (added in V1.2)
2D image: slower0
100
200
300
400
500
600
700
800
900
1000
0
10
20
30
40
50
60
70
80
90
100
110
120GTX 680 (CUDA)GTX 680 (OpenCL)
conv. matrix sizeG
FLO
PS
giga
-pix
e l-u
pdat
e s-p
er-s
econ
d
16x16 32x32 64x64 128x128 256x256
May 14-17, 2012May 14-17, 2012 65GTC'12GTC'12
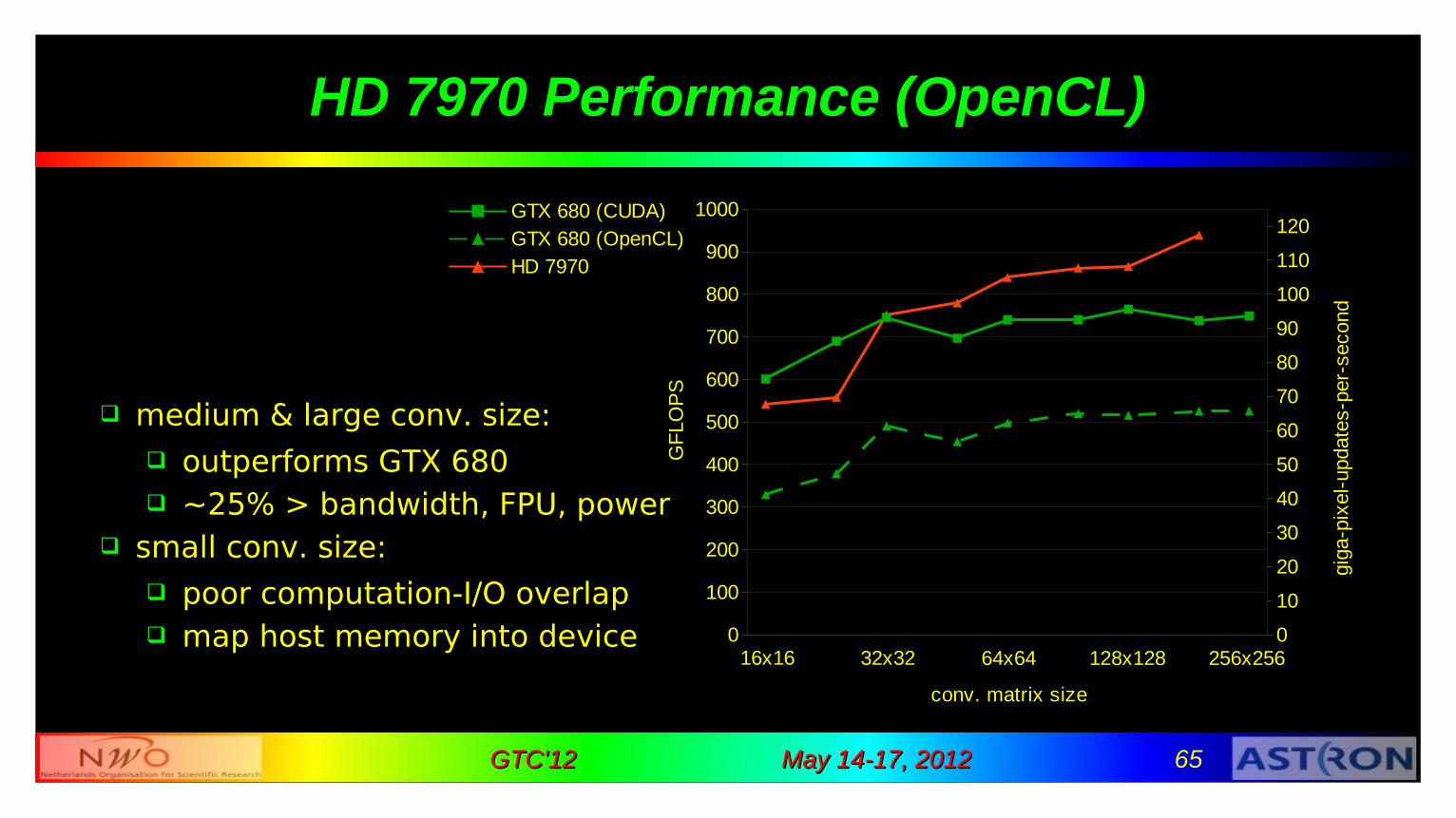
HD 7970 Performance (OpenCL)
medium & large conv. size: outperforms GTX 680 ~25% > bandwidth, FPU, power
small conv. size: poor computation-I/O overlap map host memory into device 0
100
200
300
400
500
600
700
800
900
1000
0
10
20
30
40
50
60
70
80
90
100
110
120GTX 680 (CUDA)GTX 680 (OpenCL)HD 7970
conv. matrix sizeG
FLO
PS
giga
-pix
e l-u
pdat
e s-p
er-s
econ
d
16x16 32x32 64x64 128x128 256x256
May 14-17, 2012May 14-17, 2012 66GTC'12GTC'12
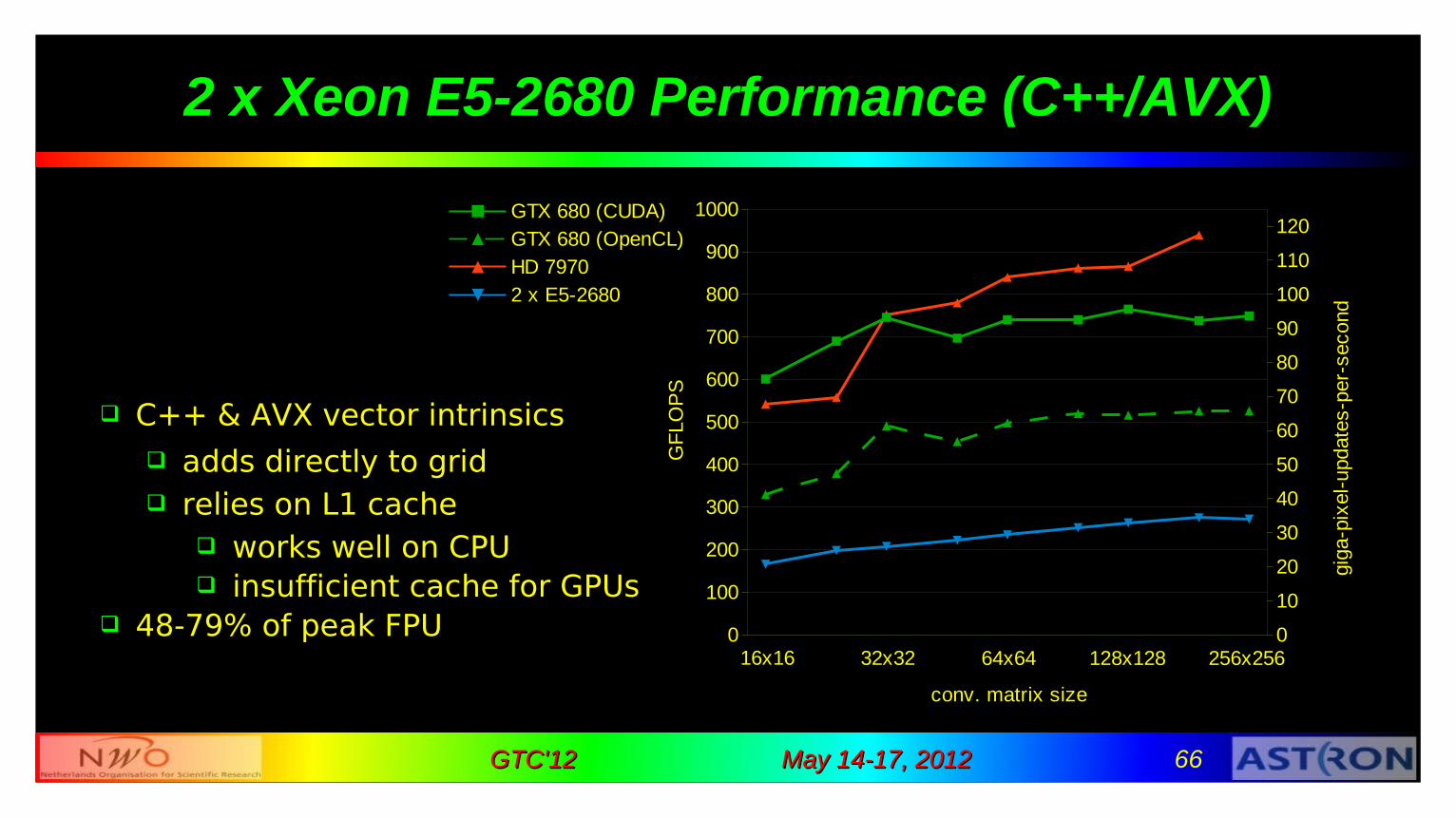
2 x Xeon E5-2680 Performance (C++/AVX)
C++ & AVX vector intrinsics adds directly to grid relies on L1 cache
works well on CPU insufficient cache for GPUs
48-79% of peak FPU 0
100
200
300
400
500
600
700
800
900
1000
0
10
20
30
40
50
60
70
80
90
100
110
120GTX 680 (CUDA)GTX 680 (OpenCL)HD 79702 x E5-2680
conv. matrix sizeG
FLO
PS
giga
-pix
e l-u
pdat
e s-p
er-s
econ
d
16x16 32x32 64x64 128x128 256x256

May 14-17, 2012May 14-17, 2012 67GTC'12GTC'12
Multi-GPU Scaling
eight Nvidia GTX 580s
0 1 2 3 4 5 6 7 80
1000
2000
3000
4000
5000256x256
64x64
16x16
nr. GPUs
GF
LOP
S
131,072 threads! scales well

May 14-17, 2012May 14-17, 2012 68GTC'12GTC'12
Green Computing
up to 1.94 GFLOP/w (with previous gen hardware!)
0 1 2 3 4 5 6 7 80
0.5
1
1.5
2
2.5 256x256
64x64
16x16
nr. GPUs
pow
er c
o nsu
mpt
ion
(kW
)
0 1 2 3 4 5 6 7 80
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
1.8
2
256x256
64x64
16x16
nr. GPUs
pow
er e
f fic
ienc
y (G
FLO
P/W
)

May 14-17, 2012May 14-17, 2012 69GTC'12GTC'12
Compared To Other GPU Gridders
1)MWA (Edgar et. al. [CPC'11])
2)Cell BE (Varbanescu [PhD,'10])
3)van Amesfoort et. al. [CF'09]
4)Humphreys & Cornwell [SKA memo 132, '11]
new method ~10x faster
0
100
200
300
400
500
600
700
800
0
12.5
25
37.5
50
62.5
75
87.5
100
new
1)
2)
3)
4)
conv. matrix sizeG
FLO
PS
giga
-pix
e l-u
pdat
e s-p
er-s
econ
d
16x16 32x32 64x64 128x128 256x256

May 14-17, 2012May 14-17, 2012 70GTC'12GTC'12
See Also
An Efficient Work-Distribution Strategy for Gridding Radio-Telescope Data on GPUs, John W. Romein, ACM International Conference on Supercomputing (ICS'12), June 25-29, 2012, Venice, Italy

May 14-17, 2012May 14-17, 2012 71GTC'12GTC'12
Future Work
LOFAR gridder combine with A-projection time-dependent conv. function ➜ compute on GPU

May 14-17, 2012May 14-17, 2012 72GTC'12GTC'12
Conclusions Part 2
efficient GPU gridding algorithm minimizes memory accesses
OpenCL lacks atomic floating-point add ~10x faster than other gridders
scales well on 8 GPUs energy efficient