serverless data architecture at scale on google cloud platform - lorenzo ridi - codemotion milan...
TRANSCRIPT

Serverless Data Architecture at scale on Google Cloud PlatformLorenzo Ridi
MILAN 25-26 NOVEMBER 2016

What’s the date today?


Black Friday (ˈblæk fraɪdɪ)noun
The day following Thanksgiving Day in the United States. Since 1932, it
has been regarded as the beginning of the Christmas shopping season.

Black Friday in the US
2012 - 2016
source: Google Trends, November 23rd 2016

Black Friday in Italy2012 - 2016
source: Google Trends, November 23rd 2016

What are we doing
Processing + analytics
Tweets about black friday
insights
$$Hashtags(blackfriday, blackfriday2016)Brands & vendors(walmart, bestbuy)
Negative Hashtags(notonedime, blackoutblackfriday)

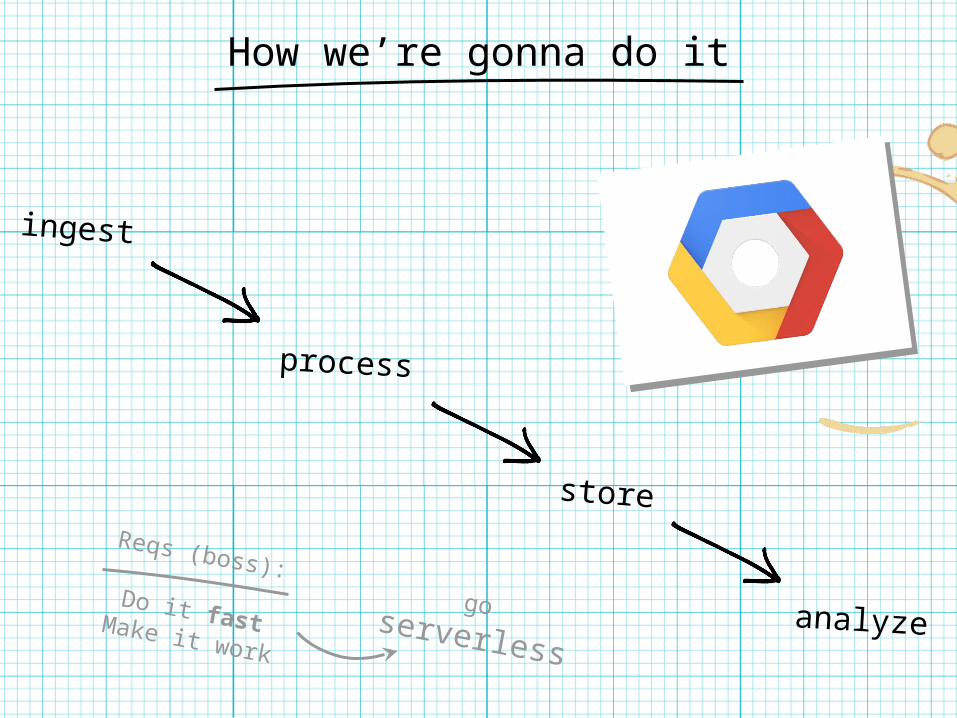
ingest
process
store
analyze
How we’re gonna do it
Reqs (boss):Do it fastMake it work
process
store
analyze
How we’re gonna do it
Reqs (boss):Do it fastMake it work
goserverless
ingest

process
store
analyze
Pub/Sub
Container Engine
(Kubernetes)
How we’re gonna do it
Reqs (boss):Do it fastMake it work
goserverless

What is Google Cloud Pub/Sub?
● Google Cloud Pub/Sub is a fully-managed real-time messaging service.
○ Guaranteed delivery■ “At least once” semantics
○ Reliable at scale■ Messages are replicated in
different zones

From Twitter to Pub/Sub
$ gcloud beta pubsub topics create blackfridaytweetsCreated topic [blackfridaytweets].
SHELL

From Twitter to Pub/Sub
?Pub/Sub Topic
Subscription A
Subscription B
Subscription C
Consumer A
Consumer B
Consumer C
Reliable AND scalable deliveryDecouples
producer and
consumer(s)
Absorbs shocks and changes

From Twitter to Pub/Sub
● Simple Python application using the TweePy library
# somewhere in the code, track a given set of keywordsstream = Stream(auth, listener)stream.filter(track=['blackfriday', [...]])
[...]
# somewhere else, write messages to Pub/Subfor line in data_lines: pub = base64.urlsafe_b64encode(line) messages.append({'data': pub})body = {'messages': messages}resp = client.projects().topics().publish( topic='blackfridaytweets', body=body).execute(num_retries=NUM_RETRIES)
PYTHON
This is our Pub/Sub topic

From Twitter to Pub/Sub
App+
Libs

VM
From Twitter to Pub/Sub
App+
Libs

VM
From Twitter to Pub/Sub
App+
Libs
doesn’tscale
hard to make
fault-tolerant
difficult todeploy & update

From Twitter to Pub/Sub
App+
Libs Container

From Twitter to Pub/Sub
App+
Libs Container
FROM google/python
RUN pip install --upgrade pipRUN pip install pyopenssl ndg-httpsclient pyasn1RUN pip install tweepyRUN pip install --upgrade google-api-python-clientRUN pip install python-dateutil
ADD twitter-to-pubsub.py /twitter-to-pubsub.pyADD utils.py /utils.py
CMD python twitter-to-pubsub.py
DOCKERFILE
install/updatelibs
execute script
copy scripts

From Twitter to Pub/Sub
App+
Libs Container
From Twitter to Pub/Sub
App+
Libs Container Pod

What is Kubernetes (K8S)?
● An orchestration tool for managing a cluster of containers across multiple hosts○ Scaling, rolling upgrades, A/B
testing, etc.
● Declarative – not procedural○ Auto-scales and self-heals to desired
state
● Supports multiple container runtimes, currently Docker and CoreOS Rkt
● Open-source: github.com/kubernetes
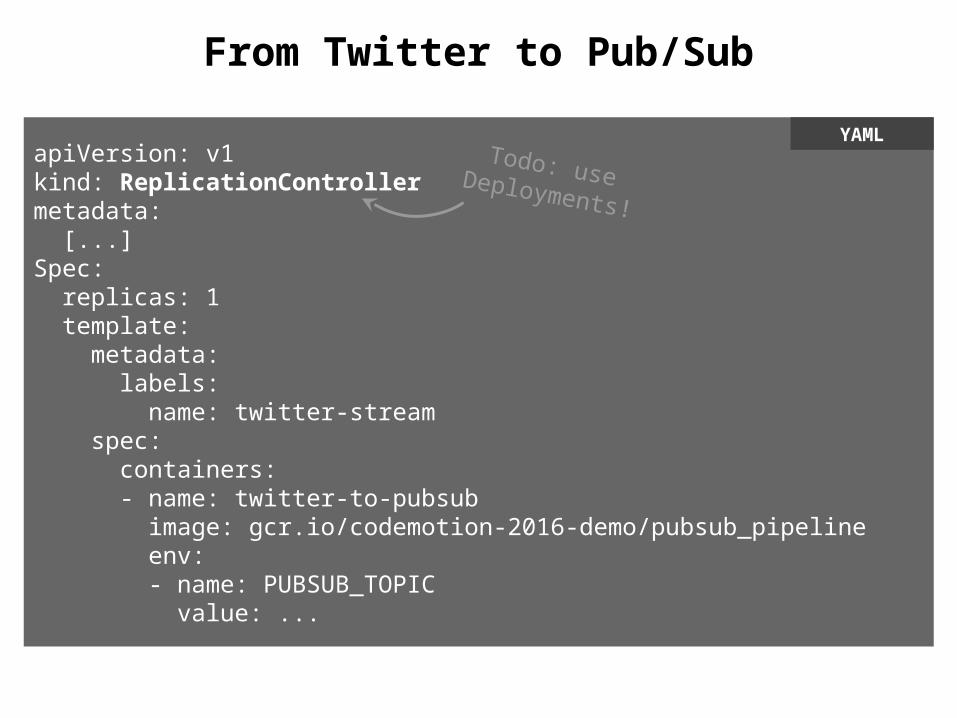
From Twitter to Pub/Sub
App+
Libs Container Pod
apiVersion: v1kind: ReplicationControllermetadata: [...]Spec: replicas: 1 template: metadata: labels: name: twitter-stream spec: containers: - name: twitter-to-pubsub image: gcr.io/codemotion-2016-demo/pubsub_pipeline env: - name: PUBSUB_TOPIC value: ...
YAMLTodo: use Deployments!

From Twitter to Pub/Sub
App+
Libs Container Pod

From Twitter to Pub/Sub
App+
Libs Container Pod Node

Node
From Twitter to Pub/Sub
Pod A Pod B
Container Engine manages the K8S master for us!
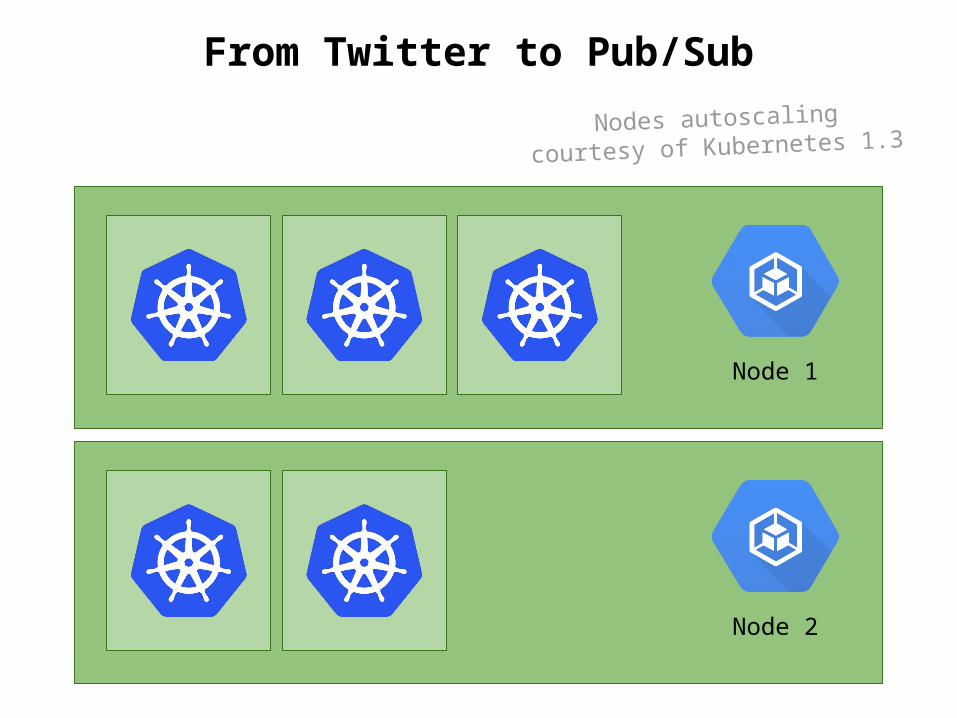
From Twitter to Pub/Sub
Node 1
Node 2
Nodes autoscalingcourtesy of Kubernetes 1.3

From Twitter to Pub/Sub
$ gcloud container clusters create codemotion-2016-demo-clusterCreating cluster cluster-1...done.Created [...projects/codemotion-2016-demo/.../clusters/codemotion-2016-demo-cluster].
$ gcloud container clusters get-credentials codemotion-2016-demo-clusterFetching cluster endpoint and auth data.kubeconfig entry generated for cluster-1.
$ kubectl create -f ~/git/kube-pubsub-bq/pubsub/twitter-stream.yamlreplicationcontroller “twitter-stream” created.
SHELL


process
store
analyze
Pub/Sub
Kubernetes
How we’re gonna do it
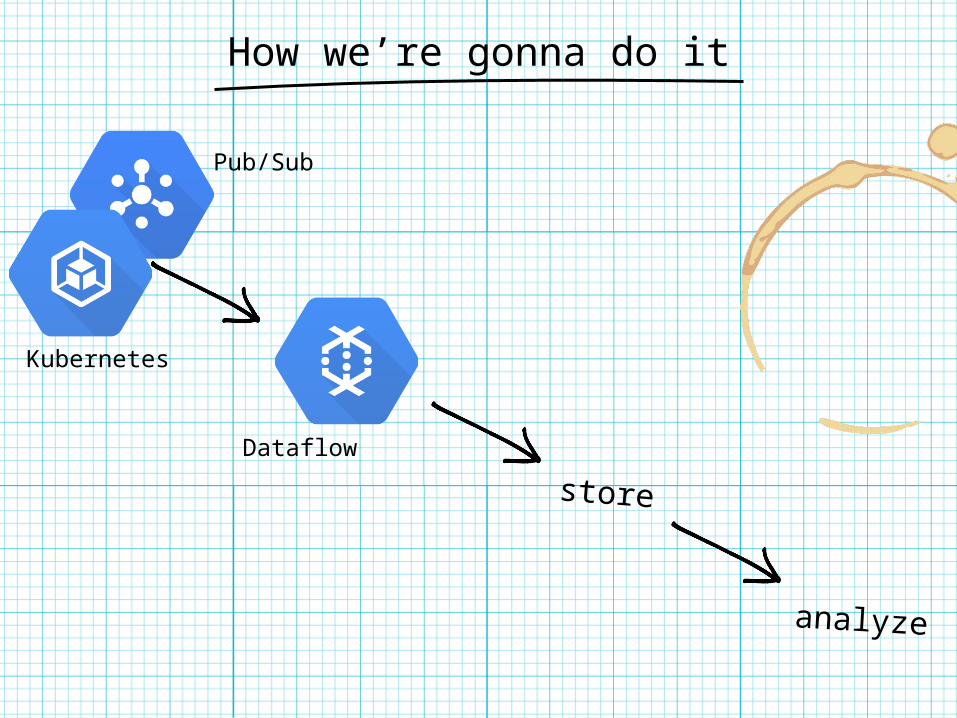
store
analyze
Pub/Sub
Kubernetes
Dataflow
How we’re gonna do it

analyze
Pub/Sub
Kubernetes
DataflowBigQuery
How we’re gonna do it

What is Google Cloud Dataflow?
● Cloud Dataflow is a collection of open source SDKs to implement parallel processing pipelines.○ same programming model
for streaming and batch pipelines
● Cloud Dataflow is a managed service to run parallel processing pipelines on Google Cloud Platform
Apache Beam

What is Google BigQuery?
● Google BigQuery is a fully-managed Analytic Data Warehouse solution allowing real-time analysis of Petabyte-scale datasets.
● Enterprise-grade features○ Batch and streaming (100K
rows/sec) data ingestion○ JDBC/ODBC connectors○ Rich SQL-2011-compliant
query language○ Supports updates and
deletesnew!
new!

From Pub/Sub to BigQuery
Pub/Sub Topic
Subscription
Read tweets from
Pub/Sub
Format tweets for BigQuery
Write tweets on BigQuery
BigQuery Table
Dataflow Pipeline

From Pub/Sub to BigQuery
● A Dataflow pipeline is a Java program.
// TwitterProcessor.java
public static void main(String[] args) {
Pipeline p = Pipeline.create();
PCollection<String> tweets = p.apply(PubsubIO.Read.topic("...blackfridaytweets"));
PCollection<TableRow> formattedTweets = tweets.apply(ParDo.of(new DoFormat()));
formattedTweets.apply(BigQueryIO.Write.to(tableReference));
p.run();
}
JAVA
Reads from Pub/Sub
Writes on BigQuery
Transforms each tweet (json) in a BigQuery record
(python too!)

From Pub/Sub to BigQuery
● A Dataflow pipeline is a Java program.
// TwitterProcessor.java
// Do Function (to be used within a ParDo)private static final class DoFormat extends DoFn<String, TableRow> { private static final long serialVersionUID = 1L;
@Override public void processElement(DoFn<String, TableRow>.ProcessContext c) { c.output(createTableRow(c.element())); }}
// Helper methodprivate static TableRow createTableRow(String tweet) throws IOException { return JacksonFactory.getDefaultInstance().fromString(tweet, TableRow.class);}
JAVA
(python too!)
Input elementWrite output

From Pub/Sub to BigQuery
● Use Maven to build, deploy or update the Pipeline.
$ mvn compile exec:java -Dexec.mainClass=it.noovle.dataflow.TwitterProcessor-Dexec.args="--streaming"
[...]
INFO: To cancel the job using the 'gcloud' tool, run:> gcloud alpha dataflow jobs --project=codemotion-2016-demo cancel 2016-11-19_15_49_53-5264074060979116717[INFO] ------------------------------------------------------------------------[INFO] BUILD SUCCESS[INFO] ------------------------------------------------------------------------[INFO] Total time: 18.131s[INFO] Finished at: Sun Nov 20 00:49:54 CET 2016[INFO] Final Memory: 28M/362M[INFO] ------------------------------------------------------------------------
SHELL

From Pub/Sub to BigQuery
● You can monitor your pipelines from Cloud Console.
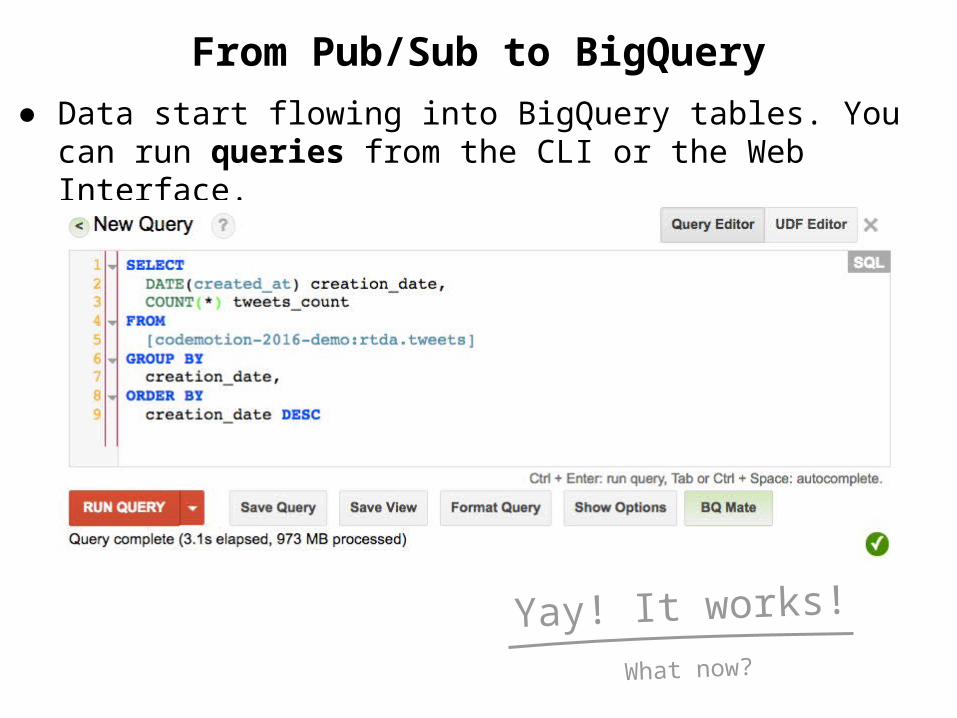
From Pub/Sub to BigQuery● Data start flowing into BigQuery tables. You can run
queries from the CLI or the Web Interface.
Yay! It works!What now?

analyze
Pub/Sub
Kubernetes
DataflowBigQuery
How we’re gonna do it

Pub/Sub
Kubernetes
DataflowBigQuery
DataStudio
How we’re gonna do it

Pub/Sub
Kubernetes
DataflowBigQuery
How we’re gonna do it
enrich
DataStudio
Add magic here

Pub/Sub
Kubernetes
DataflowBigQuery
How we’re gonna do it
Natural Language
API
DataStudio

Sentiment Analysis with Natural Language API
Polarity: [-1,1]
Magnitude: [0,+inf)
Text

Sentiment Analysis with Natural Language API
Polarity: [-1,1]
Magnitude: [0,+inf)
Text
sentiment = polarity x magnitude
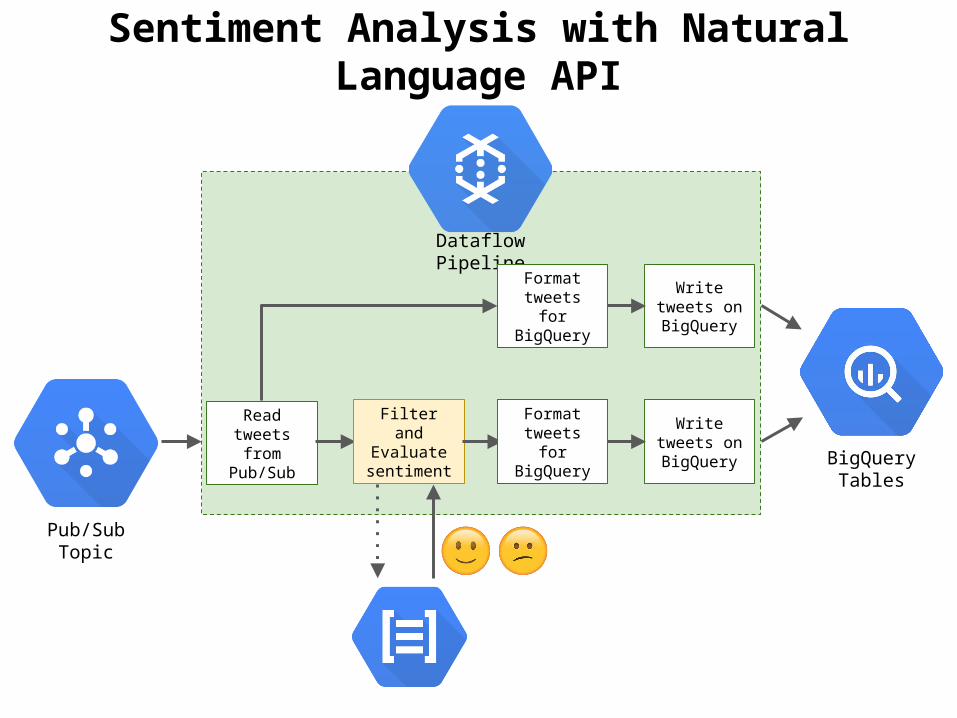
Sentiment Analysis with Natural Language API
Pub/Sub Topic
Read tweets from
Pub/Sub
Write tweets on BigQuery BigQuery
Tables
Dataflow Pipeline
Filter and Evaluate
sentiment
Format tweets for BigQuery
Write tweets on BigQuery
Format tweets for BigQuery
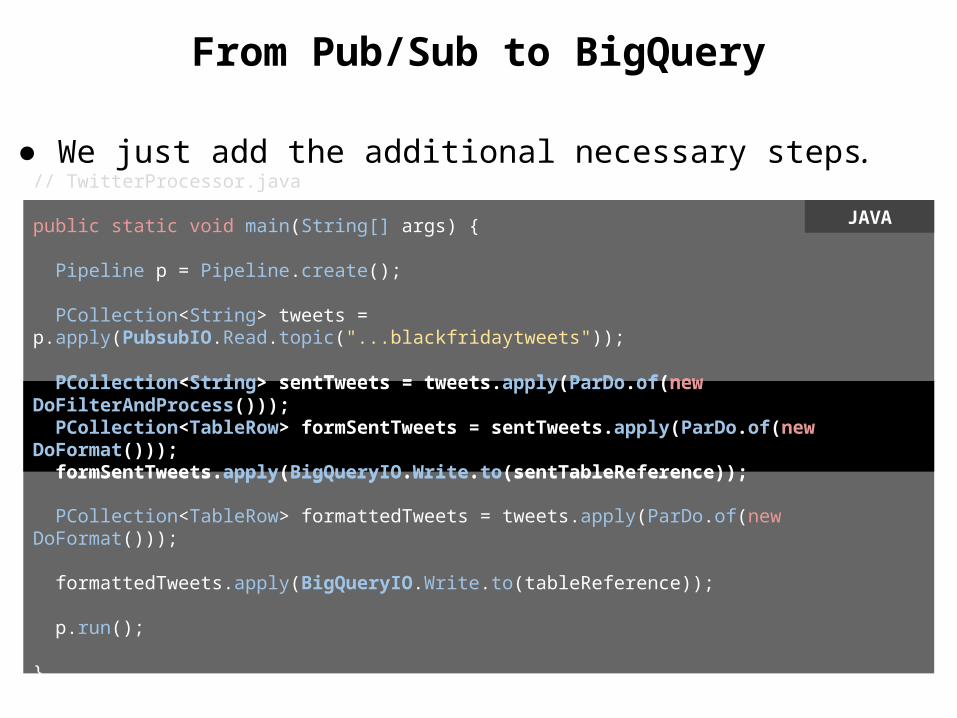
From Pub/Sub to BigQuery
● We just add the additional necessary steps.// TwitterProcessor.java
public static void main(String[] args) {
Pipeline p = Pipeline.create();
PCollection<String> tweets = p.apply(PubsubIO.Read.topic("...blackfridaytweets"));
PCollection<String> sentTweets = tweets.apply(ParDo.of(new DoFilterAndProcess())); PCollection<TableRow> formSentTweets = sentTweets.apply(ParDo.of(new DoFormat())); formSentTweets.apply(BigQueryIO.Write.to(sentTableReference));
PCollection<TableRow> formattedTweets = tweets.apply(ParDo.of(new DoFormat()));
formattedTweets.apply(BigQueryIO.Write.to(tableReference));
p.run();
}
JAVA
PCollection<String> sentTweets = tweets.apply(ParDo.of(new DoFilterAndProcess())); PCollection<TableRow> formSentTweets = sentTweets.apply(ParDo.of(new DoFormat())); formSentTweets.apply(BigQueryIO.Write.to(sentTableReference));

From Pub/Sub to BigQuery
● The update process preserves all in-flight data.
$ mvn compile exec:java -Dexec.mainClass=it.noovle.dataflow.TwitterProcessor-Dexec.args="--streaming --update --jobName=twitterprocessor-lorenzo-
1107222550"
[...]
INFO: To cancel the job using the 'gcloud' tool, run:> gcloud alpha dataflow jobs --project=codemotion-2016-demo cancel 2016-11-19_15_49_53-5264074060979116717[INFO] ------------------------------------------------------------------------[INFO] BUILD SUCCESS[INFO] ------------------------------------------------------------------------[INFO] Total time: 18.131s[INFO] Finished at: Sun Nov 20 00:49:54 CET 2016[INFO] Final Memory: 28M/362M[INFO] ------------------------------------------------------------------------
SHELL

From Pub/Sub to BigQuery

Pub/Sub
Kubernetes
DataflowBigQuery
DataStudio
We did it!
Natural Language
API

Pub/Sub
Kubernetes
DataflowBigQuery
DataStudio
We did it!
Natural Language
API
“To serve and protect”

Live demo

Polarity: -1.0Magnitude: 1.5
Polarity: -1.0Magnitude: 2.1
Open on Thursday? Bad idea..
Beta test your deals!

Thank you!