sequential data modeling - ahcweb01.naist.jp goals a the aim of this course is tolearn basic...
TRANSCRIPT

AugmentedHumanCommunicationLaboratoryGraduateSchoolofInformationScience
SequentialDataModeling
TomokiTodaGrahamNeubigSakriani Sakti

CourseGoals
a
Theaimofthiscourseisto learnbasicknowledgeofsequentialdatamodelingtechniques thatcanbeappliedtosequentialdatasuchasspeechsignals,biologicalsignals,videosofmovingobjects,ornaturallanguagetext.Inparticular,itwillfocusondeepeningknowledgeofmethodsbasedonprobabilisticmodels,suchashiddenMarkovmodelsorlineardynamicalsystems.

CreditsandGrading
b
• 1creditcourse
• Scorewillbegradedby• Assignmentreportineveryclass
• Prerequisites• FundamentalMathematicsforOptimization(最適化数学基礎)• Calculus(微分積分学)• BasicDataAnalysis(データ解析基礎)

Materials
c
• Textbook• Thereisnotextbookforthiscourse.
• Lectureslides• Handoutwillbedistributedineachclass.• PDFslidesareavailabefrom
http://ahclab.naist.jp/lecture/2016/sdm/index.html(internalaccessonly)
• Referencematerials• C.M.Bishop:PatternRecognitionandMachineLearning,SpringerScience+
BusinessMedia,LLC,2006• C.M.ビショップ(著)、元田、栗田、樋口、松本、村田(訳):パターン認識と機械学習 上・下、シュプリンガー・ジャパン、2008

OfficeHours
d
• NAISTLecturers: GrahamNeubig,Sakriani SaktiAugmentedHumanCommunicationLaboratory
• Office: B714• Officehour: byappointment(sendanemailfirst)• Email: [email protected],[email protected]
• OtherContact• TomokiToda
• Email:[email protected]

TAMembers Email:[email protected]
e
• Rui Hiraoka [email protected]• YokoIshikawa [email protected]
Hiraoka-kun Ishikawa-san

Schedule
f
• 1st slotoneveryFriday9:20-10:50 inroomL1
Sun Mon Tue Wed Thu Fri Sat
1 2 3 4
5 6 7 8 9 10 11
12 13 14 15 16 17 18
19 20 21 22 23 24 25
26 27 28 29 30
Sun Mon Tue Wed Thu Fri Sat
1 2
3 4 5 6 7 8 9
10 11 12 13 14 15 16
17 18 19 20 21 22 23
24 25 26 27 28 29 30
31 1
June July/August

Syllabus
g
Date Course description Lecturer6/03 Basicsofsequentialdatamodeling1 GrahamNeubig6/10 Basics ofsequentialdatamodeling2 GrahamNeubig6/17 Discretelatentvariablemodels1 TomokiToda6/24 Discrete latentvariablemodels2 TomokiToda7/1 Continuouslatentvariablemodels1 TomokiToda7/15 Discriminativemodelsforsequentiallabeling1 Sakriani Sakti7/29 Continuouslatentvariablemodels2 TomokiToda8/1 Discriminativemodelsforsequentiallabeling2 Sakriani Sakti
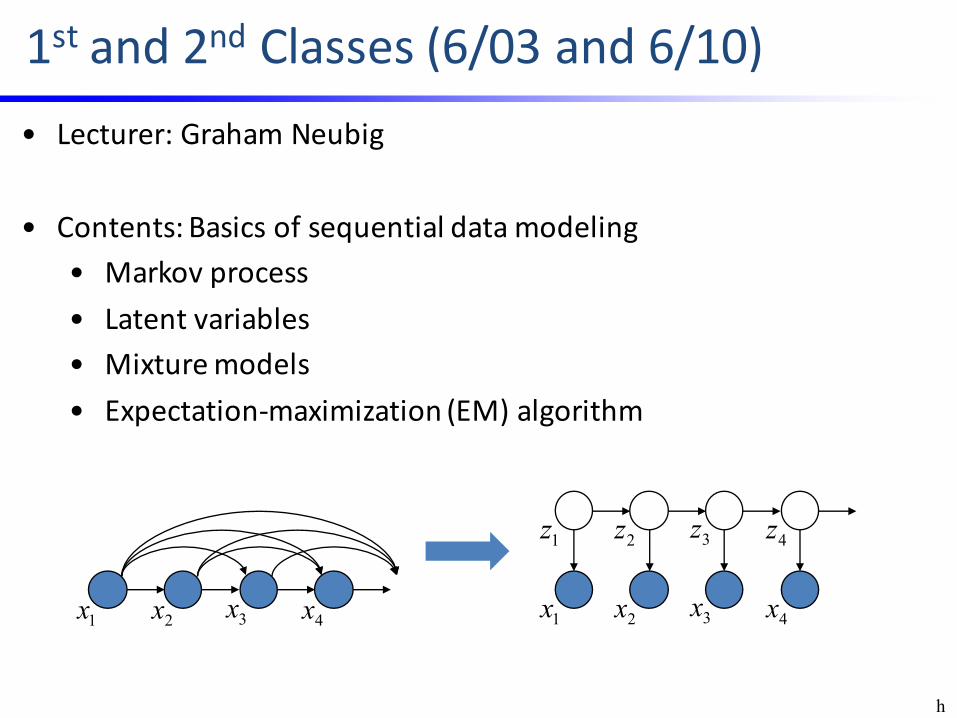
1st and2nd Classes(6/03and6/10)
h
• Lecturer:GrahamNeubig
• Contents:Basicsofsequentialdatamodeling• Markovprocess• Latentvariables• Mixturemodels• Expectation-maximization(EM)algorithm
1z 2z 3z 4z
1x 2x 3x 4x1x 2x 3x 4x

3rd and4th Classes(6/17and6/24)
i
• Lecturer:TomokiToda
• Contents:Discretelatentvariablemodels• HiddenMarkovmodels• Forward-backwardalgorithm• Viterbi algorithm• Trainingalgorithm
1
3 21 2 3/s/

5th and7th Classes(7/1 and7/29)
k
• Lecturer:TomokiToda
• Contents:Continuouslatentvariablemodels• Factoranalysis• Lineardynamicalsystems• Predictionandupdate• (Trainingalgorithm)
1z 2z 3z 4z
1x 2x 3x 4x
1z
Nz
n
x

6th and8th Classes(7/15and8/1)
j
• Lecturer:Sakriani Sakti
• Contents:Discriminativemodelsforsequentiallabeling• Structuredperceptron• ConditionalRandomFields• Trainingalgorithm
「今日は晴れだ。」
今日/は/晴れ/だ/。
今/日/は/晴れ/だ/。

AugmentedHumanCommunicationLaboratoryGraduateSchoolofInformationScience
SequentialDataModeling
1st class“Basicsofsequentialdatamodeling1”
GrahamNeubig

Question
Afterthisclass,youcananswerthesequestions!
A-san
B-san
?
Oneday,someoneatethefollowingmenu.
Q1.A-sanorB-san?Q2.IfthisisA-san’smenu,
whichis“?”,or?
LogofA-san’smenu
LogofB-san’smenu
Q3.…

SequentialData
1
• Dataexamples• Timeseries(speech,actions,movingobjects,exchangerates,…)• Characterstrings(wordsequence,symbolstring,…)
• Variouslengthsofdata• E.g.,
• Probabilisticapproachtomodelingsequentialdata• Consistentframeworkforthequantificationandmanipulationof
uncertainty• Effectivefordealingwithrealdata
Datasample1(length=5):{1,0,1,1,0}Datasample2(length=8):{1,1,1,0,1,1,0,0}Datasample3(length=3):{0,0,1}Datasample4(length=6):{0,1,0,1,1,0}

HowtoRepresentSequentialData?• Asequentialdatasampleisrepresentedinahigh-dimensional
space(“#ofdimensions”=“lengthofthesequentialdatasample”).
n = 1 n = 2 n = 1 n = 2 n = 3 n = 1 n = 2 n = 3 n = N…x1 x2 x1 x2 x3 x1 x2 x3 xN…
x1
x2
x2
x1
x3
Length=2 Length=3 Length=N
Representedby2-dimensionalvector
Examplesofsequentialdata:
Representedby3-dimensionalvector
RepresentedbyN-dimensionalvector
2
Weneedtomodelprobabilitydistributioninthesehigh-dimensionalspaces!

Rules ofProbability(1)
3
• Assumetworandomvariables,X andY• X : x1 = “Bread”, x2 = “Rice”, or x3 = “Noodle”• Y : y1 = “Home” or y2 = “Restaurant”
• Assumethefollowingdatasamples{X,Y }:{Bread,Home},{Rice,Restaurant},{Noodle,Home},{Bread,Restaurant},{Rice,Restaurant},{Noodle,Home},{Bread,Home},{Rice,Home},and{Bread,Home}
• Makethefollowingtableshowingthenumberofsamples
2 1 2
1 2 0
Bread Rice Noodle
HomeRestaurant
Numberof samples#ofsamplesof{Noodle,Home}

Jointprobability :
Sumruleofprobability :
Marginalprobability :
Conditionalprobability :
Productrule ofprobability:
Rules ofProbability(2)#ofsamplesintheith column
#ofsamplesinthejth row
#ofsamplesinthecorresponding cell
Theith valueofarandomvariableX,wherei = 1, …, M
Thejth valueofarandomvariableY,wherej = 1, …, L
ic
ijn jrjy
ix
4

• Therulesofprobability– Sumrule :
– Productrule :
• Bayes’theorem :
Rules ofProbability(3)
5

• Probabilitieswithrespecttocontinuousvariables• Probabilitydensityoverareal-valuedvariablex : p(x)
– Probability thatx willlieinaninterval(a, b) :
– Conditions tobesatisfied :
• Cumulativedistribution function:P(x)– Probability thatx liesintheinterval(-∞, z) :
ProbabilityDensities
6
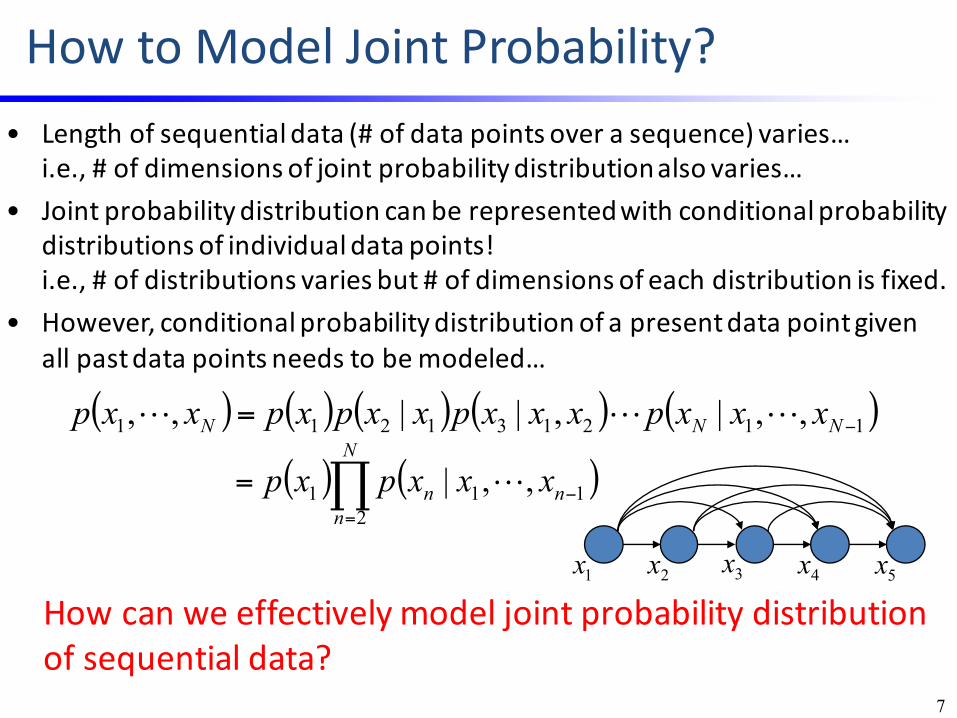
HowtoModelJointProbability?• Lengthofsequentialdata(#ofdatapointsoverasequence)varies…
i.e.,#ofdimensionsofjointprobabilitydistributionalsovaries…• Jointprobabilitydistributioncanberepresentedwithconditionalprobability
distributionsofindividualdatapoints!i.e.,#ofdistributionsvariesbut#ofdimensionsofeachdistributionisfixed.
• However,conditionalprobabilitydistributionofapresentdatapointgivenallpastdatapointsneedstobemodeled…
Howcanweeffectivelymodeljointprobabilitydistributionofsequentialdata?
1x 2x 3x 4x 5x
( ) ( ) ( ) ( ) ( )112131211 ,,|,||,, −= NNN xxxpxxxpxxpxpxxp !!!
( ) ( )∏=
−=N
nnn xxxpxp
2111 ,,| !
7

TwoBasicApproaches
• Markovprocess
• Latentvariables
1x 2x 3x 4x
1z 2z 3z 4z
1x 2x 3x 4x
8

MarkovProcess• Assumethattheconditionalprobabilitydistributionofthepresentstates
dependsonlyonafewpaststates
1x 2x 3x 4x
1x 2x 3x 4x
1st orderMarkovchain
2nd orderMarkovchain
e.g.,itdependsononlyonepaststate…
9

Exampleof1st OrderMarkovProcess• HowmanyprobabilitydistributionsareneededifwemodelEnglishtext
usingthe1st orderMarkovprocess?Ifonlyusing27charactersincluding“space”,P(“Thissentenceisrepresentedbythis…”)= P(T)P(h|T)P(i|h)P(s|i)P(-|s)P(s|-)P(e|s)P(n|e)P(t|n)P(e|t)…
10
P(x) P(x, y) P(y|x)x :1st lettery :2nd letter
Probabilityisshownbytheareasofwhitesquares.
DavidJ.C.MacKay,“InformationTheory, Inference,andLearningAlgorithms,”CambridgeUniversityPress,pp.22-24

StateTransitionDiagram/Matrix
晴
雨 曇
/s/
起 寝
/e/
⎥⎥⎥
⎦
⎤
⎢⎢⎢
⎣
⎡
4.05.01.04.03.03.01.03.06.0
0.6
0.30.1
0.30.4
0.30.1
0.50.4
0.60.3
1
0.7 0.1
0.2 ⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢
⎣
⎡
10001.03.06.002.01.07.000010
0.1
晴晴
=A
曇 雨
曇
雨
)|( 晴雨p
Sumbecomesone.
Initialstate
Finalstate
/s/
/e/
起
寝
/s/ /e/起 寝
Finalstatetransition
=A
w/explicitinitialandfinalstates
w/oexplicitinitialandfinalstates
Statetransitiondiagram Statetransitionmatrix
Statetransitiondiagram Statetransitionmatrix
Paststate
Presentstate
11
?
)|( 晴雨p
起:wakeup寝:sleep
晴:fine雨:rain曇:could

• Languagemodel(modelingdiscretevariables)• Modelingaword(morpheme)sequencewithMarkovmodel(n-gram)
e.g.,「学校に行く」 /s/, 学校, に, 行, く, /e/
• Autoregressivemodel(modelingcontinuousvariables)• PredictingthepresentdatapointfrompastM datapoints
ExampleofApplications
)|(|)|()|()|()( く行)(くに行学校に学校 eppppspsp
Decompose intomorphemes Modeling withbi-gram(2-gram)
LinearcombinationofpastM datapoints
12

• Trainingofconditionalprobabilitydistributionfromsequentialdatasamplesgivenastrainingdata…
ModelTraining(MaximumLikelihoodEstimation)
Likelihoodfunction:
Determinetheconditionalprobabilitydistributionsthatmaximizesthe(log-scaled)likelihoodfunction
subjectto
),|( λpc wwp
Constrainttonormalizetheestimatesasprobability
ModelparametersetFunctionofmodelparameters
Maximumlikelihoodestimate:#ofsamples
#ofsamples
{ }cp ww ,
pw13

ExampleofMLE
14
A-san
LogofA-san’smenu
P(|)=1/4P(|)=3/4
P(|)=2/4P(|)=1/4P(|)=1/4
P(|)=1/8P(|)=4/8P(|)=3/8
1/4 3/4
2/4
1/4
1/4
1/84/8
3/8
MLEofconditionalprobabilities
????????
???
???
??
Statetransitiondiagram

• Useofatestdataset{w1, …, wN}notincludedintrainingdata• Evaluationmetrics
• Likelihood
• Log-scaledlikelihood
• Entropy
• Perplexity
MethodsforEvaluatingModels
HPP 2=
( ) ( )∑=
−=N
nnnN wwpwwp
11212 |log|,,log λ!
( ) ( )∏=
−=N
nnnN wwpwwp
111 ||,, λ!
( ) ( )∑=
−−=−=N
nnnN wwp
Nwwp
NH
11212 |log1|,,log1 λ!
Ameasureofeffective“branchingfactor”
MPP
MMNMN
H NN
n
=
==−= ∑=
221
2 loglog11log1e.g.,setauniform distribution toalln-gramprobabilities forM words
15

Classification/Inference/GenerationClassification
Sequentialdata
Multiplemodels
Model selectionbasedonmaximumposteriorprobability Classificationresult
Model
Model
Calculationofconditionalprobability
Inference(dataorprobability)
Datagenerationbasedonjointprobability distribution Data
Sequentialdata
Inference(prediction)
Generation
16

Classificationw/MaximumA Posteriori• Selectamodelthatmaximizestheposteriorprobability
17
Likelihoodfunction Priorprobability
Constant
Posteriorprobability:
( )
( ) ( )iiNi
Nii
pxxp
xxpi
λλ
λ
|,,maxarg
,,|maxargˆ
1
1
!
!
=
=
( )iNixxpi λ|,,maxargˆ
1 !=
Ifpriorprobabilityisgivenbyauniformdistribution,
Themodelisselectedby

Classification
/s/
起 寝
/e/
0.80.1
1
0.7 0.1
0.2 0.1
/s/
起 寝
/e/
0.40.4
1
0.6 0.2
0.2 0.2
Observeddata:/s/起起寝起 /e/
0112.02.08.01.07.011 =×××××0096.02.04.02.06.011 =×××××
)|()|()|()|()|()( 起eppppspsp 寝起起寝起起起
/s/ 起 起 寝 起 /e/
Model1 Model2Models:
Likelihood:
Trellis:Expansionof thestatetransitiongraphovertimeaxis Model1:
Model2:
A.Classifiedtothemodel1.
Q.Whichmodelisthisdatasampleclassifiedto?
• Comparisonofmodellikelihoods
18
?
起:wakeup寝:sleep

MarginalizationforUnobservedData• Likelihoodcalculationwithmarginalizationevenifapartofdatais
notobserved.
( )( ) 017.01.01.02.08.0
1.001.011=×+××
×+×× ( )( ) 032.02.04.02.04.0
4.002.011=×+××
×+××
{ }∑∈ 寝起
寝寝,,
331131
)|()|()|()|()(xx
xepxpxpsxpsp
Observeddata: /s/?寝 ? /e/
Likelihood:
Trellis:
{ } { } ⎭⎬⎫
⎩⎨⎧
⎭⎬⎫
⎩⎨⎧
= ∑∑∈∈ 寝起寝起
寝寝,
33,
1131
)|()|()|()|()(xx
xepxpxpsxpsp
Model1
A.Classifiedtothemodel2.
Q.Whichmodelisthisdatasampleclassifiedto?
Considerallpossibledatasamples
/s/ 起
寝
起 /e/
寝 寝
0.4
0.4
1 0.20.2
0
0.40.2
/s/ 起
寝
起 /e/
寝 寝
0.8
0.1
1 0.10.2
0
0.10.1
Model2
19
?

Inference• Calculationofposteriorprobability
098.02.07.07.011 =××××=/s/ 起 起 起 /e/
860.0016.0098.0
098.0≅
+
Observeddata: /s/起 ?起 /e/
{ }∑∈
====
寝起
起起
起起起起起起
,2
312
2
),,,,(),,,,(),|(
xexsp
espxxxp
寝016.02.08.01.011 =××××=
140.0016.0098.0
016.0≅
+
),,,,( esp 起起起
),,,,( esp 起寝起
==== ),|( 312 起起起 xxxp
==== ),|( 312 起起寝 xxxpA.“?”is“起” with86%ofprobability.
/s/
起 寝
/e/
0.8
0.1
1
0.70.1
0.2 0.1
Model1
Posteriorprobability:
Q.Which“起” or“寝” islikelyobservedat“?”point?
0.8
1 0.7
0.1
0.20.7
20
?
?
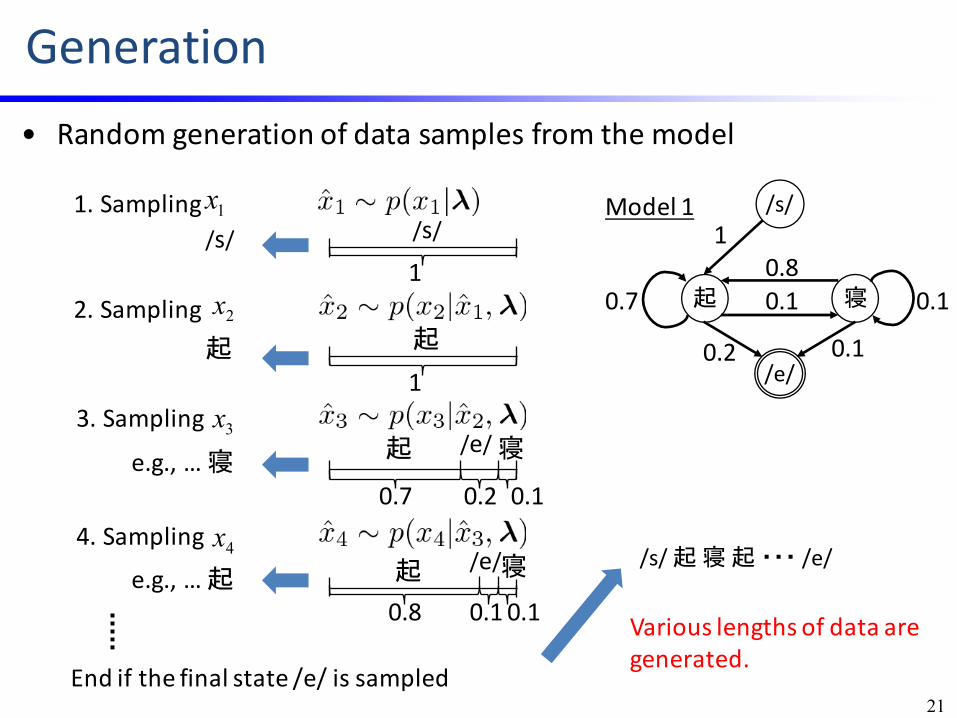
Generation• Randomgenerationofdatasamplesfromthemodel
Variouslengthsofdataaregenerated.
/s/
起 寝
/e/
0.80.1
1
0.7 0.1
0.2 0.1
Model1/s/
起
e.g.,…寝
e.g.,…起
1x1.Sampling
2x2.Sampling
3x3.Sampling
4x4.Sampling
/s/
起
起 /e/寝
起 /e/寝
1
1
0.7 0.2 0.1
0.8 0.10.1
/s/起寝起・・・ /e/
Endifthefinalstate/e/issampled21

MaximumLikelihoodDataGeneration• Datagenerationbymaximizinglikelihoodundertheconditionthat
thelengthofdataisgiven
/s/
起 起 起
/e/
寝 寝寝
1
0
1
0
0.7
0.10.8
0.7
0.1
0.1
0.7
0.10.8
0.49
0.07
0.2
0.1
0.1
0.098
/s/
起 寝
/e/
0.80.1
1
0.7 0.1
0.2 0.1
Model1
/s/起起起 /e/isgeneratedifsettingthedatalengthto3.
Dynamicprogramming1.Storethebestpathateachstate
2.Backtrackofthebestpathfromthefinalstate
1・0.70・0.8Selection
0.7・0.70.1・0.8Selection
1・0.10・0.1Selection 0.7・0.1
0.1・0.1Selection0.49・0.20.07・0.1Selection
22

YouCanAnswertheQuestion!
Let’suseMarkovmodeltoanswerthem!
A-san
B-san
?
Oneday,someoneatethefollowingmenu.
Q1.A-sanorB-san?Q2.IfthisisA-san’smenu,
whichis“?”,or?
LogofA-san’smenu
LogofB-san’smenu
Q3.…