(semantic web technologies and applications track) "a quantitative comparison of semantic web...
TRANSCRIPT

[Faculty of ScienceInformation and Computing Sciences]
A Quantitative Comparison of SemanticWeb Page Segmentation Algorithms
Robert Kreuzer Jurriaan Hage Ad Feelders
Department of Information and Computing Sciences, Universiteit [email protected]
June 25, 2015

[Faculty of ScienceInformation and Computing Sciences]
2
Topic of this talk
I Inferring the semantic structure of a page
I What parts of the page belong together semantically?
I Common examples: Navigation, Content, Header, Footer,Ads, Comments, Links
I Humans can do this intuitively (even for foreign languages)

[Faculty of ScienceInformation and Computing Sciences]
3
Example segmentation

[Faculty of ScienceInformation and Computing Sciences]
4
Why is segmentation interesting?
I The Web as a database of all human knowledge
I “Our” trigger: rendering regular websites on mobile devices
I and many others
I Segmentation provides structure to improve all of theabove

[Faculty of ScienceInformation and Computing Sciences]
5
Research question for this paper
How well do existing Web page segmentationparadigms work on modern Web sites?
Subquestions:
1. What are the current best-performing algorithms tacklingthis problem?
2. What assumptions do the paradigms make and are theystill valid?
3. In which scenarios does their approach work well and inwhich not?
4. Is a combination of paradigms a better option?
5. Is web page segmentation a solved problem?

[Faculty of ScienceInformation and Computing Sciences]
6
Three paradigms
I DOM-based: look at the structure encoded in the HTML
I Rendering-based: look at the rendered page like humans do
I Text-based: look only at the text itself

[Faculty of ScienceInformation and Computing Sciences]
7
Relative advantages
I DOM: easy to implement since no rendering, use availablestructure of the DOM
I Rendering: styling and layout can be taken into account,similar to human beings, can take implicit cues(whitespace) into account
I Text: fast, easy to implement

[Faculty of ScienceInformation and Computing Sciences]
8
Relative disadvantages
I DOM: what if HTML is not structurally aligned withcontent (e.g., due to Javascript DOM manipulation)? Howto disregard style and variations in layout?
I Rendering: complex (needs browser engine),computationally intensive, requires all external resources
I Text: does not work with pages built with Javascript(unless...), does not take structural and visual cues

[Faculty of ScienceInformation and Computing Sciences]
9
Chosen algorithms
I Following a literature review we chose:I text-based: BlockFusionI structure-based: PageSegmenterI rendering-based: VIPS
I text-based is rare, most structure- or rendering-based
I VIPS most popular, but already 10 years old
I oldest algorithms from around 1998

[Faculty of ScienceInformation and Computing Sciences]
10
Dataset?
I Datasets and method of comparison in literature differs alot
I how is algorithm performance scored?I do the datasets include external resources?I who manually segmented them?
I No standard dataset
I We constructed our own two datasets, that we haveopen-sourced

[Faculty of ScienceInformation and Computing Sciences]
11
Datasets
Random:
I 82 randomly selected Web pages fromhttp://www.whatsmyip.org/random-website-machine/
I In different languages and from all categories
I 79.4 files on average
Popular:
I The top 10 pages from 10 different categories fromhttp://dir.yahoo.com/ (70 after filtering)
I the most popular Websites, mostly in English
I 196.2 files on average
wget does a pretty good job retrieving complete websites, butJavascript remains an issue.

[Faculty of ScienceInformation and Computing Sciences]
12
Data collection
I Was done by three volunteers
I Instructed to get the top-level blocks and their sub-blocksto segment the page as completely as possible
I First select a block, then choose its type
I Type was ultimately not used, but it is in the dataset
I Datasets are available online1
1https://github.com/rkrzr/

[Faculty of ScienceInformation and Computing Sciences]
13
BlockFusion (Kohlschutter, Nejdl)
I text-based algorithm: only looks at the text-content
I does not require the DOM to be built or the page to berendered
I based on the observation that text density is acharacteristic property in quantitative linguistics
I token density: number of tokens/number of lines(line=80chars)
I start with atomic text blocks and merge them until thedensity threshold is reached
I implemented on top of Boilerpipe in Java

[Faculty of ScienceInformation and Computing Sciences]
14
PageSegmenter (Vadrevu, Gelgi, Davulcu)
I Structure-based algorithm: operates solely on theDOM-tree
I Assumes that path entropy is a good heuristic for asegementation
I Example path: /html/body/p/ul/li
I path entropy: HP (N) = −k∑
06i6k
p(i) log p(i) where p(i) is
the probability of path Pi appearing under the node N andk the number of leaf nodes below N .
I original paper unclear, implemented our interpretation inPython
I slow on big pages (runs in O(n3))

[Faculty of ScienceInformation and Computing Sciences]
15
VIPS (Cai, Yu, Wen, Ma)
I Rendering-based algorithm: Imitates how humansrecognize the segments
I Divides pages into blocks, separators and connectionsbetween them
I Looks at background colors, font sizes, font types, whitespace, images
I Implemented by Tomas Popela in Java using CSSbox

[Faculty of ScienceInformation and Computing Sciences]
16
WebTerrain (the authors)
I Combination of structure- and rendering-based approaches
I Inspired by the 3D-view (terrain-view) feature in Firefox
I The main idea is that ”mountains” map well to semanticblocks
I Implemented using python-webkit

[Faculty of ScienceInformation and Computing Sciences]
17
Setup of the experiment
I How well do the four different segmentation algorithmswork under different conditions?
I Four testing variables:
I Algorithms: BlockFusion, PageSegmenter, VIPS,WebTerrain
I Datasets: random pages or popular pagesI Type of HTML: Original HTML or DOM HTMLI Evaluation metric: Exact or Fuzzy
I In total 32 combinations, run with our (extensible,free-to-use) testing framework

[Faculty of ScienceInformation and Computing Sciences]
18
Some details on two aspects
Original vs. DOM
I Original HTML: what you get from a GET request
I DOM HTML: obtained by fully rendering the page andserializing the DOM
Exact vs. Fuzzy:
I Exact: does string equality check for serialized blocks
I Fuzzy: equal if similarity ratio of > 0.8 with Python’sdifflib

[Faculty of ScienceInformation and Computing Sciences]
19
Measuring the quality of the results
Relevant: The actual semantic blocks obtained from theground truth
Precision: The number of relevant results out of all retrievedresults (quality)
Recall: The number of retrieved results out of all relevantresults (quantity)
F-score: Combination of Precision and Recall :F = 2 ∗ P∗R
P+R

[Faculty of ScienceInformation and Computing Sciences]
20
Random dataset - Original HTML
Exact first, then Fuzzy:
Algorithm Precision Recall F-Score Retrieved Hits Relevant
BlockFusion 0.03 0.06 0.04 25.99 0.77 12.24
PageSegmenter 0.11 0.27 0.14 46.96 2.97 12.24
VIPS 0.07 0.06 0.06 7.42 0.91 12.24
WebTerrain 0.25 0.22 0.21 10.9 2.23 12.24
Algorithm Precision Recall F-Score Retrieved Hits Relevant
BlockFusion 0.06 0.11 0.07 25.99 1.51 12.24
PageSegmenter 0.19 0.45 0.24 46.96 5.24 12.24
VIPS 0.28 0.16 0.17 7.42 1.99 12.24
WebTerrain 0.48 0.43 0.42 10.9 4.5 12.24

[Faculty of ScienceInformation and Computing Sciences]
21
Random dataset - DOM HTML
Skipping the not so interesting Exact comparison now:
Algorithm Precision Recall F-Score Retrieved Hits Relevant
BlockFusion 0.1 0.17 0.12 30.96 2.35 12.24
PageSegmenter 0.15 0.51 0.2 65.04 6.12 12.24
VIPS 0.51 0.26 0.3 9.24 3.33 12.24
WebTerrain 0.57 0.49 0.49 10.58 5.33 12.24

[Faculty of ScienceInformation and Computing Sciences]
22
Popular dataset - Original HTML
Algorithm Precision Recall F-Score Retrieved Hits Relevant
BlockFusion 0.05 0.12 0.06 72.85 2.07 16.15
PageSegmenter 0.09 0.42 0.13 124.43 6.74 16.22
VIPS 0.13 0.15 0.12 16.72 2.23 16.11
WebTerrain 0.37 0.35 0.33 13.86 4.81 16.09
[Faculty of ScienceInformation and Computing Sciences]
23
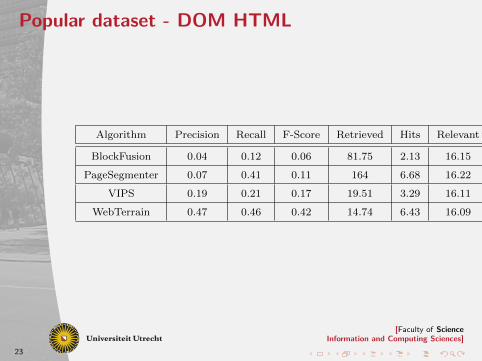
Popular dataset - DOM HTML
Algorithm Precision Recall F-Score Retrieved Hits Relevant
BlockFusion 0.04 0.12 0.06 81.75 2.13 16.15
PageSegmenter 0.07 0.41 0.11 164 6.68 16.22
VIPS 0.19 0.21 0.17 19.51 3.29 16.11
WebTerrain 0.47 0.46 0.42 14.74 6.43 16.09

[Faculty of ScienceInformation and Computing Sciences]
24
Algorithms discussion
BlockFusion: Disappointing, very low Precision and Recallscores, could not replicate results from originalpaper, too many blocks on average
PageSegmenter: generally low Precision and high Recall, waytoo many blocks on average, thus many falsepositives
VIPS: good Precision and mediocre Recall on randompages, mediocre results on popular pages
WebTerrain: best average F-Score, number of blocks is close torelevant number, combination of approachesworks well

[Faculty of ScienceInformation and Computing Sciences]
25
Other conclusions
I DOM HTML is a better basis than the original HTML
I More complex pages lead to lower performance for allalgorithms
I Fuzzy compare is more suitable than exactI Best average F-score is still only 0.49
I not good enough for general purpose applicationsI more specialized use cases already work well enough

[Faculty of ScienceInformation and Computing Sciences]
26
Threats to validity
I Did we choose good representatives of the paradigms?I Choice for often-cited well-known algorithms
I Did we compare correct implementations?I used available software as much as possibleI consult authors if we have questions
I Bias in website selection: use of popular and random sites
I Some websites were dropped: our results may not hold forDOM-manipulating-heavy Javascript
I Mark-up following a given ontology: we believe it to begeneric enough
I Mark-up made by three different people in IT: 1st authorchecked first a few results for consistency
I One of the algorithms was of our own devising: notchanged after verifying implementation was correct

[Faculty of ScienceInformation and Computing Sciences]
27
Conclusion
I Comparison of 4 different segmentation algorithms on twodifferent datasets using own testing framework
I Greater complexity poses a challenge for Web pagesegmentation algorithms
I Algorithms are not good enough yet for general purposeapplications
I specialized use cases like main content extraction, workwell enough already
I More sophisticated combinations of different approachesseem promising

[Faculty of ScienceInformation and Computing Sciences]
28
Future work
I Unified dataset and metrics to make results comparable
I The general conclusion is:new and better algorithms are needed
I Maybe domain-specific algorithms are necessary
I Feel free to test your algorithm on our benchmark!

[Faculty of ScienceInformation and Computing Sciences]
28
Future work
I Unified dataset and metrics to make results comparable
I The general conclusion is:new and better algorithms are needed
I Maybe domain-specific algorithms are necessary
I Feel free to test your algorithm on our benchmark!