secured outsourcing of frequent itemset mining hana chih-hua tai institute of information science,...
TRANSCRIPT

SECURED OUTSOURCING OF FREQUENT ITEMSET MINING
Hana Chih-Hua Tai
Institute of Information Science, Academia Sinica

OUTLINE
Preliminary – Frequent ItemSet Mining Motivation Privacy Model – K-Support Anonymity Algorithm Performance Studies Conclusion
2

OUTLINE
Preliminary – Frequent ItemSet Mining Motivation
3

FREQUENT ITEMSET MINING (FIM)
Discover what happened frequently
4
Trans. ID Items
1 wine
2 cigar, wine
3 cigar, tea
4 beer, cigar, wine
5 beer, tea, wine
When threshold set as 3 (=60%), {wine} and {cigar} are frequent.
When threshold set as 2 (=40%),{wine}, {cigar}, {tea}, {beer}, {wine, cigar}, and {wine, beer} are frequent.

FREQUENT ITEMSET MINING (FIM)
Discover what happened frequently
Frequent itemset mining (FIM)
5
Trans. ID Items
1 wine
2 cigar, wine
3 cigar, tea
4 beer, cigar, wine
5 beer, tea, wine
When threshold set as 3 (=60%), {wine} and {cigar} are frequent.
When threshold set as 2 (=40%),{wine}, {cigar}, {tea}, {beer}, {wine, cigar}, and {wine, beer} are frequent.

THE NEEDS OF OUTSOURCING FIM
For those who lack of expertise in FIM and/or computing resources, they have the need of outsourcing the mining tasks to a professional third party.
6
Data Owner
Mining Services Provider(Cloud Computing)

THE NEEDS OF OUTSOURCING FIM
For those who lack of expertise in FIM and/or computing resources, they have the need of outsourcing the mining tasks to a professional third party.
7
Data Owner
Mining Services Provider(Cloud Computing)
Privacy?
!

THE RISKS OF OUTSOURCING FIM
Encryption/decryption method is believed as the possible solution.
8
Mining Services Provider(Cloud Computing)
Data Owner

THE RISKS OF OUTSOURCING FIM
Encryption/decryption method is believed as the possible solution.
9
Mining Services Provider(Cloud Computing)
Data OwnerHow to achieve the encryption and decryption?
Privacy protected
Correct mining results
Reasonable overhead

THE RISKS OF OUTSOURCING FIM
10
Trans. ID Items
1 wine
2 cigar, wine
3 cigar, tea
4 beer, cigar, wine
5 beer, tea, wine
Trans. ID Items
1 a
2 a, c
3 c, d
4 a, b, c
5 a, b, d
Encrypt

THE RISKS OF OUTSOURCING FIM
Top frequency attack Wine is the most frequent item ‘a’ is ‘wine’
Approximate support attack The support of cigar is about 55%~60% ‘c’ is
‘cigar’
11
Trans. ID Items
1 wine
2 cigar, wine
3 cigar, tea
4 beer, cigar, wine
5 beer, tea, wine
Trans. ID Items
1 a
2 a, c
3 c, d
4 a, b, c
5 a, b, d
Encrypt

THE RISKS OF OUTSOURCING FIM
Top frequency attack Wine is the most frequent item ‘a’ is ‘wine’
Approximate support attack The support of cigar is about 55%~60% ‘c’ is
‘cigar’
12
Trans. ID Items
1 wine
2 cigar, wine
3 cigar, tea
4 beer, cigar, wine
5 beer, tea, wine
Trans. ID Items
1 a
2 a, c
3 c, d
4 a, b, c
5 a, b, d
Encrypt
The Risks of Outsourcing FIM
The support information about the frequent itemsets can be utilized to effectively reveal the raw data as well as the sensitive information from the anonymized transactions.
T. Mielik¨ainen. Privacy problems with anonymized transaction databases. In Proc. of Discovery Science, 2004.

RELATED WORKS
Encrypt each real items by a one-many mapping function.
Wong, W. K., Cheung, D. W., Hung, E., Kao, B., Mamoulis, N.: Security in Outsourcing of Association Rule Mining. In: Proc. of VLDB, 2007.
However, it does not try to anonymize the support information.
Recently it is cracked.
Molloy, I., Li, N., Li, T.: On the (In)Security and (Im)Practicality of Outsourcing Precise Association Rule Mining. In: Proc. of ICDM, 2009.
13

OUTLINE
Preliminary – Frequent ItemSet Mining Motivation Privacy Model – K-Support Anonymity
14

K-SUPPORT ANONYMITY & ANONYMIZATION For every sensitive item, there are at least k-1
other items of the same support. The probability of an item being correctly re-identified
is limited to 1/k, even when the precise support information is known.
Given a transactional database T, encrypt T into E(T) such that There exist a decryption function D such that
MiningResult(T, Δ)= D(MiningResult(E(T), Δ)), for any minimal support Δ.
E(T) is k-support anonymous.
15

SOLUTION 1: A NAÏVE APPROACH
For each set of real items of the same support, add enough fake items randomly into transactions to make the fake items as frequent as real ones.
16
Trans. ID
Items
1 wine
2 cigar, wine
3 cigar, tea
4 beer, cigar, wine
5 beer, tea, wine
For k = 3, 16 additional items are required.4 x 2 = 8 (e, f) for wine 3 x 2 = 6 (g, h) for cigar 2 x 1 = 2 (i) for beer and tea
Items
a, e, g, h, i
a, c, e, f, h, i
c, d, e, f, g
a, b, c, f, h
a, b, d, e, f, g

A NAÏVE SOLUTION
For each set of real items of the same support, add enough fake items randomly into transactions to make the fake items as frequent as real ones.
17
Trans. ID
Items
1 wine
2 cigar, wine
3 cigar, tea
4 beer, cigar, wine
5 beer, tea, wine
For k = 3, 16 additional items are required.4 x 2 = 8 (e, f) for wine 3 x 2 = 6 (g, h) for cigar 2 x 1 = 2 (i) for beer and tea
Items
a, e, g, h, i
a, c, e, f, h, i
c, d, e, f, g
a, b, c, f, h
a, b, d, e, f, g
There could be too large storage overhead when k is large.

GENERALIZED FIM
Discover all frequent items across concept levels, given a taxonomy indicating the hierarchical concepts between items
18
Trans. ID Items
1 wine
2 cigar, wine
3 cigar, tea
4 beer, cigar, wine
5 beer, tea, wine
beer
teaalcoholic
wine
beverage
all prod.
cigar
When threshold set as 3 (=60%), {wine}, {cigar}, {alcoholic}, {beverage} and {all prod.} are frequent.{beverage, cigar} are also frequent.

GENERALIZED FIM
Discover all frequent items across concept levels, given a taxonomy indicating the hierarchical concepts between items
19
Trans. ID Items
1 wine
2 cigar, wine
3 cigar, tea
4 beer, cigar, wine
5 beer, tea, wine
beer
teaalcoholic
wine
beverage
all prod.
cigar
When threshold set as 3 (=60%), {wine}, {cigar}, {alcoholic}, {beverage} and {all prod.} are frequent.{beverage, cigar} are also frequent.
1. The support of a parent node comes from the supports of it child nodes. 2. Only lead nodes need to appear in the transactions.

OUTLINE
Preliminary – Frequent ItemSet Mining Motivation Privacy Model – K-Support Anonymity Algorithm
20

ANONYMIZATION: OVERVIEW
For storage efficiency, we suggest to convert FIM to GFIM.
21
Pseudo Taxonomy Generation in the Encryption
Encrypt Transaction Data
Frequent Itemsets
Pseudo Taxonomy
Transaction
Data
Encrypted
Decrypt Frequent Itemsets
Data Owner Third Party
Generalized Frequent Itemset Mining

wine {e, f, j}cigar {b, c, d}beer and tea {a, g, h}
ANONYMIZATION: STORAGE EFFICIENCY
In GFIM, items can be at multiple levels of a taxonomy and only the items at leaf level need to appear in the database.
22
Trans. ID Items
1 wine
2 cigar, wine
3 cigar, tea
4 beer, cigar, wine
5 beer, tea, wine
Encrypt with k=3
4 additional items required
a
f
beer
wine
j
cigar
e
b
i
k
c d
g htea
Trans. ID
Items
1 c, d, g
2 b, d, g
3 b, h
4 a, b, c
5 a, c, d, h
2
1
1

In GFIM, items can be at multiple levels of a taxonomy and only the items at leaf level need to appear in the database.
wine {e, f, j}cigar {b, c, d}beer and tea {a, g, h}
ANONYMIZATION: STORAGE EFFICIENCY
23
Trans. ID Items
1 wine
2 cigar, wine
3 cigar, tea
4 beer, cigar, wine
5 beer, tea, wine
Encrypt with k=3
4 additional items required
a
f
beer
wine
j
cigar
e
b
i
k
c d
g htea
Trans. ID
Items
1 c, d, g
2 b, d, g
3 b, h
4 a, b, c
5 a, c, d, h
2
1
1
Small storage overhead compared to the naïve method.

ANONYMIZATION: EASY DECRYPTION
The real frequent itemsets can be obtained by filtering out patterns containing any fake item in 1 scan of the returned results.
24
Trans. ID Items
1 wine
2 cigar, wine
3 cigar, tea
4 beer, cigar, wine
5 beer, tea, winemin_sup = 2
a
f
beer
wine
j
cigar
e
b
i
k
c d
g htea
Trans. ID Items
1 c, d, g
2 b, d, g
3 b, h
4 a, b, c
5 a, c, d, h Results ={{beer}, {cigar}, {wine}, {tea}, {beer, wine}, {cigar, wine}}
Results ={a, b, c, d, e, f, g, h, i, j, k, ac, af, bf, ce, …}

a
f
beer
wine
j
cigar
e
b
i
k
c d
g htea
ANONYMIZATION: EASY DECRYPTION
The real frequent itemsets can be obtained by filtering out patterns containing any fake item in 1 scan of the returned results.
25
Trans. ID Items
1 wine
2 cigar, wine
3 cigar, tea
4 beer, cigar, wine
5 beer, tea, winemin_sup = 2
Trans. ID Items
1 c, d, g
2 b, d, g
3 b, h
4 a, b, c
5 a, c, d, h Results ={{beer}, {cigar}, {wine}, {tea}, {beer, wine}, {cigar, wine}}
Results ={a, b, c, d, e, f, g, h, i, j, k, ac, af, bf, ce, …}
The data owner can obtain the real results in 1 scan of the returned itemsets.
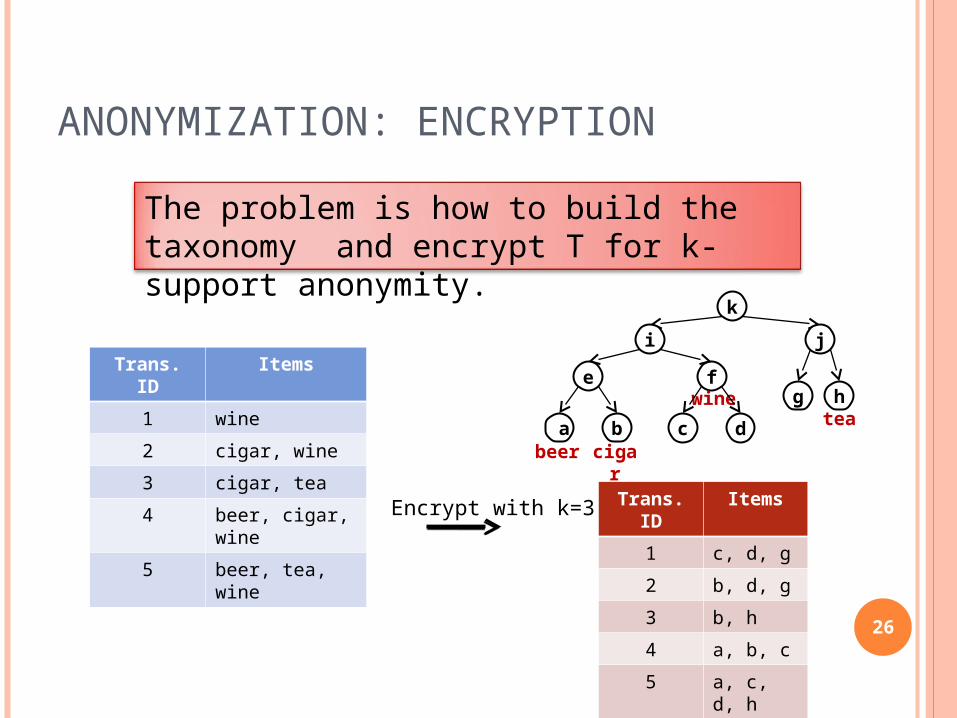
ANONYMIZATION: ENCRYPTION
26
Trans. ID Items
1 wine
2 cigar, wine
3 cigar, tea
4 beer, cigar, wine
5 beer, tea, wine
Encrypt with k=3
a
f
beer
wine
j
cigar
e
b
i
k
c d
g htea
Trans. ID
Items
1 c, d, g
2 b, d, g
3 b, h
4 a, b, c
5 a, c, d, h
The problem is how to build the taxonomy and encrypt T for k-support anonymity.

ANONYMIZATION: ENCRYPTION
1: Generalization of the Mining Task To generate a pseudo taxonomy that can
(a) conserve the correct and complete mining results, (b) facilitate k-support anonymization.
2: Anonymization with Taxonomy Tree To encrypt T for k-support anonymity with the
help of the constructed taxonomy tree.
27

1: GENERALIZATION OF THE MINING TASK
Build a k-bud tree of T All real items at the leaf level The number of nodes in three categories is equal
to or greater than kLet xM denote the most frequent real item in T A> = { v | sup(v) > sup(xM) and v is leaf}, A= = { v | sup(v) = sup(xM)}, and A< = { v | sup(v) < sup(xM) < sup(u), where u is the
parent node of v }.
2
4
(beer)
(wine)
2
(cigar)
4
3
5
5
(tea)
3-bud tree
Trans. ID Items
1 wine
2 cigar, wine
3 cigar, tea
4 beer, cigar, wine
5 beer, tea, wine
28

1: GENERALIZATION OF THE MINING TASK
29beerciga
rwine tea
3 groupsTrans. ID Items
1 wine
2 cigar, wine
3 cigar, tea
4 beer, cigar, wine
5 beer, tea, wine

1: GENERALIZATION OF THE MINING TASK
30
Trans. ID Items
1 wine
2 cigar, wine
3 cigar, tea
4 beer, cigar, wine
5 beer, tea, wine
2 4(beer) (wine)
2(cigar)
4
3
3 subtrees
(tea)
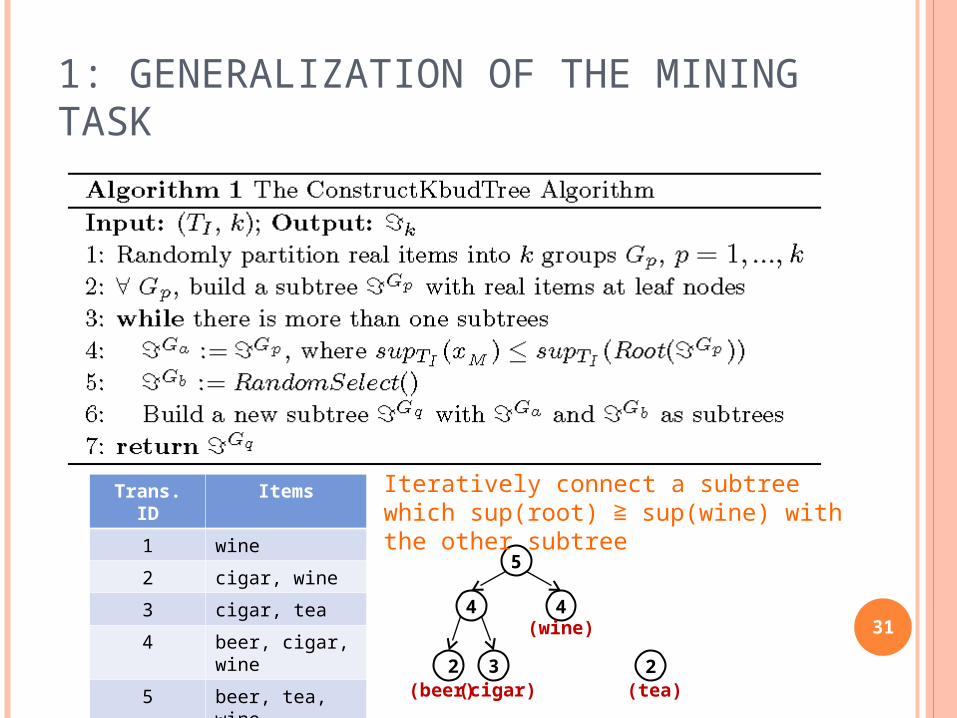
1: GENERALIZATION OF THE MINING TASK
31
Trans. ID Items
1 wine
2 cigar, wine
3 cigar, tea
4 beer, cigar, wine
5 beer, tea, wine 2(tea)(beer)
2
4(wine)
(cigar)
4
3
5
Iteratively connect a subtree which sup(root) ≧ sup(wine) with the other subtree

1: GENERALIZATION OF THE MINING TASK
32
Trans. ID Items
1 wine
2 cigar, wine
3 cigar, tea
4 beer, cigar, wine
5 beer, tea, wine2
4
(beer)
(wine)
2
(cigar)
4
3
5
5
(tea)
3 bud-tree

2: ANONYMIZATION WITH TAXONOMY TREE
Alternate k-bud tree and modify T simultaneously to achieve k-support anonymity Insertion Split Increase
33
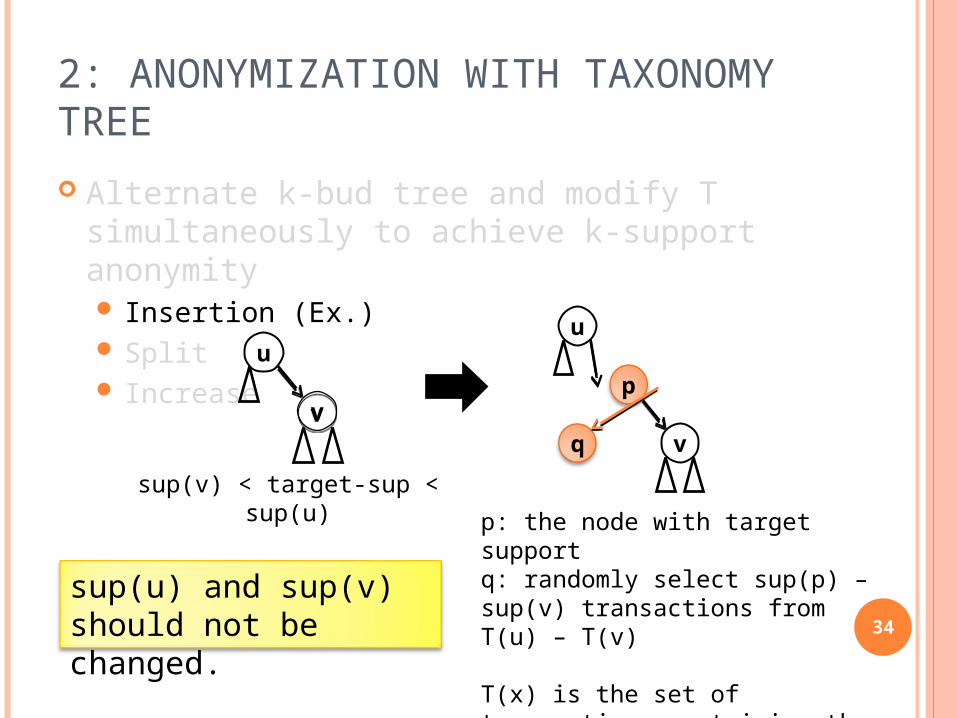
2: ANONYMIZATION WITH TAXONOMY TREE
Alternate k-bud tree and modify T simultaneously to achieve k-support anonymity Insertion (Ex.) Split Increase
34
u
p
vq
u
vv
p: the node with target supportq: randomly select sup(p) – sup(v) transactions from T(u) – T(v)
T(x) is the set of transactions containing the item x.
sup(v) < target-sup < sup(u)
sup(u) and sup(v) should not be changed.

TID Items
1 wine
2 cigar, wine
3 cigar, tea
4 beer, cigar, wine
5 beer, tea, wine
2
4
(beer)
(wine)
2
(cigar)
4
3
5
5
(tea)
3-bud tree
4
5
2 2
(tea)
insertion
Items
wine, p1
cigar, wine, p1
cigar, tea
beer, cigar, wine
beer, tea, wine
p1
x
y
35
2: ANONYMIZATION WITH TAXONOMY TREE
For wine

2: ANONYMIZATION WITH TAXONOMY TREE
Alternate k-bud tree and modify T simultaneously to achieve k-support anonymity Insertion Split (Ex.) Increase
36
v
qpv
p: randomly select target-sup transactions from T(v)q: T(p) = T(v) – T(q)
T(x) is the set of transactions containing the item x.
target-sup < sup(v)
sup(v) should not be change.
Split operation can raise up leaf nodes to internal nodes!
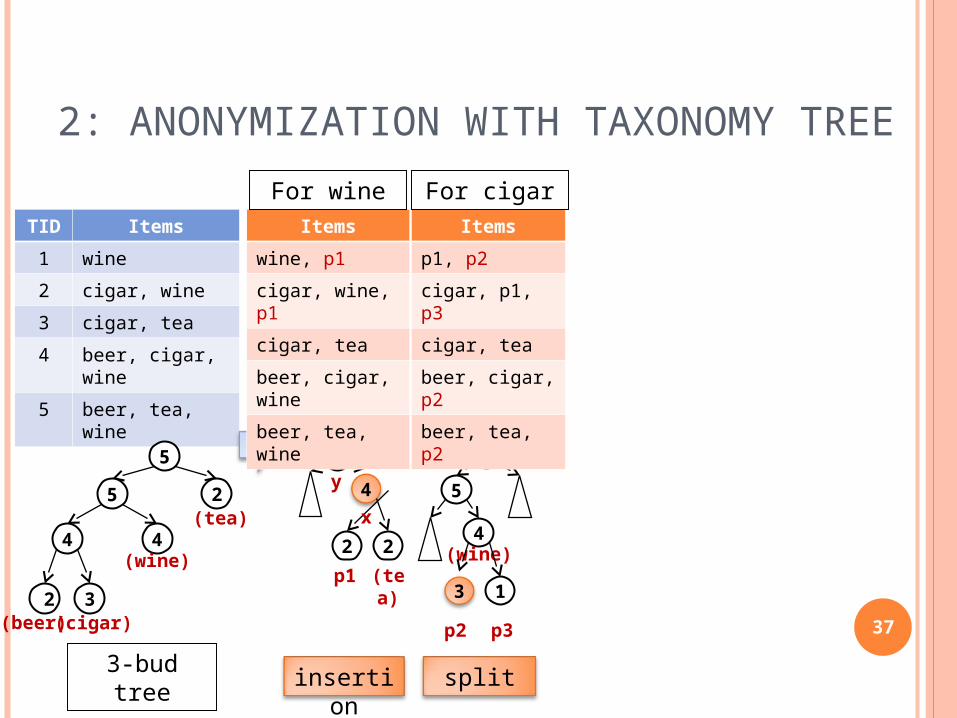
TID Items
1 wine
2 cigar, wine
3 cigar, tea
4 beer, cigar, wine
5 beer, tea, wine
2
4
(beer)
(wine)
2
(cigar)
4
3
5
5
(tea)
3-bud tree
4
5
2 2
(tea)
4(wine)
5
5
3 1
insertion
split
Items
wine, p1
cigar, wine, p1
cigar, tea
beer, cigar, wine
beer, tea, wine
Items
p1, p2
cigar, p1, p3
cigar, tea
beer, cigar, p2
beer, tea, p2
p1
p2 p3
x
y
37
2: ANONYMIZATION WITH TAXONOMY TREE
For wine For cigar

2: ANONYMIZATION WITH TAXONOMY TREE
Alternate k-bud tree and modify T simultaneously to achieve k-support anonymity Insertion Split Increase (Ex.)
38
u
v
u
v
sup(v) < target-sup randomly select target-sup – sup(v) transactions from T(u) – T(v)
sup(v) should not be changed. So, Increase operation is applicable only on node that does not belong to any anonymous group!

TID Items
1 wine
2 cigar, wine
3 cigar, tea
4 beer, cigar, wine
5 beer, tea, wine
2
4
(beer)
(wine)
2
(cigar)
4
3
5
5
(tea)
3-bud tree
4
5
2 2
(tea)
4(wine)
5
5
3 1
insertion
4(wine)
5
5
3
split increase
Items
wine, p1
cigar, wine, p1
cigar, tea
beer, cigar, wine
beer, tea, wine
Items
p1, p2
cigar, p1, p3
cigar, tea
beer, cigar, p2
beer, tea, p2
Items
p1, p2, p3
cigar, p1, p3
cigar, tea
beer, cigar, p2
beer, tea, p2, p3
p1
p2 p3 p3
x
y
39
2: ANONYMIZATION WITH TAXONOMY TREE
For wine For cigar For cigar

TID Items
1 wine
2 cigar, wine
3 cigar, tea
4 beer, cigar, wine
5 beer, tea, wine
2
4
(beer)
(wine)
2
(cigar)
4
3
5
5
(tea)
3-bud tree
TID Items
1 c, d, g
2 b, d, g
3 b, h
4 a, b, c
5 a, c, d, h
3-support anonymity
4
5
2 2
(tea)
4(wine)
5
5
3 1
insertion
2
4
a(beer
)
f(wine)
4
b(cigar
)
4
3
5
5
3 3
2 2
h(tea
)
c d
ge
i j
k
4(wine)
5
5
3
split increase
Items
wine, p1
cigar, wine, p1
cigar, tea
beer, cigar, wine
beer, tea, wine
Items
p1, p2
cigar, p1, p3
cigar, tea
beer, cigar, p2
beer, tea, p2
Items
p1, p2, p3
cigar, p1, p3
cigar, tea
beer, cigar, p2
beer, tea, p2, p3
p1
p2 p3 p3
x
y
40
2: ANONYMIZATION WITH TAXONOMY TREE
For wine For cigar For cigar

OUTLINE
Preliminary – Frequent ItemSet Mining Motivation Privacy Model – K-Support Anonymity Algorithm Performance Studies Conclusion
41

PERFORMANCE STUDIES
Data sets Retail dataset
88162 transactions with 2117 different items T10I1kD100k dataset
100k transactions with 1000 different items
Security Against precise item support attacks Against precise itemset support attacks
Storage overhead Execution efficiency
42

SECURITY
Against precise item support attacks Item accuracy: The ratio of items being re-identified DB accuracy: The avg. ratio of items in a
transaction being re-identified
4343
(a) Retail dataset (b) T10I1kD100k dataset

SECURITY
Against precise itemset support attacks Item accuracy: The ratio of items being re-identified DB accuracy: The avg. ratio of items in a
transaction being re-identified
4444
(a) Retail dataset (b) T10I1kD100k dataset
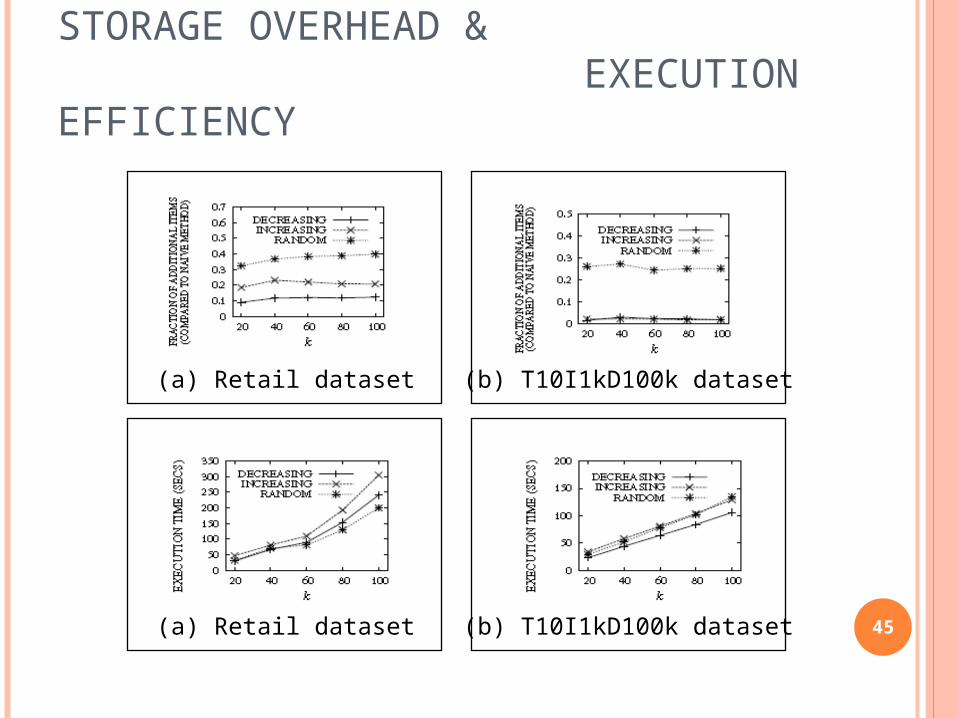
STORAGE OVERHEAD & EXECUTION EFFICIENCY
45
(a) Retail dataset (b) T10I1kD100k dataset
(a) Retail dataset (b) T10I1kD100k dataset

SUMMARY We proposed k-support anonymity to
enhance the privacy protection in outsourcing of frequent itemset mining (FIM).
For storage efficiency, we transformed FIM to GFIM, and proposed a taxonomy-based anonymization algorithm.
Our method allows the data owner to obtain the real frequent itemsets in 1 scan of the returned results.
Experimental results on both real and synthetic data sets showed that our method can achieve very good privacy protection with moderate storage overhead. 46

Q & A