scicomp15 - programming ibm powerxcell 8i
TRANSCRIPT

ScicomP 15 5/18/2009 © 2009 IBM Corporation1
Programming IBM PowerXcell 8i / QS22libSPE2, ALF, DaCS
Jordi Caubet. IBM Spain.IBM Innovation Initiative @ BSC-CNS
ScicomP 1518-22 May 2009, Barcelona, Spain

© 2009 IBM CorporationScicomP 15 5/18/20092
Overview
� SPE Runtime Management Library
� Communication Mechanisms
– Mailboxes, DMA, Signals
� SIMD
� Accelerator Library Framework (ALF)
� Data Communications and Synchronization (DaCS)

© 2009 IBM CorporationScicomP 15 5/18/20093
SPE Runtime Management Library v2.3 (libSPE2)
� The SPE runtime management library (libspe) contains the SPE thread
programming model for Cell BE applications
� is used to control SPE program execution from the PPE program
� Licensed under the GNU LPGL
� Design is independent of the underlying operating system
– can run on a variety of OS platforms
� In Linux implementation, it uses of the SPU File System (SPUFS) as the Linux
kernel interface
� Handles SPEs as virtual objects called SPE contexts
– SPE programs can be loaded and executed by operating SPE contexts
� The elfspe enables direct SPE executable execution from a Linux shell without the need for a PPE application creating an SPE thread

© 2009 IBM CorporationScicomP 15 5/18/20094
SPE Runtime Management Library v2.3Terminology
� SPE context: – Holds all persistent information about
a "logical SPE" used by the application.
� Gang context:– Holds all persistent information about
a group of SPE contexts that should be treated as a gang, that is, be executed together with certain properties.
Notes: Context’s data structure should not be accessed directly; instead the application uses a pointer to an SPE gang context as an identifier for the SPE gang it is dealing with through libspeAPI calls
� Main thread: – The application’s main thread.
– A typical CellBE application consists a main thread that creates as many SPE threads as needed and “orchestrates” them
� SPE thread: – A regular thread executing on the PPE that actually
runs an SPE context
– The API call spe_context_run is a synchronous, blocking call from the perspective of the thread using it, that is, while an SPE program is executed, the associated SPE thread blocks and is usually put to “sleep” by the operating system
� SPE event: – A mechanism for asynchronous notification.
– Typical usage is the main thread sets up an event handler to receive notification about certain events caused by the asynchronously running SPE threads.
– The current library supports events to indicate that an SPE has stopped execution, mailbox messages being written or read by an SPE, and PPE-initiated DMA operations have completed.

© 2009 IBM CorporationScicomP 15 5/18/20095
SPE Runtime Management Library v2.3Functionality
� In order to provide this functionality, the SPE Runtime Management Library
consists of various sets of PPE functions:
1. A set of PPE functions to create and destroy SPE and gang contexts.
2. A set of PPE functions to load SPE objects into SPE local store memory for
execution.
3. A set of PPE functions to start the execution of SPE programs and to obtain
information on reasons why an SPE has stopped running.
4. A set of PPE functions to receive asynchronous events generated by an SPE.
5. A set of PPE functions used to access the MFC (Memory Flow Control) problem
state facilities, which includes
a. MFC proxy command issue
b. MFC proxy tag-group completion facility
c. Mailbox facility
d. SPE signal notification facility
6. A set of PPE functions that enable direct application access to an SPE’s local store
and problem state areas.
7. Means to register PPE-assisted library calls for an SPE program.

© 2009 IBM CorporationScicomP 15 5/18/20096
SPE Runtime Management Library v2.3Function list
� SPE Context Creation
– spe_context_create
– spe_context_destroy
– spe_gang_context_create
– spe_gang_context_destroy
� SPE Program Image Handling
– spe_image_open
– spe_image_close
– spe_program_load
� SPE Run Control
– spe_context_run
– spe_stop_info_read
� SPE Event Handling
– spe_event_handler_create
– spe_event_handler_destroy
– spe_event_handler_register
– spe_event_handler_deregister
– spe_event_wait
� SPE MFC Proxy Command Issue
– spe_mfcio_put, spe_mfcio_putb, spe_mfcio_putf
– spe_mfcio_get, spe_mfcio_getb, spe_mfcio_getf
� SPE MFC Proxy Tag-Group Completion Facility
– spe_mfcio_tag_status_read
– spe_out_mbox_read
– spe_out_mbox_status
– spe_in_mbox_write
– spe_in_mbox_status
– spe_out_intr_mbox_read
– spe_out_intr_mbox_status
� SPE SPU Signal Notification Facility
– spe_signal_write
� Direct SPE Access for Applications
– spe_ls_area_get
– spe_ls_size_get
– spe_ps_area_get
� PPE-assisted Library Calls
– spe_callback_handler_register
– spe_callback_handler_deregister

© 2009 IBM CorporationScicomP 15 5/18/20097
SPE Runtime Management Library v2.3Single thread
� A simple application uses a single PPE thread, that is, the application’s PPE
thread
� The basic scheme for a simple application using an SPE is as follows:
1. Create an SPE context
2. Load an SPE executable object into the SPE context’s local store
3. Run SPE context – this transfers control to the operating
system requesting the actual scheduling of the context to a physical SPE in the system
4. Destroy SPE context
� Note that step 3 represents a synchronous call to the operating system.
The calling application’s PPE thread blocks until the SPE stops execution
and the operating system returns from the system call invoking the SPE
execution

© 2009 IBM CorporationScicomP 15 5/18/20098
SPE Runtime Management Library v2.3Hello World single thread sample
#include <stdio.h>
int main( unsigned long long speid, unsigned long long argp,
unsigned long long envp ) {
printf("Hello World!\n");
return 0;
}
#include <errno.h>
…
#include <libspe2.h>
extern spe_program_handle_t hello_spu;
int main( void) {
spe_context_ptr_t speid; // Structure for an SPE context
unsigned int flags = 0; unsigned int entry = SPE_DEFAULT_ENTRY;
void * argp = NULL; void * envp = NULL;
spe_stop_info_t stop_info;
int rc;
// Create an SPE context
speid = spe_context_create(flags, NULL);
if (speid == NULL) { perror("spe_context_create"); return -2; }
// Load an SPE executable object into the SPE context local store
if (spe_program_load(speid, &hello_spu) )
{ perror("spe_program_load"); return -3; }
// Run the SPE context
rc = spe_context_run(speid, &entry, 0, argp, envp, &stop_info);
if (rc < 0) perror("spe_context_run");
spe_context_destroy(speid); // Destroy the SPE context
return 0;
}
SPE program hello_spuPPE program
spe_context_ptr_t spe_context_create(unsigned int flags, spe_gang_context_ptr_t gang)
flags A bit-wise OR of modifiers that are applied when the SPE context is created.
gang Associate the new SPE context with this gang context. If NULL is specified, the new SPE context is
not associated with any gang.
On success, a pointer to the newly created SPE context is returned.
int spe_program_load (spe_context_ptr_t spe, spe_program_handle_t *program)
spe A valid pointer to the SPE context for which an SPE program should be loaded.
program A valid address of a mapped SPE program
On success, 0 (zero) is returned. spe_program_load loads an SPE main program that has been mapped to memory at theaddress pointed to by program into the local store of the SPE identified by the SPE context spe. This is mandatory before
running the SPE context with spe_context_run.
int spe_context_run( spe_context_ptr_t spe, unsigned int *entry, unsigned int runflags, void *argp, void *envp, spe_stop_info_t *stopinfo)
spe A pointer to the SPE context that should be run.
entry Input: The entry point, that is, the initial value of the SPU instruction pointer, at which the SPE program should start executing. If the value of entry is SPE_DEFAULT_ENTRY, the entry point for the SPU main program is obtained from the loaded SPE image. This is usually the local store address of the initialization function crt0.
Output: The SPU instruction pointer at the moment the SPU stopped execution, that is, the local store address of the next instruction that would be have been executed.
runflags A bit mask that can be used to request certain specific behavior for the execution of the SPE context. If the value is 0, this indicates default behavior (see Usage).
argp An (optional) pointer to application specific data, and is passed as the second parameter to the SPE program.
envp An (optional) pointer to environment specific data, and is passed as the third parameter to the SPE program.
Stopinfo An (optional) pointer to a structure of type spe_stop_info_t .
On success, 0 (zero) or a positive number is returned.

© 2009 IBM CorporationScicomP 15 5/18/20099
SPE Runtime Management Library v2.3Request execution of an SPE context
� A SPE program must be loaded (using spe_program_load) before you can run the SPE context.
� The thread calling spe_context_run blocks and waits until the SPE stops, due to normal termination of the SPE program, or an SPU stop and signal instruction, or an error condition. When spe_context_runreturns, the calling thread must take appropriate actions depending on the application logic.
� spe_context_run returns information about the termination of the SPE program in three ways. This allows applications to deal with termination conditions on various levels.
– First, the most common usage for many applications is covered by the return value of the function and the errno value being set appropriately.
– Second, the optional stopinfo structure provides detailed information about the termination condition in a structured way that allows applications more fine-grained error handling and enables implementation of special scenarios.
– Third, the stopinfo structure contains the field spu_status that contains the value of the CBEA SPU Status Register (SPU_Status) as specified in the Cell Broadband Engine Architecture, Version 1, section 8.5.2 upon termination of the SPE program. This can be very useful, especially in conjunction with the SPE_NO_CALLBACKS flag, for applications that run non-standard SPE programs and want to react to all possible conditions flexibly and not rely on predefined conventions.

© 2009 IBM CorporationScicomP 15 5/18/200910
SPE Runtime Management Library v2.3Single Thread Asynchronous Execution Example
� The application creates one PPE thread
� The PPE thread will run an SPE context at a time
� The basic scheme for a simple application running 1 SPE contextsasynchronously is
1. Create an SPE context
2. Load the appropriate SPE executable object into the SPE context’s
local store
3. Create a PPE thread
a. Run the SPE context in the PPE thread
b. Terminate the PPE thread
4. Wait for the PPE thread to terminate
5. Destroy the SPE context

© 2009 IBM CorporationScicomP 15 5/18/200911
SPE Runtime Management Library v2.3Single Thread Asynchronous Execution Example
#include <errno.h>
#include <stdio.h>
#include <stdlib.h>
#include <libspe2.h>
#include <pthread.h>
// Structure for an SPE thread
typedef struct ppu_pthread_data{
spe_context_ptr_t context;
pthread_t pthread;
unsigned int entry;
unsigned int flags;
void *argp;
void *envp;
spe_stop_info_t stopinfo;
} ppu_pthread_data_t;
// pthread function to run the SPE context
void *ppu_pthread_function(void *arg)
{
ppu_pthread_data_t *datap = (ppu_pthread_data_t *)arg;
int rc;
rc = spe_context_run(datap->context, &datap->entry, datap->flags, datap->argp, datap->envp, &datap->stopinfo);
pthread_exit(NULL);
}
extern spe_program_handle_t hello_spu;
int main(void)
{
ppu_pthread_data_t data;
data.context = spe_context_create(0, NULL);
spe_program_load(data.context, &hello_spu);
data.entry = SPE_DEFAULT_ENTRY;
data.flags = 0;
data.argp = NULL;
data.envp = NULL;
pthread_create( &data.pthread, NULL, &ppu_pthread_function, &data);
pthread_join(data.pthread, NULL);
spe_context_destroy(data.context);
return 0;
}
pthread
header file
Add pthread_t to
the SPE context
data structure
Define a pthread
function so we
can run the SPE
contextCall the ppu_thread_function to
run the context in the PPE
thread
Define data and fill it with
necessary context data
and then load SPE program
image
Wait until the PPE
thread terminate

© 2009 IBM CorporationScicomP 15 5/18/200912
SPE Runtime Management Library v2.3Multi-thread
� Many applications need to use multiple SPEs concurrently
� In this case, it is necessary for the application to create at least as many PPE threads as concurrent SPE contexts are required
� Each of these PPE threads may run a single SPE context at a time
� If N concurrent SPE contexts are needed, it is common to have a main application thread plus N PPE threads dedicated to SPE context execution
� The basic scheme for a simple application running N SPE contexts is
1. Create N SPE contexts
2. Load the appropriate SPE executable object into each SPE context’s local store
3. Create N PPE threads
a. In each of these PPE threads run one of the SPE contexts
b. Terminate the PPE thread
4. Wait for all N PPE threads to terminate
5. Destroy all N SPE contexts

© 2009 IBM CorporationScicomP 15 5/18/200913
SPE Runtime Management Library v2.3Multi Thread Asynchronous Execution Example
#include <stdlib.h>
#include <stdio.h>
#include <errno.h>
#include <libspe2.h>
#include <pthread.h>
extern spe_program_handle_t simple_spu;
#define SPU_THREADS 6
void *ppu_pthread_function(void *arg) {
spe_context_ptr_t ctx;
unsigned int entry = SPE_DEFAULT_ENTRY;
ctx = *((spe_context_ptr_t *)arg);
if (spe_context_run(ctx, &entry, 0, NULL, NULL, NULL) < 0) {
perror ("Failed running context");
exit (1);
}
pthread_exit(NULL);
}
Define a pthreadfunction so we can
run the SPE context

© 2009 IBM CorporationScicomP 15 5/18/200914
SPE Runtime Management Library v2.3Multi Thread Asynchronous Execution Example
int main()
{
int i;
spe_context_ptr_t ctxs[SPU_THREADS];
pthread_t threads[SPU_THREADS];
/* Create several SPE-threads to execute 'simple_spu'.
*/
for(i=0; i<SPU_THREADS; i++) {
/* Create context */
if ((ctxs[i] = spe_context_create (0, NULL)) == NULL) {
perror ("Failed creating context");
exit (1);
}
/* Load program into context */
if (spe_program_load (ctxs[i], &simple_spu)) {
perror ("Failed loading program");
exit (1);
}
/* Create thread for each SPE context */
if (pthread_create (&threads[i], NULL, &ppu_pthread_function, &ctxs[i])) {
perror ("Failed creating thread");
exit (1);
}
}
/* Wait for SPU-thread to complete execution.
*/
for (i=0; i<SPU_THREADS; i++) {
if (pthread_join (threads[i], NULL)) {
perror("Failed pthread_join");
exit (1);
}
}
printf("\nThe program has successfully executed.\n");
return (0);
}
Fork a pthread thread
giving thread id,
function, and data

© 2009 IBM CorporationScicomP 15 5/18/200915
Overview
� SPE Runtime Management Library
� Communication Mechanisms
– MFC / DMA, Mailboxes, Signals
� SIMD
� Accelerator Library Framework (ALF)
� Data Communications and Synchronization (DaCS)
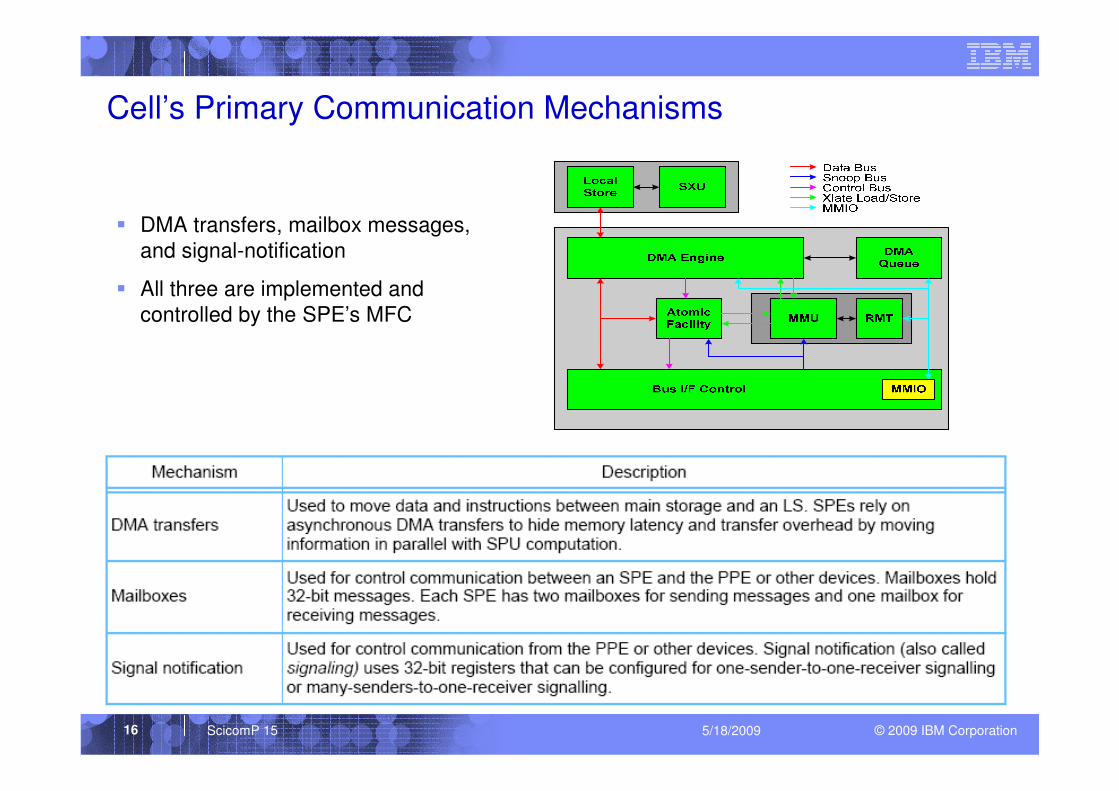
© 2009 IBM CorporationScicomP 15 5/18/200916
Cell’s Primary Communication Mechanisms
� DMA transfers, mailbox messages,
and signal-notification
� All three are implemented and
controlled by the SPE’s MFC

© 2009 IBM CorporationScicomP 15 5/18/200917
Storage Domain Communication Concepts
� An SPE program references its own LS using a Local Store Address (LSA).
� The LS of each SPE is also assigned a Real Address (RA) range within the system's memory map.
PPE maps LS areas into the Effective Address (EA) space, where the PPE and other SPEsgenerate EAs can access the LS like any regular component on the main storage.
Allows SPEs to use DMA to directly transfer data between their LS to another SPE’s LS.
This mode of data transfer is very efficient, because the DMA transfers go directly from SPE to SPE on the high performance local bus without involving the system memory.
� A code that runs on an SPU can only fetch instructions from its own LS, and loads and stores can only access that LS.
� Data transfers between the SPE's LS and main storage are primarily executed using DMA transfers controlled by the MFC DMA controller for that SPE.
� Each SPE's MFC serves as a data-transfer engine.
� DMA transfer requests contain both an LSA and an EA.
EIB (up to 96B/cycle)
SPE
LS
SXU
SPU
MFC
LS
SXU
SPU
MFC
LS
SXU
SPU
MFC
LS
SXU
SPU
MFC
LS
SXU
SPU
MFC
LS
SXU
SPU
MFC
LS
SXU
SPU
MFC
LS
SXU
SPU
MFC
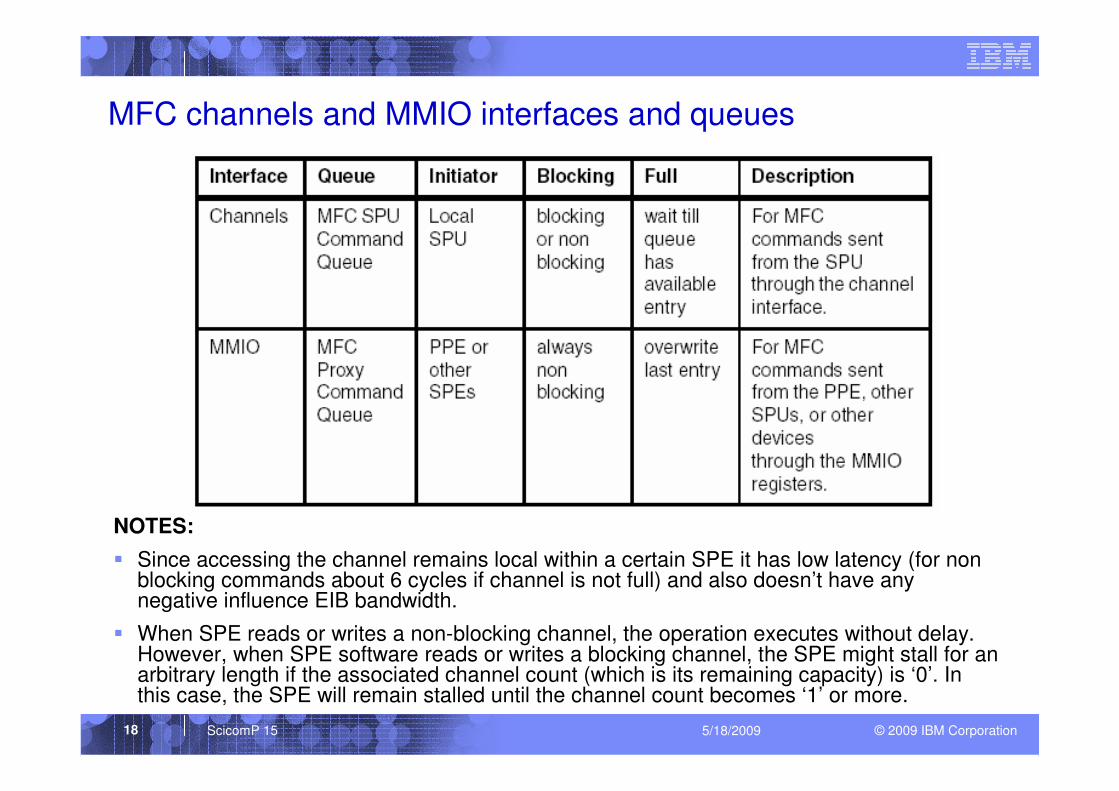
© 2009 IBM CorporationScicomP 15 5/18/200918
MFC channels and MMIO interfaces and queues
NOTES:
� Since accessing the channel remains local within a certain SPE it has low latency (for non blocking commands about 6 cycles if channel is not full) and also doesn’t have any negative influence EIB bandwidth.
� When SPE reads or writes a non-blocking channel, the operation executes without delay. However, when SPE software reads or writes a blocking channel, the SPE might stall for an arbitrary length if the associated channel count (which is its remaining capacity) is ‘0’. In this case, the SPE will remain stalled until the channel count becomes ‘1’ or more.

© 2009 IBM CorporationScicomP 15 5/18/200919
MFC Commands
� Main mechanism for SPUs to
– access main storage (DMA commands)
– maintain synchronization with other processors and devices in the system (Synchronization commands)
� Can be issued either SPU via its MFC by PPE or other device, as follows:
– Code running on the SPU issues an MFC command by executing a series of writes and/or reads using channel instructions - read channel (rdch), write channel (wrch), and read channel count (rchcnt).
– Code running on the PPE or other devices issues an MFC command by performing a series of stores and/or loads to memory-mapped I/O (MMIO) registers in the MFC
� MFC commands are queued in one of two independent MFC command queues:
– MFC SPU Command Queue — For channel-initiated commands by the associated SPU
– MFC Proxy Command Queue — For MMIO-initiated commands by the PPE or other device
SPU Core (SXU)
Channel Unit
Local Store
MFC(DMA Unit)
SPU
SPE
To Element Interconnect Bus
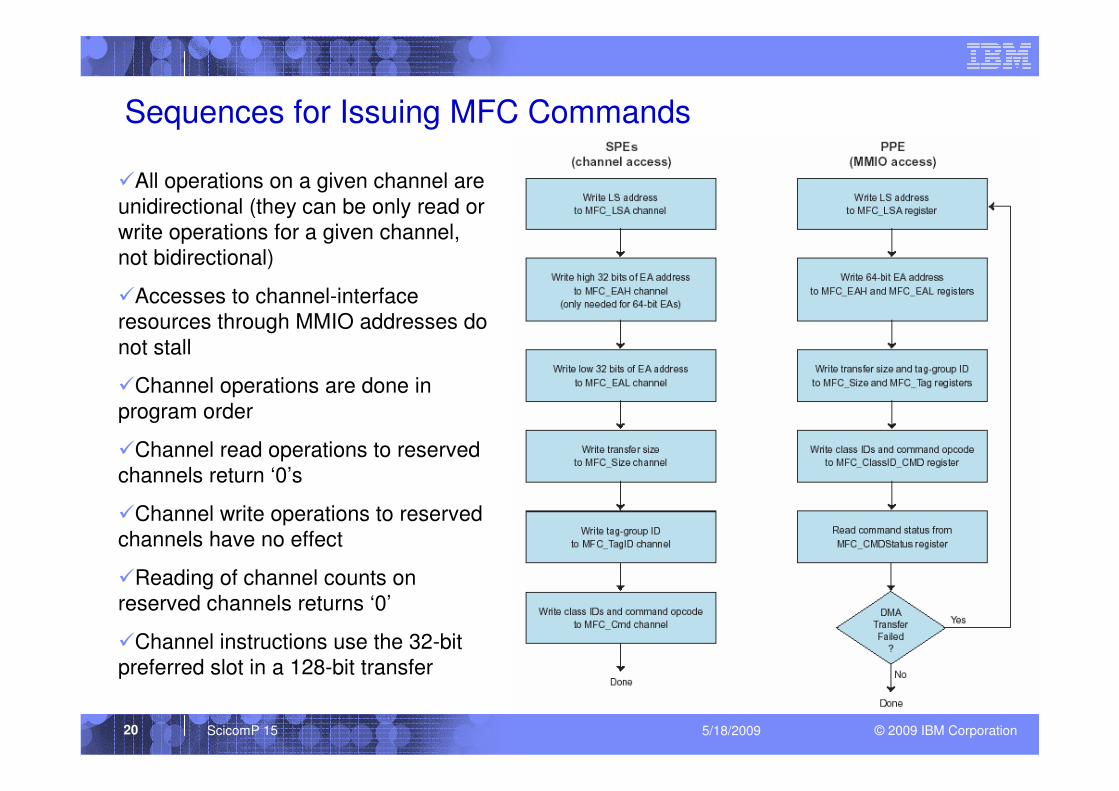
© 2009 IBM CorporationScicomP 15 5/18/200920
Sequences for Issuing MFC Commands
�All operations on a given channel are
unidirectional (they can be only read or
write operations for a given channel,
not bidirectional)
�Accesses to channel-interface
resources through MMIO addresses do
not stall
�Channel operations are done in
program order
�Channel read operations to reserved
channels return ‘0’s
�Channel write operations to reserved
channels have no effect
�Reading of channel counts on
reserved channels returns ‘0’
�Channel instructions use the 32-bit
preferred slot in a 128-bit transfer

© 2009 IBM CorporationScicomP 15 5/18/200921
DMA Overview

© 2009 IBM CorporationScicomP 15 5/18/200922
DMA Commands
� MFC commands that transfer data are referred to as DMA commands
� Transfer direction for DMA commands referenced from the SPE
� Into an SPE (from main storage to local store) � get
� Out of an SPE (from local store to main storage) � put

© 2009 IBM CorporationScicomP 15 5/18/200923
DMA Commands
Channel Control
Intrinsics
spu_writech
Composite
Intrinsics
spu_mfcdma32
MFC Commands
mfc_get
#include “spu_mfcio.h“
mfc_get(lsa, ea, size, tag, tid, rid);
// Implemented as the following composite intrinsic:
spu_mfcdma64(lsa, mfc_ea2h(ea), mfc_ea2l(ea), size, tag,
((tid<<24)|(rid<<16)|MFC_GET_CMD));
// wait until DMA transfer is complete (or do other things before that)
defined as macros in
spu_mfcio.h
mfc_get implemented as MFC command
and composite intrinsics
spu_writech(MFC_LSA, lsa);
spu_writech(MFC_EAH, eah);
spu_writech(MFC_EAL, eal);
spu_writech(MFC_Size, size);
spu_writech(MFC_TagID, tag);
spu_writech(MFC_CMD, 0x0040);
mfc_getimplemented as channel control
intrinsics
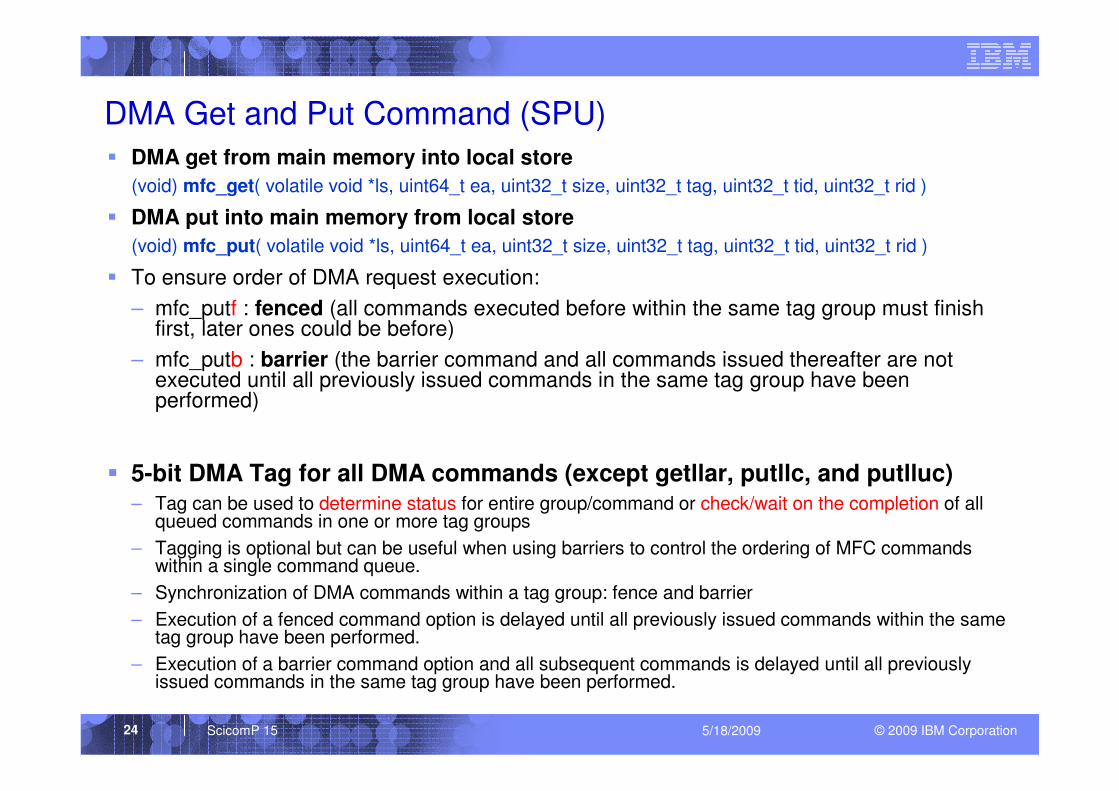
© 2009 IBM CorporationScicomP 15 5/18/200924
DMA Get and Put Command (SPU)
� DMA get from main memory into local store
(void) mfc_get( volatile void *ls, uint64_t ea, uint32_t size, uint32_t tag, uint32_t tid, uint32_t rid )
� DMA put into main memory from local store
(void) mfc_put( volatile void *ls, uint64_t ea, uint32_t size, uint32_t tag, uint32_t tid, uint32_t rid )
� To ensure order of DMA request execution:
– mfc_putf : fenced (all commands executed before within the same tag group must finish first, later ones could be before)
– mfc_putb : barrier (the barrier command and all commands issued thereafter are notexecuted until all previously issued commands in the same tag group have been performed)
� 5-bit DMA Tag for all DMA commands (except getllar, putllc, and putlluc) – Tag can be used to determine status for entire group/command or check/wait on the completion of all
queued commands in one or more tag groups
– Tagging is optional but can be useful when using barriers to control the ordering of MFC commands within a single command queue.
– Synchronization of DMA commands within a tag group: fence and barrier
– Execution of a fenced command option is delayed until all previously issued commands within the same tag group have been performed.
– Execution of a barrier command option and all subsequent commands is delayed until all previously issued commands in the same tag group have been performed.

© 2009 IBM CorporationScicomP 15 5/18/200925
Barriers and Fences – Synchronization Commands

© 2009 IBM CorporationScicomP 15 5/18/200926
DMA Characteristics
� DMA transfers
– transfer sizes can be 1, 2, 4, 8, and n*16 bytes (n integer)
– maximum is 16KB per DMA transfer
– 128B alignment is preferable
� DMA command queues per SPU
– 16-element queue for SPU-initiated requests
– 8-element queue for PPE-initiated requests
� SPU-initiated DMA is always preferable
� DMA tags
– each DMA command is tagged with a 5-bit identifier
– same identifier can be used for multiple commands
– tags used for polling status or waiting on completion of DMA commands
� DMA lists
– a single DMA command can cause execution of a list of transfer requests (in LS)
– lists implement scatter-gather functions
– a list can contain up to 2K transfer requests

© 2009 IBM CorporationScicomP 15 5/18/200927
PPE – SPE DMA Transfer
© 2009 IBM CorporationScicomP 15 5/18/200928
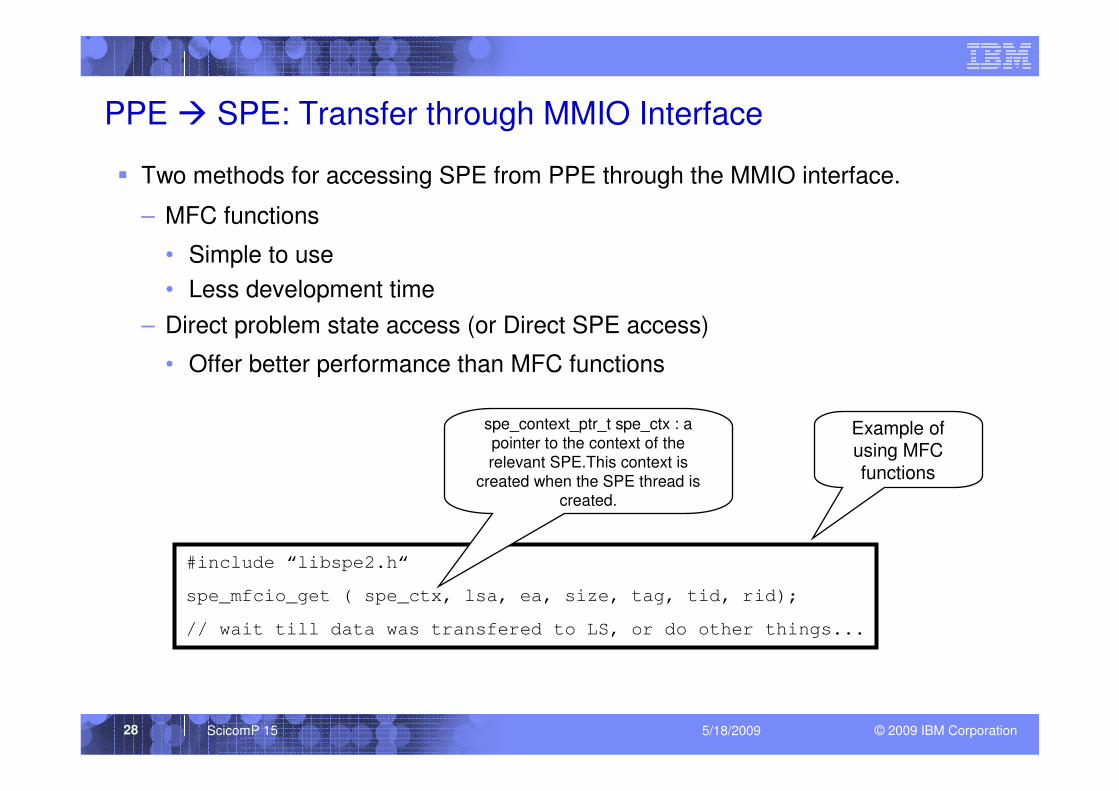
PPE � SPE: Transfer through MMIO Interface
� Two methods for accessing SPE from PPE through the MMIO interface.
– MFC functions
• Simple to use
• Less development time
– Direct problem state access (or Direct SPE access)
• Offer better performance than MFC functions
#include “libspe2.h“
spe_mfcio_get ( spe_ctx, lsa, ea, size, tag, tid, rid);
// wait till data was transfered to LS, or do other things...
Example of using MFC functions
spe_context_ptr_t spe_ctx : a pointer to the context of the relevant SPE.This context is
created when the SPE thread is created.
© 2009 IBM CorporationScicomP 15 5/18/200929
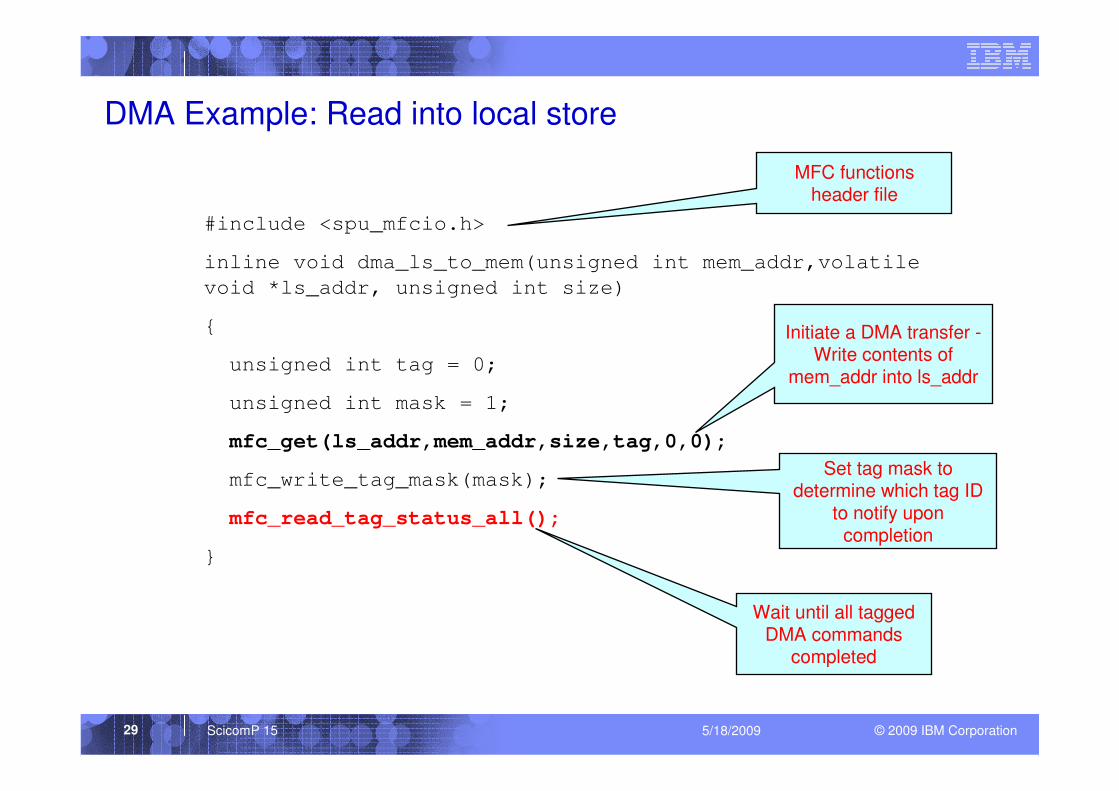
DMA Example: Read into local store
#include <spu_mfcio.h>
inline void dma_ls_to_mem(unsigned int mem_addr,volatile
void *ls_addr, unsigned int size)
{
unsigned int tag = 0;
unsigned int mask = 1;
mfc_get(ls_addr,mem_addr,size,tag,0,0);
mfc_write_tag_mask(mask);
mfc_read_tag_status_all();
}
Initiate a DMA transfer -Write contents of
mem_addr into ls_addr
Set tag mask to determine which tag ID
to notify upon completion
Wait until all tagged DMA commands
completed
MFC functions header file

© 2009 IBM CorporationScicomP 15 5/18/200930
DMA Example: Write to Main Memory
#include <spu_mfcio.h>
inline void dma_ls_to_mem(unsigned int mem_addr,volatile
void *ls_addr, unsigned int size)
{
unsigned int tag = 0;
unsigned int mask = 1;
mfc_put(ls_addr,mem_addr,size,tag,0,0);
mfc_write_tag_mask(mask);
mfc_read_tag_status_all();
}
Initiate a DMA transfer -Write contents of
mem_addr into ls_addr
Set tag mask to determine which tag ID
to notify upon completion
Wait until all tagged DMA commands
completed
MFC functions header file

© 2009 IBM CorporationScicomP 15 5/18/200931
Tips to Achieve Peak Bandwidth for DMAs
� The performance of a DMA data transfer is best when the source and
destination addresses have the same quadword offsets within a PPE
cache line.
� Quadword-offset-aligned data transfers generate full cache-line bus
requests for every unrolling, except possibly the first and last unrolling.
� Transfers that start or end in the middle of a cache line transfer a partial
cache line (less than 8 quadwords) in the first or last bus request, respectively.

© 2009 IBM CorporationScicomP 15 5/18/200932
Supported and recommended values for DMA parameters
� Direction: Data transfer may be in any of the two directions as referenced from the
perspective of an SPE:
– get commands: transfer data to a LA from the main storage.
– put commands: transfers data out of the LS to the main storage.
� Size: Transfer size should obey the following guidelines:
– Supported transfer sizes are 1, 2, 4, 8, or 16 bytes, and multiples of 16-bytes
– Maximum transfer size is 16 KB.
– Peak performance is achieved when transfer size is a multiple of 128 bytes.
� Alignment: Alignment of the LSA and the EA should obey the following guidelines:
– Source and destination addresses must have the same 4 least significant bits.
– For transfer sizes less than 16 bytes, address must be naturally aligned (bits 28 through
31 must provide natural alignment based on the transfer size).
– For transfer sizes of 16 bytes or greater, address must be aligned to at least a 16-byte
boundary (bits 28 through 31 must be ‘0’).
– Peak performance is achieved when both source and destination are aligned on a
128-byte boundary (bits 25 through 31 cleared to ‘0’).

© 2009 IBM CorporationScicomP 15 5/18/200933
Data transfer example
#include <stdio.h>
//#include <libspe.h>
//#include <libmisc.h>
#include <string.h>
#include <libspe2.h>
//spu program
extern spe_program_handle_t getbuf_spu;
//local buffer
unsigned char buffer[128] __attribute__ ((aligned(128)));
//spe context
spe_context_ptr_t speid;
unsigned int flags = 0;
unsigned int entry = SPE_DEFAULT_ENTRY;
spe_stop_info_t stop_info;
int rc;
int main (void)
{
strcpy (buffer, "Good morning!");
printf("Original buffer is %s\n", buffer);
speid = spe_context_create(flags, NULL);
spe_program_load(speid, &getbuf_spu);
rc = spe_context_run(speid, &entry, 0, buffer, NULL, &stop_info);
spe_context_destroy(speid);
printf("New modified buffer is %s\n", buffer);
return 0;
}
#include <stdio.h>
#include <string.h>
//#include <libmisc.h>
#include <spu_mfcio.h>
unsigned char buffer[128] __attribute__ ((aligned(128)));
int main( unsigned long long speid, unsigned long long argp, unsigned long long envp )
{
int tag = 31, tag_mask = 1<<tag;
// DMA in buffer from PPE
mfc_get(buffer, (unsigned long long)argp, 128, tag, 0, 0);
mfc_write_tag_mask(tag_mask);
mfc_read_tag_status_any();
printf("SPE received buffer \"%s\"\n", buffer);
// modify buffer
strcpy (buffer, "Guten Morgen!");
printf("SPE sent to PPU buffer \"%s\"\n", buffer);
// DMA out buffer to PPE
mfc_put( buffer, (unsigned long long) argp, 128, tag, 0, 0);
mfc_write_tag_mask(tag_mask);
mfc_read_tag_status_any();
return 0;
}
SPE programPPE program

© 2009 IBM CorporationScicomP 15 5/18/200934
Mailboxes

© 2009 IBM CorporationScicomP 15 5/18/200935
Mailboxes
� To communicate messages up to 32 bits in length, such as buffer completion flags or program status
– e.g., When the SPE places computational results in main storage via DMA. After requesting the DMA transfer, the SPE waits for the DMA transfer to complete and then writes to an outbound mailbox to notify the PPE that its computation is complete
� Can be used for any short-data transfer purpose, such as sending of storage addresses, function parameters, command parameters, and state-machine parameters
� Can also be used for communication between an SPE and other SPEs, processors, or devices
– Privileged software needs to allow one SPE to access the mailbox register in another SPE by mapping the target SPE’s problem-state area into the EA space of the source SPE. If software does not allow this, then only atomic operations and signal notifications are available for SPE-to-SPE communication.

© 2009 IBM CorporationScicomP 15 5/18/200936
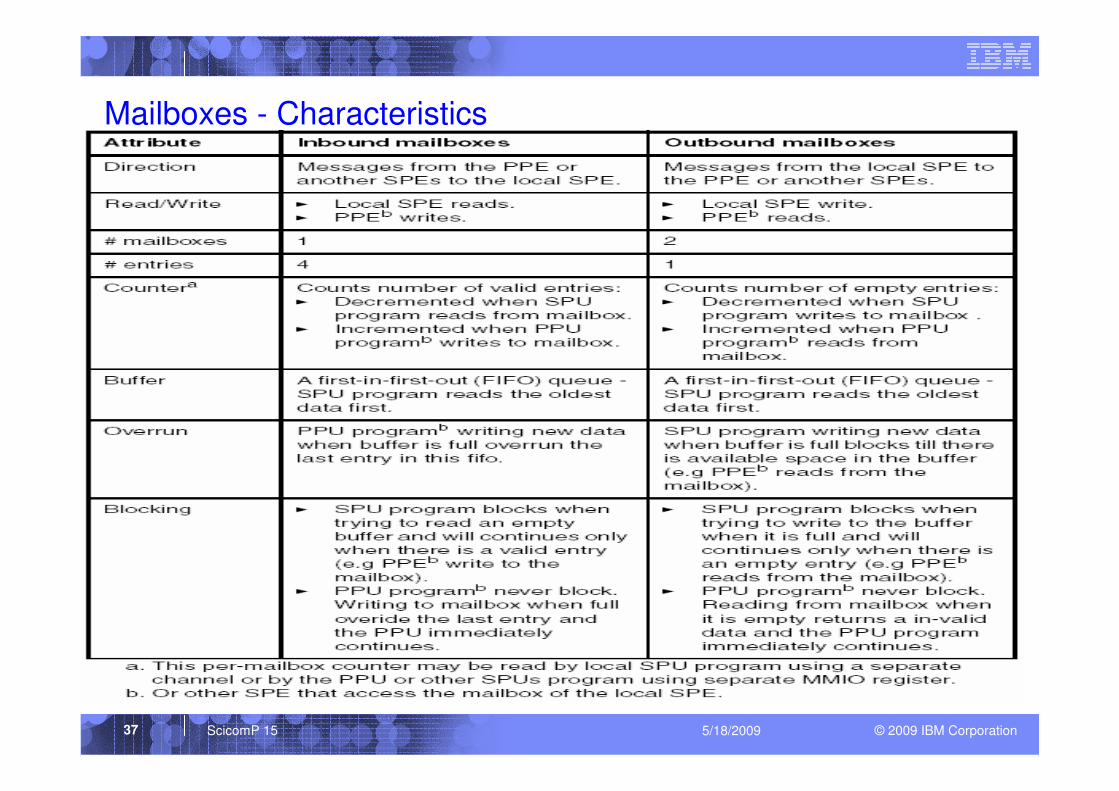
Mailboxes
Each MFC provides three mailbox queues of 32 bit each:
� Two Outbound mailboxes
To send messages from the local SPE to the PPE or other SPEs:
– SPU Write Outbound mailbox (SPU_WrOutMbox)
– SPU Write Outbound Interrupt mailbox (SPU_WrOutIntrMbox)
� One Inbound mailbox
To send messages to the local SPE from the PPE or other SPEs:
– SPU (“SPU read inbound”) mailbox queue.
� Each mailbox entry is a fullword
© 2009 IBM CorporationScicomP 15 5/18/200937
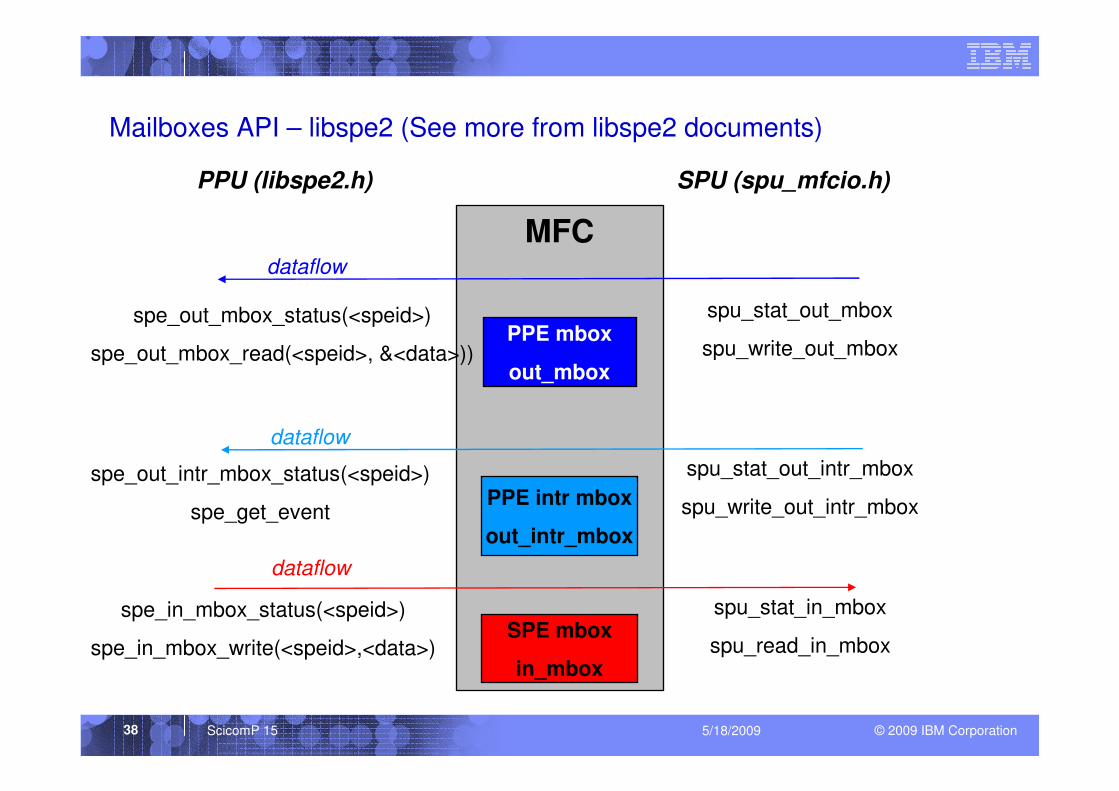
Mailboxes - Characteristics
© 2009 IBM CorporationScicomP 15 5/18/200938
Mailboxes API – libspe2 (See more from libspe2 documents)
MFC
PPE mbox
out_mbox
dataflow
spu_stat_out_mbox
spu_write_out_mbox
spe_out_mbox_status(<speid>)
spe_out_mbox_read(<speid>, &<data>))
PPE intr mbox
out_intr_mbox
spu_stat_out_intr_mbox
spu_write_out_intr_mbox
spe_out_intr_mbox_status(<speid>)
spe_get_event
dataflow
SPE mbox
in_mbox
spu_stat_in_mbox
spu_read_in_mbox
spe_in_mbox_status(<speid>)
spe_in_mbox_write(<speid>,<data>)
dataflow
PPU (libspe2.h) SPU (spu_mfcio.h)
© 2009 IBM CorporationScicomP 15 5/18/200939
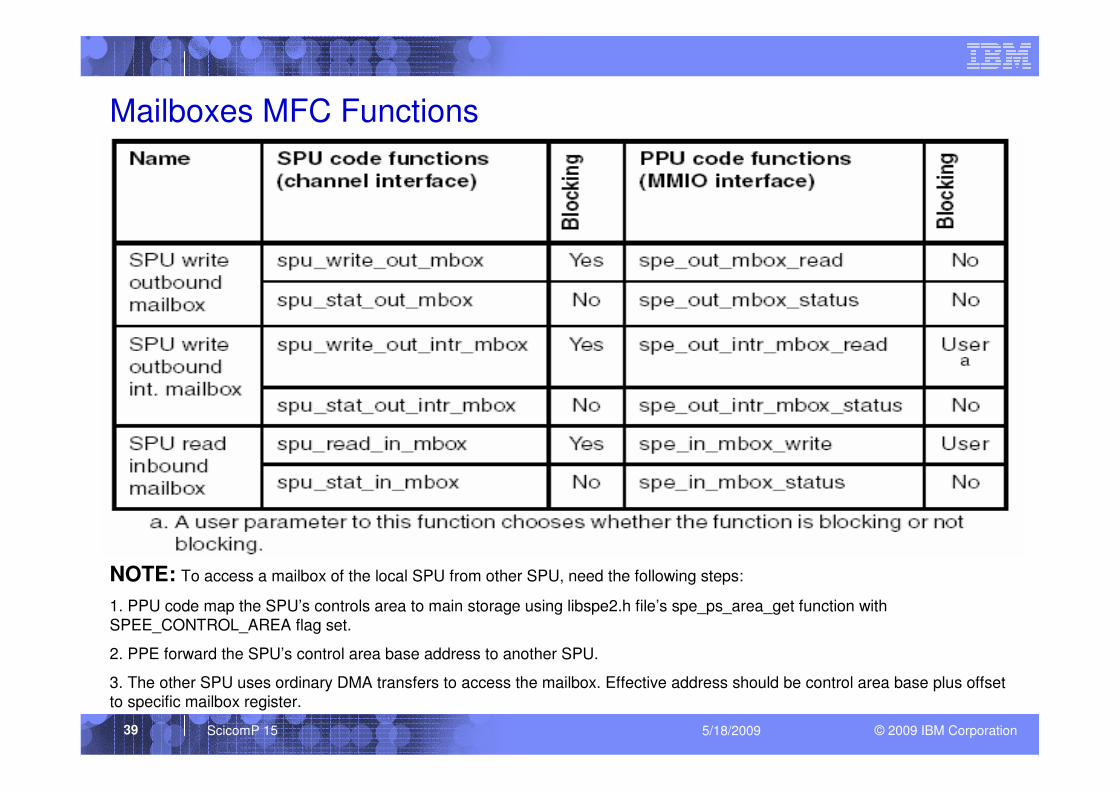
Mailboxes MFC Functions
NOTE: To access a mailbox of the local SPU from other SPU, need the following steps:
1. PPU code map the SPU’s controls area to main storage using libspe2.h file’s spe_ps_area_get function with SPEE_CONTROL_AREA flag set.
2. PPE forward the SPU’s control area base address to another SPU.
3. The other SPU uses ordinary DMA transfers to access the mailbox. Effective address should be control area base plus offset
to specific mailbox register.

© 2009 IBM CorporationScicomP 15 5/18/200940
Example of Using Mailboxes – PPE CodeAdding of two arrays on the SPU
#define MY_ALIGN(_my_var_def_, _my_al_) _my_var_def_ __attribute__((__aligned__(_my_al_)))
MY_ALIGN(float array_a[ARRAY_SIZE],128);
MY_ALIGN(float array_b[ARRAY_SIZE],128);
MY_ALIGN(float array_c[ARRAY_SIZE],128);
extern spe_program_handle_t array_spu_add;
int status;
void init_array() {
int i;
for(i=0;i<ARRAY_SIZE; i++)
{
array_a[i] = (float)(i * NUM);
array_b[i] = (float)((i * NUM)*2);
array_c[i] = 0.0f;
}
}
#include <libspe2.h>
#include <…
#define ARRAY_SIZE 1024
#define NUM 512
typedef struct ppu_thread_data {
spe_context_ptr_t context;
pthread_t pthread;
unsigned int entry;
unsigned int flags;
void *argp;
void *envp;
spe_stop_info_t stopinfo;
}ppu_pthread_data_t;

© 2009 IBM CorporationScicomP 15 5/18/200941
Example of Using Mailboxes – PPE Code
/* Create a spe context that we'll use to load our spe
program into */
threadData.context = spe_context_create(0, NULL);
/* Load our spe program: array_spu_add*/
spe_program_load( threadData.context,
&array_spu_add);
/* Setup our SPE program parameters*/
threadData.entry = SPE_DEFAULT_ENTRY;
threadData.flags = 0;
threadData.argp = NULL;
threadData.envp = NULL;
/* Now we can create thread to run on a SPE*/
pthread_create( &threadData.pthread, NULL,
&ppu_pthread_function,
&threadData);
// Setup mailbox messages (32-Bit ONLY)
mbox_data[0] = (unsigned int)&array_a[0];
mbox_data[1] = (unsigned int)&array_b[0];
mbox_data[2] = (unsigned int)&array_c[0];
(continues from previous page)
…
/* New thread*/
void *ppu_pthread_function(void *arg)
{
ppu_pthread_data_t *datap = (ppu_pthread_data_t *)arg;
spe_context_run( datap->context,
&datap->entry,
datap->flags,
datap->argp,
datap->envp,
&datap->stopinfo);
pthread_exit(NULL);
}
int main(void)
{
int i, retVal;
ppu_pthread_data_t threadData;
unsigned int *mbox_dataPtr;
unsigned int mbox_data[3];
init_array();
/* check for working hardware */
if (spe_cpu_info_get(SPE_COUNT_PHYSICAL_SPES, -1) < 1)
{
fprintf(stderr,
"System has no working SPEs. Exiting\n");
return -1;
}
…
(continues on right column)

© 2009 IBM CorporationScicomP 15 5/18/200942
Example of Using Mailboxes – PPE Code
/* wait for spe to finish */
pthread_join (threadData.pthread, NULL);
spe_context_destroy(threadData.context);
__asm__ __volatile__ ("sync" : : : "memory");
printf("Array Addition complete. Verifying
results...\n");
/* verifying */
for (i=0; i<ARRAY_SIZE; i++)
{
if (array_c[i] != (float)((i * NUM)*3))
{
printf("ERROR in matrix addition\n");
return 0;
}
}
printf(" Correct!\n");
return 0;
}
/* Send effective addresses of arrays to spe through
mailboxes*/
while (spe_in_mbox_status(threadData.context) == 0);
do
{
mbox_dataPtr = &mbox_data[0];
retVal = spe_in_mbox_write( threadData.context,
mbox_dataPtr, 1,
SPE_MBOX_ANY_NONBLOCKING);
}
while (retVal != 1);
while (spe_in_mbox_status(threadData.context) == 0);
do
{
mbox_dataPtr = &mbox_data[1];
retVal = spe_in_mbox_write(threadData.context,
mbox_dataPtr, 1,
SPE_MBOX_ANY_NONBLOCKING);
}
while (retVal !=1);
while (spe_in_mbox_status(threadData.context) == 0);
do
{
mbox_dataPtr = &mbox_data[2];
retVal = spe_in_mbox_write(threadData.context,
mbox_dataPtr, 1,
SPE_MBOX_ANY_NONBLOCKING);
}

© 2009 IBM CorporationScicomP 15 5/18/200943
Example of Using Mailboxes – SPE Code#include <stdio.h>
#include <spu_mfcio.h>
#define ARRAY_SIZE 1024
#define MY_ALIGN(_my_var_def_, _my_al_) _my_var_def_ __attribute__((__aligned__(_my_al_)))
MY_ALIGN(float array_a[ARRAY_SIZE],128);
MY_ALIGN(float array_b[ARRAY_SIZE],128);
MY_ALIGN(float array_c[ARRAY_SIZE],128);
int main(unsigned long long speid, unsigned long long argp, unsigned long long envp){
int i;
unsigned int Aaddr, Baddr, Caddr;
/* First: Read mailbox 3 times to get our array effective addresses */
Aaddr = (unsigned int) spu_read_in_mbox();
Baddr = (unsigned int) spu_read_in_mbox();
Caddr = (unsigned int) spu_read_in_mbox();
/*Now that we have the array EAs we can DMA our data over */
mfc_get(&array_a, Aaddr, (sizeof(float)*ARRAY_SIZE), 31, 0, 0);
mfc_get(&array_b, Baddr, (sizeof(float)*ARRAY_SIZE), 31, 0, 0);
mfc_write_tag_mask(1<<31);
mfc_read_tag_status_all();
/*array add*/
for(i=0; i<ARRAY_SIZE; i++)
{
array_c[i] = array_a[i] + array_b[i];
}
/* Finally, DMA computed array back to main memory*/
mfc_put(&array_c, Caddr, (sizeof(float)*ARRAY_SIZE), 31, 0, 0);
mfc_write_tag_mask(1<<31);
mfc_read_tag_status_all();
return 0;
}

© 2009 IBM CorporationScicomP 15 5/18/200944
SPU Write Outbound Mailbox
– The value written to the SPU Write Outbound Mailbox channel SPU_WrOutMbox is
entered into the outbound mailbox in the MFC if the mailbox has capacity to accept
the value.
– If the mailbox can accept the value, the channel count for SPU_WrOutMbox is
decremented by ‘1’.
– If the outbound mailbox is full, the channel count will read as ‘0’.
– If SPE software writes a value to SPU_WrOutMbox when the channel count is ‘0’, the
SPU will stall on the write.
– The SPU remains stalled until the PPE or other device reads a message from the
outbound mailbox by reading the MMIO address of the mailbox.
– When the mailbox is read through the MMIO address, the channel count is
incremented by ‘1’.

© 2009 IBM CorporationScicomP 15 5/18/200945
SPU Write Outbound Interrupt Mailbox
– The value written to the SPU Write Outbound Interrupt Mailbox channel (SPU_WrOutIntrMbox) is entered into the outbound interrupt mailbox if the mailbox has capacity to accept the value.
– If the mailbox can accept the message, the channel count for SPU_WrOutIntrMbox is decremented by ‘1’, and an interrupt is raised in the PPE or other device, depending on interrupt enabling and routing.
– There is no ordering of the interrupt and previously issued MFC commands.
– If the outbound interrupt mailbox is full, the channel count will read as ‘0’.
– If SPE software writes a value to SPU_WrOutIntrMbox when the channel count is ‘0’, the SPU will stall on the write.
– The SPU remains stalled until the PPE or other device reads a mailbox message from the outbound interrupt mailbox by reading the MMIO address of the mailbox.
– When this is done, the channel count is incremented by ‘1’.

© 2009 IBM CorporationScicomP 15 5/18/200946
PPU reads SPU Outbound Mailboxes
� PPU must check Mailbox Status Register first
– check that unread data is available in the SPU Outbound Mailbox or SPU Outbound
Interrupt Mailbox
– otherwise, stale or undefined data may be returned
� To determine that unread data is available
– PPE reads the Mailbox Status register
– extracts the count value from the SPU_Out_Mbox_Count field
� count is
– non-zero � at least one unread value is present
– zero � PPE should not read but poll the Mailbox Status register

© 2009 IBM CorporationScicomP 15 5/18/200947
SPU Read Inbound Mailbox Channel
� Mailbox is FIFO queue
– If the SPU Read Inbound Mailbox channel (SPU_RdInMbox) has a message, the value read from the mailbox is the oldest message written to the mailbox.
� Mailbox Status (empty: channel count =0)
– If the inbound mailbox is empty, the SPU_RdInMbox channel count will read as ‘0’.
� SPU stalls on reading empty mailbox
– If SPE software reads from SPU_RdInMbox when the channel count is ‘0’, the SPU will stall on the read. The SPU remains stalled until the PPE or other device writes a message to the mailbox by writing to the MMIO address of the mailbox.
� When the mailbox is written through the MMIO address, the channel count is incremented by ‘1’.
� When the mailbox is read by the SPU, the channel count is decremented by '1'.
� The SPU Read Inbound Mailbox can be overrun by a PPE in which case, mailbox message data will be lost.
� A PPE writing to the SPU Read Inbound Mailbox will not stall when this mailbox is full.

© 2009 IBM CorporationScicomP 15 5/18/200948
MFC Synchronization Commands
MFC synchronization commands
� Used to control the order in which DMA storage accesses are performed
� Four atomic commands (getllar, putllc, putlluc, and putqlluc),
� Three send-signal commands (sndsig, sndsigf, and sndsigb), and
� Three barrier commands (barrier, mfcsync, and mfceieio).

© 2009 IBM CorporationScicomP 15 5/18/200949
Overview
� SPE Runtime Management Library
� Communication Mechanisms
– Mailboxes, DMA, Signals
� SIMD
� Accelerator Library Framework (ALF)
� Data Communications and Synchronization (DaCS)
© 2009 IBM CorporationScicomP 15 5/18/200950
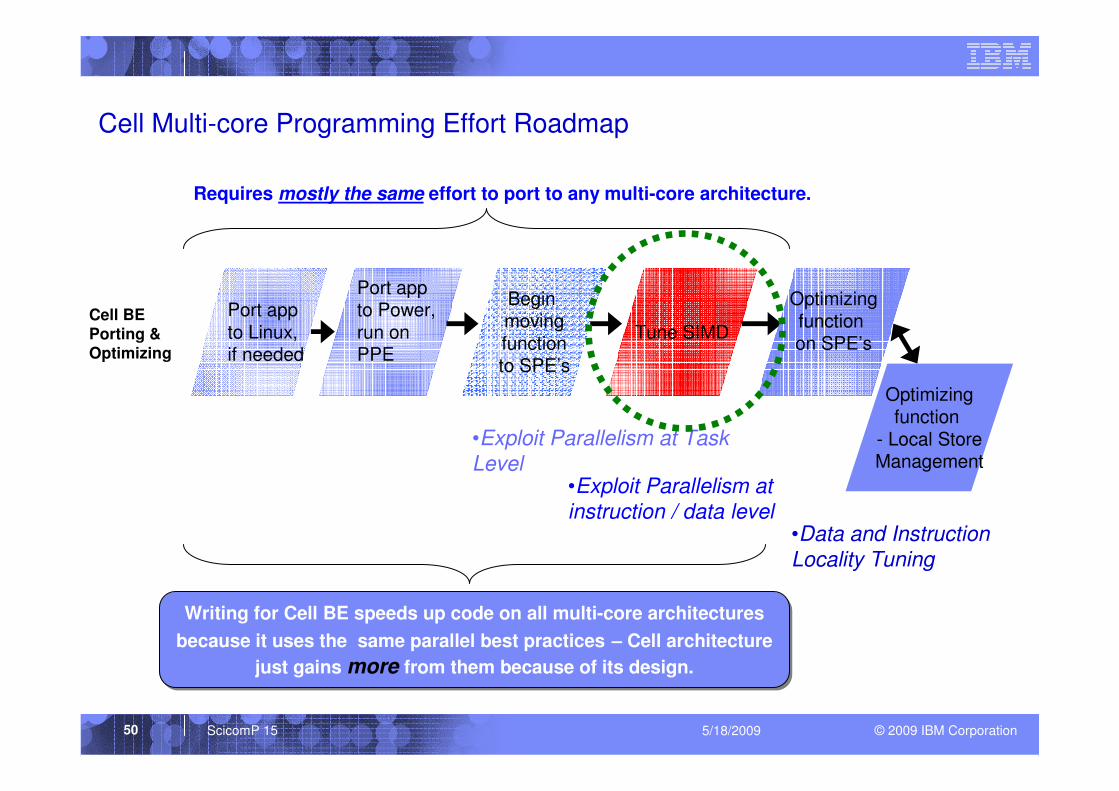
Cell Multi-core Programming Effort Roadmap
Cell BE Porting & Optimizing
Port appto Linux,if needed
Port app to Power,run on PPE
Begin movingfunctionto SPE’s
Tune SIMD
Optimizingfunction on SPE’s
Optimizingfunction
- Local StoreManagement
Requires mostly the same effort to port to any multi-core architecture.
•Exploit Parallelism at Task
Level•Exploit Parallelism at
instruction / data level•Data and Instruction
Locality Tuning
Writing for Cell BE speeds up code on all multi-core architectures
because it uses the same parallel best practices – Cell architecture
just gains more from them because of its design.
Writing for Cell BE speeds up code on all multi-core architectures
because it uses the same parallel best practices – Cell architecture
just gains more from them because of its design.

© 2009 IBM CorporationScicomP 15 5/18/200951
SIMD Architecture
� SIMD = “single-instruction multiple-data”
� SIMD exploits data-level parallelism
– a single instruction can apply the same operation to multiple data elements in
parallel
� SIMD units employ “vector registers” which holds multiple data elements
� SIMD is pervasive in the BE
– PPE includes VMX (SIMD extensions to PPC architecture)
– SPE is a native SIMD architecture (VMX-like)
� SIMD in VMX and SPE
– 128bit-wide datapath
– 128bit-wide registers
– 4-wide fullwords, 8-wide halfwords, 16-wide bytes
– SPE includes support for 2-wide doublewords
© 2009 IBM CorporationScicomP 15 5/18/200952
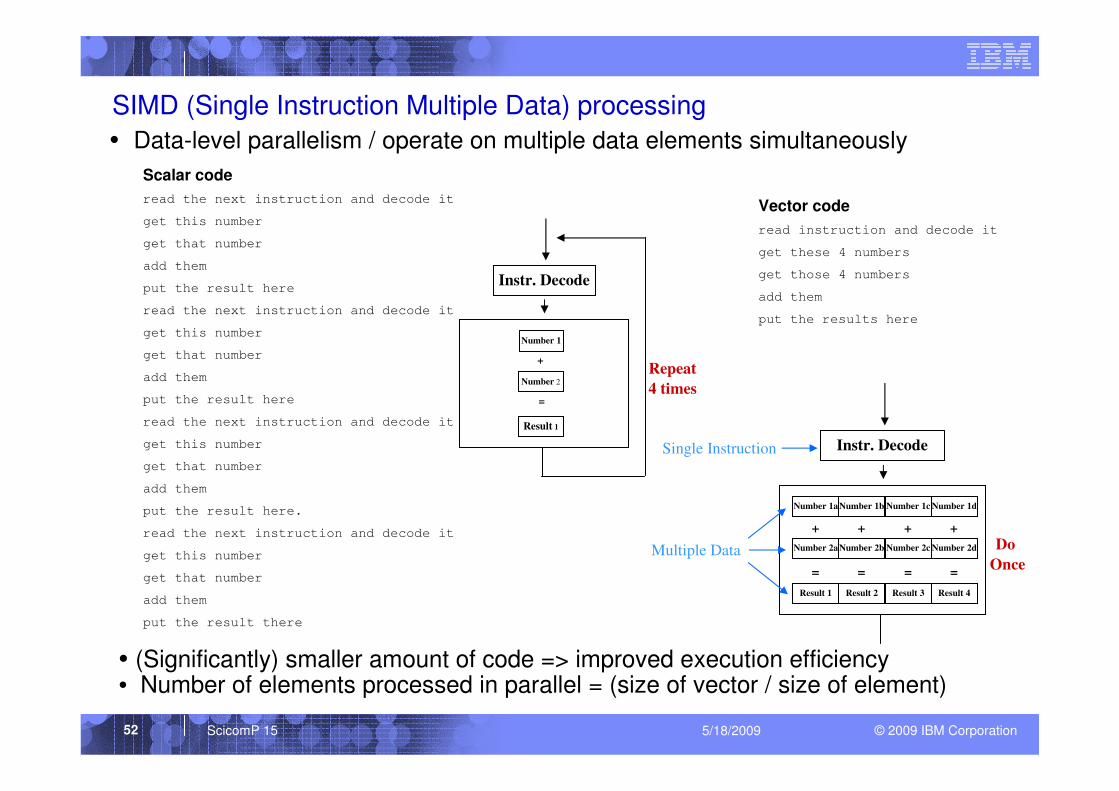
SIMD (Single Instruction Multiple Data) processing
Scalar code
read the next instruction and decode it
get this number
get that number
add them
put the result here
read the next instruction and decode it
get this number
get that number
add them
put the result here
read the next instruction and decode it
get this number
get that number
add them
put the result here.
read the next instruction and decode it
get this number
get that number
add them
put the result there
Vector code
read instruction and decode it
get these 4 numbers
get those 4 numbers
add them
put the results here
• Data-level parallelism / operate on multiple data elements simultaneously
• (Significantly) smaller amount of code => improved execution efficiency• Number of elements processed in parallel = (size of vector / size of element)
Result 1
+
=
Instr. Decode
Number 1
Number 2
Repeat
4 times
Do
Once
Result 3
+
=
Instr. Decode
Number 1c
Number 2c
Result 4
+
=
Number 1d
Number 2d
Result 1
+
=
Number 1a
Number 2a
Result 2
+
=
Number 1b
Number 2bMultiple Data
Single Instruction
© 2009 IBM CorporationScicomP 15 5/18/200953
SPU Instruction Set
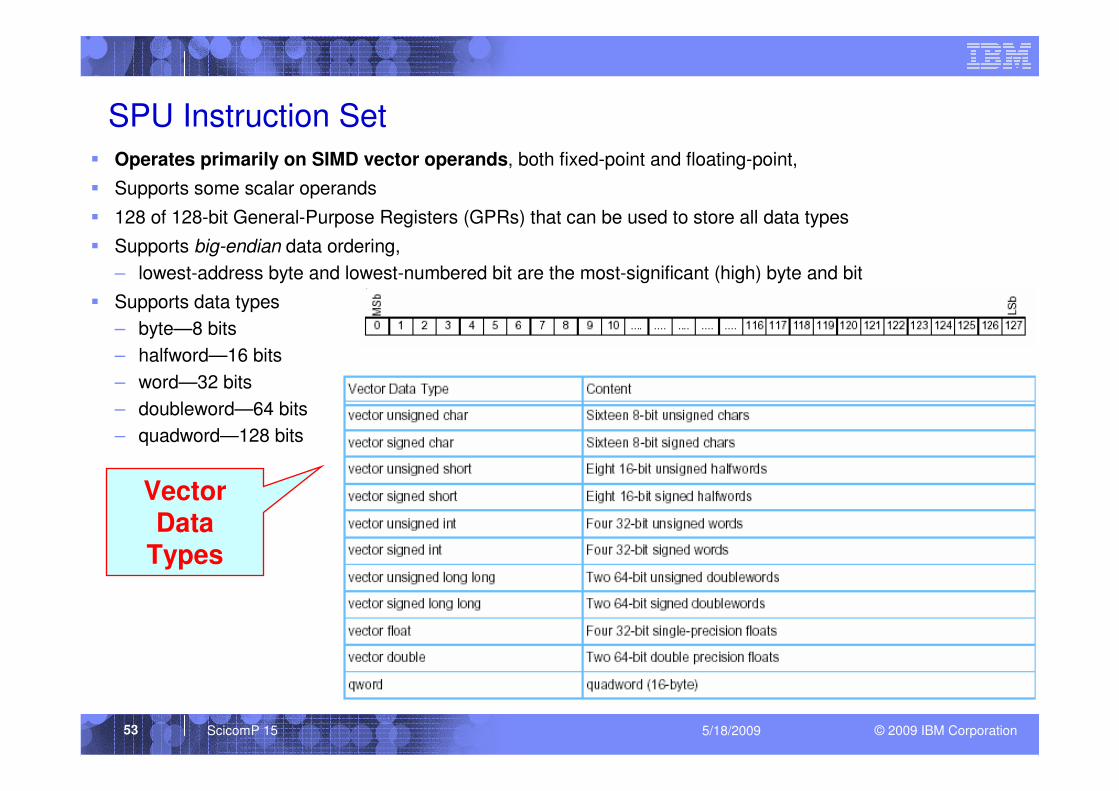
� Operates primarily on SIMD vector operands, both fixed-point and floating-point,
� Supports some scalar operands
� 128 of 128-bit General-Purpose Registers (GPRs) that can be used to store all data types
� Supports big-endian data ordering,
– lowest-address byte and lowest-numbered bit are the most-significant (high) byte and bit
� Supports data types
– byte—8 bits
– halfword—16 bits
– word—32 bits
– doubleword—64 bits
– quadword—128 bits
Vector Data
Types
© 2009 IBM CorporationScicomP 15 5/18/200954
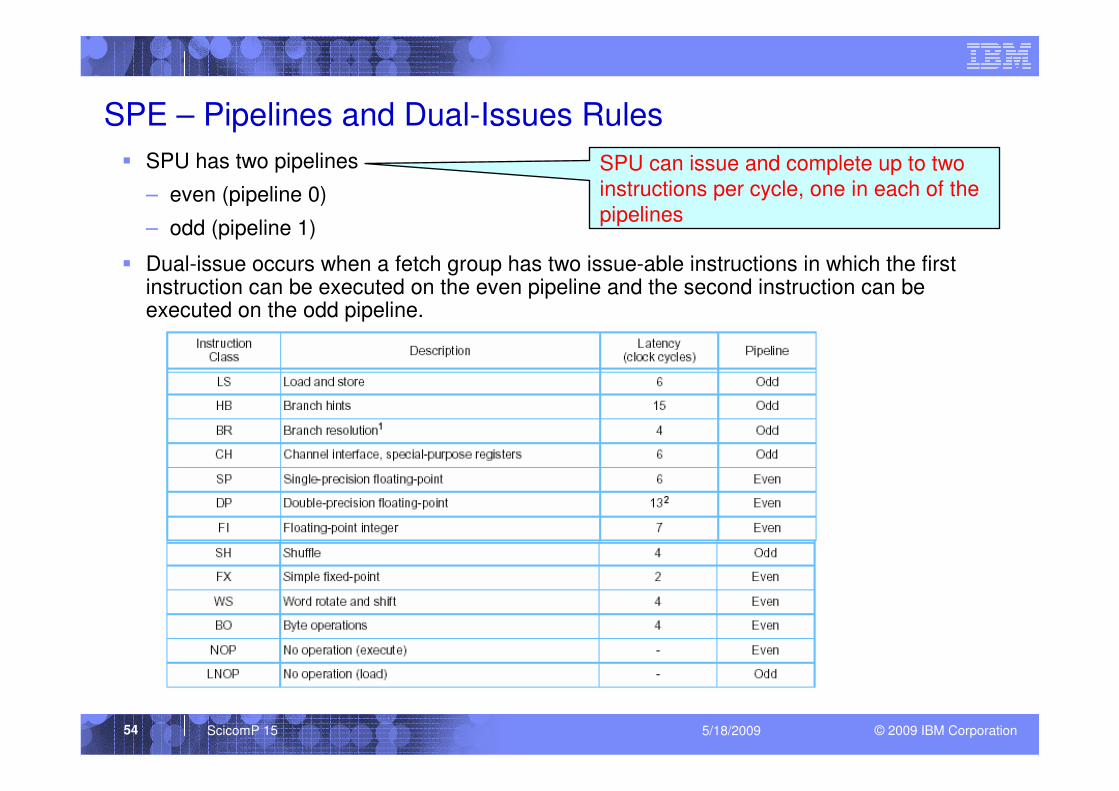
SPE – Pipelines and Dual-Issues Rules
� SPU has two pipelines
– even (pipeline 0)
– odd (pipeline 1)
� Dual-issue occurs when a fetch group has two issue-able instructions in which the first instruction can be executed on the even pipeline and the second instruction can be executed on the odd pipeline.
SPU can issue and complete up to two
instructions per cycle, one in each of the
pipelines

© 2009 IBM CorporationScicomP 15 5/18/200955
SPE and Scalar Code
� SPU only loads and stores a quadword at a time
� Value of scalar operands (including addresses) is kept in the preferred slot of a SIMD register
� Scalar (sub quadword) loads and stores require several instructions to format the data for use on the SIMD architecture of the SPE
– e.g., scalar stores require a read, scalar insert, and write operation
� Strategies to make operations on scalar data more efficient:
– Change the scalars to quadword vectors to eliminate three extra instructions associated with loading and storing scalars
– Cluster scalars into groups, and load multiple scalars at a time using a quadwordmemory access. Manually extract or insert the scalars as needed. This will eliminate redundant loads and stores.
Intrinsics for Changing Scalar and Vector Data Types

© 2009 IBM CorporationScicomP 15 5/18/200956
Register Layout of Data Types and Preferred Slot
When instructions use or produce scalar operands or addresses, the values are
in the preferred scalar slot
The left-most word (bytes 0, 1, 2, and 3) of a
register is called the preferred slot

© 2009 IBM CorporationScicomP 15 5/18/200957
SIMD Programming
� “Native SIMD” programming
– algorithm vectorized by the programmer
– coding in high-level language (e.g. C, C++) using intrinsics
– intrinsics provide access to SIMD assembler instructions
• e.g. c = spu_add(a,b) � add vc,va,vb
� “Traditional” programming
– algorithm coded “normally” in scalar form
– compiler does auto-vectorization
� but auto-vectorization capabilities remain limited

© 2009 IBM CorporationScicomP 15 5/18/200958
SPE C/C++ Language Extensions (Intrinsics)
� Specific Intrinsics: intrinsics that have a one-to-one mapping with a single assembly-language instruction (si_asembly-inst-name) and are provided for all instructions except some branch and interrupt related ones.
� Generic / Buit-In
– Constant formation (spu_splats)
– Conversion (spu_convtf, spu_convts, ..)
– Arithmetic (spu_add, spu_madd, spu_nmadd, ...)
– Byte operations (spu_absd, spu_avg,...)
– Compare and branch (spu_cmpeq, spu_cmpgt,...)
– Bits and masks (spu_shuffle, spu_sel,...)
– Logical (spu_and, spu_or, ...)
– Shift and rotate (spu_rlqwbyte, spu_rlqw,...)
– Control (spu_stop, spu_ienable, spu_idisable, ...)
– Channel Control (spu_readch, spu_writech,...)
– Scalar (spu_insert, spu_extract, spu_promote)
� Composite: DMA (spu_mfcdma32, spu_mfcdma64, spu_mfcstat)
� Vector datatypes: vector [unsigned] {char, short, float, double}
– e.g. “vector float”, “vector signed short”, “vector unsigned int”, …
� Vector pointers:
– e.g. “vector float *p” (p+1 points to the next vector (16B) after that pointed to by p)

© 2009 IBM CorporationScicomP 15 5/18/200959
Simple SIMD Operations
� Example of basic SIMD code
#include <spu_intrinsics.h>
vector float vec1={8.0,8.0,8.0,8.0}, vec2={2.0,4.0,8.0,16.0};
vec1 = vec1 + vec2;
� Example of SIMD intrinsics
#include <spu_intrinsics.h>
vector float vec1={8.0,8.0,8.0,8.0}, vec2={2.0,4.0,8.0,16.0};
vec1 = spu_sub( (vector float)spu_splats((float)3.5), vec1);
vec1 = spu_mul( vec1, vec2);

© 2009 IBM CorporationScicomP 15 5/18/200960
Vectorizing a Loop – A Simple Example
� Loop does term-by-term multiply of two arrays
– arrays assumed here to remain scalar outside of subroutine
� If arrays not quadword-aligned, extra work is necessary
� If array size is not a multiple of 4, extra work is necessary
/* scalar version */
int mult1(float *in1, float *in2, float *out, int N){ int i;
for (i = 0, i < N, i++) {
out[i] = in1[i] * in2[i]; }
return 0;
/* vectorized version */
int vmult1(float *in1, float *in2, float *out, int N){ /* assumes that arrays are quadword aligned */ /* assumes that N is divisible by 4 */
int i, Nv; Nv = N >> 2; /* N/4 vectors */ vector float *vin1 = (vector float *) (in1); vector float *vin2 = (vector float *) (in2); vector float *vout = (vector float *) (out);
for (i = 0, i < Nv, i++) {
vout[i] = spu_mul(vin1[i],vin2[i]); }
return 0;

© 2009 IBM CorporationScicomP 15 5/18/200961
Overview
� SPE Runtime Management Library
� Communication Mechanisms
– Mailboxes, DMA, Signals
� SIMD
� Accelerator Library Framework (ALF)
� Data Communications and Synchronization (DaCS)
© 2009 IBM CorporationScicomP 15 5/18/200962
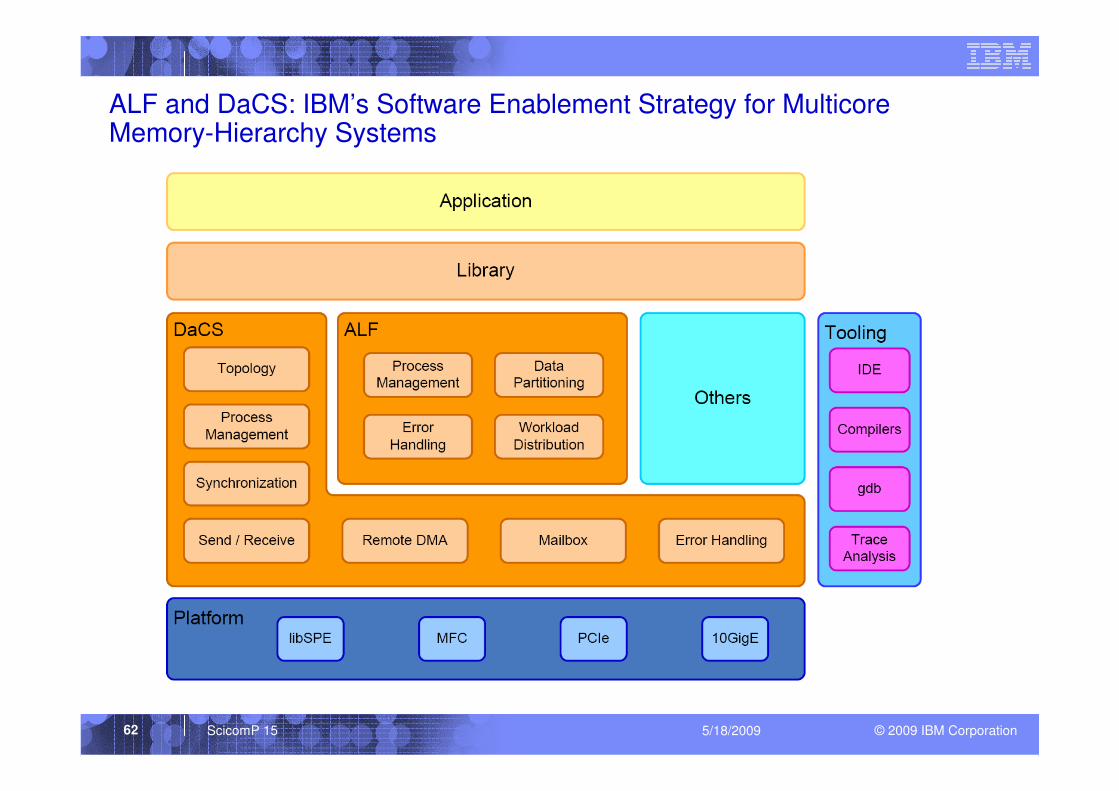
ALF and DaCS: IBM’s Software Enablement Strategy for MulticoreMemory-Hierarchy Systems

© 2009 IBM CorporationScicomP 15 5/18/200963
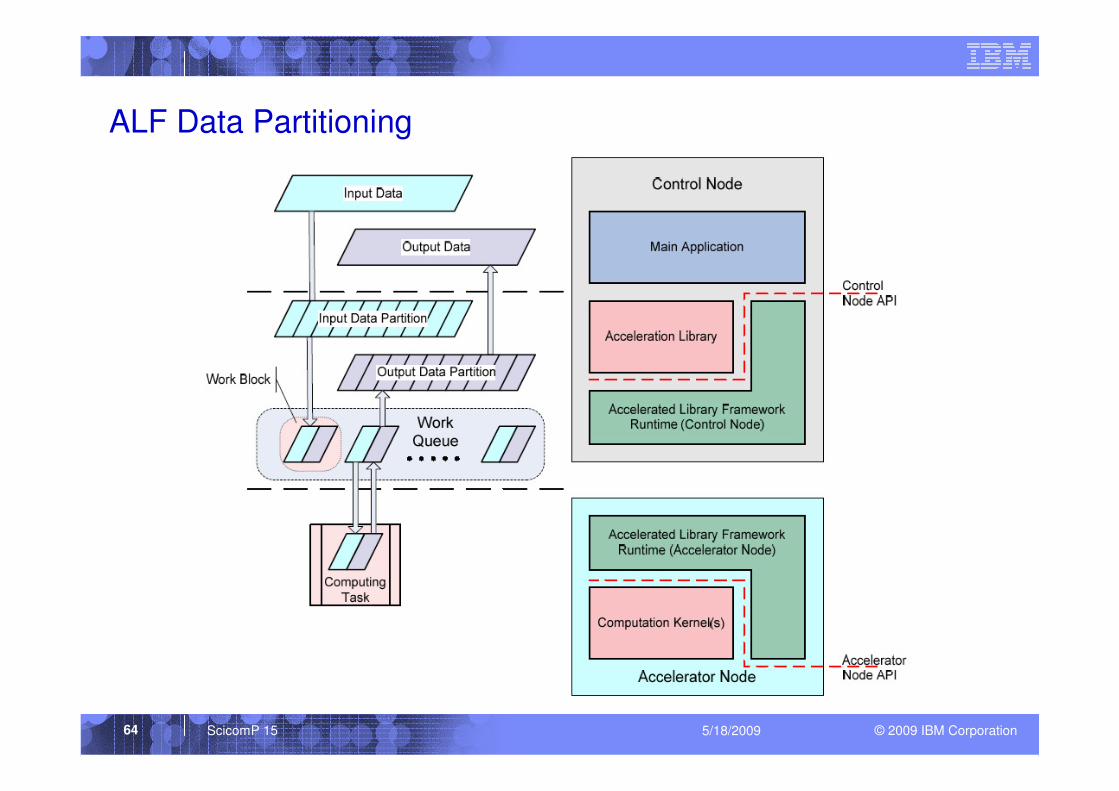
ALF - Accelerator Library Framework
� Aims at workloads that are highly parallelizable– e.g. Raycasting, FFT, Monte Carlo, Video Codecs
� Provides a simple user-level programming framework for Cell
library developers that can be extended to other hybrid
systems.� Division of Labor approach
– ALF provides wrappers for computational kernels
– Frees programmers from writing their own architectural-dependent code
including: data transfer, task management, double buffering, data
communication
� Manages data partitioning– Provides efficient scatter/gather implementations via CBE DMA
– Extensible to variety of data partitioning patterns
– Host and accelerator describe the scatter/gather operations
– Accelerators gather the input data and scatter output data from host’s
memory
– Manages input/output buffers to/from SPEs
� Remote error handling
� Utilizes DaCS library for some low-level operations (on Hybrid)
© 2009 IBM CorporationScicomP 15 5/18/200964
ALF Data Partitioning
© 2009 IBM CorporationScicomP 15 5/18/200965
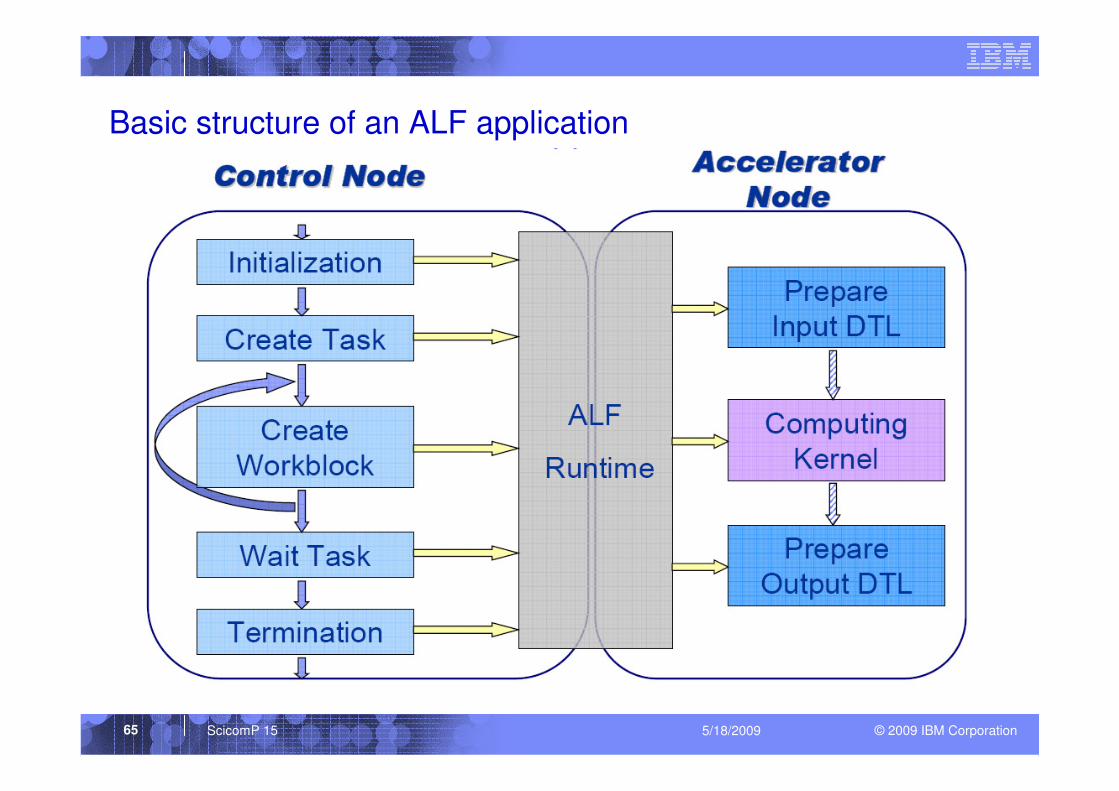
Basic structure of an ALF application
© 2009 IBM CorporationScicomP 15 5/18/200966
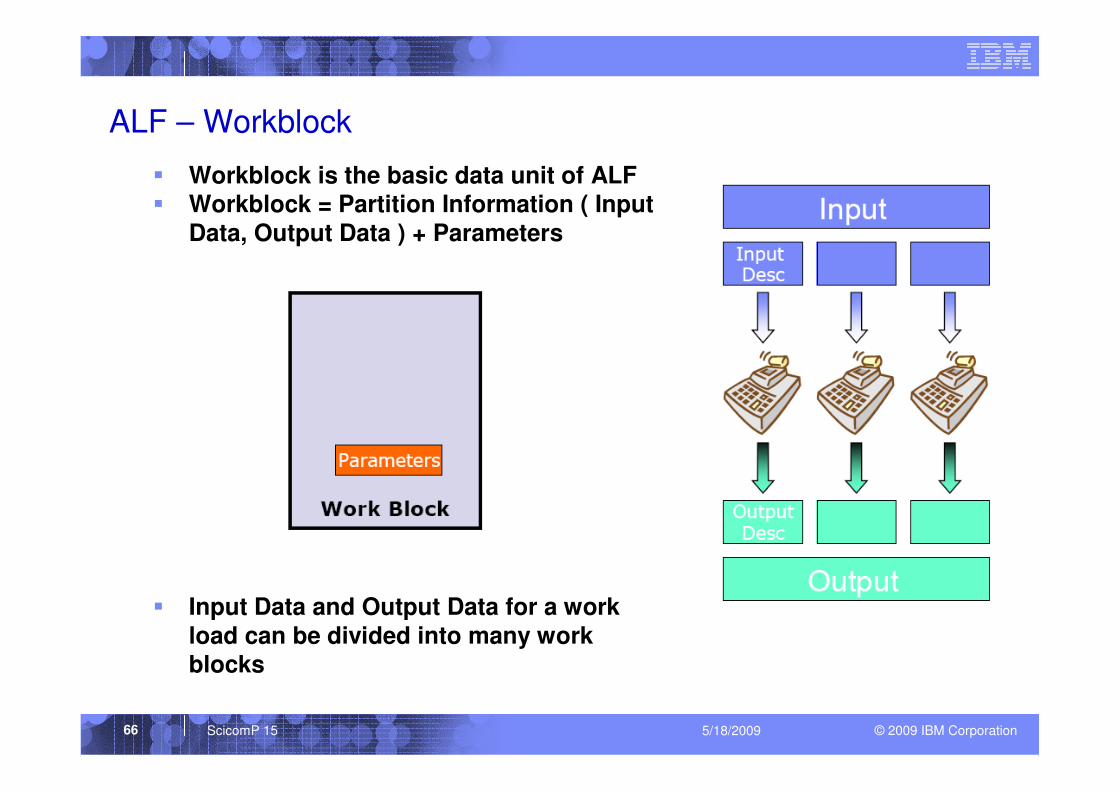
ALF – Workblock
� Workblock is the basic data unit of ALF� Workblock = Partition Information ( Input
Data, Output Data ) + Parameters
� Input Data and Output Data for a work
load can be divided into many work
blocks
© 2009 IBM CorporationScicomP 15 5/18/200967
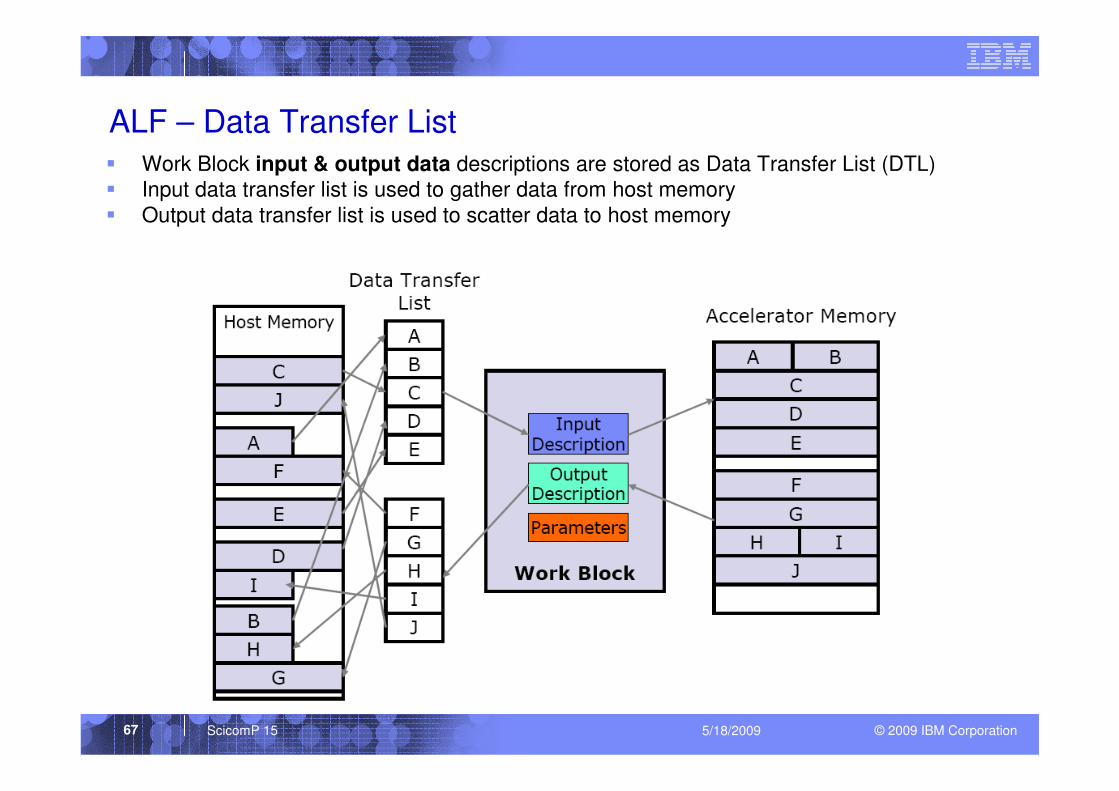
ALF – Data Transfer List
� Work Block input & output data descriptions are stored as Data Transfer List (DTL)
� Input data transfer list is used to gather data from host memory
� Output data transfer list is used to scatter data to host memory

© 2009 IBM CorporationScicomP 15 5/18/200968
ALF – Workblock
alf_wb_handle_t wb_handle;add_parms_t parm __attribute__((aligned(128)));
parm.h = H; /* horizontal size of the block */parm.v = V; /* vertical size of the block */
/* creating work blocks and adding param & io buffer */for (i = 0; i < NUM_ROW; i += H)`{
alf_wb_create(task_handle, ALF_WB_SINGLE, 0,&wb_handle);
/* begins a new Data Transfer List for INPUT */ alf_wb_dtl_set_begin(wb_handle, ALF_BUF_IN, 0); /* Add H*V element of mat_a as Input */ alf_wb_dtl_set_entry_add(wb_handle, &matrix_a[i][0], H * V, ALF_DATA_FLOAT); /* Add H*V element ofmat_b as Input */ alf_wb_dtl_set_entry_add(wb_handle, &matrix_b[i][0], H * V, ALF_DATA_FLOAT); alf_wb_dtl_set_end(wb_handle);
/* begins a new Data Transfer List OUTPUT */ alf_wb_dtl_set_begin(wb_handle, ALF_BUF_OUT, 0); /* Add H*V element of mat_c as Output */ alf_wb_dtl_set_entry_add(wb_handle, &matrix_c[i][0], H * V, ALF_DATA_FLOAT); alf_wb_dtl_set_end(wb_handle); /* pass parameters H and V to spu */
alf_wb_parm_add(wb_handle, (void *) (&parm), sizeof(parm), ALF_DATA_BYTE, 0); /* enqueuing work block */ alf_wb_enqueue(wb_handle);
}
alf_task_finalize(task_handle);
� Create NUM_ROW Work Blocks from Matrix addition and enqueue them to be
processed.
© 2009 IBM CorporationScicomP 15 5/18/200969
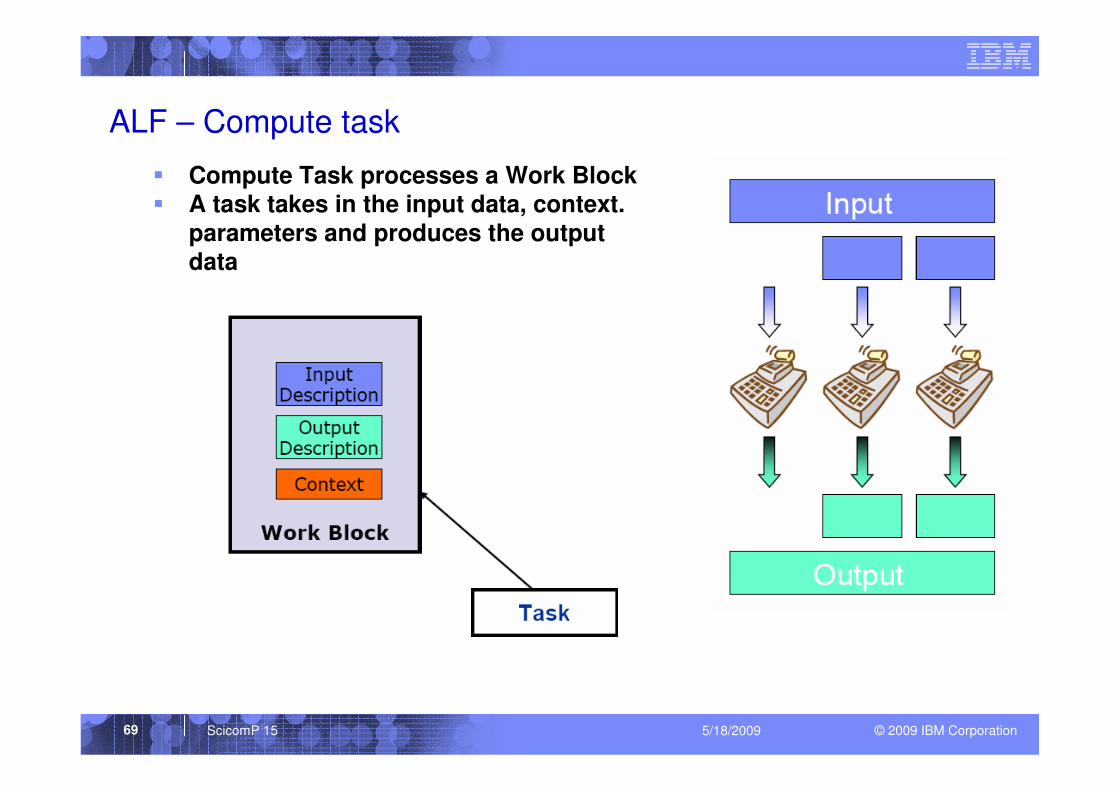
ALF – Compute task
� Compute Task processes a Work Block� A task takes in the input data, context.
parameters and produces the output
data
© 2009 IBM CorporationScicomP 15 5/18/200970
ALF – Compute Task
/* variable declarations */
alf_task_desc_handle_t task_desc_handle;alf_task_handle_t task_handle;const char* spe_image_name;const char* library_path_name;const char* comp_kernel_name = “alf_accel_comp_kernel”;
/* describing a task that’s executable on the SPE*/
alf_task_desc_create(alf_handle, ALF_ACCEL_TYPE_SPE, &task_desc_handle;);
alf_task_desc_set_int32(task_desc_handle, ALF_TASK_DESC_TSK_CTX_SIZE, 0);
alf_task_desc_set_int32(task_desc_handle, ALF_TASK_DESC_WB_PARM_CTX_BUF_SIZE, sizeof(add_parms_t));
alf_task_desc_set_int32(task_desc_handle, ALF_TASK_DESC_WB_IN_BUF_SIZE, H * V * 2 sizeof(float));
alf_task_desc_set_int32(task_desc_handle, ALF_TASK_DESC_WB_OUT_BUF_SIZE, H * V * sizeof(float));
alf_task_desc_set_int32(task_desc_handle, ALF_TASK_DESC_NUM_DTL_ENTRIES, 8);
alf_task_desc_set_int32(task_desc_handle, ALF_TASK_DESC_MAX_STACK_SIZE, 4096);
/* providing the SPE executable name */
alf_task_desc_set_int64(task_desc_handle, ALF_TASK_DESC_ACCEL_IMAGE_REF_L,(unsigned long long) spe_image_name);
alf_task_desc_set_int64(task_desc_handle, ALF_TASK_DESC_ACCEL_LIBRARY_REF_L,(unsigned long) library_path_name);
alf_task_desc_set_int64(task_desc_handle, ALF_TASK_DESC_ACCEL_KERNEL_REF_L,(unsigned long) comp_kernel_name);
int alf_accel_comp_kernel( void *p_task_context, void *p_parm_context, void *p_input_buffer, void *p_output_buffer,void *p_inout_buffer, unsigned int current_count, unsigned int total_count) {
unsigned int i, cnt;
vector float *sa, *sb, *sc;add_parms_t *p_parm = (add_parms_t *)p_parm_context;cnt = p_parm->h * p_parm->v / 4;sa = (vector float *) p_input_buffer;sb = sa + cnt;
sc = (vector float *) p_output_buffer;for (i = 0; i < cnt; i += 4) {
sc[i] = spu_add(sa[i], sb[i]);sc[i + 1] = spu_add(sa[i + 1], sb[i + 1]);sc[i + 2] = spu_add(sa[i + 2], sb[i + 2]);
sc[i + 3] = spu_add(sa[i + 3], sb[i + 3]); }return 0;
}
� Define the Compute task.
� Compute Kernel on SPE
© 2009 IBM CorporationScicomP 15 5/18/200971
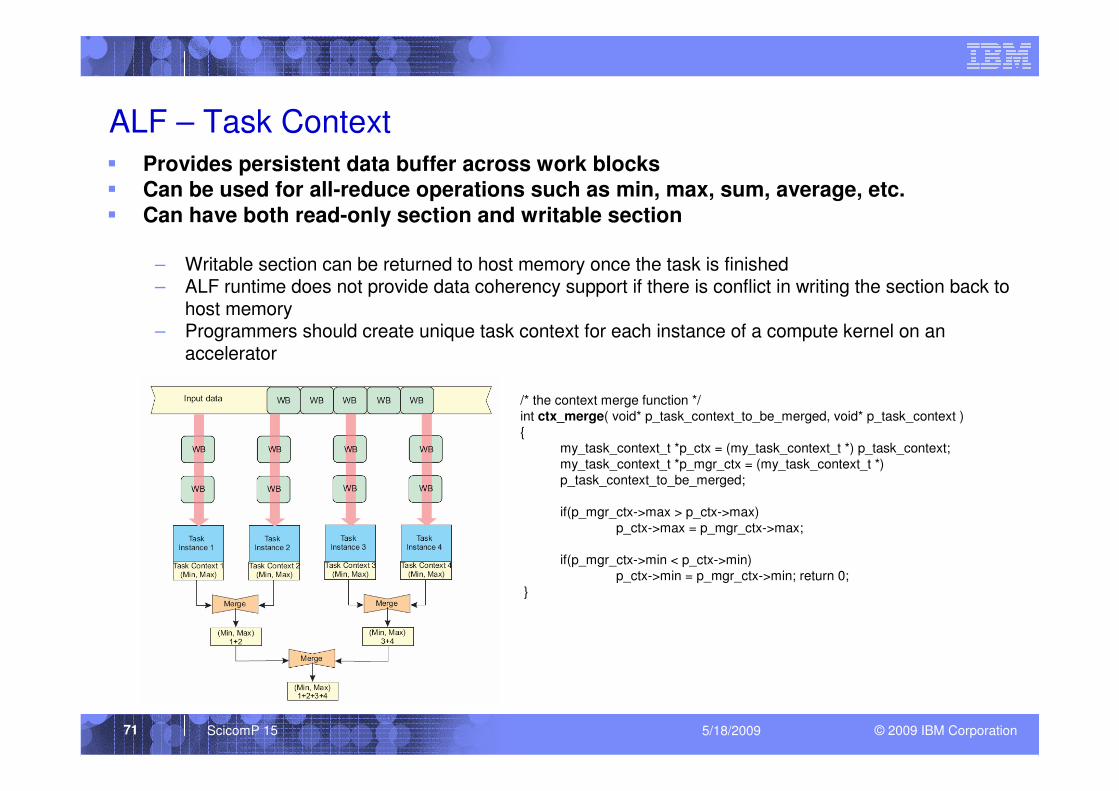
ALF – Task Context
� Provides persistent data buffer across work blocks
� Can be used for all-reduce operations such as min, max, sum, average, etc.
� Can have both read-only section and writable section
– Writable section can be returned to host memory once the task is finished– ALF runtime does not provide data coherency support if there is conflict in writing the section back to
host memory– Programmers should create unique task context for each instance of a compute kernel on an
accelerator
/* the context merge function */
int ctx_merge( void* p_task_context_to_be_merged, void* p_task_context )
{
my_task_context_t *p_ctx = (my_task_context_t *) p_task_context;
my_task_context_t *p_mgr_ctx = (my_task_context_t *)
p_task_context_to_be_merged;
if(p_mgr_ctx->max > p_ctx->max)
p_ctx->max = p_mgr_ctx->max;
if(p_mgr_ctx->min < p_ctx->min)
p_ctx->min = p_mgr_ctx->min; return 0;
}

© 2009 IBM CorporationScicomP 15 5/18/200972
ALF – Queues� Two different queues are important to programmers
– Work block queue for each task• Pending work blocks will be issued to the work queue• Task instance on each accelerator node will fetch from this queue
– Task queue for each ALF runtime• Multiple Tasks executed at one time
– except where programmer specifies dependencies• Future tasks can be issued. They will be placed on the task queue awaiting execution.
� ALF runtime manages both queues
ALF – Buffer management on accelerators
� ALF manages buffer allocation on accelerators’ local memory
� ALF runtime provides pointers to 5 different buffers to a computational kernel– Task context buffer (RO and RW sections)– Work block parameters– Input Buffer– Input/Output Buffer– Output Buffer
� ALF implements a best effort double buffering scheme– ALF determines if there is enough local memory for double buffering
� Double buffer scenarios supported by ALF– 4 buffers: [In0, Out0; In1, Out1]– 3 buffers: [In0, Out0; In1] : [Out1; In2, Out2]
© 2009 IBM CorporationScicomP 15 5/18/200973
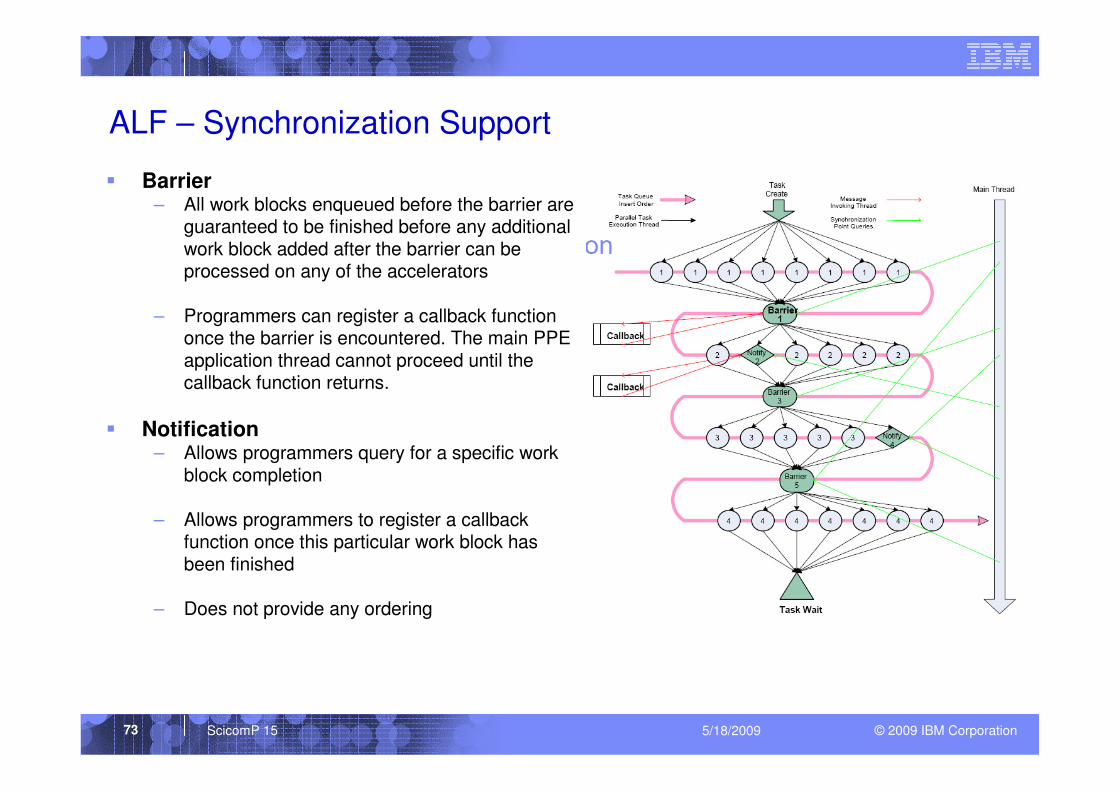
ALF – Synchronization Support
� Barrier– All work blocks enqueued before the barrier are
guaranteed to be finished before any additional work block added after the barrier can be processed on any of the accelerators
– Programmers can register a callback function once the barrier is encountered. The main PPE application thread cannot proceed until the callback function returns.
� Notification– Allows programmers query for a specific work
block completion
– Allows programmers to register a callback function once this particular work block has been finished
– Does not provide any ordering

© 2009 IBM CorporationScicomP 15 5/18/200974
ALF – Dependencies
� Task dependencies can be specified by:
• alf_task_depends_on( tsk2, tsk1 );

© 2009 IBM CorporationScicomP 15 5/18/200975
ALF Example (PPU code)/* Compute PI by Buffon-Needle method based on ALF */
#include "alf.h"
#include "pi.h"
result_t result;
char spu_image_path[PATH_BUF_SIZE]; // Used to hold the complete path to SPU image
char library_name[PATH_BUF_SIZE]; // Used to hold the name of spu library
char spu_image_name[] = "alf_pi_spu";
char kernel_name[] = "comp_kernel";
char ctx_setup_name[] = "context_setup";
char ctx_merge_name[] = "context_merge";
int main(int argc __attribute__ ((__unused__)), char *argv[] __attribute__ ((__unused__))) {
/* Declare variables for ALF runtime */
void *config_parms = NULL;
alf_handle_t alf_handle;
alf_task_desc_handle_t desc_info_handle;
alf_task_handle_t task_handle;
alf_wb_handle_t wb_handle;
if (alf_init(config_parms, &alf_handle) < 0) { printf("Failed to call alf_init\n"); return 1; }
if (alf_query_system_info(alf_handle,ALF_QUERY_NUM_ACCEL, ALF_ACCEL_TYPE_SPE, &nodes) < 0) {
printf("Failed to call alf_query_system_info.\n");
return 1;
} else if( nodes <= 0 ) {
printf("Cannot allocate spe to use.\n");
return 1;
}
alf_num_instances_set( alf_handle, nodes );
/* Create a task descriptor for the task */
alf_task_desc_create( alf_handle, ALF_ACCEL_TYPE_SPE, &desc_info_handle );
…
(continues on next page)

© 2009 IBM CorporationScicomP 15 5/18/200976
ALF Example (PPU code)(continues from previous page)
…
alf_task_desc_set_int32( desc_info_handle, ALF_TASK_DESC_WB_PARM_CTX_BUF_SIZE, sizeof(udata_t) );
alf_task_desc_set_int32( desc_info_handle, ALF_TASK_DESC_TSK_CTX_SIZE, sizeof(result_t) );
alf_task_desc_set_int64( desc_info_handle, ALF_TASK_DESC_ACCEL_IMAGE_REF_L, (unsigned long long) spu_image_name );
alf_task_desc_set_int64( desc_info_handle, ALF_TASK_DESC_ACCEL_LIBRARY_REF_L, (unsigned long long) library_name );
alf_task_desc_set_int64( desc_info_handle, ALF_TASK_DESC_ACCEL_KERNEL_REF_L, (unsigned long long) kernel_name );
alf_task_desc_set_int64( desc_info_handle, ALF_TASK_DESC_ACCEL_CTX_SETUP_REF_L, (unsigned long long) ctx_setup_name );
alf_task_desc_set_int64( desc_info_handle, ALF_TASK_DESC_ACCEL_CTX_MERGE_REF_L, (unsigned long long) ctx_merge_name );
alf_task_desc_ctx_entry_add( desc_info_handle, ALF_DATA_DOUBLE, 1 ); /* result_t.value */
alf_task_desc_ctx_entry_add( desc_info_handle, ALF_DATA_INT32, 2 ); /* result_t.wbs and result_t.pad */
// Create task
alf_task_create( desc_info_handle, &result, 0, 0, 1, &task_handle );
result.value = 0.0; my_udata.iter = ITERATIONS;
for (i = 0; i < WBS; i++) {
alf_wb_create( task_handle, ALF_WB_SINGLE, 1, &wb_handle );
my_udata.seed = rand();
alf_wb_parm_add(wb_handle, (void *)&(my_udata.seed), 1, ALF_DATA_INT32, 2);
alf_wb_parm_add(wb_handle, (void *)&(my_udata.iter), 1, ALF_DATA_INT32, 2);
alf_wb_enqueue( wb_handle );
}
alf_task_finalize(task_handle);
/* Wait until the task is finished */
alf_task_wait(task_handle, -1);
/* Cleanup */
alf_task_desc_destroy(desc_info_handle);
alf_exit(alf_handle, ALF_EXIT_POLICY_FORCE, 0);
pi = result.value / result.wbs;
printf("PI = %f\n", pi);
return 0;
}

© 2009 IBM CorporationScicomP 15 5/18/200977
ALF Example (SPU code)#include "alf_accel.h"
#include "../pi.h"
int comp_kernel(
void *p_task_ctx,
void *p_parm_ctx_buffer,
void *p_input_buffer __attribute__ ((unused)),
void *p_output_buffer __attribute__ ((unused)),
void *p_inout_buffer __attribute__ ((unused)),
unsigned int current_count __attribute__ ((unused)),
unsigned int total_count __attribute__ ((unused)))
{
udata_t *my_udata_ptr = (udata_t *)p_parm_ctx_buffer;
result_t *tsk_ctx_ptr = (result_t *)p_task_ctx;
srand(my_udata_ptr->seed);
for (i = 0; i < my_udata_ptr->iter; i++) {
x = rand() * 1.0 / RAND_MAX;
y = rand() * 1.0 / RAND_MAX;
if (x*x + y*y <= 1.0) result += 1;
}
tsk_ctx_ptr->value += (result * 4.0 / ITERATIONS);
tsk_ctx_ptr->wbs ++ ;
return 0;
}
int context_setup(void *p_task_ctx)
{
result_t *tsk_ctx_ptr = (result_t *)p_task_ctx;
tsk_ctx_ptr->value = 0.0;
tsk_ctx_ptr->wbs = 0;
return 0;
}
int context_merge(void* p_dst_task_ctx, void* p_task_ctx)
{
result_t *tsk_ctx_ptr = (result_t *)p_task_ctx;
result_t *dst_tsk_ctx_ptr = (result_t *)p_dst_task_ctx;
tsk_ctx_ptr->value += dst_tsk_ctx_ptr->value;
tsk_ctx_ptr->wbs += dst_tsk_ctx_ptr->wbs;
return 0;
}
ALF_ACCEL_EXPORT_API_LIST_BEGIN
ALF_ACCEL_EXPORT_API("", comp_kernel);
ALF_ACCEL_EXPORT_API("", context_setup);
ALF_ACCEL_EXPORT_API("", context_merge);
ALF_ACCEL_EXPORT_API_LIST_END

© 2009 IBM CorporationScicomP 15 5/18/200978
Overview
� SPE Runtime Management Library
� Communication Mechanisms
– Mailboxes, DMA, Signals
� SIMD
� Accelerator Library Framework (ALF)
� Data Communications and Synchronization (DaCS)

© 2009 IBM CorporationScicomP 15 5/18/200979
DaCS - Data Communications and Synchronization
� Focused on data movement primitives– DMA like interfaces (put, get)
– Message interfaces (send/recv)
– Mailbox
– Endian Conversion
� Provides Process Management, Accelerator Topology Services
� Based on Remote Memory windows and Data channels architecture
� Common API – Intra-Accelerator (CellBE), Host - Accelerator� Double and multi-buffering
– Efficient data transfer to maximize available bandwidth and minimize inherent
latency
– Hide complexity of asynchronous compute/communicate from developer
� Supports ALF, directly used by US National Lab for Host-Accelerator HPC environment
� Thin layer of API support on CELLBE native hardware
� Hybrid DaCS (not applicable to BSC Prototype)

© 2009 IBM CorporationScicomP 15 5/18/200980
DaCS - APIs
� Init / Term– dacs_runtime_init– dacs_runtime_exit
� Reservation Service– dacs_get_num_
avail_children– dacs_reserve_children
– dacs_release_de_list
� Process Management– dacs_de_start
– dacs_num_processes_supported
– dacs_num_processes_running
– dacs_de_wait– dacs_de_test
� Group Functions– dacs_group_init– dacs_group_add_member
– dacs_group_close– dacs_group_destroy– dacs_group_accept– dacs_group_leave– dacs_barrier_wait
� Data Communication– dacs_remote_mem_create– dacs_remote_mem_share
– dacs_remote_mem_accept– dacs_remote_mem_release– dacs_remote_mem_destroy– dacs_remote_mem_query– dacs_put– dacs_get– dacs_put_list– dacs_get_list– dacs_send– dacs_recv– dacs_mailbox_write– dacs_mailbox_read– dacs_mailbox_test– dacs_wid_reserve– dacs_wid_release– dacs_test– dacs_wait
� Locking Primitives– dacs_mutex_init– dacs_mutex_share
– dacs_mutex_accept– dacs_mutex_lock– dacs_mutex_try_lock– dacs_mutex_unlock– dacs_mutex_release– dacs_mutex_destroy
� Error Handling– dacs_errhandler_reg– dacs_strerror
– dacs_error_num– dacs_error_code– dacs_error_str– dacs_error_de– dacs_error_pid

© 2009 IBM CorporationScicomP 15 5/18/200981
DaCS Example (PPU code)
program main
integer, parameter :: N=64
!must match DATA_BUFFER_ENTRIES in control_blk.h
real, dimension(N) :: arr
integer(kind=8) :: aptr
integer :: amod
integer :: j
interface
subroutine update_array(x, i)
real x(*)
integer :: I
end subroutine
end interface
pointer(aptr,arr)
aptr = malloc(N*4+16)
write(*,'(A,z8,A,z8,A)') 'loc arr[',loc(arr),'] aptr[',aptr,']'
arr = (/(real(i),i=1, N)/);
call update_array(arr, N)
write(*,'(8f6.1)') arr
end program
#include <dacs.h>
#include "init_cb.h"
extern dacs_program_handle_t array_spu;
uint32_t local_error_handler(dacs_error_t);
void update_array_(float *carr, int *nptr) {
DACS_ERR_T rc;
int32_t status;
de_id_t rsvd_child_des[MAX_UNIT_COUNT];
dacs_process_id_t rsvd_child_pids[MAX_UNIT_COUNT];
dacs_remote_mem_t carr_remote_mem;
dacs_wid_t ppu_wid[MAX_UNIT_COUNT];
rc = dacs_init(0); ERRCHK("PPE: dacs_init", rc);
rc = dacs_errhandler_reg(local_error_handler, 0);
ERRCHK("PPE: dacs_errhandler_reg", rc);
// reserve the max spes we want
count_spes = MAX_UNIT_COUNT;
rc = dacs_reserve_children( DACS_DE_SPE, &count_spes, rsvd_child_des );
ERRCHK("PPE: dacs_reserve_children", rc);
// release extra children
if (count_spes > num_rsvd_child) {
rc = dacs_release_de_list( count_spes-num_rsvd_child,
&rsvd_child_des[ num_rsvd_child ] );
}
…
rc = dacs_remote_mem_create( carr, DATA_BUFFER_SIZE,
DACS_READ_WRITE,
&carr_remote_mem );
ERRCHK("PPE: dacs_remote_mem_create", rc);
…
(continues in next page)

© 2009 IBM CorporationScicomP 15 5/18/200982
DaCS Example (PPU code)(continues from previous page)
…
for (i=0; i<unit_count; i++) {
/* load the address into the control block */
cb1[i].offset = i*unit_buffer_size;
cb1[i].chunk_size = unit_buffer_size;
cb1[i].index = i;
}
/* allocate SPE tasks */
for (i=0; i<unit_count; i++) {
int index = cb1[i].index;
PRINTF("ppu unit.%i starting\n",index);
rc = dacs_de_start( rsvd_child_des[i], &array_spu, NULL, NULL,
DACS_PROC_EMBEDDED, &rsvd_child_pids[i] );
ERRCHK("PPE: dacs_de_start", rc);
rc = dacs_wid_reserve( &ppu_wid[i] );
ERRCHK("SPE: dacs_wid_reserve", rc);
PRINTF("ppu unit.%i sending cb\n",index);
rc = dacs_send( &cb1[i], sizeof(cb1[i]),rsvd_child_des[i],
rsvd_child_pids[i],STREAM_ID, ppu_wid[i],
DACS_BYTE_SWAP_DISABLE);
ERRCHK("PPE: dacs_send", rc);
}
for (i=0; i<unit_count; i++) {
int index = cb1[i].index;
rc = dacs_wait(ppu_wid[i]); ERRCHK("SPE: dacs_wait", rc);
PRINTF("ppu unit.%i sharing mem\n",index);
rc = dacs_remote_mem_share(rsvd_child_des[i], rsvd_child_pids[i], carr_remote_mem);
ERRCHK("PPE: dacs_remote_mem_share", rc);
}
…
(cotinues on right column)
(continues from lest column)
…
PRINTF("SPEs 0 - %d are now computing...\n",unit_count);
/* wait for SPEs to all finish */
for (i=0; i<unit_count; ++i) {
int index = cb1[i].index;
PRINTF("ppu unit.%i waiting on completion\n",index);
rc = dacs_de_wait(rsvd_child_des[i], rsvd_child_pids[i], &status);
if (rc != DACS_STS_PROC_FINISHED) {
PRINTF("dacs_de_wait rc[%d] - %s\n", rc, dacs_strerror(rc));
}
}
PRINTF("ppu destroying memory share\n");
rc = dacs_remote_mem_destroy(&carr_remote_mem);
ERRCHK("PPE: dacs_remote_mem_destroy", rc);
PRINTF("ppu exiting %i\n",i);
dacs_exit();
PRINTF("SPEs done.\n");
}

© 2009 IBM CorporationScicomP 15 5/18/200983
DaCS Example (SPU code)#include <dacs.h>
#include "init_cb.h"
/* local copy of the data array, to be filled by the DMA */
float *data;
/* local copy of the control block, to be filled by the receive */
control_block cb1 __attribute__ ((aligned(128)));
int main(unsigned long long speid, addr64 argp, addr64 envp) {
DACS_ERR_T rc;
dacs_wid_t spu_wid;
dacs_remote_mem_t spu_remote_mem;
rc = dacs_init(0); ERRCHK("array_spu: dacs_init", rc);
rc = dacs_wid_reserve(&spu_wid); ERRCHK("array_spu: dacs_wid_reserve", rc);
PRINTF("array_spu: receiving cb\n");
rc = dacs_recv(&cb1, sizeof(cb1), DACS_DE_PARENT, DACS_PID_PARENT, STREAM_ID, spu_wid,DACS_BYTE_SWAP_DISABLE);
ERRCHK("array_spu: dacs_recv", rc);
rc = dacs_wait(spu_wid);
ERRCHK("array_spu: dacs_wait", rc);
rc = dacs_remote_mem_accept(DACS_DE_PARENT, DACS_PID_PARENT, &spu_remote_mem);
n = cb1.chunk_size/sizeof(float);
data = (float *)_malloc_align(cb1.chunk_size, 7);
rc = dacs_get(data, spu_remote_mem, cb1.offset,cb1.chunk_size,spu_wid,DACS_ORDER_ATTR_NONE, DACS_BYTE_SWAP_DISABLE);
rc = dacs_wait(spu_wid);
PRINTF("array_spu: unit.%i invoking compute\n",index);
compute_f_(data, &n);
rc = dacs_put(spu_remote_mem, cb1.offset, data, cb1.chunk_size,spu_wid,DACS_ORDER_ATTR_NONE, DACS_BYTE_SWAP_DISABLE);
rc = dacs_wait(spu_wid);
rc = dacs_remote_mem_release(&spu_remote_mem);
rc = dacs_wid_release(&spu_wid);
dacs_exit();
return 0;
}
subroutine compute_f(x, n)
real :: x(*)
integer :: n
real :: factr(n)
factr = (/ (rand(), i=1, n) /)
x(1:n) = x(1:n) * factr
end subroutine

© 2009 IBM CorporationScicomP 15 5/18/200984
This document was developed for IBM offerings in the United States as of the date of publication. IBM may not make these offerings available in
other countries, and the information is subject to change without notice. Consult your local IBM business contact for information on the IBM
offerings available in your area. In no event will IBM be liable for damages arising directly or indirectly from any use of the information contained
in this document.
Information in this document concerning non-IBM products was obtained from the suppliers of these products or other public sources. Questions
on the capabilities of non-IBM products should be addressed to the suppliers of those products.
IBM may have patents or pending patent applications covering subject matter in this document. The furnishing of this document does not give
you any license to these patents. Send license inquires, in writing, to IBM Director of Licensing, IBM Corporation, New Castle Drive, Armonk, NY
10504-1785 USA.
All statements regarding IBM future direction and intent are subject to change or withdrawal without notice, and represent goals and objectives
only.
The information contained in this document has not been submitted to any formal IBM test and is provided "AS IS" with no warranties or
guarantees either expressed or implied.
All examples cited or described in this document are presented as illustrations of the manner in which some IBM products can be used and the
results that may be achieved. Actual environmental costs and performance characteristics will vary depending on individual client configurations
and conditions.
IBM Global Financing offerings are provided through IBM Credit Corporation in the United States and other IBM subsidiaries and divisions
worldwide to qualified commercial and government clients. Rates are based on a client's credit rating, financing terms, offering type, equipment
type and options, and may vary by country. Other restrictions may apply. Rates and offerings are subject to change, extension or withdrawal
without notice.
IBM is not responsible for printing errors in this document that result in pricing or information inaccuracies.
All prices shown are IBM's United States suggested list prices and are subject to change without notice; reseller prices may vary.
IBM hardware products are manufactured from new parts, or new and serviceable used parts. Regardless, our warranty terms apply.
Many of the features described in this document are operating system dependent and may not be available on Linux. For more information,
please check: http://www.ibm.com/systems/p/software/whitepapers/linux_overview.html
Any performance data contained in this document was determined in a controlled environment. Actual results may vary significantly and are
dependent on many factors including system hardware configuration and software design and configuration. Some measurements quoted in this
document may have been made on development-level systems. There is no guarantee these measurements will be the same on generally-
available systems. Some measurements quoted in this document may have been estimated through extrapolation. Users of this document
should verify the applicable data for their specific environment.
Revised January 19, 2006
Special Notices -- Trademarks

© 2009 IBM CorporationScicomP 15 5/18/200985
The following terms are trademarks of International Business Machines Corporation in the United States and/or other countries: alphaWorks, BladeCenter,
Blue Gene, ClusterProven, developerWorks, e business(logo), e(logo)business, e(logo)server, IBM, IBM(logo), ibm.com, IBM Business Partner (logo),
IntelliStation, MediaStreamer, Micro Channel, NUMA-Q, PartnerWorld, PowerPC, PowerPC(logo), pSeries, TotalStorage, xSeries; Advanced Micro-
Partitioning, eServer, Micro-Partitioning, NUMACenter, On Demand Business logo, OpenPower, POWER, Power Architecture, Power Everywhere, Power
Family, Power PC, PowerPC Architecture, POWER5, POWER5+, POWER6, POWER6+, Redbooks, System p, System p5, System Storage, VideoCharger,
Virtualization Engine.
A full list of U.S. trademarks owned by IBM may be found at: http://www.ibm.com/legal/copytrade.shtml.
Cell Broadband Engine and Cell Broadband Engine Architecture are trademarks of Sony Computer Entertainment, Inc. in the United States, other countries,
or both.
Rambus is a registered trademark of Rambus, Inc.
XDR and FlexIO are trademarks of Rambus, Inc.
UNIX is a registered trademark in the United States, other countries or both.
Linux is a trademark of Linus Torvalds in the United States, other countries or both.
Fedora is a trademark of Redhat, Inc.
Microsoft, Windows, Windows NT and the Windows logo are trademarks of Microsoft Corporation in the United States, other countries or both.
Intel, Intel Xeon, Itanium and Pentium are trademarks or registered trademarks of Intel Corporation in the United States and/or other countries.
AMD Opteron is a trademark of Advanced Micro Devices, Inc.
Java and all Java-based trademarks and logos are trademarks of Sun Microsystems, Inc. in the United States and/or other countries.
TPC-C and TPC-H are trademarks of the Transaction Performance Processing Council (TPPC).
SPECint, SPECfp, SPECjbb, SPECweb, SPECjAppServer, SPEC OMP, SPECviewperf, SPECapc, SPEChpc, SPECjvm, SPECmail, SPECimap and
SPECsfs are trademarks of the Standard Performance Evaluation Corp (SPEC).
AltiVec is a trademark of Freescale Semiconductor, Inc.
PCI-X and PCI Express are registered trademarks of PCI SIG.
InfiniBand™ is a trademark the InfiniBand® Trade Association
Other company, product and service names may be trademarks or service marks of others.
Revised July 23, 2006
Special Notices (Cont.) -- Trademarks
© 2009 IBM CorporationScicomP 15 5/18/200986
(c) Copyright International Business Machines Corporation 2005.
All Rights Reserved. Printed in the United Sates September 2005.
The following are trademarks of International Business Machines Corporation in the United States, or other countries, or both. IBM IBM Logo Power Architecture
Other company, product and service names may be trademarks or service marks of others.
All information contained in this document is subject to change without notice. The products described in this document are NOT intended for use in applications such as implantation, life support, or other hazardous uses where malfunction could result
in death, bodily injury, or catastrophic property damage. The information contained in this document does not affect or change IBM product specifications or warranties. Nothing in this document shall operate as an express or implied license or indemnity under the intellectual property rights of IBM or third parties. All information contained in this document was obtained in specific
environments, and is presented as an illustration. The results obtained in other operating environments may vary.
While the information contained herein is believed to be accurate, such information is preliminary, and should not be relied upon for accuracy or completeness, and no representations or warranties of accuracy or completeness are made.
THE INFORMATION CONTAINED IN THIS DOCUMENT IS PROVIDED ON AN "AS IS" BASIS. In no event will IBM be liable for damages arising directly or indirectly from any use of the information contained in this document.
IBM Microelectronics Division The IBM home page is http://www.ibm.com
1580 Route 52, Bldg. 504 The IBM Microelectronics Division home page is Hopewell Junction, NY 12533-6351 http://www.chips.ibm.com
Special Notices - Copyrights