scalable software hardware architecture platform for for embedded systems shapes at date 2007 pier...
TRANSCRIPT

Scalable Software Hardware Architecture PlatformScalable Software Hardware Architecture Platform
forfor
Embedded SystemsEmbedded Systems
SHAPES at DATE 2007SHAPES at DATE 2007
Pier Stanislao PAOLUCCIchief technical officer – ATMEL Roma
& (part-time) permanent staff researcher – INFN Roma
for
the SHAPES Consortium

January, 2007 2Introduction to SHAPES 2
Project Motivation and Final ObjectiveProject Motivation and Final Objective
SHAPES Acronym: Scalable Software Hardware Architecture Platform for Embedded Systems
Objective: Develop a prototype of Tiled Scalable HW & SW architecture for embedded applications characterized by inherent parallelism
Experiment: “Small” Tiles (<10 MGate) connected by “short wires” weaving a packet switching on-chip and off-chip network
The HW architecture should scale on next deep-submicron technologies
Challenges: how to program a tiled architecture
Benchmarks multi-loudspeaker multi-source wave field synthesis, Multi-microphone voice extraction from noise on multi-microphone Ultrasound scanners Physical modelling of quantum chromo dynamics

January, 2007 3Introduction to SHAPES 3
HWHW
HW Objectives maintain profitable average selling prices control NRE by IP reuse
HW Solution appropriate granularity: “Small” Tiles (<10 MGate) connected by
“short (first neighbours) wires” Inside the typical elementary Tile:
Fully C programmable VLIW DSP for computing + RISC for control + Distributed Network Processor (a kind of generalized inter-tile DMA
controller) for inter-tile communication multi-tile Silicon area >40mm2 <90mm2 management of logic & place & route complexity through IP reuse multi-level network
Intra-tile: multi-layer bus matrix Inter-tile: NoC (intra-chip) + 3DT (inter-chip)
distributed routing fabric connects on-chip and off-chip tiles weaving a packet switching network

January, 2007 4Introduction to SHAPES 4
SWSW
Communication centric, real-time aware programming environment
Application description: model based with explicit annotation of real-time constraints
Provide automated optimized binding of processes to computing resources and binding of inter-process communication on communication resources + scheduling of processes and their communication
Provide automated generation of hardware dependent software support
Retargetable compilation managing intra-tile and inter-tile parallelism, bandwidth and latencies
Fast simulation

January, 2007 5Introduction to SHAPES 5
Consortium Composition and Consortium Composition and Roles of the PartnersRoles of the Partners
System SWETH Zurich - Distributed Operation Layer: manages application parallelismTIMA Lab and THALES - Hardware dependent Software Layer and RTOSTARGET Compiler Tech. - Retargetable CompilersRWTH Aachen Univ. – Fast Simulation of Heterogeneous Multi Proc. Systems
System HWATMEL Roma - Tile:
Evolution of (Diopsis®: mAgicV VLIW DSPTM + RISC) + INFN DNPTM
INFN Roma - DNPTM Distributed Network Processor + 3D Toroidal Eng.:Evolution of APE Massive Parallel Processors
STMicrolectronics + Univ. of Cagliari and Pisa – Network on Chip:Evolution of SpidergonTM Packet Switching Network on Chip
Parallel Application benchmarkingFraunhofer IDMT – multi-loudspeaker Audio Wave Field Synthesis ESAOTE, MedCom, Fraunhofer IGD - Ultrasound scannerINFN - Physical ModellingATMEL – multi-microphone arrays for voice-extraction

January, 2007 6Introduction to SHAPES 6
Deep Sub-micron Architectures…Deep Sub-micron Architectures…
~160 MGate available on a 100 mm2 chip (45nm CMOS, 2008) Increasing GATES/CHIP Design Complexity Management:
embedded processors use a few million gates only, IP reuse possible and needed; WIRING threatens Moore’s law:
Wiring delay increases on new CMOS silicon generations The full chip cannot be reached in a single clock cycle Classic monolithic processor architectures do not scale Locally Synchronous, Globally Asynchronous needed Communication Centric SW and HW Architecture needed
… PROPOSED SOLUTION: … TILED ARCHITECTURE…BY SIMPLE GEOMETRIC DEMONSTRATION… IF CONSTANT LOGIC COMPLEXITY INSIDE EACH TILE… THEN (LENGTH OF INTRA-TILE WIRES SCALES DOWN AS THE TILE ITSELF… AND SHORT ~ FIRST NEIGHBOURS ON-CHIP AND OFF-CHIP INTER-TILE WIRES)
QUEST OF BEST TILE, ON-CHIP AND OFF-CHIP INTERCONNECT. BUT HOW TO PROGRAM? EXPLICIT PARALLEL PROGRAMMING PARADIGM, and CULTURE NEEDED
POWER DISSIPATION density approaching prohibitive values if higher clock speed used; much better Oper/Watt at moderate clock + parallelism (the human brain parallel architecture performs an excellent job at 50 HZ!... room for improvement)

January, 2007 7Introduction to SHAPES 7
Distributed Network ProcessorDistributed Network ProcessorDNP: a generalized DMA DNP: a generalized DMA controller for inter-tile or intra-controller for inter-tile or intra-tile packet routingtile packet routing
DNP
BUS Master (to read from intra-tile memories)
BUS Slave (to receive commands from RISC & DSP)
3DT X+ (forward/receive inter-tile OFF-CHIP packets)
3DT X-
3DT Y+
3DT Y-
3DT Z+
3DT Z-
NoC (to forward/receive inter-tile ON-CHIP packets)
BUS Master (simultaneous intra-tile memory write)
Collective communication

January, 2007 8Introduction to SHAPES 8
Different Types Different Types of Tilesof Tiles
DSP
DNP
Multi-Layer BUS
NoC
RISC POT
3DT
DXM
DNP
Multi-Layer BUS
NoC
RISC POT
3DT
DXM
DNP
Multi-Layer BUS
NoC
DSP POT
3DT
DXM
RDT: RISC + DSP Elementary Tile
RET: RISC Elementary Tile DET: DSP Elementary Tile
RDT
RET DET
DXM Mem Bus POT Pads
DXM Mem Bus POT Pads

January, 2007 10WP 1.6 - RISC+ VLIW DSP + DNP Tile 10
mAgicV IP Architecture mAgicV IP Architecture (Fully C programmable (Fully C programmable Gigaflops VLIW DSP)Gigaflops VLIW DSP)
4-address/cycleMultiple DSP Address
GenerationUnit
16 multi-field Address Register File10-float
ops/cycle
8R+8W 128x40Data Register File
System
2-port, 8Kx128-bit, VLIW Program Memory(DPM)
Flow Controller, VLIW Decoder
Instruction Decoder
Condition Generation
Status Register
Program Counter
VLIW Decompressor
6-access/cycleData Memory
System 2x8Kx40
(DDM)
AHB Slave,
e.g.DMA
Target
AHB MST
AHB MasterDMA
Engine
AHB SLVRST, CLOCKSIRQ OUTIRQ INDBG

January, 2007 11WP 1.6 - RISC+ VLIW DSP + DNP Tile 11
Tile Complexity estimated through Tile Complexity estimated through Synthesis & Place & Route trials Synthesis & Place & Route trials
mAgicV DSP: 915 Kgates + 1 Mbit Prog Mem + 640 Kbit Data Mem
ARM926 & peripherals <2 equivalent Mgate (including 640 Kbit mem)
Tile Complexity 4230 equivalent Kgate + DNP gate count
including on chip memories

January, 2007 12WP 1.6 - RISC+ VLIW DSP + DNP Tile 12
Silicon Floorplan Trial of Silicon Floorplan Trial of RISC + mAgicV VLIW DSP Tile RISC + mAgicV VLIW DSP Tile
DSP Reg File
DSP DataMem(DDM)
DSP Prog Mem (DPM)
DSP Logic
ARM926ARMRDM
Peripherals
AMBA Multilayer

January, 2007 13Introduction to SHAPES 13
Spidergon NoC topologySpidergon NoC topology
• It’s a family of regular/symmetric topologies
• We look for a complexity/performance trade-off• Low degree (router cost)• Low number of links (wire cost) • Symmetry (homogeneous building blocks; simple routing)• Low diameter (performance)• Good scalability (small network size granularity)

January, 2007 16Introduction to SHAPES 16
Background: APENext (2005) 2048 Background: APENext (2005) 2048 processor system, VLIW processors processor system, VLIW processors designed by INFN, manufactured by ATMELdesigned by INFN, manufactured by ATMEL

January, 2007 18Introduction to SHAPES 18
SW challenges from SW challenges from Tiled ArchitecturesTiled Architectures
Facilitate expression of parallelism: e.g. Network of Actors Express real time constraints in a formal manner, feature missing in
classical languages. This is a key cultural point!!! Avoid destroying information about available algorithm parallelism Compilation chain must fully aware of key architectural parameters:
bandwidth, computational power, pipeline and latencies Exploit memory locality – efficient management of Distributed
Memories – get rid of classical caches Manage Long delays between distant tiles Reduce Hot Spots in communications Reduce Tiled RTOS overhead (time and memory footprint) Introduce Hardware dependent Software and Hardware Abstraction
Layers Capture scalability in a library of characterized SW/HW components Support for (semi)-automation of iterative design over HW, SW,
Appl Monitor quality and real-time constraints on real HW and Simulators Simulation speed of multi-tiled architectures

January, 2007 19Introduction to SHAPES 19
SW ArchitectureSW Architecture
Optimised compilation on tiles and comms network
Distributed Operation Layer
hardware platform specification
Simulator
trace information
Model Compiler
component interaction,properties and constraints
componentsource code
mappinginformation
HdS Generator
HdSsource code
Compiler
componentbinary
HdSbinary
LinkDispatch
OS servicesbinary
gluebinary
Mapping
Memory mapping
RTOS
applicationspecs

January, 2007 20Introduction to SHAPES 20
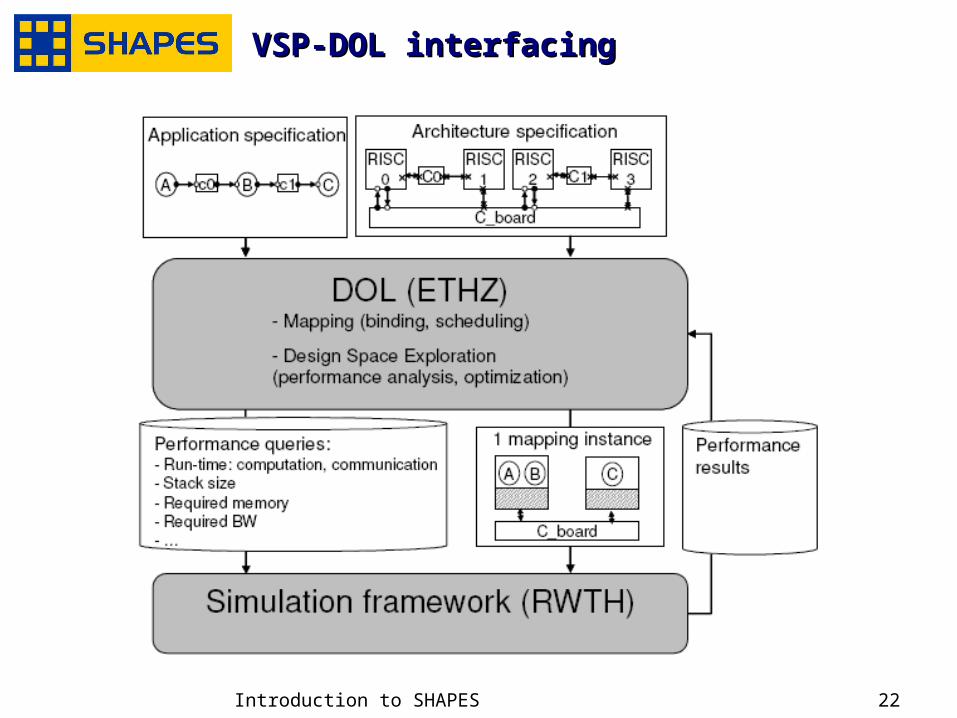
Distributed Operation Layer – Distributed Operation Layer – Application SpecificationApplication Specification
Two parts: Application structure
@system level processes FIFO SW channels
between processes interconnection between
processes
Behavior of each process process’ internals .c.c …
.xml schema definition available
A B C

January, 2007 21Introduction to SHAPES 21
Virtual SHAPES Platform (VSP)Virtual SHAPES Platform (VSP)
Enable early software development Explore different tile configurations Binary compatible with the SHAPES hardware Debugging capability Export performance information Scalability to multiple tiles
VSP
DOL
Applications
RTOSHdS
HW
SHAPES
SW and app
partners
January, 2007 22Introduction to SHAPES 22
VSP-DOL interfacingVSP-DOL interfacing

January, 2007 23Introduction to SHAPES 23
TARGET CompilerTARGET Compiler
Core related requirements
TILE
TILE TILE
TILE
OFF-CHIP MEM
OFF-CHIP MEM
OFF-CHIP MEM
OFF-CHIP MEM
TILE
TILE TILE
TILE
OFF-CHIP MEM
OFF-CHIP MEM
OFF-CHIP MEM
OFF-CHIP MEM
TILE
TILE TILE
TILE
OFF-CHIP MEM
OFF-CHIP MEM
OFF-CHIP MEM
OFF-CHIP MEM
TILE
TILE TILE
TILE
OFF-CHIP MEM
OFF-CHIP MEM
OFF-CHIP MEM
OFF-CHIP MEM
mAgicVDSP
ARM uP
uP MEM
COM
M I/F
COM
M I/F
DSP DATA MEM
COMM I/F
COMM I/F
REG FILE
DSP PROG MEM
Communication related
requirements
Conv2Div2
Sh/Log2
Conv1Div1
Sh/Log1
RF00 1 2 3
4 5 6 7
FP/I
*FP/I
*
RF10 1 2 3
4 5 6 7
FP/I
*FP/I
*
FP/I
-FP/I
+
FP/I
- +FP/I
+ -
Mul1 Mul2 Mul4Mul3
Cadd1 Cadd2
Add1 Add2MinMax2
MinMax1
P6_0
P5_0
P4_0
P3_0
P2_0
P6_1
P4_1
P5_1
P2_1
P3_1
Core_bus5Core_bus7
Core_bus5Core_bus7
mAgicV PCU
PROGRAMMEMORY
INSTR.DECODER
INSTR.SEQUEN-
CER
DECOM-PACTION
INTERRUPTCON-
TROLLER
INSTR.DECODER
mAgicV core
Support of VLIW instruction
compaction
Phase coupling: reg. allocation
SW pipelining
Support of predicated execution
Functional unit assignment for
clustered VLIWs
Communicationlatency aware
scheduling
Intra-tile multi-core on-chip debugging
Inter-tile communication
using DNP

January, 2007 24Introduction to SHAPES 24
TIMA - HdS & RTOS - PrinciplesTIMA - HdS & RTOS - Principles
Hardware dependent Software: software directly dependent on the underlying hardware
Communication differentiation Intra-subsystem & inter-subsystem communications
Networked operating system:
Application
HdS APIRTOS
(RT Linux)
COMM
HAL ARM
ARM Subsystem
Application
HdS API
Monitor COMM
HAL DSP
DSP Subsystem
Hd
S
Hd
SSW
HW
SW
HW

January, 2007 25Introduction to SHAPES 25
SW ArchitectureSW Architecture
hardware platform specification
simulation environment(RWTH) WP 1.4
trace information
model compiler(ETHZ, RWTH)WP 1.11, WP 1.4
component interaction,properties and constraints
componentsource code
mappinginformation
HdS generator(TIMA)WP 1.10
HdSsource code
Compiler(TARGET)
WP 1.9
componentbinary
HdSbinary
LinkDispatch
(TARGET)WP 1.9
OS servicesbinary
gluebinary
mapping(ETHZ) WP 1.11
Memory mapping
RTOS(TIMA, THALES)
WP 1.10
applicationspecification

January, 2007 26Introduction to SHAPES 26
SHAPES SW Architecture: challengesSHAPES SW Architecture: challenges
High-level exploration, mapping, and simulation: What is the degree of available parallelism? How can it be exposed to
the mapping stage? What is suitable model-based specification formalism? What adaptations are necessary in order to expose the inherent parallelism?
Define a common Profiling Trace Interface (PTI) over which information can be exchanged.
Hardware-dependent software and operation system: To use the provided features of the HdS (i.e. platform abstraction) a
generic interface API has to be defined. Compiler technology:
Modeling low-latency communication interfaces in the C source code that is the input for the C compiler, for the computational tiles.
Investigate how HdS can be modeled entirely in C source code, to be compiled by the C compiler for the computational tiles.
January, 2007 27Introduction to SHAPES 27
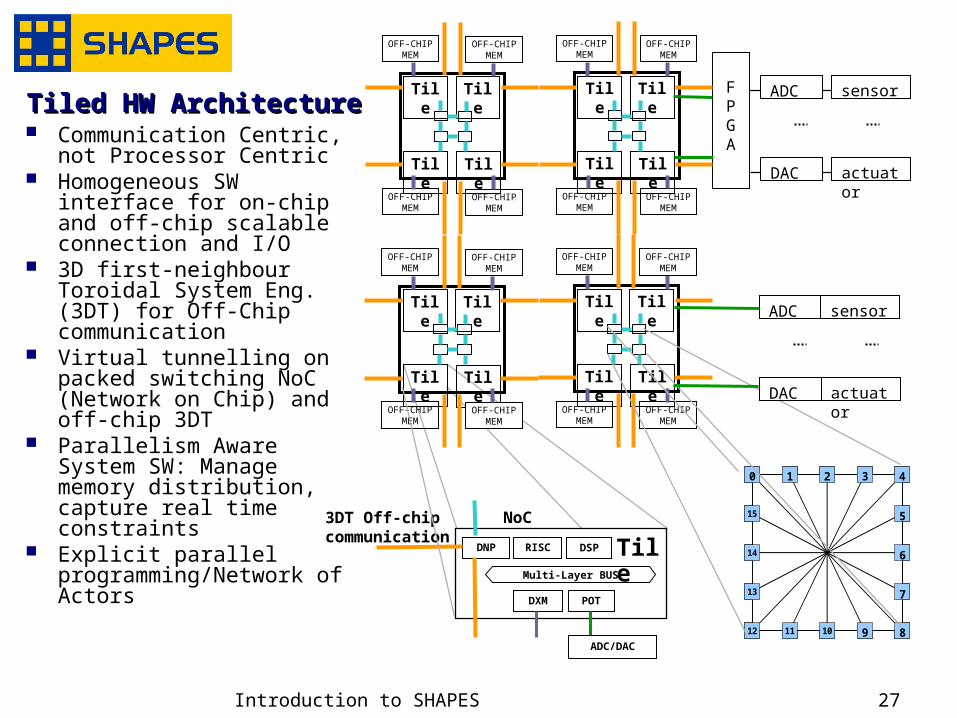
Tiled HW ArchitectureTiled HW Architecture Communication Centric,
not Processor Centric Homogeneous SW
interface for on-chip and off-chip scalable connection and I/O
3D first-neighbour Toroidal System Eng. (3DT) for Off-Chip communication
Virtual tunnelling on packed switching NoC (Network on Chip) and off-chip 3DT
Parallelism Aware System SW: Manage memory distribution, capture real time constraints
Explicit parallel programming/Network of Actors
0 1 2 3 4
5
6
7
89101112
15
14
13
0 1 2 3 4
5
6
7
89101112
15
14
13
FPGA
DAC actuator
Tile
Tile
Tile
Tile
OFF-CHIP MEM
OFF-CHIP MEM
OFF-CHIP MEM
OFF-CHIP MEM
Tile
Tile
Tile
Tile
OFF-CHIP MEM
OFF-CHIP MEM
OFF-CHIP MEM
OFF-CHIP MEM
Tile
Tile
Tile
Tile
OFF-CHIP MEM
OFF-CHIP MEM
OFF-CHIP MEM
OFF-CHIP MEM
Tile
Tile
Tile
Tile
OFF-CHIP MEM
OFF-CHIP MEM
OFF-CHIP MEM
OFF-CHIP MEM
DSPDNP
Multi-Layer BUS
NoC
RISC
POT
3DT Off-chipcommunication
DXM
Tile
ADC sensor
DAC actuator
ADC sensor
ADC/DAC

January, 2007 28Introduction to SHAPES 28
The tile:The tile:
JTAGROM
Bridge
DXM Interface(AHB EBI)
RDM SRAM
PDMA
mAgicV DSPTM JTAG
DSPAHB
Master
4-addr/cycle
Multiple DSP Addr Gen
10-float ops/cycle
16-port 256x40
Data Regs
mAgicVTM DPM2-port
DDM6-access/
cycle
DSPAHB Slave
Slave
ICE
RISC
RCM Instr Cache MMU RCM Data CacheRDM IF BIUI D I D
Master
Multi-layerBus MATRIX
APBDNPAHB
Master
DNPAHB Slave
DNPAHB
Master
DNP
X+
DXM
X-
Y+
Y-
Z+
Z-
C+
NoC(NI)
P E R I P H E R A L S
DIOPSISDIOPSIS®® + + DNPDNP