scalable platforms for web services eecs600 internet applications michael rabinovich
TRANSCRIPT

Scalable Platforms for Web Services
EECS600 Internet Applications
Michael Rabinovich

Web Resource Provisioning Challenge
• How much resources to provision?– Potentially unlimited client populations
• How to add capacity quickly?– In time for serving flash crowds
• What to do with extra capacity once the flash crowd ebbs?
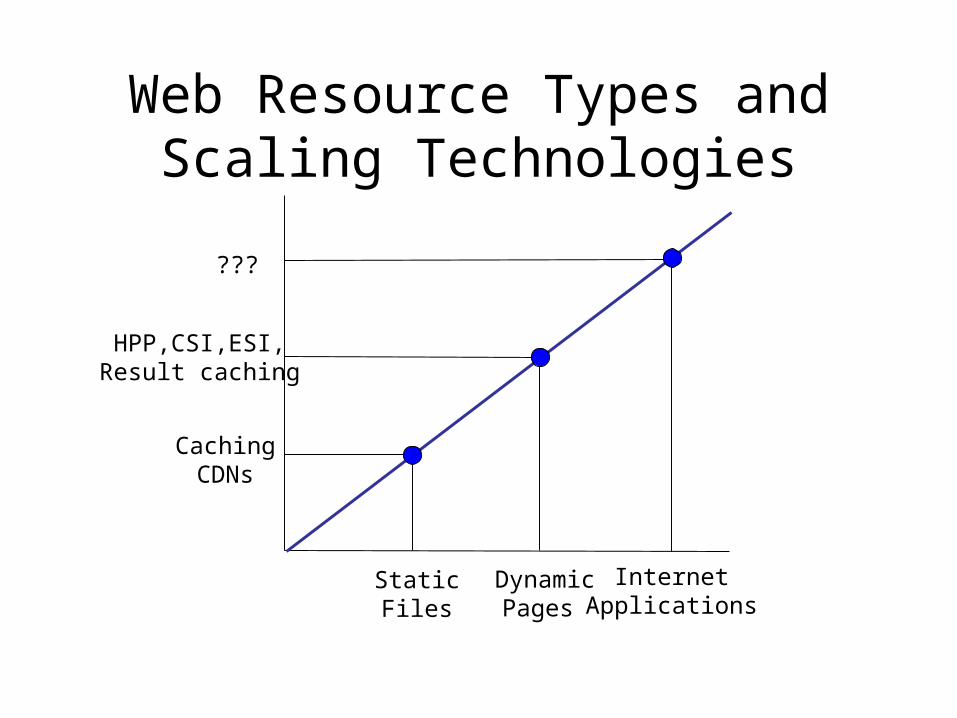
Web Resource Types and Scaling Technologies
Static Files
Dynamic Pages
InternetApplications
CachingCDNs
HPP,CSI,ESI,Result caching
???

Utility Computing• Analogous to power grid
– Autonomous resources added to the grid– Clients’ needs satisfied by transparent work distribution
• Started in scientific computing for CPU-intensive tasks
• Many difficult challenges in moving to Internet at large– Security and privacy– Billing and accounting– Migration of computation– Data consistency

Utility Computing for the Web:A Feasible Interim Approach
• Confined to a single network/hosting service provider– Security and privacy simplified by private network
• Natural boundaries in computation simplify migration– Automatic app deployment rather than migration of computation
• Typical tiered architectures simplify data consistency
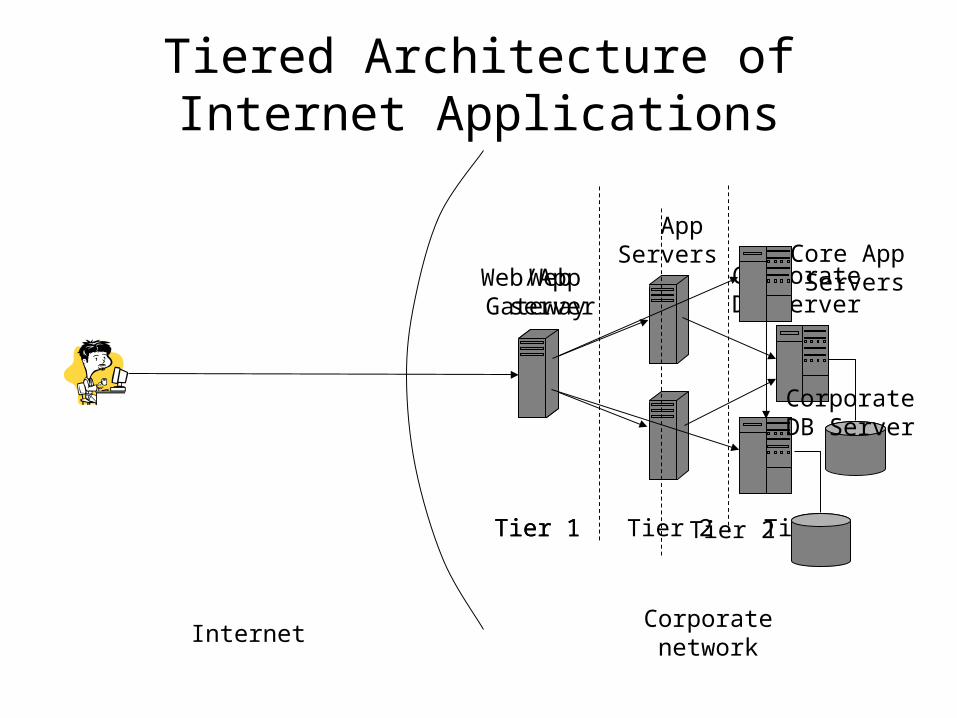
Tiered Architecture of Internet Applications
Web Gateway
AppServers
Corporate DB Server
Tier 1 Tier 2 Tier 3
InternetCorporatenetwork
Web/App server
Core App Servers
Corporate DB Server
Tier 1 Tier 2
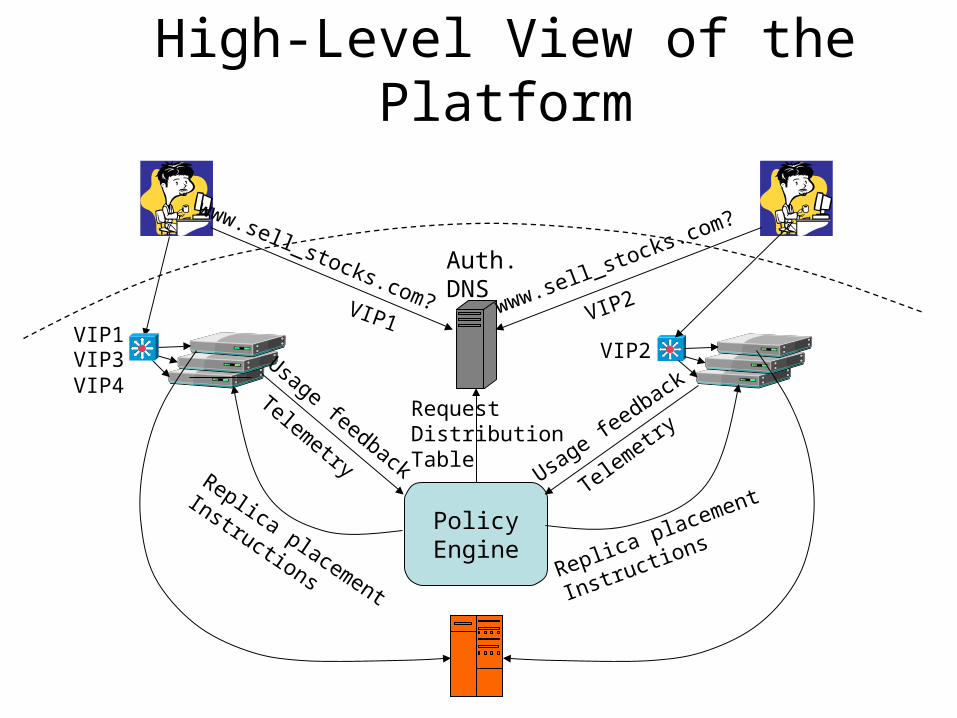
High-Level View of the Platform
Auth.DNS
PolicyEngine
Usage feedback
Telemetry
RequestDistributionTable
Usage fe
edback
Telemetry
Replica placement
Instructions
Replica placement
Instructions
www.sell_stocks.com? www.sell_stocks.com?
VIP1VIP2VIP3
VIP4
VIP1 VIP2
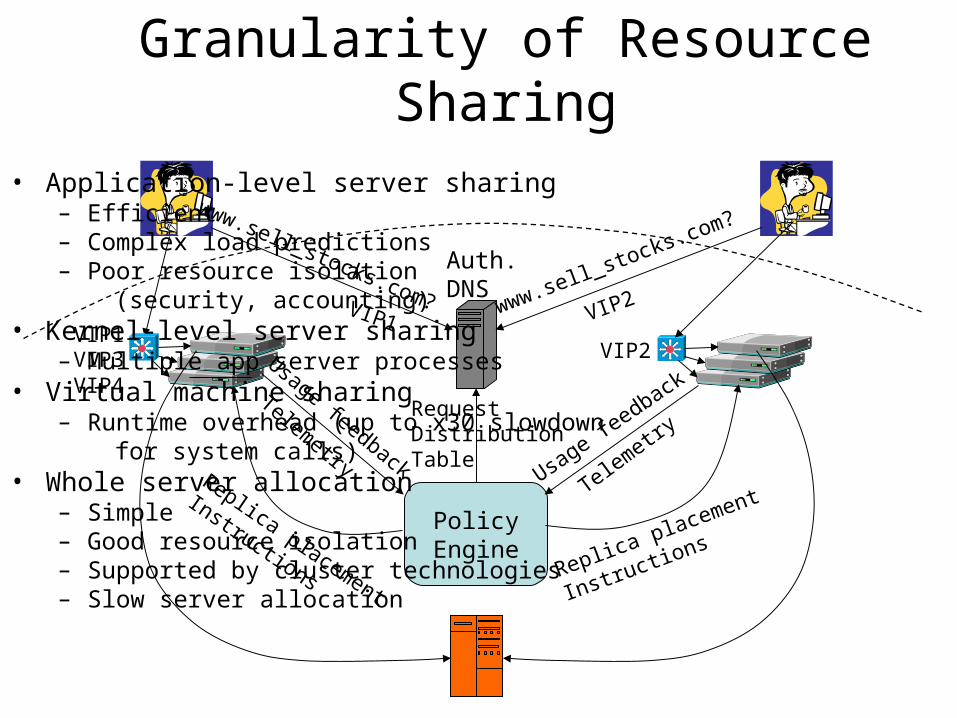
Granularity of Resource Sharing
VIP1VIP3VIP4
Auth.DNS
PolicyEngine
Usage feedback
Telemetry
RequestDistributionTable
Usage fe
edback
Telemetry
Replica placement
Instructions
Replica placement
Instructions
www.sell_stocks.com? www.sell_stocks.com?
VIP2
VIP1 VIP2
• Application-level server sharing – Efficient – Complex load predictions– Poor resource isolation (security, accounting)
• Kernel-level server sharing– Multiple app server processes
• Virtual machine sharing– Runtime overhead (up to x30 slowdown for system calls)
• Whole server allocation– Simple– Good resource isolation– Supported by cluster technologies– Slow server allocation

Major Components• Framework
– Dynamically installing and uninstalling applications
– Maintaining replica consistency
– Supporting stateful client sessions
• Algorithms and policies– Admission control algorithm
– Request distribution algorithm
– Application placement algorithm
• Performance and demand monitoring
Auth.DNS
PolicyEngine

Application Server Sharing
• Built on top of standard Web server: Apache + (Fast) CGI
• Uses standard HTTP throughout

Replication Framework• Inspired by work on software distribution (e.g., Marimba) • Metafile for each application containing:
– A list of time-stamped files (data and executable files)
– An initialization script (or a pointer to it)
FILE /home/applications/mapping/query_engine.cgi 1999.apr.14.08:46:12 FILE /home/applications/mapping/map_database 2000.oct.15.13:15:59 FILE /home/applications/mapping/user_preferences 2001.jan.30.18:00:05
SCRIPT mkdir /home/applications/mapping/access_stats setenv ACCESS_DIRECTORY /home/applications/mapping/access_stats
ENDSCRIPT

Application Metafile
• A metafile is a simple static Web page• Having a metafile is sufficient to deploy the
application• Having the current metafile is sufficient to bring the
application replica up-to-date.• Consistency of application replicas = consistency of
cached copies of the metafile

Framework Tasks
• Creating a replica– Obtaining a metafile– Obtaining a tar file with all files listed in the metafile– Running the initialization script
• Updating a replica– Obtaining the diff of metafiles– Obtaining files that are new
• Deleting a replica– Retaining the deleted replica for some time to process
residual requests before physical deletion
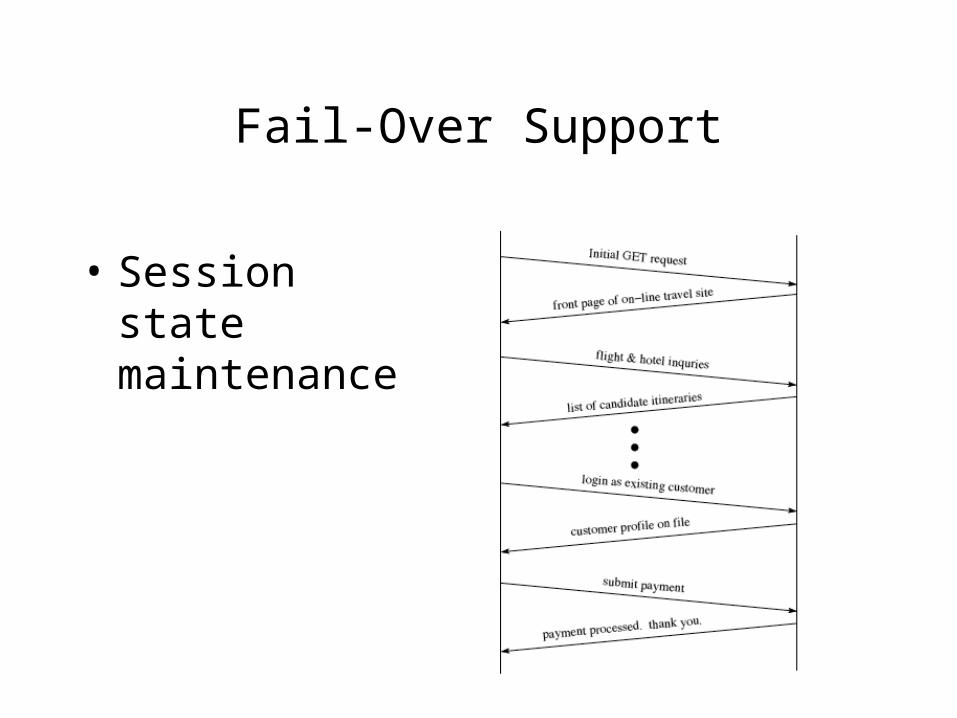
Fail-Over Support
• Session state maintenance
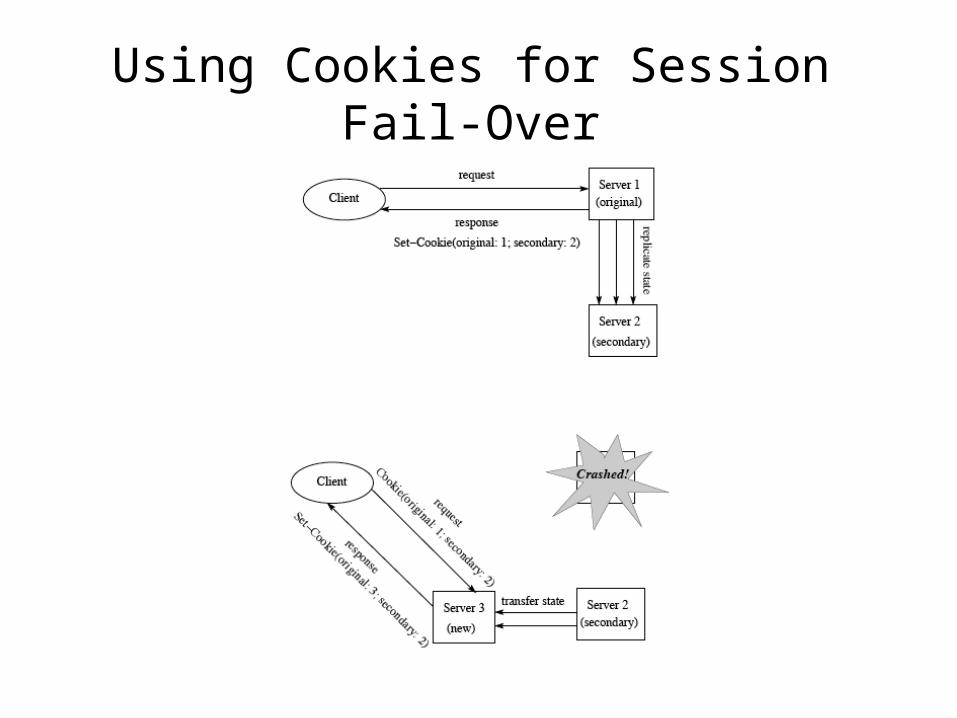
Using Cookies for Session Fail-Over

Algorithms and Policies
• Metrics• Measurement infrastructure• Algorithms

Metrics Taxonomy
• Measuring “What”– Proximity– Server load– Aggregate
• Measuring “How”– Passive measurements– Active measurements
• Measuring “When”:– Synchronous– Asynchronous
• Metric stability– Dynamic– Static

Proximity Metrics• Goal: select a “nearby” server to process a client request• Benefits: lower latency and network load• Static metrics:
– Geographical distance• (+) Provides strong lower bound for latency• (-) May not correlate with routing paths
– Autonomous System hops• (+) Counts peering points and not over-provisioned backbone hops• (-) Equates large and small ASs
– Network hops• (+) Distinguishes large and small ASs• (-) Equates local area hops, wide-area hops, and NAP hops
– General drawback: do not account for congestion
• Dynamic metrics: – Message RTT– Path bandwidth

Combining Static Proximity Metrics
• Divide the Globe into large regions• A client is closer to servers in the same region than in
different regions• Among servers in the same region, a client is closer
to a server that is fewer AS hops away• Among servers in the same region and the same AS,
a client is closer to a server with fewer network hops• Otherwise servers are equidistant.

Proximity Metrics in Practice
• Companies’ proprietary secret sauce – Knowledge of peering points and their congestion– Pricing with neighboring ISPs– Knowledge of Internet topology

Server Load Metrics
• CPU utilization• Disk utilization• Network card utilization• The number of TCP connections• Number of pending requests• Server response time• Others
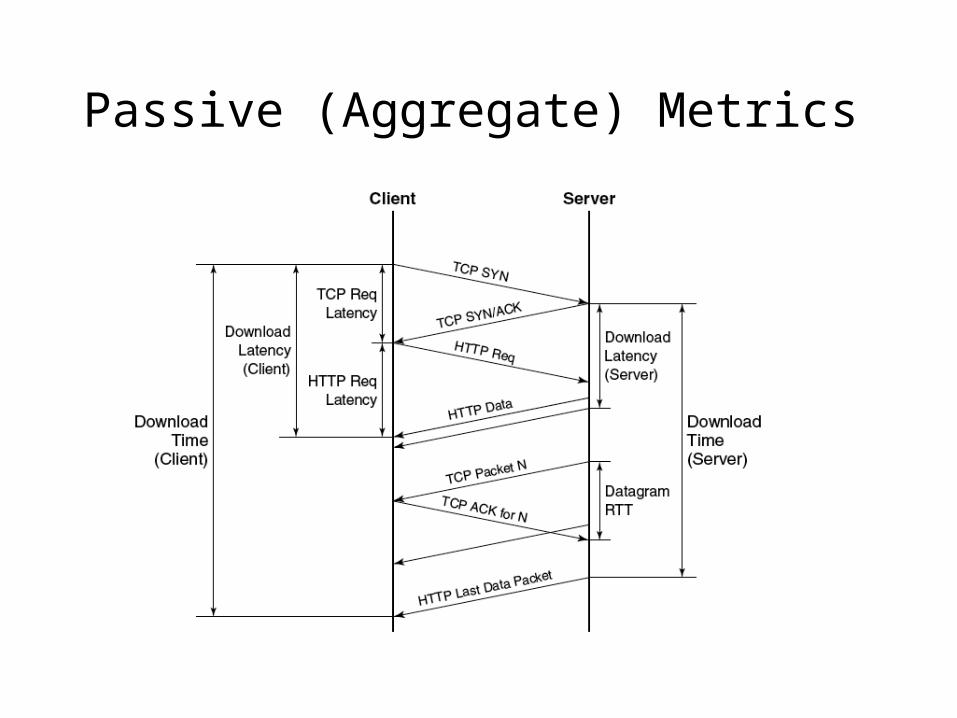
Passive (Aggregate) Metrics

Aging Dynamic Metrics
• Exponential aging
ave_new = (1-r) x ave_cur + r x sample

Measurement Infrastructure
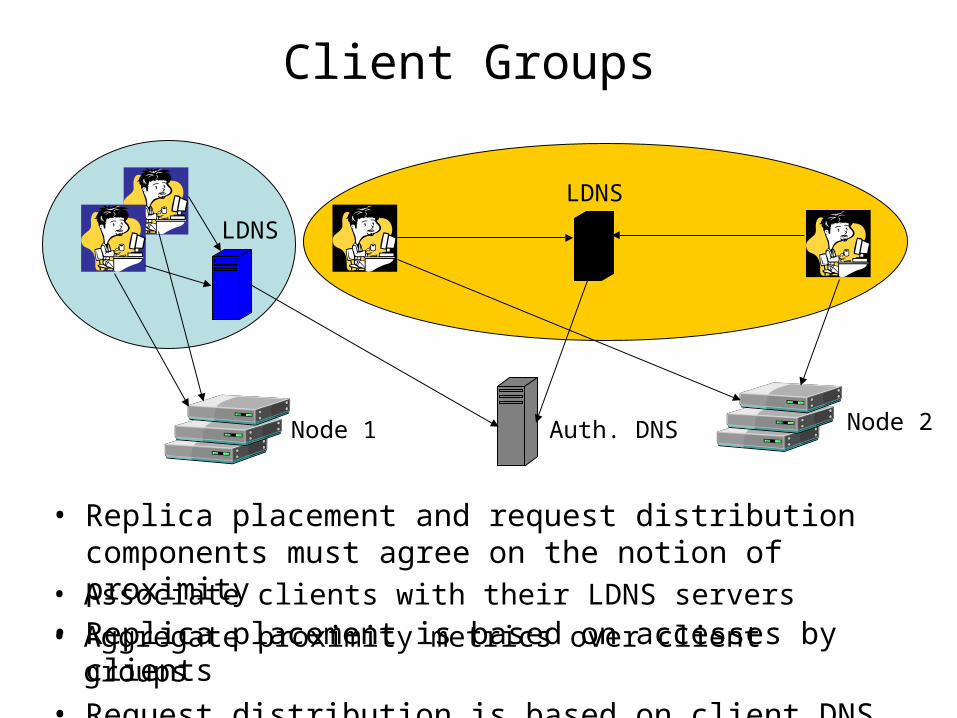
Client Groups
• Replica placement and request distribution components must agree on the notion of proximity
• Replica placement is based on accesses by clients• Request distribution is based on client DNS
• Associate clients with their LDNS servers• Aggregate proximity metrics over client groups
Auth. DNS
LDNS
LDNS
Node 1 Node 2

Measuring Client-Node Proximity
• Goal: (client_group I, node J, app K) Performance
• End-to-end response time measurements– Simple– Catch-all measure
• Scalability problem– 1.5M client groups– ~20 nodes– ~100 applications
– 3G entries with random access!
• Measurement availability problem
• Proximity depends on multiple factors
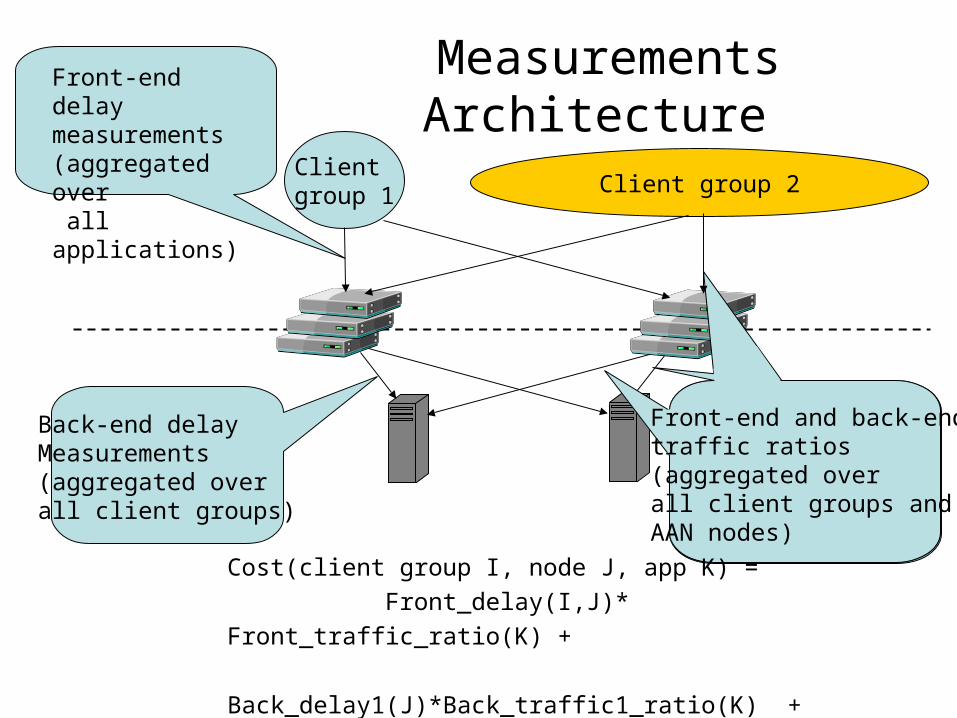
Measurements Architecture
Client group 1 Client group 2
Front-end delaymeasurements(aggregated over all applications)
Back-end delayMeasurements(aggregated overall client groups)
Cost(client group I, node J, app K) =
Front_delay(I,J)* Front_traffic_ratio(K) +
Back_delay1(J)*Back_traffic1_ratio(K) +
Back-delay2(J)*Back_traffic2_ratio(K)
Front-end and back-endtraffic ratios(aggregated over all client groups and AAN nodes)

Algorithms
• Request distribution• Replica placement• Taxonomy
– Global optimization vs. greedy– Centralized vs. distributed/hierarchical

Request Distribution Issues
• Combination of server load and client proximity factors
• Algorithm Stability– Load oscillations due to “herd effect”– Randomization violates proximity in the common case
• Challenge:– Select the closest server – Guard against overload– Be responsive in load redistribution– Avoid load oscillations

Replica Placement Issues
• Combination of server load and client proximity factors
• Simple Idea (which does not quite work):– If an existing server is overloaded, create more replicas– If an existing server is underloaded, remove some replicas– If a node is closer than existing replicas for significant part of
demand, migrate or replicate there
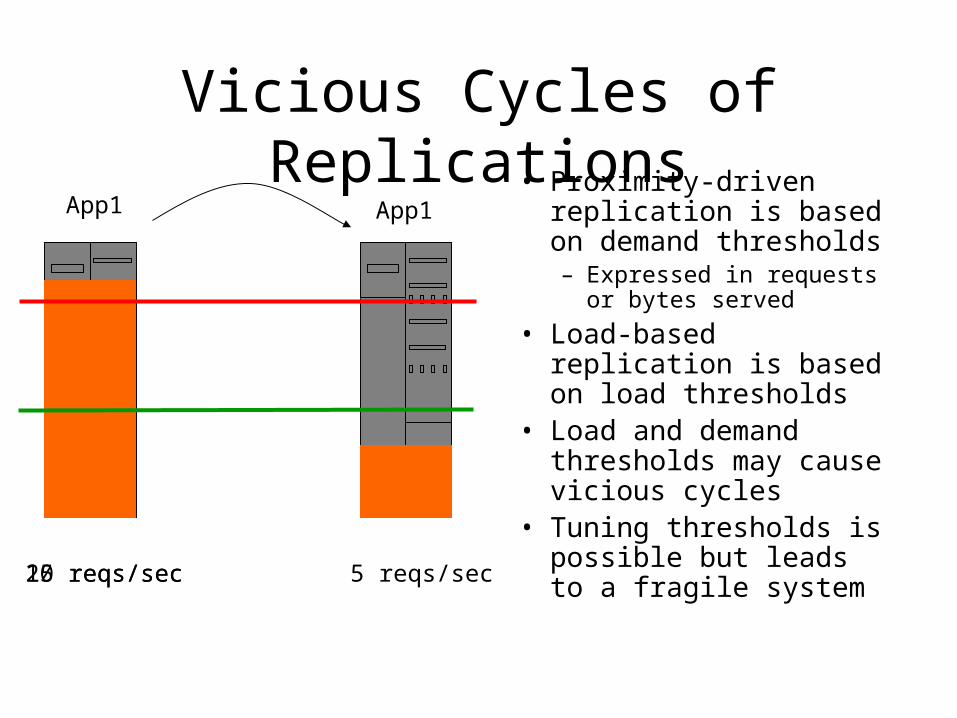
Vicious Cycles of Replications• Proximity-driven
replication is based on demand thresholds– Expressed in requests or
bytes served
• Load-based replication is based on load thresholds
• Load and demand thresholds may cause vicious cycles
• Tuning thresholds is possible but leads to a fragile system
20 reqs/sec
App1 App1
15 reqs/sec 5 reqs/sec