sawmill: analytics over clouds using hadoopfiles.meetup.com/1634302/chug 20100721 sawmill.pdfclouds...
TRANSCRIPT

Sawmill: Analytics over Clouds using Hadoop
Collin BennettOpen Data Group
2010/07/21 Chicago area Hadoop User Group

Introduction to the Problem

Scaling Data Analysis
• There is an increasing need to Scale Analytics to the Cloud; to perform analytics on large systems
• Systems where either the data is already on a cloud or can only be realistically stored on one
• Take advantage of the Large Data Cloud and analyze without exporting the data

Bring Analytics to the Data
• Open Data works with clients who have a lot (terabytes, petabytes) of data sometimes spanning several years
• Data usually already resides in some type of distributed file system
• Data is often proprietary or confidential

Problem
• How do you perform analytics on the data?
- Transfer to compute nodes on the same network (slow, is there enough space?)
- Use an Analytic Engine on the storage nodes (Distributed Analytic applications can be large, expensive, and hard to get data in and out of)

A Solution
• Create models to work on pieces of the data, so that a chunk can be analyzed without needing to know about the other chunks
• Use a parallel framework which works with the Distributed File System (Hadoop / HDFS, Sphere / Sector, GFS / Mapreduce, etc) to segment the data
• Run instances of a Scoring Instance on each data node independently of each other.

Not just Analytics
• Lot of applications are not naturally parallelizable and cannot take advantage of distributed data
• In describing a way to scale analytics to the cloud, we realized that if scoring is to parallelized in general, then it has to be achieved independently of the Application

With the proper analytic infrastructure, cloud computing can be used for data preprocessing, for scoring, for producing models, and as a platform for other services in the analytic infrastructure.

Introduction to Sawmill
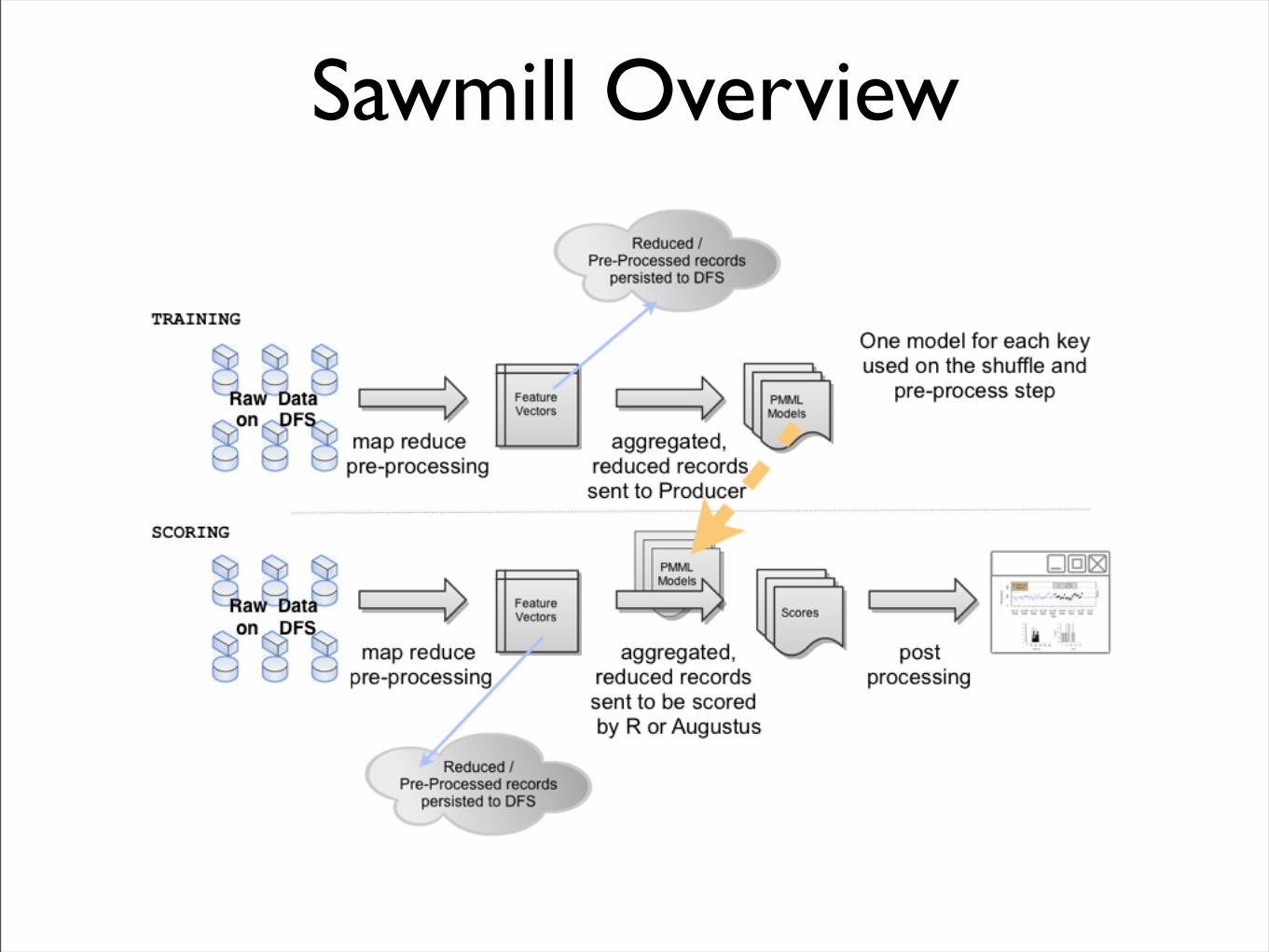
Sawmill Overview

What is SawmillSawmill is a description of an infrastructure rather than a product such as a database or web server.
The goal in defining Sawmill was to have the individual components satisfy a need, rather than be a product.
For example,
A Distributed Filesystem stores the data not HDFS
A Parallel Framework sorts and aggregates not MapReduce

Standards-based Architecture
• Data stored in a Distributed File System on a private cloud.
• A parallel programming framework over the cloud like
• Google’s MapReduce
• NCDM’s Sector
• Apache’s Hadoop
• A statistical model, in PMML, for the data analysis model
• A Scoring Engine capable of Producing and Consuming PMML models and the associated data
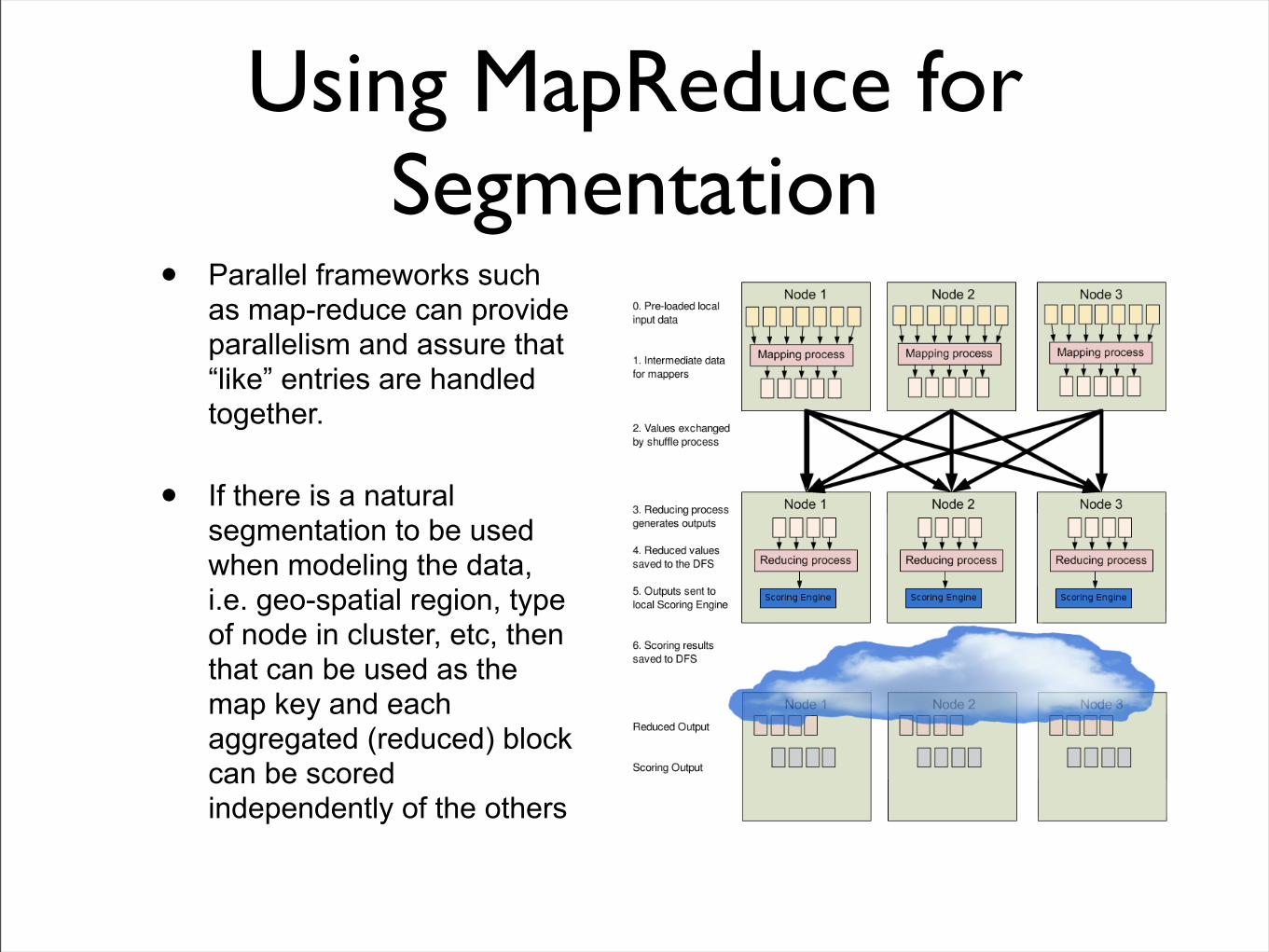
Using MapReduce for Segmentation
• Parallel frameworks such as map-reduce can provide parallelism and assure that “like” entries are handled together.
• If there is a natural segmentation to be used when modeling the data, i.e. geo-spatial region, type of node in cluster, etc, then that can be used as the map key and each aggregated (reduced) block can be scored independently of the others

Map Reduce Code
• Nothing special is done with mapping other than deciding on an appropriate key
• In fact, it is the intrinsic nature of the map and shuffle steps that we are relying on
• All events / records for a segment (map key value) gets grouped and sorted

Data Fields at Different Stages

Reducer Code
• What is the structure of the data that the analytic application expects?
• In addition to ‘reducing’ the records for each key, the reducer manipulates the data structure to get it into a usable format.
• The reducer needs to get a segment-- a fully reduced key to a local instance of the analytic application

Reducer Application
• There are at least three ways to tie the mapreduce process to the application.
- MACHINE: One instance of the application on each data node (or X per node)
- REDUCER: One instance of the application bound to each reducer
- SEGMENT: Instances can be launched by the reducers as necessary (when keys are reduced)

Tradeoffs
• You need to have a general idea of
- how long the records for a key take to be reduced.
- how long the application takes to process the segment
- how many keys are seen per reducer
• The goal is to prevent bottlenecks

One instance per node
• Good
- Saves on memory and CPU
• Bad
- Likely more than one reducer per node. Also, some nodes will have more reducers than others
- How to get data from multiple reducers to a single instance without contention?
- If there are X instances, how are they load balanced?

One instance per Reducer
• Good
- Straight forward hand off of the data from the reducer to the application
• Bad
- Unless the application is about as fast as the reducer, there is a backup. What to do with the segments waiting?
- a priori, do not know how many reducers will be on a given node. Capacity planning.

Multiple instances per Reducer
• Good
- Unless you have a good partitioning function, keys are not evenly distributed. This lets reducers with more keys run more applications
• Bad
- CPU and memory nightmare
- Constraints are necessary

From Reducer to Application
• Write reduced key to local disk and to the HDFS. The application looks for the local version.
• Reducer can push the segments to the application: Standard I/O if not already using Hadoop’s Streaming Interface, Unix named pipes (FIFO), HTTP, persist a socket connection, etc.
• Direct to the application in some cases

Reducer Examples
• Reducer writes to Standard Out which gets picked up by Hadoop and sent to the HDFS
• The local write f.write(...) is to a directory that the application is watching

Reducer Examples• Reducer writes to Standard Out which gets
picked up by Hadoop and sent to the HDFS
• Application is called directly for each processed key

Reducer Examples
• Reducer writes to Standard Out which gets picked up by Hadoop and sent to the HDFS
• As each record is finished for a key (rather than each key), it is sent to the Application for processing

Performance
• Reducing an individual key is quick unless there is not a lot of granularity
• This means that a reducer hands the data to the application quickly
• In practice, the application finishes some segments before the mapreduce job is finished.

Performance
• Scoring segments gets parallelized across the number of Reducers or nodes
• Scales better than sending larger data files to be scored

Small Example: Scoring Engine written in R
• R processed a representative segment in 20 minutes
• Using R to score 2 segments concatenated together = 60 minutes
• Using R to score 3 segments concatenated together = 140 minutes

Scaling continued
• 1 month of data, about 50 GB
• 300 mapper keys / segments
• Mapping and Reducing < 2 minutes
• Scoring: 20 minutes * max of segments per reducer
• Had anywhere from 2 to 3 reducers per node and 2 to 8 segments per reducer.
• Often ran in under 2 hours.

Canned Example
• Since there are a lot of moving parts, we put together a canned example with code for each step.
- synthetic data generator
- map and reduce code
- example of handing off the segments by writing to a local file and sending over HTTP
- pmml model

Malgen

Malgen
• Python scripts which generate large, distributed data sets suitable for testing and benchmarking parallel processing applications
• The data sets can be thought of as site-entity log files concurrently on multiple remote nodes of the cluster
• malgen.googlecode.com

Testbed Example

Health and Status Monitoring
• Gather performance and health metrics from OCC testbed & associated machines
• Over 330 machines monitored
• New ones added to monitoring weekly
• 23 collected data points: 1.6 GB / Day
• The Time of Collection is added as the 24th.
• Data for all nodes is accumulated as a list of JSON objects, compressed over HTTP

Data on the Cloud and Change Detection
• Change Detection utilizes baseline data and looks for changes
• Storing data on a large data cloud allows the data sample to grow to allow for a better baseline sample without worrying about capacity
• Parallel frameworks such as map-reduce allow for scoring data on the cloud by sorting and aggregating events
• If data & model allows for cubes of models, then scoring & model-production can be distributed
Using Segments for the model allows the Producing / Consumer to be parallelized even when the Scoring Engine is not naturally distributed

What we want to know is
• When is a machine behaving differently than expected?
• Under which criteria?
• What is the score?

Some of the nodes being monitored


Data Fields at Different Stages

Why Sawmill Works(Why Segmentation / Mapping is useful)
• Specific nodes on a rack could have dedicated jobs, such as admin, home directories, logging service, etc.
• These nodes should have different expected behavior from the other nodes in their rack, but the same behavior as their counterparts in other racks.
• All nodes should exhibit different behavior when under legitimate high load.

Other Natural Ways of Segmenting Data
• by Geographical boundary for spatial data
• by Time or Data for logs or events
• by User for weblogs, account details

45
System detects changes from baselines in real-time and distributes them as alerts.
Geographical Segmentation• 833 traffic sensors, 170,000 new sensor readings per day• also image, text & semi-structured data (about 1 TB)
Highway Traffic

Results
• Over 1000 separate statistical baselines models developed and deployed.
• Effective for discovering nodes that are hindering effective use of OCC’s large data cloud.
• Dead nodes are easy to identify and remove.
• Removing just one or two “slow” nodes from a pool of 100 nodes can improve overall performance by 15% ‐ 20%.
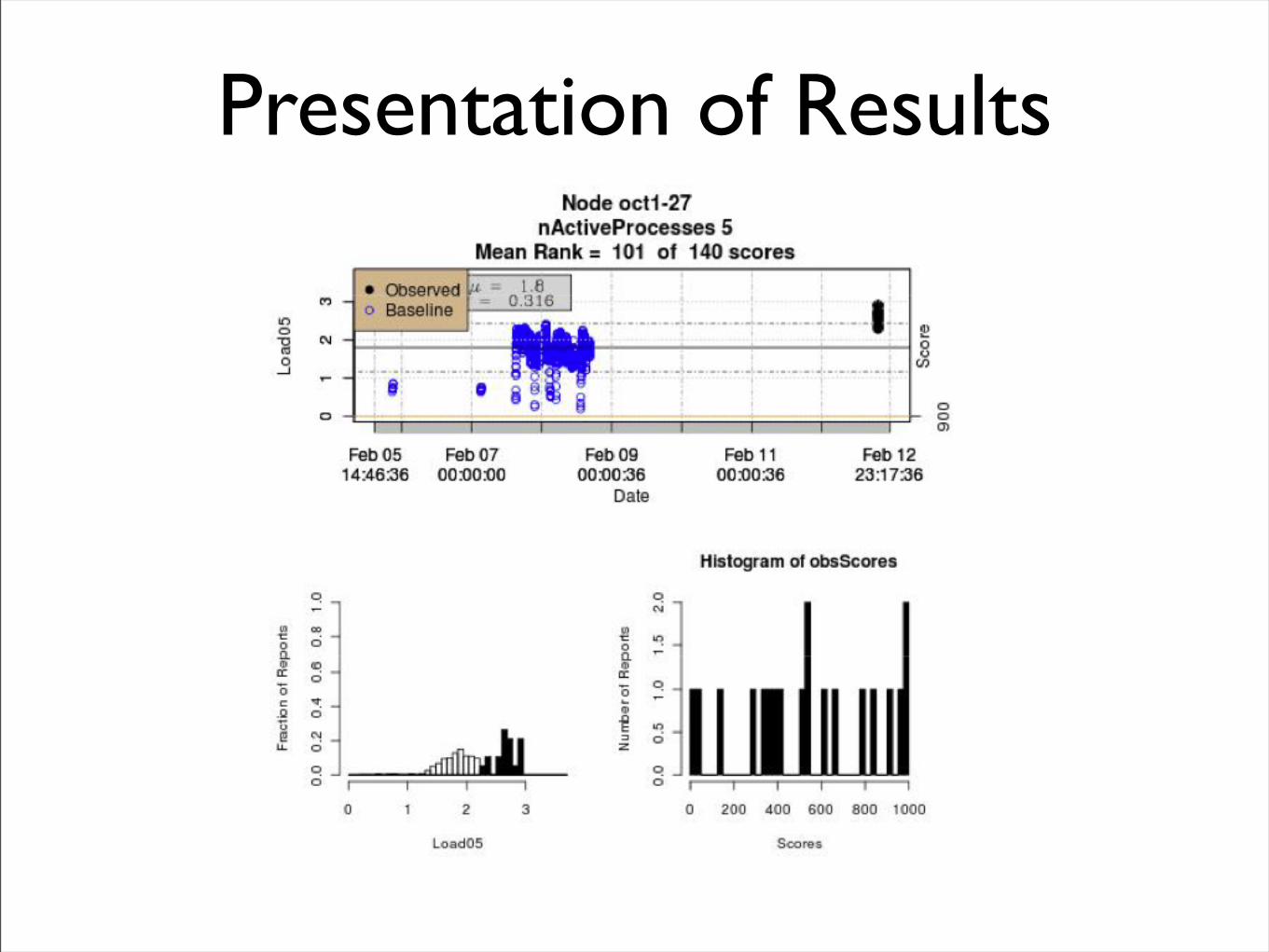
Presentation of Results

PMML

For the Dicing and Slicing, between Scoring Engine instances we use
PMML
• Has nothing to do with Hadoop or this talk
• It lets use create and combine models from each node.
• Separates models from the code and deployment
• Data Mining Group: http://dmg.org

Q: Why PMML ?
• Sawmill does not assume which large data cloud is used. Nothing prevents it from running under a variety of Distributed File Systems.
• Any parallel framework allowing for user-created functions which map, sort and aggregate data suffices at the processing layer.
• To make this truly general, we use models realized in PMML, so that Scoring Engines can be swapped in and out.
Portability

• PMML also supports XML elements to describe data preprocessing.
Model Producer
PMMLModel
DataData Pre-
processing features
algorithms to estimate models
(Simplified) Architectural View

A PMML File<PMML version="4.0"> <Header copyright="Open Data 2010" /> <DataDictionary> <DataField name="cuteness" dataType="float" optype="continuos" /> <DataField name="bonecount" dataType="integer" optype="continuos" /> </DataDictionary> <MiningModel functionName="baseline"> <MiningSchema> <MiningField name="bonecount" /> <MiningField name="cuteness" /> </MiningSchema> <Segmentation multipleModelMethod="selectAll"> <Segment> <CompoundPredicate booleanOperator="and"> <SimplePredicate field="cuteness" operator="greaterThan" value="-0.500000" /> <SimplePredicate field="cuteness" operator="lessOrEqual" value="0.500000" /> </CompoundPredicate> <BaselineModel functionName="baseline"> <MiningSchema> <MiningField name="bonecount" /> </MiningSchema> <TestDistributions field="bonecount" testStatistic="zValue" testType="threshold" threshold="3"> <Baseline> <GaussianDistribution mean="0.0" variance="1.0" /> </Baseline> </TestDistributions> </BaselineModel> </Segment>... </Segment> </Segmentation> </MiningModel></PMML>

Conclusion

For more information
• Robert Grossman Managing Partner
- rgrossman.com (blog)
• Collin Bennett
Open Data Groupwww.opendatagroup.com