sap-migrationen auf unicode - doag.org · sap-migrationen auf unicode ... 1010 11 0000 00 0000 1110...
TRANSCRIPT

© 2004 Hewlett-Packard Development Company, L.P. The information contained herein is subject to change without notice
SAP-Migrationen auf Unicode
Sebastian BuhlingerSAP Consultant, HP-SAP EMEA CC

3/31/2004 2
Agenda
1. Introduction to Unicode
2. Unicode & SAP in General
3. Technology in Depth

3/31/2004 3
Introduction to Unicode

3/31/2004 4
1. Introduction to Unicode• History of character encoding• Problem of character encoding• From ACII to Unicode• What is Unicode exactly?• Unicode Encodings

3/31/2004 5
History of Character Encoding• Historically, computers were pretty slow, had fairly
little memory and were very expensive• Up to 1960s I/O meant pushing holes into paper
tapes• Most of the character sets date back to punch-card
age and are designed with these cards in mind• In the early days of computers every hardware
manufacturer used proprietary technology (and encodings)
• International data interchange was no issue and so nothing needed to fit together

3/31/2004 6
Problem of character encoding• Which number is assigned to which character?• When typing an ‘A’ on the keyboard, the
computer uses the character code as a basis for pulling the character shape of ‘A’ from a font file listing with the same binary number, and displays or prints it
• The character ‘A’ may also have different integer values in different programs or data files (‘A’ might be ‘•’ in an Arabic font file)
• In some instances no number available for certain characters (f.i. “ä” à Ä)
• All data encoded in the form of binary numerical codes

3/31/2004 7
Character repertoire• English alphabet: with some digits and little more:~ 60 characters
• Western European Standard: ~ 300 characters for several languages
• Korean: ~12.000 syllables• Chinese dictionaries: ~ 50.000 letters• Hundreds of other characters in common use, such as math and currency symbols

3/31/2004 8
From ASCII to Unicode• Most character sets and encodings in 70s/80s were modifications or extensions of ASCII
• Many of them used 8-bit with a subset of the 94 used ASCII characters
• Most common encodings nowadays use single byte per character (SBCS)
• They are all limited to 256 characters• Due to that, none of them can even cover the letters for the Western European languages

3/31/2004 9
What is Unicode exactly?• Unicode = universally encoded character set to
store information from any language• Unicode defines
• properties for each character• standardizes script behavior• provides a standard algorithm for bi directional text• defines cross-mappings for other standards
• Unicode defines a unique code value for every character, regardless of platform, program or programming language used

3/31/2004 10
What is Unicode exactly?•The Unicode standard primarily encodes scripts rather than languages
•Scripts comprise several languages that historically share the same set of symbols
• In many cases a script may serve to write dozens of languages (e.g. the Latin script)
• In other cases one script complies to one language (e.g. Hangul)

3/31/2004 11
Unicode Encodings•UTF = Unicode Transformation Format•UCS = Universal Character Set•CESU = Compatibility Encoding Scheme
•Conversion between different encodings is a simple, bit-wise operation (defined in standard)
•No performance excessive conversion table necessary!

3/31/2004 12
Unicode Encodings•UTF-8: Unicode Transformation based on 8-bit representation
•CESU-8: Compatibility Encoding Scheme of UTF-16 on an 8-bit base
•UTF-16: Unicode Transformation based on 16-bit representation

3/31/2004 13
Unicode Encodings•UCS-2: Universal Character Set 2 byte variation (16-bit)
•UTF-32: Unicode Transformation based on 32-bit representation
•UCS-4: Universal Character Set 4 byte variation (32 bit)

3/31/2004 14
Unicode Encodings•Not all Unicode characters are 2 bytes longí no doubling of hw requirements in the first place
•Unicode encoding determines the length of a character
•Character in one Unicode encoding can be longer than 1 byte; therefore Unicode characters can be longer than characters defined in a standard code page
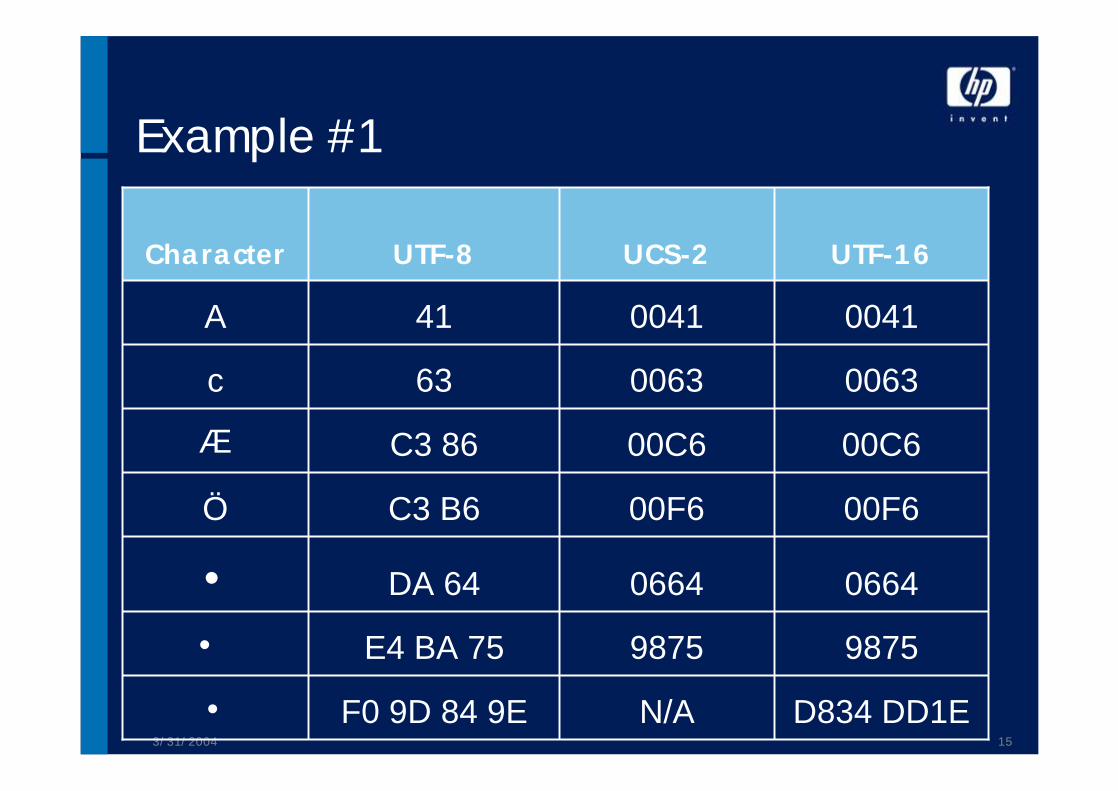
3/31/2004 15
Example #1
D834 DD1EN/AF0 9D 84 9E•
98759875E4 BA 75•
06640664DA 64•00F600F6C3 B6Ö
00C600C6C3 86Æ
0063006363c
0041004141A
UTF-16UCS-2UTF-8Character
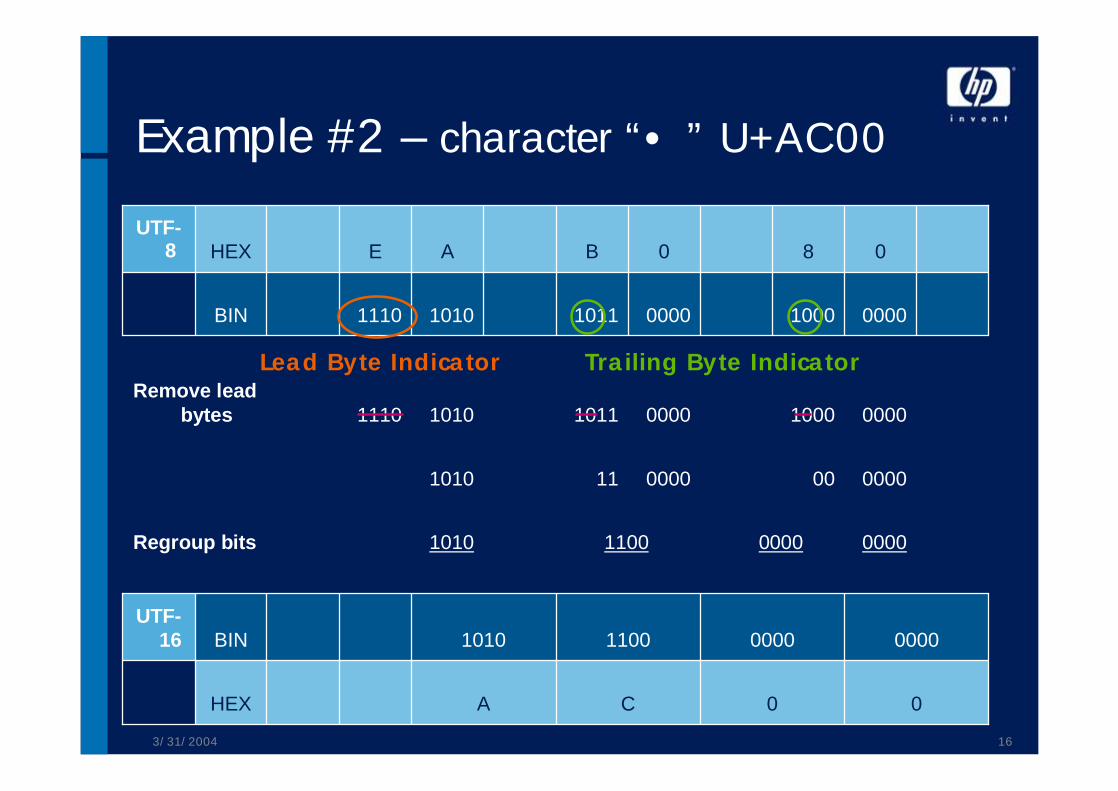
3/31/2004 16
Example #2 – character “•” U+AC00
00CAHEX
0000000011001010BINUTF-
16
00001100 00001010Regroup bits
0000000000111010
000010000000101110101110Remove lead
bytes
000010000000101110101110BIN
080BAEHEXUTF-
8
Lead Byte Indicator Trailing Byte Indicator

3/31/2004 17
Unicode & SAP in General

3/31/2004 18
2. Unicode & SAP in General• Code Pages• SAP & Code Pages• Language Combinations before Unicode• Recommendations from SAP (w/o Unicode)• When/why do customers need Unicode?
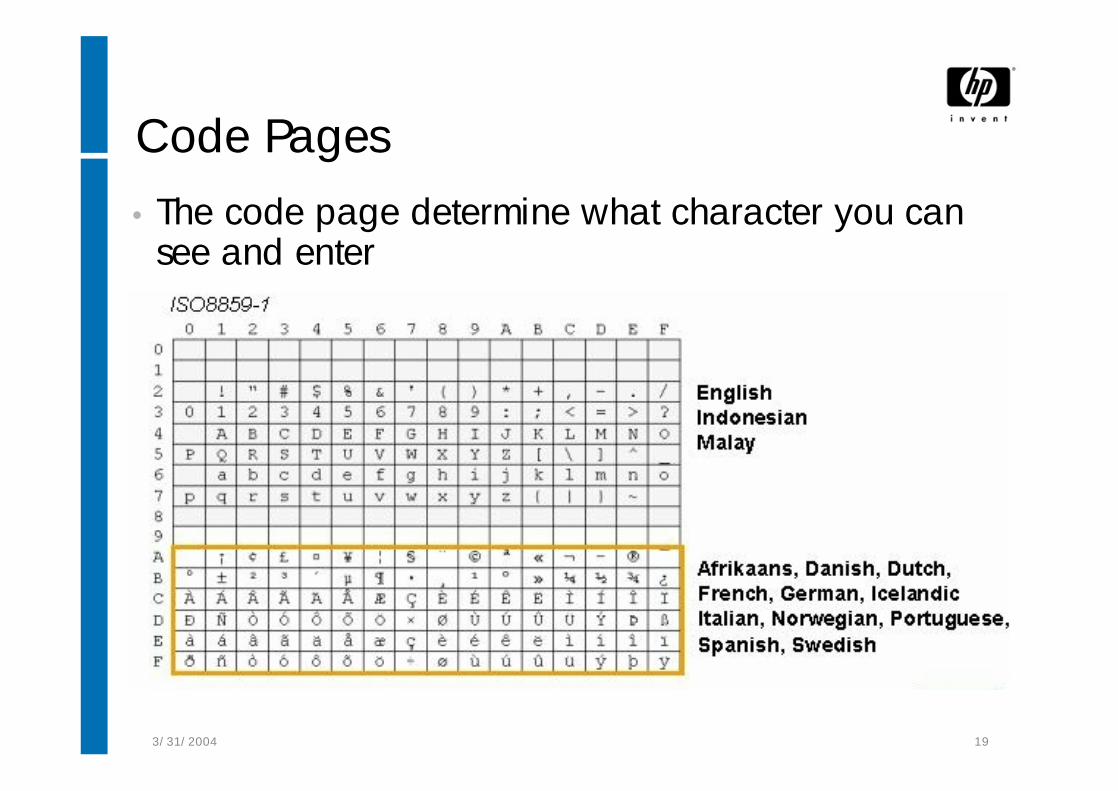
3/31/2004 19
Code Pages• The code page determine what character you can
see and enter
Characters on Disk/Memory

3/31/2004 20
Code Pages• different code pages map different characters to
the same byte sequence
Characters on Disk/MemorySingle Byte Double Byte
3/31/2004 21
SAP & Code Pages

3/31/2004 22
Language Combinations before Unicode• Single Standard Code Pages
• supports specific sets of languages• the number and combination of languages that are supported
cannot be altered
• Standard code pages and R/3 languages (w/o EBCDIC)
Double-Byte Code Pages

3/31/2004 23
Language Combinations before Unicode• It is also possible to specify a customer-specific language; this language must use one of the code pages that SAP supports; see Note 0112065

3/31/2004 24
Language Combinations before Unicode• Blended Code Pages (≥ Rel. 3.1D)
•SAP proprietary code pages that contain characters from one or more standard code pages
• increases the combinations of languages that can be used
• functionally, a Blended Code Page system uses a single code page
•a Blended Code Page is a single code page system
•users can see and enter all characters contained in the code page, regardless of their log-in language

3/31/2004 25
Language Combinations before Unicode
SAP Code Page Supported Languages

3/31/2004 26
Language Combinations before Unicode• the availability of SAP blended code pages is
platform dependent, because SAP blended locales need to be created for each platform
• Blended Locale Status (x = available −− = not available)

3/31/2004 27
Language Combinations before Unicode• MDMP (≥ Rel. 3.1I)
Multi-Display / Multi-Processing
• allows dynamic code page switching on the application server• therefore permits any combination of standard code pages on
one system• the log-on language determines the code page that is active for
each user• an MDMP system is recommended if:
1. one or more additional code pages are required to add languages to your existing installation
2. a blended code page cannot support the combination of languages you need for a new installation. For example, an MDMP system with the code pages 1100 and 8000, allows German and Japanese users to log onto the same R/3 system in their respective languages
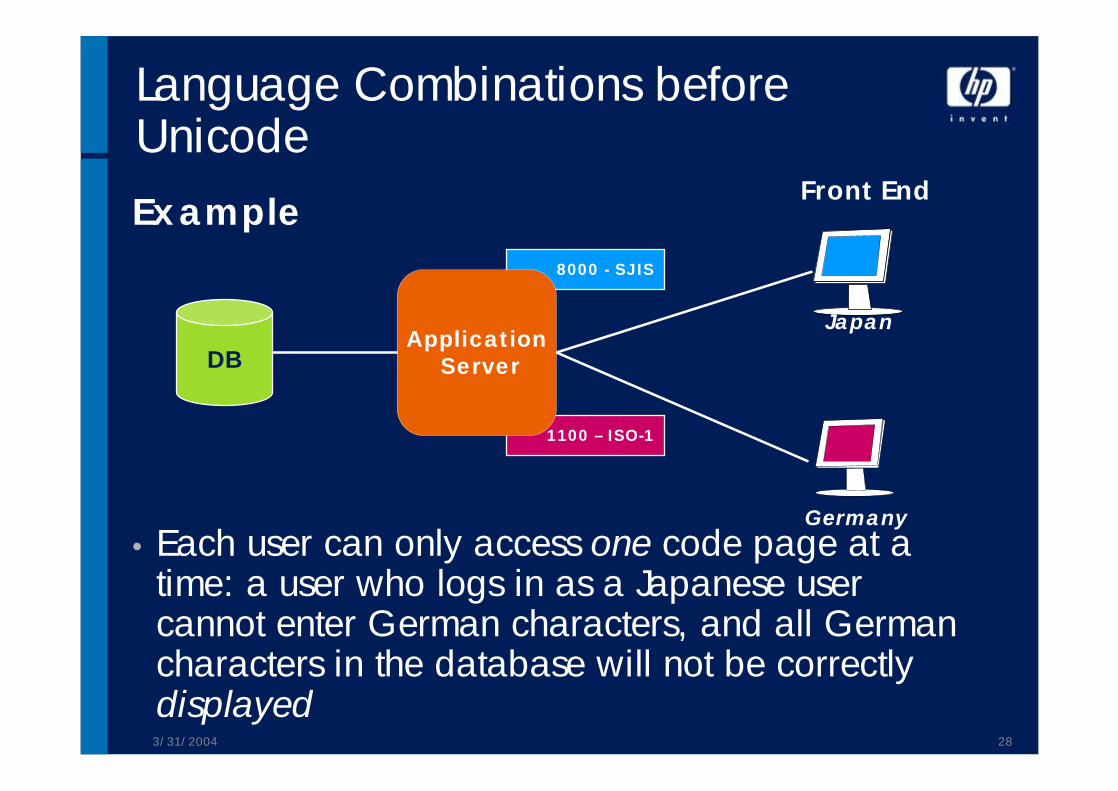
3/31/2004 28
Example
• Each user can only access one code page at a time: a user who logs in as a Japanese user cannot enter German characters, and all German characters in the database will not be correctly displayed
1100 – ISO-1
8000 - SJIS
Language Combinations before Unicode
DBApplication
Server
Front End
Japan
Germany

3/31/2004 29
Language Combinations before UnicodeExample
JapaneseUser
GermanUser

3/31/2004 30
Language Combinations before UnicodePlease Note:
• It is possible for a user to log on with German and then manipulate the character set and font settings so that he can enter what appear to be Japanese characters; these characters will not be correctly stored in the database and this data will be corrupt
• If a user wants to enter f.i. Japanese, he/she must log on in Japanese

3/31/2004 31
Language Combinations before UnicodePlease Note:
• To insure that no data corruption occurs, the following restrictions must be followed:
•Global data must contain only 7-bit ASCII characters, which are in all code pages
•Users may use only the characters of their log-in language or 7-bit ASCII
•Batch processes must be assigned with the correct user ID and language
•EBCDIC code pages are not supported

3/31/2004 32
Recommendations from SAP (w/o Unicode)
• In general, using a single standard code page for new installations and upgrades is the optimal decision
• If additional languages or language combinations are needed, SAP recommends Unambiguous Blended Code Pages for new installations and MDMP for existing installations
• Unambiguous Blended Code Pages only support certain language combinations and therefore an MDMP setup may be the only possibility for new installations as well

3/31/2004 33
Unicode-compliant SAP products
• All Unicode installations are currently planned only with written permission of SAP carried out as customer projects together with SAP, except of new installations of R/3 Enterprise Extension Set 2.0

3/31/2004 34
When/why do customers need Unciode?
• Global businesses that require IT systems to support multilingual data without any restrictionsí f.i. customers with one WW central SAP system
• Web interfaces open the door to a global customer base, and IT systems must consequently be able to support multiple local languages simultaneously

3/31/2004 35
When/why do customers need Unciode?
• With J2EE integration, mySAP components fully support web standards, and with Unicode, it now can take full advantage of XML and Java
• Only Unicode makes it possible to seamlessly integrate inhomogeneous SAP and non-SAP system landscapesí NetWeaver

3/31/2004 36
Technology in Depth

3/31/2004 37
3. Technology in Depth• Little vs. Big Endian•Unicode & Databases•SAP Unicode-based Code Pages•How to Unicode-enable a program•Unicode-enabled ABAP•Migrating to Unicode enabled ABAP•Unicode Conversion, IMIG Lab Test

3/31/2004 38
Little vs. Big Endian• UCS and Unicode are first of all just code tables that assign integer numbers to characters
• There exist several alternatives for how a sequence of such characters or their respective integer values can be represented as a sequence of bytes
• The two most obvious encodings store Unicode text as sequences of either 2 or 4 bytes sequences

3/31/2004 39
Little vs. Big Endian• Unless otherwise specified, the most significant byte comes first in these (Big Endianconvention)
• An ASCII or Latin-1 file can be transformed into a UCS-2 file by simply inserting a 0x00 byte in front of every ASCII byte
• If we want to have a UCS-4 file, we have to insert three 0x00 bytes instead before every ASCII byte
3/31/2004 40
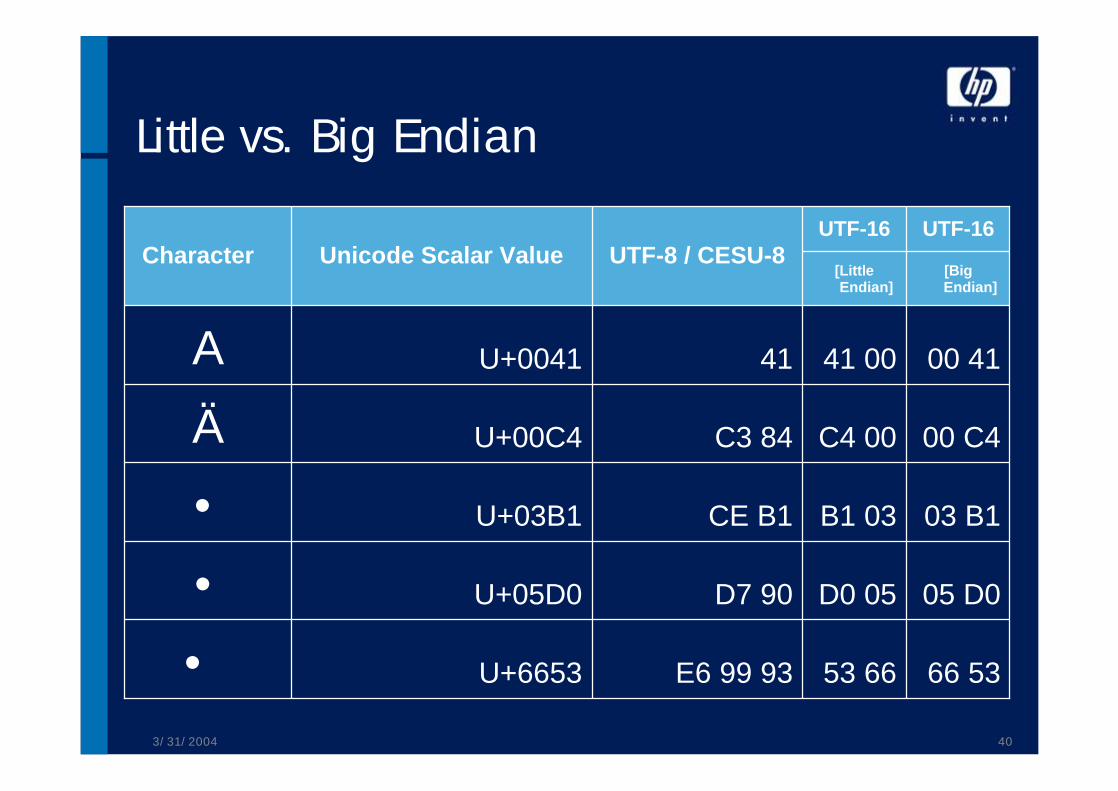
Little vs. Big Endian
66 5353 66E6 99 93U+6653•05 D0D0 05D7 90U+05D0•03 B1B1 03CE B1U+03B1•00 C4C4 00C3 84U+00C4Ä00 4141 0041U+0041A
[Big Endian]
[Little Endian]
UTF-16UTF-16UTF-8 / CESU-8Unicode Scalar ValueCharacter

3/31/2004 41
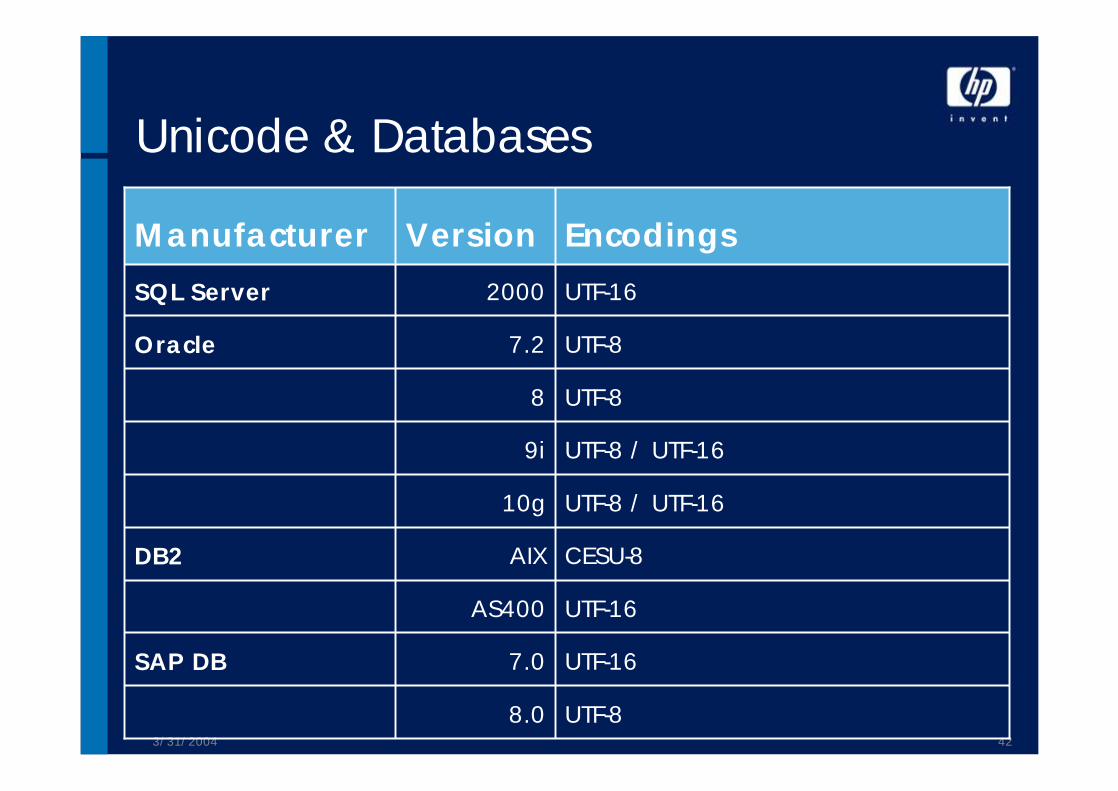
Unicode & Databases
P----PPPPSAP DB
P?PPPPPDB2
P----PPPPOracle
------------PSQL Server
LinuxOS/390OS/400AIXSolarisHP-UXWin2K
P Available ? Currently not available -- Unsupported in general
Supported Databases by SAP (WAS 6.20)
3/31/2004 42
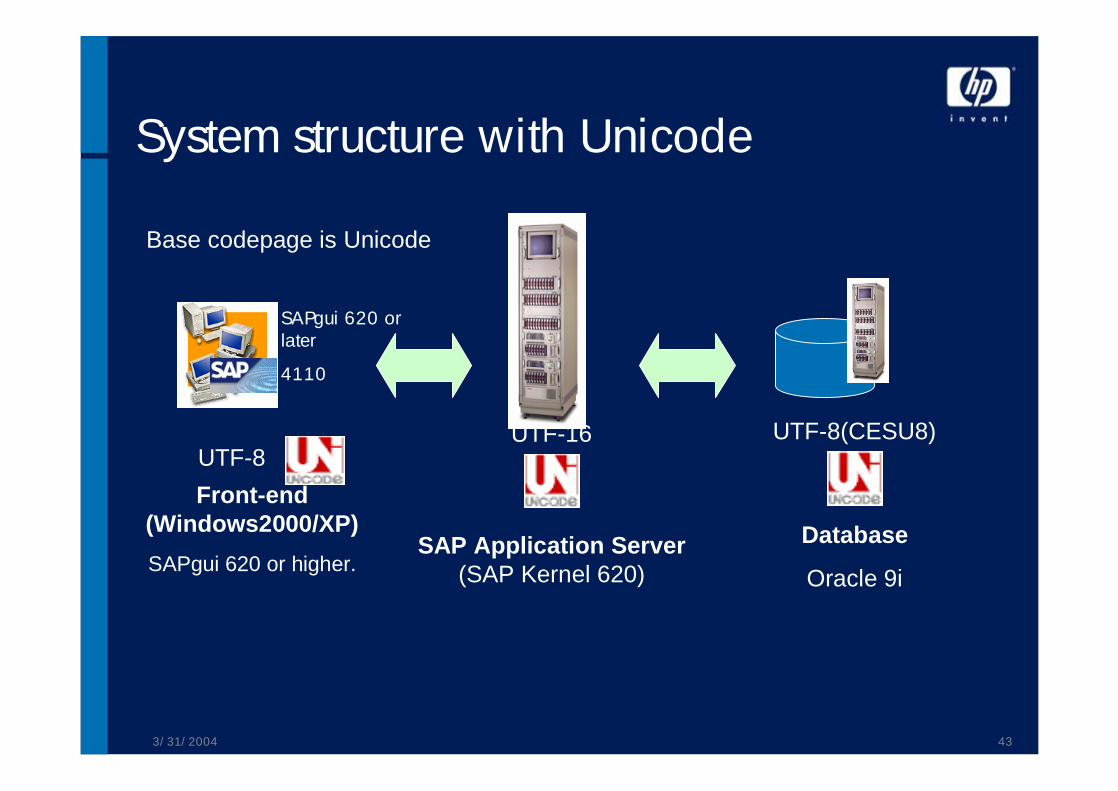
Unicode & Databases
UTF-88.0
UTF-167.0SAP DB
UTF-16AS400
CESU-8AIXDB2
UTF-8 / UTF-1610g
UTF-8 / UTF-169i
UTF-88
UTF-87.2Oracle
UTF-162000SQL Server
EncodingsVersionManufacturer
3/31/2004 43
Base codepage is Unicode
System structure with Unicode
Front-end (Windows2000/XP)SAPgui 620 or higher.
UTF-8(CESU8)
Database
Oracle 9i
SAPgui 620 or later
4110
UTF-8UTF-16
SAP Application Server(SAP Kernel 620)

3/31/2004 44
System structure with Unicode
UTF-16
SAP Application Server(SAP Kernel 620)
SAP R/3 Application Server
SAP Unicode Kernel 620 This is special kernel for Unicode R/3.
not a regular release. (Non-Unicode R/3 system)
All data handled as UTF-16 format.
ABAP programs have to be Unicode “Enabled”
Processing UTF-16 requires more CPU power and Memory because of the size and the conversion.
CPU and Memory requires +30%
SAP recommends to use 64bit processing

3/31/2004 45
System structure with Unicode
UTF-8(CESU8)
Database
Oracle 9i
Database Server – Oracle 9i in Unicode.Setup Oracle as UTF-8(CESU8)
Now, Question is.. SAP says “DB grows +35%-60%”
..Because UTF-8 is variable length set.ASCII (Alpha-Numeric) is stored as single byte
Latin character – European Accent sign is stored as double byte.
Double byte text stored as triple byte.

3/31/2004 46
Double byte? Need more storage? How about Network?
UTF-8(CESU8)
Database
Oracle 9i
Database will grow like that dramatically?
The answer is probably No...Because the majority of our data will be ASCII characters and
also linguistic factor will explain why.
e.g. English word uses more letters than Asian languages.
“Thunder” 7 bytes
“Yamamoto” 8 bytes
3 bytes
6 bytes

3/31/2004 47
System structure with codepage
SAPgui 620 or later
4110
Front-end (SAPgui) Unicode enabled SAP system requires SAPgui 620. Although 620 has some restrictions.
-Enables Unicode data handling on Client PC level.
- Users have to be aware of what kind of language data to use.
Codepage 4110 (Unicode)
Non-Unicode codepage setting (Latin-1, S-JIS etc…) will not work.
UTF-8
Front-end (Windows2000/XP)SAPgui 620 or higher.

3/31/2004 48
What is difference in Unicode R/3
•For User •For Developer•For System administration - Basis

3/31/2004 49
What is difference in Unicode R/3•For User
• SAPgui setting has changed. In order to handle multiple language data correctly.
• Unicode enabled SAP system requires SAPgui 620 or higher.
• Enables Unicode data handling on Client PC level.
• Users have to be aware of what kind of language data to use and choose.
• Use codepage 4110 • Non-Unicode codepage setting
(Latin-1, S-JIS etc…) is no longer work with Unicode R/3.

3/31/2004 50
What is difference in Unicode R/3•For Developer
•All developers have to be aware of “Unicode Enabling ABAP/4”.
•1 Character <> 1 Byte
•Many of ABAP/4 statements and data type are changed.
3/31/2004 51
What is difference in Unicode R/3
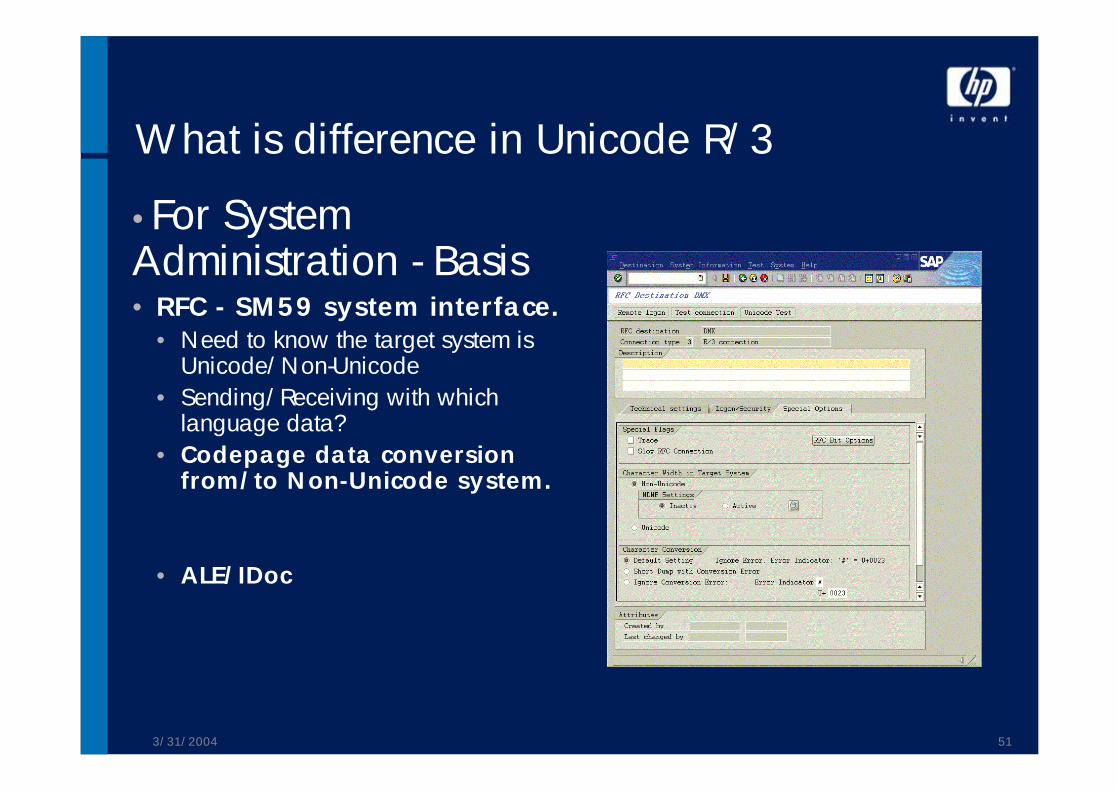
•For System Administration - Basis• RFC - SM59 system interface.
• Need to know the target system is Unicode/Non-Unicode
• Sending/Receiving with which language data?
• Codepage data conversion from/to Non-Unicode system.
• ALE/IDoc

3/31/2004 52
How to Unicode-enable a program• Separate Unicode and Non-Unicode version of
R/3ABAP
source Non-Unicode
R/3
Unicode R/3
• 1 character = 1 byte(types C, N, D, T, STRING)
• Non-Unicode kernel
• Non-Unicode database
• 1 character = 2 bytes í UTF-16
(types C, N, D, T, STRING)
• Unicode kernel
• Unicode database
• No explicit Unicode data type in ABAP• Single ABAP source for Unicode and non-Unicode systems

3/31/2004 53
How to Unicode-enable a program•Major part of ABAP coding is ready for Unicode without any changes
•Minor part of ABAP coding has to be adapted to comply with Unicode restrictions (f.i. syntactical restrictions)

3/31/2004 54
How to Unicode-enable a program• Program attribute
„Unicode checks active“

3/31/2004 55
Unicode Enabled ABAPDesign Goals• Platform independenceØIdentical behavior on Unicode and non-Unicode systems
• Highest level of compatibility to the pre-Unicode worldØMinimize costs for Unicode enabling of ABAP Programs
Main Features• Clear distinction between character and byte
processing1 Character <> 1 Byte

3/31/2004 56
Migrating to Unicode enabled ABAPStep 1
• In non-Unicode system
• Adapt all ABAP programs to Unicode syntax and runtime restrictions
• Set attribute "Unicode enabled" for all programs

3/31/2004 57
Migrating to Unicode enabled ABAPStep 2• Set up a Unicode system
• Unicode kernel + Unicode database• Only ABAP programs with the Unicode attribute are executable
• Do runtime tests in Unicode system
• Check for runtime errors
• Look for semantic errors
• Check ABAP list layout with former double byte characters

3/31/2004 58
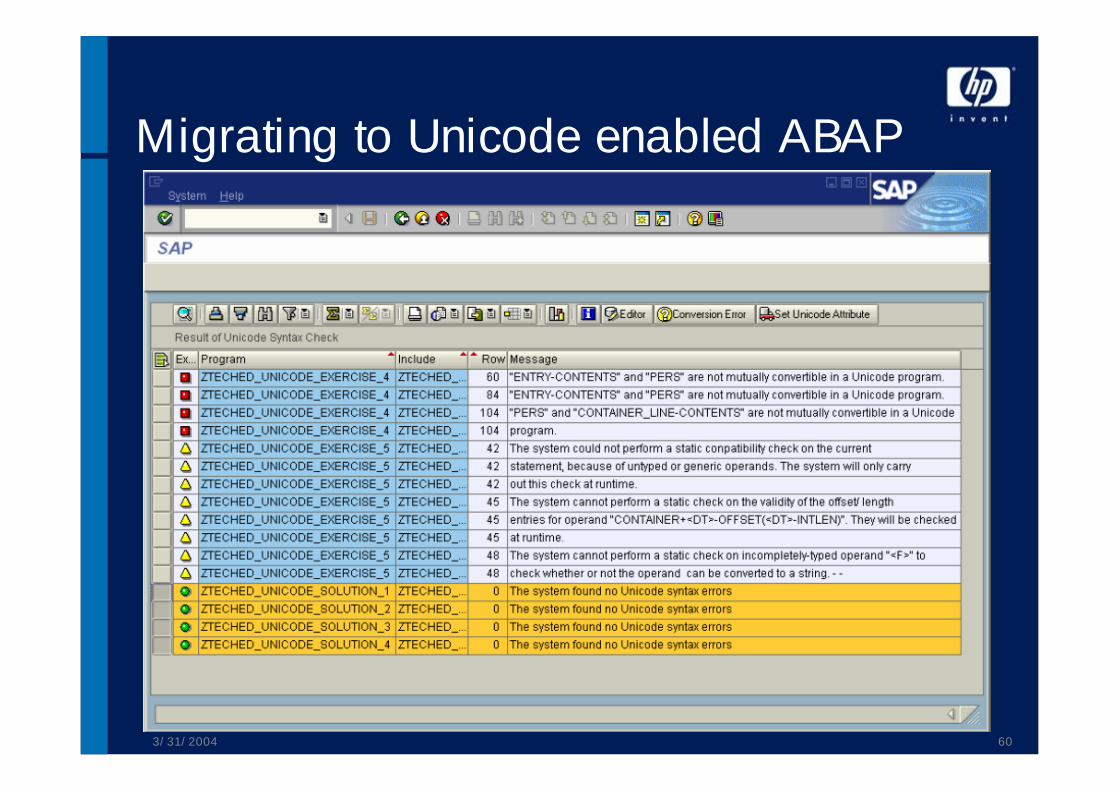
Migrating to Unicode enabled ABAPUse UCCHECK to analyze your applications:• Remove errors• Inspect statically not analyzable places (optional)
• Untyped field symbols• Offset with variable length• Generic access to database tables
• Set Unicode program attribute using UCCHECK or SE38 / SE24 / ...
• Do additional checks with SLIN (e.g. matching of actual and formal parameters in function modules)

3/31/2004 59
Migrating to Unicode enabled ABAP
3/31/2004 60
Migrating to Unicode enabled ABAP

Upgrade to Unicode

3/31/2004 62
Upgrade to Unicode• With Unicode, there are no limitations on users,
and all languages in the ISO639 standard can be used
• Unicode is technically supported as of Basis Release 6.20, see Note 0379940 for more information
• A single code page system (standard or Unambiguous Blended Code Page) can be upgraded to Unicode using the normal upgrade method

3/31/2004 63
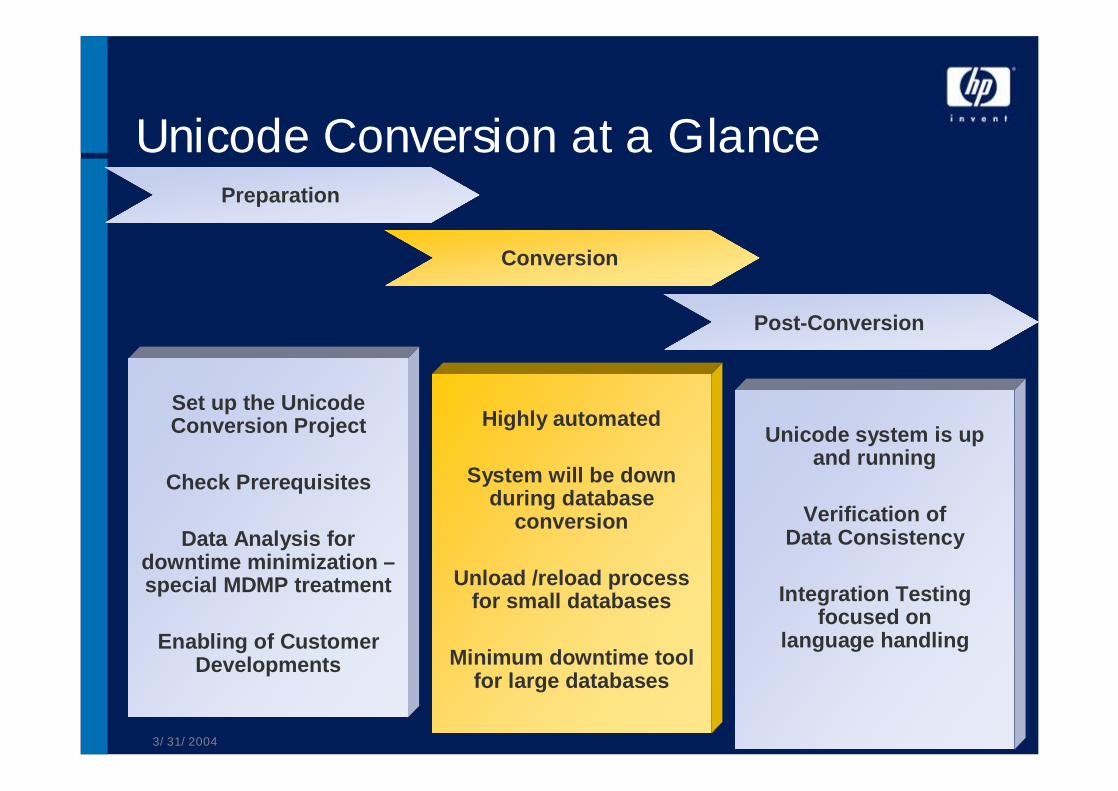
Unicode Conversion RoadmapPreparation • During preparation, topics such as
• additional hardware requirements, • downtime issues, • Unicode-enabling of customer developments, • and the special treatment of MDMP systems
have to be taken into consideration

3/31/2004 64
Unicode Conversion RoadmapConversion • The Unicode conversion process is based on a
system copy, and during this process, the database conversion and system shutdown/restart are as automated as possible
• For small to mid-size databases (< 1 TB), this is based on an SAP Unload/Reload of the complete database; minimum downtime tools will be used for larger databases.

3/31/2004 65
Unicode Conversion RoadmapPost-Conversion
• Once the Unicode system is up and running, you need to • verify data consistency on a scenario basis, • as well as carry out general integration testing
• For systems that support multiple languages, special emphasis needs to be placed on cross-language handling during the test phase.
• Correction tools are provided by SAP, which can be used in the case that conversion did not run properly.

3/31/2004 66
Unicode Conversion RoadmapPost-Conversion
• Additional Tool: SAP Data Management - reducing the database size and growth
• To keep your database costs in check, the SAP Data Management service frees up valuable database resources by showing you how to reduce the size and growth of your database by typically 25 % (see details).
3/31/2004 67
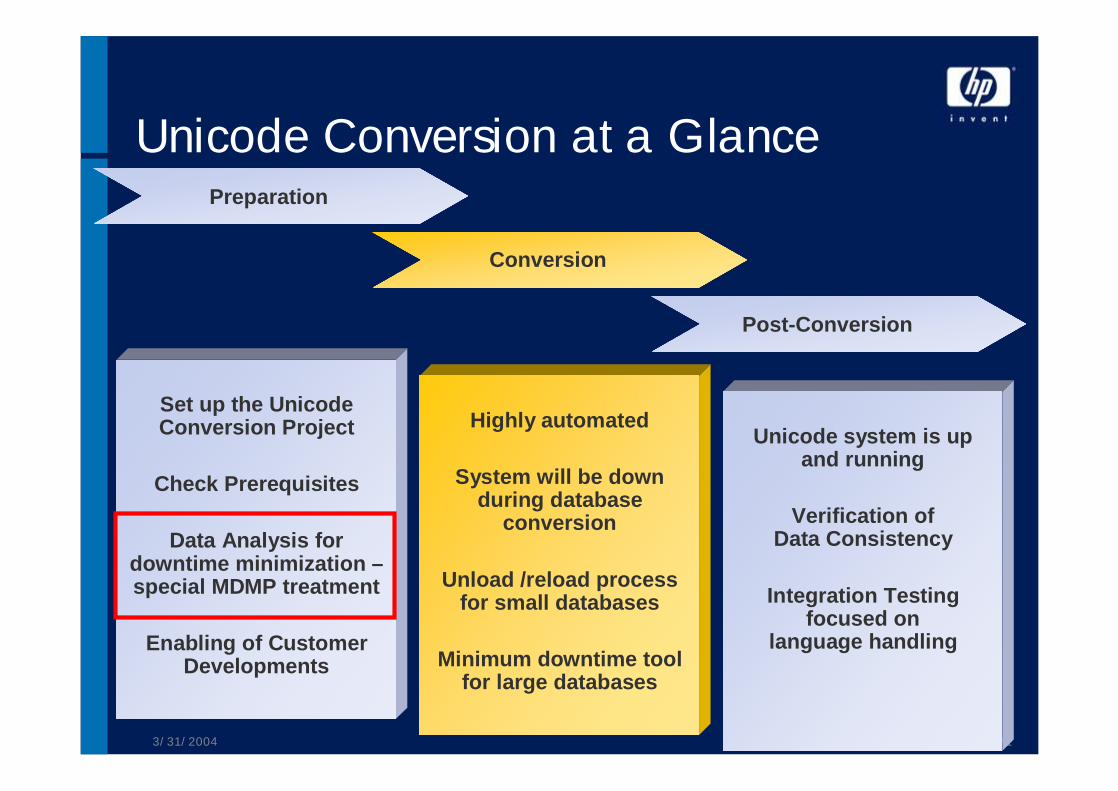
Unicode Conversion at a GlancePreparation
Conversion
Post-Conversion
Set up the Unicode Conversion Project
Check Prerequisites
Data Analysis for downtime minimization –special MDMP treatment
Enabling of Customer Developments
Highly automated
System will be down during database
conversion
Unload /reload process for small databases
Minimum downtime tool for large databases
Unicode system is up and running
Verification of Data Consistency
Integration Testing focused on
language handling

3/31/2004 68
Upgrade Paths to Unicode (R/3 Enterprise)
R/3 4.6c
Source system Target system
R/3 Enterprise
non-Unicode
R/3 Enterprise
Unicode
R/3 4.5b
R/3 3.1i
l First upgrade, then conversion to Unicode
l R/3 Enterprise Ramp-Up started 2002-07
l Unicode availability follows a phase ofrestricted shipment with pilot customers
R/3 4.6b
R/3 4.0b Conversion
Directupgrade
3/31/2004 69
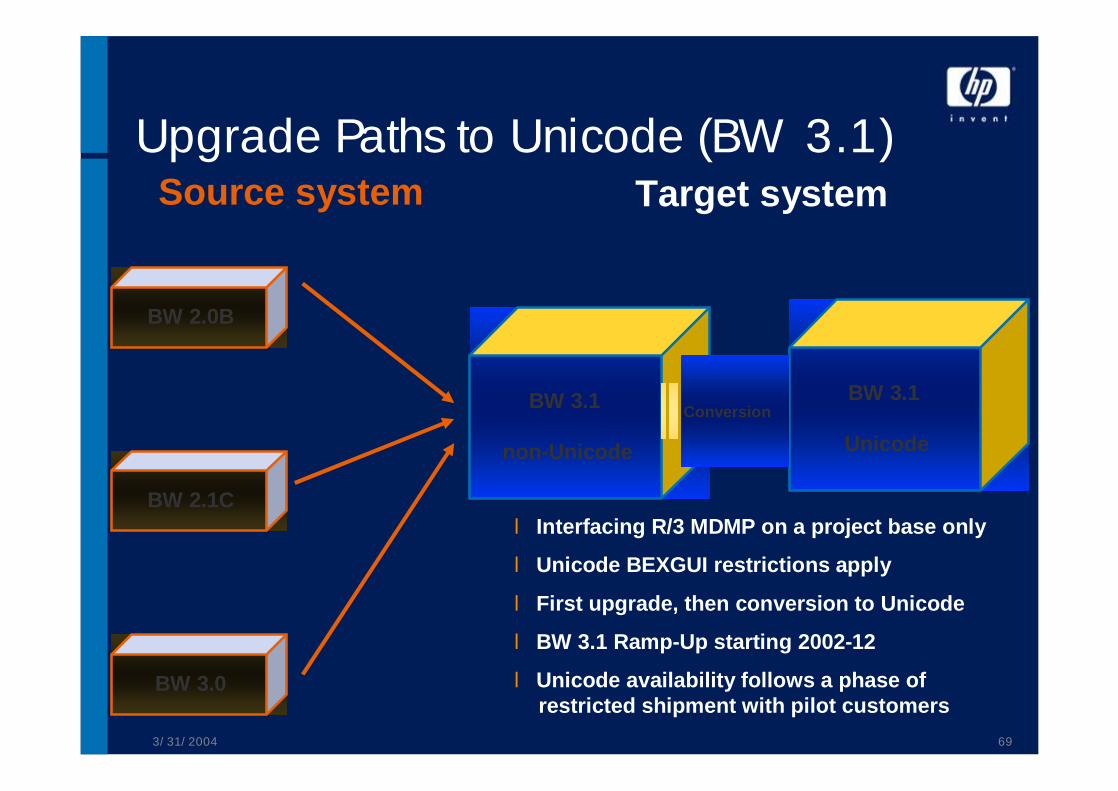
Upgrade Paths to Unicode (BW 3.1)
BW 3.0
Source system Target system
BW 3.1
non-Unicode
BW 3.1
Unicode
BW 2.1C
BW 2.0B
l Interfacing R/3 MDMP on a project base only
l Unicode BEXGUI restrictions apply
l First upgrade, then conversion to Unicode
l BW 3.1 Ramp-Up starting 2002-12
l Unicode availability follows a phase ofrestricted shipment with pilot customers
Conversion
3/31/2004 70
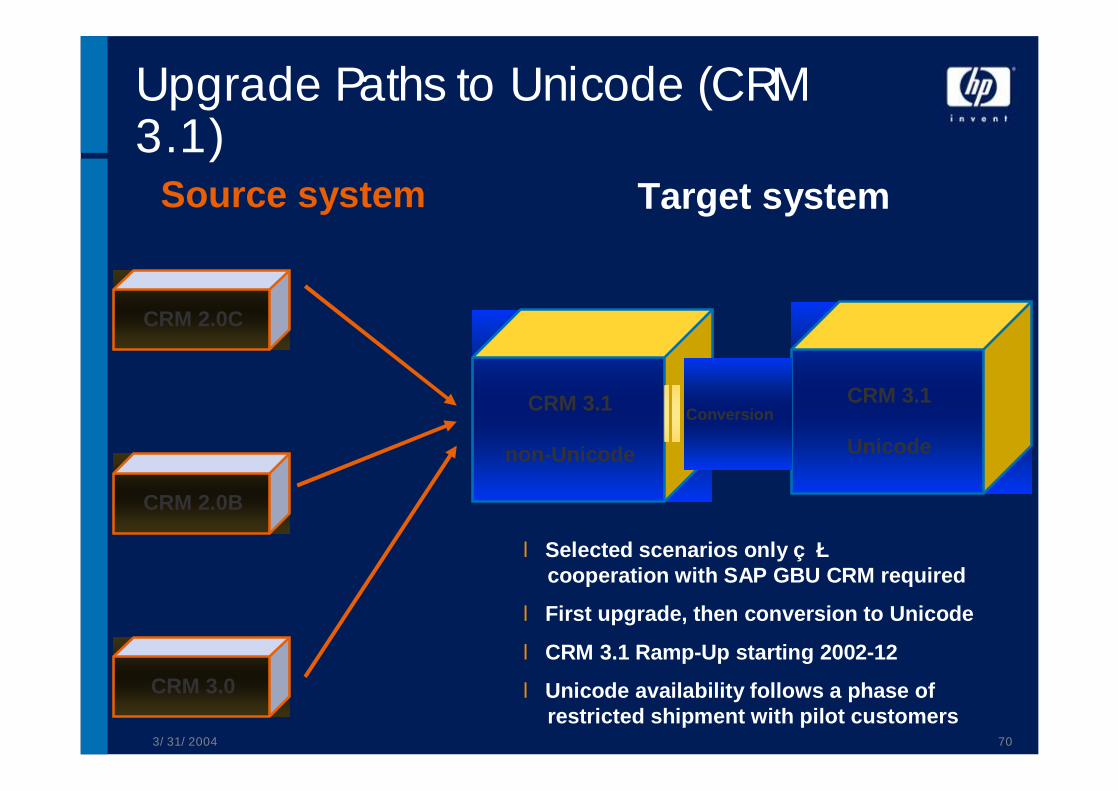
Upgrade Paths to Unicode (CRM 3.1)
CRM 3.0
Source system Target system
CRM 3.1
non-Unicode
CRM 3.1
Unicode
l Selected scenarios onlyçècooperation with SAP GBU CRM required
l First upgrade, then conversion to Unicode
l CRM 3.1 Ramp-Up starting 2002-12
l Unicode availability follows a phase ofrestricted shipment with pilot customers
CRM 2.0B
CRM 2.0C
Conversion
3/31/2004 71
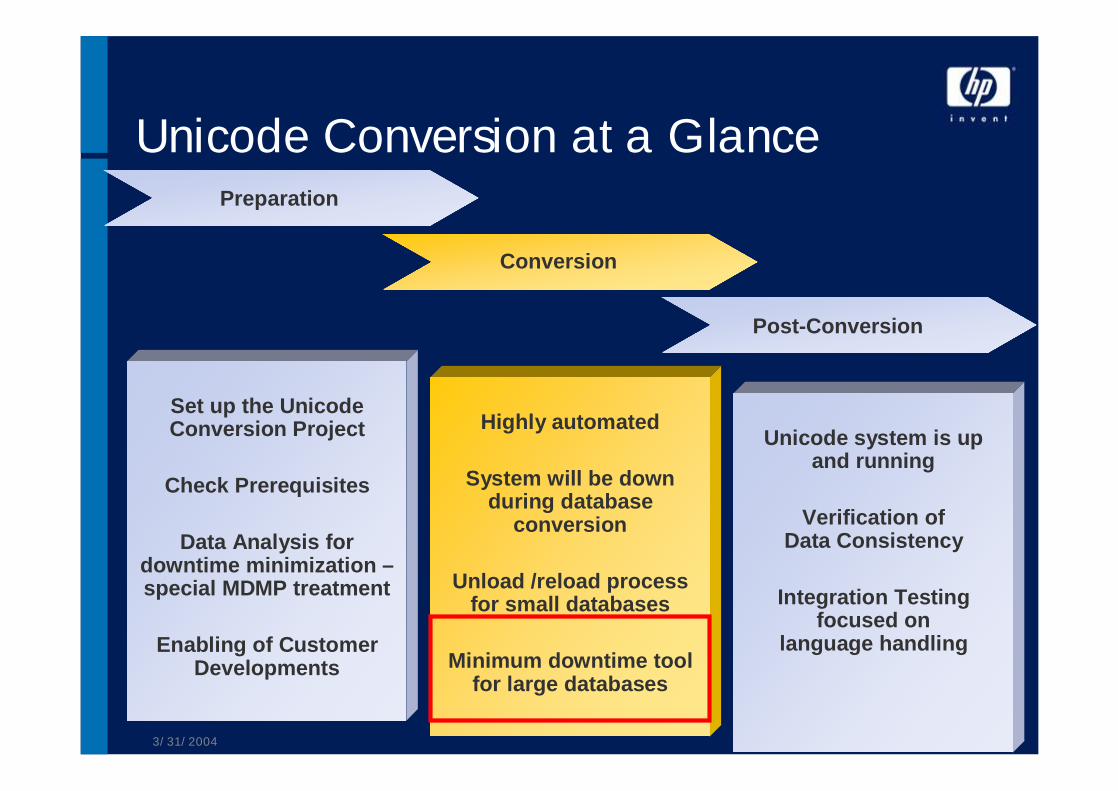
Unicode Conversion at a GlancePreparation
Conversion
Post-Conversion
Set up the Unicode Conversion Project
Check Prerequisites
Data Analysis for downtime minimization –special MDMP treatment
Enabling of Customer Developments
Highly automated
System will be down during database
conversion
Unload /reload process for small databases
Minimum downtime tool for large databases
Unicode system is up and running
Verification of Data Consistency
Integration Testing focused on
language handling

3/31/2004 72
Prerequisites, special MDMP treatment
• OSS Note 548016Conversion from Unicode to non-Unicode is not possible
The Unicode Conversion of MDMP AND also Ambiguous Code page systems ( Code Page numbers 6100, 6200 and 6500 ) is only supported on project basis with SAP involvement
• OSS Note 543715The Unicode Conversion of a BW 3.1 system requires additional steps regarding the system copy
• OSS Note 573044If you are using HR functionality within R/3 Enterprise , also additional steps are mandatory

3/31/2004 73
6.30 Unicode & MCOD
ABAP Stack (non Unicode/Unicode)
ABAP Stack (non Unicode/Unicode)
Java Stack (Unicode)
Java Stack (Unicode)
System QA1
System TC2
SAPQA1
SAPQA1DB
SAPTC2
SAPTC2DB
• With SAP WebAS 6.30 a database abstraction layer for the Java stack was introduced – OpenSQL for Java
• Tables of the Java stack are stored in the same database instance like the tables of the ABAP stack in two different schema (except Informix)
• The concept of MCOD installations is fully supported by the combined stack of ABAP and Java
3/31/2004 74
Unicode Conversion at a GlancePreparation
Conversion
Post-Conversion
Set up the Unicode Conversion Project
Check Prerequisites
Data Analysis for downtime minimization –special MDMP treatment
Enabling of Customer Developments
Highly automated
System will be down during database
conversion
Unload /reload process for small databases
Minimum downtime tool for large databases
Unicode system is up and running
Verification of Data Consistency
Integration Testing focused on
language handling

3/31/2004 75
Experience on a 280 GB database (220 GB used)
Runtime export and import: 36 hours
expected downtime (with backup, control Reports, user test): 56 hours
database grow: 40 GBPSAPBTABD 18 GB (on 115 GB)PSAPES620D 13 GB (on 4 GB)


3/31/2004 77
BACKUP SLIDES
Unicode Encodings

UTF-8• UTF-8 is the 8-bit encoding of Unicode• It’s a variable-width encoding and also a strictsuperset of 7-bit ASCII
• “Strict superset” means that every character in 7-bit ASCII is available in UTF-8 with the same corresponding code point value
• 1 character = 1byte – 4 bytes in the encoding• Characters from European scripts: either 1or 2 bytes
• Asian scripts: 3 or 4 bytes

UTF-8• UTF-8 used for UNIX-platforms, HTML and most
Internet Browsers• Main benefits of UTF-8:
•compact storage requirements for European scripts
•in general European scripts will occupy less storage on disk and memory
•ease of migration –> since 7-bit ASCII data remains the same in UTF-8, data conversion effort between ASCII based character sets and UTF-8 is reduced significantly

UTF-8 / CESU-8 (8-bit encodings)•8-bit encodings are well-suited for data transfer since all 7-bit ASCII and 8-bit ISO characters retain the same code points
•Easier communication with legacy and non-Unicode systems
•Downside: variable character length

UCS-2• UCS-2 has a fixed width of 16 bit (2 bytes)• UCS-2 is the Unicode encoding for Java & Win NT 4.0• Main benefits of UCS-2:
•More compact storage requirements for Asian scripts (each character represented with 2 bytes only)
•String processing will be faster because all characters are of the same width
•Good compatibility with Java and Microsoft clients
• Downside:•UCS-2 can support Unicode characters defined up to
Unicode 3.0 only (max. 65.536)

UTF-16• UTF-16 is the 16-bit encoding of Unicode• Basically an extension of UCS-2• One Unicode character can be 2 or 4 bytes in the encoding
• Characters from European and most Asian scripts are represented in 2 bytes
• Supplementary characters are represented in 4 bytes
• UTF-16 is the main Unicode encoding from Windows 2K

UTF-16• Main benefits of UTF-16:
•More compact storage requirements for Asian scripts (2 bytes for commonly used characters)
•Ideal if European and Asian scripts are used together --> UTF-16 will occupy less storage on disk and memory than with UTF-8 (3 bytes for Asian part)
•Balance of efficient access to characters and economical use of storage
• Above mentioned points reason for use of UTF-16 in SAP Web Application Server

UCS-2 / UTF-16 (16-bit encodings)•16-bit encodings offer a compromise between the pros and cons of the 8-bit and the 32-bit encodings, respectively
•They do not need as much memory as 32-bit encodings, but offer quasi fixed character length
•UCS-2 has a fixed character length, but it cannot define more than 2^16 (65.636) characters

UTF-32•32-Bit encoding
•Popular when memory space is no concern
•Fixed width (4Byte)

UCS-4 / UTF-32 (32-bit encodings)•All 32-bit encodings have a fixed length
•This advantage is outweighed by the extensive memory & storage requirements

3/31/2004 87
SAP System-to-System Communication

3/31/2004 88
SAP System-to-System communication• SAP Web Application Server (≥ 6.20)
• Only one source code exists for Unicode-based and non-Unicode-based systems, í new developments can be smoothly exchanged
• The interfaces (e.g. RFC) have been extended, so that communication between other Unicode-based systems or non-Unicode-based systems is possible. Furthermore, SAP provides standard tools for the installation of (and conversion to) Unicode-based systems that can also be used for checking and Unicode-enabling of customer developments

3/31/2004 89
SAP System-to-System communication• solid lines:
receiver can receive all characters
• dotted lines:receiver cannot receive characters, which are not in its own code page. But as long as you restrict the character set, data can be sent from everywhere to everywhere.
Unicode R/3
WWW
http/RFC
http/RFC
SJIS
Latin-1
Non-Unicode
R/3SJIS
MDMP R/3
Latin-1 SJIS

3/31/2004 90
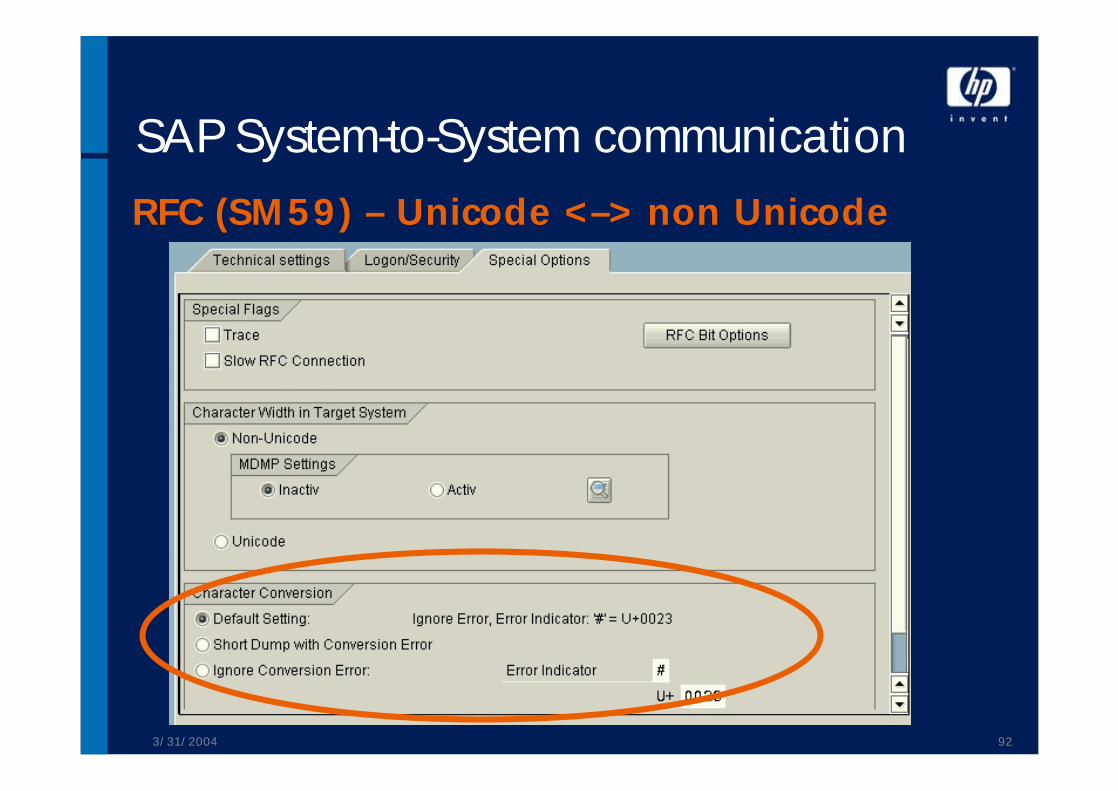
SAP System-to-System communicationRFC• Unicode <-> Unicode
• no problem
• non Unicode <-> non Unicode• old stuff, receiver converts code page if possible
• Unicode <-> non Unicode• the Unicode side converts from/ to the code page of the
non Unicode side• MDMP is converted with a languages key• System settings allow the configuration of error handling

3/31/2004 91
SAP System-to-System communicationRFC (SM59) – Unicode <–> non Unicode
3/31/2004 92
SAP System-to-System communicationRFC (SM59) – Unicode <–> non Unicode

3/31/2004 93
Sizing Information for Unicode-based SAP Systems

3/31/2004 94
Sizing Info - GeneralThe space requirements for encoding a text, compared to encodings currently in use (8 bit per character for European languages, more for Chinese/ Japanese/ Korean), is as follows í next Slide
This has an influence on disk storage space and network download speed (when no form of compression is used)

3/31/2004 95
Sizing Info - GeneralUTF-8
No change for US ASCII, just a few percent more for ISO-8859-1, 50% more for Chinese/Japanese/Korean, 100% more for Greek and Cyrillic
UCS-2 and UTF-16No change for Chinese/Japanese/Korean. 100% more for US ASCII and ISO-8859-1, Greek and Cyrillic
UCS-4100% more for Chinese/Japanese/Korean. 300% more for US ASCII and ISO-8859-1, Greek and Cyrillic

3/31/2004 96
Expected Hardware Requirements• Increase of CPU requirementsØDepending on existing solution:
ISO-LATIN1 (ASCII) ð Unicode: +30%Double-Byte/MDMP ð Unicode: + <5%
• Increase of memory requirementsØIncrease of memory requirements depending on
underlying DB (+ ~50%)ØApplication Server internally based on UTF-16; DB either
UTF-8, CESU-8 or UTF-16

3/31/2004 97
Expected Hardware Requirements• Database growth depending onØ DB Unicode encoding schema (e.g. CESU-8, UTF-16)Ø Languages in use
A
1100 8000 CESU-8 UTF-16
Ä
1100 8000 CESU-8 UTF-16
•
1100 8000 CESU-8 UTF-16
60-70%SQL Server, DB/2 (AS400), SAP DB (7.0)
UTF-16
35%Oracle, SAP DB (8.0)DB/2 (AIX)
UTF-8 CESU-8
Additional StorageReq‘s
ManufacturersEncoding
1 By
te
• Network load: (draft results) <7% for Latin-1, about 15% for Japanese, 25% for other Asian languages

3/31/2004 98
Expected Hardware Requirements
NON-Unicode
R/3 Release 4.0 4.5 4.6c 4.7 (6.20) non-Unicode
CPU 1 +20% +15% +5%
Memory 1 +20% DB: +20%; +5%App:+10%
Disk 1 +10% +10% +10%

3/31/2004 99
Expected Hardware Requirements
Unicode
R/3 Release 4.7 (6.20) non-Unicode 4.7 with Unicode
CPU 1 +30% to 35%
Memory 1 +50%
Disk 1 +~35% (UTF-8)+60-70% (UTF-16)

3/31/2004 100
IMIG lab project
Tru64 Transition program

3/31/2004 101
Unicode Conversion - IMIG • Problem Description
• R3Load cannot be used for Very Large Databases –(VLDB > 800 GB)Minimized Downtime tool is needed.
• Solution: Incremental Migration (IMIG):• The few tables that are very large are already converted
during uptime of the source system.• The remaining data can be copied during a greatly
reduced downtime, by means of a standard procedure.

3/31/2004 102
IMIG – Prerequisites• Database triggers
• All insert, update and delete activities executed on the IMIG tables during and after their initial copy are logged.
• RFC = Remote Function Call• SAP function for connecting SAP systems• Target system must exist• The activities logged by the triggers in the source system
are passed on to the corresponding tables in the target system by means of RFCs.
• SAP Basis System• Reduced SAP system that has basic functions (RFC)

3/31/2004 103
IMIG process (uptime)I n s t a l l a t i o n t e m p o r a r y t a r g e t s y s t e m
S A P W e b A S I n s t a l l a t i o n
I m p o r t I M I G p a c k a g e
I M I G T a b l eO t h e r T a b l e s
L o g T a b l e
I M I G T a b l ee m p t y
T r i g g e r
I M I G P a c k a g e
C r e a t i o n
I M I G T a b l e
L o g T a b l e
I M I G T a b l ee m p t y
L o g g i n g
E x p o r t / I m p o r t
I M I G T a b l e
L o g T a b l e
I M I G T a b l e
L o g g i n g
I m p o r t
O t h e r T a b l e s
O t h e r T a b l e s
I n i t i a l i z a t i o n
E x p o r t I M I G t a b l e s / i m p o r t i n t e m p o r a r y t a r g e t s y s t e m
U p d a t e o f I M I G t a b l e s
S A P W e b
A S T a b l e s
S A P W e b
A S T a b l e s
S A P W e b
A S T a b l e s
Update via RFC
S o u r c e S y s t e m T e m p o r a r y T a r g e tS y s t e m
P r e p a r a t i o n s
T r a n s a c t i o n I M I G
S A P i n s t
T r a n s a c t i o n I M I G

3/31/2004 104
Major steps of the IMIG procedure• Build up the target SAP basis system• Choose the IMG tables• Installation of the IMIG package • Initial copy of the IMG tables• Transfer of the recorded activities• Shutdown of the source system• Backup of the old system• Reduced DROP of the target basis system• Migration of the “rest”• Backup of the new system• Startup of the target SAP system

3/31/2004 105
Hardware environment IMIG tests
Source System:SAP R/3 4.6cOracle 8.1.7Tru64 UNIX 5.1bGS1608x EV67-730Mhz32 GB RAM
100 Mbit
Storage:2x HSG80600 GB
Target System:SAP R/3 4.6cOracle 9iV2.02HP-UX 11iV2RX56704x Itanium2-1Ghz32 GB RAM
Storage:1x VA74102100 GB
FC direct attached
F/W SCSI
3/31/2004 106
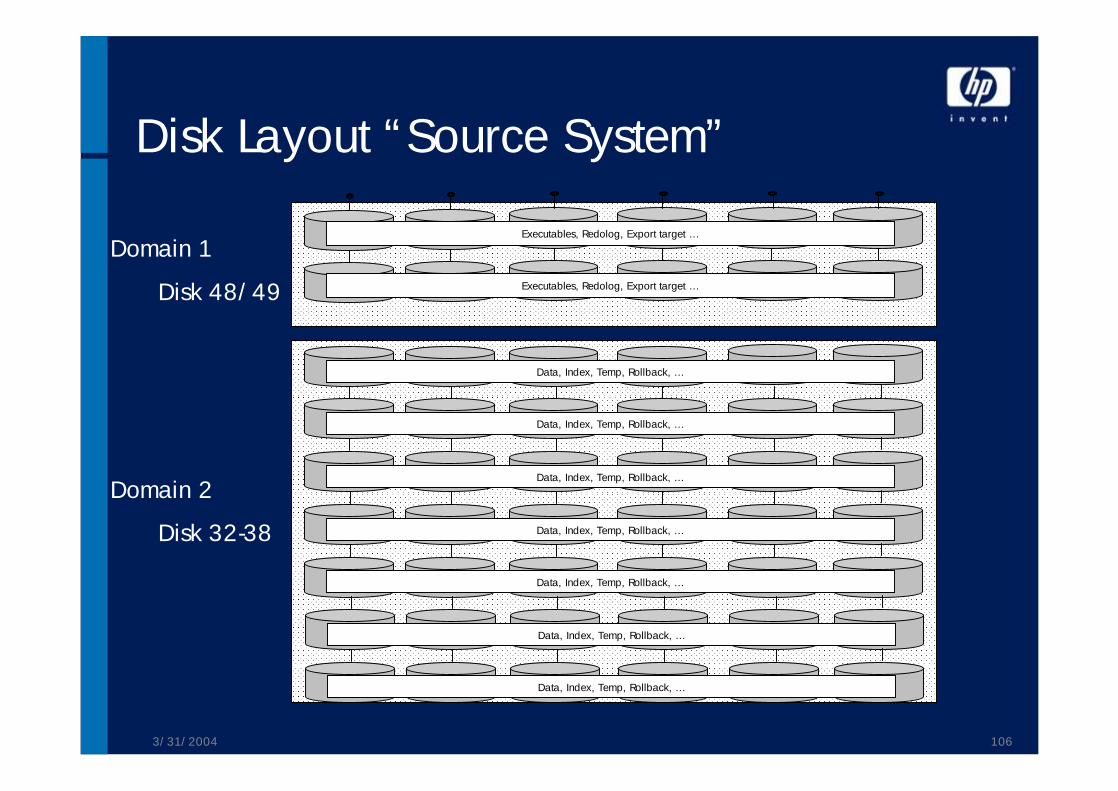
Disk Layout “Source System”
Domain 1
Disk 48/49
Domain 2
Disk 32-38
Executables, Redolog, Export target …
Executables, Redolog, Export target …
Data, Index, Temp, Rollback, …
Data, Index, Temp, Rollback, …
Data, Index, Temp, Rollback, …
Data, Index, Temp, Rollback, …
Data, Index, Temp, Rollback, …
Data, Index, Temp, Rollback, …
Data, Index, Temp, Rollback, …

3/31/2004 107
Overview db02 – database size
3/31/2004 108
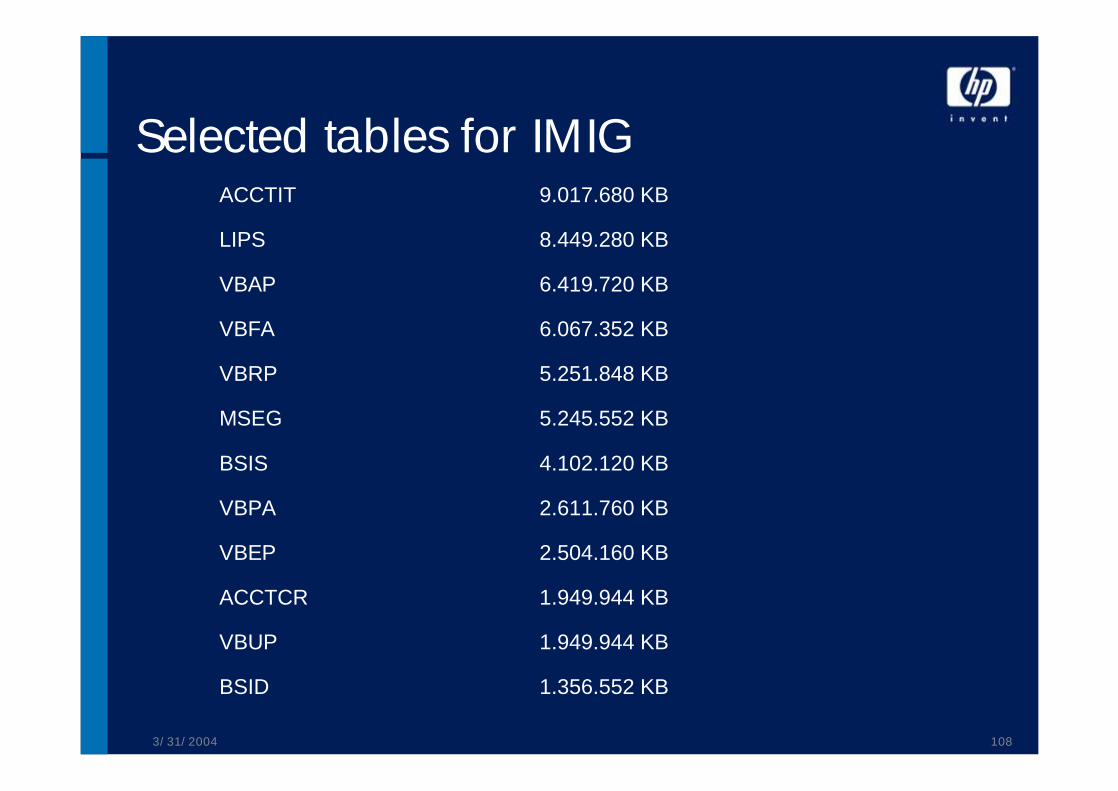
Selected tables for IMIG
1.356.552 KBBSID
1.949.944 KBVBUP
1.949.944 KBACCTCR
2.504.160 KBVBEP
2.611.760 KBVBPA
4.102.120 KBBSIS
5.245.552 KBMSEG
5.251.848 KBVBRP
6.067.352 KBVBFA
6.419.720 KBVBAP
8.449.280 KBLIPS
9.017.680 KBACCTIT

3/31/2004 109
Export step• Comparison runtime with and without parallel load• Load generation with 50 SD benchmark user, 70
loops, the basic load was roughly 15% CPU-utilization
• Largest table was the determining factor• Export step run with 12 processes• R3load process consumed 40-50% CPU-utilization
ORACLE snapshot too oldtuning of rollback segments,
undo TS

3/31/2004 110
Export stepComparison Export without parallel load to Export with parallel load
Owner Object Type KBytes Runtime in hours Runtime in hours Differencewithout load with load in minutes
SAPR3 ACCTIT TABLE 9.017.680 2:43:44 2:49:31 05:47,0SAPR3 LIPS TABLE 8.449.280 2:25:05 2:31:50 06:45,0SAPR3 VBAP TABLE 6.419.720 2:18:06 2:20:26 02:20,0SAPR3 VBFA TABLE 6.067.352 1:48:55 1:55:48 06:53,0SAPR3 VBRP TABLE 5.251.848 2:09:34 1:57:51 11:43,0SAPR3 MSEG TABLE 5.245.552 1:57:52 1:59:05 01:13,0SAPR3 BSIS TABLE 4.102.120 2:28:51 2:32:28 03:37,0SAPR3 VBPA TABLE 2.611.760 2:16:27 2:19:02 02:35,0SAPR3 VBEP TABLE 2.504.160 0:54:13 0:55:01 00:48,0SAPR3 ACCTCR TABLE 1.949.944 0:58:58 1:02:09 03:11,0SAPR3 VBUP TABLE 1.949.944 1:10:44 1:11:53 01:09,0SAPR3 BSID TABLE 1.356.552 1:24:52 1:22:50 02:02,0
Sum all tables in KBytes: 54.925.912 2:43:44 2:49:31 05:47,0Total Export without load in hours: 2:43:44Total Export with load in hours: 2:49:31Difference in minutes: 05:47,0 Only 4% difference

3/31/2004 111
Import to the new system
FS/RAW implementation tests with the data-upload of the incremental migration from Tru64 to HPUX.
Implementation: Start End Runtime12 Tables in parallelFilesystem: bs=1K, Mount Options=default 11:34:35 13:30:46 1:56:11Filesystem: bs=8K, Mount Options=default 16:40:34 18:35:35 1:55:01Filesystem: bs=8K, Mount Options=default, IO slaves=8 14:05:11 15:40:46 1:35:35Filesystem: bs=8K, Mount Options= rw,suid,largefiles,nolog,nodatainlog,mincache=direct,convosync=direct, IO slaves=8 16:44:41 18:36:22 1:51:41RAW device: async IO 11:45:53 13:00:34 1:14:41RAW device: no async IO; 8 IO slaves 16:50:37 18:00:50 1:10:13RAW device: async IO; 2 DB writer 13:50:12 15:05:11 1:14:59
Largest Table ACCTITFilesystem: bs=8K, Mount Options=default, IO slaves=8 16:08:16 16:37:24 0:29:08RAW device: async IO 13:16:35 13:44:21 0:27:46RAW device: no async IO; 8 IO slaves 9:32:39 9:59:56 0:27:17RAW device: async IO; 2 DB writer 15:15:32 15:43:51 0:28:19
•Copy export files to target system
•12 processes with 60% CPU-utilization for the fastest run
3/31/2004 112
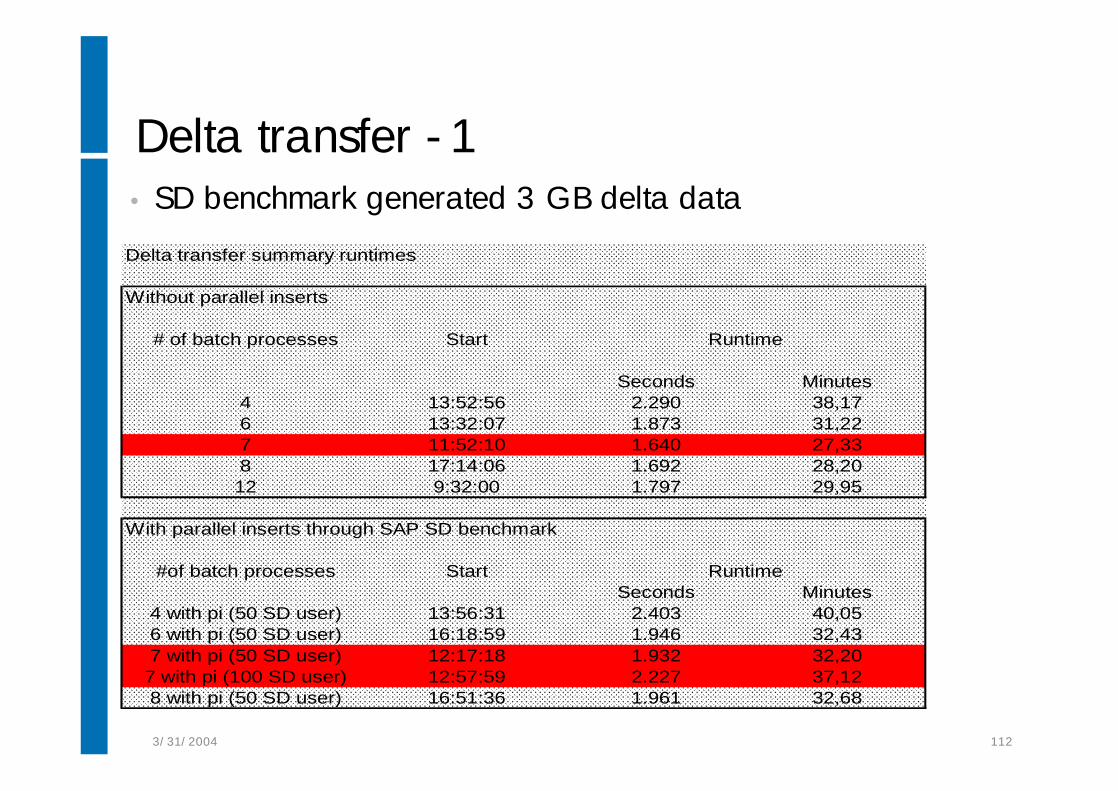
Delta transfer - 1• SD benchmark generated 3 GB delta dataDelta transfer summary runtimes
Without parallel inserts
# of batch processes Start
Seconds Minutes4 13:52:56 2.290 38,176 13:32:07 1.873 31,227 11:52:10 1.640 27,338 17:14:06 1.692 28,2012 9:32:00 1.797 29,95
With parallel inserts through SAP SD benchmark
#of batch processes StartSeconds Minutes
4 with pi (50 SD user) 13:56:31 2.403 40,056 with pi (50 SD user) 16:18:59 1.946 32,437 with pi (50 SD user) 12:17:18 1.932 32,207 with pi (100 SD user) 12:57:59 2.227 37,128 with pi (50 SD user) 16:51:36 1.961 32,68
Runtime
Runtime

3/31/2004 113
Delta transfer - 2
Ca. 40-55%Ca. 28-36%Ca. 17-22%
SAP disp+work
Ca. 42Ca. 42Ca. 42Oracle
Ca. 88%Ca. 75%Ca. 63%
User + System
With parallel load through 100 SD benchmark user
With parallel load through 50 SD benchmark user
Without parallel load
CPU

3/31/2004 114
Major findings• Largest table is the determining factor
• Storage hardware is the limiting factor, I/O tuning might be necessary
• Export stepconcurrent activities on the exported tables do not necessarily imply less throughput
• Delta-transferadditional app-server hardware for the conversion could help