sanskrit linguistic processing character-encoding, morphology, and lexicography peter m. scharf...
TRANSCRIPT

Sanskrit Linguistic Processing
Character-encoding,morphology,
and lexicography
Peter M. ScharfBrown University
23 December 2009

Peter M. Scharf, 23 Dec. 2009: 2
Roman-based Standards

Peter M. Scharf, 23 Dec. 2009: 3
Devanagarī-based Standards

Peter M. Scharf, 23 Dec. 2009: 4
Nominal inflection

Peter M. Scharf, 23 Dec. 2009: 5
Verbal inflection

Peter M. Scharf, 23 Dec. 2009: 6
Vedic Unicode

Peter M. Scharf, 23 Dec. 2009: 7
Encoding Vedic Characters
The Vedic Unicode Proposal recommends the addition of Vedic characters to the Unicode standard so that tone marks that appear in red in this palmleaf manuscript of the Vājasaneyisaṃhitā may be accurately represented in print.

Peter M. Scharf, 23 Dec. 2009: 8
Vedic Unicode Charts

Peter M. Scharf, 23 Dec. 2009: 9
Devanāgarī Extended

Peter M. Scharf, 23 Dec. 2009: 10
Vedic Extensions

Peter M. Scharf, 23 Dec. 2009: 11
LIES Appendix B
The Sanskrit Library Phonetic Basic encoding scheme (SLP1) attempts to meet high standards of unambiguous encoding while restricting encoding to 75 codepoints in the ASCII character set. SLP1 utilizes 57 codepoints to encode segments: 53 to represent phonetic segments and four to represent punctuation. In addition SLP1 utilizes 18 codepoints to encode phonetic features: three to indicate stricture, five to indicate length, eight to indicate tone, and one to indicate nasalization….

Peter M. Scharf, 23 Dec. 2009: 12
SLP1Basic Segments

Peter M. Scharf, 23 Dec. 2009: 13
B.3 Modifiers
Modifiers are added after a character to indicate variations in segment stricture, length, accent, and nasalization, in the order stated. Prolonged length, accent, and nasalization occur in classical Sanskrit as well as Vedic. Modifiers are used in combination to indicate special features of stricture, length, accent, and nasalization in Vedic.

Peter M. Scharf, 23 Dec. 2009: 14
B.3.1 Stricture
_ heaviness [used for semivowels y or v] = lightness [used for semivowels y or v]
! lack of release (abhinidhāna)[used for stops or semivowels y, v, or l]

Peter M. Scharf, 23 Dec. 2009: 15
B.3.2 Length* subsegmental epenthetic vowel (svarabhakti)
# length of half a mora
1 length of one mora [used in Vedic after shortagitated kampa; short e, o; and heavy anusvāra]
1# slightly lengthened
2 length of two morae [used for dvimātra anusvāra inVedic]
3 prolonged length of three morae [used for plutavowels]
4 prolonged length of four or more morae [used inraṅga]

Peter M. Scharf, 23 Dec. 2009: 16
B.3.3 Accent
/ high pitch
\ low pitch
^ circumflex
6 extra low tone
7 low tone
8 high tone
9 extra high tone
+ sharpness

Peter M. Scharf, 23 Dec. 2009: 17
B.3.4 Nasalization~ nasalization
Yamas
20 epenthetic nasalized segments:k~, kh~, . . . , b~, bh~
4 four epenthetic nasalized segments:k~, kh~, g~, gh~
20 replacements for a non-nasal stop before a nasal: k~, kh~, . . . , b~, bh~ (Ṛkprātiśākhya)

Peter M. Scharf, 23 Dec. 2009: 18
B.4.4 Syllabified visarga and anusvāra accent
H/ high-pitched visarga
H\ low-pitched visarga
H^ svarita visarga
M\ low-pitched anusvāra

Peter M. Scharf, 23 Dec. 2009: 19
Nominal Declension

Peter M. Scharf, 23 Dec. 2009: 20
Verbal Conjugation

Peter M. Scharf, 23 Dec. 2009: 21
XML Rules
for guṇa

Peter M. Scharf, 23 Dec. 2009: 22
ExecutablePerl code

Peter M. Scharf, 23 Dec. 2009: 23
XMLFull-form
Lexicon

Peter M. Scharf, 23 Dec. 2009: 24
Morphological Analyzer

Peter M. Scharf, 23 Dec. 2009: 25
Cologne Digital Sanskrit Dictionaries

Peter M. Scharf, 23 Dec. 2009: 26
CDSL Monier Williams

Peter M. Scharf, 23 Dec. 2009: 27
Digital Dictionaries of South Asia

Digital Sanskrit Library Integration
Flexible input and display,linking text to the full-form lexicon,
and aligning inflectional and morphological tags

Peter M. Scharf, 23 Dec. 2009: 29
Sanskrit Library Text-
lexicon Integrat
ion

Peter M. Scharf, 23 Dec. 2009: 30
Sanskrit Library Text-
lexicon Integrat
ion

Peter M. Scharf, 23 Dec. 2009: 31
Sanskrit
Library
Morpho-
logical
Analysis

Peter M. Scharf, 23 Dec. 2009: 32
Monier Williams: anuttama

Peter M. Scharf, 23 Dec. 2009: 33
Sanskrit Library Input/Display Preferences

Peter M. Scharf, 23 Dec. 2009: 34
Sanskrit Library Input/Display Preferences

Peter M. Scharf, 23 Dec. 2009: 35
Sanskrit Library Input/Display Preferences
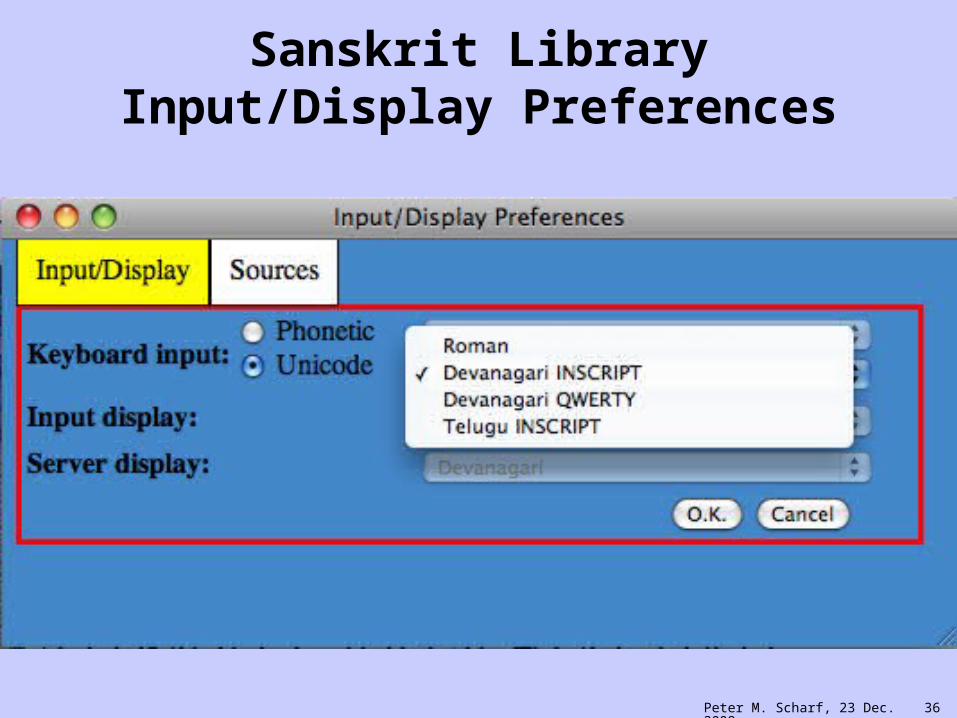
Peter M. Scharf, 23 Dec. 2009: 36
Sanskrit Library Input/Display Preferences

Peter M. Scharf, 23 Dec. 2009: 37
Sanskrit Library Lexical Sources Preferences

Peter M. Scharf, 23 Dec. 2009: 38
Böhtlingk’sSanskrit-Wörterbuch in
kürzerer Fassunganuttama

Peter M. Scharf, 23 Dec. 2009: 39
Böhtlingk and Roth’sGrosses Sanskrit-Wörterbuch
anuttama

Peter M. Scharf, 23 Dec. 2009: 40
Apte'sPractical Sanskrit-English
Dictionaryanuttama

Peter M. Scharf, 23 Dec. 2009: 41
Macdonell'sA Practical Sanskrit
Dictionaryanuttama

Sanskrit Linguistic Processing
Text-image alignment,and digital critical editing

Peter M. Scharf, 23 Dec. 2009: 43
Monier Williams Digital Image

Peter M. Scharf, 23 Dec. 2009: 44
Machine-readable text
Below is a segment of Ṣaḍguruśiṣya’s Vedārthadīpikā in SLP1 encoding.

Peter M. Scharf, 23 Dec. 2009: 45
Syllable Tags
Below is a segment of Ṣaḍguruśiṣya’s Vedārthadīpikā with orthographic syllable XML tags inserted.

Peter M. Scharf, 23 Dec. 2009: 46
Variant Readings
An XML file contains variant readings for various manuscripts and editions of Ṣaḍguruśiṣya’s Vedārthadīpikā.

Peter M. Scharf, 23 Dec. 2009: 47
Page Boundaries
An XML file of entries associates page boundaries in the manuscript Wai321 of Ṣaḍguruśiṣya’s Vedārthadīpikā with orthographic syllable tags in the machine-readable edition and in manuscript variants tags.

Peter M. Scharf, 23 Dec. 2009: 48
Word-spotting
A highlighted passage in a manuscript of Ṣaḍguruśiṣya’s Vedārthadīpikā: Wai321, folio 131, recto, line 8.

Peter M. Scharf, 23 Dec. 2009: 49
VAD Digital Critical Edition