sampling distributions:. in psychology we generally make inferences about populations on the basis...
Post on 20-Dec-2015
213 views
TRANSCRIPT

Sampling distributions:

In Psychology we generally make inferences about populations on the basis of samples.
We therefore need to know what relationship exists between samples and populations.
A population of scores has a mean (μ), a standard deviation (σ) and a shape (e.g., normal distribution).

high
frequencyof raw scores
low
µ = 63 in.σ = 2 in.
CONCRETE BUT MUNDANE EXAMPLE:HEIGHT OF ALL ADULT WOMEN IN ENGLAND
63 6561
σ
Height (inches)
6759

high
frequency of raw scores
low
64.2 in
Sample of 100 adult women from England
s = 2.5 inN = 100
s
X 64.2

If we take repeated samples, each sample has a mean height, a standard deviation (s), and a shape.
Due to random fluctuations, each sample is different - from other samples and from the parent population.
Fortunately, these differences are predictable - and hence we can still use samples in order to make inferences about their parent populations.
X 1X 2X 3.
.
.
s1
s2
s3
.
.
.

Frequency(how manymeans are agiven value)
63.0
Mean sample heights (inches)
Taking multiple samples (of a given size) gives rise to:Sampling distribution

What are the properties of the distribution of Sample Means?
(a) The mean of the sample means is the same as the mean of the population of raw scores:
(b) The sampling distribution of the mean also has a standard deviation. The standard deviation of the sample means is called the "standard error". It is NOT the same as the standard deviation of the population (of raw scores).
X
X

The standard error underestimates the population s.d.:
The bigger the sample size, the smaller the standard error.i.e., variation between samples decreases as sample size increases. (This is because producing a sample mean reduces the influence of any extreme raw scores in a sample).
X
N

frequency
63
Mean sample heights (inches)
µ = 63 in.
N = 100
Sampling distribution for N = 100
Suppose we take samples of N = 100
X
0.20

How do we calculate the standard deviation of a sampling distribution of the mean (known as
the standard error)? For N =100
X
2
100
2
100.20
Suppose the N = 16 instead of 100
X
2
16
2
40.50

(c) The distribution of sample means is normally distributed, no matter what the shape of the original distribution of raw scores in the population.
Example: Annual income of American citizens.
This distribution is positively skewed. Many people in the lower and medium income bracket; very few are ultra rich.
Suppose we take many samples of size N = 50.The sampling distribution of the mean will be normal.
This is due to the Central Limit Theorem.
This holds true only for sample sizes of 30 and greater.

Given the distribution is normal we use properties of normal distribution to do interesting things.
Various proportions of scores fall within certain limits of the mean (i.e. 68% fall within the range of the mean +/- 1 standard deviation; 95% within +/- 2 standard deviation, etc.).

Using z-scores, we can represent a given score in terms of how different it is from the mean of the group of scores.
Xi = 64μ = 63
Quick reminder of how to calculate z-score
zX X i
64 63
2
1
20.50

Relationship of a sample mean to the population mean:
We can do the same with sample means:(a) we obtain a particular sample mean;(b) we can represent this in terms of how different it is from the mean of its parent population.
μ = 63
zX
X N
64 63
2
16
12
4
2.00
64
X

If we obtain a sample mean that is much higher or lower than the population mean, there are two possible reasons:
(a) our sample mean is a rare "fluke" (a quirk of sampling variation);
(b) our sample has not come from the population we thought it did, but from some other, different, population.
The greater the difference between the sample and population means, the more plausible (b) becomes.

Take another example:
The human population I.Q. is 100.A random sample of people has a mean I.Q. of 170.
There are two explanations:(a) the sample is a fluke: by chance our random sample contained a large number of highly intelligent people.
(b) the sample does not come from the population we thought they did: our sample was actually from a different population - e.g., aliens masquerading as humans.

high
frequency of sample means
low
population mean I.Q. (100) sample mean I.Q. (170)
Relationship between population mean and sample mean:

This logic can be extended to the difference between two samples from the same population:
A common experimental design:We compare two groups of people: an experimental group and a control group.Experimental group get a "wolfman" drug.Control group get a harmless placebo.
Dependent Variable: number of dog-biscuits consumed.
At the start of the experiment, they are two samples from the same population ("humans").

At the end of the experiment, are they:(a) still two samples from the same population (i.e., still two samples of "humans" - our experimental treatment has left them unchanged); OR(b) now samples from two different populations - one from the "population of humans" and one from the "population of wolfmen"?

We can decide between these alternatives as follows:
The differences between any two sample means from the same population are normally distributed, around a mean difference of zero.
Most differences will be relatively small, since the Central Limit Theorem tells us that most samples will have similar means to the population mean (and hence similar means to each other).
If we obtain a very large difference between our sample means, it could have occurred by chance, but this is very unlikely - it is more likely that the two samples come from different populations.

Possible differences between two sample means:
high
low
mean of sample A mean of sample B
frequency of raw scores
a big difference between mean of sample A and mean of sample B:
sample meanslow high

Possible differences between two sample means (cont.):
high
low
mean of sample A mean of sample B
frequency of raw scores
a small difference between mean of sample A and mean of sample B:
sample means
low high

Frequency distribution of differences between sample means:
high
low
frequency of differences between sample means
size of difference between sample means( "sample mean A" minus "sample mean B")
no differencemean A bigger than mean B
mean A smaller than mean B
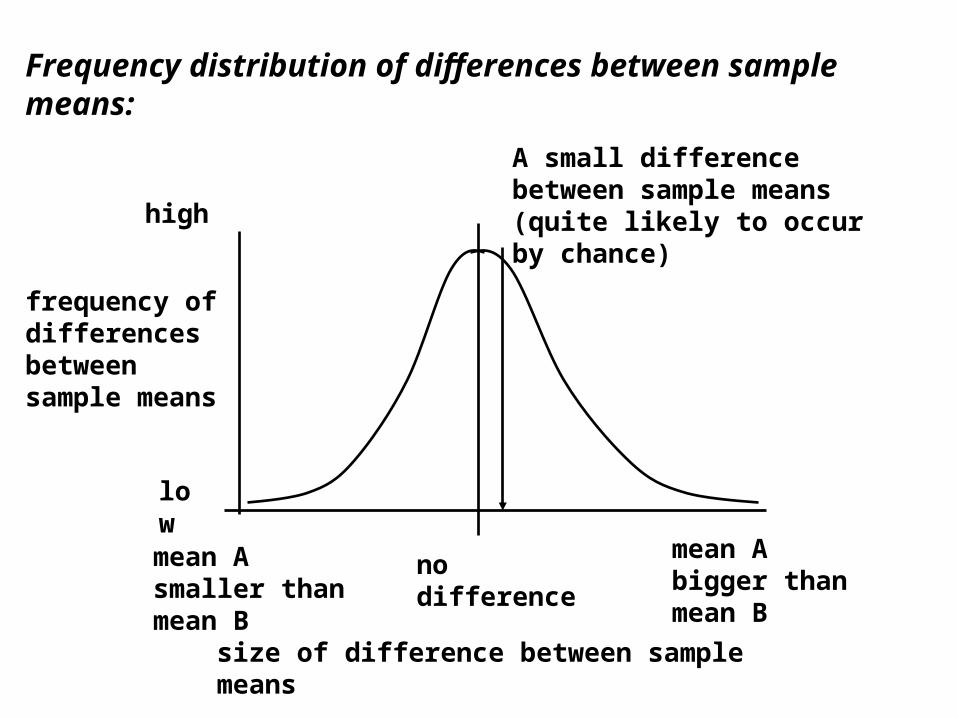
Frequency distribution of differences between sample means:
high
low
size of difference between sample means
no differencemean A bigger than mean B
mean A smaller than mean B
A small difference between sample means (quite likely to occur by chance)
frequency of differences between sample means
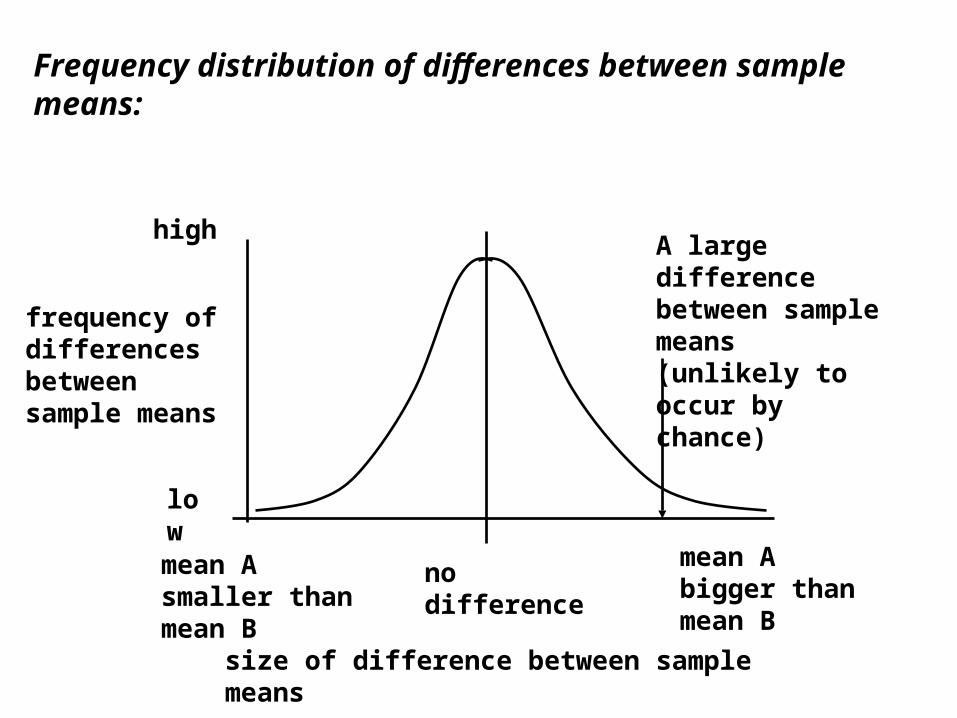
Frequency distribution of differences between sample means:
high
low
size of difference between sample means
no differencemean A bigger than mean B
mean A smaller than mean B
A large difference between sample means (unlikely to occur by chance)
frequency of differences between sample means