saleema amershi, principal researcher at microsoft research ai, … › goodsystemscscw › files...
TRANSCRIPT

Saleema Amershi, Principal Researcher at Microsoft Research AI, [email protected]
Embracing AI Failures The potential for AI technologies to enhance human capabilities and improve our lives is of little debate; yet, neither is their potential to cause harm and social disruption. While preventing or minimizing AI biases and harms is justifiably the subject of intense study in academic, industrial and even legal communities, an approach centered on acknowledging and embracing AI-based failures has the potential to shed new light on how to develop and deploy ethical AI-based systems.
Why focus on failures? AI models are our attempts to represent and operationalize key aspects of real world systems. By “attempt” I mean that it is difficult, if not impossible, for AI models to ever fully capture the complexity of the real world. Consequently, errors are essentially inherent to AI models by design. That is, many AI algorithms work to optimize some objective function, such as minimizing some notion of loss or cost. In doing so, and because AI models only partially represent reality, AI algorithms necessarily must trade off errors and sacrifice parts of the input space to produce functions that can generalize to new scenarios. Therefore, while efforts to avoid AI biases and harms are needed, ethical AI development must also recognize failures as inevitable and work towards systematically and proactively identifying, assessing, and mitigating harms that could be caused by such failures.
How should we think about failures? When thinking about AI failures, we need to think holistically about AI-based systems. AI-based systems include AI models (and the datasets and algorithms used to train them), the software and infrastructure supporting the operation of those models within an application, and the application interfaces between those models and the people directly interacting with or indirectly affected by them. AI-based failures therefore go beyond traditional notions of model errors (such as false positives and false negatives) and model accuracy measures (such as precision and recall) and include sociotechnical failures that arise when AI-based systems interact with people in the real world. For example, medical doctors or judges viewing AI-based recommendations to inform decision making may over- or under-estimate the capabilities of the AI components making those recommendations, to the potential detriment of patients and litigants. Acknowledging this type of sociotechnical failure has motivated an exciting and active area of research in algorithm transparency and explanations. Characterizing other types of sociotechnical failures associated with AI-based systems can reveal additional opportunities to mitigate harms.
How can thinking about failures help to mitigate harms? Thinking about potential points of failure in holistic AI-based systems also highlights opportunities for new types of solutions. Consider, for example, developing an AI-based notification system that automatically detects important tasks and sends people reminders when they are due. In this scenario, harms may occur if notifications appear when people are attending to critical tasks like driving. This is not a failure of the AI-model which may be correctly detecting tasks and due dates, it is a failure to adequately consider likely contexts of use. Potential mitigation strategies may therefore include re-architecting the system to monitor, infer and suspend notifications in critical contexts as well as designing mechanisms to support efficient manual dismissal in case notifications still mistakenly fire. Other types of sociotechnical AI failures may include expectation mismatches, careless model updates, and insufficient support for human oversight and control.
Framing AI development around identifying and mitigating sociotechnical AI-based failures may reveal new opportunities to ensure fair and responsible use of AI in society.

Ethical AI Starts with the Data
Position Statement Scholarship on the ethics of artificial intelligence has been, perhaps justifiably, largely focused on assessing how AI’s outputs might (re)produce instances of bias, unfairness, and injustice. Outputs, whether scientific models, products, or services, are where the ethical consequences of automated decision systems become most apparent. However, numerous potential impacts of AI also stem from the data collection process that precedes any data science or machine learning that takes place subsequently.
While various research communities have recently engaged deeply with the ethics of data collection, sharing and retention practices [1,2,3,4], these debates have often remained less visible to the computer science, data science, and machine learning communities that drive the development of AI, and where a separate set of debates surround the question of AI ethics. This threatens to produce a gap between data ethics and AI ethics with important implications—many of the AI and machine learning applications that have drawn scrutiny for causing unjust outcomes start with data collection practices that fall below ethical thresholds.
Data collection is often where unjust power relations between scientist and research subject are most clearly established, preceding the steps that are deployed to actually develop an AI system. Yet the conditions of
Paste the appropriate copyright/license statement here. ACM now supports three different publication options:
• ACM copyright: ACM holds the copyright on the work. This is the historical approach.
• License: The author(s) retain copyright, but ACM receives an exclusive publication license.
• Open Access: The author(s) wish to pay for the work to be open access. The additional fee must be paid to ACM.
This text field is large enough to hold the appropriate release statement assuming it is single-spaced in Verdana 7 point font. Please do not change the size of this text box. Each submission will be assigned a unique DOI string to be included here.
Michael Zimmer Marquette University Milwaukee, WI 53233, USA [email protected] Emanuel Moss CUNY Graduate Center | Data & Society New York, NY [email protected]

that relationship can be predictive of the ethical stakes of how the science will be applied, either as research or engineering outputs. Three examples illuminate this concern.
Example 1: Negative public attention surrounded an algorithm that could infer sexual orientation from photographs and facial recognition algorithms trained on videos of transgender people. In both cases, there were ethical concerns about both the purpose of these algorithms and the fact that the data that trained them (dating profile photos and YouTube videos, respectively) was “public” but collected from potentially vulnerable populations without consent.
Example 2: Google’s artificial intelligence company DeepMind has been granted access to the identifiable personal medical information of millions of UK patients through a data-sharing agreement with the Royal Free London NHS Foundation Trust. The agreement provides access to patient data from the last five years, including information about people who are HIV-positive, for instance, as well as details of drug overdoses and abortions. Ethical concerns arise due to the lack of any data anonymization, as well as a lack of specific patient consent for the data sharing. Google has said that each individual patient’s consent for their data being shared is implied, because it is providing “direct care” to Royal Free’s patients through its machine learning tools.
Example 3: The NIH National Institute of Mental Health is increasingly funding research to leverage existing electronic health record (EHR) data and advancements in statistical modeling to improve the prediction of suicide attempts over conventional self-
reporting methods. Researchers seek to improve existing EHR-based suicide risk prediction models by integrating additional datasets to create multifactorial predictive models of suicidal behavior risk, such as publicly available datasets containing financial, legal, life event and sociodemographic data. Combing such data with medical data represents a potential collapse of longstanding boundaries that shape individuals’ willingness to share data within particular contexts.
Unlike for many other research disciplines, the data collection that fuels the training and testing of machine learning, neural networks, and AI systems generally occurs prior to and separate from the analyses data scientists perform. But that does not absolve them of their responsibilities to ensure that data collection, and data re-use, is utilized in a fair, ethical, and just manner. While data scientists and those building AI systems cannot always control the conditions under which the data they utilize is collected, their use of the data raises a number of challenges and concerns that have not traditionally fallen under the rubric of AI ethics.
Participating in the “Good Systems: Ethical AI for CSCW” workshop will foster conversations about practices of data collection and retention within the emerging practices of pursuing ethical AI.
Acknowledgements This work is supported by the National Science Foundation under grant numbers 1947754 and 1704425, and by the Pervasive Data Ethics for Computational Research (PERVADE) project.

References 1. Christopher Frauenberger, Amy Bruckman,
Cosmin Munteanu, Melissa Densmore, and Jenny Waycott. 2017. Research Ethics in HCI: A Town Hall Meeting. Proceedings of the 2017 CHI Conference Extended Abstracts on Human Factors in Computing Systems: 1295–1299.
2. Annette Markham and Elizabeth Buchanan. 2012. Ethical Decision-Making and Internet Research: Recommendations from the AoIR Ethics Working Committee (Version 2.0). Association of Internet Researchers.
3. Jessica Vitak, Katie Shilton, and Zahra Ashktorab. 2016. Beyond the Belmont Principles: Ethical Challenges, Practices, and Beliefs in the Online Data Research Community. Proceedings of the 19th ACM Conference on Computer-Supported Cooperative Work & Social Computing, ACM, 941–953.
4. Michael Zimmer and Katharina Kinder-Kurlanda, eds. 2017. Internet Research Ethics for the Social Age: New Challenges, Cases, and Contexts. Peter Lang, New York.

To Shape the Future of AI, We Must Understand AI Developers Karen Boyd, PhD Candidate at the University of Maryland, College Park. [email protected] Researchers have verified algorithmic discrimination in outcomes and accuracy on the basis of age (Diaz et al., 2018), gender (Bolukbasi et al., 2016, Dastin, 2018), race (Sweeney, 2013; Mehrotra et al., 2017; Angwin, 2016), and the intersection of gender and race (Noble, 2018; Buolamwini & Gebru, 2018) across product types, including (for the above examples) text processing, search engines, facial recognition, ad delivery, and criminal risk estimates. Fairness isn’t the only ethical implication of machine learning (ML): concerns about privacy and accountability have also been raised as well. Anonymized training datasets released publicly have been reidentified (Narayanan & Shmatikov, 2006) and researchers, the popular press, and the courts are discussing algorithmic accountability and due process in big data (Crawford & Schultz, 2014; Angwin, 2016b; Wisconsin v. Loomis, 2016). In response to ethical concerns, researchers have designed, tested, and published technical and practice-based interventions throughout the ML development process and conferences like ACM’s Fairness Accountability and Transparency (FAT*) and Artificial Intelligence, Ethics, and Society (AIES) have emerged to publish ethics-focused work. But will interventions be adopted? In my view, the practices, perspectives, and pressures on ML engineers are understudied areas, but are key to making sure that the technologies, policies, and messages concerned actors use to try to influence AI development have their intended effects. I am early in my career and excited to change my mind with data, but here are my impressions of ML engineering based on reading, my own data, and friendly shouting matches with colleagues over beers at ICWSM:
- ML engineering (and software development in general) has an unusually strong occupational culture (Hofstede, 2011), considering its relatively few traditional markings of professionalization (i.e. no consistent training regime, certification, or other formal means of occupational closure)
- Many ML engineers see their job as primarily technical. Even though their inputs, products, and their products’ impact on the world are socio-technical, they (and their educators and employers) scope their job as primarily to achieve technical requirements and improve performance metrics. The jobs of assessing and managing social impact are someone else’s.
- Although social impact isn’t seen as their job, because of their unique skills, understanding, and access to this especially opaque and sophisticated technology, ML engineers may be the only ones in a position to affect the social impact of it by manipulating training data, setting parameters, and communicating to users about the specific risks and weaknesses of a product’s use.
- When ML engineers talk about issues of bias, privacy, and other ethical concerns, they use framings about “quality” and “security.”
I am concerned about increasingly capable AI because of its scale, impact, and opacity. Some users seem to believe that delegating important decisions, like hiring, evaluation, policing, and parole, will get around human bias, when in fact ML entrenches that bias. If we don’t take it seriously and address the social part of this sociotechincal problem throughout development and use, increasingly capable AI systems will cause more harm. My position about the future of AI is that in order to nudge it in a direction that’s aligned with human interests and values, we must understand and consider the lifeworlds of ML engineers.

References
Angwin, J. (2018, January 20). Opinion | Make Algorithms Accountable. The New York Times. Retrieved from https://www.nytimes.com/2016/08/01/opinion/make-algorithms-accountable.html
Angwin (ProPublica), J. (n.d.). Wisconsin-v-Loomis-Opinion. Retrieved March 12, 2019, from https://www.documentcloud.org/documents/2993525-Wisconsin-v-Loomis-Opinion.html
Bolukbasi, T., Chang, K.-W., Zou, J. Y., Saligrama, V., & Kalai, A. T. (2016). Man is to Computer Programmer as Woman is to Homemaker? Debiasing Word Embeddings. In D. D. Lee, M. Sugiyama, U. V. Luxburg, I. Guyon, & R. Garnett (Eds.), Advances in Neural Information Processing Systems 29 (pp. 4349–4357). Retrieved from http://papers.nips.cc/paper/6228-man-is-to-computer-programmer-as-woman-is-to-homemaker-debiasing-word-embeddings.pdf
Buolamwini, J., & Gebru, T. (n.d.). Gender Shades: Intersectional Accuracy Disparities in Commercial Gender Classication. 15.
Crawford, K., & Schultz, J. (n.d.). Big Data and Due Process: Toward a Framework to Redress Predictive Privacy Harms. 55 , 37.
Dastin, J. (2018, October 10). Amazon scraps secret AI recruiting tool that showed bias against women. Reuters. Retrieved from https://www.reuters.com/article/us-amazon-com-jobs-automation-insight-idUSKCN1MK08G
Diaz, M., Johnson, I., Lazar, A., Piper, A. M., & Gergle, D. (2018). Addressing Age-Related Bias in Sentiment Analysis. Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems - CHI ’18 , 1–14. https://doi.org/10.1145/3173574.3173986
Hofstede, G. H. (1991). Cultures and organizations: software of the mind.
Julia Angwin, J. L. (2016, May 23). Machine Bias [Text/html]. Retrieved April 13, 2018, from ProPublica website: https://www.propublica.org/article/machine-bias-risk-assessments-in-criminal-sentencing
Mehrotra, R., Anderson, A., Diaz, F., Sharma, A., Wallach, H., & Yilmaz, E. (2017). Auditing Search Engines for Differential Satisfaction Across Demographics. Proceedings of the 26th International Conference on World Wide Web Companion - WWW ’17 Companion, 626–633. https://doi.org/10.1145/3041021.3054197
Narayanan, A., & Shmatikov, V. (2006). How To Break Anonymity of the Netflix Prize Dataset. Retrieved February 28, 2019, from undefined website: /paper/How-To-Break-Anonymity-of-the-Netflix-Prize-Dataset-Narayanan-Shmatikov/56116e8ce3f57bec578ac60f6d68333aea5af59e
Noble, S. U. (2018). Algorithms of Oppression: How Search Engines Reinforce Racism. NYU Press.
Sweeney, L. (2013). Discrimination in Online Ad Delivery. ArXiv:1301.6822 [Cs]. Retrieved from http://arxiv.org/abs/1301.6822

Self-Disclosure in Chatbot AI Interaction: Ethical ConcernsYi-Chieh Lee ⇤
University of [email protected]
Naomi Yamashita⇤NTT Communication Science
Yun Huang
University of [email protected]
Author KeywordsChatbot; Self-disclosure; Ethics; Trust
DEEP SELF-DISCLOSURE IN CHATBOT AI INTERACTIONWe envision that future chatbot AI interaction will enable peo-ple’s deep self-disclosure. For example, in our recent work,we designed and evaluated a chatbot as a mediator to promoteusers’ “deep” self-disclosure to real mental health profession-als. The idea was motivated by prior findings that mentalhealth professionals (e.g., therapists) disclosed informationthemselves in face-to-face meet-ups to elicit self-disclosurefrom patients; and chatbot’s self-disclosure resulted in morepeople’s self-disclosure.
We invited 47 participants and randomly assigned them tothree groups that did not receive chatbot’s self-disclosure; re-ceived chatbot’s low-level self-disclosure; and received deepself-disclosure, respectively. After using the chatbot for threeweeks, we then asked if they were willing to share their self-disclosure data with a real mental health professional throughthe chatbot. By examining participants’ self-disclosure dataone week before and one week after sharing with the realmental health professional, we found that the chatbot’s deepself-disclosure successfully elicited participants’ deeper self-disclosure not only to the chatbot but also to the real men-tal health professional, more so than other chatbot’s chat-ting styles. We also found that even though the overall self-disclosure depth was consistent within each group betweeninteracting with the chatbot only and sharing with the profes-sional via chatbot, there were still variances among the detailsof people’s self-disclosure.
However, several participants felt surprised when they wereasked about if their self-disclosure data could be shared witha real doctor. Though these individuals had been introducedto the idea of the doctor’s involvement before being asked toshare their answers with the doctor, they still felt surprised.For example: To be honest, I felt offended in the beginning.
Maybe when I talked to the chatbot, I thought the conversation
was only between the chatbot and me, so I disclosed a lot of
secrets. But soon I calmed down and was willing to share my
answers because I felt I could trust the doctor. (S35, F)
Permission to make digital or hard copies of all or part of this work for personal orclassroom use is granted without fee provided that copies are not made or distributedfor profit or commercial advantage and that copies bear this notice and the full citationon the first page. Copyrights for components of this work owned by others than theauthor(s) must be honored. Abstracting with credit is permitted. To copy otherwise, orrepublish, to post on servers or to redistribute to lists, requires prior specific permissionand/or a fee. Request permissions from [email protected]’20, April 25–30, 2020, Honolulu, HI, USA
© 2020 Copyright held by the owner/author(s). Publication rights licensed to ACM.ISBN 978-1-4503-6708-0/20/04. . . $15.00DOI: https://doi.org/10.1145/3313831.XXXXXXX
ETHICAL CONCERNSThe fact that the participants who showed their surprises werethe ones who had high trust with the chatbot and felt com-fortable to self-disclose to the chatbot. Our self-disclosureanalysis also echoes this statement and indicates that theseparticipants disclosed deeper levels of feelings and thoughts.Even though these participants expressed surprise when
asked to share answers with the doctor, they still shared
their answers in the end. Their feelings of surprise mightbe a result of their deep self-disclosure to the chatbot withoutany expectation that their answers would be shared with a realdoctor. Our study allowed participants to edit their originalanswers and decide to share or not; however, some ethicalconcerns might still exist for an unexpected request from thechatbot because the users might have performed very differ-ently had they known about the request to share their answerwith a professional in advance.
There are several ethical issues worth addressing when design-ing a chatbot for health cares, and we want to propose themin this workshop. First, the impact of informing users in ad-
vance. When deploying such a chatbot into real applications,it is likely when people start using a chatbot they would knowthe data might be shared with a professional. This setting mayaffect users’ self-disclosure behavior with a chatbot becausethey might feel like they are being monitored and be reluctantto self-disclose deeply, which may deter the efficacy of using achatbot to improve mental health. Prior studies suggested thatpeople had less concerns of anonymously sharing their stress,depression, and anxiety on online social media platforms, thusanonymity may be leveraged by people when self-disclosingvia chatbot to address their concerns shared in the interviews.
Second, should the AI-agent be designed to dig for users’
private information? CASA paradigm indicated that peoplemay mindlessly apply human social norms to a computer agent.Thus, people might disclose some highly intimate informationto an agent after gaining trust in the agent; however, if dis-closed content includes criminal confessions and unreportedharassment issues, it will be a dilemma for a chatbot systemto deal with this situation. A chatbot’s user might be informedthat their conversation is confidential, so the user may be will-ing to disclose more. But if the chatbot detects somethingillegal, should the chatbot brake the promise? There is a lackof legislation to address this conflict, but if it is possible todisclose information without permission, the users would beconcerned and disclose less information. In addition, vali-dation of the disclosed content could also be a concern forreporting the issues. In brief, these ethical issues need furtherdiscussion in the workshop.

Operationalized Sentience for a Networked World Dianna Radpour, Department of Information Science, University of Colorado Boulder
Consider the following about the popular crowdsourcing website Amazon Mechanical Turk. Though the site is widely used in the world of research, the question of who is doing the click work is quite often overlooked, with the assumption that everyone on it is of legal age to work because it is required of Turkers to be 18. However, there is no verification process to ensure that the workers are in fact the age they claim. Go a little ways down the Reddit hole and you will quickly find threads of users admitting to, and speaking to the ease at which they are making money on MTurk while being underage. Such breaches of labor laws (along with the evidence) seem to go completely ignored because, afterall, what can really be done? The Internet knows though – should it be doing something? In the future it does. In 1986, Langdon Winner addressed the challenge of having to search for limits in an age of high technology in The Whale and the Reactor [2]. That was over 30 years ago and the technological peak we are positioned at no longer mandates us to keep searching aimlessly for the limits. We can and are on the brink of hard-coding society’s moral boundaries and digitizing ethical standards. Look to the Moral Machine experiment as an example of a crowdsourced platform for gathering a human perspective on moral decisions that machines will eventually be in charge of making, such as self-driving cars [1]. If most of the world thinks that a car ought to swerve to kill a very old person to save a pregnant woman’s life, then it seems logical that the world’s self-driving cars will remain consistent with that judgement. Following suit, we can collect, quantify, and integrate the societal expectations around different harmful activities we observe in our systems. For example, how ought a teenager who sits down at their computer every day to cyberbully strangers on the Internet be dealt with? We have the ability to design systems that are capable of condemning such activities if we collectively agree that they break some moral standards. A sentient web sits at the intersection of artificial, collective, and emotional intelligence. It is a world of digitized support systems and computers that can condemn. Different situations garner different moral judgements. Once we formalize all aspects of our own emotional intelligence, our conceptions around empathy in their entirety, we allow for sentient systems that are guided by a collective moral compass to moderate online interactions, and to ensure our technologies serve as positive “forms of life” that make way for building order in the world. [2]

References [1] Awad, E., Dsouza, S., Kim, R., Schulz, J., Henrich, J.D., Shariff, A., Bonnefon, J., & Rahwan, I. (2018). The Moral Machine experiment. Nature, 563, 59-64. [2] Winner, L. (1986). The whale and the reactor: A search for limits in an age of high technology. Chicago: University of Chicago Press.

Good Systems: Ethical AI for CSCW
Position Statement
Elliott Hauser
Doctoral Candidate
University of North Carolina at Chapel Hill
The future I’d like to explore is one in which AI Systems are evaluated as ethical agents, rather than as mere tools employed by human ethical agents. This will require two main conceptual innovations:
● An account of algorithmic agency. How can AI systems be said to do something, and how can they be held responsible for these actions. Do the actions of AI systems have ethical relevance for others, such as those that build, design, or employ them?
● An account of (philosophical) ethics suitable for AI systems. This must go beyond the familiar code-of-ethics based folkways. While folkways and community norms can be important forces for good, they are often developed in reaction to undesired behavior, which diminishes their ability to consider new technologies and practices. A coherent philosophical way of evaluating whether AI systems’ actions are good is needed to proactively and prescriptively circumscribe and guide their development.
My own work is addressing these two questions in ways I hope prove generative.
My dissertation attempts to clarify the actions and actors that enable information systems to condition social reality. Databases, for instance, now routinely contain facts, in the sense of propositional logic. That is, instead of representing some state of the world, databases such as airline ticketing systems, the No Fly list, and China’s Social Credit Score directly create the states which determine whether statements are true or false. This shift is not unique to computerized information systems; written records have sometimes played analogous roles before. But the proliferation of these systems has made this phenomenon more widespread, and more portentous in recent years.
Key to this work has been identifying the actions of promulgation , the making of inscriptions within information systems, and enactment , the conditioning of action based on promulgations. Each process has a corresponding agent. Promulgating agents are increasingly automated systems: China’s Social Credit Score is computed by algorithm, for instance. Automated enacting agents are becoming more prevalent as well. Whereas a conversation with a bank loan officer may have once been required to get a loan, and in China such officers would thereby become enacting agents that translated the Social Credit Score into social reality, it is common that even the enactment of these systems is becoming automated as well. This provides an end-to-end platform whereby those with control over automated promulgating and enacting agents can condition social reality. Human agents retain a role in many of these systems, and form a complex ethical assemblage that I’ll address in ongoing work.
My ethical approach to this problem has been through the work of philosopher Richard Rorty. Rorty 1
attempted to build a pragmatic account of ethics that was coherent even when confronted with the radical historical and cultural contingency of ethics as a philosophical project. In an increasingly divided and at times “post-truth” global context, Rorty’s thought offers an inroads to the problem of the ethical character of AI systems, their actions, and their manifold imbrications with human actors. He advances the principle of Solidarity as a way of reclaiming and justifying a focus on the value of human life, even for those that realize the contingency of ethics.
Regardless of the success of my approaches, I hope to build consensus around the importance of the questions. Considering them thoughtfully will help us avoid playing ethical catch up to AI systems.
1 Elliott Hauser and Joseph T. Tennis, “Ethics for Contingent Classifications: Rorty’s Pragmatic Ethics and Postmodern Knowledge Organization,” in Proceedings of the North American Society for Knowledge Organization , (2019).

Planning for Ethical Agent-Agent Interaction
Jesse David DinneenVictoria University of Wellington, New Zealand
ABSTRACT
In this position paper for the 2019 CSCW workshop Good
Systems: Ethical AI for CSCW I propose one tool and oneidea for navigating the complex ethical problem space that
results from the interaction of human and/or AI agents inshared, hopefully cooperative, computing environments.
KEYWORDS
AI ethics; human-computer interaction; ontic trust
AGENT-AGENT INTERACTION
The introduction of non-human agents (e.g., AI-powered
virtual assistants like Apple's Siri), which are increasinglyindistinguishable from human agents, to everyday
computing raises many questions about what AI, ourinteractions with it, and AI-AI interactions (all collectively:
agent-agent interactions) could and should be like,especially as AI grow in capacity to be moral agents akin to
humans (Floridi & Sanders, 2004). To guideimplementations and expectations of moral AI requires
considering the many ways agents’ actions can beundesirable, but presently most news media and even
scholarly discourses focus narrowly on poor performance,transgressions of the law, and negative outcomes for
particular individuals irrespective of their socio-economicgroup or status (Stahl et al., 2016). Thus, while the moral-
problem space of agent-agent interaction is arguably morevast than that of human-human interaction, we designers
and critics have so far used fewer tools to analyse it.
Towards addressing narrow thinking in AI ethics, and to aid
anticipatory (rather than reactionary) policy, I would like toconsider the use of a multi-moral matrix for assessing (in
design or post hoc) particular AI cases along multiple moralframeworks. Figure 1 shows an example matrix with agent
actions in the leftmost column and each other columnshowing possible transgressions according to various moral
frameworks (summarised to the point of caricature),including (left to right): legalism, consequentialism, virtue
ethics and deontology, social justice, and socialcontractualism. Cells at the intersections of actions and
frameworks may reflect only that there are possibletransgressions or may contain more detail. Agent actions
may be relatively easy to populate, e.g., by identifyingactions in user stories during development.
Actio
n
Illegal
Bad
ou
tcom
e
Ill-inten
tion
ed,
decep
tive,
neg
lectfdu
l
Socia
lly u
nju
st
Vio
lates a
socia
lco
ntra
ct
...
1 X X
2 X
...
Figure 1. Partial example of a multi-moral matrix foranalysing ethical issues in agent-agent interaction.
The example matrix includes only a few moral frameworks
and is meant to be neither exhaustive nor prescriptive; anyuse of such a matrix requires customisation according to the
expectations of, e.g., the relevant sectors and cultures.
Finally, I suggest to adopt or adapt into thinking about AI
ethics an idea that appears thematically appropriate and alsopromising for addressing cultural moral differences like
those just mentioned (Hongladarom, 2008): the concept ofontic trust (Floridi, 2009). Put briefly, ontic trust is a
responsibility to care for the intrinsically valuableinformation objects that populate our world/infosphere;
shorter still, causing entropy in a shared informationenvironment is unethical. Such an idea shows us a less
obvious way agent-agent interactions can be bad (i.e., bycausing entropy – it could thus go in the above matrix), but
arguably also implies rights for non-human agents (i.e., AI).Surprisingly, little has been said about ontic trust in AI
ethics discourse (and to my knowledge, nothing has beensaid in the context of CSCW). It may therefore be useful to
raise the idea at the workshop and discuss questions like:
• Is an imperative to care for information objects
equivalent to an imperative to prevent entropy?
• What do such imperatives imply entail for privacy,
data logging, the right to be forgotten, and CSCWcommunity values? (Bruckman et al., 2017)
• Can ontic trust aid universal design by, forexample, mediating disparate cultural views about
ethical AI?
CSCW 2019 | Austin TX, USA | 10 November, 2019
Authors retain copyright.

REFERENCES
Bruckman, A. S., Fiesler, C., Hancock, J., & Munteanu, C.
(2017). CSCW research ethics town hall: Working towards community norms. In Companion of the 2017
ACM Conference on Computer Supported CooperativeWork and Social Computing (pp. 113-115). ACM.
Floridi, L., & Sanders, J. W. (2004). On the morality of artificial agents. Minds and Machines, 14(3), 349-379.
Floridi, L. (2009). Global information ethics: The importance of being environmentally earnest. In
Human Computer Interaction: Concepts, Methodologies, Tools, and Applications (pp. 2450-
2461). IGI Global.
Hongladarom, S. (2008). Floridi and Spinoza on global
information ethics. Ethics and Information Technology, 10(2-3), 175-187.
Stahl, B. C., Timmermans, J., & Mittelstadt, B. D. (2016). The ethics of computing: A survey of the computing-
oriented literature. ACM Computing Surveys (CSUR), 48(4), 55.

Ethical Concerns for the Future of Face Recognition Technology and Policy Kolina Koltai (UT Austin), Claudia Flores-Saviaga (West Virginia University), Megan Rim (University
of Michigan) Regulation of face recognition technology (FRT) has not kept pace with increasingly widespread
adoption of face recognition technologies. This has resulted in the unregulated use of FRT by law enforcement in places such as Detroit, Michigan, and Baltimore, Maryland. While several bills have been introduced, there currently exists no comprehensive protections at the federal level against the use of face recognition on citizens. Although, San Francisco, California, Somerville, Massachusetts, and Oakland, California have instituted bans on FRT, some cities have opted instead to pass regulatory policies face recognition to the effect of imposing some restrictions but ultimately legitimizing its use as a policing technology. As some cities have begun implementing real-time face recognition technologies, this has stirred debate about how its use by law enforcement might violate the First Amendment's protections of the right to freedom of assembly, and Fourth Amendment’s protections against the unlawful search of private spaces (Hamann and Smith, 2019).
As it stands, we do not anticipate FRT to leave the public space in the near future. We anticipate that more governments and agencies would want to incorporate FRT into monitoring, policing, and military efforts. FRT will be built into the infrastructure of society, physically with cameras, institutionally with policy, and culturally as an accepted norm. We also anticipate there being a lack of separation between FRT data and personal data from other companies and organizations. You can imagine Social Media Platform data and FRT data combining to give a ‘catered’ experience when you go to different physical locations. While it may seem ‘Minority Report’-esqe, we may not be far from a future that has highly integrated FRT into society from shopping and catered ad preferences and consistent monitoring.
FRT biometrically identifies you by matching your unique facial dimensions against huge databases. However, a recent study uncovered large gender and racial bias in commercial Facial recognition software. In the researchers’ experiments, the accuracy in determining the gender of light-skinned men were never worse than 0.8 percent. For darker-skinned women, however, the error rates ballooned to 35 percent (Buolamwini, 2018). Afterall, FRT is only as smart as the data used to train it. If the system is trained using faces of many more white men than people of color, then it will be worse at identifying these minorities. This is worrisome as across the U.S, state and local police departments are building their own face recognition systems. But, we know very little about them. i.e. we don’t know how they address accuracy problems. As a consequence, we don’t know how any of these systems affect racial and ethnic minorities.
Recent research has proposed ways to reduce bias in identifying people in different demographic groups (Amini, 2019), but without regulation, that won’t curb the technology’s potential for abuse. Ultimately, as accuracy is improved and bias is mitigated, it is expected that law enforcement will want to use FRT for immediate identification. For example, it might soon be possible to scan the faces of people passing by the street using CCTV cameras and determine not just who someone is, but where they’ve been, where they’re going, and whether they have an outstanding warrant, immigration detainer, or unpaid traffic ticket (Kofman, 2017). If FT systems that government and law enforcement agencies use is biased and with low accuracy, there is risk that the face recognition search will lead to an investigation, if not an arrest, of the wrong person (Garvie, 2019).
The main problem is that existing privacy and civil rights laws were mainly designed to limit old-fashioned forms of privacy violation, such as illegal searches or unauthorized revelation of private activities, such as medical records. Currently, there is evidence about how face recognition is being used in police surveillance of protests (Garvie, 2016). This could have an impact on the public and political discourse. For example, past research has found that surveillance practices may create a chilling effect on democratic discourse by stifling the expression of minority political views (Stoycheff, 2016). If the of face recognition technology in public spaces continues to expand, minorities might not choose to participate in activities such as protests, if they know their face could be scanned. In the absence of regulation, the use of face recognition for law enforcement, could lead to serious risks of misidentification. In the absence of transparency, these uses threaten to violate the due process rights of those arrested (Garvie, 2019).

References Amini, A., Soleimany, A., Schwarting, W., Bhatia, S., & Rus, D. (2019). Uncovering and Mitigating Algorithmic Bias through Learned Latent Structure. Buolamwini, J., & Gebru, T. (2018, January). Gender shades: Intersectional accuracy disparities in commercial gender classification. In Conference on fairness, accountability and transparency (pp. 77-91). Garvie, C. (March, 2019). Garbage In, Garbage Out: Face Recognition on Flawed Data |Center on Privacy and Technology, Georgetown. https://www.flawedfacedata.com/. (Accessed on 09/22/2019). Garvie, C. 2016. Bedoya A. Frankle J. (October, 2016). Perpetual Line Up - Unregulated Police Face Recognition in America | |Center on Privacy and Technology, Georgetown. https://www.perpetuallineup.org/.(Accessed on 09/22/2019). Introna, L., & Nissenbaum, H. (2010). Facial recognition technology a survey of policy and implementation issues. Kofman, A. (2017, March) Privacy Fears Over Cops Using Real-Time Face Recognition | The Intercept. http://bit.ly/2m7aOku. (Accessed on 09/22/2019) Stoycheff, E. (2016). Under surveillance: Examining Facebook’s spiral of silence effects in the wake of NSA Internet monitoring. Journalism & Mass Communication Quarterly, 93(2), 296-311.

What’s in a face?Speculating the future of Computer Vision through the lens of AI
Shivani Kapania & Anushka Bhandari ⇤
[email protected], [email protected]
IIIT Delhi, India
As researchers who have worked both in Computer Vision (CV) and HCI, we recognize thatCV applications are becoming ubiquitous day-by-day due to the vast (and ongoing) research inmachine learning techniques, especially, convolutional neural networks [1] and generative adversarialnetworks [2]. The computer vision community has developed methods for object detection andtracking [3], facial recognition [4], gesture recognition [5], and much more. These systems arebeing implemented by small scale companies/ startups and multi-national corporations like Amazon,Google, and Facebook alike [6]. However, with the rapidly growing influence of all such applications,as researchers and practitioners, we must be wary of all the impending ramifications that may arisein the near or distant future.
In this paper, we draw on the work of Skirpan and Yeh [7] by investigating the Present andspeculating the future of Computer Vision. Time and again, we have been informed about thesocio-technical implications of AI systems: the invasion of users’ privacy, the possibility of securitybreaches, and most commonly, discrimination against individuals belonging to under-representedgroups [8]. In 2018, Buolamwini and Gebru uncovered intrinsic racial and gender bias in facialrecognition services by IBM, Microsoft, and Amazon [9]. More specifically, while these systemshad high overall accuracy; when the researchers analyzed the results by intersectional subgroups ofskin type and gender, these systems performed worst on darker females. Furthermore, CV methodscapable of tracking minority groups are being used for surveillance (guiding police response) whichundermines their privacy and raises questions about discrimination against these groups [10].
By attempting to locate and address the above gender or racial biases individually, we overlookthe social constructs (who creates? who benefits? whom it harms and how?) which determined theseresults in the first place. While we advocate for human-centered AI approaches, we also acknowledgethat policy-level reforms are required to bring about fairness, accountability, and transparency inthese systems. As Eubanks pointed out, ”When automated decision-making tools are not built toexplicitly dismantle structural inequities, their speed and scale intensify them.” [11].
To this end, we suggest a three-pronged approach towards more ethical AI:
• Inclusive AI workplaces: AI reflects the values of its creators. Research has pointed out thatthere exists a feedback loop between the (discriminatory) workplaces and the AI tools theybuild [12]. Tech giants like Google and Facebook have only 10% and 18% of women researchers[13]. By addressing the diversity problem in the AI workforce not just for gender and race, butalso power inequities, we can create systems better suited to operate in high stakes scenarios.
• Questioning data and algorithmic biases: Data lies at the heart of AI systems. This histori-cal data may be incomplete and non-representative of the current social structures. In 2018,Uber suspended the accounts of transgender drivers over a security concern raised by its facialrecognition system [14]. Most of these systems assume a gender binary and have di�cultyidentifying individuals undergoing gender transitions. Researchers and practitioners must en-
⇤Both authors have contributed equally.
1

sure that data collection practices respect the varied demographics and contexts of its users,and address the finer yet invisible issues from diverse vantage points.
• Policy-level reforms: By accepting that the definition of ethics is relative, continually evolv-ing, and repeatedly challenged, we understand that developing a ”perfectly ethical” AI seemsimplausible. In contrast, by placing checks using concrete policy frameworks on data-drivendecision making and in general, AI, we can ensure that power asymmetries don’t reinforce andperpetuate inequality through these systems.
We acknowledge that our interpretation of this line of work is shaped by our educational back-grounds, programming experiences, and personal perspectives. All the authors are of Indian originand are exploring approaches for designing systems for marginalized groups. One author has exam-ined the design of more inclusive mobile applications for low-literate users. One author has workedon developing a learning platform for community health workers. Both authors have experiencedeveloping deep learning AI models for multiple object tracking and super resolution in images.Attending this workshop will allow us to gauge the opportunities and challenges in designing anddeveloping ethical AI systems and participate in discourses related to our areas of research.
References
[1] Alex Krizhevsky, Ilya Sutskever, and Geo↵rey E Hinton. “Imagenet classification with deepconvolutional neural networks”. In: Advances in neural information processing systems. 2012,pp. 1097–1105.
[2] Ian Goodfellow et al. “Generative adversarial nets”. In: Advances in neural information pro-cessing systems. 2014, pp. 2672–2680.
[3] Yuesheng Lu and Michael J Higgins-Luthman. Object detection and tracking system. US Patent8,027,029. Sept. 2011.
[4] Daniel Tranel, Antonio R Damasio, and Hanna Damasio. “Intact recognition of facial expres-sion, gender, and age in patients with impaired recognition of face identity”. In: Neurology38.5 (1988), pp. 690–690.
[5] Sushmita Mitra and Tinku Acharya. “Gesture recognition: A survey”. In: IEEE Transactionson Systems, Man, and Cybernetics, Part C (Applications and Reviews) 37.3 (2007), pp. 311–324.
[6] BA Lauterbach and A Bonim. “Artificial intelligence: A strategic business and governanceimperative”. In: NACD Directorship, September/October (2016), pp. 54–57.
[7] Michael Tom Yeh et al. “Designing a moral compass for the future of computer vision usingspeculative analysis”. In: Proceedings of the IEEE Conference on Computer Vision and PatternRecognition Workshops. 2017, pp. 64–73.
[8] Adrienne Yapo and Joseph Weiss. “Ethical implications of bias in machine learning”. In:(2018).
[9] Joy Buolamwini and Timnit Gebru. “Gender shades: Intersectional accuracy disparities incommercial gender classification”. In: Conference on fairness, accountability and transparency.2018, pp. 77–91.
[10] Chris Buckley and Paul Mozur. How China Uses High-Tech Surveillance to Subdue Minori-ties. May 2019. url: https : / / www . nytimes . com / 2019 / 05 / 22 / world / asia / china -surveillance-xinjiang.html.
2

[11] Virginia Eubanks. Automating inequality: How high-tech tools profile, police, and punish thepoor. St. Martin’s Press, 2018.
[12] Kate Crawford. Artificial Intelligence’s White Guy Problem. June 2016. url: https://www.nytimes.com/2016/06/26/opinion/sunday/artificial- intelligences- white- guy-problem.html.
[13] Nitasha Tiku. Google’s Diversity Stats Are Still Very Dismal. June 2018. url: https://www.wired.com/story/googles-employee-diversity-numbers-havent-really-improved/.
[14] Jaden Urbi. Some transgender drivers are being kicked o↵ Uber’s app. Aug. 2018. url: https://www.cnbc.com/2018/08/08/transgender-uber-driver-suspended-tech-oversight-facial-recognition.html.
3

Ethical Considerations for Adolescent Online Risk Detection AI Systems
Afsaneh Razi University of Central Florida, USA
Seunghyun Kim Georgia Tech, USA
Munmun De Choudhury Georgia Tech, USA
Pamela Wisniewski University of Central Florida, USA
ABSTRACT We seek to develop future Artificial Intelligent (AI) risk detection algorithms to address keeping adolescents safe by providing accurate and customized services to teens and their parents. Training such accurate algorithms needs data of minor which raise ethical challenges. Also, the proper use of such systems is another issue. In this workshop, we hope to gain more insights about possible approaches to address these ethical challenges.
Author Keywords Ethical AI; Online risk detection; Adolescent Online Safety.
CSS Concepts • Human-centered computing~Human computer interaction (HCI)
GRAND ETHICAL CHALLENGES FOR AI ADOLESCENT ONLINE SAFETY Internet and social media use is increasingly deeply intertwined in teens’ lives [11]. Although it provides a great opportunity for teens to learn, it also exposes teens to various online risks [6]. Research has shown that solutions for adolescent online safety are relying more on parental control through device-based restrictions and direct monitoring [3]. The current approaches overwhelm parents with teens’ information which they do not find it useful, and also are privacy-invasive to teens [3, 4]. The reason is current risk detection algorithms do not take the context of online interactions into consideration (e.g. teens using curse words when joking in a group chat is different than using such words directly targeted to someone). Thus, machine learning risk detection algorithms should be optimized to the actual content that parents and teens find it risky. In the future, these optimized systems with the use of AI will help adolescent and their parent have a safe online experience. We have an NSF funded project [7] to improve automated risk detection algorithms using human-centered principles. We plan to commercialize the final solution for an easy-to-use and accessible service for adolescent online risk detection.
Using Teen Data to Create ML Algorithms In our project, we are collecting social media data of teens which includes both their private and public data. Since training with representative data is a big part of making effective classifiers, we need a contextual and in-depth knowledge of adolescent risk behaviors [9, 10]. Current risk detection systems are not taking into consideration the nuance in risk classification when it comes to risky social media content of teens [1, 5]. So, we are using human-
centered approaches and qualitative analysis to develop risks concepts. We aim to label teens social media data for ground truth before developing advanced and automated algorithms for risk detection.
However, the data collected from teens might include sensitive and possibly illegal artifacts, such as sexually explicit images that could be classified as child pornography [8]. These sensitive data pose serious ethical issues for the human-centered approach to building AI risk detection systems. Thus, we need to ensure that our data collection and algorithmic analysis of teen social media data is ethical. We have considered some ways to address these ethical issues. In collecting teens data, not only we obtain parental consent, but also, we get teen assent. We believe it gives teens more sense of authority and control over their data. There is also an intrinsic challenge in the process of collecting the data, since asking the teens to self-identify harassments might result in a recap of those experiences. We make sure to not inflict a time constraint to the participants when collecting data to not possibly overwhelm them with such experiences. For preserving the privacy of the users, we make sure to not publish any of the personally identifiable information or any quotes of their messages that can be retrieved through online search. Also, we convert usernames to randomly generated IDs to protect privacy of teens. Ethics is essential when developing data sharing policies, terms of appropriate use, and licensing agreements for the solutions that result from this project.
Deploying Adolescent Online Risk Detection Algorithms for Good (Not Evil) After the AI system is built, it is important to protect it from the wrong hands. For instance, if there exists a system that can detect minors sexually explicit images, some people can misuse the system and use it as a tool to find sexual images of youth to save it in a porn website or in darknet. Also, the data detected as risky by these systems can be hacked or misused. To combat against the potential reverse engineering of our trained adolescent online risk algorithms [2], the trained algorithms will not be released as open-source. Access privileges to the system should be monitored in order to ensure that only the correct people have the right type of access to the system. Thus, safeguards should be devised to protect the security and privacy of such system and more research should address these challenges.

CONCLUSION We found approaches to address some of the ethical challenges for improving adolescent risk detection systems. As we want to make sure to maintain the confidentiality and privacy of the data and security of the AI system that we design. We hope to gain more insights from participating in the Good Systems: Ethical AI for CSCW to tackle challenges for designing AI systems that can promote online safety for teens.
ACKNOWLEDGMENTS This research is supported by the U.S. National Science Foundation under grant number #IIP-1827700. Any opinion, findings, and conclusions or recommendations expressed in this material are those of the authors and do not necessarily reflect the views of the research sponsors.
REFERENCES [1] Adnan, A. and Nawaz, M. 2016. RGB and Hue Color
in Pornography Detection. Information Technology: New Generations (2016), 1041–1050.
[2] Barreno, M. et al. 2006. Can Machine Learning Be Secure? Proceedings of the 2006 ACM Symposium on Information, Computer and Communications Security (New York, NY, USA, 2006), 16–25.
[3] Ghosh, A.K. et al. 2018. A Matter of Control or Safety?: Examining Parental Use of Technical Monitoring Apps on Teens’ Mobile Devices. Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems (New York, NY, USA, 2018), 194:1–194:14.
[4] Ghosh, A.K. et al. 2018. Safety vs. Surveillance: What Children Have to Say about Mobile Apps for Parental Control. Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems - CHI ’18 (Montreal QC, Canada, 2018), 1–14.
[5] Hosseinmardi, H. et al. 2015. Analyzing Labeled Cyberbullying Incidents on the Instagram Social Network. Social Informatics (Dec. 2015), 49–66.
[6] Livingstone, S. and Helsper, E. 2010. Balancing opportunities and risks in teenagers’ use of the internet: the role of online skills and internet self-efficacy. New Media & Society. 12, 2 (Mar. 2010), 309–329. DOI:https://doi.org/10.1177/1461444809342697.
[7] NSF Award Search: Award#1827700 - PFI-RP: A Multi-Disciplinary Approach to Detecting Adolescent Online Risks.: https://nsf.gov/awardsearch/showAward?AWD_ID=1827700&HistoricalAwards=false. Accessed: 2018-12-21.
[8] Poole, E.S. and Peyton, T. 2013. Interaction Design Research with Adolescents: Methodological Challenges and Best Practices. Proceedings of the 12th International Conference on Interaction Design and Children (New York, NY, USA, 2013), 211–217.
[9] Wisniewski, P. et al. 2016. Dear Diary: Teens Reflect on Their Weekly Online Risk Experiences. Proceedings of the 2016 CHI Conference on Human Factors in Computing Systems (New York, NY, USA, 2016), 3919–3930.
[10] Wisniewski, P. et al. 2015. Resilience Mitigates the Negative Effects of Adolescent Internet Addiction and Online Risk Exposure. Proceedings of the 33rd Annual ACM Conference on Human Factors in Computing Systems (New York, NY, USA, 2015), 4029–4038.
[11] 2018. Teens, Social Media & Technology 2018 | Pew Research Center http://www.pewinternet.org/2018/05/31/teens-social-media-technology-2018/.

Online health communities and AI: Promise and concerns
Yung-Sheng Chang School of Information
The University of Texas at Austin [email protected]
Kolina Koltai School of Information
The University of Texas at Austin [email protected]
After the introduction of Web 2.0, online health communities (OHC), such as social
networking sites, online forums, and group chats, have increasingly become an information source for health consumers to seek and provide information [1]. The motivations for health consumers to visit OHC include seeking social support, first-hand experiences shared by similar others, and providing information out of empathy and altruism [2]. Nevertheless, OHC mostly contains information provided by laypeople. Users may also provide information anonymously, causing a decrease in identity transparency [3]. Thus, the information in OHC is mostly evaluated as lacking objectivity, trustworthiness, and expertise [4]. With the rapid development and implementation of artificial intelligence (AI) in cooperative work environments, we believe AI can help solve some of the existing problems in OHC as AI has already been shown to improve online health communication [5].
AI has the potential to improve information dissemination on OHC. For instance, AI can provide personalized information to health consumers based on their different information needs, goals, and eHealth literacy levels. Since OHC are mostly laypeople participating in the online conversation, it is likely that health consumers may accidentally provide misinformation. Thus, AI may be able to identify misinformation and provide the correct information instead. For some OHC, especially online forums, health consumers can provide information anonymously. However, anonymity is a double-edged sword that can facilitate information providers’ self-disclosure but hinder information seekers’ credibility judgment due to the lack of identity transparency. With AI, it has the potential to leverage the conundrum by allowing information providers to stay anonymous while providing additional information to verify their identity. Lastly, in OHC set up by private companies (e.g. Facebook), AI can affect the availability of online groups. For instance, if a private company wanted to limit OHC for trans-people looking for health advice and information, they could; AI could help find and identify those groups. Private companies are still free to regulate what content is on their platforms and who has access to it. For example, hospitals with religious affiliations have withheld care from patients because it goes against their beliefs, like when abortions are withheld even in life-saving situations.
Despite the beneficial promises that AI may provide, AI can also bring ethical concerns. AI may violate health consumers’ privacy and data rights. For example, there are no regulations on where the health data shared on OHC are stored or who has access. Companies developing AI program are not gaining consent from participants in OHC for their data to be scraped or analyzed to be used with an AI program. Some OHC may have health professionals to help moderate the information. If AI were to be implemented over humans, it could possibly affect health professionals’ autonomy, reputation, and professional status in the community. Companies might try to mine health data from these OHC and use the data against health consumers’ will. On the macro level, health consumers are now having different accesses to digital technologies due to their socioeconomic status and individual characteristics. Since AI relies on online technologies, it may exacerbate the digital divide, leading to an increase in health disparity. AI is an inevitability in OHC, but it will be critical to be conscientious of the ethical concerns that come with it.

Reference [1] O’Kane, A. A., Park, S. Y., Mentis, H., Blandford, A. and Chen, Y. Turning to peers: integrating understanding of the self, the condition, and others’ experiences in making sense of complex chronic conditions. Computer Supported Cooperative Work (CSCW), 25, 6 (2016), 477-501. [2] Zhang, X., Liu, S., Deng, Z. and Chen, X. Knowledge sharing motivations in online health communities: A comparative study of health professionals and normal users. Computers in Human Behavior, 75 (2017), 797-810. [3] Stuart, H. C., Dabbish, L., Kiesler, S., Kinnaird, P. and Kang, R. Social transparency in networked information exchange: a theoretical framework. ACM, City, 2012. [4] Sun, Y., Zhang, Y., Gwizdka, J. and Trace, C. B. Consumer Evaluation of the Quality of Online Health Information: Systematic Literature Review of Relevant Criteria and Indicators. Journal of medical Internet research, 21, 5 (2019), e12522. [5] Neuhauser, L., Kreps, G. L., Morrison, K., Athanasoulis, M., Kirienko, N. and Van Brunt, D. Using design science and artificial intelligence to improve health communication: ChronologyMD case example. Patient education and counseling, 92, 2 (2013), 211-217.

Good Systems: Ethical AI for CSCW -- Position Paper
Izuki Matsuba [email protected]
Integrate.ai
Divya Sivasankaran [email protected]
Integrate.ai
It is indispensable for future AI to have an ability to audit and fix unfairness while securing privacy of users. In the exploration of fixing bias and unfairness in the result of prediction, we found that it is nearly impossible to evaluate the fairness of prediction without exposing each user’s privacy sensitive information such as the one listed above, on which unfair discrimination aligns with. While privacy and prediction performance are usually juxtaposed together as the two factors to balance, our view is that it is an evaluation of fairness which should be considered to stand together with the privacy issue.
Any machine learning model we build is inherently learning to segment the data. Sometimes the data is about equipment in a factory, but in many cases the data is human. That means the point of the model is to divide individuals or populations by some set of attributes. Some of the attributes will be personal or sensitive information, which will rightly trigger privacy concerns. Furthermore, classifying people by these attributes—or others—could cause could cause biased results and lead to unfair impact due to the action taken based on the result.
Attributes are not equal and not all bias is problematic: history and social context matter. The most important fairness issues arise most when segmentation results in negative consequences for members of populations that have long faced systemic disadvantages. Many of these are recorded as protected attributes, for example, gender, socio-economic status, religion, race, and ability status.
Here, we would like to bring an example as a company applying AI technologies to business intelligence domain. One Telco company is trying to actively reach out the customers who are likely to churn from their subscription to provide some support or beneficial treatment. In order to predict which customers are in the risk of cancelling the service, the company consults a third party who is specialized in applying machine learning models to these tasks. However, the Telco company has restrictions on the data to provide as features of the model due to its privacy policy. The third party can still build a model using non person identifiable information, but no longer has an ability to evaluate the fairness of the result despite the fact they are willing to.
We are building a platform to solve the problem in this situation. In some occasions where personal information is not allowed to be used, the platform can still audit the fairness of the prediction result and action taken based on the prediction. Although our AI community is still in a very early stage of this attempt, we strongly believe that the future AI must embody this nature.

Fact-checking: Role of Transparency in Information AccessAnubrata Das
University of Texas at [email protected]
Soumyajit GuptaUniversity of Texas at Austin
Alex BraylanUniversity of Texas at Austin
ABSTRACTMisinformation is a growing area of concern for technologists, jour-nalists, policymakers and the government. In this article we discusshow ethical challenges in AI systems, speci�cally transparency,play a crucial role in battling misinformation by designing anddeveloping fact-checking systems. We seek to answer the broaderquestions we found in some of our current work.
Keywords Fact-checking, Information Retrieval, Transparency
1 INTRODUCTIONInformation Retrieval (IR) systems play a crucial role as a mediumof information access. For a majority of users, these search enginesare the primary information system to a�rm the veracity of in-formation (Fact Checking). The impact of search engines extendbeyond the digital world and can in�uence the social and politicalchoices of the public. For example, Epstein and Robertson [7] showthat manipulated search engine results can shift voting opinion ofup to 20% of users.
While interacting with search engines, users have no visibilityinto the mechanisms governing the ranking of results or the tailor-ing to the speci�c user’s search patterns. Transparency in IR canempower users to make better decisions. In this article, we explorethe transparency aspect of search systems and how it is relevant inthe context of fact-checking.
Research Questions. The complex issue of misinformation re-quires a multidisciplinary approach. However, information accessis at the core of the problem and interests all disciplines such an in-formation, communication ,and computer science. We are primarilyinterested in the questions: RQ1 How transparency of InformationAccess systems a�ect users’ trustworthiness for a fact-checkingscenario? RQ2 How are Information Access systems used for fact-checking?2 RELATEDWORKSIR systems are one of the most used form of information accesssystems in terms of seeking information online and have directin�uence on user opinion formation.
Political In�uence. Studies show that candidate selection for apolitical scenario can be in�uenced by search engines [6], and thatsimple manipulation of search results can change voting choicesin undecided voters [7]. Employing a ‘Wizard of Oz’ experiment,Epstein and Robertson [7] show that through communication ofexisting biases in the system, it is possible to lower the in�uence ofthese biases on the users’ decision-making process. Additionally,biases in social media systems can emerge from both the dataused to training and design of algorithms [8]. In the context of thepresidential primaries in 2016, a study [8] show that 70% of thetime top contents in systems like Twitter and Google matches theuser’s own political biases. Using a source-based bias-quanti�cationframework led to balanced and less biased results in such systems.
Transparent IR for Fact Checking. IR systems are at the coreof fact-checking toolkits. Both in IR system research and human-centered IR, misinformation brings new challenges in terms ofretrieval, representation, interaction, and evaluation [9]. Ensur-ing topical diversity and political diversity in the search results isanother challenge for IR systems. In recent literature of IR, NLP,and HCI, researchers are employing various methodologies to buildfact-checking systems. Cross-referencing di�erent sources and spec-ifying those sources to the user for establishing credibility in newsarticles is an e�ective interaction design technique [1]. Commu-nicating the reputation of di�erent news sources improves users’trust in fact-checking systems [11, 13]. In addition to predictionmodels for detecting false claims, it is also important to provideusers with controls for model parameters for interpretation in orderto gain users’ trust [11, 14]. Highlighting important informationfrom a news article supporting or refuting a claim help users injudging the veracity of claims. Other important additions to thefact-checking research are argument mining [15], re-ranking ofsources and stance detection [10].3 DISCUSSIONFact-checking using computational techniques has the potential toincorporate and amplify existing biases in society. Such systemscan, in turn, manipulate users’ socio-political decision making. IRsystems can establish credibility in fact-checking when they are fair,free of biases, and interpretable by non-expert users. Looking backto our research questions, we can say that intelligent systems suchas search engines can potentially provide a toolbox for fact-checkingwhen they are unbiased and transparent. We see a common themeof methodology: interpretable machine learning. We argue thatinstead of high-accuracy black box models, interpretable modelsand visualizations are the keys to building reliable decision supportsystems in the context of fact-checking.
The directions we envision are three fold: 1) Developing Trans-parent IR algorithms for fact checking. 2) Designing interfaces thatenable an unbiased representation of retrieved content. 3) Eval-uating the e�ectiveness of these algorithms and interfaces. Jointexpertise from the �eld of HCI, IR and Journalism are required inorder to address these issues.
We conclude by mentioning some of our ongoing research whichfocuses on two aspects. First, we develop a user interface to com-municate the e�ect of user bias while the user is engaged in a claimchecking activity [3–5, 12]. We show that communicating user biasenables the user in making a better judgment toward the veracity ofa claim. Second, we develop a framework to evaluate the presenceof ideological bias of a ranking system. Given a known target dis-tribution of political ideologies, we estimate a ranking distributionand identify the di�erence between the estimated ranking distribu-tion and target distribution [2]. Finally, as future work, we aim todevelop human-in-the-loop evaluation techniques for measuringtransparency and e�ectiveness of IR systems in fact-checking.

Anubrata Das, Soumyajit Gupta, and Alex Braylan
REFERENCES[1] Dimitrios Bountouridis, Monica Marrero, Nava Tintarev, and Claudia Hau�. 2018.
Explaining Credibility in News Articles using Cross-Referencing. In Proceedingsof the 1st International Workshop on ExplainAble Recommendation and Search(EARS 2018). Ann Arbor, MI, USA.
[2] Anubrata Das and Matthew Lease. 2019. A Conceptual Framework for EvaluatingFairness in Search. arXiv preprint arXiv:1907.09328 (2019).
[3] Anubrata Das, Kunjan Mehta, and Matthew Lease. 2019. CobWeb: A ResearchPrototype for Exploring User Bias in Political Fact-Checking. arXiv preprintarXiv:1907.03718 (2019).
[4] Anubrata Das, KunjanMehta, andMatthew Lease. 2019. Interpretable fact checkerwith user bias indicator. http://anubrata.pythonanywhere.com/biastask2/
[5] Anubrata Das, Kunjan Mehta, and Matthew Lease. 2019. Presenta-tion on interpretable fact checker with user bias indicator. https://docs.google.com/presentation/d/17Px--Lp50Os95QVfuH6auGzdaZReM-CWjuGnDJVQDG8/edit?usp=sharing
[6] Nicholas Diakopoulos, Daniel Trielli, Jennifer Stark, and Sean Mussenden. 2018. IVote For—How Search Informs Our Choice of Candidate. Digital Dominance: ThePower of Google, Amazon, Facebook, and Apple, M. Moore and D. Tambini (Eds.) 22(2018).
[7] Robert Epstein and Ronald E Robertson. 2015. The search engine manipulatione�ect (SEME) and its possible impact on the outcomes of elections. Proceedingsof the National Academy of Sciences 112, 33 (2015), E4512–E4521.
[8] Juhi Kulshrestha, Motahhare Eslami, Johnnatan Messias, Muhammad Bilal Zafar,Saptarshi Ghosh, Krishna P. Gummadi, and Karrie Karahalios. 2018. Searchbias quanti�cation: investigating political bias in social media and web search.Information Retrieval Journal 22 (2018), 188–227.
[9] Matthew Lease. 2018. Fact Checking and Information Retrieval. In DESIRES.[10] Moin Nadeem, Wei Fang, Brian Xu, Mitra Mohtarami, and James Glass. 2019.
FAKTA: An Automatic End-to-End Fact Checking System.[11] An T Nguyen, Aditya Kharosekar, Saumyaa Krishnan, Siddhesh Krishnan, Eliza-
beth Tate, Byron CWallace, and Matthew Lease. 2018. Believe it or not: Designinga human-AI partnership for mixed-initiative fact-checking. In The 31st AnnualACM Symposium on User Interface Software and Technology. ACM, 189–199.
[12] An T Nguyen, Aditya Kharosekar, Saumyaa Krishnan, Siddhesh Krishnan, Eliza-beth Tate, Byron C Wallace, and Matthew Lease. 2018. Interpretable fact checker.http://fcweb.pythonanywhere.com/
[13] An T Nguyen, Aditya Kharosekar, Matthew Lease, and Byron Wallace. 2018. Aninterpretable joint graphical model for fact-checking from crowds. In Thirty-Second AAAI Conference on Arti�cial Intelligence.
[14] Kashyap Popat, Subhabrata Mukherjee, Jannik Strötgen, and Gerhard Weikum.2018. CredEye: A credibility lens for analyzing and explaining misinformation.In Companion Proceedings of the The Web Conference 2018. International WorldWide Web Conferences Steering Committee, 155–158.
[15] Christian Stab, Johannes Daxenberger, Chris Stahlhut, Tristan Miller, BenjaminSchiller, Christopher Tauchmann, Ste�en Eger, and Iryna Gurevych. 2018. Argu-menText: Searching for Arguments in Heterogeneous Sources. In NAACL-HLT.

Position Paper Submitted to Workshop 10 of the 22nd ACM Conference on Computer-Supported Cooperative Work and Social Computing, Good Systems: Ethical AI for CSCW
Communication Design to Navigate the Future of Work and Artificial Intelligence
Joshua B. Barbour, Shelbey L. Rolison, Jared T. Jensen; University of Texas at Austin; [email protected]
Forecasting the future of advancements in artificial intelligence (AI) has captured the public sphere particularly as it relates to automation and the future of work (Brynjolfsson & McAfee, 2016; Lepore, 2019; Mukherjee, 2017). The mix of hype and anxiety will be familiar to scholars of the history of technology, but predicting what will, could, or should be the future of work and AI is nonetheless an important endeavor (Stone et al., 2016). However, because of the difficulty and fallibility of such prognostications, attention should also be given to societal resources for navigating the opportunities and challenges of AI and automation as they unfold. Because so much of this technological change will be negotiated by workers, society must also understand how to empower the effective design of organizational communication processes for deliberating about the development and implementation of AI and automation.
The focus on work and workers is important too because new technologies of work can transform it in ways that obscure the transformation as it happens (Leonardi, 2012; Sennett, 2009). The process of automating work also generates information about the work being automated, and the ongoing operation of data-intensive automation also generates a flow of information about the work being done (Zuboff, 1988). The datafication of work and AI may heightens the reach and scope of its ongoing transformation (Brynjolfsson & McAfee, 2016). At its core though, automation transforms work, because changes in the technologies and organization of work are intertwined (Bailey & Leonardi, 2015); and these changes unfold in and through organizational communication (Barbour, Treem, & Kolar, 2018; Leonardi, 2012)
Key questions center on how to shape the communication through which the automation of work occurs and how to cultivate preferred forms of communication. These are questions of collective communication design (Barbour, Gill, & Barge, 2018), or efforts to grapple with the puzzle of “how to make communication possible that was once difficult, impossible or unimagined” (Aakhus, 2007, p. 112). Important communicative phenomena in the intertwined transformation of technology and work include (a) information seeking about new the technologies, (b) “benchmarking” or co-workers’ questions about technology and how to use it, and (c) “technical teaching” or interactions with designers and technologists especially related to how technologies work in practice, (d) rhetorical framing and pitching of new technologies, and (e) policy-focused deliberations in the decision making about what technologies to implement and how to do so (Leonardi, 2012).
The Automation Policy and Research Organizing Network (APRON, https://www.apronlab.org) aims to advance the communicative study of the future of work by researching (a) how technology, organizations, and work change together and (b) the datafication and automation of work. The current research of the APRON Lab includes multiple empirical projects in the context of health and healthcare work. We look forward to the workshop as an opportunity to inform and improve this scholarship.
Funding Acknowledgement This material is based upon work supported by the National Science Foundation under Grant No. SES-1750731.

References
Aakhus, M. (2007). Communication as design. Communication Monographs, 74, 112-117. doi:10.1080/03637750701196383
Bailey, D. E., & Leonardi, P. M. (2015). Technology choices: Why occupations differ in their embrace of new technology. Cambridge, MA: The MIT Press.
Barbour, J. B., Gill, R., & Barge, J. K. (2018). Organizational communication design logics: A theory of communicative intervention and collective communication design. Communication Theory, 28, 332-353. doi:10.1093/ct/qtx005
Barbour, J. B., Treem, J. W., & Kolar, B. (2018). Analytics and expert collaboration: How individuals navigate relationships when working with organizational data. Human Relations, 71, 256-284. doi:10.1177/0018726717711237
Brynjolfsson, E., & McAfee, A. (2016). The second machine age: Work, progress, and prosperity in a time of brilliant technologies. New York, NY: W.W. Norton & Company.
Leonardi, P. M. (2012). Car crashes without cars: Lessons about simulation technology and organizational change from automotive design. Cambridge, MA: MIT Press.
Lepore, J. (2019). Are robots competing for your job? Probably, but don’t count yourself out. The New Yorker. Retrieved from https://www.newyorker.com/magazine/2019/03/04/are-robots-competing-for-your-job
Mukherjee, S. (2017). A.I. Versus M.D.: What happens when diagnosis is automated? The New Yorker. Retrieved from https://www.newyorker.com/magazine/2017/04/03/ai-versus-md
Sennett, R. (2009). The craftsman. New Haven, CT: Yale University Press. Stone, P., Brooks, R., Brynjolfsson, E., Calo, R., Etzioni, O., Hager, G., . . . Teller, A. (2016). "Artificial
Intelligence and Life in 2030." One Hundred Year Study on Artificial Intelligence: Report of the 2015-2016 Study Panel. Retrieved from Stanford, CA: http://ai100.stanford.edu/2016-report
Zuboff, S. (1988). In the age of the smart machine: The future of work and power. New York, NY: Basic Books.

AI Ethics, Autonomous AI Machines and Global Capitalist Society CSCW 2019 Position Paper
Ramon Diab, PhD Candidate Western University Faculty of Information and Media Studies (FIMS) Library and Information Science Program London, Ontario, Canada [email protected]

The technical capabilities of advanced artificial intelligence (AI) has generated approaches to AI ethics that consider the implications of the elevation of machine actions and decisions over human actions and decisions. Current AI ethical considerations tend to focus on the potential of AI machines to take control of society, to enact human biases, , , to enact operations that such machines were not programmed to 1 2 3 4
operationalize, or to enact operations as programmed with unintended consequences. , AI ethics tend to 5 6 7
focus on the development and embodiment of ethical and legal standards in AI machines during the design phase of AI development and/or the analysis of the consequences of either human-controlled AI or autonomous AI machines. However, the broader historical development of AI ethics has emerged with the historical development of the social forms, relations, institutions and the legal and political superstructure of the state. Current AI ethics therefore abstracts from a critique of the private ownership and development of AI machines within the relation of labour to owners of the means of production and the representatives of the state. The resolution of ethical dilemmas and the secure and safely-controlled development of AI is therefore necessary but insufficient for a broader historical analysis of the implications of the development of AI machines within the global capitalist economy. Thus the use of AI 8
as an instrument of capital, bourgeois institutions and the legal and political superstructure of the state should become an object of critique.
The production and implementation of AI machines within the relations of global capitalist society holds significant implications for the future of work and class. With the historical development of autonomous AI machines at the point of production, the reduction or elimination of the relation of capital to labour-power, and the reduction or elimination of the relation of labour-power to consumer leads to the autonomization of the capitalist mode of production, and thus, to the development of the direct relation of 9
consumers to autonomous AI machines. In the short-term, the development of autonomous commodity production and circulation contains implications for unemployment, wealth inequality, the global reproduction of class, and subsequent social and political responses to the uneven nature of global AI-powered capitalist development. In the long-term, the total replacement of labour-power with machine-10
power holds significant implications for the relation of labour to capital that is the foundational relation of the capitalist mode of production. , Further, the advanced development and implementation of AI 11 12
machines within the relations of the political and legal superstructure of the state holds implications for the expanded reproduction of the private ownership of the means of production, , the private prison-13 14
industrial system , and the means of warfare. Alternatively, a critique of the bourgeois form of AI 15 16 17
development could advance concepts of common ownership and the socialized development of AI as a means of advancing an autonomous mode of production that leads to the abolition of labour-power, the equal distribution of the social product, the dissolution of class and the dissolution of the state.
See Hutan Ashrafian, “Intelligent Robots Must Uphold Human Rights,” Nature 519 (March 26, 2015): 391. 1
See Cynthia Weber, “Engineering Bias in AI,” IEEE Pulse (January/February 2019). https://pulse.embs.org/january-2019/engineering-bias-in-ai/2
See Ludovic Righetti, Raj Madhavan, and Raja Chatila, “Unintended Consequences of Biased Robotic and Artificial Intelligence Systems,” IEEE Robotics and Automation (September 3
2019): 11-13. doi:10.1109/MRA.2019.2926996
See Anjanette H. Raymond, Emma Arrington Stone Young and Scott J. Shackelford, “Building a Better HAL 9000: Algorithms, the Market, and the Need to Prevent the Engraining of Bias,” 4
Northwestern Journal of Technology and Intellectual Property 15 No. 3 (2018): 215-254. https://scholarlycommons.law.northwestern.edu/njtip/vol15/iss3/2
See Patrick Lin, Keith Abney and George Bekey, “Robot Ethics: Mapping the Issues for a Mechanized World,” Artificial Intelligence 175 (2011): 942-949. doi:10.1016/j.artint.2010.11.026 5
See Paula Boddington, Towards a Code of Ethics for Artificial Intelligence (Springer, 2017), 96, 130-131.6
See Steve G. Sutton, Vicky Arnold and Matthew Holt, “How Much Automation is Too Much? Keeping the Human Relevant in Knowledge Work,” Journal of Emerging Technologies in 7
Accounting 15 No. 2 (Fall 2018): 15-25. doi:10.2308/jeta-52311
Kate Crawford and Ryan Calo, “There is a Blind Spot in AI Research,” Nature 538 (October 20, 2016): 311- 313. On this point, see Crawford and Calo’s analysis and of AI ethics and their call 8
for a social systems analysis of AI machines.
See Simon Schaupp and Ramon Diab, “From the Smart Factory to the Self-Organisation of Capital: ‘Industrie 4.0’ as the Cybernetisation of Production,” ephemera http://9
www.ephemerajournal.org/contribution/smart-factory-self-organisation-capital-‘industrie-40’-cybernetisation-production
See Carl Benedikt Frey and Michael A. Osborne, “The Future of Employment: How Susceptible are Jobs to Computerisation?” (2013):1-72. http://dx.doi.org/10.1016/j.techfore.2016.08.019.10
See Karl Marx, Grundrisse, (Penguin, 1993): 690-712. Kindle.11
See Kathleen Richardson, “Rethinking the I-You Relation Through Dialogic Philosophy in the Ethics of AI and Robotics,” AI and Society 34 (2019): 1-2. doi: 10.1007/s00146-017-0703-x 12
Karl Marx and Frederick Engels, The Germany Ideology, (London: Lawrence and Wishart, 2007): 79-86.13
See Bob Jessop, The Capitalist State: Marxist Theories and Methods. (Oxford: Martin Robertson, 1982). An analysis of Marx’s writings on the state. 14
David Theo Goldberg, “Surplus Value: The Political Economy of Prisons,” The Review of Education/Pedagogy/Cultural Studies 21 no. 3 (1999): 247-263. 15
See Stephan Raaijmakers, “Artificial Intelligence for Law Enforcement: Challenges and Opportunities,” IEEE Security and Privacy 17 No. 5 (2019), 74-77. doi:10.1109/MSEC.2019.292564916
See Thibault de Swarte, Omar Boufous and Paul Escalle, “Artificial Intelligence, Ethics and Human Values: The Cases of Military Drones and Companion Robots,” Artificial Life and Robotics 17
24 (2019): 291-296. doi:10.1007/s10015-019-00525-1

THE ETHICAL IMPLICATIONS OF THE USE OF MATHEMATICAL MODELS AND
ALGORITHMS IN CREW SCHEDULING FOR LONG HAUL TRAVEL
Lore Benson, MSIS Candidate
University of Texas at Austin

Background
In the growing industry of long haul travel, companies are expanding their crews to gather
more market shares. As these companies seek more growth, the complexity of crew and route
scheduling programs have increased in size and complexity. Scheduling crew, specifically, is one
of the major planning problems in the travel industry. To mitigate that, companies have now
begun to lease software that use intense mathematical models and algorithms to schedule their
crews (Devechi, 2018).
While this has expedited the scheduling process, the argument arises that companies are now
treating their crews as data sets instead of human beings. These methods of scheduling are built
on optimization, the aim being that the company’s profit outweighs the operation spending.
Currently, the algorithms do not account for crew health. This becomes an ethical conundrum.
What are the ethical implications of the use of these scheduling optimization algorithms?
Aims
The aim of this project is to:
A) Understand the mathematical models used to schedule crew in the Airline industries
B) Research the physical consequences (positive or negative) that crews undergo due to
their current schedules
C) Examine the ethical violations of relying on the methods used for crew scheduling, if any
D) Propose future directions of scheduling algorithms used in this context
Methodology
This project will collect and analyze a mix of quantitative data — in the form of algorithms,
routes and schedules used currently, and qualitative data in the form of interviews from crew

members and scheduling analysts from the Airlines. Not only that but we will also be
hypothesizing and suggesting ethical recommendation based on collected literature.
Expected Outcomes
It is expected that when considering the ethical implications of using optimized algorithms to
schedule crew, that violations and conflicts will arise. This is important because, while we
cannot stop the growth of the transit industry, we can ensure that later iterations of new software
will be designed with the ethical treatment of crew in mind.

“THE FUTURE OF AI IS NOT GOOGLE-ABLE”
(Gibson, 2004)
Nasim Motalebi Saeed Abdullah The Pennsylvania State University,
University Park, PA [email protected]
The Pennsylvania State University, University Park, PA
Only a hard-deterministic (Adler, 2008) explanation of technology can assume a known outcome of what technologies can offer in terms of social realities and social change. However, the complexities of socio-technical systems imply that the future is unknown; as it is contingent upon the context of technological development, deployment, and systems of use (Winner, 1986). This contingency is at odds with a utopian/dystopian view of autonomous technologies.
Technology is neither utopian, nor dystopian. The social and economic system in which technologies are embedded, determine social evolution and technological impact at any given moment in history. Technologies can shape social visions of enchantment and liberation. But they can also facilitate a social order that is relentlessly harsh, destructive, and miserable for a majority of people (King, 1996). In the late 60bs and early 70bs the idea of AI and autonomous technologies brought hope for social freedom; envisioning societies so advanced that labor and work would be eliminated. The Fun Palace by Cedric Price (Price, 1968) or the Walking Cities by Archigram (Stiener, 2013) are examples of utopian cravings which incentivized rebellious and anarchist movements at the time. On the other hand, communication technologies were critiqued for subjugating societies for spreading consumer culture: mass media was now responsible for class alienation, cultural homogenization, and replacing social relations with mere representation as part of commercialization effects (Debord, 1967). Such contradictory effects of technologies are recurring in the history of social evolution.
As technology becomes more and more intertwined with the society, it is necessary to collaborate with the public to develop and transform technologies for all groups and services in both micro and macro levels. For example, while AI systems provide autonomy and freedom, their development must be questioned to prevent social biases and negative effects in the future. Expanding the possibilities of future autonomous and robotic systems highly relies on understanding and responding to society’s needs, expectations, and mental models toward AI-systems. Imagined affordances of technological artifacts are constantly redefined through the interplay of agency between people and technologies; the quality and context of which can impact the direction of technological development. Therefore, for technologies to reach their full potential- for the better- it is essential to design interactions which are transparent, provide agency to their users, and create trust towards technologies.
Transparency, agency, and trust are the building blocks to create an Ethical AI. However, lack of definitions and loose policies regarding this concept is slowly diminishing reliability and intimacy with AI-systems. Hopefully, a conversation over the dangers of autonomous technological development, and methods to which public debate and protest could affect the design, diffusion, use, and regulation of autonomous technologies, could open paths for developing a more beneficial AI.

Bibliography
Adler, P.S. Technological determinism in. Clegg, S., & Bailey, J. R. (Eds.). (2007). International encyclopedia of organization studies. Sage Publications.
Contributors to Wikimedia projects. 2019. American-Canadian speculative fiction novelist and founder of the cyberpunk subgenre. (May 2019). Retrieved September 30, 2019 from https://en.wikiquote.org/wiki/William_Gibson
Debord, G. (1992). The society of the spectacle. 1967. Paris: Les Éditions Gallimard.
Kling, R. (1996). Hopes and Horrors: Technological Utopianism and Anti-Utopianism in Narratives of. Computerization and controversy: Value conflicts and social choices, 40.
Price, C., & Littlewood, J. (1968). The fun palace. The Drama Review: TDR, 127-134.
Steiner, H. A. (2013). Beyond Archigram: The structure of circulation. Routledge.

Autonomous Tools and Delegation Jeffrey V. Nickerson
Stevens Institute of Technology
There is little to admire in AI systems whose main goal is surveillance. These systems
capture traces of both digital and physical behavior and makes guesses about the future
behavior of humans in order to control or take advantage of this behavior [6]. Such AI systems
can nudge votes, purchases, and associations between people. They can instigate disruptions
in society. They can do this because they can see the networks and collective behaviors that
individuals can’t see. That is, aggregated data permit inferences and actions that are beyond
the scope of what an individual can see or affect. Larger stores of data and larger compute
farms lead to more effective surveillance, which in turn leads to more effective prediction and
behavior modification.
Another path that AI is following positions AI as tools rather than as systems. These tools
are granted some degree of autonomy, but ultimately are managed by humans, who not only
delegate but also monitor the tools. Take, for example, bots in Wikipedia [5]. They generate
knowledge. They act on their own. But they have human operators who are responsible for their
behavior. In a similar fashion, video game designers use autonomous tools to generate game
landscapes and chip designers use autonomous tools to generate layouts [3]. Many of the issues we confront in AI have been studied in management. They involve the
functions of the executive. That is, we as humans are building machines that can act
autonomously. These machines need to be trained. They can be delegated to, but, as with any
delegation situation, there is an obligation to monitor and correct. Principles of management
apply [1, 4]. But there are new issues. Humans and machines have different embodiments [2]. We need new modes of delegation and monitoring to take into account differences in the speed
and nature of processing that takes place in autonomous tools and their managers. For
example, very fast decision-makers need very fast monitors, and these monitors may need to be
machines. Thus managers become collectives of humans and machines.
References
[1] Barnard, C.I. 1968. The Functions of the Executive . Harvard University Press.
[2] Lawrence, N.D. 2017. Living Together: Mind and Machine Intelligence. arXiv [cs.AI]. [3] Seidel, S., Berente, N., Lindberg, A., Lyytinen, K. and Nickerson, J.V. 2019. Autonomous
Tools and Design: A Triple-loop Approach to Human-machine Learning. Communications of
the ACM. 62, 1 (2019), 50–57.
[4] Simon, H.A. 1997. Administrative Behavior (4th expanded edition; 1947). The Free Press,
NY.
[5] Zheng, L. N., Mai, F., Albano, C. M., Vora, N. and Nickerson, J. V. 2019. The Role Bots
Play in Wikipedia. Proceedings of the ACM: Human-Computer Interaction . 3, CSCW
(2019).
[6] Zuboff, S. 2019. The age of surveillance capitalism: The fight for a human future at the new
frontier of power. Profile Books.

Samuel Woolley Assistant Professor School of Journalism University of Texas at Austin Innovation in the artificial intelligence space has been propelled by an ethos of progress and growth at the expense of the consideration of ethics, democratic values and human rights. As companies like Facebook, Twitter and YouTube have expanded their use of machine learning (ML) algorithms in prioritizing information for users, but also in allowing programmers to interact with APIs by way of personally generated AI-enabled software, they have opened up global publics to automated manipulation and surveillance. Both technology firms and governments have failed to effectively protect user’s privacy in an era where individual ad targeting—scaffolded by AI software—has extended to spheres political and personal. Meanwhile, AI and ML are presented by tech executives, including Mark Zuckerberg in his hearings before congress, as a cure-all “McGuffin” to the problems associated with mis- and dis- information and state-sponsored computational propaganda. Undoubtedly, AI will play a crucial future role in detecting and mitigating these problems at scale. At present, however it is unclear how or whether these systems will serve to protect rather than transgress. Alongside game designer and author Jane McGonigal, and with the support and collaboration of Omidyar Networks and the Institute for the Future, I have designed the Ethical Operating System (ethicalos.org). The Ethical OS is a guide to anticipating the future impact of today’s technology. In building this toolkit, we specifically focused upon technology designers and questions at the heart of innovation in AI. We identify eight risk zones (see graphic below) associated with the current state of design thinking in tech sector: 1) truth, disinformation, propaganda, 2) addiction and the dopamine economy, 3) economic and asset inequalities, 4) machine ethics and algorithmic biases, 5) surveillance state, 6) data control and monetization, 7) implicit trust and user understandings, and 8) hateful and criminal actors. Undoubtedly, there is cross-over between these groups but we feel that the risk zones together, along with the larger Ethical OS framework, provide a starting point for asking crucial questions when building new AI technology or amending old systems. I believe the insights developed while constructing the Ethical OS, as well as ideas from my broader work on computational propaganda and emergent technologies, would be useful and provocative additions to the Good Systems: Ethical AI for CSCW workshop. The Ethical OS Toolkit is now being used by numerous large tech firms, start-ups, incubators and venture-capital firms. It has been taught in computer and information science courses at Stanford, UC Berkeley and the University of Texas at Austin as well as through MOOC courses (also through Stanford). I believe what we’ve learned in the course of our active and ongoing research will serve to undergird the insights of other researchers at this CSCW workshop. Ultimately, I hope to use this toolkit and my prior research to argue that the future of AI can be made more hopeful if we begin to design technology with human rights—and other tenants of democracy—in mind today.
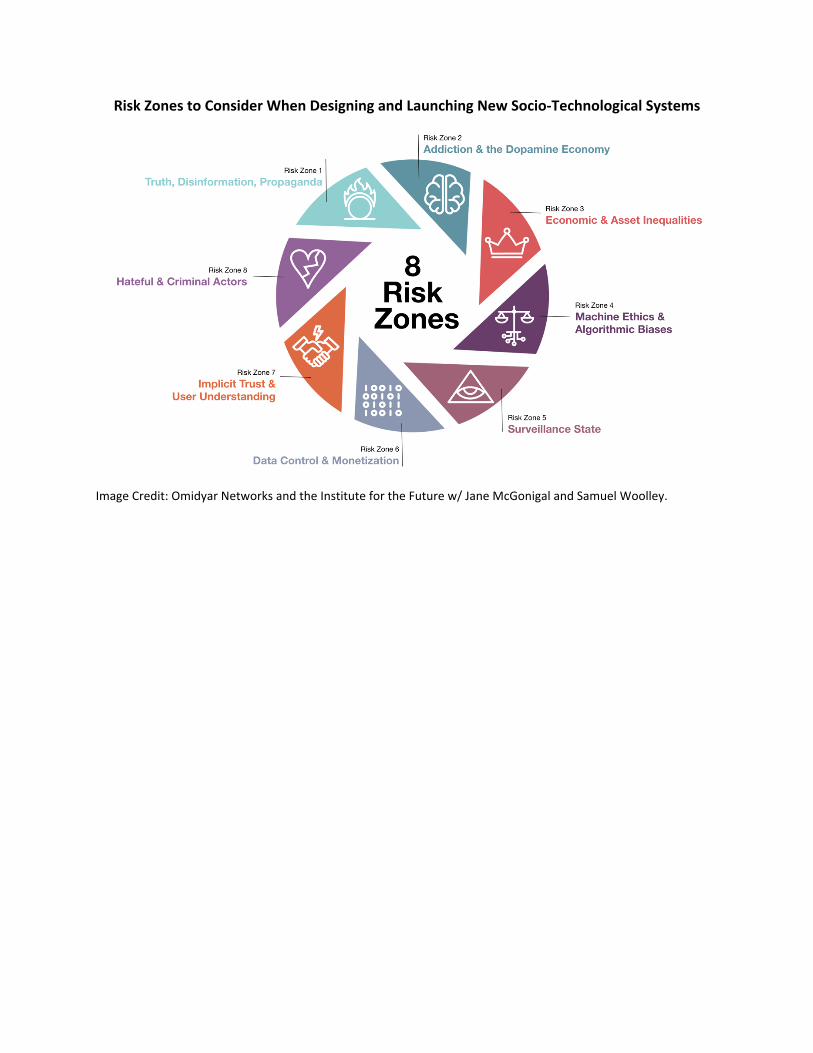
Risk Zones to Consider When Designing and Launching New Socio-Technological Systems
Image Credit: Omidyar Networks and the Institute for the Future w/ Jane McGonigal and Samuel Woolley.