running a hadoop application locally in windows
TRANSCRIPT

ACADGILDACADGILD
Let us learn running a Hadoop application locally in Windows. Here we will be running aHadoop Mapreduce word count program in Windows. For doing this, you need to downloadand extract Hadoop tar file.
In this post, we have used Hadoop-2.6.0 version. You can use the later versions as well.
You can download Hadoop-2.6.0 tar file from the below link
https://drive.google.com/open?id=0B1QaXx7tpw3SQUw5QkpYNTN2UGc
After downloading, extract the tar file. Now you will be able to see a folder called hadoop-2.6.0 in the extracted directory.
Let's quickly run a program.
Open your Eclipse and create a new Java program.
https://acadgild.com/blog/?p=18702&preview=truehttps://acadgild.com/blog/?p=18702&preview=true

ACADGILDACADGILD
https://acadgild.com/blog/?p=18702&preview=truehttps://acadgild.com/blog/?p=18702&preview=true

ACADGILDACADGILD
Here after clicking on the New Java project, it will ask for the project name as shown in thebelow screen shot. Give a project name. Here we have given the project name asWord_count.
https://acadgild.com/blog/?p=18702&preview=truehttps://acadgild.com/blog/?p=18702&preview=true

ACADGILDACADGILD
Now after giving the project name, a project will be created with the given name. Click on theproject and inside the project you will find a directory called src. Right click and create newclass as shown in the below screen shot.
https://acadgild.com/blog/?p=18702&preview=truehttps://acadgild.com/blog/?p=18702&preview=true

ACADGILDACADGILD
Now you will be prompted with another screen to provide the class name as shown in thebelow screen shot.
https://acadgild.com/blog/?p=18702&preview=truehttps://acadgild.com/blog/?p=18702&preview=true

ACADGILDACADGILD
Here, give the class name of your choice. We have given the name as WordCount. Insidethe src a file with name WordCount.java has been created. Click on the file and write theMapReduce code for the word count program.
https://acadgild.com/blog/?p=18702&preview=truehttps://acadgild.com/blog/?p=18702&preview=true

ACADGILDACADGILD
import java.io.IOException;import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.Mapper;import org.apache.hadoop.mapreduce.Reducer;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1); private Text word = new Text();
public void map(Object key, Text value, Context context ) throws IOException, InterruptedException { StringTokenizer itr = new StringTokenizer(value.toString()); while (itr.hasMoreTokens()) { word.set(itr.nextToken()); context.write(word, one); } } }
public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable> { private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context ) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) { sum += val.get(); } result.set(sum);
https://acadgild.com/blog/?p=18702&preview=truehttps://acadgild.com/blog/?p=18702&preview=true

ACADGILDACADGILD
context.write(key, result); } }
public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); Job job = Job.getInstance(conf, "word count"); job.setJarByClass(WordCount.class); job.setMapperClass(TokenizerMapper.class); job.setCombinerClass(IntSumReducer.class); job.setReducerClass(IntSumReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); System.exit(job.waitForCompletion(true) ? 0 : 1); }}
After copying the code save the file. Now you need to add a few dependency files for runningthis program in Windows.
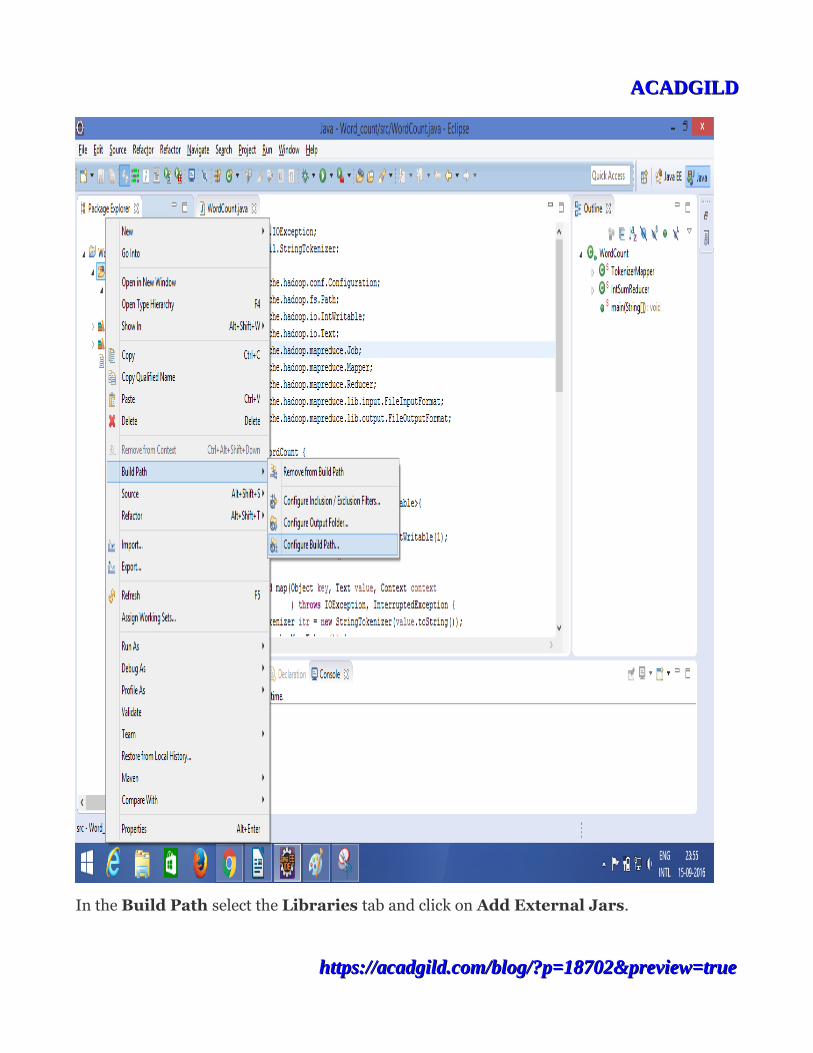
First we need to add the jar files that are present in hadoop-2.6.0/share/hadoop directory. For that Righ click on src-->Build path-->Configurebuild path as shown in the below screen shot.
https://acadgild.com/blog/?p=18702&preview=truehttps://acadgild.com/blog/?p=18702&preview=true
ACADGILDACADGILD
In the Build Path select the Libraries tab and click on Add External Jars.
https://acadgild.com/blog/?p=18702&preview=truehttps://acadgild.com/blog/?p=18702&preview=true

ACADGILDACADGILD
Now browse the path where the Hadoop-2.6.0 extracted folder is present.
Here go to hadoop-2.6.0/share/hadoop/common folder and then add the hadoop-common-2.6.0.jar file
And then open the lib folder and here add the
Commons-collections-3.2.1.jar
Commons-configuration-1.6.jar
Commons-lang-2.6.jar
Commons-logging-1.1.3.jar
guava-11.0.2.jar
Jackson-core-asl-1.9.13.jar
jackson-jaxrs-1.9.13.jar
jackson-mapper-asl-1.9.13.jar
log4j-1.2.17.jar files
Open the hadoop-2.6.0/share/hadoop/mapreduce folder and add the below specifiedjar files
hadoop-mapreduce-client-common-2.6.0.jar
hadoop-mapreduce-client-core-2.6.0.jar
hadoop-mapreduce-client-jobclient-2.6.0.jar
hadoop-mapreduce-client-shuffle-2.6.0.jar
Open the hadoop-2.6.0/share/hadoop/yarn folder and add the below specified jar files
hadoop-yarn-api-2.6.0.jar
hadoop-yarn-client-2.6.0.jar
hadoop-yarn-common-2.6.0.jar
Open the hadoop-2.6.0/share/hadoop/hdfs/lib folder and add the commons-io-2.4.jar file
Open the hadoop-2.6.0/share/hadoop/tools/lib and add the hadoop-auth-2.6.0.jar file
https://acadgild.com/blog/?p=18702&preview=truehttps://acadgild.com/blog/?p=18702&preview=true

ACADGILDACADGILD
You need to download two extra jar files. Download them from the below drive link
https://drive.google.com/open?id=0ByJLBTmJojjzU0VJeHJsOExBQmM
Download the two jar files from the below link and add those two jars also. The final list ofdependencies will be as shown in the below screen shot.
https://acadgild.com/blog/?p=18702&preview=truehttps://acadgild.com/blog/?p=18702&preview=true

ACADGILDACADGILD
That's it all the set up required for running your Hadoop application in Windows. Make surethat your input file is ready.
Here we have created our input file in the project directory itself with the name inp as shownin the below screen shot.
For giving the input and output file paths, Right click on the main class-->Run As-->Run configurations
as shown in the below screen shot.
https://acadgild.com/blog/?p=18702&preview=truehttps://acadgild.com/blog/?p=18702&preview=true

ACADGILDACADGILD
In the main select the project name and the class name of the program as shown in the belowscreen shot.
https://acadgild.com/blog/?p=18702&preview=truehttps://acadgild.com/blog/?p=18702&preview=true

ACADGILDACADGILD
Now move into the Arguments tab and provide the input file path and the output filepath as shown in the below screen shot.
https://acadgild.com/blog/?p=18702&preview=truehttps://acadgild.com/blog/?p=18702&preview=true

ACADGILDACADGILD
Since we have our input file inside the project directory itself, we have just given inp as inputfile path and then a tabspace. We have given the output file path as just output. It willcreate the output directory inside the project directory itself.
Now click on Run. You will see the Eclipse console running.
SLF4J: Failed to load class "org.slf4j.impl.StaticLoggerBinder".SLF4J: Defaulting to no-operation (NOP) logger implementationSLF4J: See http://www.slf4j.org/codes.html#StaticLoggerBinder for further details.2016-09-16 00:26:17,574 INFO [main] jvm.JvmMetrics (JvmMetrics.java:init(76)) - Initializing JVM Metrics with processName=JobTracker, sessionId=2016-09-16 00:26:18,228 WARN [main] mapreduce.JobSubmitter (JobSubmitter.java:copyAndConfigureFiles(153)) - Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.2016-09-16 00:26:18,233 WARN [main] mapreduce.JobSubmitter (JobSubmitter.java:copyAndConfigureFiles(261)) - No job jar file set. User classes may notbe found. See Job or Job#setJar(String).
https://acadgild.com/blog/?p=18702&preview=truehttps://acadgild.com/blog/?p=18702&preview=true

ACADGILDACADGILD
2016-09-16 00:26:18,285 INFO [main] input.FileInputFormat (FileInputFormat.java:listStatus(281)) - Total input paths to process : 12016-09-16 00:26:18,382 INFO [main] mapreduce.JobSubmitter (JobSubmitter.java:submitJobInternal(494)) - number of splits:12016-09-16 00:26:18,493 INFO [main] mapreduce.JobSubmitter (JobSubmitter.java:printTokens(583)) - Submitting tokens for job: job_local1920454258_00012016-09-16 00:26:18,786 INFO [main] mapreduce.Job (Job.java:submit(1300)) - The url to track the job: http://localhost:8080/2016-09-16 00:26:18,787 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1345)) - Running job: job_local1920454258_00012016-09-16 00:26:18,787 INFO [Thread-2] mapred.LocalJobRunner (LocalJobRunner.java:createOutputCommitter(471)) - OutputCommitter set in config null2016-09-16 00:26:18,801 INFO [Thread-2] mapred.LocalJobRunner (LocalJobRunner.java:createOutputCommitter(489)) - OutputCommitter is org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter2016-09-16 00:26:18,839 INFO [Thread-2] mapred.LocalJobRunner (LocalJobRunner.java:runTasks(448)) - Waiting for map tasks2016-09-16 00:26:18,840 INFO [LocalJobRunner Map Task Executor #0] mapred.LocalJobRunner (LocalJobRunner.java:run(224)) - Starting task: attempt_local1920454258_0001_m_000000_02016-09-16 00:26:18,892 INFO [LocalJobRunner Map Task Executor #0] util.ProcfsBasedProcessTree (ProcfsBasedProcessTree.java:isAvailable(181)) - ProcfsBasedProcessTree currently is supported only on Linux.2016-09-16 00:26:19,208 INFO [LocalJobRunner Map Task Executor #0] mapred.Task (Task.java:initialize(587)) - Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@57c06f982016-09-16 00:26:19,229 INFO [LocalJobRunner Map Task Executor #0] mapred.MapTask (MapTask.java:runNewMapper(753)) - Processing split: file:/C:/Users/Kirankrishna/workspace/Word_count/inp:0+842016-09-16 00:26:19,466 INFO [LocalJobRunner Map Task Executor #0] mapred.MapTask (MapTask.java:setEquator(1202)) - (EQUATOR) 0 kvi 26214396(104857584)2016-09-16 00:26:19,468 INFO [LocalJobRunner Map Task Executor #0] mapred.MapTask (MapTask.java:init(995)) - mapreduce.task.io.sort.mb: 1002016-09-16 00:26:19,468 INFO [LocalJobRunner Map Task Executor #0] mapred.MapTask (MapTask.java:init(996)) - soft limit at 838860802016-09-16 00:26:19,468 INFO [LocalJobRunner Map Task Executor #0] mapred.MapTask (MapTask.java:init(997)) - bufstart = 0; bufvoid = 1048576002016-09-16 00:26:19,468 INFO [LocalJobRunner Map Task Executor #0] mapred.MapTask (MapTask.java:init(998)) - kvstart = 26214396; length = 65536002016-09-16 00:26:19,472 INFO [LocalJobRunner Map Task Executor #0] mapred.MapTask (MapTask.java:createSortingCollector(402)) - Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer2016-09-16 00:26:19,486 INFO [LocalJobRunner Map Task Executor #0] mapred.LocalJobRunner (LocalJobRunner.java:statusUpdate(591)) -2016-09-16 00:26:19,487 INFO [LocalJobRunner Map Task Executor #0] mapred.MapTask (MapTask.java:flush(1457)) - Starting flush of map output2016-09-16 00:26:19,487 INFO [LocalJobRunner Map Task Executor #0] mapred.MapTask (MapTask.java:flush(1475)) - Spilling map output2016-09-16 00:26:19,487 INFO [LocalJobRunner Map Task Executor #0] mapred.MapTask (MapTask.java:flush(1476)) - bufstart = 0; bufend = 135; bufvoid = 1048576002016-09-16 00:26:19,487 INFO [LocalJobRunner Map Task Executor #0] mapred.MapTask (MapTask.java:flush(1478)) - kvstart = 26214396(104857584); kvend = 26214348(104857392); length = 49/65536002016-09-16 00:26:19,536 INFO [LocalJobRunner Map Task Executor #0] mapred.MapTask (MapTask.java:sortAndSpill(1660)) - Finished spill 02016-09-16 00:26:19,544 INFO [LocalJobRunner Map Task Executor #0] mapred.Task (Task.java:done(1001)) - Task:attempt_local1920454258_0001_m_000000_0 is done. And is in the process of committing2016-09-16 00:26:19,551 INFO [LocalJobRunner Map Task Executor #0] mapred.LocalJobRunner (LocalJobRunner.java:statusUpdate(591)) - map
https://acadgild.com/blog/?p=18702&preview=truehttps://acadgild.com/blog/?p=18702&preview=true

ACADGILDACADGILD
2016-09-16 00:26:19,551 INFO [LocalJobRunner Map Task Executor #0] mapred.Task (Task.java:sendDone(1121)) - Task 'attempt_local1920454258_0001_m_000000_0' done.2016-09-16 00:26:19,551 INFO [LocalJobRunner Map Task Executor #0] mapred.LocalJobRunner (LocalJobRunner.java:run(249)) - Finishing task: attempt_local1920454258_0001_m_000000_02016-09-16 00:26:19,552 INFO [Thread-2] mapred.LocalJobRunner (LocalJobRunner.java:runTasks(456)) - map task executor complete.2016-09-16 00:26:19,553 INFO [Thread-2] mapred.LocalJobRunner (LocalJobRunner.java:runTasks(448)) - Waiting for reduce tasks2016-09-16 00:26:19,554 INFO [pool-3-thread-1] mapred.LocalJobRunner (LocalJobRunner.java:run(302)) - Starting task: attempt_local1920454258_0001_r_000000_02016-09-16 00:26:19,558 INFO [pool-3-thread-1] util.ProcfsBasedProcessTree (ProcfsBasedProcessTree.java:isAvailable(181)) - ProcfsBasedProcessTree currently is supported only on Linux.2016-09-16 00:26:19,593 INFO [pool-3-thread-1] mapred.Task (Task.java:initialize(587)) - Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@4c95e8542016-09-16 00:26:19,596 INFO [pool-3-thread-1] mapred.ReduceTask (ReduceTask.java:run(362)) - Using ShuffleConsumerPlugin: org.apache.hadoop.mapreduce.task.reduce.Shuffle@5b3f77aa2016-09-16 00:26:19,605 INFO [pool-3-thread-1] reduce.MergeManagerImpl (MergeManagerImpl.java:<init>(196)) - MergerManager: memoryLimit=1321939712, maxSingleShuffleLimit=330484928, mergeThreshold=872480256, ioSortFactor=10, memToMemMergeOutputsThreshold=102016-09-16 00:26:19,607 INFO [EventFetcher for fetching Map Completion Events] reduce.EventFetcher (EventFetcher.java:run(61)) - attempt_local1920454258_0001_r_000000_0 Thread started: EventFetcher for fetching Map Completion Events2016-09-16 00:26:19,636 INFO [localfetcher#1] reduce.LocalFetcher (LocalFetcher.java:copyMapOutput(141)) - localfetcher#1 about to shuffle output of map attempt_local1920454258_0001_m_000000_0 decomp: 120 len: 124 to MEMORY2016-09-16 00:26:19,661 INFO [localfetcher#1] reduce.InMemoryMapOutput (InMemoryMapOutput.java:shuffle(100)) - Read 120 bytes from map-output for attempt_local1920454258_0001_m_000000_02016-09-16 00:26:19,699 INFO [localfetcher#1] reduce.MergeManagerImpl (MergeManagerImpl.java:closeInMemoryFile(314)) - closeInMemoryFile -> map-output of size: 120, inMemoryMapOutputs.size() -> 1, commitMemory -> 0, usedMemory ->1202016-09-16 00:26:19,700 INFO [EventFetcher for fetching Map Completion Events] reduce.EventFetcher (EventFetcher.java:run(76)) - EventFetcher is interrupted.. Returning2016-09-16 00:26:19,702 INFO [pool-3-thread-1] mapred.LocalJobRunner (LocalJobRunner.java:statusUpdate(591)) - 1 / 1 copied.2016-09-16 00:26:19,702 INFO [pool-3-thread-1] reduce.MergeManagerImpl (MergeManagerImpl.java:finalMerge(674)) - finalMerge called with 1 in-memory map-outputs and 0 on-disk map-outputs2016-09-16 00:26:19,712 INFO [pool-3-thread-1] mapred.Merger (Merger.java:merge(597)) - Merging 1 sorted segments2016-09-16 00:26:19,713 INFO [pool-3-thread-1] mapred.Merger (Merger.java:merge(696)) - Down to the last merge-pass, with 1 segments left of total size: 112 bytes2016-09-16 00:26:19,714 INFO [pool-3-thread-1] reduce.MergeManagerImpl (MergeManagerImpl.java:finalMerge(751)) - Merged 1 segments, 120 bytes to disk to satisfy reduce memory limit2016-09-16 00:26:19,716 INFO [pool-3-thread-1] reduce.MergeManagerImpl (MergeManagerImpl.java:finalMerge(781)) - Merging 1 files, 124 bytes from disk2016-09-16 00:26:19,716 INFO [pool-3-thread-1] reduce.MergeManagerImpl (MergeManagerImpl.java:finalMerge(796)) - Merging 0 segments, 0 bytes from memory into reduce2016-09-16 00:26:19,717 INFO [pool-3-thread-1] mapred.Merger (Merger.java:merge(597)) - Merging 1 sorted segments2016-09-16 00:26:19,719 INFO [pool-3-thread-1] mapred.Merger (Merger.java:merge(696)) - Down to the last merge-pass, with 1 segments left of total size: 112 bytes2016-09-16 00:26:19,720 INFO [pool-3-thread-1] mapred.LocalJobRunner (LocalJobRunner.java:statusUpdate(591)) - 1 / 1 copied.
https://acadgild.com/blog/?p=18702&preview=truehttps://acadgild.com/blog/?p=18702&preview=true

ACADGILDACADGILD
2016-09-16 00:26:19,728 INFO [pool-3-thread-1] Configuration.deprecation (Configuration.java:warnOnceIfDeprecated(1049)) - mapred.skip.on is deprecated. Instead, use mapreduce.job.skiprecords2016-09-16 00:26:19,732 INFO [pool-3-thread-1] mapred.Task (Task.java:done(1001)) - Task:attempt_local1920454258_0001_r_000000_0 is done. And is in the process of committing2016-09-16 00:26:19,734 INFO [pool-3-thread-1] mapred.LocalJobRunner (LocalJobRunner.java:statusUpdate(591)) - 1 / 1 copied.2016-09-16 00:26:19,734 INFO [pool-3-thread-1] mapred.Task (Task.java:commit(1162)) - Taskattempt_local1920454258_0001_r_000000_0 is allowed to commit now2016-09-16 00:26:19,746 INFO [pool-3-thread-1] output.FileOutputCommitter (FileOutputCommitter.java:commitTask(439)) - Saved output of task 'attempt_local1920454258_0001_r_000000_0' to file:/C:/Users/Kirankrishna/workspace/Word_count/output/_temporary/0/task_local1920454258_0001_r_0000002016-09-16 00:26:19,750 INFO [pool-3-thread-1] mapred.LocalJobRunner (LocalJobRunner.java:statusUpdate(591)) - reduce > reduce2016-09-16 00:26:19,750 INFO [pool-3-thread-1] mapred.Task (Task.java:sendDone(1121)) - Task 'attempt_local1920454258_0001_r_000000_0' done.2016-09-16 00:26:19,750 INFO [pool-3-thread-1] mapred.LocalJobRunner (LocalJobRunner.java:run(325)) - Finishing task: attempt_local1920454258_0001_r_000000_02016-09-16 00:26:19,754 INFO [Thread-2] mapred.LocalJobRunner (LocalJobRunner.java:runTasks(456)) - reduce task executor complete.2016-09-16 00:26:19,789 WARN [Thread-2] mapred.LocalJobRunner (LocalJobRunner.java:run(560)) - job_local1920454258_0001java.lang.NoClassDefFoundError: org/apache/commons/httpclient/HttpMethod at org.apache.hadoop.mapred.LocalJobRunner$Job.run(LocalJobRunner.java:546)Caused by: java.lang.ClassNotFoundException: org.apache.commons.httpclient.HttpMethod at java.net.URLClassLoader.findClass(Unknown Source) at java.lang.ClassLoader.loadClass(Unknown Source) at sun.misc.Launcher$AppClassLoader.loadClass(Unknown Source) at java.lang.ClassLoader.loadClass(Unknown Source) ... 1 more2016-09-16 00:26:19,790 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1366)) - Job job_local1920454258_0001 running in uber mode : false2016-09-16 00:26:19,804 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1373)) - map 100% reduce 100%2016-09-16 00:26:19,805 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1386)) - Job job_local1920454258_0001 failed with state FAILED due to: NA2016-09-16 00:26:19,819 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1391)) - Counters: 33 File System Counters FILE: Number of bytes read=790 FILE: Number of bytes written=386816 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 Map-Reduce Framework Map input records=3 Map output records=13 Map output bytes=135 Map output materialized bytes=124 Input split bytes=117 Combine input records=13 Combine output records=10 Reduce input groups=10 Reduce shuffle bytes=124 Reduce input records=10
https://acadgild.com/blog/?p=18702&preview=truehttps://acadgild.com/blog/?p=18702&preview=true

ACADGILDACADGILD
Reduce output records=10 Spilled Records=20 Shuffled Maps =1 Failed Shuffles=0 Merged Map outputs=1 GC time elapsed (ms)=0 CPU time spent (ms)=0 Physical memory (bytes) snapshot=0 Virtual memory (bytes) snapshot=0 Total committed heap usage (bytes)=468713472 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=84 File Output Format Counters Bytes Written=90
You will get the above messages in the console after the completion of the job. You can checkfor the output file in the project directory and you can see the output in the part-r-00000 file as shown in the below screen shot.
In the above screen shot you can see the output of our wordcount program. We havesuccessfully ran a Hadoop application in Windows.
https://acadgild.com/blog/?p=18702&preview=truehttps://acadgild.com/blog/?p=18702&preview=true

ACADGILDACADGILD
We hope this blog helped you run a Hadoop application in Windows. Keep visiting oursite www.acadgild.com for more updates on bigdata and other technologies.
https://acadgild.com/blog/?p=18702&preview=truehttps://acadgild.com/blog/?p=18702&preview=true