rosette - basis technology€¦ · rosette ® is a suite of ... make real-world connections in your...
TRANSCRIPT

Modern enterprise is well-acquainted with the promise of big data to revolutionize our insights and decision making, although it is less well-known that up to 80% of big data is represented by Big Text. Big Text is large quantities of “unstructured” text chunks found in documents, webpages, and databases with all the hallmarks of big data: the three Vs (Volume, Velocity, and Variety). Big Text is also multilingual, covering many languages and scripts, in all of their complexities and challenges.
Because of the intrinsic nature of unstructured text, standard enterprise data solutions have a very limited ability to understand and utilize this treasure trove of information.
Rosette® is a suite of software components for use in enterprise applications. It uses linguistic analysis, statistical modeling, and machine learning to accurately process Big Text, revealing valuable information and actionable data.
Individually, each component is a robust tool for processing language, documents, or names. When combined together, they create powerful solutions that deliver useful information for better decisions and deep value for their users. Our customers across the globe, in government, finance, eDiscovery, search, social media, and beyond, depend on Rosette to analyze and transform their Big Text.
Gain insight and deep value from unstructured text 55 Supported
Languages
Start using ROSETTE today Try our free product evaluation
www.basistech.com
KEY FEATURES
- Simple API
- Fast and scalable
- Industrial-strength support
- Easy installation
- Flexible and customizable
- Java or C++
- Unix, Linux, Mac, or Windows
- Built to work with Apache Solr™ and
Elasticsearch
- Cloudera certified partner
www.basistech.com [email protected]
+1 617-386-2090
En
glis
h
Pronoun Verb Name
Concept
Pronoun+VerbVerb NounConjunction
Person
Title Name
Pronoun Verb Name
Concept
Determiner Noun
Place
Verb Name
Place
Title Name NamePrep.
Person Place
Urdu: “Islamabad”
Noun VerbRel. Pronoun Verb Verb Inf. Verb Noun
Pronoun+Verb Adjective Noun Prep. Adjective Adjective
Japanese:"Fukushima”
What is Big Text ?
It's huge volumes of multilingual , unstructured
text that must be processed to deliver insights
and build connections . It’s President Clinton
helping Malawi . Secretary Clinton in .
The福島 meltdown . This is Big Text .
Rosette®
BIG TEXT ANALYTICS
RES
RNT
RNI
REX
RBL
RLILanguage Identifier Identify languages and encodings
Base Linguistics Search many languages with high accuracy
Entity Extractor Tag names of people, places, and organizations
Name Indexer Match names between many variations
Name Translator Translate foreign names into English
CategorizerCategorize Everything In Sight
Sentiment AnalyzerDetect The Sentiments Of Your Text
Entity Resolver Make real-world connections in your data
Better Search
Tagged Entities
Real Identities
Matched Names
Sorted Languages
Translated Names
Sorted Content
Actionable Insights
RES
RNT
RNI
REX
RBL
RLI ROSETTELanguage Identifier
ROSETTEBase Linguistics
ROSETTEEntity Extractor
ROSETTEName Indexer
ROSETTEName Translator
ROSETTECategorizer
ROSETTESentiment Analyzer
ROSETTEEntity Resolver
RCA
RSA
RCA
RSA

Select Customers
Select Government Customers
Code Base Platform Support
Compatibility
© 2015 Basis Technology Corporation. “Basis Technology Corporation” , “Rosette”, and “Highlight” are registered trademarks of Basis Technology Corporation. “Big Text Analytics” is a trademark of Basis Technology Corporation. All other trademarks, service marks, and logos used in this document are the property of their respective owners. (2015-06-29-RLP)
WEST COAST
1700 Montgomery St.San Francisco, CA 94111
FEDERAL
2553 Dulles View Dr.Suite 450Herndon, VA 20171
HEADQUARTERS
One Alewife CenterCambridge, MA 02140
EUROPE
Furzeground WayMiddlesex UB11 1BD, UK
ASIA
9-6 Nibancho, Chiyoda-kuTokyo 102-0084, Japan
THE ROSETTE SOLUTIONTHE PROBLEM THE RESULT
CHARACTERISTICS
- 80% of Big Data
- Unstructured
- Multilingual
- Huge Volume
Rosette®
BIG TEXT ANALYTICS
RES
RNT
RNI
REX
RBL
RLILanguage Identifier Identify languages and encodings
Base Linguistics Search many languages with high accuracy
Entity Extractor Tag names of people, places, and organizations
Name Indexer Match names between many variations
Name Translator Translate foreign names into English
CategorizerCategorize Everything In Sight
Sentiment AnalyzerDetect The Sentiments Of Your Text
Entity Resolver Make real-world connections in your data
Better Search
Tagged Entities
Real Identities
Matched Names
Sorted Languages
Translated Names
Sorted Content
Actionable Insights
RES
RNT
RNI
REX
RBL
RLI ROSETTELanguage Identifier
ROSETTEBase Linguistics
ROSETTEEntity Extractor
ROSETTEName Indexer
ROSETTEName Translator
ROSETTECategorizer
ROSETTESentiment Analyzer
ROSETTEEntity Resolver
RCA
RSA
RCA
RSA
Rosette®
BIG TEXT ANALYTICS
RES
RNT
RNI
REX
RBL
RLILanguage Identifier Identify languages and encodings
Base Linguistics Search many languages with high accuracy
Entity Extractor Tag names of people, places, and organizations
Name Indexer Match names between many variations
Name Translator Translate foreign names into English
CategorizerCategorize Everything In Sight
Sentiment AnalyzerDetect The Sentiments Of Your Text
Entity Resolver Make real-world connections in your data
Better Search
Tagged Entities
Real Identities
Matched Names
Sorted Languages
Translated Names
Sorted Content
Actionable Insights
RES
RNT
RNI
REX
RBL
RLI ROSETTELanguage Identifier
ROSETTEBase Linguistics
ROSETTEEntity Extractor
ROSETTEName Indexer
ROSETTEName Translator
ROSETTECategorizer
ROSETTESentiment Analyzer
ROSETTEEntity Resolver
RCA
RSA
RCA
RSA
Rosette®
BIG TEXT ANALYTICS
RES
RNT
RNI
REX
RBL
RLILanguage Identifier Identify languages and encodings
Base Linguistics Search many languages with high accuracy
Entity Extractor Tag names of people, places, and organizations
Name Indexer Match names between many variations
Name Translator Translate foreign names into English
CategorizerCategorize Everything In Sight
Sentiment AnalyzerDetect The Sentiments Of Your Text
Entity Resolver Make real-world connections in your data
Better Search
Tagged Entities
Real Identities
Matched Names
Sorted Languages
Translated Names
Sorted Content
Actionable Insights
RES
RNT
RNI
REX
RBL
RLI ROSETTELanguage Identifier
ROSETTEBase Linguistics
ROSETTEEntity Extractor
ROSETTEName Indexer
ROSETTEName Translator
ROSETTECategorizer
ROSETTESentiment Analyzer
ROSETTEEntity Resolver
RCA
RSA
RCA
RSA
Search Engines

Rosette® Language Identifier (RLI) analyzes text from a few words to whole documents, to detect the languages and character encoding with speed and very high accuracy. Automatic language identification is the necessary first step for applications that categorize, search, process, and store text in many languages. Individual documents may be routed to language specialists, or sent into language-specific analysis pipelines (such as Rosette Base Linguistics) to improve the quality of search results.
For applications that analyze tweets, search keywords, and other short text, RLI offers market-leading accuracy for language detection given 1-3 words (<20 bytes) up to a full sentence.
RLI achieves its incredible accuracy through the use of proprietary algorithms with information-rich language profiles derived from statistical analysis, in addition to language-specific methods for short text language detection. Basis Technology continually improves the Rosette product family with language additions, feature updates, and the latest innovations from the academic world.
Identify languages and transform encodings 55 Supported
Languages
KEY FEATURES
- Simple API
- Fast and scalable
- Industrial-strength support
- Easy installation
- Flexible and customizable
- Java or C++
- Unix, Linux, Mac, or Windows
- Component of the Rosette SDK
Select Customers
www.basistech.com [email protected]
+1 617-386-2090
Start using RLI today Try our free product evaluation
www.basistech.com
Primary Language
FrenchPrimary Script
Latin
English
Chinese
French
Arabic
8%
22%
31%
39%
English
Arabic
Instantly identify and triagemany languages within largevolumes of text.
Chinese
Identifiez et triez instantanément plusieurs
langues à travers de nombreux textes. French
即时识别和处理大量多语言文本。
التحديد والتصنيف الفوري للعديد من اللغات ضمن كميات كبيرة من النصوص.
StumbleUpon
Rosette®BIG TEXT ANALYTICS
RES
RNT
RNI
REX
RBL
RLI Language Identifier Identify languages and encodings
Base Linguistics Search many languages with high accuracy
Entity Extractor Tag names of people, places, and organizations
Name Indexer Match names between many variations
Name Translator Translate foreign names into English
CategorizerCategorize Everything In Sight
Sentiment AnalyzerDetect The Sentiments Of Your Text
Entity Resolver Make real-world connections in your data
Better Search
Tagged Entities
Real Identities
Matched Names
Sorted Languages
Translated Names
Sorted Content
Actionable Insights
RES
RNT
RNI
REX
RBL
RLI ROSETTELanguage Identifier
ROSETTEBase Linguistics
ROSETTEEntity Extractor
ROSETTEName Indexer
ROSETTEName Translator
ROSETTECategorizer
ROSETTESentiment Analyzer
ROSETTEEntity Resolver
RCA
RSA
RCA
RSA

Albanian — ISO-8859-1, Windows-1252Arabic — ISO-8859-6, Windows-720, Windows-1256Arabic (transliterated) — ISO-8859-1, Windows-1252, Windows-1256Bengali — ISCII-BengaliBulgarian — ISO-8859-5, Windows-1251, KOI8-RCatalan — ISO-8859-1, Windows-1252Chinese, Simplified — GB-2312, GB-18030, HZ-GB-2312, ISO-2022-CNChinese, Traditional — Big5, Big5-HKSCSCroatian — Windows-1250Czech — ISO-8859-2, Windows-1250Danish — ISO-8859-1, Windows-1252Dutch — ISO-8859-1, Windows-1252English — ISO-8859-1, Windows-1252Estonian — ISO-8859-13, Windows-1257Finnish — ISO-8859-1, Windows-1252French — ISO-8859-1, Windows-1252German — ISO-8859-1, Windows-1252Greek — ISO-8859-7, Windows-1253Gujarati — ISCII-GujaratiHebrew — ISO-8859-8, Windows-1255Hindi — ISCII-HindiHungarian — ISO-8859-2, Windows-1250Icelandic — ISO-8859-1, Windows-1252Indonesian — ISO-8859-1, Windows-1252Italian — ISO-8859-1, Windows-1252Japanese — EUC-JP, ISO-2022-JP, Shift-JIS, Shift-JIS-2004 (JIS X 0213)Kannada — ISCII-KannadaKorean — EUC-KR, ISO-2022-KRKurdish — Windows-1256Kurdish (transliterated) — ISO-8859-1, Windows-1252, Windows-1256Latvian — ISO-8859-13, Windows-1257
IDENTIFICATION FEATURES
- Identifies the primary or dominant language of a document
- Identifies the language scripts within the document, such as Latin and Cyrillic
- Determines the languages and their percentages within multilingual documents
- Works with texts that have been transliterated, such as Arabic chat that is written in the Latin script
- Accurate with short strings—from 1-3 words (<20 bytes) to a full sentence to enable full analysis of search queries, tweets, image captions, metadata, news headlines, email subject lines, and more.
Digital text is often composed of multiple languages within the same document, presenting a challenge to computers and humans alike. RLI enriches the text with start and end markers for each language placed within multilingual documents—even if all the languages are written in the same script—such as English, French, German, or Italian. Boundaries of each writing system are also detected, such as Latin, Cyrillic, Japanese kana, or Chinese hanzi.
LANGUAGE BOUNDARY LOCATOR
188557
44
Latin ScriptVariants (Transliterations)
LegacyEncodings
Languageswith Unicode
Language/Encoding Pairs
ENCODING CONVERSION
Although modern text encoding standards, such as XML, mandate the use of Unicode, many existing applications, documents, websites, and data streams use “legacy encodings,” such as ASCII, ISO 8859-1, Shift-JIS, and many others.
Rosette accurately converts large collections of text with these legacy encodings into a single, uniform format in the Unicode standard. This converted text can then be used in any language, which eliminates data corruption and other problems due to incompatible code.
Lithuanian — ISO-8859-13, Windows-1257Macedonian — ISO-8859-5, Windows-1251Malay — ISO-8859-1, Windows-1252Malayalam — ISCII-MalayalamNorwegian — ISO-8859-1, Windows-1252Pashto — ISO-8859-6, Windows-1256Pashto (transliterated) — ISO-8859-1, Windows-1252Persian — ISO-8859-6, Windows-1256Persian (transliterated) — ISO-8859-1, Windows-1252, Windows-1256Polish — ISO-8859-2, Windows-1250Portuguese — ISO-8859-1, Windows-1252Romanian — ISO-8859-2, Windows-1250Russian — ISO-8859-5, Windows-1251, KOI8-R, IBM-866, Mac CyrillicSerbian — ISO-8859-5, Windows-1251Serbian (transliterated) — ISO-8859-2, Windows-1250Slovak — Windows-1250Slovenian — Windows-1250Somali — ISO-8859-1, Windows-1252Spanish — ISO-8859-1, Windows-1252Swedish — ISO-8859-1, Windows-1252Tagalog — ISO-8859-1, Windows-1252Tamil — ISCII-TamilTelugu — ISCII-TeluguThai — Windows-874Turkish — ISO-8859-9, Windows-1254Ukrainian — ISO-8859-5, Windows-1251, KOI8-RUrdu — ISO-8859-6, Windows-1256Urdu (transliterated) — ISO-8859-1, Windows-1252Uzbek — ISO-8859-5, Windows-1251, KOI8-RUzbek (transliterated) — Windows-1251Vietnamese — TCVN, VIQR, VISCII, VNI, VPS
LANGUAGE AND ENCODING COMPATIBILITY
Code Base Platform Support
Compatibility
ENGLISH FRENCH GERMAN SPANISH
J'ai été surprise par cette surprise. Vice President
Biden spoke about this in Munich. El carpintero
prensa los bordes de la placa decorativa. Proper
wound care management prevents die Geige gibt
einen schoenen Laut von sich.
© 2015 Basis Technology Corporation. “Basis Technology Corporation” , “Rosette”, and “Highlight” are registered trademarks of Basis Technology Corporation. “Big Text Analytics” is a trademark of Basis Technology Corporation. All other trademarks, service marks, and logos used in this document are the property of their respective owners. (2015-06-29-RLI)
WEST COAST
1700 Montgomery St.San Francisco, CA 94111
FEDERAL
2553 Dulles View Dr.Suite 450Herndon, VA 20171
HEADQUARTERS
One Alewife CenterCambridge, MA 02140
EUROPE
Furzeground WayMiddlesex UB11 1BD, UK
ASIA
9-6 Nibancho, Chiyoda-kuTokyo 102-0084, Japan
Rosette®BIG TEXT ANALYTICS
RES
RNT
RNI
REX
RBL
RLI Language Identifier Identify languages and encodings
Base Linguistics Search many languages with high accuracy
Entity Extractor Tag names of people, places, and organizations
Name Indexer Match names between many variations
Name Translator Translate foreign names into English
CategorizerCategorize Everything In Sight
Sentiment AnalyzerDetect The Sentiments Of Your Text
Entity Resolver Make real-world connections in your data
Better Search
Tagged Entities
Real Identities
Matched Names
Sorted Languages
Translated Names
Sorted Content
Actionable Insights
RES
RNT
RNI
REX
RBL
RLI ROSETTELanguage Identifier
ROSETTEBase Linguistics
ROSETTEEntity Extractor
ROSETTEName Indexer
ROSETTEName Translator
ROSETTECategorizer
ROSETTESentiment Analyzer
ROSETTEEntity Resolver
RCA
RSA
RCA
RSA
Rosette®BIG TEXT ANALYTICS
RES
RNT
RNI
REX
RBL
RLI Language Identifier Identify languages and encodings
Base Linguistics Search many languages with high accuracy
Entity Extractor Tag names of people, places, and organizations
Name Indexer Match names between many variations
Name Translator Translate foreign names into English
CategorizerCategorize Everything In Sight
Sentiment AnalyzerDetect The Sentiments Of Your Text
Entity Resolver Make real-world connections in your data
Better Search
Tagged Entities
Real Identities
Matched Names
Sorted Languages
Translated Names
Sorted Content
Actionable Insights
RES
RNT
RNI
REX
RBL
RLI ROSETTELanguage Identifier
ROSETTEBase Linguistics
ROSETTEEntity Extractor
ROSETTEName Indexer
ROSETTEName Translator
ROSETTECategorizer
ROSETTESentiment Analyzer
ROSETTEEntity Resolver
RCA
RSA
RCA
RSA

Every language, including English, presents unique and difficult challenges for search applications to deliver relevant and precise results. Rosette® Base Linguistics (RBL) enables enterprise applications to effectively search or process text in many languages by providing a complete set of linguistic services. RBL enriches the original text in its native language for best-of-class natural language processing, improving speed, and accuracy.
As linguistics experts with deep understanding at the intersection of language and technology, Basis Technology continually improves the Rosette product family with language additions, feature updates, and the latest innovations from the academic world.
Supported Languages
Search many languages with high accuracy 40
KEY FEATURES
- Simple API
- Fast and scalable
- Industrial-strength support
- Easy installation
- Flexible and customizable
- Java or C++
- Component of the Rosette SDK
- Customizable features such as user
dictionaries, orthographic normalization,
and script conversion
- Built to work with Apache Solr™ and
Elasticsearch
- Cloudera certified partner
Select Customers
www.basistech.com [email protected]
+1 617-386-2090
Start using RBL today Try our free product evaluation
www.basistech.com
Verb Determiner
Preposition Determiner
Noun
Noun Noun
Noun
Noun Punctuation
Conjunction
Preposition Adjective
Adjective
Improve the speed and
accuracy of your search
application with advanced
linguistic analysis .
Rosette®BIG TEXT ANALYTICS
RES
RNT
RNI
REX
RBL
RLI Language Identifier Identify languages and encodings
Base Linguistics Search many languages with high accuracy
Entity Extractor Tag names of people, places, and organizations
Name Indexer Match names between many variations
Name Translator Translate foreign names into English
CategorizerCategorize Everything In Sight
Sentiment AnalyzerDetect The Sentiments Of Your Text
Entity Resolver Make real-world connections in your data
Better Search
Tagged Entities
Real Identities
Matched Names
Sorted Languages
Translated Names
Sorted Content
Actionable Insights
RES
RNT
RNI
REX
RBL
RLI ROSETTELanguage Identifier
ROSETTEBase Linguistics
ROSETTEEntity Extractor
ROSETTEName Indexer
ROSETTEName Translator
ROSETTECategorizer
ROSETTESentiment Analyzer
ROSETTEEntity Resolver
RCA
RSA
RCA
RSA

TOKENIZATION
Many search tools use bigrams to understand languages written without spaces between words. This results in a larger index size and a reduction in relevancy. RBL, in contrast, accurately identifies and separates each word through advanced statistical modeling. The resulting token output (also known as segmentation) minimizes index size, enhances search accuracy, and increases relevancy.
DECOMPOUNDING
RBL breaks down compound words into sub-components and delivers each individual element to be indexed. This is especially useful for increasing search relevancy in languages such as German and Korean.
WESTERN EUROPE- Catalan*- Czech- Danish- Dutch- English- Finnish*- French- German- Greek- Italian- Norwegian- Portuguese- Spanish- Swedish
EASTERN EUROPE- Albanian*- Bulgarian*- Croatian*- Estonian*- Hungarian- Latvian*- Polish- Romanian- Russian- Serbian*- Slovak*- Slovenian*- Turkish- Ukranian*
Search Engines
Advanced Morphological Features
Available Languages
LEMMATIZATION
Most search engines utilize a crude method of chopping off characters at the end of a word in the hopes of removing unimportant differences. This method, called stemming, often results in extra recall and poor precision. Instead, RBL finds the true dictionary form of each word, known as a lemma, by using vocabulary, context, and advanced morphological analysis. Indexing the root form increases search relevancy and slims the search index by not indexing all inflected forms. Alternative lemmas are also made available to supplement indexing.
PART OF SPEECH TAGGING
As part of the lemmatization process, statistical modeling is used to determine the correct part of speech, even with ambiguous words.
Each token is then tagged for enhanced comprehension and search relevancy.Because different languages have different grammars, part-of-speech tags differ.
Rosette supports the Universal POS Tag standard from which the developer can map to Penn Treebank or other POS tag systems.
Compatibility
MIDDLE EAST- Arabic- Hebrew- Pashto- Persian- Urdu
ASIA- Chinese, Simplified- Chinese, Traditional- Indonesian- Japanese- Korean- Malay*- Thai
Example: GermanSamstagmorgen is a compound word formed with Samstag (Saturday) and morgen (morning). Decompounding allows for an appropriate match when searching for "Samstag".
Example: EnglishLinguistic analysis is useful for every language; lemmatization for English improves recall and precision.
NOUN PHRASE EXTRACTION
Certain nouns, especially proper names, canbe very tricky to identify as a single entity.RBL groups the nouns and their modifiers, which is useful in document clustering and concept extraction.
SENTENCE DETECTION
The start and end of each sentence is automatically identified even though punctuation use may be ambiguous.
CHALLENGE QUERY STEM LEMMA
Two unrelated words may share a stem.
animalsanimated
anim animalanimate
Stemming may deliver unintended results.
several sever several
Irregular verbs and nouns stump the stemmer.
spoke spoke speak (v.)spoke (n.)
WEST COAST
1700 Montgomery St.San Francisco, CA 94111
FEDERAL
2553 Dulles View Dr.Suite 450Herndon, VA 20171
HEADQUARTERS
One Alewife CenterCambridge, MA 02140
EUROPE
Furzeground WayMiddlesex UB11 1BD, UK
ASIA
9-6 Nibancho, Chiyoda-kuTokyo 102-0084, Japan
Code Base Platform Support
Example: Chinese Consider the problem of indexing “Beijing University Biology Department” and a subsequent search for “student”:
Beijing University
Biology Department
(Student)
INDEX
BIGRAMMING
RBL MORPHOLOGICAL TOKENIZATION
SEARCH
学
学
学
4 51 2
1 2
652 3 3 4 6 7
Beijing
Beijing University Biology Department
(non-word) University (Student) Biology Dept.
(non-word)
"Student" Incorrectly hits “Beijing University Biology Department”
Correctly misses “Beijing University Biology Department”
* Limited Support
© 2015 Basis Technology Corporation. “Basis Technology Corporation” , “Rosette”, and “Highlight” are registered trademarks of Basis Technology Corporation. “Big Text Analytics” is a trademark of Basis Technology Corporation. All other trademarks, service marks, and logos used in this document are the property of their respective owners. (2015-06-29-RBL)
Rosette®BIG TEXT ANALYTICS
RES
RNT
RNI
REX
RBL
RLI Language Identifier Identify languages and encodings
Base Linguistics Search many languages with high accuracy
Entity Extractor Tag names of people, places, and organizations
Name Indexer Match names between many variations
Name Translator Translate foreign names into English
CategorizerCategorize Everything In Sight
Sentiment AnalyzerDetect The Sentiments Of Your Text
Entity Resolver Make real-world connections in your data
Better Search
Tagged Entities
Real Identities
Matched Names
Sorted Languages
Translated Names
Sorted Content
Actionable Insights
RES
RNT
RNI
REX
RBL
RLI ROSETTELanguage Identifier
ROSETTEBase Linguistics
ROSETTEEntity Extractor
ROSETTEName Indexer
ROSETTEName Translator
ROSETTECategorizer
ROSETTESentiment Analyzer
ROSETTEEntity Resolver
RCA
RSA
RCA
RSA
Rosette®BIG TEXT ANALYTICS
RES
RNT
RNI
REX
RBL
RLI Language Identifier Identify languages and encodings
Base Linguistics Search many languages with high accuracy
Entity Extractor Tag names of people, places, and organizations
Name Indexer Match names between many variations
Name Translator Translate foreign names into English
CategorizerCategorize Everything In Sight
Sentiment AnalyzerDetect The Sentiments Of Your Text
Entity Resolver Make real-world connections in your data
Better Search
Tagged Entities
Real Identities
Matched Names
Sorted Languages
Translated Names
Sorted Content
Actionable Insights
RES
RNT
RNI
REX
RBL
RLI ROSETTELanguage Identifier
ROSETTEBase Linguistics
ROSETTEEntity Extractor
ROSETTEName Indexer
ROSETTEName Translator
ROSETTECategorizer
ROSETTESentiment Analyzer
ROSETTEEntity Resolver
RCA
RSA
RCA
RSA

Rosette® Entity Extractor (REX) delivers structure, clarity, and insight, by revealing the key information—names, places, organizations, products, and other words and phrases—lying hidden within large volumes of unstructured Big Text.
REX is the foundation for applications in eDiscovery, social media analysis, financial compliance, and government intelligence. The effectiveness of these mission-critical applications depend on REX for its accuracy, robustness, and ability to find entities across many languages.
By nature, statistically trained models are most accurate on the type of data they are trained on. Besides machine learning from a wide range of text beyond news articles, REX is unique among named entity recognition software in its adaptability. REX’s field training mechanism enables you to add your text data to increase REX’s accuracy on your text.
Accurate & adaptable statistical entity extraction 17 Supported
Languages
KEY FEATURES
- Component of the Rosette SDK
- Simple API
- Fast and scalable
- Industrial-strength support
- Easy installation
- Flexible and customizable
- Java or C++
- Unix, Linux, Mac, or Windows
Start using REX today Try our free product evaluation
www.basistech.com
Select Customers
www.basistech.com [email protected]
+1 617-386-2090
Automatically find names
of people, places , products ,
and organizations in text
across many languages.
ACTIVE INTELLIGENCE
Rosette®BIG TEXT ANALYTICS
RES
RNT
RNI
REX
RBL
RLI Language Identifier Identify languages and encodings
Base Linguistics Search many languages with high accuracy
Entity Extractor Tag names of people, places, and organizations
Name Indexer Match names between many variations
Name Translator Translate foreign names into English
CategorizerCategorize Everything In Sight
Sentiment AnalyzerDetect The Sentiments Of Your Text
Entity Resolver Make real-world connections in your data
Better Search
Tagged Entities
Real Identities
Matched Names
Sorted Languages
Translated Names
Sorted Content
Actionable Insights
RES
RNT
RNI
REX
RBL
RLI ROSETTELanguage Identifier
ROSETTEBase Linguistics
ROSETTEEntity Extractor
ROSETTEName Indexer
ROSETTEName Translator
ROSETTECategorizer
ROSETTESentiment Analyzer
ROSETTEEntity Resolver
RCA
RSA
RCA
RSA

Additional languages are available through custom development.
- Arabic- Hebrew- Pashto- Persian- Urdu
- Chinese, Simplified- Chinese, Traditional- Indonesian- Japanese- Korean
- Dutch- English- French- German- Italian- Portuguese- Russian- Spanish
Available Languages
REX natively supports the following entity types. User-defined entities, such as SKU numbers, are also available.
- Person- Location- Organization- Product- Title- Nationality- Religion- Credit Card Number- Geographic Coordinate- Money- Generic Number- Personal ID Number- Phone Number- Email Address/URL- Distance- Date- Time
Predefined Entity Types
STATISTICAL ENTITY EXTRACTION
Statistical modeling with advanced linguistics solves the three biggest challenges in entity extraction: finding entities which cannot be exhaustively listed, finding entities which are yet unknown, and using context to distinguish between similar entities, e.g., the place “Newton, MA” and the person “Isaac Newton”.
How it works REX in action
FIELD TRAINING FOR INCREASED ACCURACY
For users with text that is particularly challenging in format, style, or vocabulary, REX’s unique field training capability has multiple mechanisms to adapt its statistical model to their data. Users just add a quantity of their data (unannotated or annotated), and rebuild the model for maximum accuracy.
PATTERN-MATCHING RULES
Rules expressed as regular expressions find entities which follow a pattern, such as dates, times, and email addresses. Many standard string patterns are included with REX; customers can customize by editing or adding their own rules, based on their specific needs.
CUSTOM ENTITY LISTS
Custom lists are helpful when users know that specific words or phrases in their data are almost never misspelled and always refer to the same thing (i.e., are
unambiguous). REX comes with such lists for entity types like religions and nationalities.
Code Base Platform Support
Compatibility
Person
Location
Organization
Date
Time
Title
The New York Philharmonic Orchestra will make a historic trip to North Korea in February, it has announced. Dominique de Villepin a été nommé Premier ministrece mardi en fin de matinée par Jacques Chirac.
The orchestra's president and executive director, Zarin Mehta said it would play in the capital Pyongyang on February 26. In August, the reclusive communist country's Ministry of Culture sent an invitation to the orchestra at Lincoln Center in Manhattan.
L'ancien ministre de l'Intérieur, qui n'a jamais participé à une élection, a déjeuné avec les députés UMP et UDF à l'invitation du président de l'Assemblée nationale, Jean-Louis Debré.
اخلميس 5/2/1431 هـ - املوافق 21/1/2010 م (آخر حتديث) الساعة 10:01 (مكة املكرمة)، 7:01 (غرينتش) ناتويفكر مبسؤول مدني ألفغانستان يخطط حلف شمال األطلسي (ناتو)
لتعيني مسؤول مدني كبير في أفغانستان، وسط دعواتلتحسني التنسيق السياسي والتنموي فيالبالد وفق ما نقلته صحيفة وول ستريت
小澤征爾は、日本を代表する世界的な指揮者である。1973年、38歳のときに、アメリカ5大オーケストラの一つであるボストン交響楽団の音楽監督に就任した。
© 2015 Basis Technology Corporation. “Basis Technology Corporation” , “Rosette”, and “Highlight” are registered trademarks of Basis Technology Corporation. “Big Text Analytics” is a trademark of Basis Technology Corporation. All other trademarks, service marks, and logos used in this document are the property of their respective owners. (2015-06-29-REX)
WEST COAST
1700 Montgomery St.San Francisco, CA 94111
FEDERAL
2553 Dulles View Dr.Suite 450Herndon, VA 20171
HEADQUARTERS
One Alewife CenterCambridge, MA 02140
EUROPE
Furzeground WayMiddlesex UB11 1BD, UK
ASIA
9-6 Nibancho, Chiyoda-kuTokyo 102-0084, Japan
Rosette®BIG TEXT ANALYTICS
RES
RNT
RNI
REX
RBL
RLI Language Identifier Identify languages and encodings
Base Linguistics Search many languages with high accuracy
Entity Extractor Tag names of people, places, and organizations
Name Indexer Match names between many variations
Name Translator Translate foreign names into English
CategorizerCategorize Everything In Sight
Sentiment AnalyzerDetect The Sentiments Of Your Text
Entity Resolver Make real-world connections in your data
Better Search
Tagged Entities
Real Identities
Matched Names
Sorted Languages
Translated Names
Sorted Content
Actionable Insights
RES
RNT
RNI
REX
RBL
RLI ROSETTELanguage Identifier
ROSETTEBase Linguistics
ROSETTEEntity Extractor
ROSETTEName Indexer
ROSETTEName Translator
ROSETTECategorizer
ROSETTESentiment Analyzer
ROSETTEEntity Resolver
RCA
RSA
RCA
RSA
Rosette®BIG TEXT ANALYTICS
RES
RNT
RNI
REX
RBL
RLI Language Identifier Identify languages and encodings
Base Linguistics Search many languages with high accuracy
Entity Extractor Tag names of people, places, and organizations
Name Indexer Match names between many variations
Name Translator Translate foreign names into English
CategorizerCategorize Everything In Sight
Sentiment AnalyzerDetect The Sentiments Of Your Text
Entity Resolver Make real-world connections in your data
Better Search
Tagged Entities
Real Identities
Matched Names
Sorted Languages
Translated Names
Sorted Content
Actionable Insights
RES
RNT
RNI
REX
RBL
RLI ROSETTELanguage Identifier
ROSETTEBase Linguistics
ROSETTEEntity Extractor
ROSETTEName Indexer
ROSETTEName Translator
ROSETTECategorizer
ROSETTESentiment Analyzer
ROSETTEEntity Resolver
RCA
RSA
RCA
RSA
Customized extraction

Rosette® Entity Resolver (RES) reveals meaningful information in your text. It connects the words that represent real-world things to one another and to entities in an entity database like Wikipedia, both within and across documents.
Good quality entity resolution means dealing with three key problems: variety, where one thing can have many names; ambiguity, where many things can have very similar if not exactly the same name, and ghosts, where some collection of names identify a previously unknown real-world thing.
RES enriches your text with high, quality metadata, enabling you to perform intuitive, entity-centric search and discovery. With it you can power notification applications designed to detect and track new people in text streams. It provides excellent raw material for building the custom knowledge graphs at the heart of many of today’s most innovative applications.
Linking and learning for real-world dataKEY FEATURES
- Standard training from 2.5M Wikipedia entities
- “Learning” Mode: Identifies previously unknown
entities (“ghosts”) and learns new aliases from
text as it processes
- “Linking” Mode: Rapidly links only known entities
- Custom entity database training
- Fast and scalable
- Industrial-strength support
- Flexible and customizable
- Java
- Unix, Linux, Mac, or Windows
Start using RESTry our free product evaluation
www.basistech.com
www.basistech.com [email protected]
+1 617-386-2090
Paris Tamerlan Tsarnaev Apple
Connect your unstructured
text to the real-world people,
organizations and places you
care about.
Paris, Texas (33°39 N, 95°32 W)—or—Paris, France (48°51 N 2°21 E)
Tamerlin Tsarnaev (TheAtlantic.com) —or— Tamerlane Tsarnaevy (Mir24.net)
Apple Corps Ltd. (Music)—or—Apple Inc. (Technology)
EXAMPLES:
Rosette®BIG TEXT ANALYTICS
RES
RNT
RNI
REX
RBL
RLI Language Identifier Identify languages and encodings
Base Linguistics Search many languages with high accuracy
Entity Extractor Tag names of people, places, and organizations
Name Indexer Match names between many variations
Name Translator Translate foreign names into English
CategorizerCategorize Everything In Sight
Sentiment AnalyzerDetect The Sentiments Of Your Text
Entity Resolver Make real-world connections in your data
Better Search
Tagged Entities
Real Identities
Matched Names
Sorted Languages
Translated Names
Sorted Content
Actionable Insights
RES
RNT
RNI
REX
RBL
RLI ROSETTELanguage Identifier
ROSETTEBase Linguistics
ROSETTEEntity Extractor
ROSETTEName Indexer
ROSETTEName Translator
ROSETTECategorizer
ROSETTESentiment Analyzer
ROSETTEEntity Resolver
RCA
RSA
RCA
RSA
Organize Big Text using entity linking and learning
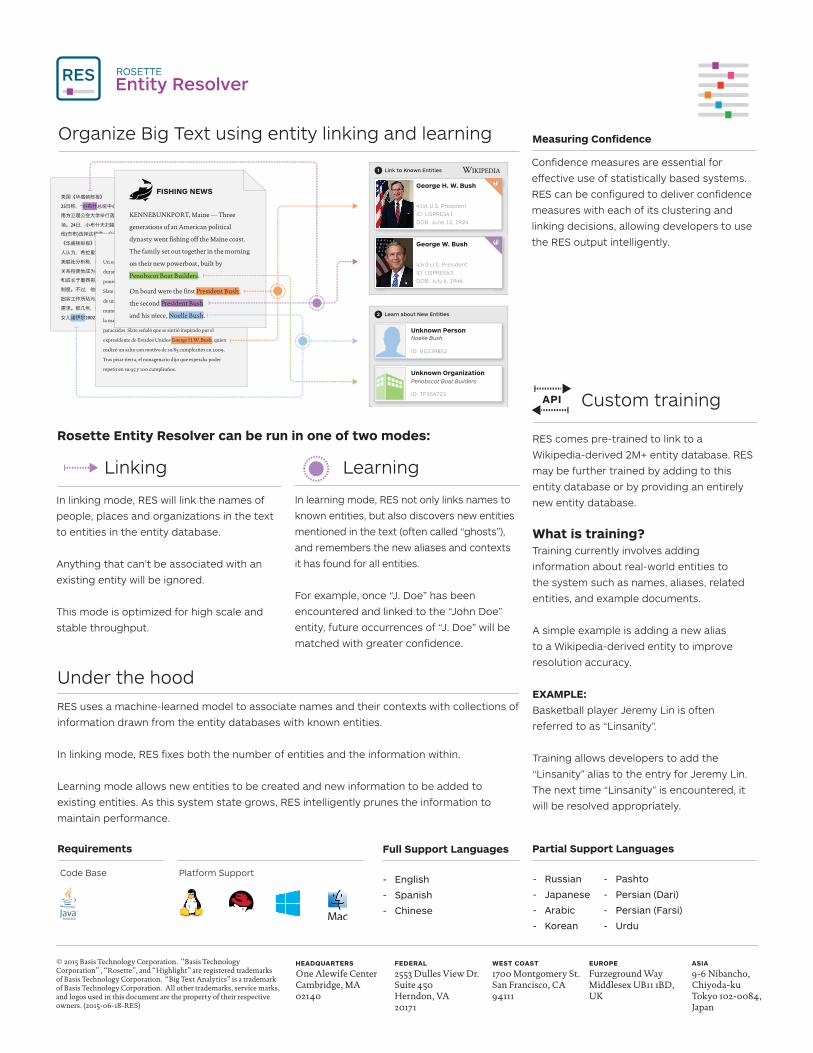
In linking mode, RES will link the names of people, places and organizations in the text to entities in the entity database.
Anything that can’t be associated with an existing entity will be ignored.
This mode is optimized for high scale and stable throughput.
Linking Learning
Code Base Platform Support
Requirements
Custom training
Partial Support Languages
Confidence measures are essential for effective use of statistically based systems. RES can be configured to deliver confidence measures with each of its clustering and linking decisions, allowing developers to use the RES output intelligently.
© 2015 Basis Technology Corporation. “Basis Technology Corporation” , “Rosette”, and “Highlight” are registered trademarks of Basis Technology Corporation. “Big Text Analytics” is a trademark of Basis Technology Corporation. All other trademarks, service marks, and logos used in this document are the property of their respective owners. (2015-06-18-RES)
- Russian
- Japanese
- Arabic
- Korean
Rosette Entity Resolver can be run in one of two modes:
In learning mode, RES not only links names to known entities, but also discovers new entities mentioned in the text (often called “ghosts”), and remembers the new aliases and contexts it has found for all entities.
For example, once “J. Doe” has been encountered and linked to the “John Doe” entity, future occurrences of “J. Doe” will be matched with greater confidence.
RES uses a machine-learned model to associate names and their contexts with collections of information drawn from the entity databases with known entities.
In linking mode, RES fixes both the number of entities and the information within.
Learning mode allows new entities to be created and new information to be added to existing entities. As this system state grows, RES intelligently prunes the information to maintain performance.
Under the hood
RES comes pre-trained to link to a Wikipedia-derived 2M+ entity database. RES may be further trained by adding to this entity database or by providing an entirely new entity database.
What is training?Training currently involves adding information about real-world entities to the system such as names, aliases, related entities, and example documents.
A simple example is adding a new alias to a Wikipedia-derived entity to improve resolution accuracy.
EXAMPLE:Basketball player Jeremy Lin is often referred to as “Linsanity”.
Training allows developers to add the “Linsanity” alias to the entry for Jeremy Lin. The next time “Linsanity” is encountered, it will be resolved appropriately.
Un estadounidense que aprendió a saltar en paracaídas
durante la Segunda Guerra Mundial cumplió su sueño de
poner en práctica su habilidad a los 90 años de edad. Lester
Slate saltó este domingo en el estado de Maine acompañado
de un guía paracaidista. A pesar de haber volado en
numerosas ocasiones, según la prensa local, este veterano de
la marina estadounidense nunca se había lanzado en
paracaídas. Slate señaló que se sintió inspirado por el
expresidente de Estados Unidos Goerge H.W. Bush, quien
realizó un salto con motivo de su 85 cumpleaños en 2009.
Tras pisar tierra, el nonagenario dijo que esperaba poder
repetir en su 95 y 100 cumpleaños.
George H. W. Bush
41st U.S. PresidentID: USPRES41DOB: June 12, 1924
George W. Bush
43rd U.S. PresidentID: USPRES43DOB: July 6, 1946
FISHING NEWS
Noelle Bush
ID: BD239852
Unknown Person
Unknown OrganizationPenobscot Boat Builders
ID: TF354723
KENNEBUNKPORT, Maine — Three
generations of an American political
dynasty went fishing off the Maine coast.
The family set out together in the morning
on their new powerboat, built by
Penobscot Boat Builders.
On board were the first President Bush;
the second President Bush
and his niece, Noelle Bush.
1 Link to Known Entities
2 Learn about New Entities
API
- Pashto
- Persian (Dari)
- Persian (Farsi)
- Urdu
Measuring Confidence
- English
- Spanish
- Chinese
Full Support Languages
WEST COAST
1700 Montgomery St.San Francisco, CA 94111
FEDERAL
2553 Dulles View Dr.Suite 450Herndon, VA 20171
HEADQUARTERS
One Alewife CenterCambridge, MA 02140
EUROPE
Furzeground WayMiddlesex UB11 1BD, UK
ASIA
9-6 Nibancho, Chiyoda-kuTokyo 102-0084, Japan
Rosette®BIG TEXT ANALYTICS
RES
RNT
RNI
REX
RBL
RLI Language Identifier Identify languages and encodings
Base Linguistics Search many languages with high accuracy
Entity Extractor Tag names of people, places, and organizations
Name Indexer Match names between many variations
Name Translator Translate foreign names into English
CategorizerCategorize Everything In Sight
Sentiment AnalyzerDetect The Sentiments Of Your Text
Entity Resolver Make real-world connections in your data
Better Search
Tagged Entities
Real Identities
Matched Names
Sorted Languages
Translated Names
Sorted Content
Actionable Insights
RES
RNT
RNI
REX
RBL
RLI ROSETTELanguage Identifier
ROSETTEBase Linguistics
ROSETTEEntity Extractor
ROSETTEName Indexer
ROSETTEName Translator
ROSETTECategorizer
ROSETTESentiment Analyzer
ROSETTEEntity Resolver
RCA
RSA
RCA
RSA
Rosette®BIG TEXT ANALYTICS
RES
RNT
RNI
REX
RBL
RLI Language Identifier Identify languages and encodings
Base Linguistics Search many languages with high accuracy
Entity Extractor Tag names of people, places, and organizations
Name Indexer Match names between many variations
Name Translator Translate foreign names into English
CategorizerCategorize Everything In Sight
Sentiment AnalyzerDetect The Sentiments Of Your Text
Entity Resolver Make real-world connections in your data
Better Search
Tagged Entities
Real Identities
Matched Names
Sorted Languages
Translated Names
Sorted Content
Actionable Insights
RES
RNT
RNI
REX
RBL
RLI ROSETTELanguage Identifier
ROSETTEBase Linguistics
ROSETTEEntity Extractor
ROSETTEName Indexer
ROSETTEName Translator
ROSETTECategorizer
ROSETTESentiment Analyzer
ROSETTEEntity Resolver
RCA
RSA
RCA
RSA

Names are the linchpin that connect data points in financial compliance, anti-fraud, government intelligence, law enforcement, and identity verification. Yet, names are challenging to connect because of their incredible variation in misspellings, nicknames, initials, and titles. In international databases, a single name may also appear in many languages!
Rosette® Name Indexer (RNI) solves these challenges with a linguistic, knowledge-based system that compares and matches names of people, places, and organizations despite their many variations. RNI is unrivalled in its ability to match names because of its intelligent approach.
As linguistics experts with deep understanding at the intersection of language and technology, Basis Technology continually improves the Rosette product family with language additions, feature updates, and the latest innovations from the academic world. RNI is unrivalled in its ability to match the names of entities—find out how your organization can utilize this pioneering technology for extraordinary results.
Accurate fuzzy name matching in many languages 14 Supported
Languages
KEY FEATURES
- Component of the Rosette SDK
- Simple API
- Fast and scalable
- Industrial-strength support
- Easy installation
- Flexible and customizable
- Java
- Unix, Linux, Mac, or Windows
- Matches names of people, places, and
organizations
- Increases name search accuracy
- Ranks results by relevancy with a similarity
score
- Built to work with Apache™ Solr and
Elasticsearch
Select Customers
www.basistech.com [email protected]
+1 617-386-2090
Start using RNI today Try our free product evaluation
www.basistech.com
Franklin D. Roosevelt
32nd U.S. PresidentID: USPRES32DOB: Jan. 30, 1882
82%
97%
77%
82%
84%
85%
74%
79%
73%
富兰克林·罗塞费尔特
Gov. Franklin Roosevelt
Frank Delano Roosevelt
Franklin Rosenvelt
President Roosevelt
Рузвельт, Франклин
F. D. R.F. D. Roosev
Franklin Delano Roosevelt, also known by his initials, FDR, was the 32nd President of the United States and a central figure in world events during the mid-20th century, leading the United States during....
Rosette®BIG TEXT ANALYTICS
RES
RNT
RNI
REX
RBL
RLI Language Identifier Identify languages and encodings
Base Linguistics Search many languages with high accuracy
Entity Extractor Tag names of people, places, and organizations
Name Indexer Match names between many variations
Name Translator Translate foreign names into English
CategorizerCategorize Everything In Sight
Sentiment AnalyzerDetect The Sentiments Of Your Text
Entity Resolver Make real-world connections in your data
Better Search
Tagged Entities
Real Identities
Matched Names
Sorted Languages
Translated Names
Sorted Content
Actionable Insights
RES
RNT
RNI
REX
RBL
RLI ROSETTELanguage Identifier
ROSETTEBase Linguistics
ROSETTEEntity Extractor
ROSETTEName Indexer
ROSETTEName Translator
ROSETTECategorizer
ROSETTESentiment Analyzer
ROSETTEEntity Resolver
RCA
RSA
RCA
RSA

Our knowledge-based system combines the latest in Natural Language Processing (NLP) to intelligently match names based on their linguistic and cultural structures and norms.
Unlike expensive and less accurate legacy solutions driven by thousands of spelling variants from known names, RNI analyzes the intrinsic structure of each name component and performs an intelligent comparison using advanced linguistic algorithms.
Our approach is not limited to a particular list of variants and reduces the likelihood of both “false positives” (wrong matches) and “false negatives” (missed matches).
List driven systems cannot equal RNI for matching never-seen-before names or mis-segmented names (Mary Ellen vs. MaryEllen).
- Arabic scripts: Arabic, Persian, Pashto, Urdu- Cyrillic: Russian - Hangul: Korean - Hanzi (Simplified & Traditional): Chinese- Kanji, Katakana, Hirigana: Japanese- Roman scripts: English, Spanish, French,
Italian, German, Portuguese
RNI matches names from these languages either in transliteration to English or written in their native scripts.
Available Languages and Scripts
Name Matching Capabilities
Code Base Platform Support
Compatibility
Same name in multiple languagesMao Zedong 1 Мао Цзэдун 1 毛泽东
Phonetic spelling di erencesCairns 1 Kearns 1 Kerns
Transliteration spelling di erencesAbdul Rasheed 1 Abd-al-Rasheed 1 Abdulrashid
NicknamesWilliam 1 Will 1 Bill 1 Billy
InitialsJ. E. Smith 1 James Earl Smith
Titles and honorificsDr. 1 Mr. 1 Ph.D.
Out-of-order name componentsDiaz, Carlos Alfonzo 1 Carlos Alfonzo Diaz
Missing name componentsPhillip Charles Carr 1 Phillip Carr
Missing spaces or hyphensMaryEllen 1 Mary Ellen 1 Mary-Ellen
Truncated name componentsMcDonalds 1 McD 1 McDonald
Name split inconsistently across database fieldsDick • Van Dyke 1 Dick Van • Dyke
© 2015 Basis Technology Corporation. “Basis Technology Corporation” , “Rosette” and “Highlight” are registered trademarks of Basis Technology Corporation. “Big Text Analytics” is a trademark of Basis Technology Corporation. All other trademarks, service marks, and logos used in this document are the property of their respective owners. (2015-06-29-RNI)
WEST COAST
1700 Montgomery St.San Francisco, CA 94111
FEDERAL
2553 Dulles View Dr.Suite 450Herndon, VA 20171
HEADQUARTERS
One Alewife CenterCambridge, MA 02140
EUROPE
Furzeground WayMiddlesex UB11 1BD, UK
ASIA
9-6 Nibancho, Chiyoda-kuTokyo 102-0084, Japan
Rosette®BIG TEXT ANALYTICS
RES
RNT
RNI
REX
RBL
RLI Language Identifier Identify languages and encodings
Base Linguistics Search many languages with high accuracy
Entity Extractor Tag names of people, places, and organizations
Name Indexer Match names between many variations
Name Translator Translate foreign names into English
CategorizerCategorize Everything In Sight
Sentiment AnalyzerDetect The Sentiments Of Your Text
Entity Resolver Make real-world connections in your data
Better Search
Tagged Entities
Real Identities
Matched Names
Sorted Languages
Translated Names
Sorted Content
Actionable Insights
RES
RNT
RNI
REX
RBL
RLI ROSETTELanguage Identifier
ROSETTEBase Linguistics
ROSETTEEntity Extractor
ROSETTEName Indexer
ROSETTEName Translator
ROSETTECategorizer
ROSETTESentiment Analyzer
ROSETTEEntity Resolver
RCA
RSA
RCA
RSA
Rosette®BIG TEXT ANALYTICS
RES
RNT
RNI
REX
RBL
RLI Language Identifier Identify languages and encodings
Base Linguistics Search many languages with high accuracy
Entity Extractor Tag names of people, places, and organizations
Name Indexer Match names between many variations
Name Translator Translate foreign names into English
CategorizerCategorize Everything In Sight
Sentiment AnalyzerDetect The Sentiments Of Your Text
Entity Resolver Make real-world connections in your data
Better Search
Tagged Entities
Real Identities
Matched Names
Sorted Languages
Translated Names
Sorted Content
Actionable Insights
RES
RNT
RNI
REX
RBL
RLI ROSETTELanguage Identifier
ROSETTEBase Linguistics
ROSETTEEntity Extractor
ROSETTEName Indexer
ROSETTEName Translator
ROSETTECategorizer
ROSETTESentiment Analyzer
ROSETTEEntity Resolver
RCA
RSA
RCA
RSA
The Rosette Advantage
Financial institutions use RNI to manage and update watchlists to block terrorist access to funds, simultaneously avoiding compliance violations and protecting their reputation. Applications also include fraud detection, money laundering, and document triage.
Financial Compliance
Names are often the most critical data point in intelligence, law enforcement, and border control. RNI is being adopted throughout the U.S. government to address the challenge of matching names in all their variations—particularly names from non-Latin languages such as Arabic, Russian, Chinese, Korean, or Persian.
Government Intelligence
Trust is foundational to the sharing economy. Whether booking room rentals, rides, or odd jobs, it is important to establish ways to connect the online and offline worlds to reinforce that trust and confidence.
Name matching is a key component of verifying online identities with real-world documentation (passports, driver’s licenses). Members of the sharing economy such as Airbnb rely on RNI to match names originating from all over the world, and internationally between names written in alphabets besides the Roman A-to-Z.
Identity Verification in the Sharing Economy
Rosette® Name Indexer integrates easily into Apache Solr™ as a plug-in or into applications as a Java library to support its main use cases. RNI can also be adapted to match the needs of each application.
Apache SolrApache Solr™-based search systems can easily add high-quality fuzzy name matching to every search by simply adding name fields. RNI provides a special Solr field type for names. This mechanism means Solr can index documents with multiple name fields, each with multiple values (e.g., an “alias” field may contain more than one name). Each document could also contain non-name fields like dates or plain text.
<fieldname=”primary”>MuhammadAli</field> <fieldname=”alias”>CassiusClayJr</field> <fieldname=”alias”>TheGreatest</field> <fieldname=”dob”>1/7/1942</field>
A single query can then be constructed that gives different weight to the various fields. For example, a single query can find movies starring “Binedict Cumberbund” with screenplays by “Giyermo Diltoro” that were released around 2014.
Java LibraryAny application that needs name matching can directly integrate a Java library which takes care of storing watchlists without incurring the overhead of a web-service call.
Integration Options
- Set the minimum threshold of the similarity score to manage the precision and recall of the returned search results.
- Ignore a given list of words (“stopwords”) with respect to matching (e.g., titles, honorifics).
- Force two name words to always match with a given score (e.g., “Elizabeth” and “Lisbeth” always match at 90%).
- Force two names to always match with a given score (e.g., “John Doe” and “Joe Bloggs” always match at 95%).
- Link multiple names to a single individual (e.g., queries for "Marilyn Monroe" and "Norma Jeane Mortensen" include the same person).
Customize To Your Needs
Same name in multiple languagesMao Zedong 1 Мао Цзэдун 1 毛泽东
Phonetic spelling di erencesCairns 1 Kearns 1 Kerns
Transliteration spelling di erencesAbdul Rasheed 1 Abd-al-Rasheed 1 Abdulrashid
NicknamesWilliam 1 Will 1 Bill 1 Billy
InitialsJ. E. Smith 1 James Earl Smith
Titles and honorificsDr. 1 Mr. 1 Ph.D.
Out-of-order name componentsDiaz, Carlos Alfonzo 1 Carlos Alfonzo Diaz
Missing name componentsPhillip Charles Carr 1 Phillip Carr
Missing spaces or hyphensMaryEllen 1 Mary Ellen 1 Mary-Ellen
Truncated name componentsMcDonalds 1 McD 1 McDonald
Name split inconsistently across database fieldsDick • Van Dyke 1 Dick Van • Dyke
Use Cases

Names are an essential source of information, but most names in the world are not written in English, rendering them nearly useless to Anglocentric corporations and governments. These organizations must quickly and accurately translate names, often at a very large scale. Rosette® Name Translator (RNT) can quickly process millions of names from foreign languages and produce highly accurate, standardized English translations using industry-leading technologies, such as linguistic algorithms and statistical modeling. In addition, RNT can also translate any name written in English into its equivalent in any supported language, such as Arabic or Chinese.
As linguistics experts with deep understanding at the intersection of language and technology, Basis Technology continually improves the Rosette product family with language additions, feature updates, and the latest innovations from the academic world.
Instantly translate many names to (and from) English 10 Supported
Languages
KEY FEATURES
- Component of the Rosette SDK
- Simple API
- Fast and scalable
- Industrial-strength support
- Easy installation
- Flexible and customizable
- Java
- Unix, Linux, Mac, or Windows
Select Customers
www.basistech.com [email protected]
+1 617-386-2090
Start using RNT today Try our free product evaluation
www.basistech.com
Abu-Yusif Ya'qubأبو يوسف يعقوب
Yao MingOrigin Chinese
Entity Type Person
Language Chinese
Origin Japanese
Entity Type Location
Language Japanese
Shinano River
John KennedyOrigin English
Entity Type Person
Language Arabic
Origin Arabic
Entity Type Person
Language Arabic
Chan Ho PakOrigin Korean
Language Russian
Entity Type Person
جون كينيدي
姚明
Чан Хо Пак
信濃川
Rosette®BIG TEXT ANALYTICS
RES
RNT
RNI
REX
RBL
RLI Language Identifier Identify languages and encodings
Base Linguistics Search many languages with high accuracy
Entity Extractor Tag names of people, places, and organizations
Name Indexer Match names between many variations
Name Translator Translate foreign names into English
CategorizerCategorize Everything In Sight
Sentiment AnalyzerDetect The Sentiments Of Your Text
Entity Resolver Make real-world connections in your data
Better Search
Tagged Entities
Real Identities
Matched Names
Sorted Languages
Translated Names
Sorted Content
Actionable Insights
RES
RNT
RNI
REX
RBL
RLI ROSETTELanguage Identifier
ROSETTEBase Linguistics
ROSETTEEntity Extractor
ROSETTEName Indexer
ROSETTEName Translator
ROSETTECategorizer
ROSETTESentiment Analyzer
ROSETTEEntity Resolver
RCA
RSA
RCA
RSA

A DIFFICULT PROBLEMTranslating names from other languages into English is quite difficult. Even the most powerful and expensive “machine translation” systems struggle when confronted with the task of accurately translating large numbers of names. Why is this so hard?
A FEW CHALLENGES:- Which words in a name should be
translated according to their spelling (i.e., transliterated) and which words according to their meaning?
- Within a language, there may be conflicting conventions for translation. Both “Fuji” and “Huzi” are accepted name spellings of the iconic Japanese volcano. Arguments over spelling the capital of Ukraine as “Kiev” vs. “Kyiv” have almost triggered diplomatic crises.
- Common practice may conflict with organizational standards. For example, the name of the former ruler of Iraq typically appears in the news media as “Saddam Hussein”. However, the CIA’s official spelling is “Saddam Husayn”. Similarly, the conventional spelling of the Syrian ruler is “Assad”. However, CIA guidelines say “Asad”.
- A name written in a foreign language may be native to that language, such as محمود أحمدي جناد (Mahmoud Ahmadinejad), or may be an English name written in a foreign alphabet, such as جورج دبليو بوش (George W. Bush).
HOW IT WORKSRNT combines dictionary look-ups and transliteration to find the most accurate English spelling of a name. First, the foreign name is examined in user-supplied name dictionaries, known as gazetteers. If the name is not found, RNT transliterates the name into English by using linguistic algorithms and statistical modeling, then matches it using preferred name standards. For example, names written in Chinese are converted from ideographic characters into a phonetic representation. Names written in “unvocalized” Arabic (i.e., without short vowels) are automatically vocalized to enable a phonetic translation according to any of several user-selected standard systems.
UNIQUE CAPABILITIES- Generate consistent “conventional spellings”
of frequently appearing foreign names
- Process “unrecognized” names, i.e., those not appearing in any known catalog of foreign names
- Incorporate complex transliteration standards (such as the IC or U.S. Board on Geographic Names) for translating a name from a foreign alphabet into English
- Automatically resolve name spelling ambiguities in the source language, such as partial vocalization of Arabic, or word segmentation in Chinese
Arabic 1 EnglishDari 1 EnglishFarsi 1 EnglishPashto 1 EnglishUrdu English
Chinese 1 EnglishJapanese EnglishKorean 1 EnglishRussian 1 English
Additional languages are available via custom development.
1 Indicates names can be translated to and from English
Indicates names can be translated only to English
Available Languages Pairs
Code Base Platform Support
Compatibility
COMBINING REX & RNT
Washington
Tanzania
Anne Patterson
American
Darfur
Security Council
United NationsAfrican Union
Person
Location
Organization
Nationality
Rosette Entity Extractor (REX) may be paired with RNT to extract and translate key names in a document, with accuracy superior to either statistical or rule-based machine translation systems. This approach may also be used to enrich or remediate the output of such systems in situations where translations of entire paragraphs or documents are required.
واقترحت واشنطن بدال من ذلك إنشاء محكمة جديدة تابعة لألمم املتحدة واالحتاد األفريقي
في تنزانيا وتعهدت بتقدمي دعم مالي كبير لها، مطالبة الدول الغنية األخرى بتوفير
مساعدات مماثلة. وأكدت القائمة بأعمال املندوب األميركي في مجلس األمن
آن باترسون اهتمام بالدها مبساءلة من وصفتهم مبرتكبي األعمال الوحشية في دارفور
REX RNT
King 'Abdallah Bin-'Abd-al-'Aziz
Instead of “Malik” Instead of “Servant of God”,son of “Servant of the Precious One”
عبد اهللا بن عبد العزيز ملك
© 2015 Basis Technology Corporation. “Basis Technology Corporation” , “Rosette”, and “Highlight” are registered trademarks of Basis Technology Corporation. “Big Text Analytics” is a trademark of Basis Technology Corporation. All other trademarks, service marks, and logos used in this document are the property of their respective owners. (2015-06-29-RNT)
WEST COAST
1700 Montgomery St.San Francisco, CA 94111
FEDERAL
2553 Dulles View Dr.Suite 450Herndon, VA 20171
HEADQUARTERS
One Alewife CenterCambridge, MA 02140
EUROPE
Furzeground WayMiddlesex UB11 1BD, UK
ASIA
9-6 Nibancho, Chiyoda-kuTokyo 102-0084, Japan
Rosette®BIG TEXT ANALYTICS
RES
RNT
RNI
REX
RBL
RLI Language Identifier Identify languages and encodings
Base Linguistics Search many languages with high accuracy
Entity Extractor Tag names of people, places, and organizations
Name Indexer Match names between many variations
Name Translator Translate foreign names into English
CategorizerCategorize Everything In Sight
Sentiment AnalyzerDetect The Sentiments Of Your Text
Entity Resolver Make real-world connections in your data
Better Search
Tagged Entities
Real Identities
Matched Names
Sorted Languages
Translated Names
Sorted Content
Actionable Insights
RES
RNT
RNI
REX
RBL
RLI ROSETTELanguage Identifier
ROSETTEBase Linguistics
ROSETTEEntity Extractor
ROSETTEName Indexer
ROSETTEName Translator
ROSETTECategorizer
ROSETTESentiment Analyzer
ROSETTEEntity Resolver
RCA
RSA
RCA
RSA
Rosette®BIG TEXT ANALYTICS
RES
RNT
RNI
REX
RBL
RLI Language Identifier Identify languages and encodings
Base Linguistics Search many languages with high accuracy
Entity Extractor Tag names of people, places, and organizations
Name Indexer Match names between many variations
Name Translator Translate foreign names into English
CategorizerCategorize Everything In Sight
Sentiment AnalyzerDetect The Sentiments Of Your Text
Entity Resolver Make real-world connections in your data
Better Search
Tagged Entities
Real Identities
Matched Names
Sorted Languages
Translated Names
Sorted Content
Actionable Insights
RES
RNT
RNI
REX
RBL
RLI ROSETTELanguage Identifier
ROSETTEBase Linguistics
ROSETTEEntity Extractor
ROSETTEName Indexer
ROSETTEName Translator
ROSETTECategorizer
ROSETTESentiment Analyzer
ROSETTEEntity Resolver
RCA
RSA
RCA
RSA