robobees + aladdin + helix - … · robobees + aladdin + helix approximate accelerator...
TRANSCRIPT

RoboBees + Aladdin + HELIX
Approximate Accelerator
Architectures
Gu-Yeon WeiSchool of Engineering and Applied Sciences
Harvard University

TechnologicalFallow Period
CMOS scaling is running out
2

Power wall Lost performance
Power wall multicore
3

Two obvious paths to higher performance
Parallel processing Specialized processing
4

Today’s talk
• RoboBees: A Convergence of Body, Brain and Colony
• Aladdin: A pre-RTL accelerator modeling tool
• HELIX-UP: Approximate parallelization trades accuracy for speed
Future architectures for approximate accelerator systems
5

Our Inspiration
6

7
The problem
• 30% of world’s food supply pollinated by honeybees
• Big problem if they all disappear…
7

Build micro-sized robotic bees!
8[K. Ma et al., Science 2013] [Takeoff Video: http://goo.gl/RTkeSF]
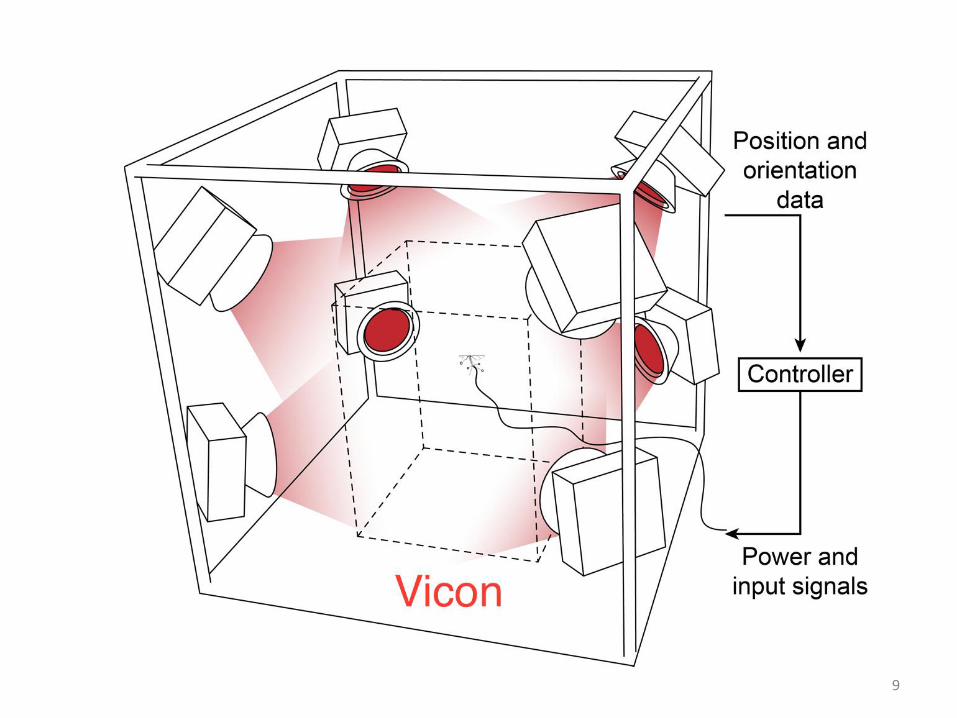
9
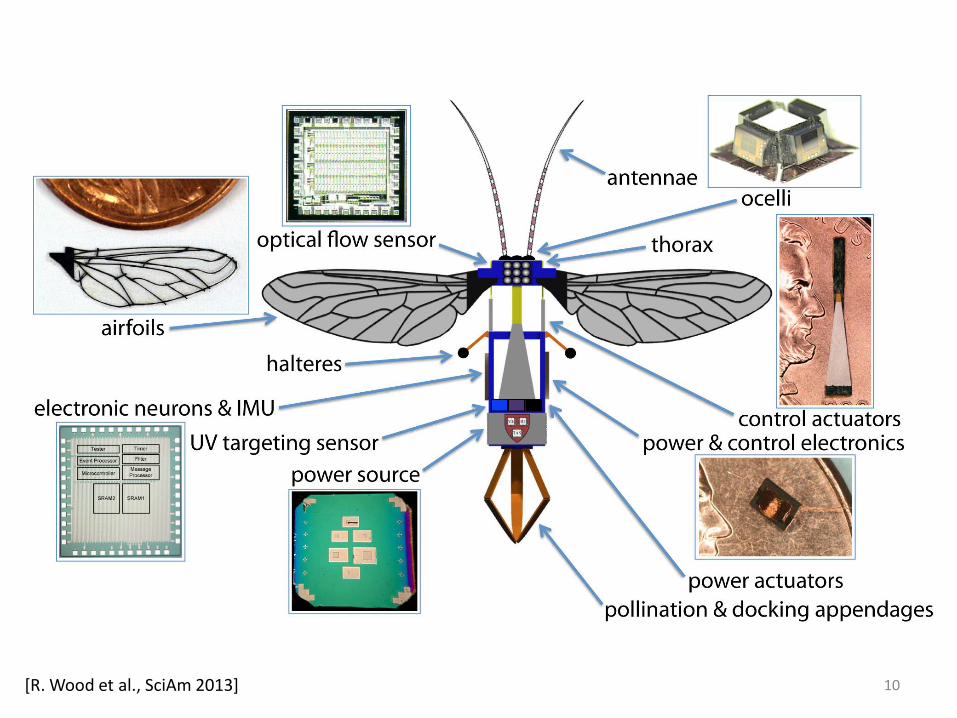
10[R. Wood et al., SciAm 2013]
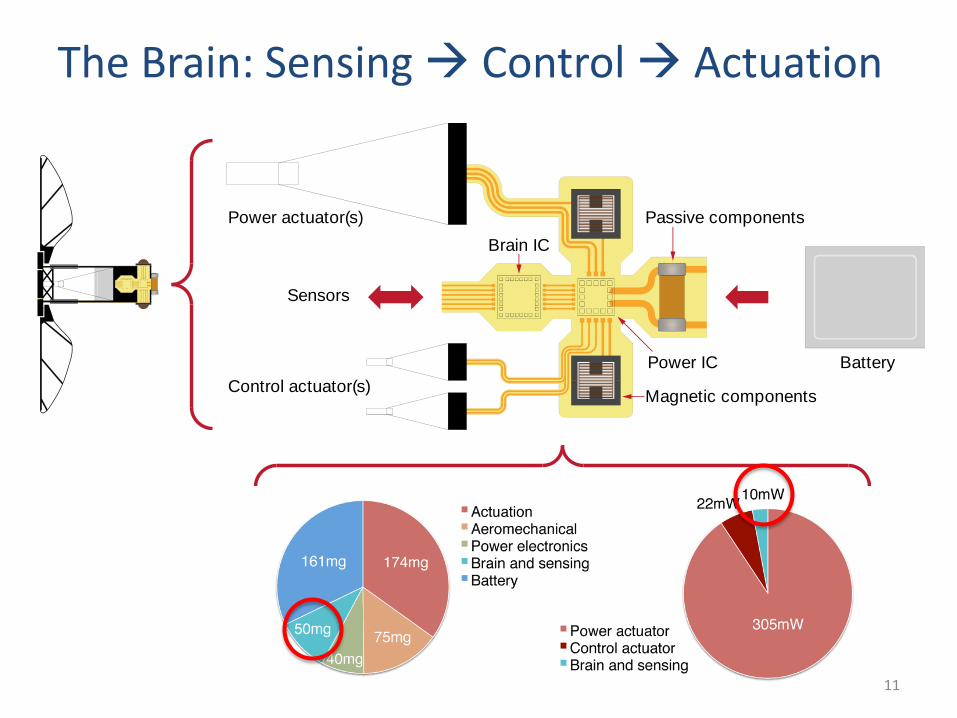
The Brain: Sensing Control Actuation
Power actuator(s)
Control actuator(s)
Sensors
Battery
Magnetic components
Passive components
Brain IC
Power IC
11

A 50mg budget No off-chip components
• Fully-integrated 4:1 voltage regulator– Cascade two 2:1 switched-capacitor converters
– Brain SoC operates directly off of ~3.7V battery
• Self clocking via voltage-tracking oscillator– No external reference clock/oscillator
– Frequency tracks operating conditions
*A calibrated relaxation oscillator provides 10MHz +/- 1.2% frequency for “absolute” timing to flap wings
12
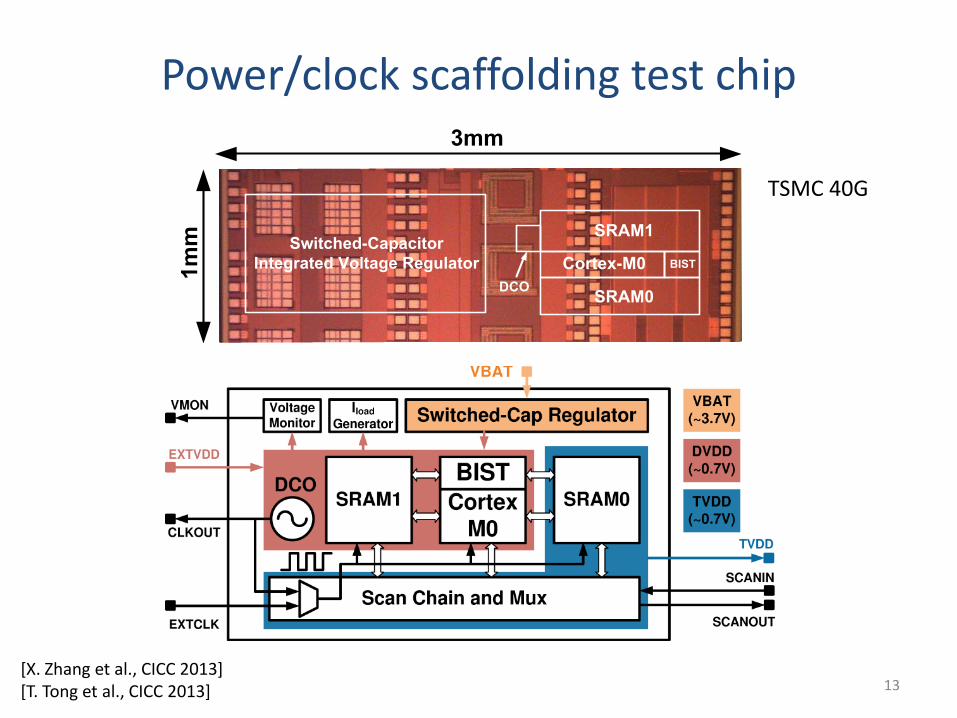
Power/clock scaffolding test chip
Switched-Capacitor
Integrated Voltage Regulator
SRAM1
DCO
1m
m
SRAM0
Cortex-M0
3mm
BIST
13
TSMC 40G
[X. Zhang et al., CICC 2013] [T. Tong et al., CICC 2013]

How to “sense” the world?14

on-bee sensors
26666664
✓x✓y✓z✓x✓y✓z
37777775
26666664
xy
z
x
y
z
37777775
Sensor Type Mass Power BW Precision Remarks
Ocelli1 light 22 mg < 5 mW 100 kHz 2 deg/s
Gyroscope MEMS 40 mg 20 mW 200 Hz 1 deg/sec vibration-sensitive
Accelerometer MEMS 40 mg 20 mW 200 Hz 0.2 milli-g
Sonar audio 14 mg .4 mW 100 Hz low wings as emitters?
Magnetometer magnetic 16 mg 1 mw 1 kHz 1 deg magnetic interference?
Pressure MEMS 30 mg 1 mW 200 Hz 1 m
Optical flow2 CMOS >100 mg 10-20mW 40 Hz NA computation-heavy
Airspeed1 PC-MEMS 5 mg 25 mW 100 Hz 10 cm/s
Laser rangefinder CMOS 5 mg 1.5 mW 40 Hz ~1 cm needs camera
magnetometer
accelerometer
gyroscope
ocelli
optical flowantenna (wind)
sonar
(audio)laser
rangefinder
pressure
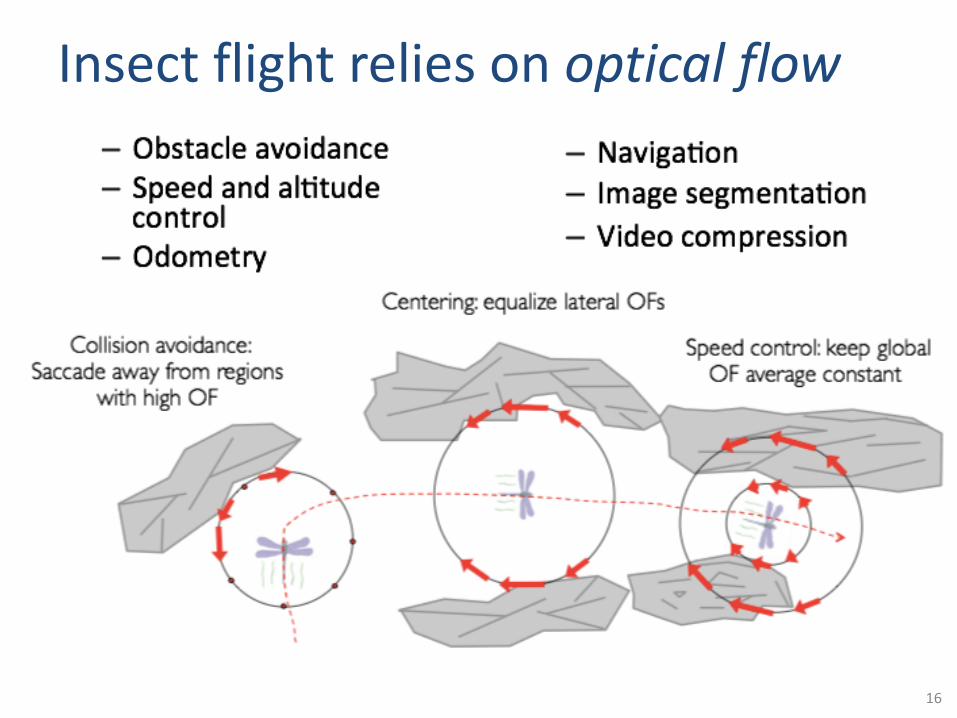
Insect flight relies on optical flow
16

optical flow sensor integration
17
Sensor: 4x32 pixels
[P. Duhamel et al., Trans. Mechatronics 2013]

altitude control w/ optical flow
18[P. Duhamel et al., Trans. Mechatronics 2013]
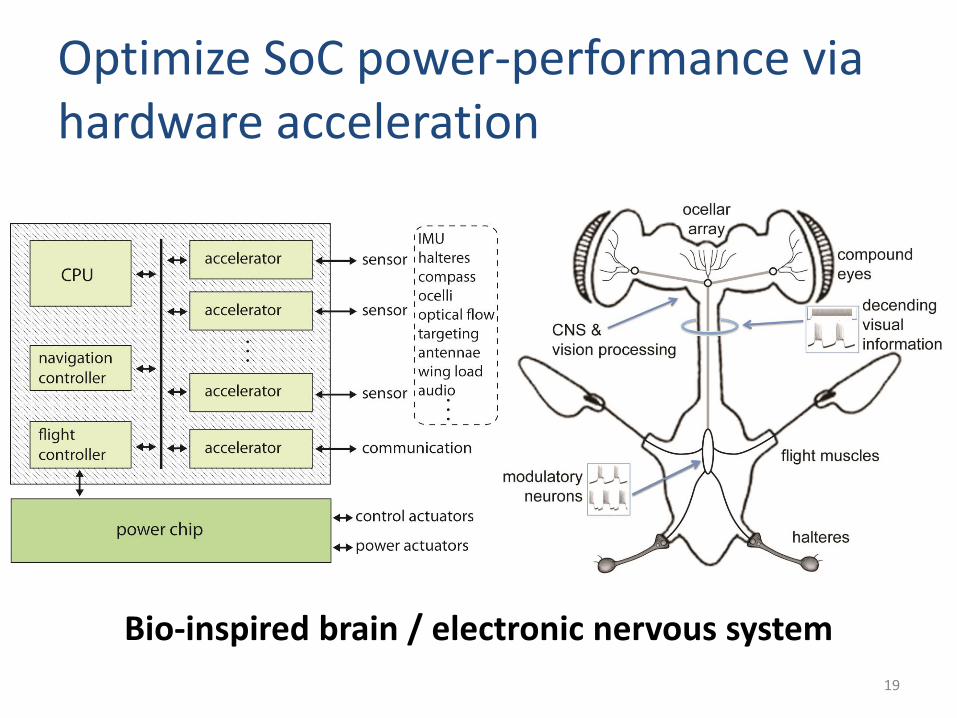
Optimize SoC power-performance via hardware acceleration
19
Bio-inspired brain / electronic nervous system

We built a BrainSoC test-chip prototype
20[X. Zhang et al., Symp. VLSI Circuit 2015]
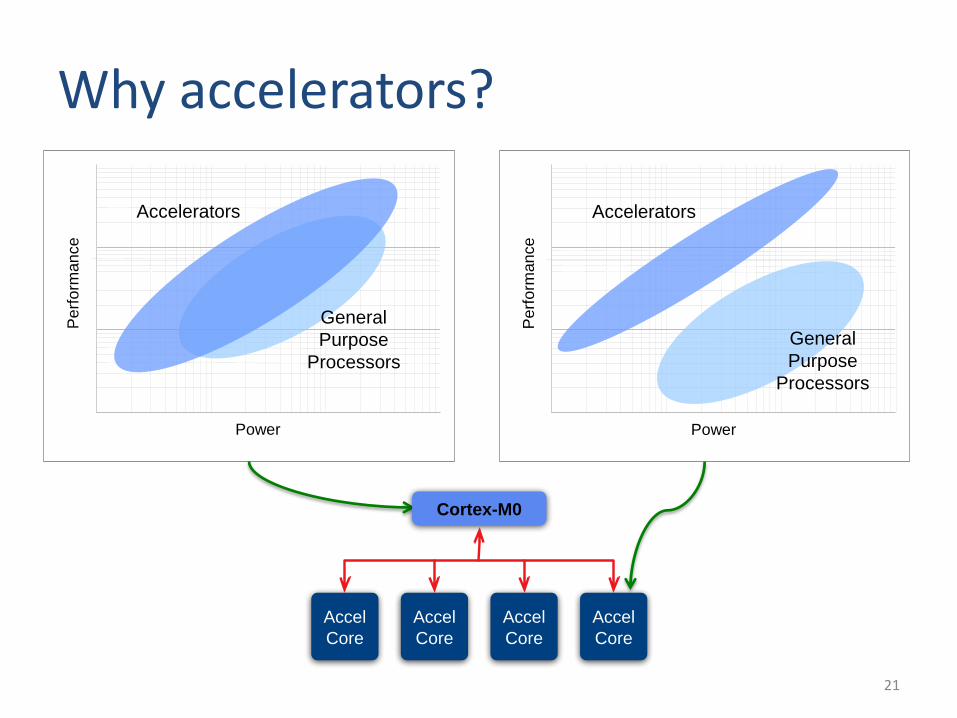
Why accelerators?
21
General
Purpose
Processors
Accelerators
Power
Pe
rfo
rman
ce
General
Purpose
Processors
Accelerators
Power
Pe
rfo
rman
ce
Cortex-M0
Accel
Core
Accel
Core
Accel
Core
Accel
Core

E.g.: Apple A8 SoC has cores, memories, GPU + lots of accelerators
22
Out-of-CoreAccelerators
[www.anandtech.com/show/8562/chipworks-a8]
Out-of-CoreAccelerators
Maltiel Consultingestimates
Our estimates
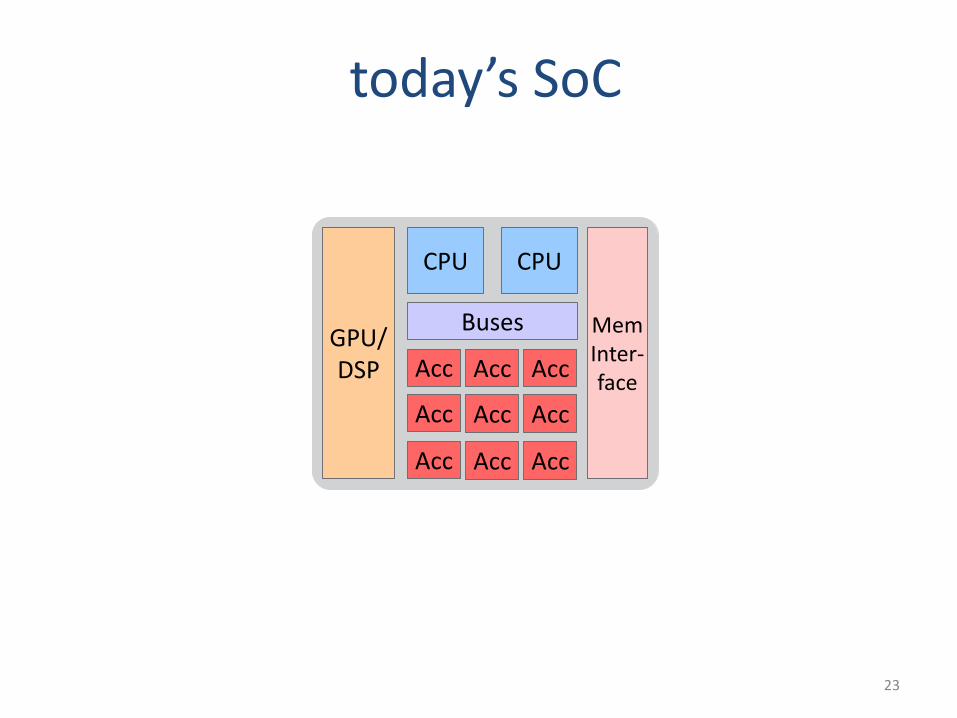
today’s SoC
GPU/DSP
CPU
Buses MemInter-face
Acc
CPU
Acc
Acc
Acc
Acc
Acc
Acc
Acc
Acc
23
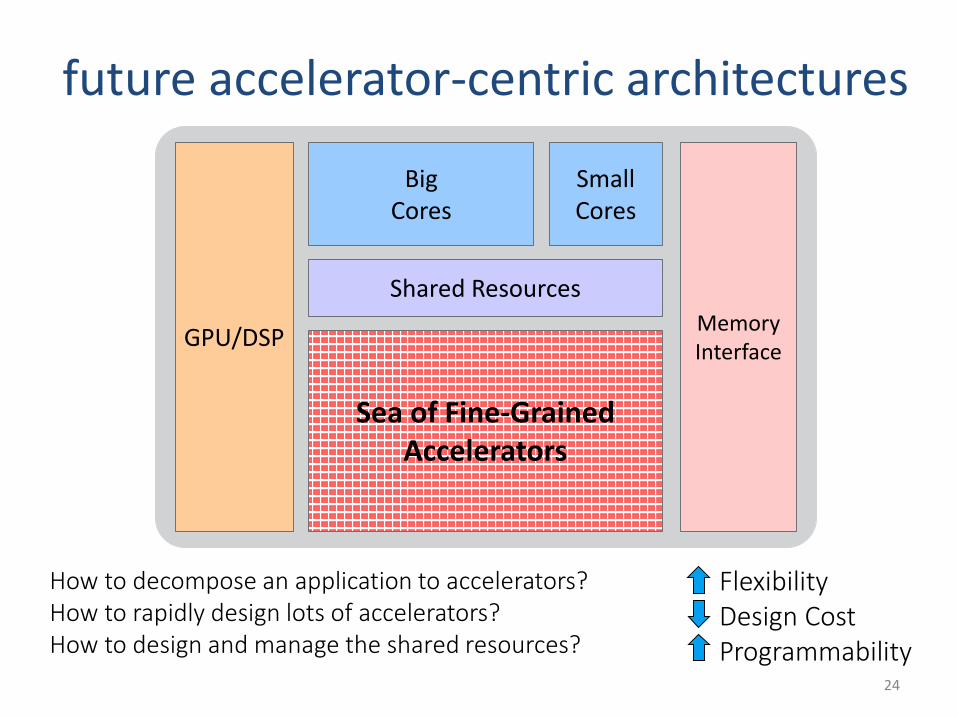
future accelerator-centric architectures
FlexibilityDesign Cost Programmability
How to decompose an application to accelerators?How to rapidly design lots of accelerators?How to design and manage the shared resources?
GPU/DSP
Big Cores
Shared Resources
MemoryInterface
Sea of Fine-Grained Accelerators
Small Cores
24
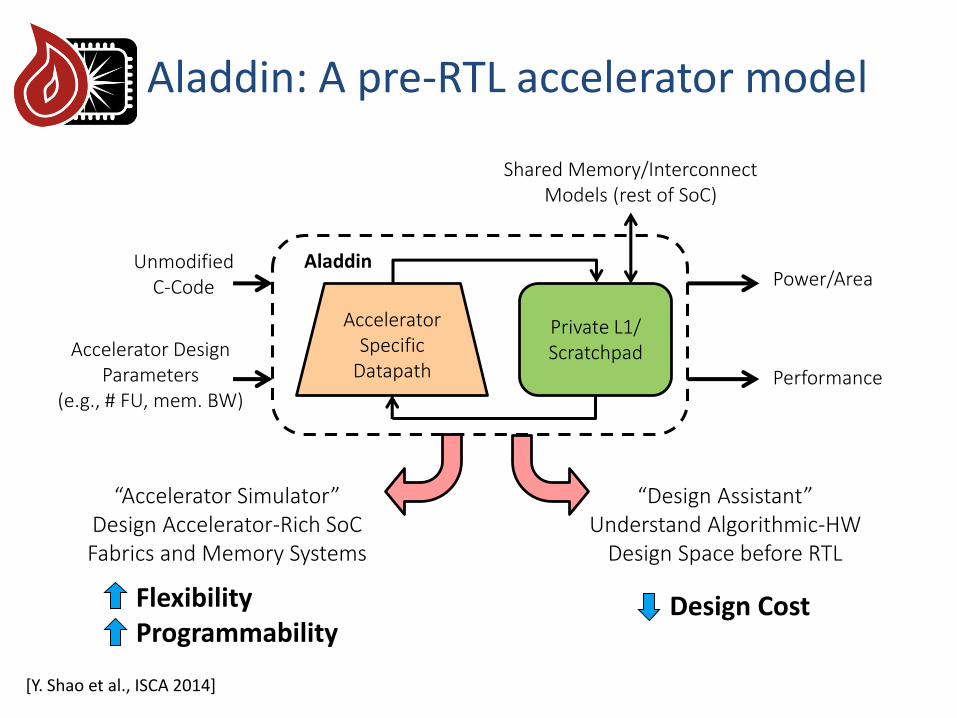
Private L1/Scratchpad
Aladdin
AcceleratorSpecific
Datapath
Shared Memory/InterconnectModels (rest of SoC)
UnmodifiedC-Code
Accelerator DesignParameters
(e.g., # FU, mem. BW)
Power/Area
Performance
“Accelerator Simulator” Design Accelerator-Rich SoCFabrics and Memory Systems
Aladdin: A pre-RTL accelerator model
“Design Assistant” Understand Algorithmic-HW
Design Space before RTL
[Y. Shao et al., ISCA 2014]
Design Cost Flexibility Programmability
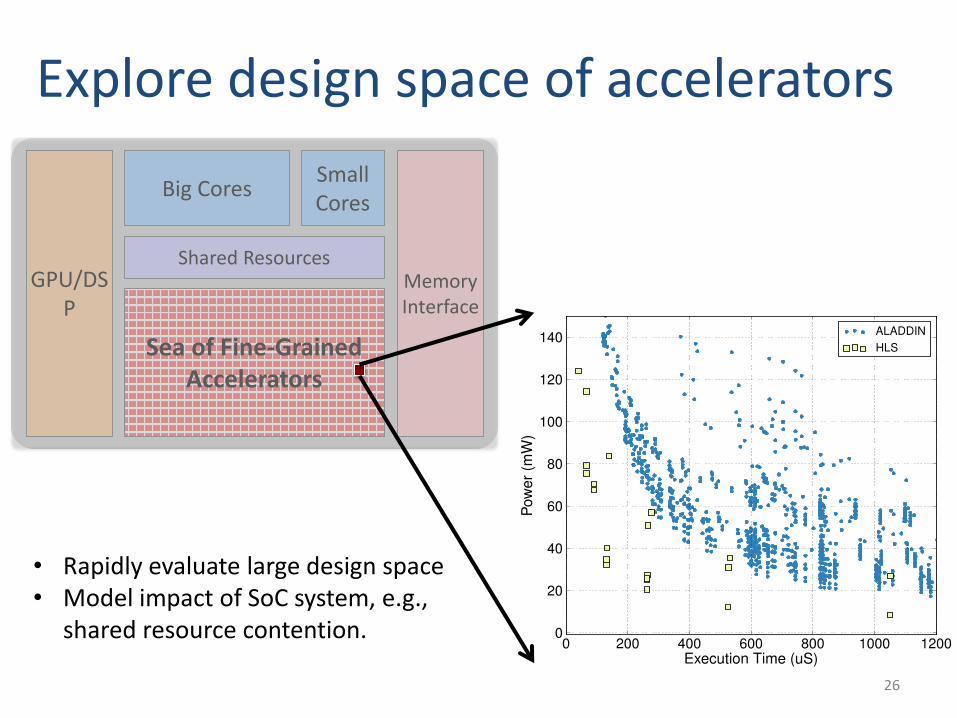
GPU/DSP
Big Cores
Shared ResourcesMemoryInterface
Sea of Fine-Grained Accelerators
Small Cores
Explore design space of accelerators
• Rapidly evaluate large design space • Model impact of SoC system, e.g.,
shared resource contention.
26
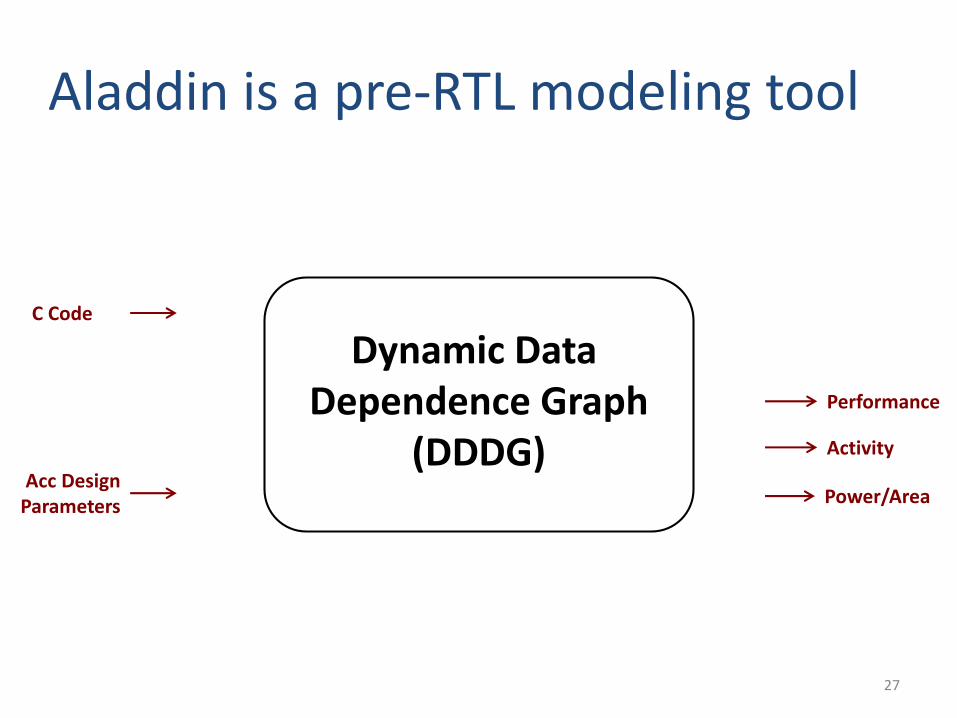
Aladdin is a pre-RTL modeling tool
C Code
Power/Area
Performance
Activity
Acc Design Parameters
Dynamic Data Dependence Graph
(DDDG)
27

Aladdin is a pre-RTL modeling tool
C CodeOptimistic
IRInitialDDDG
IdealisticDDDG
Program Constrained
DDDG
ResourceConstrained
DDDG
Power/Area Models
Optimization Phase
Realization Phase
Power/Area
Performance
Activity
Acc Design Parameters
28

Example of C to accelerator design
C Code:For (i=0; i<N; ++i)c[i] = a[i] + b[i];
0. r0=0 //i = 01. r4=load (r0 + r1) //load a[i]2. r5=load (r0 + r2) //load b[i]3. r6=r4 + r54. store(r0 + r3, r6) //store c[i]5. r0=r0 + 1 //++i6. r4=load(r0 + r1) //load a[i]7. r5=load(r0 + r2) //load b[i]8. r6=r4 + r59. store(r0 + r3, r6) //store c[i]10. r0 = r0 + 1 //++i…
29
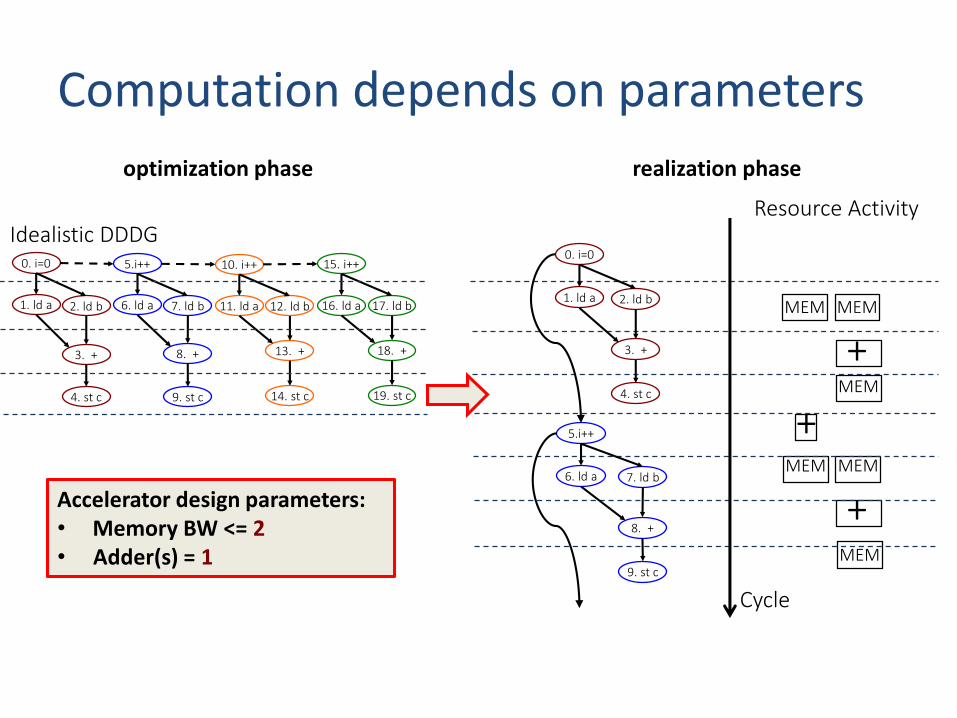
Computation depends on parameters
MEM MEM
MEM MEM
MEM
MEM
+
+
+
Resource Activity Idealistic DDDG
Accelerator design parameters:• Memory BW <= 2• Adder(s) = 1
0. i=0 5.i++ 10. i++
11. ld a 12. ld b
13. +
14. st c
6. ld a 7. ld b
8. +
9. st c
1. ld a 2. ld b
3. +
4. st c
15. i++
16. ld a 17. ld b
18. +
19. st c
Cycle
0. i=0
5.i++
6. ld a 7. ld b
8. +
9. st c
1. ld a 2. ld b
3. +
4. st c
optimization phase realization phase

Computation depends on parameters
MEM MEM MEM MEM
MEM MEM MEM MEM
MEM MEM
MEM MEM
+ +
+ +
+ +
+
Resource Activity
Cycle
0. i=0 5.i++
10. i++
11. ld a 12. ld b
13. +
14. st c
7. ld b
8. +
9. st c
1. ld a 2. ld b
3. +
4. st c
15. i++
16. ld a 17. ld b
18. +
19. st c
6. ld a
Idealistic DDDG0. i=0 5.i++ 10. i++
11. ld a 12. ld b
13. +
14. st c
6. ld a 7. ld b
8. +
9. st c
1. ld a 2. ld b
3. +
4. st c
15. i++
16. ld a 17. ld b
18. +
19. st c
Accelerator design parameters:• Memory BW <= 4• Adder(s) = 2
optimization phase realization phase
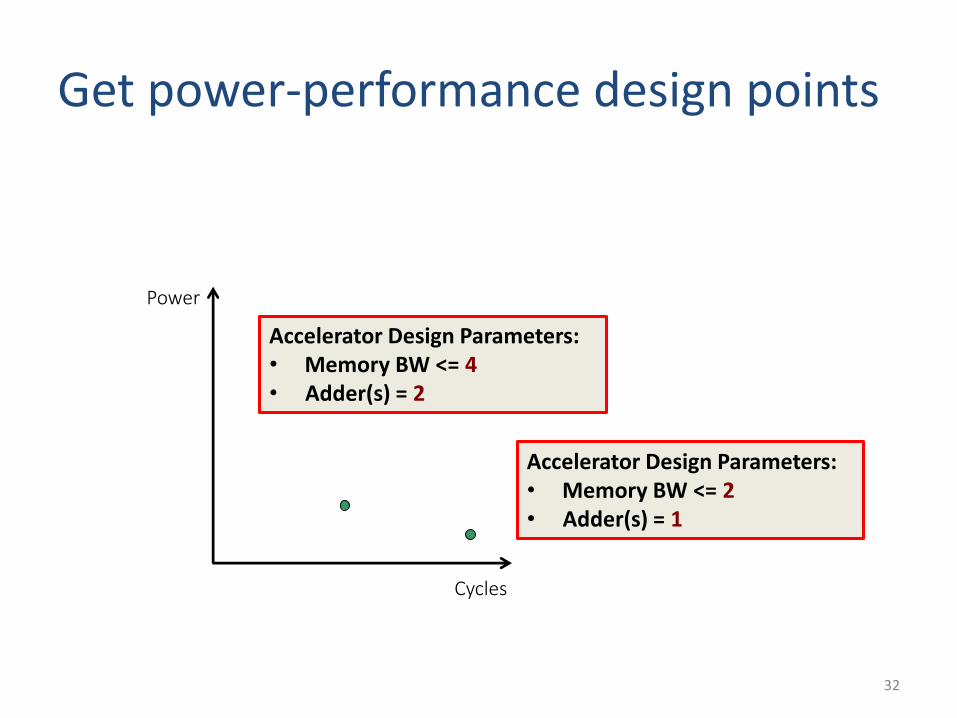
Cycles
Power
Get power-performance design points
32
Accelerator Design Parameters:• Memory BW <= 2• Adder(s) = 1
Accelerator Design Parameters:• Memory BW <= 4• Adder(s) = 2

Easily generate full design space
Cycles
Power
33
Designer chooses best design from Pareto frontier
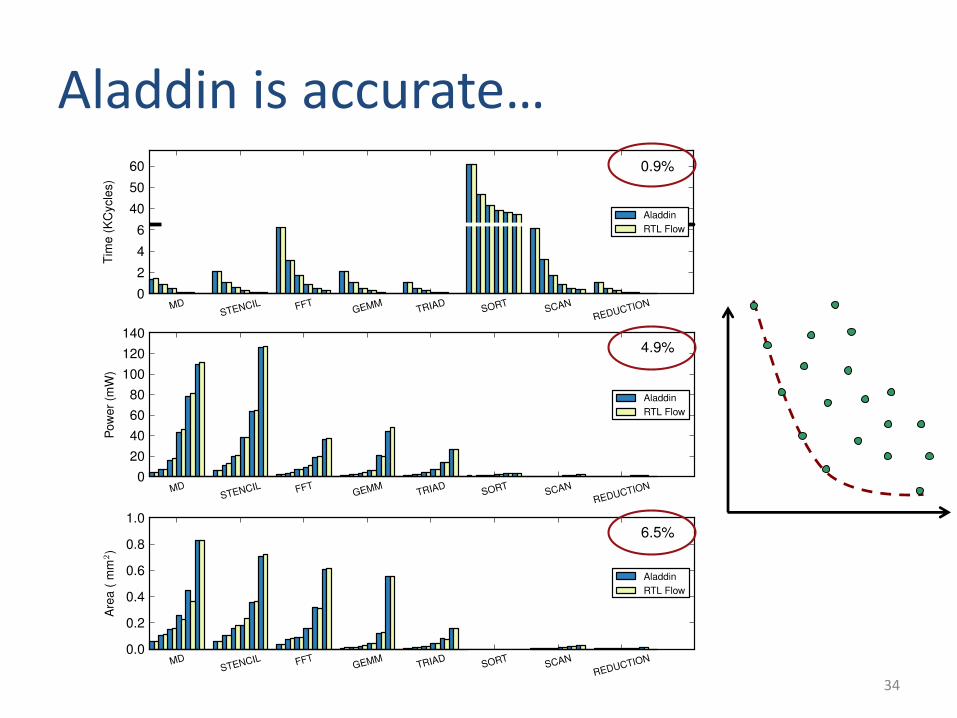
Aladdin is accurate…
34
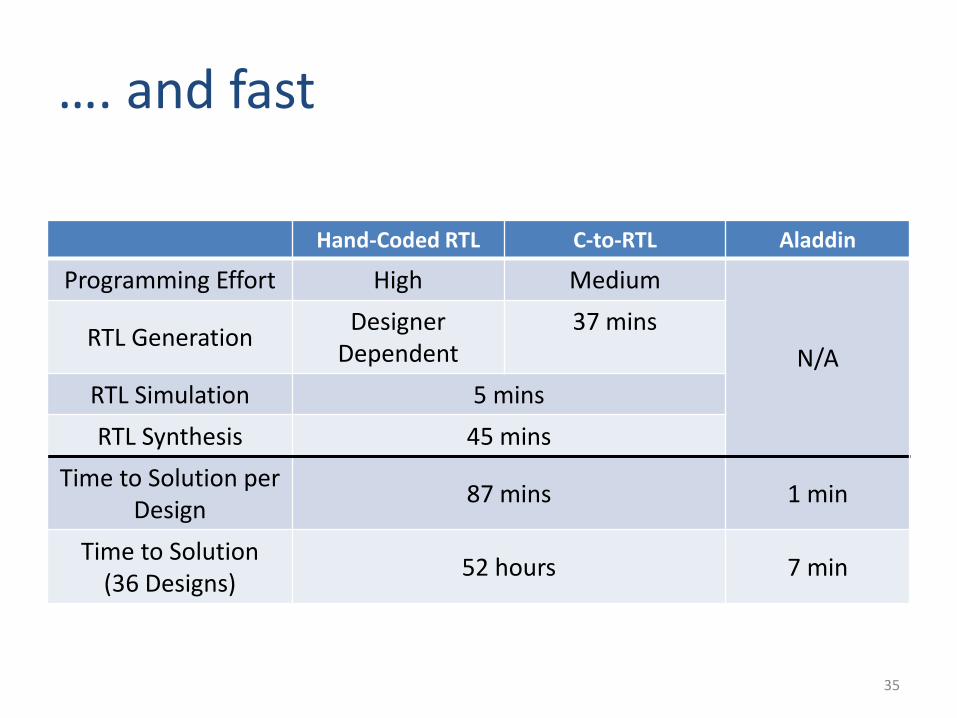
…. and fast
Hand-Coded RTL C-to-RTL Aladdin
Programming Effort High Medium
N/ARTL Generation
DesignerDependent
37 mins
RTL Simulation 5 mins
RTL Synthesis 45 mins
Time to Solution per Design
87 mins 1 min
Time to Solution (36 Designs)
52 hours 7 min
35

Aladdin enables pre-RTL simulation of accelerators with the rest of the SoC
GPU
Shared Resources
MemoryInterface
Sea of Fine-Grained Accelerators
Big Cores
Small Cores
GPGPU-Sim
MARSx86...
XIOSim…
Cacti/Orion2
DRAMSim2
36

Automatic parallelization is the other path
Parallel processing Specialized processing
37

HELIX is an automatic parallelization framework to enhance TLP in CMPs
• Parallelize loops by distributing loop iterations across multiple CMP cores– Like DOACROSS parallelization
• Heavily relies on code analysis (DDG) and various transformations– No speculation (at this time)
• Synchronization via memory– Performance sensitive to core-to-core
communication
38[S. Campanoni et al., CGO 2012]

Convert loop into a form that facilitates HELIX parallelization
• Sequential segments (ss) contain loop-carried data dependences– ss in next iteration may require data from prior iteration(s)– Synchronization via wait/signal instructions
39
original
loop
code
prologue
loop
body
seq. segment 1
parallel code
seq. segment 2
parallel code
seq. segment 3
wait(1)
signal(1)
wait(2)
signal(2)
wait(3)
signal(3)
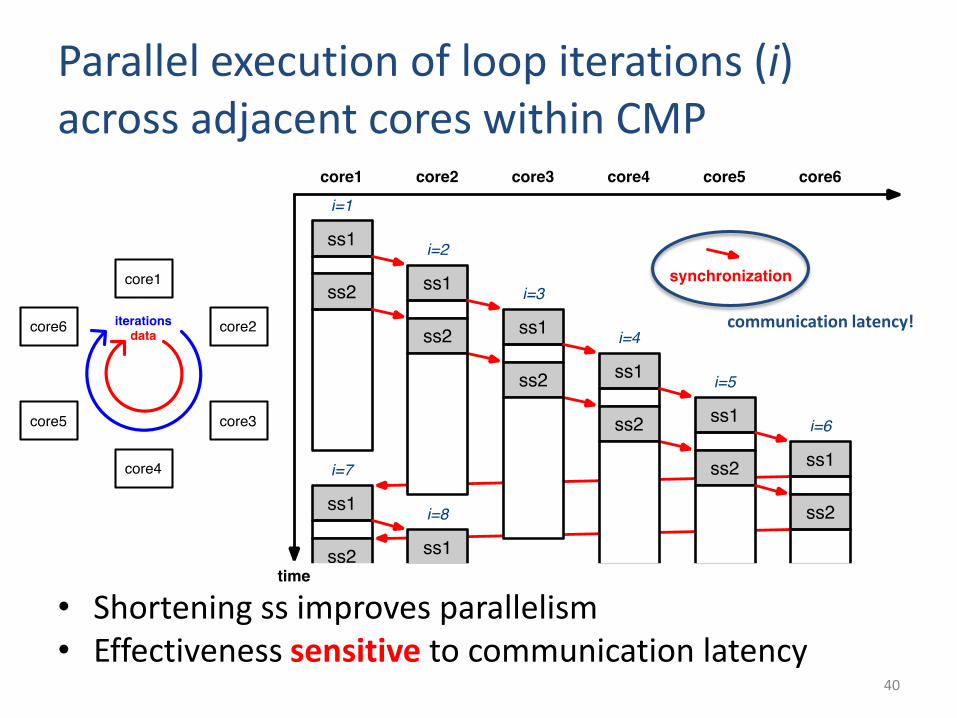
Parallel execution of loop iterations (i) across adjacent cores within CMP
• Shortening ss improves parallelism• Effectiveness sensitive to communication latency
communication latency!
40
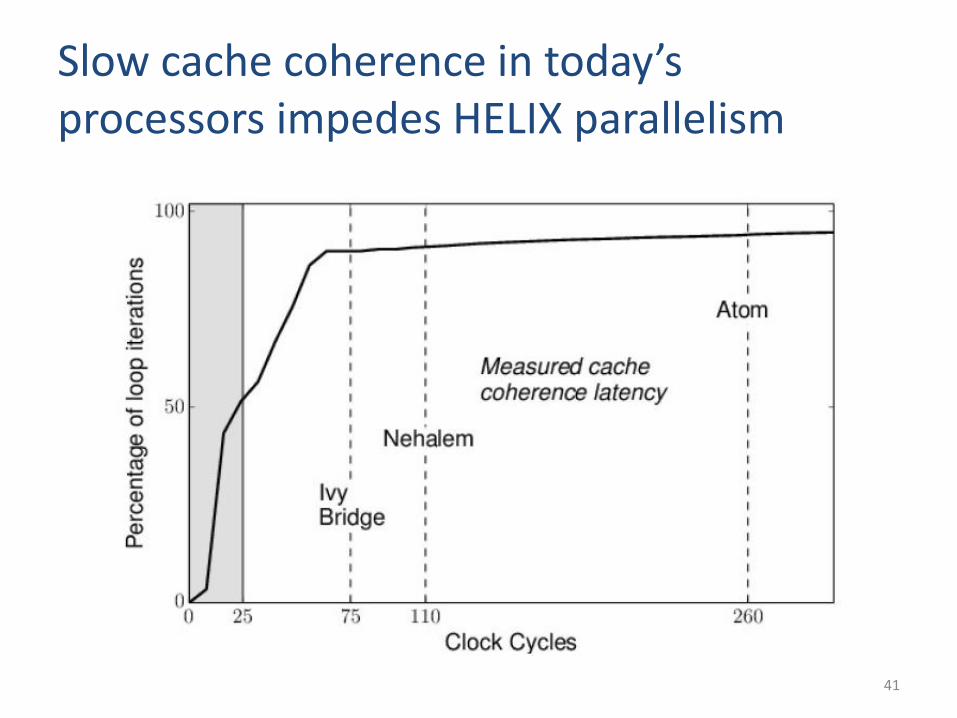
Slow cache coherence in today’s processors impedes HELIX parallelism
41
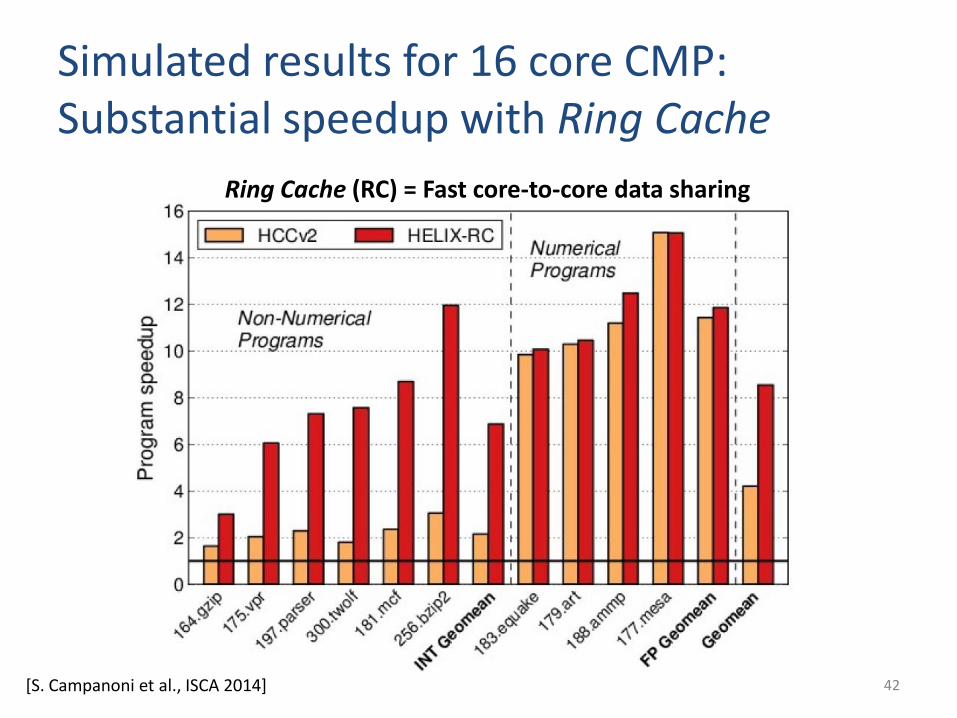
Simulated results for 16 core CMP: Substantial speedup with Ring Cache
42
Ring Cache (RC) = Fast core-to-core data sharing
[S. Campanoni et al., ISCA 2014]

What if we relax strict adherence to program semantics?
• Inspired by approximate computing
• Tolerable distortion is workload-dependent
• E.g., bzip2 has 2 outputs
43
Compressed file (100%)Statistics (0 ~ 100%)

E.g., break sequential bottlenecks
• A code region executed sequentially
44
Inst 1Inst 2Inst 3Inst 4
Inst 3Inst 4
Inst 3Inst 4
Dep
Thread 1 Thread 2 Thread 3
Inst 1Inst 2
Inst 1Inst 2
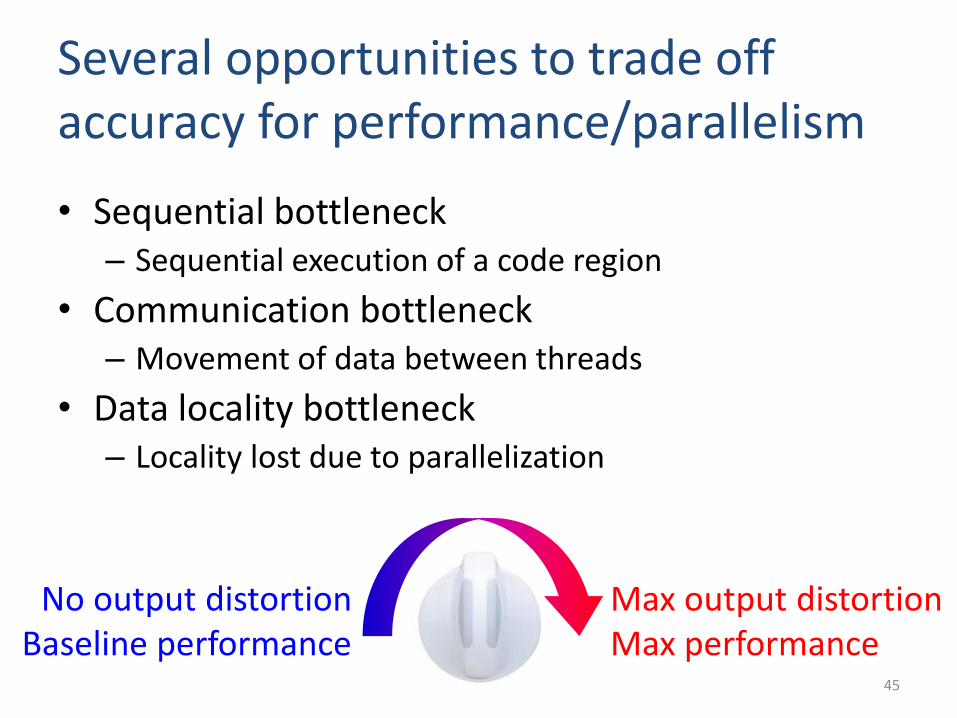
Several opportunities to trade off accuracy for performance/parallelism
• Sequential bottleneck– Sequential execution of a code region
• Communication bottleneck– Movement of data between threads
• Data locality bottleneck– Locality lost due to parallelization
45
No output distortionBaseline performance
Max output distortionMax performance
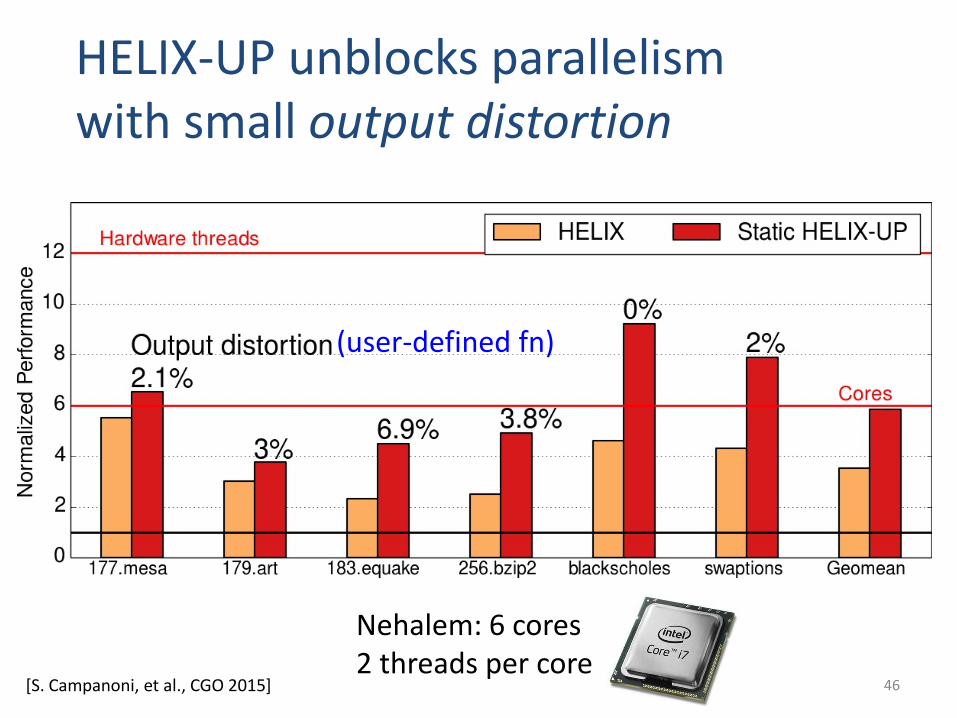
HELIX-UP unblocks parallelismwith small output distortion
46
Nehalem: 6 cores2 threads per core
(user-defined fn)
[S. Campanoni, et al., CGO 2015]
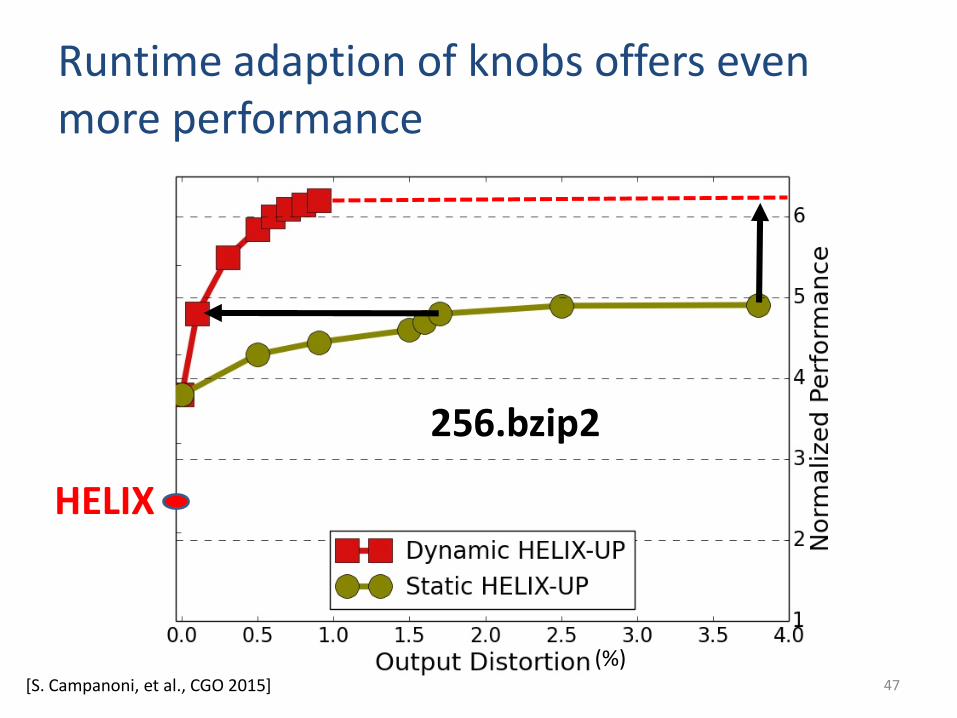
Runtime adaption of knobs offers even more performance
47
256.bzip2
HELIX
(%)[S. Campanoni, et al., CGO 2015]

Many examples of approximate computing hardware proposed in recent years
48
• Simplify hardware/logic to trade accuracy for power, delay, and area– Approximate logic to “check” computation 1
– Imprecise arithmetic for CORDIC 2
– Approximate adders for DSP 3
– ABACUS: Approximate logic synthesis 4
original exact design description
AST modified AST approximate design description
Fig. 2. Overall methodology of ABACUS.
variants through transformations to the AST; and (iii) finallywrite back the modified AST into readable RTL or behavioralHDL design. The three steps are illustrated in Figure 2. Thenew approximate design is then pushed through the standardASIC/FPGA flow for evaluation in terms of accuracy and otherdesign metrics. In an AST, each node represents an actionto be taken by the behavioral code, or an object to be actedupon [17]. Building an AST for a HDL syntax automaticallycaptures all the concurrency that is in the design. Compared toa regular parsing tree, the AST captures the logical structuresof the statements and shows less of the grammar structure,which makes it a better candidate to analyze and transformthe code. Compared to control flow graphs, ASTs are easierto use to produce readable code. The novelty in our ABACUSapproach allows us to make automated transformations toany generic HDL design without the need to have any apriori knowledge of the functionality or the semantics of thedesign. Hence, a much broader range of transformations canbe explored at the high level, leading to a superior design thatwhat could not be achieved with prior approaches.
There are two key questions we address in our approach:
1. What kind of transformations can be applied to HDL-based ASTs? Generating approximate AST variantsfrom the original AST requires the application ofHDL-aware transformations that lead to syntacticallycorrect, yet approximate HDL designs. In SectionIII-A, we propose a set of transformations that can beapplied to the AST to generate meaningful approxi-mate HDL designs.
2. How do we avoid the explosive increase in designsearch space resulting from these transformations?The application of a set of operators combinatoriallyto the original design can lead to an exponential num-ber of variant designs that need to be explored. Giventhe size of modern designs and runtimes of typicaldesign flows, this approach is clearly infeasible interms of total runtime. Thus, we propose in SectionIII-B an approach to effectively explore the design ofpossible approximate designs and identify the onesthat provide the optimal trade-offs between accuracyand hardware design metrics.
A. Generating HDL-based Approximate Transformations
We present a set of transformation operators thatcan be applied to the original HDL-based AST toyield meaningful approximate designs for error-resilientapplications. Whenever any of these transformations isinvoked, ABACUS automatically traverses through the ASTand searches for places in the AST where the change couldbe applied. We propose and implement the following fivetransformation operators in ABACUS:
1. Data Type Simplifications: For applications dealing withmassive data, truncating the size of intermediate signals maybeagood way to achievesavings on power, since it reduces therequirements for the underlying hardware, especially for fixed-point arithmetic operations. ABACUS is capable of performingtruncation in two ways: first, by resetting a number of the leastsignificant bits to zero, and second by truncating a certainnumber of significant bits for operands during binary arith-metic operations and then shifting the result of the operationto get the approximation. The latter transformation yields moresignificant power and area savings.
2. Operation Transformations: Another proposed operator is tosubstitute an arithmetic operation with one or more arithmeticapproximate operations that use less power and hardware area.For example, arithmetic additions could be replaced by bitwiseORs or a multiplication could be replaced by shifts and anaddition. Also, astandard adder or multiplier could be replacedby an approximate unit from the ones proposed in the literature[11]–[13]. Thus, our behavioral-based approach can easilyleverage approximate Boolean arithmetic circuits.
3. Arithmetic Expression Transformations: There are caseswhere near similar arithmetic structures appear in the samestatement description. Through a transformation, these near-similar structures could be transformed to approximate similarstructures in which case they could be shared and simplified.For instance, we can approximate the expression (wi ⇥xi +wj ⇥xj) with substitutions to the variables or the constants,such as substituting xj by xi leading to (wi + wj) ⇥ xi orsubstituting wj by wi leading towi⇥(xi+xj), thus saving onemultiplier. We can simplify computations by sharing commonor similar operands and get good approximations.
4. Variable-to-Constant Substitution Transformations: Simula-tion results of the original design contain useful informationabout the numerical characteristics of the design variables.This information can guide the transformation operations. Forinstance, if an intermediate variable derived from a certainarithmetic operation appears to be a constant or has a smallstandard deviation in the simulation results, then we can sub-stitute it with a constant based on its average value, thus savingits computational circuit. ABACUS implements this feature byreading simulation results from the original exact design toidentify design variables that are constant or are within a 10%standard deviation. These design variables are candidates forsubstitution by a constant based on their simulation results.
5. Loop Transformations: ABACUSautomatically unrolls loopsin behavioral descriptions. Loop unrolling is typically usedas a compiler transformation technique; however, in our casewe use automatic unrolling in the pre-compiler phase of thebehavioral description of an algorithm. Loop unrolling opensthe door for the application of other simplification operators.In addition, the unrolling can be done in an approximate wayby skipping certain iterations and substituting the outcomes ofthese iterations from the results of prior iterations.
B. Effective Design Space Exploration
Application of the proposed operator transformations canlead to a combinatorial explosion in possible approximatedesign variants, as there are multiple operators, where eachoperator can be applied at several locations, and the AST
1[M. Choudhury et al. DATE 2008]2[J. Huang & J Lach DAC 2011]
3[V. Gupta et al. TCAD 2013]4[K. Nepal et al. DATE 2014]
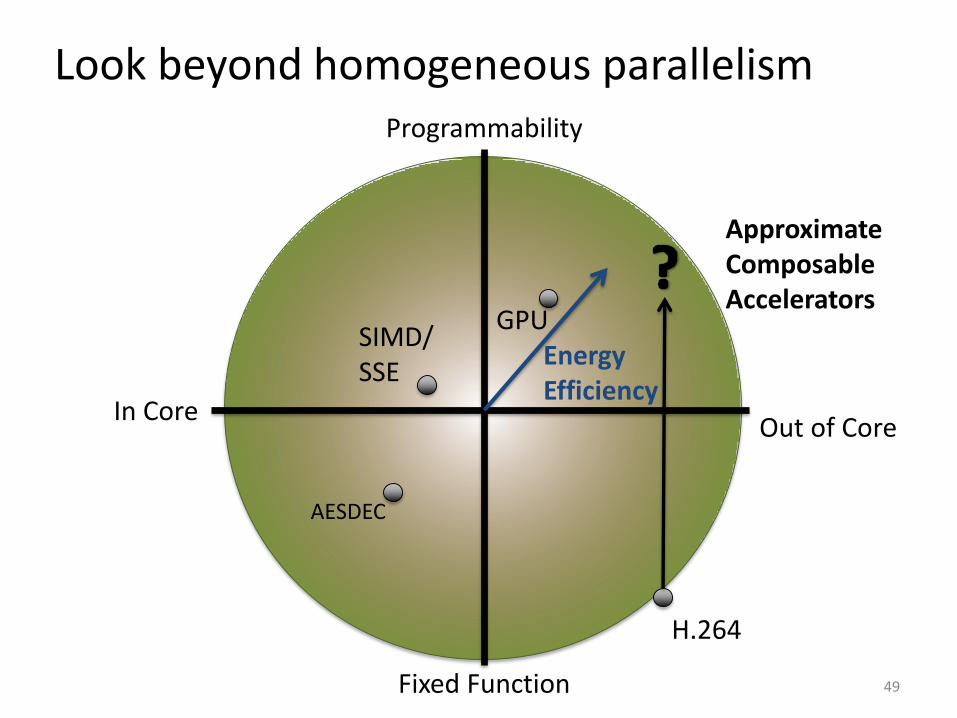
Look beyond homogeneous parallelism
49
SIMD/ SSE
AESDEC
In CoreOut of Core
GPU
H.264
Approximate ComposableAccelerators
Energy Efficiency
Programmability
Fixed Function
UP
To wrap up…
50
original exact design description
AST modified AST approximate design description
Fig. 2. Overall methodology of ABACUS.
variants through transformations to the AST; and (iii) finallywrite back the modified AST into readable RTL or behavioralHDL design. The three steps are illustrated in Figure 2. Thenew approximate design is then pushed through the standardASIC/FPGA flow for evaluation in terms of accuracy and otherdesign metrics. In an AST, each node represents an actionto be taken by the behavioral code, or an object to be actedupon [17]. Building an AST for a HDL syntax automaticallycaptures all the concurrency that is in the design. Compared toa regular parsing tree, the AST captures the logical structuresof the statements and shows less of the grammar structure,which makes it a better candidate to analyze and transformthe code. Compared to control flow graphs, ASTs are easierto use to produce readable code. The novelty in our ABACUSapproach allows us to make automated transformations toany generic HDL design without the need to have any apriori knowledge of the functionality or the semantics of thedesign. Hence, a much broader range of transformations canbe explored at the high level, leading to a superior design thatwhat could not be achieved with prior approaches.
There are two key questions we address in our approach:
1. What kind of transformations can be applied to HDL-based ASTs? Generating approximate AST variantsfrom the original AST requires the application ofHDL-aware transformations that lead to syntacticallycorrect, yet approximate HDL designs. In SectionIII-A, we propose a set of transformations that can beapplied to the AST to generate meaningful approxi-mate HDL designs.
2. How do we avoid the explosive increase in designsearch space resulting from these transformations?The application of a set of operators combinatoriallyto the original design can lead to an exponential num-ber of variant designs that need to be explored. Giventhe size of modern designs and runtimes of typicaldesign flows, this approach is clearly infeasible interms of total runtime. Thus, we propose in SectionIII-B an approach to effectively explore the design ofpossible approximate designs and identify the onesthat provide the optimal trade-offs between accuracyand hardware design metrics.
A. Generating HDL-based Approximate Transformations
We present a set of transformation operators thatcan be applied to the original HDL-based AST toyield meaningful approximate designs for error-resilientapplications. Whenever any of these transformations isinvoked, ABACUS automatically traverses through the ASTand searches for places in the AST where the change couldbe applied. We propose and implement the following fivetransformation operators in ABACUS:
1. Data Type Simplifications: For applications dealing withmassive data, truncating the size of intermediate signals maybeagood way to achievesavings on power, since it reduces therequirements for the underlying hardware, especially for fixed-point arithmetic operations. ABACUS is capable of performingtruncation in two ways: first, by resetting a number of the leastsignificant bits to zero, and second by truncating a certainnumber of significant bits for operands during binary arith-metic operations and then shifting the result of the operationto get the approximation. The latter transformation yields moresignificant power and area savings.
2. Operation Transformations: Another proposed operator is tosubstitute an arithmetic operation with one or more arithmeticapproximate operations that use less power and hardware area.For example, arithmetic additions could be replaced by bitwiseORs or a multiplication could be replaced by shifts and anaddition. Also, astandard adder or multiplier could be replacedby an approximate unit from the ones proposed in the literature[11]–[13]. Thus, our behavioral-based approach can easilyleverage approximate Boolean arithmetic circuits.
3. Arithmetic Expression Transformations: There are caseswhere near similar arithmetic structures appear in the samestatement description. Through a transformation, these near-similar structures could be transformed to approximate similarstructures in which case they could be shared and simplified.For instance, we can approximate the expression (wi ⇥xi +wj ⇥xj) with substitutions to the variables or the constants,such as substituting xj by xi leading to (wi + wj) ⇥ xi orsubstituting wj by wi leading towi⇥(xi+xj), thus saving onemultiplier. We can simplify computations by sharing commonor similar operands and get good approximations.
4. Variable-to-Constant Substitution Transformations: Simula-tion results of the original design contain useful informationabout the numerical characteristics of the design variables.This information can guide the transformation operations. Forinstance, if an intermediate variable derived from a certainarithmetic operation appears to be a constant or has a smallstandard deviation in the simulation results, then we can sub-stitute it with a constant based on its average value, thus savingits computational circuit. ABACUS implements this feature byreading simulation results from the original exact design toidentify design variables that are constant or are within a 10%standard deviation. These design variables are candidates forsubstitution by a constant based on their simulation results.
5. Loop Transformations: ABACUSautomatically unrolls loopsin behavioral descriptions. Loop unrolling is typically usedas a compiler transformation technique; however, in our casewe use automatic unrolling in the pre-compiler phase of thebehavioral description of an algorithm. Loop unrolling opensthe door for the application of other simplification operators.In addition, the unrolling can be done in an approximate wayby skipping certain iterations and substituting the outcomes ofthese iterations from the results of prior iterations.
B. Effective Design Space Exploration
Application of the proposed operator transformations canlead to a combinatorial explosion in possible approximatedesign variants, as there are multiple operators, where eachoperator can be applied at several locations, and the AST
ABACUS